
URL — Википедия
Единый указатель ресурса (от англ. Uniform Resource Locator — унифицированный указатель ресурса, сокр. URL [ˌjuː ɑːr ˈel]) — система унифицированных адресов электронных ресурсов, или единообразный определитель местонахождения ресурса (файла)[1].
Используется как стандарт записи ссылок на объекты в Интернет (Гипертекстовые ссылки во «всемирной паутине» www).
URL был изобретён Тимом Бернерсом-Ли в 1990 году в стенах Европейского совета по ядерным исследованиям (фр. Conseil Européen pour la Recherche Nucléaire, CERN) в Женеве, Швейцария. URL стал фундаментальной инновацией в Интернете. Изначально URL предназначался для обозначения мест расположения ресурсов (чаще всего файлов) во Всемирной паутине. Сейчас URL применяется для обозначения адресов почти всех ресурсов Интернета. Стандарт URL закреплён в документе RFC 3986. Сейчас URL позиционируется как часть более общей системы идентификации ресурсов URI, сам термин URL постепенно уступает место более широкому термину
В 2009 году Тим Бернерс-Ли высказал мнение об избыточности двойного слеша // в начале URL, после указания сетевого протокола[2].
Изначально локатор URL был разработан как система для максимально естественного указания на местонахождения ресурсов в сети. Локатор должен был быть легко расширяемым и использовать лишь ограниченный набор ASCII‐символов (к примеру, пробел никогда не применяется в URL). В связи с этим, возникла следующая традиционная форма записи URL:
<схема>:[//[<логин>[:<пароль>]@]<хост>[:<порт>]][/<URL‐путь>][?<параметры>][#<якорь>]
В этой записи:
- схема
- схема обращения к ресурсу; в большинстве случаев имеется в виду сетевой протокол
- логин
- имя пользователя, используемое для доступа к ресурсу
- пароль
- пароль указанного пользователя
- хост
- полностью прописанное доменное имя хоста в системе DNS или IP-адрес хоста в форме четырёх групп десятичных чисел, разделённых точками; числа — целые в интервале от 0 до 255.
- порт
- порт хоста для подключения
- URL-путь
- уточняющая информация о месте нахождения ресурса; зависит от протокола.
- параметры
- строка запроса с передаваемыми на сервер (методом GET) параметрами. Начинается с символа
?, разделитель параметров — знак&. Пример:?параметр_1=значение_1&параметр_2=значение_2&параметр3=значение_3 - якорь
- идентификатор «якоря» (англ.)русск. с предшествующим символом
#. Якорем может быть указан заголовок внутри документа или атрибут id (англ.)русск. элемента. По такой ссылке браузер откроет страницу и переместит окно к указанному элементу. Например, ссылка на этот раздел статьи:
Общепринятые схемы (протоколы) URL включают:
- ftp — Протокол передачи файлов FTP
- http — Протокол передачи гипертекста HTTP
- rtmp — Real Time Messaging Protocol проприетарный протокол потоковой передачи данных, в основном используется для передачи потокового видео и аудиопотоков с веб-камер через интернет.
- rtsp — Потоковый протокол реального времени.
- https — Специальная реализация протокола HTTP, использующая шифрование (как правило, SSL или TLS)
- gopher — Протокол Gopher
- mailto — Адрес электронной почты
- news — Новости Usenet
- nntp — Новости Usenet через протокол NNTP
- irc — Протокол IRC
- smb — Протокол SMB/CIFS
- prospero — Служба каталогов Prospero Directory Service
- telnet — Ссылка на интерактивную сессию Telnet
- wais — База данных системы WAIS
- xmpp — Протокол XMPP (часть Jabber)
- file — Имя локального файла
- data — Непосредственные данные (Data: URL)
- tel — звонок по указанному телефону
Экзотические схемы URL:
- afs — Глобальное имя файла в файловой системе Andrew File System
- cid — Идентификатор содержимого для частей MIME
- mid — Идентификатор сообщений для электронной почты
- mailserver — Доступ к данным с почтовых серверов
- nfs — Имя файла в сетевой файловой системе NFS
- tn3270 — Эмуляция интерактивной сессии Telnet 3270
- z39.50 — Доступ к службам ANSI Z39.50
- skype — Протокол Skype
- smsto — Открытие редактора SMS в некоторых мобильных телефонах
- ed2k — Файлообменная сеть eDonkey, построенная по принципу P2P
- market — Android Маркет
- steam — протокол Steam
- bitcoin — Криптовалюта Биткойн
- tg — Telegram
Схемы URL в браузерах:
Стандарт URL использует набор символов US-ASCII. Это имеет серьёзный недостаток, поскольку разрешается использовать лишь латинские буквы, цифры и несколько знаков пунктуации. Все другие символы необходимо перекодировать. Например, перекодироваться должны буквы кириллицы, буквы с диакритическими знаками, лигатуры, иероглифы. Перекодирующая кодировка описана в стандарте RFC 3986 и называется URL-encoding, URLencoded или percent‐encoding.
Пример кодирования можно видеть в русскоязычной Википедии, использующей в URL русский язык. Например, строка вида:
https://ru.wikipedia.org/wiki/Википедия
кодируется как:
https://ru.wikipedia.org/wiki/%D0%92%D0%B8%D0%BA%D0%B8%D0%BF%D0%B5%D0%B4%D0%B8%D1%8F
Реализация[править | править код]
Преобразование происходит в два этапа: сначала каждый символ кириллицы кодируется в UTF-8 в последовательность из двух байтов, а затем каждый байт этой последовательности записывается в шестнадцатеричном представлении с предшествующим знаком процента (%):
В → D0 и 92 → %D0%92 и → D0 и B8 → %D0%B8 к → D0 и BA → %D0%BA и → D0 и B8 → %D0%B8, и т. д.
Все другие символы в URI кодируются.
Зарезервированные символы кодируются в таком соответствии:
| ! | » | #[5] | $ | % | &[5] | ‘ | * | + | ,[5] | :[5] | ;[5] | < | =[5] | > | ?[5] | [ | ] | ^ | ` | { | | | } | <пробел> |
| %21 | %22 | %23 | %24 | %25 | %26 | %27 | %2A | %2B | %2C | %3A | %3B | %3C | %3D | %3E | %3F | %5B | %5D | %5E | %60 | %7B | %7C | %7D | %20[6] |
Кодирование параметров в Internet Explorer и старом Firefox происходит несколько иначе[7].
В некоторых случаях URL формируется с использованием кодирования Base58[8].
Стандарт IRI[править | править код]
Поскольку такому преобразованию подвергаются буквы всех алфавитов, кроме базовой латиницы, то URL со словами подавляющего большинства языков может стать нечитаемым для человека.
Это всё входит в противоречие с принципом интернационализма, провозглашаемого всеми ведущими организациями Интернета, включая W3C и ISOC. Эту проблему призван решить стандарт IRI (англ. Internationalized Resource Identifier) — международных идентификаторов ресурсов, в которых можно было бы без проблем использовать символы Юникода, и которые поэтому не ущемляли бы права других языков. Хотя заранее сложно сказать, смогут ли когда‐либо идентификаторы IRI заменить столь широко используемые URL (и URI в целом).
Формально, длина URL не ограничена, но браузеры имеют ограничения по длине URL. Не рекомендуется использовать URL длиной более 2048 символов, так как Microsoft Internet Explorer имеет именно такое ограничение[9].
Ещё один кардинальный недостаток URL состоит в отсутствии гибкости. Ресурсы во Всемирной паутине и Интернете перемещаются, а ссылки в виде URL остаются, указывая на уже отсутствующие ресурсы. Это особенно болезненно для электронных библиотек, каталогов и энциклопедий. Для решения этой проблемы были предложены постоянные локаторы PURL (англ. Persistent Uniform Resource Locator). В сущности это те же URL, но они указывают не на конкретное место расположения ресурса, а на запись в базе данных PURL, где, в свою очередь, записан уже конкретный URL‐адрес ресурса. При обращении к PURL сервер находит нужную запись в этой базе данных и перенаправляет запрос уже на конкретное местоположение ресурса. Если адрес ресурса меняется, то нет нужды исправлять все бесчисленные ссылки на него — достаточно лишь изменить запись в БД. В настоящий момент эта идея не стандартизирована и не имеет широкого распространения.
структура и значение для SEO [инфографика]
Что такое URL
URL (или URL адрес) – это форма уникального адреса конкретного веб-ресурса в сети Интернет. Он может ссылаться на веб-сайт, какой-то индивидуальный документ или изображение. Пользователю Интернета нужно вставить этот код в поле поиска, чтобы найти нужный сайт, документ, папку или изображение. На простом языке это означает следующее: благодаря URL адресу пользователь узнает информацию о том, где находятся нужные ему данные.
URL адрес – это аббревиатура, обозначающая термин Universal Resource Locator (всеобщий указатель ресурса). Он содержит ссылку на сервер, который является хранилищем искомого ресурса. В общем, URL это путь с сервера к последнему устройству (которое является платформой работы пользователя). Верхний элемент – это сервер хранения ресурсов, самый низкий – пользовательское устройство. Все точки между этими двумя являются дополнительными серверами.
Найдите проблемные URL
Проведите аудит вашего сайт и получите полный список страниц, где URL больше 100 символов
Структура URL адреса
URL адрес имеет определенную структуру, которая включает:
- метод доступа к ресурсу, который также называется сетевым протоколом;
- авторизацию доступа;
- хосты – DNS адрес, который указан как IP адрес;
- порт – еще одна обязательная деталь, которая включается в сочетание с IP адресом;
- трек – определяет информацию о методе получения доступа;
- параметр – внутренние данные ресурса о файле.
Как скопировать URL
Некоторые пользователи сталкиваются с проблемами при попытке определить URL адрес той страницы, на которой они находятся или файла, который хотят скачать. Самый простой метод узнать его – просмотреть и скопировать адрес прямо из адресной строки. Выделите его и скопируйте, нажав CTRL + C. Или в контекстном меню выберите «Копировать».
URL адрес имеют не только ресурсы сайта, но также его изображения, файлы и папки. Чтобы получить данные об их URL адресах, вы должны нажать правую кнопку мыши на интересующее вас изображение и выбрать в контекстном меню параметр «Копировать URL изображения».
Если вы желаете узнать URL адрес документа, выполните те же действия, что и при выборе изображения в контекстном меню, но на этот раз воспользуйтесь опцией «Скопировать адрес ссылки».
Скопировав ссылку, вы переносите её в буфер обмена. Также вы можете вставлять её в новую адресную строку, чтобы найти нужный документ, отправить ссылку, прикрепив её к сообщению, или вставить её в существующий текст в своем документе.
Примеры URL адресов
Основная часть URL адреса – это доменное имя веб-сайта. Чтобы выбрать правильный адрес для эффективного продвижения сайта в поисковой выдаче, следуйте такому правилу. Идеальный адрес страницы сайта должен быть коротким и релевантным запросу пользователя.
Такой идеальный адрес еще называется человекопонятным URL (ЧПУ, семантический URL). Ниже показаны примеры URL который понятен пользователям и URL который не несет никакой информации ни для пользователя, ни для поисковых систем.
Человекопонятный URL (ЧПУ)
Основная ценность ЧПУ состоит в том, что он помогает пользователю:
- Понять содержание страницы еще до ее загрузки.
- Запоминать ценные страницы и легко к ним возвращаться;
- Быстрее перемещаться по сайтам;
- Удобнее делится ссылкой с другими людьми.
Шифрование URL
Часто, скопировав адрес некоторого русскоязычного ресурса, пользователи остаются озадачены тем, что они видят. Набор символов, который они видят, очень сложно идентифицировать. Он совсем не похож на адрес, который находится в адресной строке. Причина в том, что адресные надписи могут быть сформированы только с помощью символов предлагаемого списка. Кириллический алфавит не входит в такой список. Если адрес включает кириллические символы, он будет зашифрован, хотя содержание ссылки и не изменится.
История URL адреса
Как и любое другое понятие, URL имеет собственную историю. Сегодня его основная функция – указать конечный сервер, на котором хранится информация. Созданный в 1990 году известным британским изобретателем Тимоти Джоном, первый URL был представлен в Женеве. Раньше он использовался для определения местоположения конечных веб-документов в Интернете. Но разработчики пришли к мысли, что URL адрес может предоставлять пользователям доступ и к другим ресурсам.
URL: что это и как формируется адрес сайта, динамический идентификатор URL
Москва г. Москва, ул. Нобеля 7, п. 56 +7 (800) 700-59-30

У пользователей нередко возникают вопросы, что такое URL-адрес файла (сайта), как узнать его и в чем ценность такого реквизита. Наша статья даст необходимые ответы.
Что такое URL
Uniform Resource Locator расшифровывается как «указатель местонахождения сайта в Сети». URL-идентификатор состоит из доменного имени и пути к определённой странице с названием её файла. Изобретателем URL-адреса был член Европейского совета по ядерно-военным проблемам, заседающего в Женеве, Тим Бернерс-Ли. На момент своего создания в 1990 году URL сайта – это просто адрес в системе, по которому находится файл. Чтобы узнать URL сайта, достаточно заглянуть в адресную строку, а для определения адреса файла необходимо перейти в контекстное меню, нажав на соответствующем объекте правую кнопку мыши. Обладая множеством преимуществ, в частности доступностью навигации в Сети, такой адрес имеет и недостаток – способность работать исключительно с латиницей, некоторыми символами и цифрами. При необходимости использования кириллицы проводится специальная перекодировка.
Разновидности URL
-
Статический – не предполагает изменений на странице.
-
Динамический URL – что это, можно понять, если представить поисковую форму или другой навигационный инструмент, в котором информация генерируется в зависимости от поступающих запросов.
-
Адрес с идентификатором сессий, который добавляется каждый раз, когда пользователи посещают страницу.
Значение URL в SEO-продвижении
-
Поисковики учитывают ключи, входящие в URL. Больше всего влияют на поисковое продвижение ключевые слова в домене и поддоменах.
-
Если адрес сайта информативен, это также повышает рейтинг. Поисковый робот с большой вероятностью выдаст его в ответ на тематический запрос.
-
URL, который соответствует запросу, выделяется в поисковой выдаче жирным шрифтом, привлекая дополнительное внимание и повышая кликабельность.
что это такое, как его узнать, правильно оптимизировать при написании
Есть проблемы с ранжированием, проект не растет, хотите проверить работу своих специалистов по продвижению? Закажите профессиональный аудит в Семантике

Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
![]()
URL страницы (Universal Resource Locator) — это адрес файла в интернете, по которому к нему может обратиться пользователь, у которого есть нужные права доступа.
Для ответа на вопрос “Что такое URL и где его взять”, представьте, что все сайты интернета находятся в огромном городе, где каждый ресурс обладает собственным домом. Папки внутри сайта — квартиры в доме, а файлы — их жители. Учитывая масштабы интернета, город будет иметь невообразимое количество кварталов и улиц.
Вы нашли среди этого многообразия то, что давно искали. В одном из домов в определенной квартире находится красивая картинка с котятами. Возникает вопрос, как сообщить другу максимально коротко и понятно, куда ему нужно идти, чтобы найти это замечательное изображение.
Пожалуй, будет лучшим решением, если оба придумают стандарт, по которому именуются адреса среди мегаполиса. Так мы получим краткую, лаконичную и простую запись координат местоположения объекта. Для удобства, разместим все в иерархическом порядке: квартал, улица, дом, а затем квартира.
Точно так же работает URL. В адресном пространстве с помощью URL выражаются уникальные координаты файлов среди огромной сети интернет. Существуют определенные правила написания и формирования ссылок, это сделано для предотвращения разночтений и единого формата адресации.
Структура URL
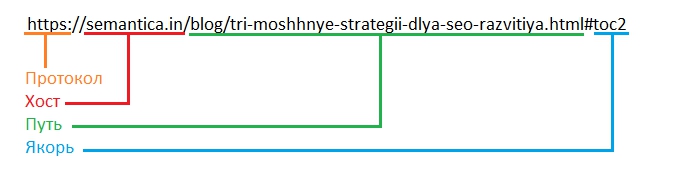
Чтобы понять, как правильно писать URL, рассмотрим правила его формирования. Шаблон ссылки выглядит следующим образом
<протокол>://<логин>:<пароль>@<хост>:<порт>/<путь>?<параметры запроса>#<якорь>
- <протокол> — выражает способ подключения к ресурсу. Это может быть привычный HTTP, защищенный TLS — HTTPS, протокол передачи файлов FTP и прочие способы соединения с хостом.
- <логин>:<пароль> — этой парой в случае необходимости передаются авторизационные данные для некоторых протоколов, например FTP.
- <хост> — в идеале, IP-адрес конечного сервера. В реальной жизни, благодаря использованию DNS-серверов необходимости писать цифровые обозначения отпадает. Мы пишем буквенный адрес сайта с указанием его доменной зоны. (например semantica.in).
- <порт> — порт подключения к серверу ресурса, по умолчанию принимает заранее определенные значения системы (для HTML, например, 80 порт).
- <путь> — путь к необходимому файлу, формируется по образцу путей в файловой системе компьютера. Через слэш перечисляются в иерархическом порядке папки, описание заканчивается названием и расширением целевого файла (здесь указываются папки (разделы) в которых лежит нужный файл и его имя).
- <параметры> — параметры, передающиеся на управляющие скрипты сервера. В случае HTML мы можем читать переданные параметры, как данные метода GET.
- <якорь> — опциональная строка для HTTP/HTTPS протоколов. Используется для обозначения определённой области на странице и работы некоторых JavaScript скриптов (например так удобно ссылаться на какой-то пункт статьи из ее содержания).
Как узнать URL адрес
Сделать это можно несколькими способами:
- Открытый в браузере сайт
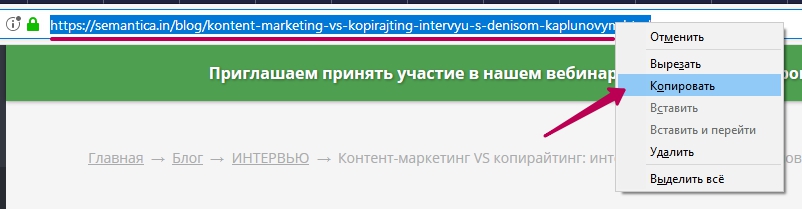
— Посмотрите на верхнюю часть окна браузера — найдите адресную строку.
— Выделите её содержание при помощи курсора.
— Скопируйте с помощью сочетания клавиш Ctrl+C.
— Адрес на сайт теперь содержится в буфере обмена.
- Изображение на сайте

— Нажмите правой кнопкой мыши на изображение.
— В выпадающем меню выберите “Копировать ссылку на изображение”.
— Адрес картинки теперь содержится в Вашем буфере обмена.
- Гиперссылка на ресурс
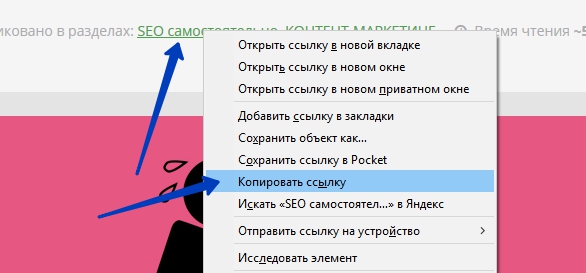
— Нажмите правой кнопкой мыши на ссылку.
— В выпадающем меню выберите “Копировать ссылку”.
— Ссылка на объект появится в буфере обмена.
Шифрование в URL
URL может содержать в себе только символы из определённого набора. Использование посторонних, таких например, как кириллица, допустимо, но в результате это будет искажать ссылку в некоторых браузерах.
Обработка URL происходит в следующем порядке:
- Если ссылка состоит только из допустимых символов, латиницы, цифр, букв, дефисов и нижних подчеркиваний — все кодируется в Юникод и формируется адрес.
- Если в ссылке есть посторонние символы, после кодирования в Юникод, двухбайтовые последовательности преобразуется в шестнадцатеричный код, разделённый знаком процента.
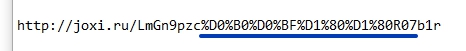
Наглядно видеть “шифрование” правильного URL можно было в старых браузерах. Современные обозреватели выводят на экран все символы в читаемом виде, используя кодирование только для внутреннего обмена. Но проблемы возникают теперь при копировании такого адреса из строки браузера в какой-либо текстовый редактор, который не умеет преобразовывать код. Отослать другу красивую и понятную ссылку не получится.
Сокращенные URL
Вы часто встречаете очень короткие, однотипные, ничего не значащие ссылки, ведущие вас на совершенно другие сайты. Такой подход называется сокращение URL.
Для этих целей используются специальные сервисы. Удобно, если нужно предоставить короткий адрес вашего ресурса и собрать статистику кликов именно по сокращенному URL. Сервис переадресует пользователей по заданному URL, выступая в роли посредника с коротким именем.
Рассмотрим сервис Goo.gl — самый стабильный и надежный сократитель ссылок от компании Google с отличными аналитическими инструментами.
Достаточно ввести адрес своего сайта — goo.gl автоматически выдаст короткую ссылку.
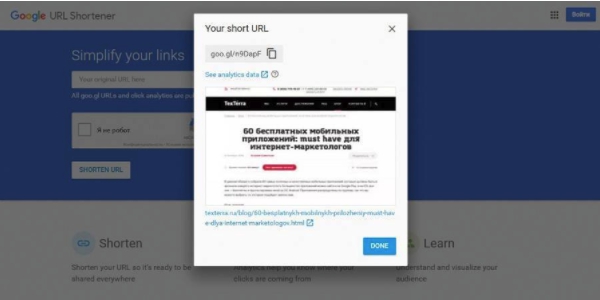
В аналитическом блоке можно будет просматривать
- Браузеры и платформы, откуда были переходы на ссылку.
- Географическое ранжирование.
- Число посетителей и упоминаний URL в интернете.
Оптимизация URL
Немаловажным является оптимизация URL-адресов средствами конфигурации сервера.
Настройте свой веб-узел для так называемых ЧПУ ссылок: удобных и красивых внутренних ссылок, отражающих структуру сайта в понятном виде.
Если вы пользуетесь CMS, то модуль SEO-ссылок скорее всего там есть. Если проект самописный, то нужно реализовать ЧПУ-шлюз вручную. Чаще всего это делается с помощью связки .htaccess mod_rewrite rules + PHP.
- Вписывайте ключевые фразы в URL транслитом. Возьмите главное ключевое слово страницы, транслируйте в латиницу и используйте как URL для достижения максимальной SEO-оптимизации.
- Старайтесь не передавать GET параметры, если от них зависит отдача статики. Лучше настроить сервер так, чтобы выдаваемое содержание обрабатывалось ЧПУ-шлюзом по понятному названию из адресной строки, а не через GET-данные.
- Разделяйте слова дефисом. Не плюсом\минусом, нижним подчеркиванием, а именно дефисом. Это официальная рекомендации поискового гиганта Google.
- Несмотря на важность иерархии, не перебарщивайте с вложенными папками на сайте. Если возможно, все статьи адресуйте в корневой директории. Уходить ниже третьего уровня директории от корня сайта — плохой тон.
- Не используйте комбинации строчных и заглавных букв, всегда делайте ссылки строчными. Иначе есть вероятность появления в поиске дублей.
- Все дубли блокируйте средствами robots.txt.
- Используйте канонические URL для страниц, где есть вероятность дублирования одинакового содержания.
Оптимизированная SEO-ссылка: http://localhost.ru/zakaz-uslugi-vds
Неоптимизированная: http://localhost.ru/itemid5453?type=vds
Мой URL — это не ваш URL / Habr
Когда давным-давно в 1996 году я приступил к работе над программой httpget, предшественницей проекта Curl, я написал свой первый синтаксический анализатор URL. Как раз тогда этот универсальный адрес получил название URL: Uniform Resource Locator (единый указатель ресурсов). Его спецификация была опубликована IETF в 1994 году. Аббревиатура «URL» была затем использована как источник вдохновения для названия инструмента и проекта Curl.
Термин «URL» был позднее изменён; его стали называть URI (Uniform Resource Identifier — единый идентификатор ресурсов), согласно спецификации, опубликованной в 2005 году, однако основное сохранилось: синтаксис для строки, задающей онлайн-ресурс и указывающей протокол для получения этого ресурса. Мы требуем, чтобы curl принимал указатели URL, как определено данной спецификацией RFC 3986. Ниже я расскажу, почему на самом деле это не совсем так.
Был ещё родственный RFC, описывающий IRI: Internationalized Resource Identifier (международный идентификатор ресурсов). IRI, по существу, то же самое, что URI, но IRI позволяют использовать символы, не входящие в ASCII.
Консорциум WHATWG позднее создал свою собственную спецификацию URL, в основном, сведя вместе форматы и идеи от URI и IRI с сильным упором на браузеры (что неудивительно). Одна из объявленных ими целей — «Модернизировать RFC 3986 и RFC 3987 в соответствии с современными реализациями и постепенно вывести их из употребления». Они хотят вернуться к использованию термина «URL», справедливо заявляя, что термины URI и IRI просто запутывают ситуацию и что люди так и не поняли их (или часто даже не знают, что эти термины существуют).
Спецификация WHATWG написана в духе старой доброй мантры браузеров: быть как можно более либеральными с пользователями, всегда пытаться угадать, что они имеют в виду, и выворачиваться наизнанку, пытаясь сделать это. Хотя при этом мы все знаем сейчас, что закон Постеля — не самый лучший подход к делу. На деле это значит, что спецификация позволяет использовать в URL слишком много слэшей, пробелы и символы, не входящие в ASCII.
С моей точки зрения, такую спецификацию также очень трудно читать и соблюдать, поскольку она не очень подробно описывает синтаксис или формат, но при этом навязывает обязательный алгоритм парсинга. Чтобы проверить моё утверждение: посмотрите, что это спецификация говорит о концевой точке после имени хоста в URL.
Вдобавок ко всем этим стандартам и спецификациям, в интерфейсе всех браузеров есть адресная строка (которую часто называют и по-другому), которая позволяет пользователям вводить какие угодно забавные строки и преобразовывает их в URL. Если ввести «http://localhost/%41» в адресную строку, то участок с процентом будет преобразован в «A» (поскольку 41 в шестнадцатеричном исчислении является заглавной буквой A в ASCII), но если ввести «http://localhost/A A«, то фактически в исходящий HTTP-запрос GET будет отправлено «/A%20A» (с пробелом в URL-кодировке). Я говорю об этом, так как люди часто думают, что всё, что можно ввести в эту строку — и есть URL.
Указанное выше — в основном моё (искаженное) представление, с какими спецификациями и стандартами нам пока приходится работать. Теперь давайте добавим реальности и посмотрим, какие проблемы мы получаем, когда мой URL — это не ваш URL.
Так что же такое URL?
Или более конкретно — как мы пишем их? Какой синтаксис используем?
Думаю, одна из самых больших ошибок в спецификации WHATWG (и в ней причина, почему я выступаю против этой спецификации в её текущей форме с твёрдым убеждением, что они неправы) состоит в том, что они полагают, будто только им позволено работать с URL и давать им определение; они ограничивают свое представление об URL исключительно браузерами, HTML и адресными строками. Конечно, WHATWG создан большими компаниями, представляющими браузеры, которые использует почти каждый, а в этих браузерах широко работают указатели URL, но сами URL — явление значительно большее.
Представление об URL, существующее у WHATWG, не слишком широко принимается за пределами браузеров.
Двоеточие-слэш-слэш
Если спросить пользователей — обычных людей без какого-либо особого знания протоколов или сети — о том, что такое URL, то что они ответят? Последовательность «://» (двоеточие-слэш-слэш) была бы в начале списка ответов; несколько лет назад, когда браузеры показывали URL более полно, это было бы еще заметнее. Увидев эту последовательность, мы сразу понимаем, что перед нами именно URL.
Однако давайте отойдём от пользователей и оглядимся — в мире существуют почтовые клиенты, эмуляторы терминалов, текстовые редакторы, Perl-скрипты и многое-многое другое, что способно распознавать URL и работать с ними. Например, открыть URL в браузере, превратить в активную ссылку в сгенерированном HTML и так далее. Огромное количество названных скриптов и программ будет использовать именно последовательность «двоеточие-слэш-слэш» как главный признак.
Спецификация WHATWG говорит, что должен быть как минимум один слэш и что парсер при этом обязан принимать какое угодно количество слэшей. Это значит, что «http:/example.com» и «http:///////////////example.com» — полностью подходящие варианты. RFC 3986 и многие другие с этим не согласны. Ну, действительно, большинство из людей, с которыми я спорил последние несколько дней, даже те, кто работает в вебе, говорит, думает и убеждено, что URL имеет два слэша. Просто посмотрите внимательнее на скриншот результата поиска картинок в Гугл по запросу «URL» выше в этой статье.
Мы просто знаем, что у URL есть два слэша (хотя, да, URL типа file: обычно имеют три слэша, но давайте пока проигнорируем это). Не один. Не три. Два. Но WHATWG с этим не согласен.
«Есть хоть одна настоящая причина принимать более двух слэшей для не-файловых URL?» (спрашиваю я раздраженно у членов WHATWG)
«Факт в том, что это делают все браузеры.»
Спецификация говорит это, потому что браузеры реализовали её именно так.
Никакое лучшее объяснение не было дано даже после того, как я указал, что это утверждение неправильное и далеко не все браузеры делают так. Возможно, эта ветка обсуждения покажется вам весьма познавательной.
В проекте Curl мы как раз недавно начали обсуждать, как обращаться с указателями URL, имеющими число слэшей, отличное от двух, потому что, оказывается, уже есть серверы, передающие обратно такие URL в заголовке “Location:”, и некоторые браузеры без возражений принимают их. Curl — нет, так же как и большинство из множества других библиотек и инструментов командной строки. Кого нам поддержать?
Пробелы
Символ пробела (код 32 в ASCII, шестнадцатеричный код 0x20) не может быть частью URL. Если требуется отправить его, то следует использовать URL-кодировку, как это делают с любым другим недопустимым символом, который надо сделать частью URL. URL-кодировка — это байтовое значение в шестнадцатеричном исчислении со знаком процента перед ним. Таким образом, «%20» означает пробел. Это также означает, что синтаксический анализатор, например, сканирующий текст на предмет указателей URL, узнаёт, что достиг конца URL, когда он обнаруживает недопустимый символ. Например, пробел.
Браузеры обычно преобразовывают все %20 в своих адресных строках в символ пробела, чтобы ссылки выглядели прилично. При копировании адреса в буфер и вставке его в текстовый редактор мы видим пробелы как %20, что и требуется.
Я не уверен, в этом ли причина, но браузеры также принимают пробелы как часть URL, получая, например, переадресацию в HTTP-ответе. Такие URL передаются от сервера к клиенту в заголовке «Location:». Браузеры без проблем допускают пробелы в них URL, кодируя их в виде %20 и отправляя следующий запрос. Это заставляет curl принимать пробелы в перенаправляемых «URL».
Не-ASCII
Поддержка в URL языков, включающих символы, не входящие в ASCII, конечно, важно, особенно для незападных сообществ, и я согласен, что спецификация IRI никогда не была достаточно хороша. Я лично далёко не эксперт в интернационализации, поэтому я руководствуюсь тем, что слышал от других. Но, конечно, пользователи нелатинских алфавитов и систем печати должны иметь возможность записывать свои «интернет-адреса» в ресурсы и использовать их как ссылки.
В идеальном случае у нас была бы интернационализированная версия для показа пользователю, и версия в кодировке ASCII для внутреннего использования в сетевых запросах.
Для международных доменных имён имя преобразуется в кодировку punycode так, чтобы оно могло быть прочитано обычными серверами DNS, которые ничего не знают об именах в кодировке, отличной от ASCII. Идентификаторы URI не имеют IDN-имён; IRI и URL по версии WHATWG — имеют. Сurl поддерживает IDN-имена хостов.
WHATWG заявляет, что URL могут использовать UTF-8, тогда как URI — только ASCII. Curl не воспринимает не-ASCII-символы в части адреса, задающей путь, но кодирует их процентом в исходящих запросах; это порождает “интересные» побочные эффекты, когда не-ASCII-символы представлены в коде, отличном от UTF-8, что является, например, стандартным для Windows.
Подобно тому, что я написал выше, это приводит к серверам, отправляющим назад не-ASCII-коды в HTTP-заголовках, которые браузеры охотно принимают, и не-браузерам тоже приходится работать с ними.
Стандарта URL не существует
Я не пытался представить полный список проблем или несоответствий — здесь просто некоторая подборка трудностей, с которыми я недавно столкнулся. «URL», выданный в одном месте, конечно, совсем необязательно будет принят или понят в другом месте как «URL».
В наши дни даже curl уже не следует строго ни одной опубликованной спецификации — мы медленно деградируем в угоду “веб-совместимости”.
Единый стандарт URL отсутствует, и какая-либо работа в этом направлении не ведётся. Я не могу считать, что WHATWG прилагает настоящие усилия к этому, поскольку она пишет спецификацию закрытой группой без серьёзных попыток привлечь более широкое сообщество.
Изучаем URLы и их структуру — Изучение веб-разработки
Данная статья описывает Единый локатор ресурсов или Uniform Resource Locators (URLs), объясняет, что это такое, и опиcывает его структуру.
Введение
Наряду с понятиями гипертекста и протокола HTTP, понятие URL является одной из основных концепций Всемирной паутины. Это механизм, используемый браузерами для получения любого опубликованного во Всемирной сети ресурса.
URL обозначает Uniform Resource Locator. URL это лишь адрес, который выдан уникальному ресурсу в интернете. В теории, каждый корректный URL ведет на уникальный ресурс. Такими ресурсами могут быть HTML-страница, CSS-файл, изображение и т.д. На практике, существуют некоторые исключения, когда, например, URL ведет на ресурс, который больше не существует или который был перемещён. Поскольку ресурс, доступный по URL, а также сам URL обрабатываются веб-сервером, его владелец должен внимательно следить за размещаемыми ресурсами и связанными с ними URL.
Активное обучение
There is no active learning available yet. Please, consider contributing.
Подробная информация
Основы: анатомия URL
Вот несколько примеров URL:
https://developer.mozilla.org https://developer.mozilla.org/en-US/docs/Learn/ https://developer.mozilla.org/en-US/search?q=URL
Каждый из этих URLs могут быть напечатаны в адресной строке браузера, чтобы заставить его загрузить связанную страницу (ресурс).
URL состоит из различных частей, некоторые из которых являются обязательными, а некоторые — факультативными. Рассмотрим наиболее важные части на примере:
http://www.example.com:80/path/to/myfile.html?key1=value1&key2=value2#SomewhereInTheDocument
http://это протокол. Он отображает, какой протокол браузер должен использовать. Обычно это HTTP-протокол или его безопасная версия — HTTPS. Интернет требует эти 2 протокола, но браузеры часто могут использовать и другие протоколы, напримерmailto:(чтобы открыть почтовый клиент) илиftp:для запуска передачи файлов, так что не стоит удивляться, если вы вдруг увидите другие протоколы.www.example.comэто доменное имя. Оно означает, какой веб-сервер должен быть запрошен. В качестве альтернативы может быть использован и IP-адрес, но это делается редко, поскольку запоминать IP сложнее, и это не популярно в интернете.:80это порт. Он отображает технический параметр, используемый для доступа к ресурсам на веб-сервере. Обычно подразумевается, что веб-сервер использует стандартные порты HTTP-протокола (80 для HTTP и 443 для HTTPS) для доступа к своим ресурсам. В любом случае, порт — это факультативная составная часть URL./path/to/myfile.htmlэто адрес ресурса на веб-сервере. В прошлом, адрес отображал местоположение реального файла в реальной директории на веб-сервере. В наши дни это чаще всего абстракция, позволяющая обрабатывать адреса и отображать тот или иной контент из баз данных.?key1=value1&key2=value2это дополнительные параметры, которые браузер сообщает веб-серверу. Эти параметры — список пар ключ/значение, которые разделены символом&. Веб-сервер может использовать эти параметры для исполнения дополнительных команд перед тем как отдать ресурс. Каждый веб-сервер имеет свои собственные правила обработки этих параметров и узнать их можно, только спросив владельца сервера.#SomewhereInTheDocumentэто якорь на другую часть того же самого ресурса. Якорь представляет собой вид «закладки» внутри ресурса, которая переадресовывает браузер на «заложенную» часть ресурса. В HTML-документе, например, браузер может переместиться в точку, где установлен якорь; в видео- или аудио-документе браузер может перейти к времени, на которое ссылается якорь. Важно отметить, что часть URL после #, которая также известна как идентификатор фрагмента, никогда не посылается на сервер вместе с запросом.
Вам стоит представлять URL как обычный почтовый адрес: протокол обозначает почтовый транспорт, который вы собираетесь использовать,доменное имя — это город, порт — это почтовый индекс; адрес — это номер дома;параметры представляют собой дополнительную информацию, как, например, номер квартиры; и, наконец, якорь представляет собой конкретного получателя, которому вы адресуете своё письмо.
Как использовать URL
Каждый URL может быть напечатан напрямую в адресной строке браузера, чтобы сразу получить запрошенный ресурс. Но это только вершина айсберга!
Язык HTML — который будет обсуждать позже — позволяет активно использовать URL для:
- создания ссылок на другие документы с помощью тега
<a>; - связывания документа с его дополнительными файлами, например с помощью тегов
<link>или<script>; - отображения медиа-элементов, например изображений (с помощью тега
<img>), видео (с помощью тега<video>), звуков и музыки (с помощью тега<audio>) и так далее; - отображения других HTML-документов внутри текущего с помощью тега
<iframe>.
Другие технологии, такие как CSS или JavaScript, также активно используют URL, так что это реально основа веба.
Абсолютные и относительные URL
Все, что мы изучали выше — это абсолютные URL. Но так же существуют и относительные URL. Изучим это.
Обязательные части URL во многом зависят от контекста, в котором используется URL. В адресной строке браузера URL не имеет никакого контекста, так что приходится вводить полный (или абсолютный) URL, такие как мы рассматривали выше. Обычно вам не требуется вводить протокол (браузер подставляет HTTP по умолчанию) и порт (который нужен только в том случае, если сервер использует нестандартный порт), но остальные части URL всё равно необходимы.
Когда URL используется в документе, например в HTML-странице, ситуация отличается. Потому что браузер уже знает URL текущего документа и он может использовать эти сведения для дополнения недостающих частей любого адреса, указанного в документе. Простейший пример относительного URL — указание только адресной части URL. А если адрес в URL начинается с символа "/«, браузер запросит ресурс от корня сервера, без отсылки к контексту текущего документа.
Разберем это на примерах.
Примеры абсолютных URL
- Полный URL (такой же, как обсуждали в начале статьи)
https://developer.mozilla.org/en-US/docs/Learn
- Скрыт протокол
//developer.mozilla.org/en-US/docs/Learn
В этом случае браузер использует тот же протокол, что использовался для загрузки текущего документа.
- Скрыт домен
/en-US/docs/Learn
Это наиболее частый пример использования аболютного URL в HTML-документе. Браузер использует тот же протокол и то же доменное имя, как у текущего документа. Примечание: не возможно скрыть домен, не скрывая при этом протокол, только вместе.
Примеры относительных URL
Для лучшего понимания следующих примеров, давайте договоримся, что мы обращаемся к URL из документа, который опубликован по адресу: https://developer.mozilla.org/en-US/docs/Learn
- Дочерние ресурсы
Skills/Infrastructure/Understanding_URLs
Поскольку URL не начинается с/, браузер сделает попытку найти документ в поддиректории относительно текущего документа. В данном примере будет запрошен этот URL:https://developer.mozilla.org/en-US/docs/Learn/Skills/Infrastructure/Understanding_URLs- Назад по дереву папок
../CSS/display
В этом случае, мы используем команду
../— унаследованную из файловой системы UNIX — чтобы сказать браузеру, что он должен подняться на 1 директорию вверх. Соответственно, здесь мы хотим открыть URL:https://developer.mozilla.org/en-US/docs/Learn/../CSS/display, который может быть упрощен до вида:https://developer.mozilla.org/en-US/docs/CSS/display
Семантические URL
Помимо своего технического значения, URL представляют собой человеко-читаемые записи о местоположении документов на веб-ресурсе. Они могут быть запомнены и любой может ввести их в адресную строку своего браузера. Веб создавался для людей и распространённой практикой является принцип записи URL, который называется семантические URL. Семантические URL используют в своём составе слова, значение которых может быть понято любым человеком, даже тем, кто не разбирается в технических нюансах.
Семантика, разумеется, плохо распознаётся компьютерами. Вы наверняка видели URL, которые выглядят как куча случайных символов. Но у семантических URL есть много преимуществ:
- Ими легче управлять.
- Они дают понять пользователю, что находится по данному URL даже без перехода на страницу.
- Поисковые системы могут использовать семантику для улучшения классификации страниц.
Следующие шаги
Как создавать URL-адреса, которые будут понятны поисковым системам и целевой аудитории 
Зачем это нужно?
URL — это адрес вашего сайта. URL-адреса часто являются первым, что видит поисковик Google и посетители. Создание дружественных (понятных) адресов URL — простой вариант улучшения SEO. Если вы уделите внимание этому моменту, то сможете улучшить видимость сайта в поисковике.Кроме того, дружественные адреса лучше воспринимаются посетителями сайта, которые ищут тематический контент. Чересчур длинные ссылки, изобилующие предлогами, параметрами и лишними категориями, смотрятся хуже, чем короткие адреса, полностью передающие суть контента ресурса. Поэтому создание понятных URL приобретает стратегически важное значение.
В этом обзоре мы:
приведем ряд общих рекомендаций для создания дружественных URL-адресов;
расскажем, как улучшить URL для сайтов на платформах Joomla и WordPress;
дадим простые и эффективные советы для оптимизации структуры URL.
Что такое дружественные URL-адреса?
Дружественные URL-адреса — это ссылки, хорошо воспринимаемые не только посетителями, но и поисковыми системами. Грамотно составленные адреса играют первостепенную роль для качественной работы SEO. Создавая URL-адреса, пользуйтесь следующими рекомендациями:
легкая читаемость и максимальное соответствие тематике страницы/сайта;
отсутствие сложно запоминаемых длинных названий;
последовательный подход в создании структуры URL-адресов.
Применяйте принцип KISS (Keep It Short and Simple) — «делайте это короче и понятнее». Ранее этот принцип применяли в ВМС США, а сегодня он является одним из «китов» при проектировании любого сайта.В Google придерживаются мнения, что структура URL-адреса сайта должна быть как можно более простой. Поэтому применение принципа KISS — это не примитивизм, а мудрое решение. Создавайте URL-адреса логически понятными и легко читаемыми.
Приведем примеры хороших и плохих URL-адресов:
https://www.example.com/iphone-8 — хороший;
https://www.example.com/index.php?productID=83671 — плохой.
Когда потенциальные посетители посмотрят на адрес, у них не должно быть сомнений в том, какого рода контент им будет предложен. Если ваш адрес будет простым и максимально читаемым, посетители с большим интересом захотят перейти по ссылке, представленной в поисковых результатах Google.
Кроме того, в URL желательно включить 1-2 важных ключевых запроса. Это способствует лучшему ранжированию. Однако не переусердствуйте. Если вы заполняете URL только ключевыми запросами, это ухудшает читаемость и свидетельствует о плохой оптимизации. Поэтому вам нужно избегать этого. От увеличения количества поисковых фраз в URL нет никакой пользы, а иногда это даже приносит вред.
Как подобрать верные ключи? В этом видео есть отличные объяснения по этому поводу:
Следует избегать стоп-слов (слов, которые не несут смысловой нагрузки) в URL. Их использование бессмысленно, они только увеличивают длину адреса. Следовательно, восприятие URL, перегруженного предлогами и союзами, будет только хуже.
Приведем примеры:
https://www.example.com/blog/best-advice-for-copywriter/ — хороший адрес;
https://www.example.com/blog/the-best-advice-for-a-copywriter/ — плохой адрес.
Также старайтесь не пользоваться параметрами в URL. Взгляните на эту ссылку: www.example.com/index.php?product=331. Согласитесь, визуально она воспринимается тяжело и может отпугнуть потенциальных посетителей. Конечно, в ряде случаев параметры крайне необходимы. В таких ситуациях необходимо просто свести их число к минимуму.
Разделяйте слова в URL-адресах с использованием дефисов (-). Невзирая на то, что поисковики сегодня поддерживают символы подчеркивания (_) в качестве разделителей слов, читатели визуально лучше воспринимают именно дефисы.
Поисковые системы и посетители отдают предпочтение коротким URL-адресам, потому максимально сокращайте их. Старайтесь использовать минимум каталогов, в идеале — только один. Однако короткие URL — это не главная цель. Ваша основная задача состоит в создании логических и хорошо читаемых URL-адресов.
Как изменить URL-адреса для сайта на Joomla?
Чтобы поменять длинные и громоздкие URL на более короткие, необходимо открыть админку вашего Joomla-сайта. Далее переходите в System -> «Глобальная конфигурация»:
Откроется экран «Глобальная конфигурация». Нас интересуют «Настройки SEO».
Здесь мы видим параметр «Дружественные адреса». Выбрав «Да», вы согласитесь с тем, чтобы ваши URL были оптимизированы для поисковиков.
У нас есть два предупреждения перед тем, как вы начнете:
Эти настройки следует менять очень осторожно, поскольку их изменение может привести к печальным последствиям. К счастью, исправить ситуацию легко — если поменяете какой-либо из параметров на «Да», а ресурс станет создавать нерабочие ссылки, просто снова поменяйте настройки на «Нет». Немного ниже мы расскажем о настройке этих параметров, если их изменение привело к проблемам на вашем сайте.
Желательно установить эти параметры непосредственно перед запуском вашего ресурса. Если вы поменяете их позднее, это может привести к разрушению ранее работавших ссылок и, как следствие, недовольству посетителей.
По умолчанию установлено значение «Да», что очень хорошо.
Мы также видим параметр «Использовать перезапись URL». Здесь все чуточку сложнее. Вам необходимо произвести настройки под Apache-сервер. В случае с Windows IIS настройки будут сложнее. Первым делом перед тем, как вы обратитесь к пункту «Использовать перезапись URL», чтобы избавиться от index.php в URL-адресах, необходимо поменять название одного из ваших файлов.
Вы должны будете войти в вашу файловую систему Joomla. Искомый файл носит название htaccess.txt.
Вы должны найти его. Файл располагается в главном каталоге Joomla-ресурса, рядом с файлами configuration.php, readme.txt, index.php и так далее. Вам понадобится удалить расширение файла –.txt. Вы должны будете поставить точку в самом начале файла. Таким образом, имя файла поменяется с htaccess.txt на.htaccess. Этого достаточно для нормальной работы файла.
Теперь необходимо вернуться к меню «Настройки SEO». Вы должны перейти к пункту «Использовать кнопку перезаписи URL». Здесь можно удалить index.php из URL-адресов. Теперь благодаря настройке этих двух параметров вы получили более понятный и простой для запоминания URL-адрес. Наверняка вы обратили внимание и на другие пункты в настройках. В частности, у вас есть возможность добавления суффикса к URL (пункт «Добавить суффикс к URL»):
Честно говоря, мы не считаем этот суффикс полезным. При включении этого параметра к концу URL-адреса будет добавлен суффикс.html. Таким образом, адрес становится более сложным. При этом сайты уже давно не создаются на чистом HTML. Сомневаемся в полезности этого пункта.
Если вы создаете контент сайта на языке, использующем разные символы (не только A-Z), вам может понадобиться установить параметр «Псевдонимы Юникод» в «Да». Если же вы планируете использовать только буквы латинского (или большинства европейских языков), можно установить «Нет».
Итак, мы разобрались с тем, как сделать понятными URL-адреса для Joomla-ресурса. Если вы поменяете имя файла htaccess.txt на.htaccess и произведете настройки параметров, как было рассказано выше, получите красивые и простые URL-адреса для своего сайта, работающего на движке Joomla. Далее мы рассмотрим, как сделать дружественными URL ресурса, созданного на базе CRM (системы управления сайтом) WordPress.
Создание понятных URL-адресов на WordPress
Желаете, что Google «понимал» ваш контент и связывал его с конкретными поисковыми фразами? Для этого вы должны удостовериться, что URL-адреса содержат ключевые запросы, соответствующие тематике сайта. Например, если вы рассказываете о фестивале «Республика КаZантип», проходящем в этом году в Крыму, ссылка должна выглядеть примерно так: www.site.com.festival-republic-kazantip-2018, а не www.site.com/?p=123.Какой адрес привлекает больше? Естественно, первый. Здесь сразу ясно, о чем будет рассказываться на сайте. Ваша URL-ссылка должна сообщать Google и потенциальным посетителям, просматривающим поисковые результаты, о сути содержимого ресурса.
В первом случае адрес содержит необходимые ключевые слова, поэтому Google легко интерпретирует контент. Людям тоже будет проще разобраться, ведь сразу ясно, что сайт посвящен фестивалю, проходящему в 2018 году. В итоге мы получаем беспроигрышный вариант.
CRM WordPress не всегда создает дружественные и понятные адреса. Поэтому вам может понадобиться поменять структуру ссылок самостоятельно. Для этого откройте «Настройки» -> «Постоянная ссылка». Вашему вниманию предстанут следующие вариации:
1. Обычная — не рекомендуется, поскольку такой URL-адрес не описывает контент.
2. День и название — рекомендуется, поскольку помогает поисковику понять тематику контента и узнать точную дату его публикации (это нужно посетителям).
3. Месяц и название — рекомендуется, как и в прошлом случае, только здесь вместо дня отображается месяц публикации контента.
4. Числовой — не рекомендуется, поскольку такой URL-адрес не описывает контент.
5. Название поста — идеальный вариант. Вы сможете исправить ссылку так, чтобы она максимально соответствовала тематике контента.
6. Настраиваемая структура — здесь для настройки адреса предлагается использовать специальные теги. Если ваш сайт состоит из нескольких важных разделов, используйте тег типа /% category% /% postname% / для добавления категории к вашему URL. Этот способ дает поисковой системе больше информации о контенте. Здесь все зависит от вашей грамотности.
После настройки постоянных ссылок жмите «Сохранить изменения», иначе настройки не сохранятся. Впоследствии с помощью «админки» вы сможете исправлять URL-адреса любых страниц.
Также советуем ознакомиться с рекомендациями, касающимися изменения URL-адресов в WordPress:
Делайте адреса релевантными. Удалите все не соответствующие тематике сайта слова и сконцентрируйтесь на целевых ключевых запросах. Также избавьтесь от междометий, союзов и предлогов. Они являются «балластом», поскольку не несут смысловой нагрузки. Согласитесь, что ссылка www.site.com.festival-republic-kazantip-2018 смотрится лучше, чем www.site.com.the-festival-of-republic-kazantip-in-2018.
Укорачивайте URL-адреса. Длинные URL часто ранжируются хуже коротких. Вы можете уменьшить длину адреса, воспользовавшись предыдущим советом. Важно пользоваться релевантными ключевыми фразами и убирать лишние слова.
Следите за тем, чтобы формат URL был одинаков для каждой страницы. Если вы используете дефис («-») для разделения слов во всех своих ссылках, нельзя внезапно переходить на символ подчеркивания («_»). Делайте так, как и WordPress — используйте традиционный дефис для разделения слов в ваших URL-адресах.
Пользуясь этими рекомендациями, вы сможете сделать человеко-понятными URL-адреса для своего сайта на платформе WordPress.
Как оптимизировать структуру URL: основные рекомендации
Создание привлекательного сайта, наполненного качественным тематическим контентом, — это только полдела. Поисковым системам важно не только то, как красиво смотрится ваш ресурс. Для них огромное значение имеет и соответствие его структуры потребностям поискового движка.
Конечно, внешний вид тоже важен, поскольку посетителям больше нравится находиться на сайте с красивым оформлением, чем посещать малопривлекательный ресурс. Это также влияет на ранжирование в поисковиках. Однако не менее важен вопрос создания дружественных адресов. Для этого необходимо подумать об оптимизации URL сайта, чтобы их легче «понимали» Google и посетители.
Тематические поисковые фразы
Каждому владельцу сайта хочется, чтобы его детище было доступно целевой аудитории (и поисковым системам), потому необходимо добавить соответствующие ключевые слова. В URL-адрес необходимо включить слово (словосочетание), которое лучше всего передает тематику вашего сайта.
Общий пример:
https://example.com/topic
Пример в случае с «виски» (whiskey):
https://example.com/whiskey
Есть два варианта написания слова «виски» на английском — whiskey и whisky. Оба используются, причем первый — ирландский, второй — шотландский. В Соединенных Штатах приняли ирландскую орфографию, но далеко не факт, что пользователи чаще всего ищут в Google именно этот вариант.
Приложение Moz Keyword Explorer отлично подходит для решения подобных вопросов, так как оно позволяет оценить объем поиска для определенных тем. В эпоху неопределенных поисковых запросов Moz представляет собой великолепное решение.
Как видим, чаще всего люди вбивают в поиск слово whiskey, потому в названии URL желательно использовать именно этот вариант написания.
Планирование структуры адресов
Вероятно, самой серьезной проблемой, с которой нам приходится сталкиваться при определении иерархии URL-адресов на сайтах, является обеспечение ее соответствия нашим целям на долгие годы вперед.
Именно поэтому многие ресурсы заканчиваются «лоскутным одеялом» субдоменов и конфликтующими путями. Это неудовлетворительно не только с точки зрения рядового пользователя. Google тоже получает невнятную информацию о классификации вашей продукции.
Приведем пример:
https://primer.com/whiskey/irish-whiskey/jameson
https://primer.com/bushmills
Первый URL-адрес логически вытекает из домена в категорию, потом в подкатегорию и в продукт. Второй URL идет сразу от домена к продукту. В плане иерархии оба варианта продукции должны иметь на сайте один уровень, но пример Jameson лучше для пользователей и SEO.
Такая проблема встречается часто. Почему? Это может быть связано с плохой организацией работы, когда коллектив разработчиков запускает новую страницу на сайт, не проконсультировавшись с остальными сторонами. Причина также может быть в отсутствии планирования как такового.
В любой ситуации необходимо планировать структуру заранее. Необходимо постоянно пополнять свои знания SEO для формирования архитектуры сайта. Чем больше вы планируете, тем меньше ошибок допустите.
Удаление лишних слов
Убедитесь, что пользователь сможет понять, что представляет собой ваш контент, при одном лишь взгляде на URL. Это значит, что вы не должны включать в адрес каждый предлог или союз. Слова наподобие «просто» либо «и» являются отвлекающими факторами, потому их можно полностью удалить из URL. Если вы уберете их, пользователи и поисковые системы по-прежнему будут хорошо ориентироваться в тематике вашего сайта, так как предлоги и союзы не несут серьезной смысловой нагрузки.
Также вам нужно избегать повторения поисковых фраз в URL-адресах. Многократное добавление одного и того же ключевого запроса в надежде увеличения шансов на ранжирование приведет только к созданию спам-структуры URL. Пример такого ненужного повторения:
https://domain.com/whiskey/irish-whiskey/jameson-irish-whiskey/jameson-irish-whiskey-history
Первые два использования основной поисковой фразы имеют смысл, тогда как третье и четвертое — чрезмерны.
Несколько дополнительных моментов, которые следует учитывать.
Чувствительность к регистру. На удивление часто встречается несколько версий одного и того же URL-адреса, причем один в нижнем регистре, а остальные — случайные заглавные буквы. Применяйте канонические теги, чтобы отметить URL нижнего регистра в качестве предпочтительной версии, или используйте постоянные переадресации, если это возможно.
Хеши: они могут быть полезны для отправки пользователей в определенный раздел страницы. Однако в других обстоятельствах лучше ограничить их использование.
Разделители слов: пользуйтесь дефисами для разделения слов в строках URL. Подчеркивания служат для объединения двух слов вместе, поэтому будьте осторожны с их использованием.
Длина URL: Google усекает ваш URL-адрес на страницах результатов поиска после 512 пикселей. Поэтому создавайте URL-адреса максимально короткими без утраты общего смысла.
Уменьшение строк динамических URL Это может быть сложнее, чем кажется, в зависимости от используемой вами системы управления контентом (Joomla, WordPress и так далее.). Некоторые коммерческие платформы автоматически «выплевывают» строки символов, вследствие чего получаются вот такие непонятные URL-адреса:
https://domain.com/cat/?cid=7078.
Адрес выглядит неприглядно и противоречит правилам SEO, которые мы изложили выше. Важно, чтобы статические URL-адреса включали логическую структуру папок и тематические ключевые слова.
Хотя в поисковиках нет проблем с индексацией любого варианта, для SEO лучше использовать статические URL-адреса. Они содержат ключевые фразы и более удобны для читателя, поскольку суть содержимого понятна при одном только взгляде на статический URL-адрес.
Также к URL-адресу добавляют некоторые параметры для отслеживания аналитики. Чтобы узнать, не увеличивают ли параметры количество URL-адресов с дублирующимся содержимым, выполните какое-либо из действий:
Укажите Google игнорировать ряд параметров в Google Webmaster Tools (Инструментах вебмастера Google) в разделе Configuration -> URL Parameters (Конфигурация -> Параметры URL).
Посмотрите, может ли CRM заменить URL-адреса с опциональными параметрами на более короткие аналоги.
Объединение разных версий сайта
В большинстве случае поисковые системы содержат две версии домена: www и не-www. Добавим к этому безопасную (https) и небезопасную (http) версии, причем поисковая система Google отдает предпочтение первому варианту. Многие оптимизаторы используют 301-редирект для перехода с одной версии сайта на другую. Таким образом, поисковики получают информацию о том, что какой-либо URL переехал в иной пункт назначения.
Альтернативным решением (когда нет возможности перенаправлять) станет указание своей предпочтительной версии сайта в Google Webmaster Tools в разделе Configuration -> Settings -> Preferred Domain (Конфигурация -> Настройки -> Предпочтительный Домен). Этот способ имеет свои минусы:
он актуален исключительно для Google;
можно работать только с корневыми доменами (если вы располагаете сайтом example.wordpress.com, об этом способе можно забыть).
Однако почему нужно вообще задумываться о проблеме www? Некоторые обратные ссылки могут указывать на вашу версию www, а другие могут перейти к версии, отличной от www. Чтобы все версии были ценными, необходимо установить между ними эту связь. Сделать это можно при помощи 301-редиректа, в Google Webmaster Tools или посредством канонического тега.
Канонические теги
Канонические теги являются очень полезными фрагментами кода, если вы располагаете несколькими версиями одной и той же страницы. Если вы добавите канонический тег, вы тем самым указываете Google, какой версии нужно отдать предпочтение.
Канонические теги полезны почти любому сайту, но особую эффективность они демонстрируют в случае с интернет-магазинами. Поисковики достаточно хорошо идентифицируют канонические URL-адреса. Но посмотрите, что пишет сотрудница корпорации Google Сьюзен Москва (Susan Moskwa) в официальном блоге вебмастеров Google (Google Webmaster Central):«Если нам не удастся найти все копии одной и той же страницы, не удастся консолидировать свойства. Следствием будет худшее ранжирование контента, поскольку получится разделение на несколько URL».
Карта сайта XML Как только вы выполните перечисленные выше действия, вы захотите убедиться, что поисковым системам известно,