
App Store: Переводчик для камеры: Перевод
Описание
Переводите текст из фото и документов на любые языки одним касанием. Мощное приложение для камеры и перевод на основе искусственного интеллекта. Сканирование текста на большинстве языков мира и перевод в одно мгновение.
Наведите камеру из приложения на текст на фото или документе, нажмите кнопку, чтобы получить перевод на нужный язык. Камера сканирует обьемные документы на разных языках и система переводит их на нужные вам. Сканирование и перевод осуществляются мгновенно обучаемой системой, использующей гигантские массивы данных.
Переводчик для камеры — лучшее приложение для перевода для изучающих языки и путешественников:
— мгновенный перевод текста.
— поддержка более 100 языков.
— распознавание текстовых документов большого количества форматов.
— распознавание фото и рисунков форматов png, jpg и других
— возможность редактирования отсканированного текста в приложении.
— копирование текста и возможность поделиться им через любые приложения.
Пепеводчик для камеры — лучшее приложение для путешествий,туризма и обучения. С его помощью можно легко перевести меню в ресторане или отеле, газету или уличную вывеску всего одним касанием. Исследователи также могут использовать его для сканирования и перевода документов на свой язык.
Пользователи, оформившие платную подписку получают неограниченный доступ к услугам перевода.
Оплата осуществляется через аккаунт iTunes после подтверждения оплаты. Подписка продлевается в течение 24 часов до окончания действующей подписки. Управление подпиской и отключение автоматического продления осуществляется в разделе Настройки аккаунта после оплаты полписки.
Неиспользованный срок бесплатного тестового периода, если предлагается, будет списан после покупки пользователем подписки, если это применимо.
Условия и положения: http://vulcanlabs.co/index.php/terms-of-use/
Политика конфиденциальности: http://vulcanlabs.
Написать нам: [email protected]
Версия 12.1
Исправьте незначительные ошибки
Оценки и отзывы
Оценок: 1,7 тыс.
Очень хороший, но бесплатный всего 3 дня.
Прекрасное приложение! Воспользовался для перевода с греческого. Камера работает отлично, каждую букву считал. Извините, но я отказался от подписки, т.к мне не требуется в дальнейшем, но если кому то нужно постоянно переводить, советую.
Переводчик
Удобное приложение.
Неудобно.
 Ещё и платное.
Ещё и платное.Работает. Но Результат нужен наложением прямо в кадре, а не строками текста, которые при переводе табличек ещё и перепутаны не по порядку.
Подписки
Недельная премия
Неограниченный транслятор камеры на одну неде
Пробная подписка
Ежемесячная премия
Неограниченный транслятор камеры на один меся
Пробная подписка
Разработчик Vulcan Labs Company Limited указал, что в соответствии с политикой конфиденциальности приложения данные могут обрабатываться так, как описано ниже. Подробные сведения доступны в политике конфиденциальности разработчика.
Данные, используемые для отслеживания информации
Следующие данные могут использоваться для отслеживания информации о пользователе в приложениях и на сайтах, принадлежащих другим компаниям:
- Геопозиция
- Идентификаторы
Не связанные с пользователем данные
Может вестись сбор следующих данных, которые не связаны с личностью пользователя:
- Геопозиция
- Пользовательский контент
- Идентификаторы
- Данные об использовании
- Диагностика
Конфиденциальные данные могут использоваться по-разному в зависимости от вашего возраста, задействованных функций или других факторов. Подробнее
Подробнее
Информация
- Провайдер
- Vulcan Labs Company Limited
- Размер
- 442,1 МБ
- Категория
- Справочники
- Возраст
- 4+
- Copyright
- © Vulcan Labs 2018
- Цена
- Бесплатно
- Сайт разработчика
- Поддержка приложения
- Политика конфиденциальности
Другие приложения этого разработчика
Вам может понравиться
Перевод с помощью Weblate — документация Weblate 4.
 14.2
14.2Благодарим вас за проявленный интерес к переводу с помощью Weblate. Проекты могут быть настроены либо на прямой перевод, либо на принятие предложений, внесённых пользователями без учётных записей.
В целом, существует два режима перевода:
Проект принимает прямые переводы
Проект принимает только предложения, которые автоматически подтверждаются по достижении определённого числа голосов
Для получения более подробной информации о процессе перевода, пожалуйста, ознакомьтесь с разделом Рабочие процессы перевода.
Варианты видимости проекта перевода:
См.также
Управление доступом, Рабочие процессы перевода
Проекты перевода
В проекте перевода содержатся относящиеся к нему компоненты — ресурсы связанные с одним и тем же программным обеспечением, книгой или проектом.
Ссылки на перевод
При переходе к компоненту будет представлен список ссылок, которые ведут к актуальному переводу. Далее перевод подразделяется на отдельные проверки, такие как Непереведённые строки или Незавершённые строки.
Предложения
Примечание
Фактические разрешения могут отличаться в зависимости от ваших настроек Weblate.
Анонимные пользователи могут только вносить предложения (по умолчанию). Тоже самое могут делать и зарегистрированные пользователи, если они неуверенны в собственном переводе. Эти предложения в дальнейшем сможет просмотреть и отрецензировать другой переводчик.
Предложения ежедневно сканируются с целью удаления дубликатов и предложений, совпадающих с текущим переводом.
Варианты
Варианты используются для группировки вариантов строки с различной длиной. Таким образом, пользовательский интерфейс вашего проекта может использовать различные строки в зависимости от размеров экрана или окна.
См.также
Варианты строк, Варианты
Метки
Метки используются для категоризации строк в проекте для дальнейшего изменения рабочего процесса локализации (например, для определения категорий строк).
Weblate использует следующие метки:
- Автоматически переведено
Строка была переведена с помощью Автоматический перевод.
- Исходная строка требует рецензирования
Строка была помечена для правки с помощью Рецензирование исходных строк.
См.также
Метки строк
Перевод
На странице перевода отображаются исходная строка и собственно область редактирования перевода. Если переводится строка со множественным числом, то показываются несколько исходных строк и областей редактирования, каждая из которых снабжена меткой, описывающей и приводящей числовые примеры для этой формы множественного числа в данном языке.
Все специальные пробельные символы подчёркиваются красным цветом и обозначаются серыми видимыми символами-заменителями. Более одного последовательного пробела также подчёркиваются красным цветом, чтобы предупредить переводчика о потенциальной проблеме форматирования.
На этой странице также могут быть показаны различные кусочки дополнительной информации, большая часть которой берётся из исходного кода проекта (например, контекст, комментарии разработчика или место, где используется сообщение). Если переводчик в параметрах своего профиля выбрал дополнительные языки, то над исходной строкой будет также показан перевод на каждый из этих языков (смотрите раздел Вспомогательные языки).
Если переводчик в параметрах своего профиля выбрал дополнительные языки, то над исходной строкой будет также показан перевод на каждый из этих языков (смотрите раздел Вспомогательные языки).
Под переводом будут показаны предложения, внесённые другими пользователями, которые вы, в свою очередь, можете принять(✓), принять с изменениями(✏️) или удалить(🗑).
Формы множественного числа
Слова, изменяющие свою форму в зависимости от того, какое число находится рядом с ними, называются в Weblate «формами множественного числа». Каждый язык имеет своё определение множественного числа. В английском языке, например, существует всего одна такая форма. Если слово стоит в единичном числе, к примеру, «автомобиль» — «car» — неявно подразумевается именно одна машина, а во множественном — «автомобили» — «cars» — подразумеваются уже две или более машины, либо же просто понятие «автомобили» как существительное. Такие языки, как, например, чешский, арабский или русский, имеют больше форм множественного числа, а правила употребления этих форм отличаются от правил английского.
Weblate полностью поддерживает каждую из этих форм, на каждом соответствующем языке, путём отдельного перевода каждой формы множественного числа. Количество полей и способ их использования в переводе зависит от настроенной формулы множественного числа. Weblate показывает только основную информацию, но вы можете найти более подробное описание в языковых правилах для форм множественного числа от Консорциума Юникода.
См.также
Формула множественного числа
Альтернативные переводы
Добавлено в версии 4.13.
Примечание
В настоящее время это поддерживается только с Многозначный CSV-файл.
В некоторых форматах можно быть больше переводов для одной строки. Вы можете добавить больше альтернативных переводов, используя меню Инструменты. Любые пустые дополнительные переводы будут автоматически удалены при сохранении.
Горячие клавиши
Изменено в версии 2.18: Горячие клавиши в версии 2.18 были исправлены, чтобы они с меньшей вероятностью конфликтовали с клавишами по умолчанию браузера или системы.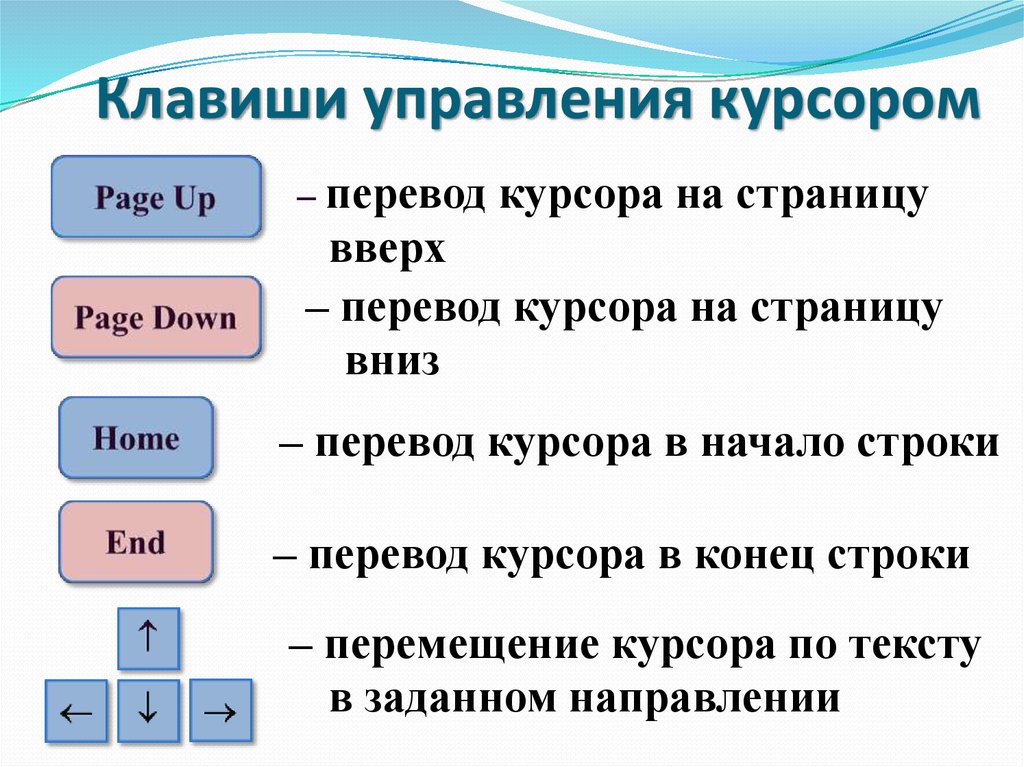
При переводе можно использовать следующие горячие клавиши:
Горячие клавиши | Описание |
|---|---|
Alt+Home | Переход к первому переводу в текущем поиске. |
Alt+End | Переход к последнему переводу в текущем поиске. |
Alt+PageUp или Ctrl+↑ или Alt+↑ или Cmd+↑ | Переход к предыдущему переводу в текущем поиске. |
Alt+PageDown или Ctrl+↓ или Alt+↓ или Cmd+↓ | Переход к последующему переводу в текущем поиске. |
Alt+Enter или Ctrl+Enter или Cmd+Enter | Submit current form; this is same as pressing Save and continue while editing translation. |
Ctrl+Shift+Enter или Cmd+Shift+Enter | Снятие с перевода пометки «на правку» и его сохранение. |
Ctrl+E или Cmd+E | Фокусировка на редакторе перевода. |
Ctrl+U или Cmd+U | Фокусировка на редакторе комментариев. |
Ctrl+M или Cmd+M | Показ вкладки Автоматические предложения, смотреть раздел Автоматические предложения. |
Ctrl+1 — Ctrl+9 или Cmd+1 — Cmd+9 | Копирование из исходной строки кусочка под соответствующим номером. |
Ctrl+M+1 to 9 or Cmd+M+1 to 9 | Копирование в текущий перевод машинного перевода с заданным номером. |
Ctrl+I+1 to 9 or Cmd+I+1 to 9 | Игнорирование одного элемента в списке неудачных проверок. |
Ctrl+J или Cmd+J | Показ вкладки Соседние строки. |
Ctrl+S или Cmd+S | Фокус на поле поиска. |
Ctrl+O или Cmd+O | Копировать исходную строку. |
Ctrl+Y или Cmd+Y | Переключение флажка На правку. |


Визуальная клавиатура
Чуть выше поля перевода показывается небольшой ряд визуальной клавиатуры. Она может быть полезна для того, чтобы помнить о местной пунктуации (поскольку строка является локальной для каждого языка) или иметь под рукой символы, которые иначе трудно набрать.
Показываемые символы разделены на три категории:
Настроенные пользователем Специальные символы, определенные в Профиль пользователя
Предоставляемые Weblate символы для конкретного языка (например, кавычки или символы, специфичные для текста справа-налево)
Символы, настроенные через параметр
SPECIAL_CHARS
Контекст перевода
Это контекстное описание содержит инфо, относящуюся к текущей строке.
- Атрибуты строки
Такие вещи, как идентификатор сообщения, его контекст (
msgctxt) или местоположение в исходном коде.- Снимки экрана
В Weblate могут быть загружены снимки экрана, чтобы лучше информировать переводчиков о том, где и как используется строка, смотрите раздел Визуальный контекст для строк.
- Соседние строки
Отображает соседние сообщения из файла перевода. Обычно они также используются в аналогичном контексте и оказываются полезными для поддержания согласованности перевода.
- Другие вхождения
В случае, если сообщение появляется в нескольких местах (например, в нескольких компонентах), эта вкладка показывает их все, если в них найдены противоречия (смотрите раздел Противоречия). Вы можете выбрать, какую из строк использовать.
- Память переводов
Показывает похожие строки, переведённые в прошлом, смотрите раздел Память переводов.
- Глоссарий
Отображает термины из глоссария проекта, используемые в текущем сообщении.

- Недавние изменения
Список людей, которые недавно изменили это сообщение, используя Weblate.
- Проект
Информация о проекте, например, инструкции для переводчиков, или каталог, или ссылка на строку в репозитории системе контроля версий, используемой проектом.
Если вам нужны прямые ссылки, формат перевода должен это поддерживать.
История переводов
Каждое изменение по умолчанию (если это не отключено в настройках компонента) сохраняется в базе данных и может быть отменено. Также при необходимости через нижележащую систему управления версиями можно отменить всё, что угодно.
Длина переведённой строки
Weblate может ограничивать длину перевода несколькими способами, чтобы гарантировать, что переведённая строка не будет слишком длинной:
По умолчанию установлена ограничение в соответствии с которым перевод может быть не более чем в десять раз длиннее исходной строки. Его можно отключить с помощью параметра
LIMIT_TRANSLATION_LENGTH_BY_SOURCE_LENGTH. Если вы упёрлись в это ограничение, то это может быть вызвано тем, что одноязычный перевод ошибочно сконфигурирован как двуязычный, в результате чего Weblate считает, что исходной строкой является ключ перевода, а не собственно исходная строка. Дополнительную информацию смотрите в разделе Двуязычные и одноязычные форматы.
Если вы упёрлись в это ограничение, то это может быть вызвано тем, что одноязычный перевод ошибочно сконфигурирован как двуязычный, в результате чего Weblate считает, что исходной строкой является ключ перевода, а не собственно исходная строка. Дополнительную информацию смотрите в разделе Двуязычные и одноязычные форматы.Максимальная длина в символах, определяемая в файле перевода или флагом, смотрите раздел Максимальная длина перевода.
Максимальный отрисовываемый размер текста в пикселях, определяемый флагами, смотрите раздел Максимальный размер перевода.
Автоматические предложения
На основе своих настроек и языка, на который вы переводите, Weblate подберёт несколько сервисов машинного перевода и памяти переводов и обеспечит вам доступ к предложениям от оных. Все машинные переводы будут доступны на одной вкладке на странице перевода.
См.также
Список поддерживаемых инструментов можно найти в разделе Настройка автоматических предложений.
Автоматический перевод
Для автоматического начального перевода вашего проекта на основе внешних источников вы можете использовать Автоматический перевод, который доступен в меню Инструменты для определённой пары компонента и языка:
Возможны два режима работы этого инструмента:
Вы также можете выбрать, какие строки должны быть переведены автоматически.
Предупреждение
Имейте в виду, что если использовать широкие фильтры, вроде фильтра Все строки, это приведёт к перезаписи существующих переводов.
Инструмент полезен в ряде ситуаций, например, при объединении переводов различных компонентов (к примеру, приложения его веб-сайта) или при начальном переводе нового компонента с использованием существующих переводов (памяти переводов).
Автоматически переведённые строки помечены Автоматически переведено.
См.также
Поддержание единого перевода в разных компонентах
Ограничение частоты запросов
Чтобы избежать злоупотребления интерфейсом, ограничение на частоту запросов применяется к некоторым операциям, таким как поиск, отправка контактных форм или перевод. В случае воздействия, вы будете на определённый период заблокированы, по истечению которого вы сможете заново выполнить операцию.
В случае воздействия, вы будете на определённый период заблокированы, по истечению которого вы сможете заново выполнить операцию.
Ограничения по умолчанию и точная настройка описаны в руководстве по администрированию, смотреть раздел Ограничение частоты запросов.
Поиск и замена
Для эффективного изменения какого-то термина или для производства какого-либо массового исправления в строках, ваш нужен Поиск и замена — Он расположен в меню Инструменты.
Подсказка
Не бойтесь испортить строку. Это двухэтапный процесс, показывающий предварительный просмотр отредактированных строк до подтверждения фактического изменения.
Массовая правка
Массовая правка позволяет выполнять операцию одновременно с несколькими строками. Вы определяете строки путём их поиска и задаёте, что нужно сделать для совпадающих строк. Поддерживаются следующие операции:
Изменение состояния строки (например, для утверждения всех нерецензируемых строк).
Корректировка флагов перевода (смотрите раздел Настройка поведения с помощью флагов)
Корректировка меток строк (смотрите раздел Метки строк)
Подсказка
Этот инструмент называется Массовая правка и доступен он из меню Инструменты проекта, компонента или перевода.![]()
См.также
Надстройка «Массовая правка»
Просмотр в виде матрицы
Для эффективного сравнения разных языков можно использовать матричное представление. Он доступен на каждой странице компонента в меню Инструменты. Сначала выберите все языки, которые вы хотите сравнить, и подтвердите свой выбор, после чего вы можете нажать на любой перевод, чтобы быстро открыть и отредактировать его.
Матричный вид также является очень хорошей отправной точкой для поиска недостающих переводов на разных языках и их быстрого добавления из одного вида.
Дзен-режим
Дзен-редактор можно включить, нажав на кнопку Дзен справа вверху во время перевода компонента. Он упрощает компоновку и удаляет дополнительные элементы пользовательского интерфейса, такие как Соседние строки или Глоссарий.
Вы можете выбрать Дзен-редактор в качестве редактора по умолчанию, используя вкладку Настройки в вашем Профиль пользователя. Здесь вы также можете выбрать, как перечислять переводы: сверху вниз или сбоку, в зависимости от ваших личных предпочтений.
8 функций Google Translate, которые вы, скорее всего, не используете / Хабр
Google Translate — это самая крупная система для работы с языками. По статусу на июнь 2020 года в ней полностью реализовано 108 языков мира.
Каждый день Google Translate переводит свыше 100 млрд слов. Но многие люди используют только основную его функцию и даже не знают, что кроме стандартного перевода у него есть целый ряд довольно удобных инструментов.
В этой статье мы расскажем о них. И попробуем узнать, помогает ли Google Translate вообще учить английский язык.
Перевод страниц сайтов
Функция известная и используется часто. Смысл в том, чтобы перевести страницу сайта, полностью сохраняя интерфейс.
В браузере Google Chrome уже вшито расширение Google Translate. Чтобы перевести страницу, нужно всего лишь кликнуть правой кнопкой мыши и нажать «Перевести».
Если вы используете другой браузер, то нужно будет установить расширение.![]() Вот версии для Firefox и для Opera.
Вот версии для Firefox и для Opera.
Кстати, у расширений есть еще интересные функции. К примеру, перевод слов в всплывающем окне. Просто кликаешь — и сразу видишь перевод. Не нужно даже переключаться на другую вкладку или лезть в мобильный словарь.
Есть еще один способ, как перевести страницу сайта. Для этого нужно вставить URL сайта в окно перевода, выбрать нужный язык и кликнуть на результат в другом окне. Страница откроется на указанном языке.
Перевод документов
Удобная функция, если у вас есть куча текстовых файлов, которые нужно перевести. Для этого не нужно вручную открывать каждый из них и копировать текст. Просто кликните на вкладку «Документы» и закиньте в Google Translate весь файл целиком.
Сервис понимает практически все текстовые типы файлов и даже презентации в Power Point. Вот полный список: DOC, DOCX, ODF, PDF, PPT, PPTX, PS, RTF, TXT, XLS, XLSX.
PDF-файлы система может прочитать и перевести, если в них распознан текст.![]() Даже частично сохранит оригинальную верстку (только без изображений). Но файлы электронных книг MOBI, FB2, EPUB прочитать не получится.
Даже частично сохранит оригинальную верстку (только без изображений). Но файлы электронных книг MOBI, FB2, EPUB прочитать не получится.
Важно! Юридические документы и договора таким способом переводить нельзя. Гугловский перевод не дает необходимой точности из-за чего подписание подобных документов может быть даже опасным с юридической точки зрения.
Перевод в строке поиска Google
Переводить слова и фразы можно даже с помощью обычной строки поиска Google. Если алгоритм поисковика поймет, что вы хотите перевести слово или фразу на другой язык, он первым выдаст окно Google Translate с переводом.
Причем работает это не только на стартовой странице Google, но и в адресной строке браузера, если поисковиком по умолчанию назначен Google.
Собственный словарь слов и фраз
Если вы часто пользуетесь Google Translate для перевода отдельных слов, фраз или словосочетаний, то можно создать собственный словарь.
Если нужно сохранить фразу или слово, нажмите звездочку в правом верхнем углу. А чтобы вывести на экран весь словарь, иконку «Сохранено» внизу.
Функция довольно полезная, если вам, например, нужно сделать небольшой карманный разговорник при поездке в другую страну. Приложение Google Translate работает и без интернета, так что если нужно объясниться с носителем языка или спросить дорогу. Это поможет даже в местности, где нет доступа к Wi-Fi.
Но вот учить английский так неудобно. Забросил фразу в словарь и забыл. Для изучения лексики лучше использовать специализированные приложения, в которых лексика изучается методов рациональных повторений.
Кстати, хабровчане еще могут получить бесплатный доступ к премиум-пакету приложения для изучения английской лексики ED Words. Просто введите промокод transl8 на этой странице или прямо в приложении ED Words.
Синхронный перевод
Буквально в марте 2020 года Google анонсировали обновление в приложении Google Translate, с помощью которого можно делать синхронный перевод речи.
Алгоритм распознает речь и мгновенно переводит ее на другой язык с непрерывной подачей текста. Это будет очень полезным, если нужно прослушать лекцию, речь со сцены или длительный монолог. Также неплохо в переводе фильмов, к которым нет субтитров.
При желании можно настроить приложение на запись транскрибации монолога. Если у вас не идеальные навыки восприятия информации на слух, то подобная хитрость поможет лучше понимать речь. Ведь вы будете одновременно и слушать, и читать.
Перевод диалога
Вместе с синхронным был обновлен алгоритм перевода во время диалога. Функция стала еще более удобной.
Чтобы начать перевод, нужно нажать кнопку «Conversation» в приложении. Откроется двойное окно. При нажатии кнопки микрофона в одном из них, программа будет воспринимать этот язык и переводить на второй.
Чтобы начать перевод со второго языка, нужно только нажать кнопку микрофона там.
Сейчас функция доступна на 32 языках.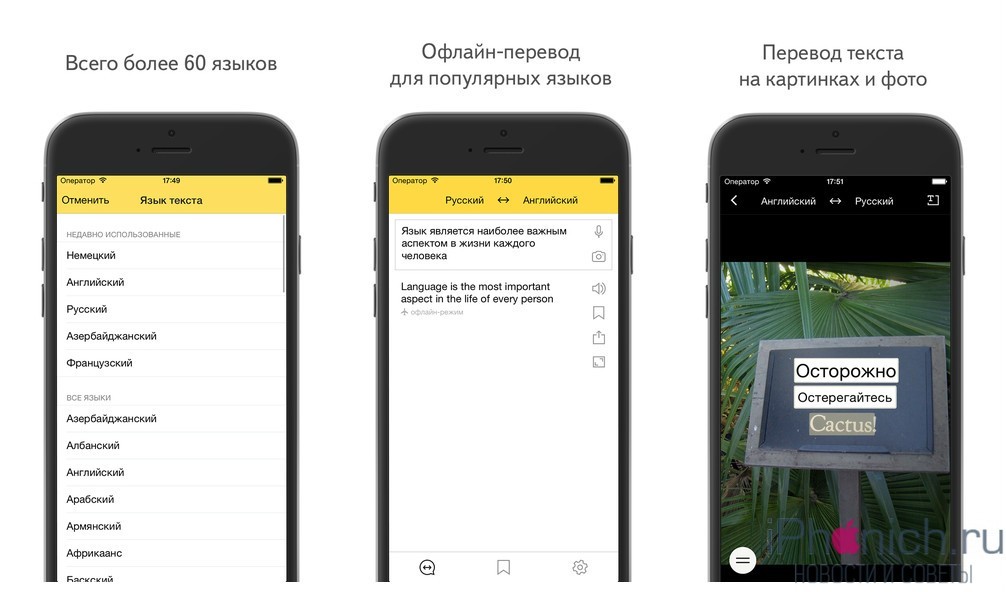 Русский тоже есть, поэтому приложение поможет пообщаться с иностранцем, даже если вы знаете язык очень слабо или не знаете вообще.
Русский тоже есть, поэтому приложение поможет пообщаться с иностранцем, даже если вы знаете язык очень слабо или не знаете вообще.
Перевод с помощью камеры
Интересный инструмент, который поможет вам перевести указатели и надписи на знаках, витринах или уличной рекламе. Можно прочитать надписи на карте или меню в ресторане — в общем, просто находка для путешественника.
Чтобы включить Google Word Lens, просто включаете приложение Google Translate, кликаете на кнопку камеры и наводите ее на текст. На экране будет сразу переведенная надпись.
Механизм распознавания текста еще не совершенен. Разработчики говорят, что слишком стилизованные шрифты или дизайнерские начертания букв система может не понять.
Перевод слов от руки
Еще одна фича приложения. Пользуется просто дикой популярностью у студентов, которые изучают восточные языки: китайский, японский, корейский, вьетнамский хинди, урду или другие.
Потому что написать слово от руки здесь намного проще, чем искать нужные иероглифы среди доступных в алфавите.
На европейских языках функция тоже работает, но ее полезность куда меньше. Все же алфавит из 26 букв (для английского языка) на клавиатуру влезает весь, не нужно тратить много времени на поиск букв. Напечатать будет быстрее. Но попробовать можно в любом случае.
***
Google Translate — это отличное приложение для путешественника. С его помощью можно объясниться с иностранцем, даже если знаний языка нет вообще. Но всегда полагаться на технику — недальновидно. Ведь если телефон разрядится или сломается, то будет очень сложно найти общий язык в чужой стране. Google Translate не помогает учить английский — он не включает механизмы запоминания. Мозг просто не будет лишний раз напрягаться.
Так что учите английский и разговаривайте безо всяких Google Translate.
Онлайн-школа EnglishDom.com — вдохновляем выучить английский через технологии и человеческую заботу
Только для читателей Хабра первый урок с преподавателем по Skype бесплатно! А при покупке занятий получите до 3 уроков в подарок!
Получи целый месяц премиум-подписки на приложение ED Words в подарок.
Введи промокод transl8 на этой странице или прямо в приложении ED Words. Промокод действителен до 09.06.2021.
Наши продукты:
- Учи английские слова в мобильном приложении ED Words
- Учи английский от А до Z в мобильном приложении ED Courses
- Установи расширение для Google Chrome, переводи английские слова в интернете и добавляй их на изучение в приложении Ed Words
- Учи английский в игровой форме в онлайн тренажере
- Закрепляй разговорные навыки и находи друзей в разговорных клубах
- Смотри видео лайфхаки про английский на YouTube-канале EnglishDom
языков с помощью RNN. Построить рекуррентную нейронную сеть (RNN)… | Томас Трейси
Построить рецидивирующую нейронную сеть, которая переводит английский на французский
29 августа 2018 г. на Томас Трейси , первоначально Опубликовано на Github
Версион. перевод этого поста доступен здесь , любезно предоставлен Ibidem Group . Большое спасибо Чема Бескос !
перевод этого поста доступен здесь , любезно предоставлен Ibidem Group . Большое спасибо Чема Бескос !
В этом посте рассказывается о моей работе над финальным проектом программы Udacity Artificial Intelligence Nano Degree. Моя цель — помочь другим учащимся и специалистам, находящимся на ранних этапах развития своей интуиции в области машинного обучения (МО) и искусственного интеллекта (ИИ).
Имейте в виду, что по профессии я менеджер по продукту (не инженер и не специалист по данным). Итак, далее следует полутехническое, но доступное объяснение концепций и алгоритмов машинного обучения в этом проекте. Если что-либо из перечисленного ниже является неточным или если у вас конструктивная обратная связь, я хотел бы услышать от вас.
Мой репозиторий Github для этого проекта можно найти здесь. Исходный репозиторий исходного кода Udacity для этого проекта находится здесь.![]()
В этом проекте я создаю глубокую нейронную сеть, которая функционирует как часть конвейера машинного перевода. Конвейер принимает текст на английском языке в качестве входных данных и возвращает перевод на французский язык. Цель состоит в том, чтобы достичь максимально возможной точности перевода.
Способность общаться друг с другом является фундаментальной частью человека. В мире существует около 7000 различных языков. По мере того, как наш мир становится все более взаимосвязанным, языковой перевод обеспечивает важный культурный и экономический мост между людьми из разных стран и этнических групп. Некоторые из наиболее очевидных вариантов использования включают в себя:
- бизнес : международная торговля, инвестиции, контракты, финансы
- торговля : путешествия, покупка иностранных товаров и услуг, поддержка клиентов
- СМИ : доступ к информации через поиск, обмен информацией через социальные сети, локализация контента и рекламы
- образование : обмен идеями, сотрудничество, перевод исследовательских работ
- правительство : международные отношения, переговоры
Чтобы удовлетворить эти потребности, технологические компании вкладывают значительные средства в машинный перевод. Эти инвестиции и недавние достижения в области глубокого обучения привели к значительному улучшению качества перевода. По данным Google, переход на глубокое обучение привел к повышению точности перевода на 60% по сравнению с подходом на основе фраз, который ранее использовался в Google Translate. Сегодня Google и Microsoft могут переводить более чем на 100 различных языков, и точность многих из них приближается к человеческому уровню.
Эти инвестиции и недавние достижения в области глубокого обучения привели к значительному улучшению качества перевода. По данным Google, переход на глубокое обучение привел к повышению точности перевода на 60% по сравнению с подходом на основе фраз, который ранее использовался в Google Translate. Сегодня Google и Microsoft могут переводить более чем на 100 различных языков, и точность многих из них приближается к человеческому уровню.
Однако, хотя машинный перевод достиг значительного прогресса, он все еще не идеален. 😬
Плохой перевод или крайняя плотоядность?Чтобы перевести корпус английского текста на французский, нам нужно построить рекуррентную нейронную сеть (RNN). Прежде чем погрузиться в реализацию, давайте сначала создадим некоторое представление о RNN и о том, почему они полезны для задач НЛП.
Обзор RNN
RNN предназначены для приема текстовых последовательностей в качестве входных данных или возврата текстовых последовательностей в качестве выходных данных, или и того, и другого. Они называются рекуррентными, потому что скрытые слои сети имеют цикл, в котором выходные данные и состояние ячейки с каждого временного шага становятся входными данными на следующем временном шаге. Это повторение служит формой памяти. Это позволяет контекстуальной информации проходить через сеть, так что соответствующие выходные данные из предыдущих временных шагов могут быть применены к сетевым операциям на текущем временном шаге.
Они называются рекуррентными, потому что скрытые слои сети имеют цикл, в котором выходные данные и состояние ячейки с каждого временного шага становятся входными данными на следующем временном шаге. Это повторение служит формой памяти. Это позволяет контекстуальной информации проходить через сеть, так что соответствующие выходные данные из предыдущих временных шагов могут быть применены к сетевым операциям на текущем временном шаге.
Это аналогично тому, как мы читаем. Когда вы читаете этот пост, вы сохраняете важную информацию из предыдущих слов и предложений и используете ее в качестве контекста для понимания каждого нового слова и предложения.
Другие типы нейронных сетей не могут этого сделать (пока). Представьте, что вы используете сверточную нейронную сеть (CNN) для обнаружения объектов в фильме. В настоящее время информация об объектах, обнаруженных в предыдущих сценах, не может использоваться для информирования модели об обнаружении объектов в текущей сцене. Например, если в предыдущей сцене были обнаружены зал суда и судья, эта информация может помочь правильно классифицировать молоток судьи в текущей сцене, а не ошибочно классифицировать его как молоток или молоток.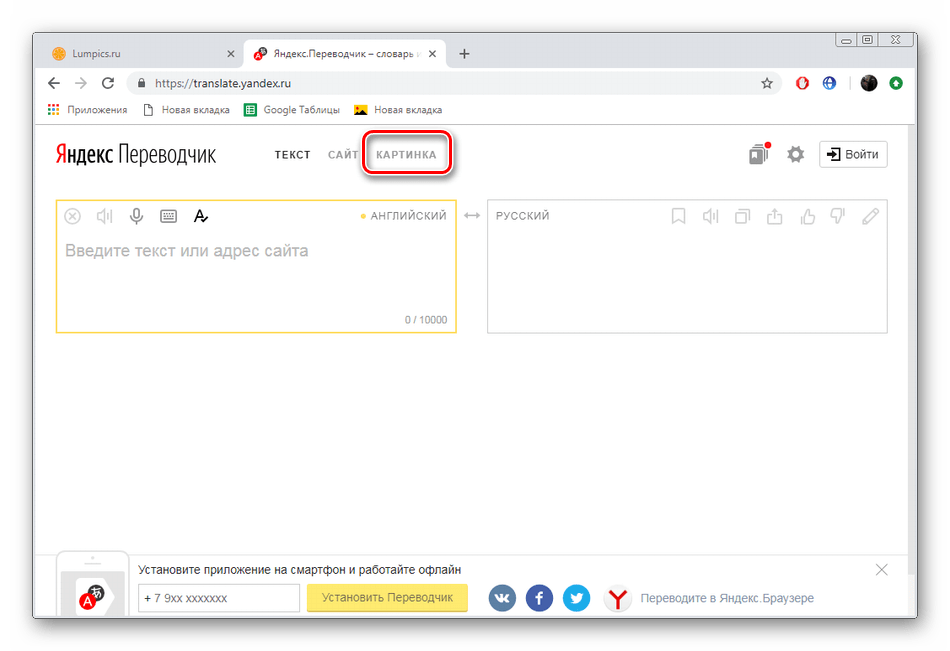 Но CNN не позволяют этому типу контекста временных рядов проходить через сеть, как это делают RNN.
Но CNN не позволяют этому типу контекста временных рядов проходить через сеть, как это делают RNN.
Настройка RNN
В зависимости от варианта использования вы можете настроить RNN для обработки входных и выходных данных по-разному. В этом проекте мы будем использовать процесс «многие ко многим», в котором на входе будет последовательность английских слов, а на выходе — последовательность французских слов (четвертое слева на диаграмме ниже).
Диаграмма различных типов последовательностей RNN. Фото: Andrej KarpathyКаждый прямоугольник представляет собой вектор, а стрелки представляют собой функции (например, умножение матрицы). Входные векторы показаны красным, выходные векторы — синим, а зеленые векторы содержат состояние RNN (подробнее об этом позже).
Слева направо: (1) Ванильный режим обработки без RNN, от ввода фиксированного размера к выводу фиксированного размера (например, классификация изображений). (2) Вывод последовательности (например, субтитры изображения берут изображение и выводят предложение слов).
(3) Ввод последовательности (например, анализ настроений, когда данное предложение классифицируется как выражающее положительное или отрицательное настроение). (4) Ввод последовательности и вывод последовательности (например, машинный перевод: RNN читает предложение на английском языке, а затем выводит предложение на французском языке). (5) Синхронизированный ввод и вывод последовательности (например, классификация видео, где мы хотим пометить каждый кадр видео). Обратите внимание, что в каждом случае нет заранее заданных ограничений на длины последовательностей, потому что рекуррентное преобразование (зеленый) фиксировано и может применяться столько раз, сколько нам нужно.
— Андрей Карпати, Необоснованная эффективность рекуррентных нейронных сетей
Ниже приводится сводка различных этапов предварительной обработки и моделирования. К высокоуровневым шагам относятся:
- Предварительная обработка : загрузка и проверка данных, очистка, токенизация, заполнение
- Моделирование : построение, обучение и тестирование модели
- Прогнозирование : создание конкретных переводов английского языка Французский, и сравните выходные переводы с реальными переводами
- Итерация : итерация модели, экспериментирование с различными архитектурами
Более подробное руководство, включая исходный код, см. в блокноте Jupyter в репозитории проекта.
в блокноте Jupyter в репозитории проекта.
Фреймворки
В этом проекте мы используем Keras для внешнего интерфейса и TensorFlow для внутреннего интерфейса. Я предпочитаю использовать Keras поверх TensorFlow, потому что синтаксис проще, что делает построение слоев модели более интуитивным. Однако с Keras есть компромисс, поскольку вы теряете возможность выполнять тонкую настройку. Но это не повлияет на модели, которые мы строим в этом проекте.
Загрузка и проверка данныхВот пример данных. Входные данные представляют собой предложения на английском языке; выводами являются соответствующие переводы на французский язык.
Когда мы проводим подсчет слов, мы видим, что словарный запас для набора данных довольно мал. Это было задумано для этого проекта. Это позволяет нам обучать модели в разумные сроки.
Очистка
На этом этапе дополнительная очистка не требуется. Данные уже преобразованы в нижний регистр и разделены таким образом, чтобы между всеми словами и знаками препинания были пробелы.
Примечание : Для других проектов НЛП вам может потребоваться выполнить дополнительные действия, такие как: удалить теги HTML, удалить стоп-слова, удалить знаки препинания или преобразовать в представления тегов, пометить части речи или выполнить извлечение объектов.
Токенизация
Далее нам нужно токенизировать данные, т. е. преобразовать текст в числовые значения. Это позволяет нейронной сети выполнять операции над входными данными. В этом проекте каждому слову и знаку препинания будет присвоен уникальный идентификатор. (Для других проектов НЛП может иметь смысл присвоить каждому персонажу уникальный идентификатор.)
Когда мы запускаем токенизатор, он создает индекс слов, который затем используется для преобразования каждого предложения в вектор.
Заполнение
Когда мы подаем в модель наши последовательности идентификаторов слов, каждая последовательность должна быть одинаковой длины. Для этого к любой последовательности, которая короче максимальной длины (т. е. короче самого длинного предложения), добавляется отступ.
е. короче самого длинного предложения), добавляется отступ.
One-Hot Encoding (не используется)
В этом проекте наши входные последовательности будут представлять собой вектор, содержащий ряд целых чисел. Каждое целое число представляет собой английское слово (как показано выше). Однако в других проектах иногда выполняется дополнительный шаг для преобразования каждого целого числа в вектор с горячим кодированием. Мы не используем горячее кодирование (OHE) в этом проекте, но вы увидите ссылки на него на некоторых диаграммах (например, на приведенной ниже). Я просто не хотел, чтобы вы запутались.
Одним из преимуществ OHE является эффективность, поскольку он может работать с более высокой тактовой частотой, чем другие кодировки. Другое преимущество заключается в том, что OHE лучше представляет категориальные данные, где нет порядковой связи между различными значениями. Например, предположим, что мы классифицируем животных как млекопитающих, рептилий, рыб или птиц. Если мы закодируем их как 1, 2, 3, 4 соответственно, наша модель может предположить, что между ними существует естественный порядок, которого нет. Бесполезно структурировать наши данные таким образом, что млекопитающие предшествуют рептилиям и так далее. Это может ввести нашу модель в заблуждение и привести к плохим результатам. Однако если мы затем применим к этим целым числам однократное кодирование, изменив их на двоичные представления — 1000, 0100, 0010, 0001 соответственно — тогда модель не сможет вывести никакую порядковую связь.
Если мы закодируем их как 1, 2, 3, 4 соответственно, наша модель может предположить, что между ними существует естественный порядок, которого нет. Бесполезно структурировать наши данные таким образом, что млекопитающие предшествуют рептилиям и так далее. Это может ввести нашу модель в заблуждение и привести к плохим результатам. Однако если мы затем применим к этим целым числам однократное кодирование, изменив их на двоичные представления — 1000, 0100, 0010, 0001 соответственно — тогда модель не сможет вывести никакую порядковую связь.
Но одним из недостатков OHE является то, что векторы могут быть очень длинными и разреженными. Длина вектора определяется словарным запасом, то есть количеством уникальных слов в вашем текстовом корпусе. Как мы видели на этапе проверки данных выше, наш словарный запас для этого проекта очень мал — всего 227 английских слов и 355 французских слов. Для сравнения, Оксфордский словарь английского языка насчитывает 172 000 слов. Но если мы включим различные имена собственные, времена слов и сленг, то в каждом языке могут быть миллионы слов. Например, word2vec от Google обучается на словаре из 3 миллионов уникальных слов. Если бы мы использовали OHE в этом словаре, вектор для каждого слова включал бы одно положительное значение (1), окруженное 2,999 999 нулей!
Например, word2vec от Google обучается на словаре из 3 миллионов уникальных слов. Если бы мы использовали OHE в этом словаре, вектор для каждого слова включал бы одно положительное значение (1), окруженное 2,999 999 нулей!
И, поскольку мы используем вложения (на следующем шаге) для дальнейшего кодирования представлений слов, нам не нужно возиться с OHE. Любое повышение эффективности не стоит того на таком маленьком наборе данных.
Во-первых, давайте разберем архитектуру RNN на высоком уровне. Ссылаясь на диаграмму выше, мы должны знать о нескольких частях модели:
- Входы . Входные последовательности подаются в модель одним словом для каждого временного шага. Каждое слово кодируется как уникальное целое число или вектор с горячим кодированием, который сопоставляется со словарем набора данных английского языка.
- Встраивание слоев . Вложения используются для преобразования каждого слова в вектор. Размер вектора зависит от сложности словаря.

- Повторяющиеся слои (кодировщик) . Здесь контекст из векторов слов на предыдущих временных шагах применяется к текущему вектору слов.
- Плотные слои (декодер) . Это типичные полносвязные слои, используемые для декодирования закодированного ввода в правильную последовательность перевода.
- Выходы . Выходные данные возвращаются в виде последовательности целых чисел или векторов с горячим кодированием, которые затем можно сопоставить со словарем французского набора данных.
Вложения
Вложения позволяют нам фиксировать более точные синтаксические и семантические отношения слов. Это достигается путем проецирования каждого слова в n-мерное пространство. Слова со сходными значениями занимают сходные области этого пространства; чем ближе два слова, тем больше они похожи. И часто векторы между словами представляют полезные отношения, такие как пол, время глагола или даже геополитические отношения.
Обучающие встраивания на большом наборе данных с нуля требуют огромного количества данных и вычислений. Таким образом, вместо того, чтобы делать это самостоятельно, мы обычно используем предварительно обученный пакет встраивания, такой как GloVe или word2vec. При таком использовании встраивания представляют собой форму трансферного обучения. Однако, поскольку наш набор данных для этого проекта имеет небольшой словарный запас и низкую синтаксическую вариацию, мы будем использовать Keras для самостоятельного обучения вложений.
Кодер и декодер
Наша модель последовательностей связывает две рекуррентные сети: кодер и декодер. Кодер суммирует ввод в переменную контекста, также называемую состоянием. Затем этот контекст декодируется и генерируется выходная последовательность.
Изображение предоставлено: Udacity Поскольку и кодировщик, и декодер являются рекуррентными, у них есть циклы, которые обрабатывают каждую часть последовательности на разных временных шагах. Чтобы представить это, лучше всего развернуть сеть, чтобы мы могли видеть, что происходит на каждом временном шаге.
Чтобы представить это, лучше всего развернуть сеть, чтобы мы могли видеть, что происходит на каждом временном шаге.
В приведенном ниже примере для кодирования всей входной последовательности требуется четыре временных шага. На каждом временном шаге кодировщик «считывает» входное слово и выполняет преобразование его скрытого состояния. Затем он передает это скрытое состояние на следующий временной шаг. Имейте в виду, что скрытое состояние представляет соответствующий контекст, проходящий через сеть. Чем больше скрытое состояние, тем больше обучаемость модели, но и тем больше требования к вычислениям. Мы поговорим больше о преобразованиях в скрытом состоянии, когда будем рассматривать закрытые рекуррентные единицы (GRU).
Изображение предоставлено: измененная версия от Udacity А пока обратите внимание, что для каждого временного шага после первого слова в последовательности есть два входа: скрытое состояние и слово из последовательности. Для кодировщика это следующих слов во входной последовательности. Для декодера это предыдущих слов из выходной последовательности.
Для декодера это предыдущих слов из выходной последовательности.
Кроме того, помните, что когда мы говорим о «слове», мы на самом деле имеем в виду векторное представление слова, полученное из слоя внедрения.
Вот еще один способ визуализации кодировщика и декодера, за исключением ввода последовательности китайского языка.
Изображение предоставлено: xiandong79.github.ioДвунаправленный уровень
Теперь, когда мы понимаем, как контекст проходит через сеть через скрытое состояние, давайте сделаем еще один шаг, разрешив этому контексту течь в обоих направлениях. Это то, что делает двунаправленный слой.
В приведенном выше примере кодировщик имеет только исторический контекст. Но предоставление будущего контекста может привести к повышению производительности модели. Это может показаться нелогичным по отношению к тому, как люди обрабатывают язык, поскольку мы читаем только в одном направлении. Однако людям часто требуется контекст будущего, чтобы интерпретировать сказанное. Другими словами, иногда мы не понимаем предложение, пока в конце не будет указано важное слово или фраза. Происходит это всякий раз, когда Йода говорит. 😑 🙏
Другими словами, иногда мы не понимаем предложение, пока в конце не будет указано важное слово или фраза. Происходит это всякий раз, когда Йода говорит. 😑 🙏
Чтобы реализовать это, мы одновременно обучаем два слоя RNN. На первый слой подается входная последовательность как есть, а на второй — ее перевернутая копия.
Изображение предоставлено: UdacityСкрытый слой с закрытой рекуррентной единицей (GRU)
Теперь давайте сделаем нашу RNN немного умнее. Вместо того, чтобы позволить всей информации из скрытого состояния проходить через сеть, что, если бы мы могли быть более избирательными? Возможно, какая-то информация более актуальна, а другую информацию следует отбросить. По сути, это то, что делает рекуррентный блок с закрытым входом (GRU).
В GRU есть два шлюза: шлюз обновления и шлюз сброса. Эта статья Симеона Костадинова подробно объясняет это. Подводя итог, можно сказать, что шлюз обновления (z) помогает модели определить, сколько информации из предыдущих временных шагов необходимо передать в будущее.![]() Между тем, шлюз сброса (r) решает, какую часть прошлой информации следует забыть.
Между тем, шлюз сброса (r) решает, какую часть прошлой информации следует забыть.
Окончательная модель
Теперь, когда мы обсудили различные части нашей модели, давайте взглянем на код. Опять же, весь исходный код доступен здесь, в записной книжке (версия .html).
Результаты окончательной модели можно найти в ячейке 20 блокнота.
Точность проверки: 97,5%
Время обучения: 23 эпохи
- Правильное разделение данных (обучение, проверка, тестирование) . В настоящее время тестового набора нет, только обучение и проверка. Очевидно, что это не соответствует лучшим практикам.
- LSTM + внимание . Это была де-факто архитектура для RNN в течение последних нескольких лет, хотя есть некоторые ограничения. Я не использовал LSTM, потому что я уже реализовал его в TensorFlow в другом проекте, и я хотел поэкспериментировать с GRU + Keras для этого проекта.

- Тренируйтесь на большем и разнообразном текстовом корпусе . Текстовый корпус и словарный запас для этого проекта довольно малы с небольшими изменениями в синтаксисе. В результате модель очень хрупкая. Чтобы создать модель, которая лучше обобщает, вам нужно будет тренироваться на большем наборе данных с большей вариативностью грамматики и структуры предложений.
- Остаточные слои . Вы можете добавить остаточные слои в глубокую LSTM RNN, как описано в этой статье. Или используйте остаточные слои в качестве альтернативы LSTM и GRU, как описано здесь.
- Вложения . Если вы тренируетесь на большом наборе данных, вам обязательно следует использовать предварительно обученный набор вложений, таких как word2vec или GloVe. Еще лучше используйте ELMo или BERT.
- Языковая модель встраивания (ELMo) . Одним из самых больших достижений в области универсальных вложений в 2018 году стал ELMo, разработанный Институтом искусственного интеллекта Аллена.
 Одним из основных преимуществ ELMo является то, что он решает проблему полисемии, когда одно слово имеет несколько значений. ELMo основан на контексте (а не на словах), поэтому разные значения слова занимают разные векторы в пространстве встраивания. В GloVe и word2vec каждое слово имеет только одно представление в пространстве встраивания. Например, слово «королева» может относиться к матриарху королевской семьи, пчеле, шахматной фигуре или 19Рок-группа 70-х. При традиционных вложениях все эти значения привязаны к одному вектору для слова queen . В ELMO это четыре различных вектора, каждый из которых имеет уникальный набор контекстных слов, занимающих одну и ту же область пространства встраивания. Например, мы ожидаем увидеть такие слова, как ферзь , ладья и пешка в аналогичном векторном пространстве, связанном с игрой в шахматы. И мы ожидаем увидеть матку , улей и мед в другом векторном пространстве, связанном с пчелами.
Одним из основных преимуществ ELMo является то, что он решает проблему полисемии, когда одно слово имеет несколько значений. ELMo основан на контексте (а не на словах), поэтому разные значения слова занимают разные векторы в пространстве встраивания. В GloVe и word2vec каждое слово имеет только одно представление в пространстве встраивания. Например, слово «королева» может относиться к матриарху королевской семьи, пчеле, шахматной фигуре или 19Рок-группа 70-х. При традиционных вложениях все эти значения привязаны к одному вектору для слова queen . В ELMO это четыре различных вектора, каждый из которых имеет уникальный набор контекстных слов, занимающих одну и ту же область пространства встраивания. Например, мы ожидаем увидеть такие слова, как ферзь , ладья и пешка в аналогичном векторном пространстве, связанном с игрой в шахматы. И мы ожидаем увидеть матку , улей и мед в другом векторном пространстве, связанном с пчелами. Это обеспечивает значительный прирост семантического кодирования.
Это обеспечивает значительный прирост семантического кодирования. - Двунаправленный энкодер Представления от Трансформаторы (BERT) . До сих пор в 2019 году самым большим достижением в двунаправленных встраиваниях был BERT, исходный код которого был открыт Google. Чем отличается БЕРТ?
Контекстно-свободные модели, такие как word2vec или GloVe, генерируют представление встраивания одного слова для каждого слова в словаре. Например, слово «банк» будет иметь одинаковое внеконтекстное представление в словах «банковский счет» и «берег реки». Вместо этого контекстные модели генерируют представление каждого слова на основе других слов в предложении. Например, в предложении «Я получил доступ к банковскому счету» однонаправленная контекстуальная модель будет представлять «банк» на основе «Я получил доступ к», но не «счет». Однако BERT представляет «банк», используя как предыдущий, так и следующий контекст — «Я получил доступ к… учетной записи» — начиная с самого низа глубокой нейронной сети, делая ее глубоко двунаправленной.
— Джейкоб Девлин и Минг-Вей Чанг, блог Google AI
Надеюсь, вы нашли это полезным. Опять же, если у вас есть какие-либо отзывы, я хотел бы их услышать. Не стесняйтесь писать в комментариях.
Если вы хотите обсудить другие возможности сотрудничества или карьеры, вы можете найти меня здесь, в LinkedIn, или просмотреть мое портфолио здесь.
Как переводить текст между языками в облаке с помощью Amazon Translate
Начало работы / Практические занятия / …
с Amazon Translate
Из этого руководства вы узнаете, как переводить текст между языками с помощью Amazon Translate. Amazon Translate – это сервис нейронного машинного перевода, который обеспечивает быстрый, качественный и недорогой языковой перевод.
Как разработчик, языковой перевод — это проблема, с которой вы столкнетесь при разработке многоязычных веб-сайтов и приложений, переводе пользовательского контента или поддержке связи в реальном времени в приложении. Amazon Translate позволяет решить эту задачу, предоставляя точный естественно звучащий перевод с помощью облачного API глубокого обучения.
Amazon Translate позволяет решить эту задачу, предоставляя точный естественно звучащий перевод с помощью облачного API глубокого обучения.
В этом учебном сценарии вам, как сотруднику международной фирмы по производству багажа, необходимо понять, что клиенты говорят о вашем продукте в отзывах на местном языке рынка — французском. Поскольку здесь переводится несколько предложений, идеальным вариантом будет использование консоли. Консоль также полезна для проверки качества перевода. Для рабочих нагрузок, которые необходимо масштабировать, лучше использовать Translate API через AWS CLI или AWS SDK вместо использования консоли.
Для этого руководства требуется учетная запись AWS
Создайте бесплатную учетную запись
Начать работу с уровнем бесплатного пользования Amazon Translate легко. Переводите до 2 млн символов в месяц — бесплатно в течение первых 12 месяцев, начиная с первого запроса на перевод.
Подробнее об уровне бесплатного пользования >>
Откройте Консоль управления AWS, чтобы не закрывать это пошаговое руководство. Когда экран загрузится, введите имя пользователя и пароль, чтобы начать. Затем введите Translate в строке поиска и выберите Amazon Translate , чтобы открыть сервисную консоль.
Когда экран загрузится, введите имя пользователя и пароль, чтобы начать. Затем введите Translate в строке поиска и выберите Amazon Translate , чтобы открыть сервисную консоль.
Закрыть
(нажмите, чтобы увеличить)
Шаг 2. Переведите отзыв
На этом шаге вы переведете отзыв клиента с помощью консоли перевода.
а. На главной странице консоли Amazon Translate щелкните Попробуйте Amazon Translate .
Закрыть
(нажмите, чтобы увеличить)
б. На левой панели навигации выберите Попробуйте Amazon Translate . Для Исходный язык выберите Французский . Для Целевой язык выберите English . Вы можете увидеть полный список языков, которые поддерживает Amazon Translate, в раскрывающемся списке.
В случаях, когда вы не знаете исходный язык, Translate может автоматически определить его для вас.
Закрыть
(нажмите, чтобы увеличить)
г. В поле Исходный код скопируйте и вставьте следующий текст:
Cette valise est d’un perfect rapport qualité prix et présente de très solides atouts:
— Elle est légère (плюс que ce à quoi je m’attendait )- Elle parait solide (pour l’instant, pas encore utilisée enconditions réelles qui seules pourront donner le vrai verdict sur sa solidité)- Elle est parfaitement conçue et fabriquée: Matériaux bien choisis et qui respirent la qualité (poignées, roulettes, aménagement) intérieur, soufflet d’extension…)
Néanmoins, elle présente un défaut TRES gênant, qui est quadriment rédhibitoire en ce qui me refere : Rien n’est prévu pour la verrouiller !!!Pas de verrou à code intégré, ça c’est visible dans la description mais, encore plus gênant, il n’y a même pas d’anneau intégré à la glissière de fermeture pour y fixer un cadenas, la seule possibilité est d’accrocher le dit cadenas aux Tirettes de fermeture, ce qui est tres moyen en terme де солитит де fermeture.![]()
В том, что меня беспокоит, я могу найти непостижимых консультантов, которые не знают, что такое багаж, в твердом состоянии !!!
Cette aurait valise aurait décroché ses 5 étoiles avec un dispositif de fermeture (verrou ou anneau intégré pour passer un cadenas) malheureusement elle n’en possède aucun.
Закрыть
(нажмите, чтобы увеличить)
д. Результаты процесса перевода автоматически появятся в Целевой язык раздел.
Закрыть
(нажмите, чтобы увеличить)
эл. На панели образцов JSON вы можете увидеть ввод и вывод JSON. Это полезно для отладки кода при использовании AWS CLI или AWS SDK. Дополнительные сведения см. в описании операции TranslateText через API или SDK.
Закрыть
(нажмите, чтобы увеличить)
Теперь вы понимаете, как Amazon Translate позволяет переводить текст с помощью веб-консоли AWS. Та же функциональность, которую вы использовали здесь, доступна через AWS SDK и AWS CLI. Вы можете использовать Amazon Translate, чтобы включить многоязычный анализ тональности контента социальных сетей, обеспечить перевод по запросу пользовательского контента и добавить перевод в реальном времени для коммуникационных приложений.
Та же функциональность, которую вы использовали здесь, доступна через AWS SDK и AWS CLI. Вы можете использовать Amazon Translate, чтобы включить многоязычный анализ тональности контента социальных сетей, обеспечить перевод по запросу пользовательского контента и добавить перевод в реальном времени для коммуникационных приложений.
Узнать больше
Попробуйте другой учебник
Создайте свой персональный переводчик
Было ли это руководство полезным?
Войдите в консоль
Узнайте об AWS
- Что такое AWS?
- Что такое облачные вычисления?
- AWS Разнообразие, равенство и инклюзивность
- Что такое DevOps?
- Что такое контейнер?
- Что такое озеро данных?
- Облачная безопасность AWS
- Что нового
- Блоги
- Пресс-релизы
Ресурсы для AWS
- Начало работы
- Обучение и сертификация
- Портфель решений AWS
- Архитектурный центр
- Часто задаваемые вопросы по продуктам и техническим вопросам
- Аналитические отчеты
- Партнеры AWS
Разработчики на AWS
- Центр разработчиков
- SDK и инструменты
- .
 NET на AWS
NET на AWS - Python на AWS
- Java на AWS
- PHP на AWS
- JavaScript на AWS
Помощь
- Свяжитесь с нами
- Подайте заявку в службу поддержки
- Центр знаний
- AWS re: Сообщение
- Обзор поддержки AWS
- Юридический
- Карьера в AWS
Amazon является работодателем с равными возможностями: Меньшинства / Женщины / Инвалидность / Ветеран / Гендерная идентичность / Сексуальная ориентация / Возраст.
- Конфиденциальность
- |
- Условия сайта
- |
- Настройки файлов cookie
- |
- © 2022, Amazon Web Services, Inc. или ее дочерние компании. Все права защищены.
Поддержка AWS для Internet Explorer заканчивается 31. 07.2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari.
Подробнее »
07.2022. Поддерживаемые браузеры: Chrome, Firefox, Edge и Safari.
Подробнее »
Перевод с английского на испанский с преобразователем последовательности в последовательность
» Примеры кода / Обработка естественного языка / Перевод с английского на испанский с преобразованием последовательности в последовательность
Автор: fchollet
Дата создания: 26.05.2021
Последнее изменение: 26.05.2021
Описание: Внедрение преобразователя последовательности в последовательность и обучение его выполнению задачи машинного перевода.
Посмотреть в Colab • Исходный код GitHub
Введение
В этом примере мы построим модель преобразователя последовательностей, которая мы потренируемся на задаче машинного перевода с английского на испанский.
Вы узнаете, как:
- Векторизировать текст с помощью Keras
Слой TextVectorization.
- Реализовать слой
TransformerEncoder, слойTransformerDecoder, и слойPositionalEmbedding. - Подготовьте данные для обучения модели последовательностей.
- Используйте обученную модель для создания переводов невиданных ранее входные предложения (последовательный вывод).
Приведенный здесь код взят из книги Глубокое обучение с Python, второе издание (глава 11: Глубокое обучение для текста). Настоящий пример довольно примитивен, поэтому для подробного объяснения как работает каждый строительный блок, а также теория, лежащая в основе Трансформеров, Я рекомендую прочитать книгу.
Настройка
импортировать pathlib импортировать случайный строка импорта импортировать повторно импортировать numpy как np импортировать тензорный поток как tf из тензорного потока импортировать керас из слоев импорта tensorflow.keras из tensorflow.keras.layers импортировать TextVectorization
Загрузка данных
Мы будем работать с набором данных перевода с английского на испанский
предоставлено Анки. Скачиваем его:
Скачиваем его:
text_file = keras.utils.get_file(
fname="spa-eng.zip",
origin="http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip",
экстракт = правда,
)
text_file = pathlib.Path(text_file).parent / "spa-eng" / "spa.txt"
Анализ данных
Каждая строка содержит предложение на английском языке и соответствующее предложение на испанском языке.
Английское предложение — это исходная последовательность , а испанское — целевая последовательность .
Мы добавляем токен "[начало]" и добавляем токен "[конец]" к испанскому предложению.
с открытым (текстовым_файлом) как f:
строки = f.read().split("\n")[:-1]
text_pairs = []
для строки в строке:
eng, spa = line.split("\t")
spa = "[начало] " + spa + " [конец]"
text_pairs.append((англ, спа))
Вот как выглядят наши пары предложений:
для _ в диапазоне (5):
печать (случайный выбор (text_pairs))
(«Ты умеешь танцевать, не так ли?», '[начало] Puedes bailar, ¿verdad? [конец]') («Вчера я проходил мимо ее дома», «[начало] Me pasé por su casa ayer.[конец]») («Мне нравятся тюльпаны», «[начало] Me gustan los tulipanes. [конец]») («Он свободно говорит по-французски», «[начало] Habla un francés fluido. [конец]») («Том спросил меня, что я делал.», «[начало] Tom me preguntó qué había estado haciendo. [конец]»)
Теперь давайте разделим пары предложений на обучающий набор, проверочный набор, и тестовый набор.
случайный.перемешивание(text_pairs)
num_val_samples = int (0,15 * длина (text_pairs))
num_train_samples = длина (text_pairs) - 2 * num_val_samples
train_pairs = text_pairs[:num_train_samples]
val_pairs = text_pairs[num_train_samples : num_train_samples + num_val_samples]
test_pairs = text_pairs[num_train_samples + num_val_samples:]
print(f"{len(text_pairs)} всего пар")
print(f"{len(train_pairs)} тренировочные пары")
print(f"{len(val_pairs)} проверочные пары")
print(f"{len(test_pairs)} тестовых пар")
118964 Всего пар 83276 тренировочных пар 17844 пары проверки 17844 тестовых пары
Векторизация текстовых данных
Мы будем использовать два экземпляра слоя TextVectorization для векторизации текста
данные (один для английского и один для испанского),
то есть превратить исходные строки в целочисленные последовательности
где каждое целое число представляет индекс слова в словаре.
Английский слой будет использовать стандартизацию строк по умолчанию (удалить знаки пунктуации)
и схема разделения (разделение по пробелам), в то время как
испанский слой будет использовать пользовательскую стандартизацию, где мы добавим символ "¿" на набор знаков препинания, которые нужно удалить.
Примечание: в модели машинного перевода производственного уровня я бы не рекомендовал
удаление знаков препинания на любом языке. Вместо этого я бы рекомендовал обратить
каждый знак препинания в свой собственный токен,
чего вы можете достичь, предоставив пользовательскую функцию split для слоя TextVectorization .
strip_chars = строка.пунктуация + "¿"
strip_chars = strip_chars.replace("[", "")
strip_chars = strip_chars.replace("]", "")
размер_слова = 15000
длина последовательности = 20
размер партии = 64
определение custom_standardization (input_string):
нижний регистр = tf.strings.lower(input_string)
вернуть tf. strings.regex_replace (нижний регистр, "[%s]" % re.escape (strip_chars), "")
eng_vectorization = TextVectorization(
max_tokens=vocab_size, output_mode="int", output_sequence_length=sequence_length,
)
spa_vectorization = TextVectorization(
max_tokens=vocab_size,
выход_режим = "целое",
output_sequence_length = длина_последовательности + 1,
стандартизировать = custom_standardization,
)
train_eng_texts = [pair[0] для пары в train_pairs]
train_spa_texts = [pair[1] для пары в train_pairs]
eng_vectorization.adapt(train_eng_texts)
spa_vectorization.adapt (train_spa_texts)
strings.regex_replace (нижний регистр, "[%s]" % re.escape (strip_chars), "")
eng_vectorization = TextVectorization(
max_tokens=vocab_size, output_mode="int", output_sequence_length=sequence_length,
)
spa_vectorization = TextVectorization(
max_tokens=vocab_size,
выход_режим = "целое",
output_sequence_length = длина_последовательности + 1,
стандартизировать = custom_standardization,
)
train_eng_texts = [pair[0] для пары в train_pairs]
train_spa_texts = [pair[1] для пары в train_pairs]
eng_vectorization.adapt(train_eng_texts)
spa_vectorization.adapt (train_spa_texts)
Далее мы отформатируем наши наборы данных.
На каждом этапе обучения модель будет пытаться предсказать целевые слова N+1 (и далее) используя исходное предложение и целевые слова от 0 до N.
Таким образом, обучающий набор данных даст кортеж (входные данные, цели) , где: декодер_входы . encoder_inputs — векторизованное исходное предложение и encoder_inputs — целевое предложение «пока что»,
то есть слова от 0 до N, используемые для предсказания слова N+1 (и далее) в целевом предложении.
target — целевое предложение, смещенное на один шаг:
он предоставляет следующие слова в целевом предложении — то, что модель попытается предсказать. def format_dataset(eng, spa):
eng = eng_vectorization(eng)
spa = spa_vectorization(spa)
return ({"encoder_inputs": eng, "decoder_inputs": spa[:, :-1],}, spa[:, 1:])
def make_dataset (пары):
eng_texts, spa_texts = zip(*пары)
eng_texts = список(eng_texts)
spa_texts = список (spa_texts)
набор данных = tf.data.Dataset.from_tensor_slice((eng_texts, spa_texts))
набор данных = набор данных.пакет (размер_пакета)
набор данных = набор данных.карта (формат_набор данных)
вернуть набор данных.shuffle(2048).prefetch(16).cache()
train_ds = make_dataset (train_pairs)
val_ds = make_dataset(val_pairs)
Давайте кратко рассмотрим фигуры последовательности (у нас есть партии из 64 пар, и все последовательности имеют длину 20 шагов):
для входных данных, целей в train_ds.take(1): print(f'inputs["encoder_inputs"].shape: {inputs["encoder_inputs"].shape}') print(f'inputs["decoder_inputs"].shape: {inputs["decoder_inputs"].shape}') print(f"targets.shape: {targets.shape}")
inputs["encoder_inputs"].shape: (64, 20) входы["decoder_inputs"].shape: (64, 20) target.shape: (64, 20)
Построение модели
Наш преобразователь последовательности в последовательность состоит из TransformerEncoder и TransformerDecoder , соединенные вместе. Чтобы модель знала о порядке слов,
мы также используем слой PositionalEmbedding .
Исходная последовательность будет передана в TransformerEncoder ,
который создаст новое представление о нем.
Затем это новое представление будет передано
в TransformerDecoder вместе с целевой последовательностью (целевые слова от 0 до N). TransformerDecoder затем попытается предсказать следующие слова в целевой последовательности (N+1 и далее).
Ключевым элементом, который делает это возможным, является каузальная маскировка.
(см. метод get_causal_attention_mask() на TransformerDecoder ).
Декодер TransformerDecoder видит сразу все последовательности, и поэтому мы должны сделать так, чтобы
убедитесь, что он использует информацию только из целевых токенов от 0 до N при прогнозировании токена N+1
(иначе он мог бы использовать информацию из будущего, что
приводит к модели, которую нельзя использовать во время вывода).
класс TransformerEncoder(layers.Layer):
def __init__(self, embed_dim, плотно_dim, num_heads, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.embed_dim = встроенный_dim
self.dense_dim = плотный_dim
self.num_heads = количество_голов
self.attention = слои.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim
)
self.dense_proj = keras.Sequential(
[layers. Dense(dense_dim, активация="relu"),layers.Dense(embed_dim),]
)
self.layernorm_1 = слои.LayerNormalization()
self.layernorm_2 = слои.LayerNormalization()
self.supports_masking = Истина
вызов def (я, входы, маска = нет):
если маска не None:
padding_mask = tf.cast(mask[:, tf.newaxis, tf.newaxis,:], dtype="int32")
внимание_выход = я.внимание(
запрос=входы, значение=входы, ключ=входы, маска_внимания=маска_заполнения
)
proj_input = self.layernorm_1 (входы + внимание_выход)
proj_output = self.dense_proj(proj_input)
вернуть self.layernorm_2 (proj_input + proj_output)
класс PositionalEmbedding (слои. Слой):
def __init__(self, sequence_length, vocab_size, embed_dim, **kwargs):
super(PositionalEmbedding, self).__init__(**kwargs)
self.token_embeddings = слои.Встраивание(
input_dim=vocab_size, output_dim=embed_dim
)
self.position_embeddings = слои.
Dense(dense_dim, активация="relu"),layers.Dense(embed_dim),]
)
self.layernorm_1 = слои.LayerNormalization()
self.layernorm_2 = слои.LayerNormalization()
self.supports_masking = Истина
вызов def (я, входы, маска = нет):
если маска не None:
padding_mask = tf.cast(mask[:, tf.newaxis, tf.newaxis,:], dtype="int32")
внимание_выход = я.внимание(
запрос=входы, значение=входы, ключ=входы, маска_внимания=маска_заполнения
)
proj_input = self.layernorm_1 (входы + внимание_выход)
proj_output = self.dense_proj(proj_input)
вернуть self.layernorm_2 (proj_input + proj_output)
класс PositionalEmbedding (слои. Слой):
def __init__(self, sequence_length, vocab_size, embed_dim, **kwargs):
super(PositionalEmbedding, self).__init__(**kwargs)
self.token_embeddings = слои.Встраивание(
input_dim=vocab_size, output_dim=embed_dim
)
self.position_embeddings = слои. Встраивание(
input_dim=sequence_length, output_dim=embed_dim
)
self.sequence_length = длина_последовательности
self.vocab_size = vocab_size
self.embed_dim = встроенный_dim
деф вызов(я, входы):
длина = tf.shape (входы) [-1]
position = tf.range (start = 0, limit = length, delta = 1)
embedded_tokens = self.token_embeddings (входы)
встроенные_позиции = self.position_embeddings(позиции)
вернуть встроенные_токены + встроенные_позиции
def calculate_mask (я, входы, маска = нет):
вернуть tf.math.not_equal (входы, 0)
класс TransformerDecoder (слои. Слой):
def __init__(self, embed_dim, hidden_dim, num_heads, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.embed_dim = встроенный_dim
self.latent_dim = скрытый_dim
self.num_heads = количество_голов
self.attention_1 = слои.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim
)
self.
Встраивание(
input_dim=sequence_length, output_dim=embed_dim
)
self.sequence_length = длина_последовательности
self.vocab_size = vocab_size
self.embed_dim = встроенный_dim
деф вызов(я, входы):
длина = tf.shape (входы) [-1]
position = tf.range (start = 0, limit = length, delta = 1)
embedded_tokens = self.token_embeddings (входы)
встроенные_позиции = self.position_embeddings(позиции)
вернуть встроенные_токены + встроенные_позиции
def calculate_mask (я, входы, маска = нет):
вернуть tf.math.not_equal (входы, 0)
класс TransformerDecoder (слои. Слой):
def __init__(self, embed_dim, hidden_dim, num_heads, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.embed_dim = встроенный_dim
self.latent_dim = скрытый_dim
self.num_heads = количество_голов
self.attention_1 = слои.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim
)
self. attention_2 = слои.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim
)
self.dense_proj = keras.Sequential(
[layers.Dense(latent_dim, активация="relu"),layers.Dense(embed_dim),]
)
self.layernorm_1 = слои.LayerNormalization()
self.layernorm_2 = слои.LayerNormalization()
self.layernorm_3 = слои.LayerNormalization()
self.supports_masking = Истина
вызов def (я, входы, encoder_outputs, маска = нет):
causal_mask = self.get_causal_attention_mask(входные данные)
если маска не None:
padding_mask = tf.cast (маска [:, tf.newaxis, :], dtype = "int32")
padding_mask = tf.minimum (padding_mask, causal_mask)
внимание_выход_1 = я.внимание_1(
запрос=входы, значение=входы, ключ=входы, маска_внимания=каузальная_маска
)
out_1 = self.layernorm_1 (входы + внимание_выход_1)
внимание_выход_2 = я.внимание_2(
запрос=out_1,
значение = encoder_outputs,
ключ = encoder_outputs,
Attention_mask=padding_mask,
)
out_2 = self.
attention_2 = слои.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim
)
self.dense_proj = keras.Sequential(
[layers.Dense(latent_dim, активация="relu"),layers.Dense(embed_dim),]
)
self.layernorm_1 = слои.LayerNormalization()
self.layernorm_2 = слои.LayerNormalization()
self.layernorm_3 = слои.LayerNormalization()
self.supports_masking = Истина
вызов def (я, входы, encoder_outputs, маска = нет):
causal_mask = self.get_causal_attention_mask(входные данные)
если маска не None:
padding_mask = tf.cast (маска [:, tf.newaxis, :], dtype = "int32")
padding_mask = tf.minimum (padding_mask, causal_mask)
внимание_выход_1 = я.внимание_1(
запрос=входы, значение=входы, ключ=входы, маска_внимания=каузальная_маска
)
out_1 = self.layernorm_1 (входы + внимание_выход_1)
внимание_выход_2 = я.внимание_2(
запрос=out_1,
значение = encoder_outputs,
ключ = encoder_outputs,
Attention_mask=padding_mask,
)
out_2 = self. layernorm_2 (out_1 + внимание_output_2)
proj_output = self.dense_proj(out_2)
вернуть self.layernorm_3 (out_2 + proj_output)
def get_causal_attention_mask (я, входы):
input_shape = tf.shape (входы)
размер_пакета, длина последовательности = форма_ввода[0], форма_ввода[1]
i = tf.range(sequence_length)[:, tf.newaxis]
j = tf.range(sequence_length)
маска = tf.cast(i >= j, dtype="int32")
маска = tf.reshape (маска, (1, input_shape [1], input_shape [1]))
мульт = tf.concat(
[tf.expand_dims(batch_size, -1), tf.constant([1, 1], dtype=tf.int32)],
ось=0,
)
вернуть tf.tile (маска, мульти)
layernorm_2 (out_1 + внимание_output_2)
proj_output = self.dense_proj(out_2)
вернуть self.layernorm_3 (out_2 + proj_output)
def get_causal_attention_mask (я, входы):
input_shape = tf.shape (входы)
размер_пакета, длина последовательности = форма_ввода[0], форма_ввода[1]
i = tf.range(sequence_length)[:, tf.newaxis]
j = tf.range(sequence_length)
маска = tf.cast(i >= j, dtype="int32")
маска = tf.reshape (маска, (1, input_shape [1], input_shape [1]))
мульт = tf.concat(
[tf.expand_dims(batch_size, -1), tf.constant([1, 1], dtype=tf.int32)],
ось=0,
)
вернуть tf.tile (маска, мульти)
Далее собираем модель встык.
embed_dim = 256 скрытый_дим = 2048 число_голов = 8 encoder_inputs = keras.Input(shape=(None,), dtype="int64", name="encoder_inputs") x = PositionalEmbedding (sequence_length, vocab_size, embed_dim) (encoder_inputs) encoder_outputs = TransformerEncoder (встроенный_dim, скрытый_dim, num_heads) (x) encoder = keras.Model (encoder_inputs, encoder_outputs) decoder_inputs = keras.Input(shape=(None,), dtype="int64", name="decoder_inputs") encoded_seq_inputs = keras.Input(shape=(None, embed_dim), name="decoder_state_inputs") x = PositionalEmbedding (sequence_length, vocab_size, embed_dim) (decoder_inputs) x = TransformerDecoder (embed_dim, hidden_dim, num_heads) (x, encoded_seq_inputs) x = слои. Выпадение (0,5) (x) decoder_outputs = слои.Dense (vocab_size, активация = "softmax") (x) декодер = keras.Model([decoder_inputs, encoded_seq_inputs], decoder_outputs) decoder_outputs = декодер ([decoder_inputs, encoder_outputs]) трансформатор = keras.Model( [encoder_inputs, decoder_inputs], decoder_outputs, name="transformer" )
Обучение нашей модели
Мы будем использовать точность как быстрый способ отслеживать ход обучения на проверочных данных. Обратите внимание, что машинный перевод обычно использует баллы BLEU, а также другие показатели, а не точность.
Здесь мы тренируемся только на 1 эпоху, но чтобы модель действительно сходилась
вы должны тренироваться не менее 30 эпох.
эпох = 1 # Это должно быть не менее 30 для сходимости
трансформатор.резюме()
трансформатор.компилировать(
"rmsprop", loss="sparse_categorical_crossentropy", metrics=["точность"]
)
трансформатор.фит (train_ds, эпохи = эпохи, validation_data = val_ds)
Модель: "трансформер"
______________________________________________________________________________________________________________
Слой (тип) Выходная форма Параметр # Подключен к
================================================== ================================================
encoder_inputs (InputLayer) [(Нет, Нет)] 0
______________________________________________________________________________________________________________
positional_embedding (Positiona (None, None, 256) 3845120 encoder_inputs[0][0]
______________________________________________________________________________________________________________
decoder_inputs (InputLayer) [(Нет, Нет)] 0
______________________________________________________________________________________________________________
convert_encoder (Transforme (None, None, 256) 3155456 positional_embedding[0][0]
______________________________________________________________________________________________________________
model_1 (Функциональный) (Нет, Нет, 15000) 12959640 decoder_inputs[0][0]
трансформер_энкодер[0][0]
================================================== ================================================
Всего параметров: 19 960 216
Обучаемые параметры: 19 960 216
Необучаемые параметры: 0
______________________________________________________________________________________________________________
1302/1302 [=============================] - 1297 с 993 мс/шаг - потери: 1,6495 - точность: 0,4284 - val_loss : 1,2843 - val_accuracy: 0,5211
 python.keras.callbacks.History по адресу 0x164a6c250>
python.keras.callbacks.History по адресу 0x164a6c250>
Расшифровка тестовых предложений
Наконец, давайте продемонстрируем, как переводить совершенно новые английские предложения.
Мы просто загружаем в модель векторизованное английское предложение.
а также целевой токен "[start]" , то мы неоднократно генерировали следующий токен, пока
мы попали в токен "[end]" .
spa_vocab = spa_vectorization.get_vocabulary() spa_index_lookup = dict(zip(диапазон(len(spa_vocab)), spa_vocab)) max_decoded_sentence_length = 20 def decode_sequence (input_sentence): tokenized_input_sentence = eng_vectorization([input_sentence]) decoded_sentence = "[начало]" для i в диапазоне (max_decoded_sentence_length): tokenized_target_sentence = spa_vectorization([decoded_sentence])[:, :-1] прогнозы = трансформатор ([tokenized_input_sentence, tokenized_target_sentence]) sampled_token_index = np.argmax (предсказания [0, i,:]) sampled_token = spa_index_lookup[sampled_token_index] decoded_sentence += " " + sampled_token если sampled_token == "[конец]": ломать вернуть decoded_sentence test_eng_texts = [pair[0] для пары в test_pairs] для _ в диапазоне (30): input_sentence = random.
