
Неинформированный метод поиска — Википедия
Неинформи́рованный по́иск (также слепой поиск, метод грубой силы, англ. uninformed search, blind search, brute-force search) — стратегия поиска решений в пространстве состояний, в которой не используется дополнительная информация о состояниях, кроме той, которая представлена в определении задачи. Всё, на что способен метод неинформированного поиска, — вырабатывать преемников и отличать целевое состояние от нецелевого[1][2][3].
Поиск в ширину[править | править код]
Поиск в ширину (breadth-first search, BFS) — это стратегия поиска решений в пространстве состояний, в которой вначале развёртывается корневой узел, затем — все преемники корневого узла, после этого развёртываются преемники этих преемников и т.д. Прежде чем происходит развёртывание каких-либо узлов на следующем уровне, развёртываются все узлы на данной глубине в дереве поиска.
Алгоритм является полным. Если все действия имеют одинаковую стоимость, поиск в ширину является оптимальным.
Общее число выработанных узлов (временная сложность) равно O(bd+1), где b — коэффициент ветвления, d — глубина поиска. Пространственная сложность также равна O(bd+1)[1].
Реализация поиска в ширину может использовать очередь FIFO. В начале очередь содержит только корневой узел. На каждой итерации основного цикла из начала очереди извлекается узел curr. Если узел curr является целевым, поиск останавливается, в противном случае узел curr развёртывается, и все его преемники добавляются в конец очереди[4][5].
function BFS(v : Node) : Boolean;
begin
enqueue(v);
while queue is not empty do
begin
curr := dequeue();
if is_goal(curr) then
begin
BFS := true;
exit;
end;
mark(curr);
for next in successors(curr) do
if not marked(next) then
begin
enqueue(next);
end;
end;
BFS := false;
end;
Поиск по критерию стоимости[править | править код]
Поиск по критерию стоимости (метод равных цен, uniform-cost search, UCS) — обобщение алгоритма поиска в ширину, учитывающее стоимости действий (рёбер графа состояний). Поиск по критерию стоимости развёртывает узлы в порядке возрастания стоимости кратчайшего пути от корневого узла. На каждом шаге алгоритма развёртывается узел с наименьшей стоимостью g(n). Узлы хранятся в очереди с приоритетом[6].
Этот алгоритм является полным и оптимальным, если стоимости этапов строго положительны. Если стоимости всех этапов равны, поиск по критерию стоимости идентичен поиску в ширину.
Процедура поиска по критерию стоимости может войти в бесконечный цикл, если окажется, что в ней развёрнут узел, имеющий действие с нулевой стоимостью, которое снова указыает на то же состояние. Можно гарантировать полноту и оптимальность поиска при условии, что стоимости всех действий строго положительны
Поиск по критерию стоимости логически эквивалентен алгоритму Дейкстры (англ. Dijkstra’s single-source shortest-path algorithm). В частности, оба алгоритма развёртывают одни и те же узлы в одном и том же порядке. Основное различие связано с наличием узлов в очереди с приоритетом: в алгоритме Дейкстры все узлы добавляются в очередь при инициализации, а в алгоритме поиска по критерию стоимости узлы добавляются «на лету» (англ. on-the-fly, lazily) во время поиска. Из этого следует, что алгоритм Дейкстры применим к явно заданным графам, в то время как алгоритм UCS может быть применён как к явным, так и к неявным графам[7].
Поиск в глубину[править | править код]
Поиск в глубину (depth-first search, DFS) — стратегия поиска решений в пространстве состояний, при которой всегда развёртывается самый глубокий узел в текущей периферии дерева поиска. При поиске в глубину анализируется первый по списку преемник текущего узла, затем — его первый преемник и т. д. Развёрнутые узлы удаляются из периферии, поэтому в дальнейшем поиск «возобновляется» со следующего самого поверхностного узла, который всё ещё имеет неисследованных преемников [1].
Стратегия поиска в глубину может быть реализована с помощью стека LIFO или с помощью рекурсивной функции[8].
function DFS(v : Node; depth : Integer) : Boolean;
begin
if is_goal(v) then
begin
DFS := true;
exit;
end;
for next in successors(v) do
if DFS(next, depth + 1) then
begin
DFS := true;
exit;
end;
DFS := false;
end;
Поиск с ограничением глубины[править | править код]
Поиск с ограничением глубины (depth-limited search, DLS) — вариант поиска в глубину, в котором применяется заранее определённый предел глубины l, что позволяет решить проблему бесконечного пути.
Поиск с ограничением глубины не является полным, так как при l < d цель не будет найдена, и не является оптимальным при l > d. Его временная сложность равна O(
Поиск с ограничением глубины применяется в алгоритме поиска с итеративным углублением.
function DLS(v : Node; depth, limit : Integer) : Boolean;
begin
if (depth < limit) then
begin
if is_goal(v) then
begin
DLS := true;
exit;
end;
for next in successors(v) do
begin
if DLS(next, depth + 1, limit) then
begin
DLS := true;
exit;
end;
end;
end;
DLS := false;
end;
Поиск в глубину с итеративным углублением[править | править код]
Поиск в глубину с итеративным углублением (iterative-deepening depth-first search, IDDFS, DFID) — стратегия, которая позволяет найти наилучший предел глубины поиска DLS. Это достигается путём пошагового увеличения предела l до тех пор, пока не будет найдена цель.
В поиске с итеративным углублением сочетаются преимущества поиска в глубину (пространственная сложность O( b·l)) и поиска в ширину (полнота и оптимальность при конечном b и неотрицательных весах рёбер).
Хотя в поиске с итеративным углублением одни и те же состояния формируются несколько раз, большинство узлов находится на нижнем уровне дерева поиска, поэтому затратами времени на повторное развёртывание узлов обычно можно пренебречь. Временная сложность алгоритма имеет порядок O(bl)[1][9][10].
function IDDFS(v : Node) : Integer;
var
lim: Integer;
begin
lim := 0;
while not DLS(v, 0, lim) do
lim := lim + 1;
IDDFS := lim;
end;
Двунаправленный поиск[править | править код]
Двунаправленный поиск (bidirectional search) в ширину (или глубину) — усложнённый алгоритм поиска в ширину (или глубину), идея которого заключается в том, что можно одновременно проводить два поиска (в прямом направлении, от начального состояния, и в обратном направлении, от цели), останавливаясь после того, как два процесса поиска встретятся на середине.
Двунаправленный поиск может быть основан на стратегии итеративного углубления. Одна итерация включает в себя поиск на глубину k в прямом направлении и два поиска на глубину k и k + 1 в обратном направлении. Так как в памяти хранятся только состояния, найденные прямым поиском на глубине k, пространственная сложность поиска определяется как O(bd/2). Проверка принадлежности узла, найденного обратным поиском, к периферии дерева прямого поиска может быть выполнена за постоянное время, поэтому временная сложность двунаправленного поиска определяется как O(bd/2)[1][9][11].
Основные методы поиска информации в Интернете
Можно выделить следующие основные методы поиска информации в Интернете, которые, в зависимости от целей и задач ищущего, используются по отдельности или в комбинации друг с другом:
1. Непосредственный поиск с использованием гипертекстовых ссылок
Поскольку все сайты в пространстве WWW фактически оказываются связанными между собой, поиск информации может быть произведен путем последовательного просмотра связанных страниц с помощью браузера.
Хотя этот полностью ручной метод поиска выглядит полным анахронизмом в Сети, содержащей более 60 млн. узлов, «ручной» просмотр Web-страниц часто оказывается единственно возможным на заключительных этапах информационного поиска, когда механическое «копание» уступает место более глубокому анализу.
Использование каталогов, классифицированных и тематических списков и всевозможных небольших справочников также относится к этому виду поиска.
2. Использование поисковых машин
Сегодня этот метод является одним из основных и фактически единственным при проведении предварительного поиска. Результатом последнего может являться список ресурсов Cети, подлежащих детальному рассмотрению.
Как правило, применение поисковых машин основано на использовании ключевых слов, которые передаются поисковым серверам в качестве аргументов поиска: что искать.
3. Поиск с применением специальных средств
Этот полностью автоматизированный метод может оказаться весьма эффективным для проведения первичного поиска.
Одна из технологий этого метода основана на применении специализированных программ — спайдеров, которые в автоматическом режиме просматривают Web-страницы, отыскивая на них искомую информацию.
Фактически это автоматизированный вариант просмотра с помощью гипертекстовых ссылок, описанный выше (поисковые машины для построения своих индексных таблиц используют похожие методы).
Нет нужды говорить, что результаты автоматического поиска обязательно требуют последующей обработки.
Применение данного метода целесообразно, если использование поисковых машин не может дать необходимых результатов (например, в силу нестандартности запроса, который не может быть адекватно задан существующими средствами поисковых машин).
Выбор между использованием спайдера или поисковых серверов являет собой вариант классического выбора между применением универсальных или специализированных средств.
1.4 Анализ новых ресурсов
Поиск по новообразованным ресурсам может оказаться необходимым при проведении повторных циклов поиска, поиска наиболее свежей информации или для анализа тенденций развития объекта исследования в динамике.
Другой возможной причиной может явиться то, что большинство поисковых машин обновляет свои индексы со значительной задержкой, вызванной гигантскими объемами обрабатываемых данных, и эта задержка обычно тем больше, чем менее популярна интересующая тема.
Это соображение может оказаться весьма существенным при проведении поиска в узкоспециальной предметной области.
Методы информационного поиска (стр. 1 из 2)
Типология методов поиска
Более или менее серьезный подход к любой задаче начинается с анализа возможных методов ее решения. Поиск информации в Интернете может быть произведен по нескольким методам, значительно различающимся как по эффективности и качеству поиска, так и по типу извлекаемой информации. В ряде случаев приходится использовать весьма трудоемкие методы — результат того стоит.
Можно выделить следующие основные методы поиска информации в Интернете, которые, в зависимости от целей и задач ищущего, используются по отдельности или в комбинации друг с другом:
Непосредственный поиск с использованием гипертекстовых ссылок
Поскольку все сайты в пространстве WWW фактически оказываются связанными между собой, поиск информации может быть произведен путем последовательного просмотра связанных страниц с помощью броузера.
Хотя этот полностью ручной метод поиска выглядит полным анахронизмом в Сети, содержащей более 60 млн узлов, «ручной» просмотр Web-страниц часто оказывается единственно возможным на заключительных этапах информационного поиска, когда механическое «копание» уступает место более глубокому анализу. Использование каталогов, классифицированных и тематических списков и всевозможных небольших справочников также относится к этому виду поиска.
Использование поисковых машин
Сегодня этот метод является одним из основных и фактически единственным при проведении предварительного поиска. Результатом последнего может являться список ресурсов Cети, подлежащих детальному рассмотрению.
Как правило, применение поисковых машин основано на использовании ключевых слов, которые передаются поисковым серверам в качестве аргументов поиска: что искать. Если делать все правильно, то формирование списка ключевых слов требует предварительной работы по составлению тезауруса.
Поиск с применением специальных средств
Этот полностью автоматизированный метод может оказаться весьма эффективным для проведения первичного поиска.
Одна из технологий этого метода основана на применении специализированных программ — спайдеров, которые в автоматическом режиме просматривают Web-страницы, отыскивая на них искомую информацию. Фактически это автоматизированный вариант просмотра с помощью гипертекстовых ссылок, описанный выше (поисковые машины для построения своих индексных таблиц используют похожие методы). Нет нужды говорить, что результаты автоматического поиска обязательно требуют последующей обработки.
Применение данного метода целесообразно, если использование поисковых машин не может дать необходимых результатов (например, в силу нестандартности запроса, который не может быть адекватно задан существующими средствами поисковых машин). В ряде случаев этот метод может быть очень эффективен.
Выбор между использованием спайдера или поисковых серверов являет собой вариант классического выбора между применением универсальных или специализированных средств.
Анализ новых ресурсов
Поиск по новообразованным ресурсам может оказаться необходимым при проведении повторных циклов поиска, поиска наиболее свежей информации или для анализа тенденций развития объекта исследования в динамике.
Другой возможной причиной может явиться то, что большинство поисковых машин обновляет свои индексы со значительной задержкой, вызванной гигантскими объемами обрабатываемых данных, и эта задержка обычно тем больше, чем менее популярна интересующая вас тема. Это соображение может оказаться весьма существенным при проведении поиска в узкоспециальной предметной области.
Технология поиска с использованием поисковых машин
Определение географических регионов поиска
Поскольку проведение информационного поиска преследует практические цели — маркетинговые, производственные, сугубо утилитарные и тому подобные, — практическая ценность информационного ресурса может зависеть и от географического расположения соответствующего источника.
Составление тезауруса
Для эффективного использования поисковых серверов необходим список ключевых слов, организованный с учетом семантических отношений между ними, т.е. тезаурус. При составлении тезауруса необходимо предусмотреть обработку синонимов, омонимов и морфологических вариаций ключевых слов.
Использование законов Зипфа
Число, показывающее сколько раз встречается слово в тексте, называется частотой вхождения слова. Если расположить частоты по мере убывания и пронумеровать, то порядковый номер частоты называется ранг частоты. Вероятность обнаружения слова в тексте = частота вхождения слова / число слов в тексте. Зипф нашел, что если умножить вероятность обнаружения слова в тексте на ранг частоты, то получившаяся величина приблизительно постоянна для всех текстов на одном языке:
С = (частота вхождения слов X ранг частоты) / число слов
Это значит, что график зависимости ранга от частоты — равносторонняя гипербола.
Зипф также установил, что зависимость количества слов с данной частотой от частоты — также гипербола и постоянная для всех текстов в пределах одного языка.
Что можно извлечь из этих законов? Исследования вышеуказанных зависимостей для различных текстов показали, что наиболее значимые слова текста лежат в средней части диаграммы, так как слова с максимальной частотой как правило являются предлогами, частицами, местоимениями, в английском языке — артиклями (так называемые «стоп-слова»), а редко встречающиеся слова в большинстве случаев не имеют решающего значения. Основываясь на этой закономерности, можно предложить следующую методику.
Составление списка ключевых слов
Правильный набор ключевых слов имеет определяющее значение для оптимального поиска информации. К примеру, задав поисковой машине в качестве ключевого слова «МАРП», мы получим список документов, в которых встречается эта аббревиатура (Московское Агентство по Развитию Предпринимательства). Но если нас интересуют документы по более широкой теме, например: развитие предпринимательства, и мы сформируем простой запрос из этих двух слов, то поисковая машина выдаст нам список из сотен тысяч наименований, ориентироваться в котором будет весьма непросто.
Поэтому для составления оптимального набора ключевых слов используют процедуру, основанную на применении законов Зипфа, которая заключается в следующем: берут любой текст-источник, близкий к искомой теме, т.е. «образец», и анализируют его, выделяя значимые слова. В качестве текста-источника может служить книга, статья, Web-страница, любой другой документ. Анализ текста производится таким образом:
— Удаление из текста стоп-слов.
— Вычисление частоты вхождения каждого слова и составление списка, в котором слова расположены в порядке убывания их частоты.
— Выбор диапазона частот, лежащего в середине списка, и отбор из этого диапазона слов, наиболее полно соответствующих смыслу текста.
— Составление запроса к поисковой машине в форме перечисления отобранных таким образом ключевых слов, связанных логическим оператором ИЛИ (OR). Запрос в таком виде позволяет обнаружить тексты, в которых встречается хотя бы одно из перечисленных слов.
Число документов, полученных в результате поиска по этому запросу, может быть огромно. Однако, благодаря ранжированию документов (расположению их в порядке убывания частоты вхождения слов запроса в документ), применяемому в большинстве поисковых машин, на первых страницах списка практически все документы окажутся релевантными, причем документ-источник может находиться далеко от начала.
Более адекватной представляется структура тезауруса в виде так называемых семантических срезов, где для каждого основного термина отдельно строится таблица сопутствующих слов и слов шумовых (которые не должны встречаться в источнике), — некоторые поисковые машины (AltaVista) позволяют это использовать. Таким образом, вместо единой иерархической структуры терминов мы получаем пакет таблиц, которые могут расширяться и модифицироваться отдельно.
Отбор поисковых машин
Устанавливается последовательность использования поисковых машин в соответствии с убыванием ожидаемой эффективности поиска с применением каждой машины.
Всего известно около 180 поисковых серверов, различающихся по регионам охвата, принципам проведения поиска (а следовательно, по входному языку и характеру воспринимаемых запросов), объему индексной базы, скорости обновления информации, способности искать «нестандартную» информацию и тому подобное. Основными критериями выбора поисковых серверов являются объем индексной базы сервера и степень развитости самой поисковой машины, то есть уровень сложности воспринимаемых ею запросов.
Более подробно поисковые машины описаны в разделе курса «Сетевые средства поиска информации».
Составление и выполнение запросов к поисковым машинам
Это наиболее сложный и трудоемкий этап, связанный с обработкой большого количества информации (в основном шумовой). На основе тезауруса формируются запросы к выбранным поисковым серверам, после чего возможно уточнение запроса с целью отсечения очевидно нерелевантной информации. Затем производится отбор ресурсов, начиная с наиболее интересных, с точки зрения целей поиска. Данные с ресурсов, признанных релевантными, собираются для последующего анализа.
Формирование запросов
Как формат, так и семантика запросов варьируются в зависимости от применяемой поисковой машины и конкретной предметной области. Запросы составляются так, чтобы область поиска была максимально конкретизирована и сужена.
Предпочтение отдается использованию нескольких узких запросов по сравнению с одним расширенным. В общем случае для каждого основного понятия из тезауруса готовится отдельный пакет запросов. Так же производится пробная реализация запросов — как для уточнения и пополнения тезауруса, так и с целью отсечения шумовой информации.
Лекции Техносферы. 2 семестр. Современные методы и средства построения систем информационного поиска
Снова в эфире наша образовательная рубрика. На этот раз предлагаем ознакомиться с очередным курсом Техносферы, посвящённым информационному поиску. Цель курса — рассказать об основных методах, применяемых при создании поисковых систем. Некоторые из них представляют собой хороший пример смекалки, некоторые показывают, где и как может применяться современный математический аппарат. Преподаватели курса: Алексей Воропаев, Владимир Гулин, Дмитрий Соловьев, Игорь Андреев, Алексей Романенко, Ян Кисель.
Лекция 1. Введение в информационный поиск. Обзор архитектуры поисковых систем
Определение задачи информационного поиска. Примеры поисковых систем. Задачи, связанные с поиском информации. История развития поисковых систем. Логическая модель информационного поиска, его задачи. Принципы булева поиска. Матрица «термин-документ». Обратный индекс. Словарь и координатные блоки. Создание обратного индекса. Разбиение на токены и сортировка. Словари и координатные блоки.
Лекция 2. Лингвистика
Что такое лингвистика, каковы её задачи. История зарождения и развития лингвистики как науки. Задачи, решаемые лингвистикой, её разновидности. Общая лингвистика: фонетика, фонология, морфология, синтаксис, семантика, прагматика. Историческая лингвистика. Лингвистическая типология. Социолингвистика. Диалектология. Лексикография. Психолингвистика. Математическая лингвистика. Статистическая лингвистика. Подходы к языку: рационалистический и эмпирический. Морфология. Корпусная лингвистика. Конкорданс, законы Ципфа, поправки и формула Мандельброта.
Лекция 3. Основы обработки текста
Критерии документа, кодировки. Уровни лингвистического анализа. Токены и термины. Детекция языка: графематический, N-граммный и лексический подходы. Нормализация. Проблемы токенизации. Наличие и отсутствие пробелов. Китайский, японский, арабский языки. Ударение и диакритика. Классы эквивалентности. Понижение регистра. Стоп-слова. Лемматизация. Стемминг. Предиктор. Виды языков. Статистическое снятие омонимии. Разбиение текста на предложения. Расширение поискового запроса.
Лекция 4. Коллокации
Методы подсчёта вероятности: параметрический и непараметрический подходы, стандартные и биноминальные распределения, мультиноминальное и нормальное распределения, аппроксимирование. Байесовский подход к статистике. Определение коллокаций, их признаки. Частотность биграмм. Фильтр по частям речи. Отклонения, гистограммы отклонений. Поиск коллокаций, примеры применения t-критерия. Поиск отличий в словоупотреблении. Критерий Пирсона. x2-критерий. Критерий отношения правдоподобия. Относительные частоты. Взаимная информация. Разреженность данных. F-мера.
Лекция 5. Языковые модели. N-граммы. Цепи Маркова
Цели распознавания языка. Языковые модели. Поиск с использованием языковых моделей. Фундаментальная проблема нехватки данных. Построение N-грамм. Метод максимального правдоподобия. Сглаживание. Валидация моделей. Линейное смешение моделей. Цепь Маркова. Матрица переходов. Последовательность состояний. Скрытые марковские модели. Три задачи HMM. Алгоритмы вперёд и назад. Алгоритмы Витерби, Баума-Уэлша. Применение НММ Таггер. Анализ поведения пользователя.
Лекция 6. Машинный перевод
Определение и задачи машинного перевода. История развития машинного перевода. Подходы к машинному переводу: rule-based, corpora-based, hybrid. Три основные методологии. RBMT, его сравнение с SMT, их преимущества и недостатки. Параллельный корпус. Выравнивание по предложениям. Word-based модели. Модели IBM Model, их ограничения. Фразовые модели: фразовый статистический перевод, вычисление вероятности перевода, модель языка, модель перевода, построение фразовой таблицы. Декодирование. Оценка машинного перевода. BLEU (Bilingual evaluation understudy). Эволюция машинного перевода.
Лекция 7. Индексация
Общая схема базы поиска. Назначение обратного индекса. Технические ограничения и дисковая подсистема. Cостав обратного индекса и варианты его построения. Оптимизация пересечения блоков. Сжатие координатных блоков: сравнение побитовых и побайтовых подходов: код Фибоначчи, VarByte, гамма-коды, Simple9. Практические советы по уменьшению объема индекса. Структуры данных, используемые для построения словаря. Подходы к хранению стоп-слов. Проблемы индексации больших объемов. Распределение документов и балансировка баз. Архитектура индексатора.
Лекция 8. Архитектура web-поиска. Текстовое ранжирование
Логическая схема поисковой машины. Поисковый кластер. Индексация. Булев поиск. Вычисление веса. Коэффициент Жаккара. Частотная матрица. Модель «мешка слов». Частота термина. Логарифмическое взвешивание. Документная частота. IDF. Документы как векторы. Методы оптимизации текстового ранжирования. Термины с большим IDF. Документы с большим количеством терминов из запроса. Статические веса, общий вес. Эшелоны. Кластеризация индекса. Параметрические индексы и зоны. Поля (числовые зоны). Индексы для зон. Компактность вхождения. Вероятностный поиск. Использование языковых моделей при поиске. Варианты сравнения моделей. Правдоподобие запроса и документа. Сравнение моделей. Обратная связь по релевантности. Бинарная вероятностная модель. Байесовы сети в задаче ранжирования.
Лекция 9. Дизайн поисковой выдачи. Сниппеты. Оценка качества поиска
Примеры дизайнов страниц поисковых выдач разных ресурсов. Компоненты SERP. Органические результаты. Выделение параграфов. Разбиение на предложения. Формирование сниппета, общий алгоритм формирования. Обогащение сниппетов. Метрики сниппетов. Оценка асессорами. Метрики качества поисковой системы. Качество поиска. Стандартные коллекции. TREC. Точность/полнота. Критика чистой релевантности. Маркерные тесты. Поиск периферийных сайтов. Региональная навигация. Тематический поиск. Общее качество поиска. Асессорская служба. Оценка релевантности документа. Кросс-валидация. SOM-карты. Автопоиск ошибок. Онлайн-метрики. Оценка гипотез. Кликовые метрики. Корреляция с асессорами.
Лекция 10. Особенности web-поиска. Спайдер
Популярность пользования поиском. История поисковых систем. Основы web-поиска. Потребности пользователей. Эмпирическая оценка поисковых результатов пользователем. Коллекция web-документов. Поисковая реклама, как она ранжируется, каковы её плюсы и минусы. Спайдер, его задачи. Очередь URL’ов. Поисковые роботы. Основная архитектура спайдера. Парсинг: нормализация URL. Распределённый спайдер. Взаимодействие серверов. Схема Mercator. Front queues, back queues. Свежесть базы. Deep Web (труднодоступные сайты). Карты сайтов. Хранение документов. Удаление шума.
Лекция 11. Поиск дубликатов в Web
Сравнение документов: точные и неточные дубликаты, почти дубликаты, версии для печати. Три этапа определения похожих документов. Шинглы (shingles), опция сжатия. Множественная модель, матричная модель. Поиск похожих колонок. Сигнатуры. Выявление похожего множества (minhashing). Поиск похожих пар. Отбор кандидатов из сигнатур Minhash. Locality-sensitive hashing. Распределение по частям и по корзинам. LSH-компромиссы. Поиск дубликатов в Web.
Лекция 12. Применение самоорганизующихся карт в поисковой машине
Лекция разбита на две части. Первая часть: вопросы приоритезации спайдера поисковой машины, алгоритмы сегментации больших сайтов на части и распределение приоритетов обкачки сегментов. Вторая часть: алгоритмы анализа и визуализации больших объемов данных при помощи самоорганизующихся карт Кохонена (SOM), применение этого инструмента в задаче анализа структуры веба и приоритезации поискового робота, возможность применения SOM для анализа данных в различных областях разработки поискового движка.
Лекция 13. Выявление спам-сайтов на основе анализа контента страниц
Различные аспекты очистки поискового индекса от мусора. Вопросы построения классификаторов. Базовые темы машинного обучения: правильное построение обучающего множества, генерация признаков, выбор алгоритмов классификации. Проблематика построения классификаторов для различных классов данных.
Лекция 14. Поведенческое и ссылочное ранжирование
Вычисление поведенческой релевантности. Индексация анкорного текста. Алгоритм HITS, Page Rank. Метод блочной структуры. Системы для обработки графов.
Лекция 15. Ранжирование с машинным обучением
Классическое ранжирование. Факторы ранжирования. Ранжирование на основе машинного обучения. Специфика задачи машинного обучения ранжированию. Формальная постановка задачи. Градиентный спуск. Деревья решений. «Невнимательные» деревья решений. Алгоритмические композиции над деревьями решений (bagging, boosting). Стакинг. Алгоритм BagBoo. Вопросы построения обучающих данных. Активное обучение. Сэмплирование неопределённости. Комитетные методы активного обучения. Применение самоорганизующихся карт для сэмплирования обучающих данных. Алгоритм SOM+QBag для активного обучения ранжированию.
Предыдущие выпуски
Технопарк:
Техносфера:
Подписывайтесь на youtube-канал Технопарка и Техносферы!
Методы поиска
Делятся на методы поиска среди упорядоченных и неупорядоченных данных.
Среди неупорядоченных:
последовательный поиск
быстрый последовательный поиск
последовательный поиск в самоорганизующемся массиве данных
Быстрый последовательный поиск. Организуется цикл не со счётчиком, а цикл с условием совпадения ключей. Условие повторения — несовпадение ключей. При такой организации число сравнений в среднем N/2 .
Поиск в самоорганизующемся массиве данных. Массив данных неупорядоченный. Если нашли нужный элемент, помещаем его в начало, а остальные сдвигаем на одну позицию. Как только снова потребовался поиск, снова сравниваются все подряд. Нашли — ставим на первое место, остальные сдвигаем.
25 17 83 22 64
17: 17 25 83 22 64
64: 64 17 25 83 22
83: 83 64 17 25 22
17: 17 83 64 25 22
Методы поиска среди упорядоченных данных
Метод бинарного поиска
Сверяется со средним элементом (n/2). Если искомый ключ меньше среднего, ищем в левой половине, если больше — в правой. Количество сравнений log(N,2).
Однородный бинарный поиск
Используется переменная H (ширина отрезка). Позиция будет вычисляться по формуле i = +- H. H=H/2 . Число элементов массива должно быть степенью двойки.
Метод Фибоначчи
0 1 1 2 3 5 8 13 21 34 …
Сравнение как в бинарном поиске, но по числам Фибоначчи. Если массив из 34, сравниваем с 21 элементом. Если < 21 , то сравниваем с 13. Если меньше 13, то с 8 и т.д.
Если элемент оказался больше, следующая позиция вычисляется: 21 + 8 (Fi+Fi-2)
Число сравнений log(N,2) . Если элемент ближе к правой части массива, то нужно брать метод Фибоначчи.
Интерполяционный поиск
Реализована идея поиска по словарю. Для поиска используется формула i = Л+(П-Л)/(Кп-Кл) * (К-Кл)
Сначала Л=0, П=длина массива, Кп — ключ в правой позиции, Кл — ключ в левой позиции, К — искомый ключ.
log(N*log(N,2),2)
Поиск со вставкой по дереву
Сравнение с ключом-корнем дерева, если меньше, то left, больше — right и т.д.
log(N,2) для сбалансированных деревьев. Для вырожденного случая число сравнений N.
Для случайных величин 2*ln(N) = 1.4*log(N,2)
Цифровой поиск со вставкой по дереву
Для выбора ветви используются битовые значения ключей.
Поиск по бору

Сбалансированное двухпоточное слияние
Есть 4 файла F1..F4 , файлы хранятся на дисках.

Двухфазное слияние
Фаза слияния и фаза перезаписи.

Многофазное слияние с фиббоначиевым разбиением

Семестр 2
Алгоритмы на графах
Граф — упорядоченная пара G = (V,E)
V — вершины
E — рёбра
Вершины, соединённые общим ребром — смежные.
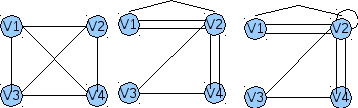
Взвешенный граф

Цикл — путь длиной 3 ребра или более, заканчивающийся в том же узле, из которого начался.
Ациклический граф — граф без циклов.
Сильносвязный граф — граф, у которого из каждой вершины есть путь в любую другую вершину этого графа.
Представление графов
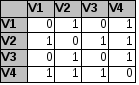
Матрицы смежности
Матрица, число строк и столбцов равно количеству вершин в графе. На пересечении ставится 0 (если вершины не связаны) или 1 (если вершины связаны).
Матрица весов — вместо 0 и 1 записывается вес ребра.
Матрицы инцидентности
Число строк — количество вершин. Число столбцов — количество рёбер (дуг)

Плотный граф — граф, близкий к полному. У которого каждая вершина связана с большинством оставшихся.
Разреженный — каждая вершина связана с небольшим количеством оставшихся вершин.
Список примыканий (МП1)
Дерево — связный граф без циклов.
Ребро — неупорядоченная пара вершин, соединённых между собой
Степень вершины — число инцидентных ей рёбер.
Порядок графа — число его вершин. Записывается |V|
Размер графа — число рёбер. Записывается |E|
Кратные рёбра, концевые вершины совпадают
Петля — ребро, вершины которого совпадают
Мультиграф — граф с кратными рёбрами
Псевдограф — мультиграф с петлями
Простой граф — без петель
Орграф — граф, все рёбра которого являются дугами.
Смешанный граф — граф, часть рёбер которого является ориентированными.
Нагруженный граф — каждому ребру соответствует вес
Сеть — взвешенный орграф.
Маршрут — последовательность вершин и рёбер, в которой каждая, кроме последующей, соединена ребром со следующей
Путь — маршрут в орграфе.
Длина маршрута — число составляющих его рёбер для невзвешенного или сумма весов для взвешенного
Цикл — цепь, в которой первая и последняя вершина совпадают
Эйлеров цикл — цикл, проходящий по каждому ребру в неориентированном мультиграфе ровно 1 раз.
Гамильтонов цикл — содержит каждую вершину один раз.
Контур — цикл в орграфе
Простой путь — в котором рёбра не повторяются.
Ациклический граф — граф без циклов
Связный граф — в котором для любой вершины существует путь из одной вершины в другую.
Компоненты связности — такое подмножество вершин, для любых двух … из которого существует путь из одной в другую и нет пути в остальные.
Разреженный — число рёбер много меньше квадрата его порядка.
Матрица смежности (примыканий) — элемент i,j содержит число рёбер, идущих из одной вершины в другую.
Списки примыканий — способ представления графов в виде списков, число которых равно количеству узлов.
Способы поиска в Интернете Три способа поиска в Интернете
Интернет в целом и Всемирная паутина, в частности, предоставляют абоненту доступ к тысячам серверов и миллионам Web-страниц, на которых хранится невообразимый объем информации. Как не потеряться в этом «информационном океане»? Для этого необходимо научиться искать и находить нужную информацию в сети.
Как уже было сказано, существуют три основных способа поиска информации в Интернете.
1. Указание адреса страницы. Это самый быстрый способ поиска, но его можно использовать только в том случае, если точно известен адрес документа.
2. Передвижение по гиперссылкам. Это наименее удобный способ, так как с его помошыо можно искать документы, только близкие по смыслу текущему документу. Если текущий документ посвящен, например, музыке, то, используя гиперссылки этого документа, вряд ли можно будет попасть на сайт, посвященный спорту.
3. Обращение к поисковому серверу (поисковой системе). Использование поисковых серверов — наиболее удобный способ поиска информации. В настоящее время в русскоязычной части Интернета популярны следующие поисковые серверы:
Yandex; Rambler; Апорт.
Существуют и другие поисковые системы. Например, эффективная система поиска реализована на сервере почтовой службы mail.ru.
Поисковые серверы
Наиболее доступным и удобным способом поиска информации во Всемирной паутине является использование поисковых систем. При этом поиск информации можно осуществлять по каталогам, а также по набору ключевых слов, характеризующих отыскиваемый текстовый документ.
Рассмотрим использование поисковых серверов более подробно. Поисковый сервер содержит большое количество ссылок на самые различные документы, и все эти ссылки систематизированы в тематические каталоги. Например: спорт, кино, автомобили, игры, наука и др. Причем эти ссылки устанавливаются сервером самостоятельно, в автоматическом режиме путем регулярного просмотра всех появляющихся во Всемирной паутине Web-страниц. Кроме того, поисковые серверы предоставляют пользователю возможность поиска информации по ключевым словам. После ввода ключевых слов поисковый сервер начинает просматривать документы на других Web-серверах и выводить на экран ссылки на те документы, в которых встретились указанные слова. Обычно результаты поиска сортируются по убыванию специального рейтинга документов, который показывает, насколько полно заданный документ отвечает условиям поиска или насколько часто он запрашивается в сети.
Язык запросов поисковой системы
Группа ключевых слов, сформированная по определенным правилам — с помощью языка запросов, называется запросом к поисковому серверу. Языки запросов к разным поисковым серверам очень похожи. Подробнее об этом можно узнать, посетив раздел «Помощь» нужного поискового сервера. Рассмотрим правила формирования запросов на примере поисковой системы Яndex.
Синтаксис оператора | Что означает оператор | Пример запроса |
пробел или & | Логическое И (в пределах предложения) | лечебная физкультура |
&& | Логическое И (в пределах документа) | рецепты && (плавленый сыр) |
| | Логическое ИЛИ | фото | фотография | снимок | фотоизображение |
+ | Обязательное наличие слова в найденном документе | +быть или +не быть |
( ) | Группирование слов | (технология | изготовление) (сыра | творога) |
~ | Бинарный оператор И НЕ (в пределах предложения) | банки ~ закон |
~~ или _ | Бинарный оператор И НЕ (в пределах документа) | путеводитель по Парижу ~~ (агентство | тур) |
/(n m) | Расстояние в словах (минус (-) — назад, плюс (+) — вперед) | поставщики /2 кофе музыкальное /(-2 4) образование вакансии ~ /+1 студентов |
» « | Поиск фразы | «красная шапочка» Эквивалентно: красная /+1 шапочка |
&&/(n m) | Расстояние в предложениях (минус (-) — назад, плюс (+) — вперед) | банк && /1 налоги |
Чтобы получить лучшие результаты поиска, необходимо запомнить несколько простых правил:
1. Не искать информацию только по одному ключевому слову.
2. Лучше не вводить ключевые слова с прописной буквы, так как это может привести к тому, что не будут найдены те же слова, написанные со строчной буквы.
3. Если в итоге поиска вы не получили никаких результатов, проверьте, нет ли в ключевых словах орфографических ошибок.
Современные поисковые системы предоставляют возможность подключения к сформированному запросу семантического анализатора. С его помощью можно, введя какое-либо слово, выбрать документы, в которых встречаются производные от этого слова в различных падежах, временах и пр.
48 защита информации в компьютерных сетях
Объекты защиты информации в сети К объектам защиты информации в компьютерных сетях, подвергающихся наиболее интенсивному воздействию со стороны злоумышленников, относятся: сервера; рабочие станции; каналы связи; узлы коммутации сетей. Основными задачами серверов являются хранение и предоставление доступа к информации и некоторые виды сервисов. Следовательно, и все возможные цели злоумышленников можно классифицировать как получение доступа к информации, получение несанкционированного доступа к услугам, попытка вывода из рабочего режима определенного класса услуг, попытка изменения информации или услуг, как вспомогательный этап какой-либо более крупной атаки. Попытки получения доступа к информации, находящейся на сервере, в принципе ничем не отличаются от подобных попыток для рабочих станций, и мы рассмотрим их позднее. Проблема получения несанкционированного доступа к услугам принимает чрезвычайно разнообразные формы и основывается в основном на ошибках или недокументированных возможностях самого программного обеспечения, предоставляющего подобные услуги. Основной целью атаки рабочей станции является, конечно, получение данных, обрабатываемых, либо локально хранимых на ней. А основным средством подобных атак до сих пор остаются «троянские» программы. Эти программы по своей структуре ничем не отличаются от компьютерных вирусов, однако при попадании на ЭВМ стараются вести себя как можно незаметнее. При этом они позволяют любому постороннему лицу, знающему протокол работы с данной троянской программой, производить удаленно с ЭВМ любые действия. То есть основной целью работы подобных программ является разрушение системы сетевой защиты станции изнутри – пробивание в ней огромной бреши. Для борьбы с троянскими программами используется как обычное антивирусное ПО, так и несколько специфичных методов, ориентированных исключительно на них. В отношении первого метода как и с компьютерными вирусами необходимо помнить, что антивирусное ПО обнаруживает огромное количество вирусов, но только таких, которые широко разошлись по стране и имели многочисленные преценденты заражения. В тех же случаях, когда вирус или троянская программа пишется с целью получения доступа именно к Вашей ЭВМ или корпоративной сети, то она практически с вероятностью 90% не будет обнаружена стандартным антивирусным ПО. Каналы связи Естественно, основным видом атак на среду передачи информации является ее прослушивание. В отношении возможности прослушивания все линии связи делятся на: широковещательные с неограниченным доступом широковещательные с ограниченным доступом каналы «точка-точка» Узлы коммутации сетей Узлы коммутации сетей представляют интерес для злоумышленников 1) как инструмент маршрутизации сетевого трафика, 2) как необходимый компонент работоспособности сети. Защита информации в сети Internet Наибольший риск подвергнуться атаке со стороны внешних злоумышленников возникает в случае, если ваш компьютер, или локальная, или корпоративная сеть предприятия подключена в публичную глобальную сеть. Самой большой публичной глобальной сетью является Internet. Многие корпоративные сети используют каналы Internet для объединения удаленных частей сети. Широкое распространение получили корпоративные intranet–сети, основанные на использование технологий Internet. От злоумышленников страдают в основном информационные ресурсы предприятий, которые имеют постоянные соединения с Интернет и используют постоянные IP-адреса, по которым можно атаковать внутренние корпоративные сайты. Пользователи же Интернет, соединяющиеся с Интернет по модему на небольшое время и использующие временный IP-адрес, предоставляемый провайдером на период сессии, могут пострадать только от почтовых вирусов или от «дырок» в системе мгновенных сообщений, такой как ICQ. С этой точки зрения представляют интерес механизмы защиты, используемые в Internet.
49 безопасность сетей
Обеспечение безопасности сети требует постоянной работы и пристального внимания к деталям. Пока «в Багдаде все спокойно», эта работа заключается в предсказании возможных действий злоумышленников, планировании мер защиты и постоянном обучении пользователей. Если же вторжение состоялось, то администратор безопасности должен обнаружить брешь в системе защиты, ее причину и метод вторжения
Формируя политику обеспечения безопасности, администратор прежде всего проводит инвентаризацию ресурсов, защита которых планируется; идентифицирует пользователей, которым требуется доступ к каждому из этих ресурсов, и выясняет наиболее вероятные источники опасности для каждого из этих ресурсов. Имея эту информацию, можно приступать к построению политики обеспечения безопасности, которую пользователи будут обязаны выполнять.
Политика обеспечения безопасности — это не обычные правила, которые и так всем понятны. Она должна быть представлена в форме серьезного печатного документа. А чтобы постоянно напоминать пользователям о важности обеспечения безопасности, можно разослать копии этого документа по всему офису, чтобы эти правила всегда были перед глазами сотрудников.
Хорошая политика обеспечения безопасности включает несколько элементов, в том числе следующие:
Оценка риска. Что именно мы защищаем и от кого? Нужно идентифицировать ценности, находящиеся в сети, и возможные источники проблем.
Ответственность. Необходимо указать ответственных за принятие тех или иных мер по обеспечению безопасности, начиная от утверждения новых учетных записей и заканчивая расследованием нарушений.
Правила использования сетевых ресурсов. В политике должно быть прямо сказано, что пользователи не имеют права употреблять информацию не по назначению, использовать сеть в личных целях, а также намеренно причинять ущерб сети или размещенной в ней информации.
Юридические аспекты. Необходимо проконсультироваться с юристом и выяснить все вопросы, которые могут иметь отношение к хранящейся или генерируемой в сети информации, и включить эти сведения в документы по обеспечению безопасности.
Процедуры по восстановлению системы защиты. Следует указать, что должно быть сделано в случае нарушения системы защиты и какие действия будут предприняты против тех, кто стал причиной такого нарушения.
Поиск с запретами — Википедия
Поиск с запретами или табу-поиск является мета-алгоритмом поиска, использующим методы локального поиска, используемые для математической оптимизации. Алгоритм создал Фред У. Гловер в 1986[1] и формализовал в 1989[2][3]
Локальный поиск (по соседям) берёт потенциальное решение задачи и проверяет его непосредственных соседей (то есть решения, которые похожи, за исключением нескольких очень малых деталей) в надежде нахождения улучшенного решения. Методы локального поиска имеют тенденцию застрять в подоптимальных областях или плато, где многие решения равно подходят.
Поиск с запретами улучшает производительность локального поиска путём ослабления его основного правила. Для начала, на каждом шаге может быть принято ухудшение, если нет никакого улучшения (подобно случаю, когда поиск застревает на локальном минимуме). Кроме того, запреты (они же табу) вводятся для того, чтобы воспрепятствовать поиску по уже посещённым решениям.
Реализация поиска с запретами использует структуры, которые описывают посещённые решения или пользовательские наборы правил[2]. Если потенциальное решение было посещено во время некоторого короткого срока или оно нарушает правило, его помечают как «табу», так что алгоритм не будет рассматривать решение повторно.
Слово табу происходит от тонганского слова, означающего вещи, которые нельзя трогать, поскольку они священны[4].
Поиск с запретами является мета-алгоритмом, который может быть использован для решения задач комбинаторной оптимизации (задачи, где нужно найти оптимальное упорядочение и выбор опций).
Текущие приложения поиска с запретами распространяется на такие области, как планирования ресурсов, телекоммуникации, разработка СБИС, финансовый анализ, составление расписаний, пространственное планирование, распределение энергии, молекулярная инженерия, логистика, классификация образов, гибкое производство, утилизация отходов, поиск полезных ископаемых, биомедицинский анализ, защита окружающей среды и многие другие. В последние годы журналы во многих областях науки публиковали учебные статьи и вычислительные исследования, показывающие успех поиска с запретами в расширении границ задач, которые могут быть решены эффективно, давая решения, качество которых часто существенно превосходило решения, полученные применяемыми до этих пор методами. Обширный список приложений, включая итоговое описание полученного результата от практического применения, можно найти в статье Гловера и Лагуны[5]. Современные разработки по поиску с запретами и приложения можно найти в статье Tabu Search Vignettes.
Поиск с запретами использует процедуру локального поиска или поиска по соседям, чтобы итеративно продвигаться от одного потенциального решения x{\displaystyle x} к улучшенному решению x′{\displaystyle x’} в окрестности x{\displaystyle x}, пока не достигнем выполнения некоторого остановочного критерия (обычно это количество итераций или порог целевой оценки). Процедуры локального поиска часто застревают в областях с плохими целевыми оценками или в областях, где оценка образует плато (ровную горизонтальную поверхность). Чтобы избежать этих ловушек и исследовать области пространства поиска, которые остались бы нерассмотренными другими процедурами поиска, поиск с запретами тщательно исследует соседство каждого решения в процессе поиска. Решения, признанные новыми соседями, N∗(x){\displaystyle N^{*}(x)}, определяются с помощью структур в памяти. Используя эти структуры, поиск прогрессирует путём итеративного перехода от текущего решения x{\displaystyle x} к улучшенному решению x′{\displaystyle x’} из списка N∗(x){\displaystyle N^{*}(x)}.
Эти структуры образуют так называемые табу-списки, множество правил и помеченных решений, используемых для фильтрации, какие решения из соседей N∗(x){\displaystyle N^{*}(x)} обрабатывать при поиске. В простейшей форме табу-список является краткосрочным набором решений, которые были посещены за последние итерации (менее чем за n{\displaystyle n} итераций, где n{\displaystyle n} равно числу запоминаемых решений и это число называется сроком действия табу). Более часто табу-лист состоит из решений, которые были изменены в процессе перехода от одного решения к другому. Удобно для простоты изложения понимать «решение» закодированным и представленным некоторыми атрибутами.
Структуры памяти, используемые в поиске с запретами, можно грубо разбить на три категории[6]:
- Краткосрочные: Список недавно рассмотренных решений. Если потенциальное решение оказывается в списке запрещённых, оно не может быть посещено второй раз, пока не достигнем истечения срока действия запрета.
- Среднесрочные: Правила усиления, предназначенные для смещения поиска в сторону перспективных областей пространства поиска.
- Долгосрочные: Правила расширения, которые ведут поиск в новые области (то есть относящиеся к сбросу, когда поиск застревает на плато иди подоптимальном тупике).
Краткосрочные, среднесрочные и долгосрочные списки могут перекрываться. Внутри этих категорий память может далее дифференцироваться по критериям, таким как частота и воздействие сделанных изменений. Одним из примеров среднесрочной структуры является запрет или поощрение решений, которые содержат некоторые атрибуты (например, решения, которые включают нежелательные или желательные значения некоторых определённых переменных) или структура памяти, которая предотвращает или порождает некоторые движения (например, основываясь на частоте встречающихся признаков в перспективных и неперспективных решения, найденных ранее). В краткосрочной памяти выбранные атрибуты в недавно посещённых решениях помечаются «табу-активными». Использование решений с табу-активными элементами запрещается. Для изменения статуса табу решения используется критерий удаления, включая исключённые решения в разрешённый список (решение «достаточно хорошо» согласно мере качества или различия). Простым и обычно используемым критерием удаления является разрешение использования решений, которые лучше известного на данный момент лучшего решения.
Краткосрочная память одна может оказаться достаточной для получения решения, превосходящего найденное обычными методами локального поиска, но среднесрочные и долгосрочные структуры часто необходимы для решения более сложных задач[7]. Поиск с запретами часто сравнивается с другими мета-алгоритмическими методами — такими как алгоритм имитации отжига, генетические алгоритмы, муравьиные алгоритмы, реагирующий поиск, управляемый локальный поиск или жадный адаптивный случайный поиск[en]. Кроме того, поиск с запретами иногда комбинируется с другими мета-алгоритмами для создания гибридных методов. Наиболее частый гибрид поиска с запретами возникает путём соединения его с разбросанным поиском (англ. Scatter Search)[8][9], классом процедур, которые имеют общие корни с поиском с запретами и которые часто применяются для решения нелинейных оптимизационных задач большого размера.
Следующий псевдокод представляет упрощённую версию алгоритма поиска с запретами, как описано выше. Эта реализация имеет простейший вариант краткосрочной памяти и не содержит среднесрочных или долгосрочных структур. Термин «fitness» относится к вычислению целевой функции для кандидата в решения.
1 sBest ← s0 2 bestCandidate ← s0 3 tabuList ← [] 4 tabuList.push(s0) 5 while (not stoppingCondition()) 6 sNeighborhood ← getNeighbors(bestCandidate) 7 for (sCandidate in sNeighborhood) 8 if ( (not tabuList.contains(sCandidate)) and (fitness(sCandidate) > fitness(bestCandidate)) ) 9 bestCandidate ← sCandidate 10 end 11 end 12 if (fitness(bestCandidate) > fitness(sBest)) 13 sBest ← bestCandidate 14 end 15 tabuList.push(bestCandidate) 16 if (tabuList.size > maxTabuSize) 17 tabuList.removeFirst() 18 end 19 end 20 return sBest
Строки 1—4 делают начальные присвоения, создавая начальное решение (возможно, полученное методами случайного поиска), устанавливают полученное решение как первое просмотренное и инициализируют табу-список этим решением. В этом примере табу-список является просто краткосрочной структурой, которая содержит записи посещённых элементов.
Основной цикл начинается со строки 5. Этот цикл продолжает поиск оптимального решения, пока не получит заданного пользователем критерия останова (двумя примерами такого критерия являются просто ограничение по времени или порог оценки годности (fitness score)). Соседние решения проверяются на табу в строке 8. Кроме того, алгоритм хранит лучшие незапрещённые решения по соседям.
Целевая функция fitness обычно является математической функцией, которая возвращает целевую оценку или критерий — например, целевым критерием может считаться нахождение нового пространства поиска[4]. Если лучший локальный кандидат имеет более высокое значение функции fitness, то текущее значение лучшее (строка 12), оно теперь принимается в качестве лучшего (строка 13). Локальный лучший кандидат всегда добавляется в табу-список (строка 15) и если табу-список полон (строка 16), табу некоторого элемента считается истекшим (строка 17). Обычно элементы удаляются из списка в порядке их занесения в него. Процедура выбирает лучшего локального кандидата (хотя он имеет значение fitness хуже, чем sBest), чтобы выскочить из локального оптимума.
Этот процесс продолжается, пока не получим определённый пользователем критерий останова, и в этот момент возвращается лучшее решение, встреченное в процессе (строка 20).
Задача коммивояжёра иногда используется, чтобы показать работу поиска с запретами[7]. Эта задача спрашивает, если дан список городов, каков кратчайший маршрут для посещения всех городов? Например, если город A и город B находятся близко друг от друга, а город C отстоит о них далеко, общая длина маршрута будет короче, если мы сначала посетим A и B, а затем отправимся в город C. Поскольку нахождение оптимального решения NP-трудно, для получения близкого к оптимальному решения полезны основанные на эвристике приближённые методы (такие как локальный поиск). Для получения хороших решений задачи коммивояжёра важно исследовать структуру графа. Значение исследования структуры задачи является повторяющейся темой в мета-алгоритмических методах, а поиск с запретами хорошо подходит для этого. Класс стратегий, связанный с поиском с запретами и называемый методами извлечения цепочек (англ. ejection chain methods), дают возможность получить высококачественные решения задачи коммивояжёра эффективно[10].
С другой стороны, простой поиск с запретами может быть использован для поиска удовлетворительного[en] решения для задачи коммивояжёра (то есть решения, удовлетворяющего критерию пригодности, хотя и невысокого качества, которое получается после исследования структуры графа). Поиск начинается с начального решения, которое может быть получено случайным образом или согласно некоего рода алгоритму поиска ближайшего соседа. Чтобы создать новые решения, порядок, в котором города посещаются, в потенциальном решении обмениваются местами. Полное расстояние маршрута между всеми городами используется для сравнения, насколько лучше одно решение другого. Чтобы предотвратить зацикливание, то есть повторного получения определённого набора решений, и застревание в локальном оптимуме, решение добавляется в список запрещённых решений, если оно принято при поиске среди соседей, N∗(x){\displaystyle N^{*}(x)}.
Новые решения создаются, пока не достигнем некоторого критерия остановки, такого как число итераций. Как только простой поиск с запретами останавливается, он возвращает лучшее решение, найденное при выполнении.
- ↑ Glover, 1986, с. 533–549.
- ↑ 1 2 Glover, 1989, с. 190–206.
- ↑ Glover, 1990, с. 4–32.
- ↑ 1 2 http://www.ise.ncsu.edu/fangroup/ie789.dir/IE789F_tabu.pdf
- ↑ Glover, Laguna, 1997.
- ↑ Glover/A Tutorial, 1990.
- ↑ 1 2 Malek, Huruswamy, Owens, Pandya, 1989.
- ↑ Glover, Laguna, Marti, 2000, с. 653–684.
- ↑ Laguna, Marti, 2003.
- ↑ Gamboa, Rego, Glover, 2005, с. 154–171.
- Fred Glover. Future Paths for Integer Programming and Links to Artificial Intelligence // Computers and Operations Research. — 1986. — Т. 13, вып. 5. — DOI:10.1016/0305-0548(86)90048-1.
- Fred Glover. Tabu Search – Part 1 // ORSA Journal on Computing. — 1989. — Т. 1, вып. 2. — DOI:10.1287/ijoc.1.3.190.
- Fred Glover. Tabu Search – Part 2 // ORSA Journal on Computing. — 1990. — Т. 2, вып. 1. — DOI:10.1287/ijoc.2.1.4.
- Gamboa D., Rego C., Glover F. Data Structures and Ejection Chains for Solving Large Scale Traveling Salesman Problems // European Journal of Operational Research. — 2005. — Т. 160, вып. 1. — DOI:10.1016/j.ejor.2004.04.023.
- Glover F., Laguna M. Tabu Search. — Kluwer Academic Publishers. — 1997.
- Fred Glover. Tabu Search: A Tutorial // Interfaces. — 1990.
- Malek M., Huruswamy M., Owens H., Pandya M. Serial and parallel search techniques for the traveling salesman problem. — Annals of OR: Linkages with Artificial Intelligence. — 1989.
- Glover F., Laguna M., Marti R. Fundamentals of Scatter Search and Path Relinking. — Control and Cybernetics. — 2000. — Т. 29. — С. 653–684.
- Laguna M., Marti R. Scatter Search: Methodology and Implementations in C. — Kluwer Academic Publishers, Boston. — 2003.