
Запрет индексации страниц/директорий через robots.txt
Все поисковые роботы при заходе на сайт в первую очередь ищут файл robots.txt. Это текстовый файл, находящийся в корневой директории сайта (там же где и главный файл index., для основного домена/сайта, это папка public_html), в нем записываются специальные инструкции для поисковых роботов.
Эти инструкции могут запрещать к индексации папки или страницы сайта, указать роботу на главное зеркало сайта, рекомендовать поисковому роботу соблюдать определенный временной интервал индексации сайта и многое другое
Если файла robotx.txt нет в каталоге вашего сайта, тогда вы можете его создать.
Чтобы запретить индексирование сайта через файл robots.txt, используются 2 директивы: User-agent и Disallow.
- User-agent: УКАЗАТЬ_ПОИСКОВОГО_БОТА
- Disallow: / # будет запрещено индексирование всего сайта
- Disallow: /page/ # будет запрещено индексирование директории /page/
Запретить индексацию вашего сайта ботом MSNbot
User-agent: MSNBot
Disallow: /
Запретить индексацию вашего сайта ботом Yahoo
User-agent: Slurp
Disallow: /
Запретить индексацию вашего сайта ботом Yandex
User-agent: Yandex
Disallow: /
Запретить индексацию вашего сайта ботом Google
User-agent: Googlebot
Disallow: /
Запретить индексацию вашего сайта для всех поисковиков
User-agent: *
Disallow: /
Запрет индексации папок cgi-bin и images для всех поисковиков
User-agent: *
Disallow: /cgi-bin/
Disallow: /images/
Теперь как разрешить индексировать все страницы сайта всем поисковикам (примечание: эквивалентом данной инструкции будет пустой файл robots. txt):
txt):
User-agent: *
Disallow:
Пример:
Разрешить индексировать сайт только ботам Yandex, Google, Rambler с задержкой 4сек между опросами страниц.
User-agent: *
Disallow: /
User-agent: Yandex
Crawl-delay: 4
Disallow:
User-agent: Googlebot
Crawl-delay: 4
Disallow:
User-agent: StackRambler
Crawl-delay: 4
Disallow:
Запретить индексацию страниц/директорий (robots.txt) — База знаний
Все поисковые роботы при заходе на сайт в первую очередь ищут файл robots.txt. Это текстовый файл, находящийся в корневой директории сайта (там же где и главный файл index., для основного домена/сайта, это папка public_html), в нем записываются специальные инструкции для поисковых роботов. Эти инструкции могут запрещать к индексации папки или страницы сайта, указать роботу на главное зеркало сайта, рекомендовать поисковому роботу соблюдать определенный временной интервал индексации сайта и многое другое
Если файла robotx. txt нет в каталоге вашего сайта, тогда вы можете его создать.
txt нет в каталоге вашего сайта, тогда вы можете его создать.
Чтобы запретить индексирование сайта через файл robots.txt, используются 2 директивы: User-agent и Disallow.
User-agent: УКАЗАТЬ_ПОИСКОВОГО_БОТА
Disallow: / # будет запрещено индексирование всего сайта
Disallow: /page/ # будет запрещено индексирование директории /page/
Примеры:
1. Запретить индексацию вашего сайта ботом MSNbot
User-agent: MSNBot
Disallow: /
2. Запретить индексацию вашего сайта ботом Yahoo
User-agent: Slurp
Disallow: /
3. Запретить индексацию вашего сайта ботом Yandex
User-agent: Yandex
Disallow: /
4. Запретить индексацию вашего сайта ботом Google
User-agent: Googlebot
Disallow: /
5. Запретить индексацию вашего сайта для всех поисковиков
User-agent: *
Disallow: /
6. Усложняем задачу и например Яндексу запрещаем индексировать папки cgi-bin и images, а Апорту файлы myfile1.htm и myfile2.htm в директории subdir (название папки где расположены файлы myfile1. htm и myfile2.htm)
htm и myfile2.htm)
User-agent: Yandex
Disallow: /cgi-bin/
Disallow: /images/
User-agent: Aport
Disallow: /subdir/myfile1.htm
Disallow: /subdir/myfile2.htm
7. Запрет индексации папок cgi-bin и images для всех поисковиков
User-agent: *
Disallow: /cgi-bin/
Disallow: /images/
Теперь как разрешить индексировать все страницы сайта всем поисковикам (примечание: эквивалентом данной инструкции будет пустой файл robots.txt):
User-agent: *
Disallow:
P.S. Для различных CMS, в интернете можно найти рекомендации, какие директории лучше закрыть от индексации поисковиками., в большей степени это нужно ради безопасности и уменьшения нагрузки на сервер.
Как настроить robots.txt | REG.RU
«robots.txt» — это специальный файл, позволяющий настроить порядок индексирования вашего сайта поисковыми роботами.
Вот некоторые настройки, которые можно произвести при помощи «robots.txt»:
- закрыть от индексирования определённые страницы сайта;
- запретить индексацию для конкретных роботов или вовсе закрыть сайт от индексации;
- задать время (интервал) посещения страницы вашего сайта поисковыми роботами.
Настройка robots.txt
Файл «robots.txt» необходимо размещать в каталоге сайта. Если файла не существует, просто создайте его.
Как задать временной интервал обращения поисковых роботов?
Задать временной интервал обращения можно на странице Индексирование — Скорость обхода
в Яндекс.Вебмастере. Подробнее читайте на странице справки Яндекса.Обратите внимание:
— снижать скорость обхода сайта роботом нужно только в том случае, если создается избыточная нагрузка на сервер. В других случаях менять параметр не требуется;
— снижение скорости обхода сайта роботом не влияет на поисковую выдачу в Яндексе.
Как закрыть индексацию папки, URL?
# закрываем индексацию страницы vip.html для Googlebot:
User-agent: Googlebot
Disallow: /vip.html
# закрываем индексацию папки private всеми роботами:
User-agent: *
Disallow: /private/
# разрешаем доступ только к страницам, начинающимся с '/shared' для Yandexbot
User-agent: Yandex
Disallow: /
Allow: /sharedДиректива «User-agent» определяет, для какого робота будут работать правила. Можно указать названия конкретных роботов, а можно задать правило для всех роботов.
Как полностью закрыть сайт от индексации?
Для запрета индексации вашего сайта всеми поисковыми роботами добавьте в файл «robots.txt» следующие строки:
User-agent: *
Disallow: /Примечание
Не все поисковые роботы следуют правилам в «robots.txt». Так, например, «Googlebot» следует запрещающим правилам («Disallow»), но не следует директиве «Crawl-delay». Ограничивать «Googlebot» необходимо через Инструменты для веб-мастеров Google.
Справка Google: О файлах robots.txt
Для робота «YandexBot» максимально возможное ограничение через «robots.txt» составляет 2 секунды. Чтобы указать нужную частоту, с которой робот будет индексировать ваш сайт, воспользуйтесь Яндекс.Вебмастером.
Справка Yandex: Использование robots.txt
Помогла ли вам статья? 33
раза уже
помогла
Работа с файлом robots.
 txt
txtКогда происходит создание сайта, то оптимизация его содержания происходит в двух направлениях :
- Оптимизируют дизайн и тексты для посетителей веб-ресурса
- Оптимизации подвергается программная часть сайта, которая важна для поисковых систем
Файл robots.txt имеет неоднозначную оценку в среде веб-программистов и специалистов по продвижению веб-сайтов. Этот файл существует во всех сайтах, его готовят специалисты для поисковых систем в ходе оптимизации веб-ресурса для раскрутки. Но все же не до конца понятно то, важен ли в наше время этот файл. Нужно заметить, что файл robots.txt представляет собой неисполняемый файл, который имеет содержание сугубо для поисковых систем. Причем те инструкции, которые указываются в файле robots.txt могут быть применены и без него, если установить в CMS сайта нужные функциональные плагины.
Например, через файл robots.txt имеется возможность запретить индексирование сайта, однако та же функция имеется и в специальных плагинов для seo, которые можно установить бесплатно через магазин плагинов для любой CMS, а также запретить индексировать сайт или отдельные страницы сайта можно и через панель управления служб Яндекс Вебмастер и Google Вебмастер.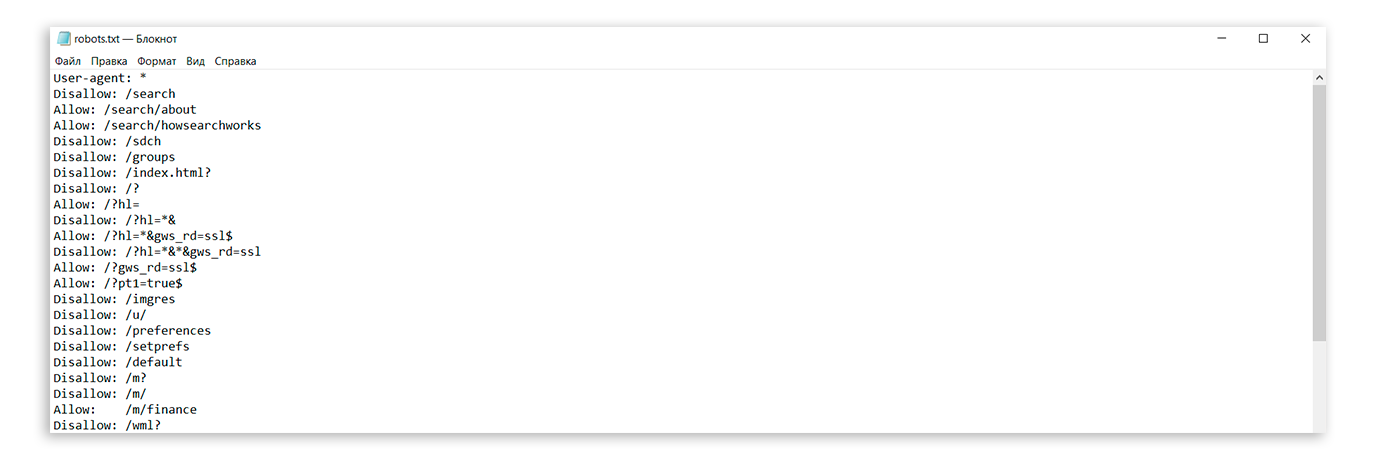 Также через эти службы, как и через файл robots.txt, можно запретить индексирование, например, версий страниц сайта для печати.
Также через эти службы, как и через файл robots.txt, можно запретить индексирование, например, версий страниц сайта для печати.
Когда начинается процесс индексирования контента сайта поисковыми системами, те в первую очередь ищут в корневом каталоге файл robots.txt, который должен с самого начала указать поисковым ботом то, какие страницы разрешено индексировать, а какие все же нет. Но, как указывают специалисты, поисковые боты индексируют все страницы сайтов, даже если их запрещает владелец сайта через файл robots.txt, только запрещенные к индексации страницы не попадут в поисковую выдачу. И вот опять можно задать вопрос- зачем тогда нужен файл robots.txt? Его функции заменяют панель управления сайтами через службы вебмастера от крупнейших поисковиков, и даже при запрещении индексирования некоторого контента через этот файл, все равно поисковики индексируют весь контент сайта.
Не стоит забывать, что файл robots.txt не исполняемый, то есть его можно только читать. Править этот файл можно разными способами. И через обычный бесплатный редактор Notepad, установленный на компьютер, либо через панель управления контентом CMS, где также есть возможность управлять записями этого файла. Конечно, не стоит забывать, что хоть файл robots.txt это всего лишь читаемый файл, содержание его обращено к поисковым ботам, а значит информация в этом файле должна быть написана на понятном языке для всех поисковых ботов в мире, и иметь ясную и четкую структуру.
И через обычный бесплатный редактор Notepad, установленный на компьютер, либо через панель управления контентом CMS, где также есть возможность управлять записями этого файла. Конечно, не стоит забывать, что хоть файл robots.txt это всего лишь читаемый файл, содержание его обращено к поисковым ботам, а значит информация в этом файле должна быть написана на понятном языке для всех поисковых ботов в мире, и иметь ясную и четкую структуру.
Структура файла robots.txt
Начинается записать в файле robots.txt всегда с упоминания того поискового бота, к которому будет обращены команды. Обращаться к поисковому боту можно с помощью директивы User-agent. Стоит отметить и то, что если после директивы User-agent стоит звездочка *, то значит команда директивы обращена ко всем поисковым ботам. Также не стоит забывать и о том, что текст в файле robots.txt не чувствителен к регистру, то есть можно писать как с большой буквы. Так и большими буквами. Но лучше всего, раз уж этот традиционный файл используется на сайте, лучше соблюдать все традиции. После директивы user-agent используется название поискового бота, к которому и обращено послание. Если к поисковому боту от Google, то после директивы первой стоит добавить googlebot, если к поисковой системе Яндекс, то Yandex. Таким образом, первая запись всегда в файле robots.txt имеет первую строку :
После директивы user-agent используется название поискового бота, к которому и обращено послание. Если к поисковому боту от Google, то после директивы первой стоит добавить googlebot, если к поисковой системе Яндекс, то Yandex. Таким образом, первая запись всегда в файле robots.txt имеет первую строку :
User-agent: googlebot
После обращению к поисковому боту стоит указать те папки или файлы, которые запрещено индексировать. Используется для этого простая директива Disallow. После ее объявления, нужно указать запрещенные к индексированию папки или файлы, как указано в примере ниже:
Disallow: /feedback.php Disallow: /cgi-bin/
В данном примере показано, что в файле robots.txt были запрещены к индексированию файл feedback.php и папка cgi-bin/ , которые находятся в корневом каталоге сайта. Для особо ленивых предусмотрена возможность блокировки по начальным символам, поэтому стоит всегда быть аккуратней с директивой Disallow, а также с упоминанием в ней различных файлов и папок. Если указать в файле robots.txt :
Если указать в файле robots.txt :
Disallow : prices
То поисковой бот не будет индексировать и имеющиеся файлы http://site.ru/prices.php и даже папку http://site.ru/prices/
Также не стоит забывать, что после директивы Disallow ничего не находится, то полностью все содержание сайта будет проиндексировано. Если же после директивы Disallow стоит символ /, то абсолютно полностью все содержимое сайта запрещено индексировать.
Если вдруг возникла свободная минутка и есть желание пообщаться с поисковыми ботами, но нет желание ничего запрещать для индексирования, то можно создать файл robots.txt с командой :
User-agent: * Disallow:
Поисковой бот любой поймет, что владелец сайта имеет много свободного времени, раз тратить свое время на создание файла robots.txt, в котором разрешает всем ботам индексировать все содержание сайта. Если не будет такой записи или даже вообще будет отсутствовать файл robots.txt, то любой поисковик так и сделает.
Директива Allow и ее магические свойства
Не все волшебство файла robots.txt заключено в запрете индексирования файлов сайта, также можно разрешать индексировать. Все точно также, как и с директивой Disallow, только используется директива Allow, которая разрешает индексацию всего, что указано. Вот пример :
User-agent: Yandex Allow: /prices Disallow: /
Все ясно и понятно – Поисковому боту от Яндекса запрещается индексировать на сайте все, кроме папки prices. Стоит отметить, что директиву Allow используют всегда перед директивой Disallow. Если после Allow в файле robots.txt будет пусто , то это означает, что поисковому боту Яндекса запрещена индексация всех файлов :
User-agent: Yandex Allow:
Иными словами, в файле robots.txt директивы Disallow / и Allow равнозначны, запрещающие индексацию.
Все поисковые системы, по крайней мере речь если идет о крупнейших, понимают содержание записей файла robots. txt одинаково. Если есть опасения запутаться в директивах данного файла, то лучше всего использовать службы Яндекс Вебмастер и Google Вебмастер, через которые можно начать индексацию страниц сайта, а также без труда управлять индексацией страниц, разрешая или запрещая те или иные страницы для поисковых ботов. Эти службы помогают также загрузить карту сайта.
txt одинаково. Если есть опасения запутаться в директивах данного файла, то лучше всего использовать службы Яндекс Вебмастер и Google Вебмастер, через которые можно начать индексацию страниц сайта, а также без труда управлять индексацией страниц, разрешая или запрещая те или иные страницы для поисковых ботов. Эти службы помогают также загрузить карту сайта.
Специальные регулярные выражения для robots.txt
С помощью всемогущего файла robots.txt можно запретить индексировать не только отдельные страницы сайта или какие-то папки с файлами, но и отдельно файлы. Это очень удобно бывает в том случае, если сайт достаточно крупный, и в нем находится большое количество файлов различного содержания. Тут нужно отдельно указать, что регулярные выражение $ означает окончание ссылки, указанной в файле, а звездочка * на любой адрес ссылки или название файла в указанном формате. Вот пример :
User-agent: Yandex Allow: /prices/*.html$ Disallow: /
Ценителям магии файла robots. txt все понятно с этой записью, точно также, как и поисковому боту от Яндекса. Поисковик должен индексировать все файлы в папке prices в html формате, но запрещена индексация любых других файлов на сайте. Или еще один пример с регулярными выражениями для robots.txt :
txt все понятно с этой записью, точно также, как и поисковому боту от Яндекса. Поисковик должен индексировать все файлы в папке prices в html формате, но запрещена индексация любых других файлов на сайте. Или еще один пример с регулярными выражениями для robots.txt :
User-agent: Yandex Disallow: *.pdf$
Запись говорит, что Яндекс-боту запрещена индексация всех файлов в формате pdf.
Путь к карте сайта
Файл robots.txt многофункциональный читаемый файл, которые также указывает и направление поисков поисковыми ботами карты сайта. Стоит отметить, что карта сайта, если веб-ресурс действительно обширен, очень важна для того, чтобы поисковые системы могли проиндексировать все нужные страницы и файлы сайта. Послать поисковой бот можно с помощью директивы Sitemap :
User-agent: googlebot Disallow: Sitemap: http://site.ru/sitemap.xml
Загрузить карту сайта можно и с помощью служб Яндекс Вебмастер и Google Вебмастер, не работая с директивами robots.txt.
Работа с зеркалами сайта в файле robots.txt
Не так давно поисковой гигант Google решил начать борьбу за повышенную защищенность посетителей сайтов в интернете, и решил оценивать сайты с шифрованном трафиком с https протоколом выше сайтов, которые были всегда с стандартным http протоколом. И многие владельцы сайтов, даже если они не работали с платежными системами, должны были перейти на https протокол для того, чтобы поднять свой рейтинг в поисковой выдачи. Но как это сделать?
Начать нужно с того, что для поисковых систем сайты http://site.ru/ и https://site.ru/ являются различными, хотя имеют одинаковое название, и являются по сути зеркалами друг друга, но поисковые системы будут их по-разному индексировать и оценивать. Чтобы указать поисковым ботам, что нужно индексировать только одно главное зеркало сайта, требуется использовать директиву Hosts в файле robots.txt. Выглядеть это будет так :
User-agent: googlebot Disallow: /prices.php Host: https://site.(.*)$ http://www.site.ru/$1 [R=301,L]
Использование комментариев в robots.txt
Зачем комментировать что-то для поисковых ботов в файле robots.txt? Сложно сказать, но если кому-то захочется это делать, стоит использовать символ #. Вот пример :
User-agent: googlebot Disallow: /prices/ # тут нет ничего интересного
Краткое описание работы с файлом robots.txt
1.Как разрешить всем поисковым ботам индексацию всех файлов на сайте?
User-agent: * Disallow:
2.Как запретить всем поисковым ботам индексацию всех файлов на сайте?
User-agent: * Disallow: /
3.Как запретить поисковому боту от Google индексировать файл prices.html?
User-agent: googlebot Disallow: prices.html
4.Как разрешить всем поисковым ботам индексировать весь сайта, а боту от Google запрещаем индексацию папки prices?
User-agent: googlebot Disallow: /prices/ User-agent: * Disallow:
Какие ошибки могут возникнуть при работе с файлом robots.
 txt?
txt?Нужно сказать, что поисковые боты не чувствительны к регистру букв при написании директив, но с названием файлов и папок нужно быть осторожнее. Также проблем между директивами не стоит делать просто так для красоты, ведь для файла robots.txt проблем означает разделение команд для разных поисковых ботов.
Для каждого поискового бота нужно создавать свою директиву user-agent, а не пытаться в одну вписать несколько ботов. Очень часто забывают использовать символ / перед названием папок, что приведет к недопониманию поисковым ботом директивы. Также админка сайта исключается всегда поисковыми ботами из индексации и ее не следует указывать в файле. Есть мнение специалистов, что большой размер файла robots.txt с огромным списком страниц сайта и файлов, исключаемых из индексации, просто игнорируются поисковыми системами.
Поэтому надежней всего удалять ненужные файлы, а не указывать запрет на их индексацию.
Как проверить файл robots.txt на фатальные ошибки?
Если файл robots.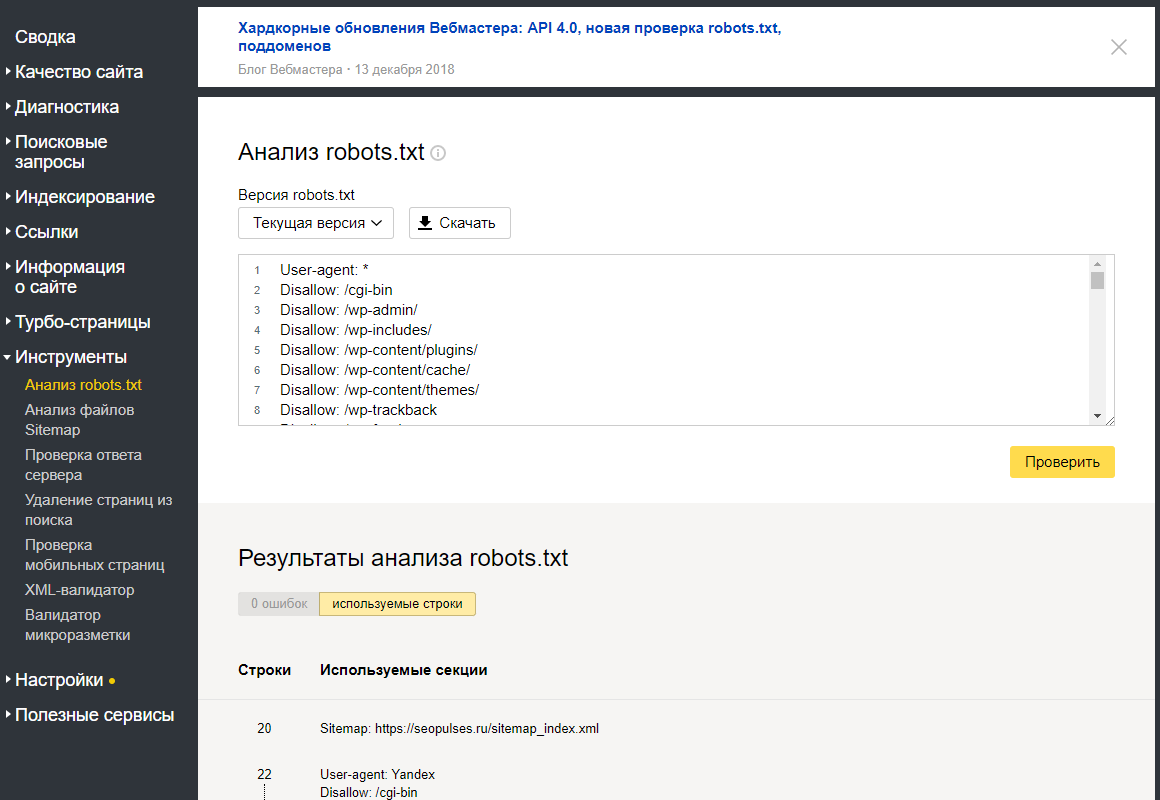 txt отличается многословием, то есть в нем указаны команды для поисковых ботов для множества файлов и страниц сайта, то лучше провести проверку качества файла robots.txt с помощью ресурсов Яндекс Вебмастер и Google Вебмастер.
txt отличается многословием, то есть в нем указаны команды для поисковых ботов для множества файлов и страниц сайта, то лучше провести проверку качества файла robots.txt с помощью ресурсов Яндекс Вебмастер и Google Вебмастер.
Зачем вам нужен robots.txt
Почти в каждом материале по разработке и продвижению мы упоминаем robots.txt. Сегодня не будем упоминать, а всю статью будем рассказывать про него, про правильный robots.txt в 2021 году.
Вот так выглядит robots.txt Google. Примерно так же выглядит и robots.txt вашего сайта. По сути, это текстовый файл со списком исключений для поисковых роботов. Исключения запрещают индексировать одни разделы сайта и разрешают другие. Это необходимо, чтобы защитить конфиденциальную информацию, административные файлы или страницы, которые в силу требований SEO не должны попасть в поиск.
Инструкции
Поисковые роботы законопослушны. Они четко следуют инструкциям robots. txt и сканируют только те ссылки, которые разрешены. Инструкции в файле называются директивами, и в дальнейшем мы будем употреблять именно этот термин.
txt и сканируют только те ссылки, которые разрешены. Инструкции в файле называются директивами, и в дальнейшем мы будем употреблять именно этот термин.
Директива User-agent для разграничения команд
Все robots.txt начинаются с user-agent. Это своеобразный маршрутизатор, который определяет адресата последующих команд. К ботам Яндекса и Гугла user-agent обращается по-разному — User-agent:Yandex и User-agent:GoogleBot, соответственно. User-agent из файла Google начинается с символа * и это значит, что дальнейшие команды относятся ко всем поисковым ботам.
Сразу отвечаем на закономерно возникающий вопрос: «Зачем указывать отдельные директивы для Яндекса и Гугла, если можно сделать универсальный список?». Поисковых ботов несколько. У одного только Гугла их семь: анализатор рекламы на десктопах и мобильных, индексатор картинок и видео, новостной сканер, бот по оценке рекламы для приложений на Android. Подставляя в user-agent имя нужного бота, можно определить список директив именно для него. Например, запретить индексацию картинок. Плюс у поисковых ботов разный подход к сканированию. Так, команду clean-param воспринимает только Яндекс и бесполезно указывать ее в блоке указаний для Гугла — не поймет.
Например, запретить индексацию картинок. Плюс у поисковых ботов разный подход к сканированию. Так, команду clean-param воспринимает только Яндекс и бесполезно указывать ее в блоке указаний для Гугла — не поймет.
Для больших сайтов с разными стратегиями продвижения имеет смысл прописывать директивы под конкретных ботов. Маленьким несложным ресурсам мы обычно рекомендует обращаться сразу ко всем индексаторам и использовать User-agent с символом *.
Директива disallow
Disallow — команда запрета. Она запрещает индексировать отдельные файлы, страницы или целые разделы. Обычно, disallow закрывают страницу входа в панель администрирования, документы PDF, DOC, XLS, формы регистрации, корзины, страницы с персональными данными клиентов и пр.
В robots.txt для Bitrix, например, disallow выглядит так:
User-agent: *
Disallow: /wp-admin/
Это в случае, когда мы закрываем доступ к панели управления.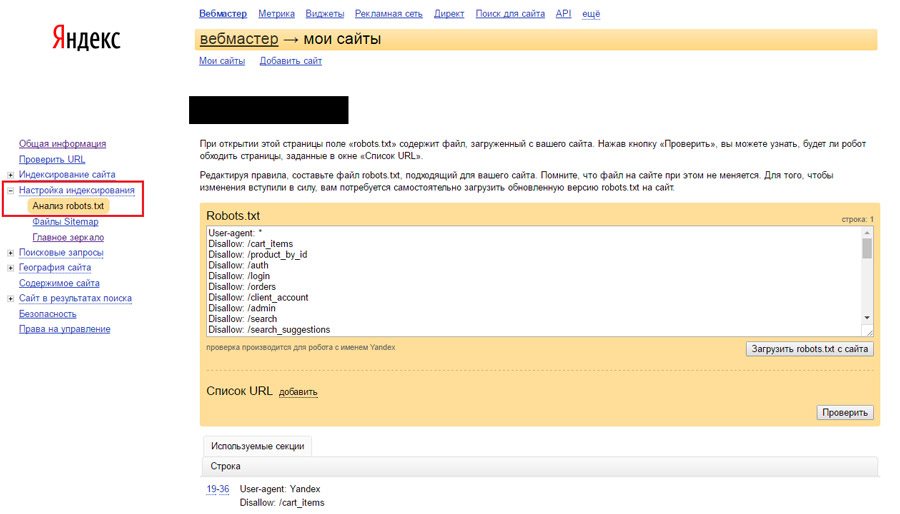
Или так:
User-agent: *
Disallow: /images/
Такая комбинация запретит боту индексировать иллюстрации.
В структуре команды символ / обозначает, что нужно закрыть от индексации, а знак * боты понимают как «любой текст».
Важно! Disallow закрывает доступ поисковым роботам, но не людям, поэтому конфиденциальную информацию на сайте рекомендуем обязательно защищать аутентификацией.
Директивы allow и sitemap
Allow разрешает все, что не запрещает disallow. Это может показаться странным, ведь бот и без того может индексировать все, что не закрыто от сканирования. На самом деле allow нужна для выборочной индексации файлов или документов в закрытом разделе. Допустим, у вас есть закрытый с помощью disallow раздел для дистрибьюторов:
User-agent: *
Disallow: /distributoram/
Он будет выглядеть так, когда вы полностью закрываете индексацию раздела. Но допустим, в закрытом каталоге есть страница или файл, который имеет смысл показать пользователям. Вот тут на сцену выходит allow. Получается так:
User-agent: *
Disallow: /distributoram/
Allow: /distributoram/usloviya.html
При такой расстановке боты поймут, что из всего раздела distributoram они могут сканировать только контент страницы usloviya.html.
Sitemap одновременно и карта сайта, и директива. Про карту сайта в другой раз, а в роли директивы sitemap используется во всех случаях, когда вы хотите направить роботов на определенные разделы сайта.
Директиву sitemap поисковые боты воспринимают как указатель на приоритетные разделы, но если Яндекс понимает ее как рекомендацию, то GoogleBot как обязательное требование. Само собой, используя в robots.txt команду sitemap, саму карту в корневом каталоге необходимо поддерживать в актуальном состоянии.
Создаем и проверяем robots.txt
Для создания файла подойдет любой текстовый редактор, тот же «Блокнот». На первое место ставим адресную директиву user-agent, потом блоками вносим disallow и allow. Примеры и руководства есть у обоих поисковиков. У Яндекса в разделе «Помощь вебмастеру». У Google в Центре Google Поиска.
Чтобы прописать robots.txt на сайте, файл сохраняем в текстовом формате и загружаем в корень. После загрузки проверьте правильность установки — robots.txt должен открываться по адресу вашсайт/robots.txt. Для проверки работоспособности вставьте ссылку на сайт и код файла в специальные поля сервиса https://webmaster.yandex.ru/tools/robotstxt/ Яндекса и выберите подтвержденный ресурс в https://www.google.com/webmasters/tools/robots-testing-tool в Google.
Зачем проверять robots.txt
В случае с robots ошибки проводят к выпадению из индекса одного раздела и попаданию в выдачу другого, совершенно лишнего и абсолютно ненужного. Кроме того, поисковые системы регулярно меняют правила индексации и добавляют/убирают отдельные директивы. Так, с 22 февраля 2018 года Яндекс перестал учитывать crawl-delay, но у многих сайтов в robots.txt она до сих пор есть и SEO-менеджеры до сих пор уверены, что управляют скоростью обхода.
Кроме того, поисковые системы регулярно меняют правила индексации и добавляют/убирают отдельные директивы. Так, с 22 февраля 2018 года Яндекс перестал учитывать crawl-delay, но у многих сайтов в robots.txt она до сих пор есть и SEO-менеджеры до сих пор уверены, что управляют скоростью обхода.
Держите руку на пульсе и не пренебрегайте базовыми правилами защиты сайта. Тем более, что с маленьким фалом robots.txt это совсем несложно.
Что такое robots.txt [Основы для новичков]
Успешная индексация нового сайта зависит от многих слагаемых. Один из них — файл robots.txt, с правильным заполнением которого должен быть знаком любой начинающий веб-мастер. Обновили материал для новичков.
Подробно о правилах составления файла в полном руководстве «Как составить robots.txt самостоятельно».
А в этом материале основы для начинающих, которые хотят быть в курсе профессиональных терминов.
Что такое robots.
 txt
txtФайл robots.txt — это документ в формате .txt, содержащий инструкции по индексации конкретного сайта для поисковых ботов. Он указывает поисковикам, какие страницы веб-ресурса стоит проиндексировать, а какие не нужно допустить к индексации.
Поисковый робот, придя к вам на сайт, первым делом пытается отыскать robots.txt. Если робот не нашел файл или он составлен неправильно, бот будет изучать сайт по своему собственному усмотрению. Далеко не факт, что он начнет с тех страниц, которые нужно вводить в поиск в первую очередь (новые статьи, обзоры, фотоотчеты и так далее). Индексация нового сайта может затянуться. Поэтому веб-мастеру нужно вовремя позаботиться о создании правильного файла robots.txt.
На некоторых конструкторах сайтов файл формируется сам. Например, Wix автоматически создает robots.txt. Чтобы посмотреть файл, добавьте к домену «/robots.txt». Если вы увидите там странные элементы типа «noflashhtml» и «backhtml», не пугайтесь: они относятся к структуре сайтов на платформе и не влияют на отношение поисковых систем.
Зачем нужен robots.txt
Казалось бы, зачем запрещать индексировать какое-то содержимое сайта? Далеко не весь контент, из которого состоит сайт, нужен поисковым роботам. Есть системные файлы, есть дубликаты страниц, есть рубрики ключевых слов и много чего еще есть, что вовсе не обязательно индексировать. Есть одно но:
Содержимое файла robots.txt — это рекомендации для ботов, а не жесткие правила. Рекомендации боты могут проигнорировать.
Google предупреждает, что через robots.txt нельзя заблокировать страницы для показа в Google. Даже если вы закроете доступ к странице в robots.txt, если на какой-то другой странице будет ссылка на эту, она может попасть в индекс. Лучше использовать и ограничения в robots, и другие методы запрета:
Запрет индексирования сайта, Яндекс
Блокировка индексирования, Google
Тем не менее, без robots.txt больше вероятность, что информация, которая должна быть скрыта, попадет в выдачу, а это бывает чревато раскрытием персональных данных и другими проблемами.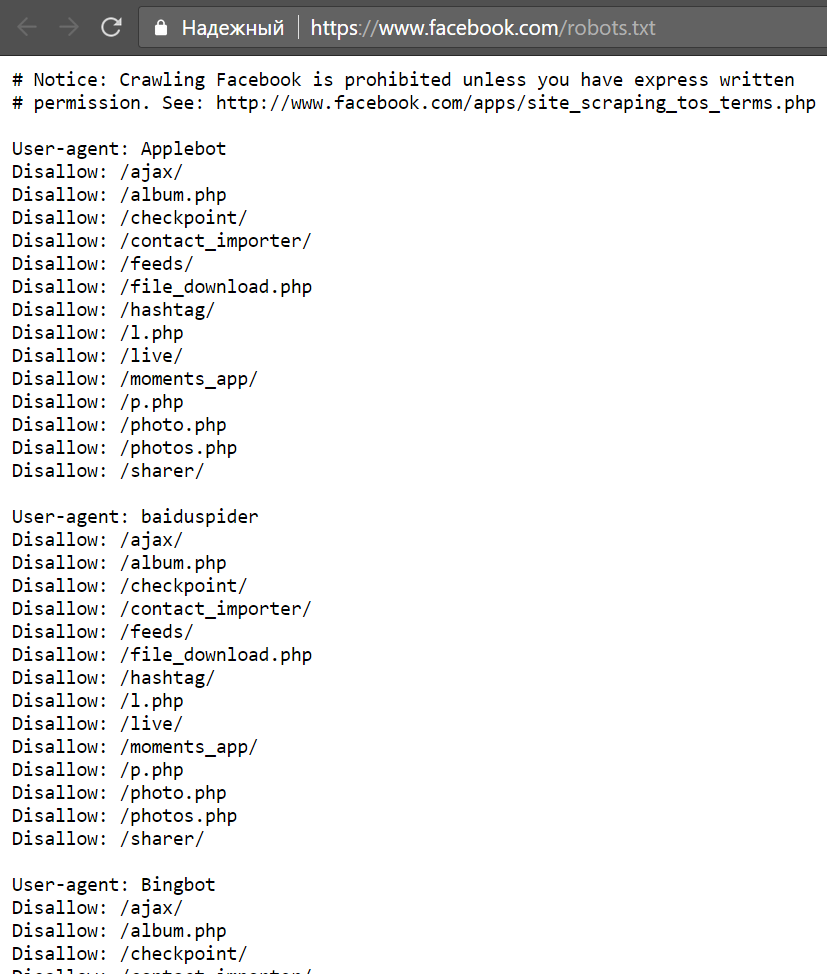
Из чего состоит robots.txt
Файл должен называться только «robots.txt» строчными буквами и никак иначе. Его размещают в корневом каталоге — https://site.com/robots.txt в единственном экземпляре. В ответ на запрос он должен отдавать HTTP-код со статусом 200 ОК. Вес файла не должен превышать 32 КБ. Это максимум, который будет воспринимать Яндекс, для Google robots может весить до 500 КБ.
Внутри все должно быть на латинице, все русские названия нужно перевести с помощью любого Punycode-конвертера. Каждый префикс URL нужно писать на отдельной строке.
В robots.txt с помощью специальных терминов прописываются директивы (команды или инструкции). Кратко о директивах для поисковых ботах:
«Us-agent:» — основная директива robots.txt
Используется для конкретизации поискового робота, которому будут давать указания. Например, User-agent: Googlebot или User-agent: Yandex.
В файле robots.txt можно обратиться ко всем остальным поисковым системам сразу. Команда в этом случае будет выглядеть так: User-agent: *. Под специальным символом «*» принято понимать «любой текст».
Команда в этом случае будет выглядеть так: User-agent: *. Под специальным символом «*» принято понимать «любой текст».
После основной директивы «User-agent:» следуют конкретные команды.
Команда «Disallow:» — запрет индексации в robots.txt
При помощи этой команды поисковому роботу можно запретить индексировать веб-ресурс целиком или какую-то его часть. Все зависит от того, какое расширение у нее будет.
User-agent: Yandex Disallow: /
Такого рода запись в файле robots.txt означает, что поисковому роботу Яндекса вообще не позволено индексировать данный сайт, так как запрещающий знак «/» не сопровождается какими-то уточнениями.
User-agent: Yandex Disallow: /wp-admin
На этот раз уточнения имеются и касаются они системной папки wp-admin в CMS WordPress. То есть индексирующему роботу рекомендовано отказаться от индексации всей этой папки.
Команда «Allow:» — разрешение индексации в robots.txt
Антипод предыдущей директивы. При помощи тех же самых уточняющих элементов, но используя данную команду в файле robots.txt, можно разрешить индексирующему роботу вносить нужные вам элементы сайта в поисковую базу.
User-agent: * Allow: /catalog Disallow: /
Разрешено сканировать все, что начинается с «/catalog», а все остальное запрещено.
На практике «Allow:» используется не так уж и часто. В ней нет надобности, поскольку она применяется автоматически. В robots «разрешено все, что не запрещено». Владельцу сайта достаточно воспользоваться директивой «Disallow:», запретив к индексации какое-то содержимое, а весь остальной контент ресурса воспринимается поисковым роботом как доступный для индексации.
Директива «Sitemap:» — указание на карту сайта
«Sitemap:» указывает индексирующему роботу правильный путь к так Карте сайта — файлам sitemap.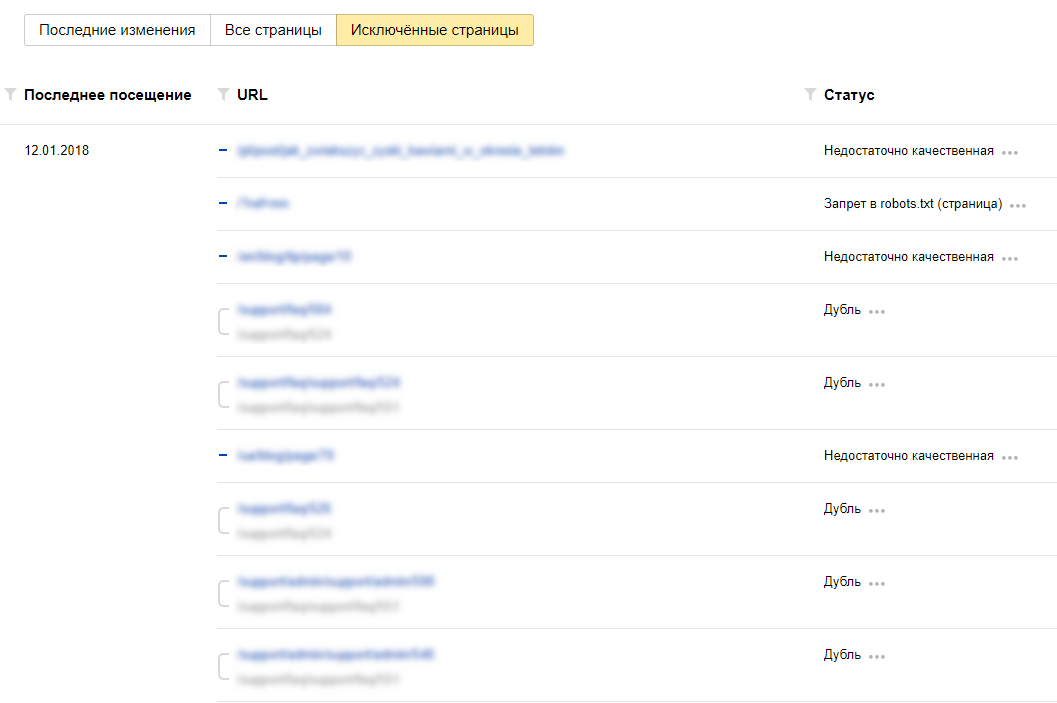 xml и sitemap.xml.gz в случае с CMS WordPress.
xml и sitemap.xml.gz в случае с CMS WordPress.
User-agent: * Sitemap: http://pr-cy.ru/sitemap.xml Sitemap: http://pr-cy.ru/sitemap.xml.gz
Прописывание команды в файле robots.txt поможет поисковому роботу быстрее проиндексировать Карту сайта. Это ускорит процесс попадания страниц ресурса в выдачу.
Файл robots.txt готов — что дальше
Итак, вы создали текстовый документ robots.txt с учетом особенностей вашего сайта. Его можно сделать автоматически, к примеру, с помощью нашего инструмента.
Что делать дальше:
- проверить корректность созданного документа, например, посредством сервиса Яндекса;
- при помощи FTP-клиента закачать готовый файл в корневую папку своего сайта. В ситуации с WordPress речь обычно идет о системной папке Public_html.
Дальше остается только ждать, когда появятся поисковые роботы, изучат ваш robots.txt, а после возьмутся за индексацию вашего сайта.
Как посмотреть robots.txt чужого сайта
Если вам интересно сперва посмотреть на готовые примеры файла robots.txt в исполнении других, то нет ничего проще. Для этого в адресной строке браузера достаточно ввести site.ru/robots.txt. Вместо «site.ru» — название интересующего вас ресурса.
Запрет индексации сайта поисковыми системами. Самостоятельно проверяем и меняем файл robots.txt. Зачем закрывать сайт от индексации?
Зачем закрывать сайт от индексации? Проверяем и меняем файл robots.txt самостоятельно.
Ответ
Для закрытия всего сайта от индексации во всех поисковых системах необходимо в файле robots.txt прописать следующую директиву:
Disallow: /
Далее, подробнее разберемся в вопросе подробнее и ответим на другие вопросы:
- Процесс индексации что это?
- Зачем закрывать сайт от индексации?
- Инструкции по изменению файла robots.
 txt
txt - Проверка корректности закрытия сайта от индексации
- Альтернативные способы закрыть сайт от поисковых систем
Оглавление
Процесс индексации
Индексация сайта — это процесс добавления данных вашего ресурса в индексную базу поисковых систем. Ранее мы подробно разбирали вопрос индексации сайта в Яндекс и Google.
Именно в этой базе и происходит поиск информации в тот момент, когда вы вводите любой запрос в строку поиска:
Именно из индексной базы поисковая система в момент ввода запроса производит поиск информации.Если сайта нет в индексной базе поисковой системе = тогда сайте нет и в поисковой выдаче. Его невозможно будет найти по поисковым запросам.
В каких случаях может потребоваться исключать сайт из баз поисковых систем?
Зачем закрывать сайт от индексации
Причин, по которым необходимо скрыть сайт от поисковых
систем может быть множество. Мы не можем знать личных мотивов всех вебмастеров.
Давайте выделим самые основные объективные причины, когда закрытие сайта от
индексации оправданно.
Мы не можем знать личных мотивов всех вебмастеров.
Давайте выделим самые основные объективные причины, когда закрытие сайта от
индексации оправданно.
Сайт еще не готов
Ваш сайт пока не готов для просмотра целевой аудиторией. Вы находитесь в стадии разработки (или доработки) ресурса. В таком случае его лучше закрыть от индексации. Тогда сырой и недоработанный ресурс не попадет в индексную базу и не испортит «карму» вашему сайту. Открывать сайт лучше после его полной готовности и наполненности контентом.
Сайт узкого содержания
Ресурс предназначен для личного пользования или для узкого круга посетителей. Он не должен быть проиндексирован поисковыми системами. Конечно, данные такого ресурса можно скрыть под паролем, но это не всегда необходимо. Часто, достаточно закрыть его от индексации и избавить от переходов из поисковых систем случайных пользователей.
Переезд сайта или аффилированный ресурс
Вы решили изменить главное зеркало сайта. Мы закрываем от индексации старый домен и открываем новый. При этом меняем главное зеркало сайта. Возможно у Вас несколько сайтов по одной теме, а продвигаете вы один, главный ресурс.
Мы закрываем от индексации старый домен и открываем новый. При этом меняем главное зеркало сайта. Возможно у Вас несколько сайтов по одной теме, а продвигаете вы один, главный ресурс.
Стратегия продвижения
Возможно, Ваша стратегия предусматривает продвижение ряда доменов, например, в разных регионах или поисковых системах. В этом случае, может потребоваться закрытие какого-либо домена в какой-либо поисковой системе.
Другие мотивы
Может быть целый ряд других личных причин закрытия сайта от индексации поисковыми системами. Можете написать в комментариях Вашу причину закрытия сайта от индексации.
Закрываем сайт от индексации в robots.txt
Обращение к Вашему сайту поисковой системой начинается с прочтения содержимого файла robots.txt. Это служебный файл со специальными правилами для поисковых роботов.
Подробнее о директивах robots.txt:
Самый простой и быстрый способ это при первом обращении к
вашему ресурсу со стороны поисковых систем (к файлу robots. txt) сообщить
поисковой системе о том, что этот сайт закрыт от индексации. В зависимости от
задач, сайт можно закрыть в одной или нескольких поисковых системах. Вот так:
txt) сообщить
поисковой системе о том, что этот сайт закрыт от индексации. В зависимости от
задач, сайт можно закрыть в одной или нескольких поисковых системах. Вот так:
| Закрыть во всех системах | Закрыть только в Яндекс | Закрыть только в Google |
| User-agent: * Disallow: / | User-agent: Yandex Disallow: / | User-agent: Googlebot Disallow: / |
Инструкция по изменению файла robots.txt
Мы не ставим целью дать подробную инструкцию по всем способам подключения к хостингу или серверу, укажем самый простой способ на наш взгляд.
Файл robots.txt всегда находится в корне Вашего сайта. Например, robots.txt сайта iqad.ru будет находится по адресу:
https://iqad.ru/robots.txt
Для подключения к сайту, мы должны в административной панели
нашего хостинг провайдера получить FTP (специальный протокол передачи файлов
по сети) доступ: <ЛОГИН> И <ПАРОЛЬ>.
В описании раздела или в разделе помощь, необходимо найти и сохранить необходимую информацию для подключения по FTP к серверу, на котором размещены файлы Вашего сайта. Данные отражают информацию, которую нужно указать в FTP-клиенте:
- Сервер (Hostname) – IP-адрес сервера, на котором размещен Ваш аккаунт
- Логин (Username) – логин от FTP-аккаунта
- Пароль (Password) – пароль от FTP-аккаунта
- Порт (Port) – числовое значение, обычно 21
Далее, нам потребуется любой FTP-клиент, можно воспользоваться бесплатной программой filezilla (https://filezilla.ru/). Вводим данные в соответствующие поля и нажимаем подключиться.
FTP-клиент filezilla интуитивно прост и понятен: вводим cервер (host) + логин (имя пользователя) + пароль + порт и кнопка {быстрое соединение}. В поле справа находим файл robots.txt и изменяем его. Не забудьте сохранить изменения.
В поле справа находим файл robots.txt и изменяем его. Не забудьте сохранить изменения.После подключения прописываем необходимые директивы. См.
раздел:
Закрываем сайт от индексации в robots.txt
Проверка корректности закрытия сайта от индексации
После того, как вы внесли все необходимые коррективы в файл robots.txt необходимо убедится в том, что все сделано верно. Для этого открываем файл robots.txt на вашем сайте.
Инструменты iqadВ арсенале команды IQAD есть набор бесплатных инструментов для SEO-оптимизаторов. Вы можете воспользоваться бесплатным сервисом просмотра файла robots.txt:
Проверить индексацию
СамостоятельноОткрыть самостоятельно, файл находится корне Вашего сайта, по адресу:
www.site.ru/robots.txt
Где www.site.ru – адрес Вашего сайта.
Бесплатный сервис Я.ВЕБМАСТЕР — анализ robots.txt.
Бесплатный сервис ЯНДЕКС.ВЕБМАСТЕР проверит ваш robots.txt, покажет какими секциями Вашего файла пользуется поисковая система Яндекс:
Так же, в сервисе можно проверить запрещена ли та или иная страница вашего сайта к индексации:
Достаточно в специальное поле внести интересующие Вас страницы и ниже отобразится результат.Альтернативные способы закрыть сайт от поисковых систем
Помимо классического способа с использованием файла robots.txt можно прибегнуть и к другим, не стандартным, подходам. Однако у них есть ряд недостатков.
- Вы можете отдавать поисковым роботам отличный от 200 код ответа сервера. Но это не гарантирует 100% исключения сайта из индекса. Какое-то время робот может хранить копию Ваших страниц и отдавать именно их.
- С помощью специального meta тега: <meta name=»robots»>
<meta name=»robots» content=»noindex, nofollow»>
Но
так как метатег размещается и его действие относиться только к 1 странице, то
для полного закрытия сайта от индексации Вам придется разместить такой тег на
каждой странице Вашего сайта.
Недостатком этого может быть несовершенство поисковых систем и проблемы с индексацией ресурса. Пока робот не переиндексирует весь сайт, а на это может потребоваться много времени, иногда несколько месяцев, часть страниц будет присутствовать в поиске.
- Использование технологий, усложняющих индексацию Вашего сайта. Вы можете спрятать контент Вашего сайта под AJAX или скриптами. Таким образом поисковая система не сможет увидеть контент сайта. При этом по названию сайта или по открытой части в индексе поисковиков может что-то хранится. Более того, уже завра новое обновление поисковых роботов может научится индексировать такой контент.
- Скрыть все данные Вашего сайта за регистрационной формой. При этом стартовая страница в любом случае будет доступна поисковым роботам.
Заключение
Самым простым способом закрыть сайт от индексации, во всех поисковых системах, необходимо в файле robots.txt прописать следующую директиву:
Disallow: /
«robots. txt» это служебный файл со специальными правилами для поисковых роботов.
txt» это служебный файл со специальными правилами для поисковых роботов.
Файл robots.txt всегда находится в корне Вашего сайта. Для изменения директив файла Вам потребуется любой FTP-клиент.
Помимо классического способа с использованием файла robots.txt можно прибегнуть и к другим, не стандартным, подходам. Однако у них есть ряд недостатков. Для проверки текущих директив Вашего сайта предлагаем воспользоваться бесплатным сервисом просмотра файла robots.txt:
Проверить индексацию
Отключить индексацию поисковой системой | Webflow University
Запретить поисковым системам индексировать страницы, папки, весь ваш сайт или только ваш субдомен webflow.io.
В этом видео используется старый интерфейс. Скоро выйдет обновленная версия!
В этом видео используется старый интерфейс. Скоро выйдет обновленная версия!
В этом видео используется старый интерфейс. Скоро выйдет обновленная версия!
Вы можете указать поисковым системам, какие страницы сканировать, а какие нет на вашем сайте, написав файл robots. txt файл. Вы можете запретить сканирование страниц, папок, всего вашего сайта. Или просто отключите индексацию своего поддомена webflow.io. Это полезно, чтобы скрыть такие страницы, как ваша страница 404, от индексации и включения в результаты поиска.
txt файл. Вы можете запретить сканирование страниц, папок, всего вашего сайта. Или просто отключите индексацию своего поддомена webflow.io. Это полезно, чтобы скрыть такие страницы, как ваша страница 404, от индексации и включения в результаты поиска.
В этом уроке
Отключение индексации субдомена Webflow
Вы можете запретить Google и другим поисковым системам индексировать субдомен webflow.io, просто отключив индексирование в настройках вашего проекта.
- Перейдите в Настройки проекта → SEO → Индексирование
- Установите Отключить индексирование субдоменов на «Да»
- Сохраните изменения и опубликуйте свой сайт
Уникальный robots.txt будет опубликовано только на поддомене, указав поисковым системам игнорировать домен.
Создание файла robots.txt
Файл robots.txt обычно используется для перечисления URL-адресов на сайте, которые вы не хотите, чтобы поисковые системы сканировали. Вы также можете включить карту сайта своего сайта в файл robots.txt, чтобы сообщить сканерам поисковых систем, какой контент они должны сканировать .
Вы также можете включить карту сайта своего сайта в файл robots.txt, чтобы сообщить сканерам поисковых систем, какой контент они должны сканировать .
Как и карта сайта, файл robots.txt находится в каталоге верхнего уровня вашего домена.Webflow сгенерирует файл /robots.txt для вашего сайта, как только вы заполните его в настройках своего проекта.
- Перейдите в Настройки проекта → SEO → Индексирование
- Добавьте нужные правила robots.txt (см. Ниже)
- Сохраните изменения и опубликуйте свой сайт
Robots.txt rules
Вы можете использовать любое из этих правил для заполнения роботов.txt файл.
- User-agent: * означает, что этот раздел применим ко всем роботам.
- Disallow: запрещает роботу посещать сайт, страницу или папку.

Чтобы скрыть весь ваш сайт
User-agent: *
Disallow: /
Чтобы скрыть отдельные страницы
User-agent: *
Disallow: / page-name
Чтобы скрыть всю папку страниц
User-agent: *
Disallow: / folder-name /
Чтобы включить карту сайта
Sitemap: https: // your-site.com / sitemap.xml
Полезные ресурсы
Ознакомьтесь с другими полезными правилами robots.txt
Необходимо знать
- Содержимое вашего сайта может быть проиндексировано, даже если оно не было просканировано. Это происходит, когда поисковая система знает о вашем контенте либо потому, что он был опубликован ранее, либо есть ссылка на этот контент в другом онлайн-контенте. Чтобы страница не проиндексировалась, не добавляйте ее в robots.txt. Вместо этого используйте метакод noindex.
- Кто угодно может получить доступ к robots вашего сайта.txt, чтобы они могли идентифицировать и получать доступ к вашему личному контенту.

Лучшие практики
Если вы не хотите, чтобы кто-либо мог найти определенную страницу или URL-адрес на вашем сайте, не используйте файл robots.txt, чтобы запретить сканирование URL-адреса. Вместо этого используйте любой из следующих вариантов:
Попробуйте Webflow — это бесплатно
В этом видео используется старый интерфейс. Скоро выйдет обновленная версия!
Robots.txt Введение и руководство | Центр поиска Google
Что такое роботы.txt файл?
Файл robots.txt сообщает сканерам поисковых систем, какие страницы или файлы он может или
не могу запросить с вашего сайта. Это используется в основном для того, чтобы не перегружать ваш сайт
Запросы; это не механизм для защиты веб-страницы от Google. Чтобы веб-страница не попала в Google, вы должны использовать директив noindex ,
или защитите свою страницу паролем.
Что такое роботы.txt используется для?
Файл robots.txt используется в основном для управления трафиком сканера на ваш сайт, а обычно для защиты страницы от Google, в зависимости от типа страницы:
| Тип страницы | Управление движением | Скрыть от Google | Описание |
|---|---|---|---|
| Интернет-страница | Для веб-страниц (HTML, PDF или другие форматы, не относящиеся к мультимедиа, которые может читать Google), файл robots.txt можно использовать для управления сканирующим трафиком, если вы считаете, что ваш сервер будет перегружен запросами от поискового робота Google, или чтобы избежать сканирования неважных или похожих страниц на вашем сайте. Вы не должны использовать файл robots.txt как средство, чтобы скрыть свои веб-страницы от результатов поиска Google. Если ваша веб-страница заблокирована файлом robots.txt , она все равно может отображаться в результатах поиска, но результат поиска не будет иметь описания и будет выглядеть примерно так. Файлы изображений, видеофайлы, PDF-файлы и другие файлы, отличные от HTML, будут исключены. Если вы видите этот результат поиска для своей страницы и хотите его исправить, удалите запись robots.txt, блокирующую страницу. Если вы хотите полностью скрыть страницу от поиска, воспользуйтесь другим методом. | ||
| Медиа-файл | Используйте robots.txt для управления трафиком сканирования, а также для предотвращения появления файлов изображений, видео и аудио в результатах поиска Google. | ||
| Файл ресурсов | Вы можете использовать файл robots.txt для блокировки файлов ресурсов, таких как неважные изображения, скрипты или файлы стилей, , если вы считаете, что страницы, загруженные без этих ресурсов, не пострадают от потери .Однако, если отсутствие этих ресурсов затрудняет понимание страницы поисковым роботом Google, вы не должны блокировать их, иначе Google не сможет хорошо проанализировать страницы, зависящие от этих ресурсов. |
 Это потому, что, если другие страницы указывают на вашу страницу с описательным текстом, ваша страница все равно может быть проиндексирована без посещения страницы. Если вы хотите заблокировать свою страницу из результатов поиска, используйте другой метод, например защиту паролем или директиву
Это потому, что, если другие страницы указывают на вашу страницу с описательным текстом, ваша страница все равно может быть проиндексирована без посещения страницы. Если вы хотите заблокировать свою страницу из результатов поиска, используйте другой метод, например защиту паролем или директиву 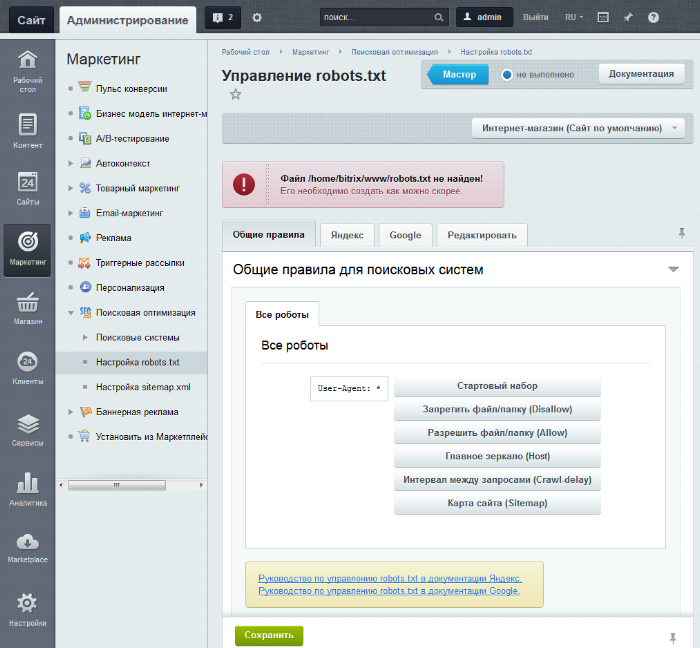 (Обратите внимание, что это не помешает другим страницам или пользователям ссылаться на ваш файл изображения / видео / аудио.)
(Обратите внимание, что это не помешает другим страницам или пользователям ссылаться на ваш файл изображения / видео / аудио.)Я пользуюсь услугами хостинга сайтов
Если вы используете службу хостинга веб-сайтов, такую как Wix, Drupal или Blogger, вам может не потребоваться (или у вас будет возможность) напрямую редактировать файл robots.txt. Вместо этого ваш провайдер может открыть страницу настроек поиска или какой-либо другой механизм, чтобы сообщить поисковым системам, сканировать ли вашу страницу или нет.
Чтобы узнать, просканировала ли ваша страница Google, найдите URL-адрес страницы в Google.
Если вы хотите скрыть (или показать) свою страницу от поисковых систем, добавьте (или удалите) любую страницу входа в систему. требования, которые могут существовать, и поиск инструкций по изменению вашей страницы видимость в поисковых системах на вашем хостинге, например: wix скрыть страницу от поисковых систем
Ознакомьтесь с ограничениями файла robots.txt
Прежде чем создавать или редактировать файл robots.txt, вы должны знать ограничения этого метода блокировки URL. Иногда вам может потребоваться рассмотреть другие механизмы, чтобы гарантировать, что ваши URL-адреса не будут найдены в Интернете.
- Директивы Robots.txt могут поддерживаться не всеми поисковыми системами.
Инструкции в файлах robots.txt не могут обеспечить поведение сканера на вашем сайте; гусеничный робот должен им подчиняться. В то время как робот Googlebot и другие известные поисковые роботы подчиняются инструкциям в файле robots.txt, другие поисковые роботы могут этого не делать.Поэтому, если вы хотите защитить информацию от веб-сканеров, лучше использовать другие методы блокировки, такие как защита паролем личных файлов на вашем сервере.
В то время как робот Googlebot и другие известные поисковые роботы подчиняются инструкциям в файле robots.txt, другие поисковые роботы могут этого не делать.Поэтому, если вы хотите защитить информацию от веб-сканеров, лучше использовать другие методы блокировки, такие как защита паролем личных файлов на вашем сервере. - Различные поисковые роботы по-разному интерпретируют синтаксис
Хотя уважаемые веб-сканеры следуют директивам в файле robots.txt, каждый поисковый робот может интерпретировать директивы по-разному. Вы должны знать правильный синтаксис для обращения к разным поисковым роботам, поскольку некоторые из них могут не понимать определенные инструкции. - Роботизированная страница все еще может быть проиндексирована, если на нее есть ссылки с других сайтов
Хотя Google не будет сканировать и индексировать контент, заблокированный файлом robots.txt, мы все равно можем найти и проиндексировать запрещенный URL, если на него есть ссылка с другого места в сети. В результате URL-адрес и, возможно, другая общедоступная информация, такая как текст привязки в ссылках на страницу, все еще может отображаться в результатах поиска Google. Чтобы правильно предотвратить появление вашего URL в результатах поиска Google, вы должны защитить паролем файлы на своем сервере или использовать метатег
В результате URL-адрес и, возможно, другая общедоступная информация, такая как текст привязки в ссылках на страницу, все еще может отображаться в результатах поиска Google. Чтобы правильно предотвратить появление вашего URL в результатах поиска Google, вы должны защитить паролем файлы на своем сервере или использовать метатег noindexили заголовок ответа (или полностью удалить страницу).
Тестирование страницы на наличие блоков robots.txt
Вы можете проверить, заблокирована ли страница или ресурс правилом robots.txt.
Для проверки директив noindex используйте инструмент проверки URL.
Правильный способ предотвращения индексации вашего сайта • Yoast
Йост де ВалкЙост де Валк — основатель и директор по продуктам Yoast.Он интернет-предприниматель, который незадолго до основания Yoast инвестировал и консультировал несколько стартапов. Его основная специализация — разработка программного обеспечения с открытым исходным кодом и цифровой маркетинг.
Мы уже говорили это когда-то, но мы повторим: нас удивляет, что до сих пор есть люди, использующие только файлов robots.txt и , чтобы предотвратить индексацию своего сайта в Google или Bing. В результате их сайт все равно появляется в поисковых системах. Вы знаете, почему это нас удивляет? Потому что robots.txt на самом деле не выполняет последнего, хотя и предотвращает индексацию вашего сайта. Позвольте мне объяснить, как это работает, в этом посте.
Чтобы узнать больше о robots.txt, прочтите robots.txt: полное руководство. Или найдите лучшие методы работы с robots.txt в WordPress.
Есть разница между индексированием и включением в Google
Прежде чем мы продолжим объяснять вещи, нам нужно сначала рассмотреть некоторые термины:
- Индексирование / индексирование
Процесс загрузки сайта или содержимого страницы на сервер поисковой системы, тем самым добавляя его в свой «индекс».” - Рейтинг / Листинг / Отображение
Отображение сайта на страницах результатов поиска (также известных как SERP).
Итак, хотя наиболее распространенный процесс идет от индексирования к листингу, сайт не обязательно должен быть проиндексирован , чтобы быть внесенным в список. Если ссылка указывает на страницу, домен или другое место, Google перейдет по этой ссылке. Если файл robots.txt в этом домене препятствует индексации этой страницы поисковой системой, он все равно будет показывать URL в результатах, если он может быть получен из других переменных, на которые, возможно, стоит обратить внимание.
Раньше это мог быть DMOZ или каталог Yahoo, но я могу представить, что Google использует, например, данные о вашем бизнесе в наши дни или старые данные из этих проектов. Больше сайтов резюмируют ваш сайт, верно.
Теперь, если приведенное выше объяснение не имеет смысла, взгляните на это видеообъяснение бывшего сотрудника Google Мэтта Каттса из 2009 г .:
Если у вас есть причины для предотвращения индексации вашего веб-сайта, добавление этого запроса на конкретную страницу, которую вы хотите заблокировать, как говорит Мэтт, по-прежнему является правильным способом.
Но вам нужно сообщить Google об этом метатеге robots. Итак, если вы хотите эффективно скрыть страницы от поисковых систем, вам нужно , чтобы проиндексировали этих страниц. Хотя это может показаться противоречивым. Это можно сделать двумя способами.
Предотвратить листинг вашей страницы, добавив метатег роботов
Первый способ предотвратить размещение вашей страницы в списке — использовать метатеги robots. У нас есть подробное руководство по метатегам роботов, которое более обширно, но в основном оно сводится к добавлению этого тега на вашу страницу:
Если вы используете Yoast SEO, это очень просто! Самостоятельно добавлять код не нужно.Узнайте, как добавить тег noindex с помощью Yoast SEO здесь.
Проблема с таким тегом в том, что его нужно добавлять на каждую страницу.
Управление метатегами роботов упрощено в Yoast SEO Чтобы упростить процесс добавления метатега robots на каждую страницу вашего сайта, поисковые системы разработали HTTP-заголовок X-Robots-Tag. Это позволяет вам указать HTTP-заголовок с именем X-Robots-Tag и установить значение так же, как и значение мета-тегов robots.Самое замечательное в этом то, что вы можете сделать это для всего сайта. Если ваш сайт работает на Apache и включен mod_headers (обычно это так), вы можете добавить следующую единственную строку в свой файл .htaccess :
Заголовочный набор X-Robots-Tag "noindex, nofollow"
И это приведет к тому, что весь сайт может быть проиндексирован . Но никогда не будет отображаться в результатах поиска.
Итак, избавьтесь от этого файла robots.txt с Disallow: / в it.Используйте вместо этого X-Robots-Tag или этот метатег robots!
Подробнее: Полное руководство по мета-тегу robots »
Файл Robots.txt [Примеры 2021] — Moz
Что такое файл robots.txt?
Robots.txt — это текстовый файл, который веб-мастера создают, чтобы проинструктировать веб-роботов (обычно роботов поисковых систем), как сканировать страницы на их веб-сайтах. Файл robots.txt является частью протокола исключения роботов (REP), группы веб-стандартов, которые регулируют, как роботы сканируют Интернет, получают доступ и индексируют контент, а также предоставляют этот контент пользователям.REP также включает в себя такие директивы, как мета-роботы, а также инструкции для страницы, подкаталога или сайта о том, как поисковые системы должны обрабатывать ссылки (например, «следовать» или «nofollow»).
На практике файлы robots.txt показывают, могут ли определенные пользовательские агенты (программное обеспечение для веб-сканирования) сканировать части веб-сайта. Эти инструкции сканирования определяются как «запрещающие» или «разрешающие» поведение определенных (или всех) пользовательских агентов.
Базовый формат:User-agent: [имя user-agent] Disallow: [URL-строка, которую нельзя сканировать]
Вместе эти две строки считаются полными robots.txt — хотя один файл robots может содержать несколько строк пользовательских агентов и директив (например, запрещает, разрешает, задержки сканирования и т. д.).
В файле robots.txt каждый набор директив пользовательского агента отображается как дискретный набор , разделенных разрывом строки:
В файле robots.txt с несколькими директивами пользовательского агента, каждая из которых запрещает или разрешает правило Только применяется к агентам-пользователям, указанным в этом конкретном наборе, разделенном разрывом строки. Если файл содержит правило, которое применяется более чем к одному пользовательскому агенту, поисковый робот будет только обратить внимание (и следовать директивам в) наиболее конкретной группе инструкций.
Вот пример:
Msnbot, discobot и Slurp вызываются специально, поэтому эти пользовательские агенты только обратят внимание на директивы в своих разделах файла robots.txt. Все остальные пользовательские агенты будут следовать директивам в группе user-agent: *.
Пример robots.txt:
Вот несколько примеров использования robots.txt для сайта www.example.com:
URL файла Robots.txt: www.example.com/robots.txt Блокировка всех поисковых роботов от всего контентаUser-agent: * Disallow: /
Использование этого синтаксиса в файле robots.txt укажет всем поисковым роботам не сканировать никакие страницы www.example .com, включая домашнюю страницу.
Разрешение всем поисковым роботам доступа ко всему контентуUser-agent: * Disallow:
Использование этого синтаксиса в файле robots.txt указывает поисковым роботам сканировать все страницы на www.example.com, включая домашнюю страницу.
Блокировка определенного поискового робота из определенной папкиUser-agent: Googlebot Disallow: / example-subfolder /
Этот синтаксис сообщает только поисковому роботу Google (имя пользователя-агента Googlebot) не сканировать страницы, которые содержать строку URL www.example.com/example-subfolder/.
Блокирование определенного поискового робота с определенной веб-страницыUser-agent: Bingbot Disallow: /example-subfolder/blocked-page.html
Этот синтаксис сообщает только поисковому роботу Bing (имя агента пользователя Bing) избегать сканирование конкретной страницы www.example.com/example-subfolder/blocked-page.html.
Как работает robots.txt?
Поисковые системы выполняют две основные задачи:
- Сканирование Интернета для обнаружения контента;
- Индексирование этого контента, чтобы его могли обслуживать искатели, ищущие информацию.
Чтобы сканировать сайты, поисковые системы переходят по ссылкам с одного сайта на другой — в конечном итоге просматривая многие миллиарды ссылок и веб-сайтов. Такое ползание иногда называют «пауками».”
После перехода на веб-сайт, но перед его сканированием поисковый робот будет искать файл robots.txt. Если он найдет его, сканер сначала прочитает этот файл, прежде чем продолжить просмотр страницы. Поскольку файл robots.txt содержит информацию о , как должна сканировать поисковая система, найденная там информация будет указывать дальнейшие действия сканера на этом конкретном сайте. Если файл robots.txt не содержит , а не содержат директив, запрещающих действия пользовательского агента (или если на сайте нет файла robots.txt), он продолжит сканирование другой информации на сайте.
Другой быстрый файл robots.txt, который необходимо знать:
(более подробно обсуждается ниже)
Чтобы его можно было найти, файл robots.txt должен быть помещен в каталог верхнего уровня веб-сайта.
Robots.txt чувствителен к регистру: файл должен называться «robots.txt» (не Robots.txt, robots.TXT и т. Д.).
Некоторые пользовательские агенты (роботы) могут игнорировать ваших роботов.txt файл. Это особенно характерно для более гнусных поисковых роботов, таких как вредоносные роботы или парсеры адресов электронной почты.
Файл /robots.txt является общедоступным: просто добавьте /robots.txt в конец любого корневого домена, чтобы увидеть директивы этого веб-сайта (если на этом сайте есть файл robots.txt!). Это означает, что любой может видеть, какие страницы вы хотите или не хотите сканировать, поэтому не используйте их для сокрытия личной информации пользователя.
Каждый субдомен в корневом домене использует отдельных роботов.txt файлы. Это означает, что и blog.example.com, и example.com должны иметь свои собственные файлы robots.txt (по адресу blog.example.com/robots.txt и example.com/robots.txt).
Обычно рекомендуется указывать расположение любых карт сайта, связанных с этим доменом, в нижней части файла robots.txt. Вот пример:
Технический синтаксис robots.txt
Синтаксис Robots.txt можно рассматривать как «язык» файлов robots.txt. Есть пять общих терминов, которые вы, вероятно, встретите в файле robots.К ним относятся:
User-agent: Конкретный поисковый робот, которому вы даете инструкции для сканирования (обычно это поисковая система). Список большинства пользовательских агентов можно найти здесь.
Disallow: Команда, используемая для указания агенту пользователя не сканировать определенный URL. Для каждого URL разрешена только одна строка «Disallow:».
Разрешить (применимо только для робота Googlebot): команда, сообщающая роботу Googlebot, что он может получить доступ к странице или подпапке, даже если его родительская страница или подпапка могут быть запрещены.
Crawl-delay: Сколько секунд сканер должен ждать перед загрузкой и сканированием содержимого страницы. Обратите внимание, что робот Googlebot не подтверждает эту команду, но скорость сканирования можно установить в консоли поиска Google.
Карта сайта: Используется для вызова местоположения любых XML-файлов Sitemap, связанных с этим URL. Обратите внимание, что эта команда поддерживается только Google, Ask, Bing и Yahoo.
Сопоставление с шаблоном
Когда дело доходит до фактических URL-адресов для блокировки или разрешения, robots.txt могут быть довольно сложными, поскольку они позволяют использовать сопоставление с шаблоном для охвата диапазона возможных вариантов URL. И Google, и Bing соблюдают два регулярных выражения, которые можно использовать для идентификации страниц или подпапок, которые SEO хочет исключить. Эти два символа — звездочка (*) и знак доллара ($).
- * — это подстановочный знак, который представляет любую последовательность символов.
- $ соответствует концу URL-адреса
. Google предлагает здесь большой список возможных синтаксисов и примеров сопоставления с образцом.
Где находится файл robots.txt на сайте?
Когда бы они ни заходили на сайт, поисковые системы и другие роботы, сканирующие Интернет (например, сканер Facebook Facebot), ищут файл robots.txt. Но они будут искать этот файл в только в одном конкретном месте : в основном каталоге (обычно это корневой домен или домашняя страница). Если пользовательский агент посещает www.example.com/robots.txt и не находит там файла роботов, он будет считать, что на сайте его нет, и продолжит сканирование всего на странице (и, возможно, даже на всем сайте. ).Даже если страница robots.txt и существует ли , скажем, по адресу example.com/index/robots.txt или www.example.com/homepage/robots.txt, она не будет обнаружена пользовательскими агентами и, следовательно, сайт будет обрабатываться так, как если бы в нем вообще не было файла robots.
Чтобы гарантировать, что ваш файл robots.txt найден, всегда включает его в ваш основной каталог или корневой домен.
Зачем нужен robots.txt?
Файлы Robots.txt управляют доступом поискового робота к определенным областям вашего сайта.Хотя это может быть очень опасно, если вы случайно запретите роботу Google сканировать весь ваш сайт (!!), в некоторых ситуациях файл robots.txt может оказаться очень полезным.
Вот некоторые распространенные варианты использования:
- Предотвращение появления дублированного контента в результатах поиска (обратите внимание, что мета-роботы часто являются лучшим выбором для этого)
- Сохранение конфиденциальности целых разделов веб-сайта (например, промежуточного сайта вашей группы инженеров)
- Предотвращение показа страниц результатов внутреннего поиска в общедоступной поисковой выдаче
- Указание местоположения карты (карт) сайта
- Предотвращение индексации определенных файлов на вашем веб-сайте поисковыми системами (изображений, PDF-файлов и т. Д.))
- Указание задержки сканирования для предотвращения перегрузки ваших серверов, когда сканеры загружают сразу несколько частей контента
Если на вашем сайте нет областей, к которым вы хотите контролировать доступ агента пользователя, вы не можете вообще нужен файл robots.txt.
Проверка наличия файла robots.txt
Не уверены, есть ли у вас файл robots.txt? Просто введите свой корневой домен, а затем добавьте /robots.txt в конец URL-адреса. Например, файл роботов Moz находится по адресу moz.ru / robots.txt.
Если страница .txt не отображается, значит, у вас нет (активной) страницы robots.txt.
Как создать файл robots.txt
Если вы обнаружили, что у вас нет файла robots.txt или вы хотите изменить свой, создание его — простой процесс. В этой статье от Google рассматривается процесс создания файла robots.txt, и этот инструмент позволяет вам проверить, правильно ли настроен ваш файл.
Хотите попрактиковаться в создании файлов роботов? В этом сообщении блога рассматриваются некоторые интерактивные примеры.
Рекомендации по поисковой оптимизации
Убедитесь, что вы не блокируете какой-либо контент или разделы своего веб-сайта, которые нужно просканировать.
Ссылки на страницах, заблокированных файлом robots.txt, переходить не будут. Это означает 1.) Если на них также не ссылаются другие страницы, доступные для поисковых систем (т. Е. Страницы, не заблокированные через robots.txt, мета-роботы или иным образом), связанные ресурсы не будут сканироваться и не могут быть проиндексированы. 2.) Никакой ссылочный капитал не может быть передан с заблокированной страницы на место назначения ссылки.Если у вас есть страницы, на которые вы хотите передать средства, используйте другой механизм блокировки, отличный от robots.txt.
Не используйте robots.txt для предотвращения появления конфиденциальных данных (например, личной информации пользователя) в результатах поисковой выдачи. Поскольку другие страницы могут напрямую ссылаться на страницу, содержащую личную информацию (таким образом, в обход директив robots.txt в вашем корневом домене или домашней странице), она все равно может быть проиндексирована. Если вы хотите заблокировать свою страницу из результатов поиска, используйте другой метод, например защиту паролем или метадирективу noindex.
Некоторые поисковые системы имеют несколько пользовательских агентов. Например, Google использует Googlebot для обычного поиска и Googlebot-Image для поиска изображений. Большинство пользовательских агентов из одной и той же поисковой системы следуют одним и тем же правилам, поэтому нет необходимости указывать директивы для каждого из нескольких сканеров поисковой системы, но такая возможность позволяет вам точно настроить способ сканирования содержания вашего сайта.
Поисковая система кэширует содержимое robots.txt, но обычно обновляет кэшированное содержимое не реже одного раза в день.Если вы изменили файл и хотите обновить его быстрее, чем это происходит, вы можете отправить свой URL-адрес robots.txt в Google.
Robots.txt vs meta robots vs x-robots
Так много роботов! В чем разница между этими тремя типами инструкций для роботов? Во-первых, robots.txt — это фактический текстовый файл, тогда как meta и x-robots — это метадирективы. Помимо того, чем они являются на самом деле, все три выполняют разные функции. Файл robots.txt определяет поведение сканирования сайта или всего каталога, тогда как мета и x-роботы могут определять поведение индексации на уровне отдельной страницы (или элемента страницы).
Продолжайте учиться
Приложите свои навыки к работе
Moz Pro может определить, блокирует ли ваш файл robots.txt доступ к вашему веб-сайту. Попробуйте >>
Как запретить поисковым системам индексировать страницу
Недавно я помог клиенту удалить старое видео YouTube со своего канала. Они не собирались делать его общедоступным и не осознавали этого, пока сами не искали в Google.
Хотя это не сразу деиндексирует страницу от Google, это заставило меня задуматься о причинах, по которым кто-то может захотеть запретить поисковым системам индексировать страницу до того, как будет нанесен какой-либо ущерб.
3 причины заблокировать Google от индексации страницы
Хотя есть очень мало неотложных причин, по которым вы можете захотеть узнать, как запретить Google индексировать страницу, вот некоторые из маркетинговых причин для этого.
1. Улучшение отслеживания и атрибуции целей
Для многих веб-мастеров и маркетологов цели заполнения форм отслеживаются посещениями страницы с благодарностью. Чтобы предотвратить случайное получение органического трафика на вашу страницу с благодарностью, вы захотите узнать, как запретить Google полностью проиндексировать эту страницу.
Если у вас есть целевой целевой трафик на вашей странице в дополнение к пользователям, заполнившим ваши формы, ваши цели и коэффициент конверсии не будут точными. ВНИМАНИЕ !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! »
2. Уменьшение количества страниц, не имеющих ценности для пользователя
Хотя это слишком упрощенная модель, вы можете почти представить, что ваш сайт имеет определенную ценность для SEO.
Для сайта с 10 страницами каждая страница получает примерно 1/10 SEO-ценности. Если владелец сайта научился проводить исследование ключевых слов и оптимизировал все свои страницы, все эти страницы будут эффективны и эффективны для генерирования органического трафика.
И наоборот, изобразите сайт со 100 страницами. Есть четыре страницы, которые на самом деле рассказывают об услугах компании, а остальные 96 страниц представляют собой «сообщения в блогах», которые на самом деле представляют собой всего лишь загрузку информации владельцем на свой сайт. Эти страницы не удовлетворяют известные потребности аудитории и не оптимизированы для каких-либо релевантных групп ключевых слов.
В нашей упрощенной модели ценность SEO невелика. Каждая из четырех страниц служб получает 1/100 совокупной SEO-ценности сайта, что делает их очень слабыми, даже несмотря на то, что они относительно оптимизированы.Остальные 96 страниц получают 96/100 стоимости, но это тупиковые пути, которые несут в себе ловушку и растрачивают рейтинговый потенциал вашего сайта.
Изучение того, как запретить поисковым системам индексировать страницу (или 96), — отличный способ не допустить слишком низкого распространения SEO-ценности вашего сайта. Вы можете скрыть большую часть своего веб-сайта от поисковых систем, чтобы Google знал только о полезных и релевантных страницах, которые заслуживают того, чтобы их нашли.
3. Избегайте проблем с дублированием контента
Публикация страницы, идентичной или почти идентичной другой странице в Интернете, может привести к принятию некоторых ненужных решений для Google.
Какая страница является оригинальной? Даже если одна из страниц была опубликована первой, является ли дублирующая страница, которая следовала за более авторитетным источником? Если на вашем веб-сайте есть обе страницы, какую из них вы хотели бы включить в результаты поиска Google? Результат может не всегда нравиться.
Чтобы избежать проблем с дублированием контента, вы можете попытаться запретить ботам сканировать определенные страницы вашего сайта.
Как запретить Google индексировать страницу
Самый простой и наиболее распространенный метод предотвращения индексации страницы поисковыми системами — это включить метатег noindex.
Включить тег Noindex
Метатег noindex используется между тегами HTML
на веб-странице, чтобы предотвратить включение этой страницы роботами поисковых систем в свой индекс. Это по-прежнему позволяет сканерам читать ваши страницы, но предполагает, что они не включают его копию для показа в результатах поиска.Тег noindex для предотвращения индексации страницы поисковыми системами выглядит следующим образом:
Если вас беспокоит только то, что Google не может проиндексировать страницу, вы можете используйте следующий код:
Если вы используете WordPress в качестве CMS (что я настоятельно рекомендую), то вы можете использовать плагин Yoast SEO (который Тоже очень рекомендую).С помощью пары щелчков мыши вы можете добавить тег noindex на любую страницу, которую захотите.
В бэкэнде любой страницы прокрутите вниз до поля Yoast SEO. Затем щелкните значок шестеренки и измените раскрывающееся поле с надписью «Разрешить поисковым системам показывать это сообщение в результатах поиска?» сказать «Нет»
Это не директива, поэтому поисковая система может игнорировать ваш метатег noindex. Для более надежной техники вы можете использовать файл robots.txt.
Запретить использование ботов в ваших роботах.txt
Если вы хотите быть уверены, что такие роботы, как Googlebot и Bingbot, вообще не могут сканировать ваши страницы, вы можете добавить директивы в свой файл robots.txt.
Robots.txt — это файл, находящийся в корне сервера Apache, который может вообще запретить некоторым ботам попадать на ваши страницы. Важно отметить, что некоторые боты могут быть проинструктированы игнорировать ваш файл robots.txt, поэтому вы действительно можете заблокировать только этих «хороших» ботов с помощью этой техники.
Давайте использовать страницу на вашем сайте https: // www.mysite.com/example-page/, например. Чтобы запретить всем ботам доступ к этой странице, вы должны использовать следующий код в своем robots.txt:
User-agent: * Disallow: / example-page /
Обратите внимание, что вам не нужно использовать полный URL-адрес, только URI, который идет после вашего доменного имени. Если вы хотите только заблокировать сканирование страницы роботом Googlebot, вы можете использовать следующий код:
User-agent: Googlebot Disallow: / example-page /
Запретить роботам сканировать ваш сайт с помощью.htaccess
Я лично не знаю ни одного клиента, которому когда-либо понадобилось бы это использовать, но вы можете использовать свой файл .htaccess, чтобы заблокировать сканирование вашего сайта любым пользовательским агентом.
Это способ полностью запретить Google сканирование вашего сайта, который не может быть проигнорирован даже «плохими» ботами. Предостережение заключается в том, что это более широкое решение, менее ориентированное на конкретную страницу. Управление целевым отказом в доступе к нескольким страницам внутри вашего файла .htaccess было бы кошмаром.
Код для блокировки только робота Google будет выглядеть так:
RewriteEngine On
RewriteCond% {HTTP_USER_AGENT} Googlebot [NC]
RewriteRule.. * (Googlebot | Bingbot | Baiduspider). * $ [NC]
RewriteRule. * - [F, L] Иногда необходимо научиться предотвращать индексирование одной из ваших страниц поисковой системой, и это не очень сложно, в зависимости от того, как вы это решите.
Если вам нужна дополнительная помощь с поисковой оптимизацией вашего бизнес-сайта, ознакомьтесь с контрольным списком запуска веб-сайта моей компании, MARION.
Блокировать страницы или сообщения блога от индексации поисковыми системами
Есть несколько способов запретить поисковым системам индексировать определенные страницы вашего сайта.Рекомендуется тщательно изучить каждый из этих методов, прежде чем вносить какие-либо изменения, чтобы гарантировать, что только нужные страницы заблокированы для поисковых систем.Обратите внимание: : эти инструкции блокируют индексирование URL страницы для поиска. Узнайте, как настроить URL-адрес файла в инструменте файлов, чтобы заблокировать его от поисковых систем.
Файл Robots.txt
Ваш файл robots.txt — это файл на вашем веб-сайте, который сканеры поисковых систем читают, чтобы узнать, какие страницы они должны и не должны индексировать.Узнайте, как настроить файл robots.txt в HubSpot.
Google и другие поисковые системы не могут задним числом удалять страницы из результатов после реализации метода файла robots.txt. Хотя это говорит ботам не сканировать страницу, поисковые системы все равно могут индексировать ваш контент (например, если на вашу страницу есть входящие ссылки с других веб-сайтов). Если ваша страница уже проиндексирована и вы хотите удалить ее из поисковых систем задним числом, рекомендуется вместо этого использовать метод метатега «Без индекса».
Мета-тег «Без индекса»
Обратите внимание: : , если вы решите использовать метод метатега «Без индекса», имейте в виду, что его не следует комбинировать с методом файла robots.txt. Поисковым системам необходимо начать сканирование страницы, чтобы увидеть метатег «Без индекса», а файл robots.txt полностью предотвращает сканирование.
Мета-тег «без индекса» — это строка кода, введенная в раздел заголовка HTML-кода страницы, который сообщает поисковым системам не индексировать страницу.
Консоль поиска Google
Если у вас есть учетная запись Google Search Console , вы можете отправить URL-адрес для удаления из результатов поиска Google. Обратите внимание, что это будет применяться только к результатам поиска Google. Если вы хотите заблокировать файлы в файловом менеджере HubSpot (например, документ PDF) от индексации поисковыми системами, вы должны выбрать подключенный субдомен для файла (ов) и использовать URL-адрес файла для блокировки веб-сканеров.
Как HubSpot обрабатывает запросы от пользовательского агента
Если вы устанавливаете строку пользовательского агента для проверки сканирования вашего веб-сайта и видите сообщение об отказе в доступе, это ожидаемое поведение. Google все еще сканирует и индексирует ваш сайт.
Причина, по которой вы видите это сообщение, заключается в том, что HubSpot разрешает запросы от пользовательского агента googlebot только с IP-адресов, принадлежащих Google. Чтобы защитить сайты, размещенные на HubSpot, от злоумышленников или спуферов, запросы с других IP-адресов будут отклонены.HubSpot делает это и для других сканеров поисковых систем, таких как BingBot, MSNBot и Baiduspider.
SEO Целевые страницы Блог Настройки аккаунта Страницы веб-сайта
Руководство для новичков по блокировке URL-адресов в роботах.txt файл | Ignite Visibility
Robots.txt, также известный как исключение роботов, является ключом к предотвращению сканирования роботами поисковых систем ограниченных областей вашего сайта.
В этой статье я расскажу об основах блокировки URL-адресов в robots.txt.
Что мы рассмотрим:
Что такое файл Robots.txt?
Robots.txt — это текстовый файл, который веб-мастера создают, чтобы научить роботов сканировать страницы веб-сайтов и позволяет сканерам узнать, обращаться к файлу или нет.
Вы можете заблокировать URL-адреса в robots txt, чтобы Google не индексировал личные фотографии, просроченные специальные предложения или другие страницы, к которым вы не готовы для пользователей. Использование его для блокировки URL-адреса может помочь в SEO.
Он может решить проблемы с дублированным контентом (однако могут быть более эффективные способы сделать это, о чем мы поговорим позже). Когда робот начинает сканирование, он сначала проверяет наличие файла robots.txt, который не позволяет им просматривать определенные страницы.
Когда следует использовать файл Robots.txt?
Вам нужно будет использовать его, если вы не хотите, чтобы поисковые системы индексировали определенные страницы или контент. Если вы хотите, чтобы поисковые системы (например, Google, Bing и Yahoo) получали доступ и индексировали весь ваш сайт, вам не нужен файл robots.txt. Хотя стоит упомянуть, что в некоторых случаях люди все же используют его, чтобы направлять пользователей на карту сайта.
Однако, если другие сайты ссылаются на страницы вашего сайта, заблокированные, поисковые системы могут по-прежнему индексировать URL-адреса, и в результате они по-прежнему могут отображаться в результатах поиска.Чтобы этого не произошло, используйте x-robots-tag , метатег noindex или относительный канонический к соответствующей странице.
Эти типы файлов помогают веб-сайтам со следующим:
- Сохранять конфиденциальность частей сайта — например, страницы администратора или изолированную программную среду вашей команды разработчиков.
- Предотвратить появление дублирующегося контента в результатах поиска.
- Избегайте проблем с индексацией
- Блокировка URL-адреса
- Запрещает поисковым системам индексировать определенные файлы, такие как изображения или PDF-файлы
- Управляйте трафиком сканирования и предотвращайте появление мультимедийных файлов в результатах поиска.
- Используйте его, если вы размещаете платные объявления или ссылки, требующие специальных инструкций для роботов.
Тем не менее, если на вашем сайте нет каких-либо областей, которые вам не нужно контролировать, то она вам и не нужна. В рекомендациях Google также упоминается, что вам не следует использовать robots.txt для блокировки веб-страниц из результатов поиска.
Причина в том, что если другие страницы ссылаются на ваш сайт с описательным текстом, ваша страница все равно может быть проиндексирована благодаря отображению на этом стороннем канале.Здесь лучше использовать директивы Noindex или защищенные паролем страницы.
Начало работы с Robots.txt
Прежде чем вы начнете собирать файл, убедитесь, что у вас его еще нет. Чтобы найти его, просто добавьте «/robots.txt» в конец любого доменного имени — www.examplesite.com/robots.txt. Если он у вас есть, вы увидите файл со списком инструкций. В противном случае вы увидите пустую страницу.
Затем проверьте, не блокируются ли какие-либо важные файлы.
Зайдите в консоль поиска Google, чтобы узнать, блокирует ли ваш файл какие-либо важные файлы.Тестер robots.txt покажет, не препятствует ли ваш файл поисковым роботам Google достичь определенных частей вашего веб-сайта.
Также стоит отметить, что вам может вообще не понадобиться файл robots.txt. Если у вас относительно простой веб-сайт, и вам не нужно блокировать определенные страницы для тестирования или для защиты конфиденциальной информации, вам ничего не нужно. И на этом учебник заканчивается.
Настройка файла Robots.Txt
Эти файлы можно использовать по-разному.Однако их главное преимущество заключается в том, что маркетологи могут разрешать или запрещать использование нескольких страниц одновременно, не обращаясь к коду каждой страницы вручную.
Все файлы robots.txt приведут к одному из следующих результатов:
- Полное разрешение — можно сканировать весь контент.
- Полное запрещение — сканирование контента невозможно. Это означает, что вы полностью блокируете доступ поисковых роботов Google к любой части вашего веб-сайта.
- Условное разрешение — правила, указанные в файле, определяют, какой контент открыт для сканирования, а какой заблокирован.Если вам интересно, как запретить использование URL-адреса, не заблокировав для поисковых роботов доступ ко всему сайту, то вот оно.
Если вы хотите создать файл, процесс на самом деле довольно прост и включает два элемента: «пользовательский агент», который представляет собой робота, к которому применяется следующий блок URL, и «запретить», который является URL, который вы хотите заблокировать. Эти две строки рассматриваются как одна запись в файле, что означает, что вы можете иметь несколько записей в одном файле.
Как заблокировать URL-адреса в роботах txt:
В строке «пользователь-агент» вы можете указать конкретного бота (например, Googlebot) или применить блокировку URL-адреса txt ко всем ботам с помощью звездочки.Ниже приведен пример того, как пользовательский агент блокирует всех ботов.
User-agent: *
Во второй строке записи, запретить, перечислены определенные страницы, которые вы хотите заблокировать. Чтобы заблокировать весь сайт, используйте косую черту. Для всех остальных записей сначала используйте косую черту, а затем укажите страницу, каталог, изображение или тип файла.
Disallow: / блокирует весь сайт.
Disallow: / bad-directory / блокирует как каталог, так и все его содержимое.
Disallow: /secret.html блокирует страницу.
После выбора пользовательского агента и запрета выбора одна из ваших записей может выглядеть так:
Пользовательский агент: *
Запретить: / bad-directory /
Просмотреть другие примеры записей из Google Search Console .
Как сохранить файл
- Сохраните файл, скопировав его в текстовый файл или блокнот и сохранив как «robots.текст».
- Обязательно сохраните файл в каталоге верхнего уровня вашего сайта и убедитесь, что он находится в корневом домене с именем, точно соответствующим «robots.txt».
- Добавьте файл в каталог верхнего уровня кода вашего веб-сайта для упрощения сканирования и индексации.
- Убедитесь, что ваш код имеет правильную структуру: User-agent → Disallow → Allow → Host → Sitemap. Это позволяет поисковым системам получать доступ к страницам в правильном порядке.
- Поместите все URL-адреса, для которых требуется «Разрешить:» или «Запретить:», в отдельной строке.Если несколько URL-адресов отображаются в одной строке, сканерам будет сложно разделить их, и у вас могут возникнуть проблемы.
- Всегда используйте строчные буквы для сохранения файла, так как имена файлов чувствительны к регистру и не содержат специальных символов.
- Создавать отдельные файлы для разных поддоменов. Например, «example.com» и «blog.example.com» имеют отдельные файлы со своим собственным набором директив.
- Если вы должны оставлять комментарии, начните с новой строки и поставьте перед комментарием символ #.Знак # позволяет сканерам знать, что эту информацию нельзя включать в свою директиву.
Как проверить свои результаты
Проверьте свои результаты в своей учетной записи Google Search Console, чтобы убедиться, что боты сканируют те части сайта, которые вам нужны, и блокируют URL-адреса, которые вы не хотите видеть поисковиками.
- Сначала откройте инструмент тестера и просмотрите свой файл на предмет предупреждений или ошибок.
- Затем введите URL-адрес страницы вашего веб-сайта в поле внизу страницы.
- Затем выберите user-agent , который вы хотите смоделировать, из раскрывающегося меню.
- Щелкните ТЕСТ.
- Кнопка ТЕСТ должна читать либо ПРИНЯТО или ЗАБЛОКИРОВАНО, , что укажет, заблокирован файл поисковыми роботами или нет.
- При необходимости отредактируйте файл и повторите попытку.
- Помните, любые изменения, которые вы вносите в тестере GSC, не будут сохранены на вашем веб-сайте (это симуляция).
- Если вы хотите сохранить изменения, скопируйте новый код на свой веб-сайт.
Имейте в виду, что это будет тестировать только Googlebot и другие пользовательские агенты, связанные с Google. Тем не менее, использование тестера имеет огромное значение, когда дело доходит до SEO. Видите ли, если вы все же решите использовать файл, вам обязательно нужно правильно его настроить.