
что это такое и зачем используется?
В современных устройствах применяется графический процессор, который еще обозначают как GPU. Что это и каков его принцип работы? GPU (Graphics Processing Unit) — процессор, основная задача которого — обработка графики и вычислений с плавающей точкой. GPU облегчает работу главного процессора, если идет речь о тяжелых играх и приложениях с 3D-графикой.

Что это?
Графический процессор создает графику, текстуры, цвета. Процессор, который обладает несколькими ядрами, может работать на высоких скоростях. У графического много ядер, функционирующих преимущественно на низких скоростях. Они занимаются вычислениями пикселей и вершин. Обработка последних в основном происходит в системе координат. Процессор графический обрабатывает различные задачи, создавая на экране трехмерное пространство, то есть объекты в нем перемещаются.
Принцип работы
Что делает графический процессор? Он занимается обработкой графики в формате 2D и 3D. Благодаря GPU компьютеру быстрее и легче удается выполнять важные задачи. Особенность графического процессора состоит в том, что он увеличивает скорость расчета графической информации на максимальном уровне. Его архитектура устроена так, что позволяет более эффективно обрабатывать визуальную информацию, чем центральный CPU компьютера.
Он отвечает за расположение трехмерных моделей в кадре. Кроме того, каждый из типов графического процессора фильтрует треугольники, входящие в него. Он определяет, какие на виду, удаляет те, которые скрываются за другими объектами. Прорисовывает источники света, определяет, каким образом эти источники влияют на цвет. Графический процессор (что это такое — описано в статье) создает изображение, выдает его пользователю на экран.

Эффективность работы
Чем обусловлена эффективная работа графического процессора? Температурой. Одна из проблем ПК и ноутбуков — перегрев. Именно это становится главной причиной того, почему устройство и его элементы быстро выходят из строя. Проблемы с GPU начинаются, когда температура процессора превышает 65 °С. В этом случае пользователи замечают, что процессор начинает работать слабее, пропускает такты, чтобы самостоятельно понизить увеличенную температуру.
Температурный режим 65-80 °С — критический. В этом случае начинается перезагрузка системы (аварийная), компьютер выключается самостоятельно. Пользователю важно отслеживать, чтобы температура графического процессора не превышала 50 °С. Нормальной считается t 30-35 °С в простое, 40-45 °С при многочасовой нагрузке. Чем ниже температура, тем выше производительность компьютера. Для материнской платы, видеокарты, корпуса и жестких дисков — свои температурные режимы.
Но многих пользователей также беспокоит вопрос, как же уменьшить температуру процессора, чтобы повысить эффективность его работы. Для начала нужно выяснить причину перегрева. Это может быть засорение системы охлаждения, высохшая термопаста, вредоносная программа, разгон процессора, сырая прошивка БИОСа. Самое простое, что может сделать пользователь, — это заменить термопасту, которая находится на самом процессоре. Кроме того, нужно произвести чистку системы охлаждения. Еще специалисты советуют установить мощный кулер, улучшить циркуляцию воздуха в системном блоке, увеличить скорость вращения на графическом адаптере кулера. Для всех компьютеров и графических процессоров одинаковая схема понижения температуры. Важно следить за устройством, вовремя его чистить.

Специфика
Графический процессор расположен на видеокарте, его главная задача — это обработка 2D и 3D графики. Если на компьютере установлен GPU, то процессор устройства не выполняет лишнюю работу, поэтому функционирует быстрее. Главная особенность графического в том, что его основная цель — это увеличение скорости расчета объектов и текстур, то есть графической информации. Архитектура процессора позволяет им работать намного эффективнее, обрабатывать визуальную информацию. Обычному процессору такое не под силу.
Виды
Что это — графический процессор? Это компонент, входящий в состав видеокарты. Существует несколько видов чипов: встроенный и дискретный. Специалисты утверждают, что лучше справляется со своей задачей второй. Его устанавливают на отдельные модули, так как отличается он своей мощью, но ему необходимо отличное охлаждение. Встроенный графический процессор есть практически во всех компьютерах. Его устанавливают в CPU, чтобы сделать потребление энергии в несколько раз ниже. С дискретными по мощи он не сравнится, но тоже обладает хорошими характеристиками, демонстрирует неплохие результаты.

Компьютерная графика
Это что? Так называется область деятельности, в которой для создания изображений и обработки визуальной информации используют компьютерные технологии. Современная компьютерная графика, в том числе научная, позволяет графически обрабатывать результаты, строить диаграммы, графики, чертежи, а также производить различного рода виртуальные эксперименты.
С помощью конструктивной графики создаются технические изделия. Существуют и другие виды компьютерной графики:
- анимационная;
- мультимедийная;
- художественная;
- рекламная;
- иллюстративная.
С технической точки зрения компьютерная графика — это двухмерные и трехмерные изображения.

CPU и GPU: разница
В чем разница между этими двумя обозначениями? Многие пользователи в курсе, что графический процессор (что это — рассказано выше) и видеокарта выполняют разные задачи. Кроме того, они отличаются по своей внутренней структуре. И CPU, и GPU — это процессоры, которые обладают многими сходными чертами, но сделаны они для разных целей.
CPU выполняет определенную цепочку инструкций за короткий промежуток времени. Он сделан так, что формирует одновременно несколько цепочек, разбивает поток инструкций на множество, выполняет их, затем снова сливает в одно целое в конкретном порядке. Инструкция в потоке находится в зависимости от тех, что за ней следуют, поэтому в CPU содержится малое число исполнительных блоков, здесь главный приоритет отдается скорости выполнения, уменьшению простоев. Все это достигается при помощи конвейера и кэш-памяти.

У GPU другая важная функция — рендеринг визуальных эффектов и 3D-графики. Работает он проще: на входе получает полигоны, проводит необходимые логические и математические операции, на выходе выдает координаты пикселей. Работа GPU — это оперирование большим потоком разных задач. Его особенность в том, что он наделен большим объемом памяти, но медленно работает по сравнению с CPU. Кроме того, в современных GPU более 2000 исполнительных блоков. Отличаются они между собой методами доступа к памяти. Например, графическому не нужна кэшированная память большого размера. У GPU пропускная способность больше. Если объяснять простыми словами, то CPU принимает решения в соответствии с задачами программы, а GPU производит множество одинаковых вычислений.
Как разогнать видеокарту и зачем это делать | Видеокарты | Блог
Ответ на вопрос «Зачем?» можно свести к одной простой фразе: чтобы повысить производительность.
Производительность компьютерных комплектующих, определяется количественными характеристиками. В случае с рабочими частотами видеокарт зависимость абсолютно прямая и линейная: чем выше частота — тем выше производительность.
Устройство всегда имеет «номинальный» режим работы. Но в каждом выпущенном на рынок чипе есть определенный запас по частотам. Насколько велик этот запас в цифрах — зависит исключительно от конкретного экземпляра, однако заводские частоты практически никогда не являются пределом возможностей.
Ярчайшим примером здесь будет частотная модель последних поколений видеокарт Nvidia — а точнее, чипов из семейств Pascal и Turing. У этих чипов есть базовая частота, которую вы никогда не увидите, а есть частота динамического разгона, которая и указывается в характеристиках, то есть гарантируется производителем для любых условий. А сверх этого есть еще технология GPU Boost, разгоняющая чип еще сильнее, если остается запас по температурам.
Как результат — вполне реальная GTX 1060, выпущенная одним из вендоров, имеет базовую частоту в 1506 МГц, динамический разгон до 1721 МГц, а в реальности умудряется работать в диапазоне от 1870 до 1910 МГц.
А если производитель считает нормальным изменять частоту чипа в столь широких пределах — почему бы рядовому пользователю не заняться тем же самым, тем более если для этого есть необходимый инструментарий?
Какой результат можно получить от разгона видеокарты?
Все линейки видеокарт проектируются таким образом, что даже при помощи разгона практически невозможно добиться от младшей карты производительности старшей. Например, разница в количестве исполнительных блоков между GTX 1660 Ti и RTX 2060 такова, что даже предельный разгон младшей модели не выдаст производительность, которую старшая показывает на номинальных для нее частотах.
Есть, разумеется, и единичные исключения — например, Radeon RX 570 в разгоне может и догонять, и обходить номинальный Radeon RX 580, но такие случаи встречаются редко.
Любой разгон должен быть оправдан практически.
Для примера: если вы используете видеокарты начального класса, вроде Radeon R5 230 или GeForce GT 710, и в более-менее новых играх получаете всего 12 кадров в секунду — разгон, вероятно, позволит получить 14–15 кадров. Кардинально ничего не меняется, геймплей не становится комфортным.
Обратный пример: если в вашем компьютере установлены видеокарты флагманского уровня, вроде Radeon VII или GeForce RTX 2080 Ti, и при любых настройках графики вы получаете более 60 кадров в секунду даже в разрешениях 2K и 4K — лучше забыть о разгоне и наслаждаться непосредственно игровым процессом. Разницы между условными 110 и 120 кадрами в секунду вы также не ощутите.
Разгон действительно оправдан, если вам не хватает производительности, чтобы геймплей был комфортным на выбранных настройках графики, или чтобы попробовать более высокие настройки и/или разрешения экрана. Разница между 45 и 50 кадрами может казаться несущественной на бумаге, но в игре очень хорошо заметна.
Наглядный пример — реальная GeForce GTX 1660 Ti. И два разрешения экрана при одинаковых настройках:
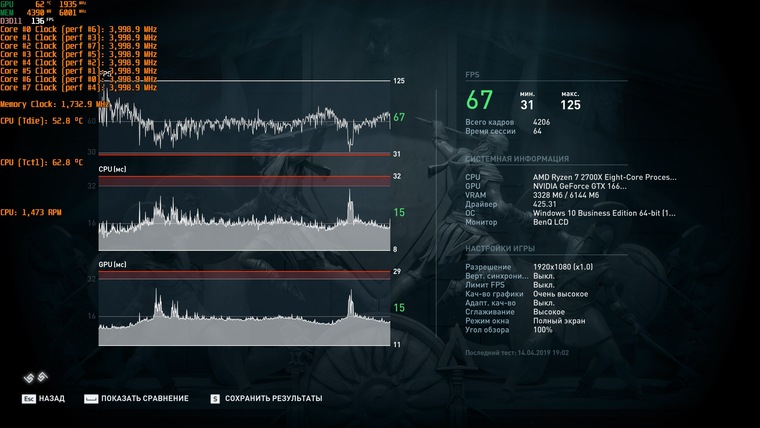
Full HD, номинальный режим
Full HD, режим разгона
В Full HD от разгона получили 71 FPS вместо 67. Играть одинаково комфортно в обоих случаях, и разница в количестве кадров не ощутима.
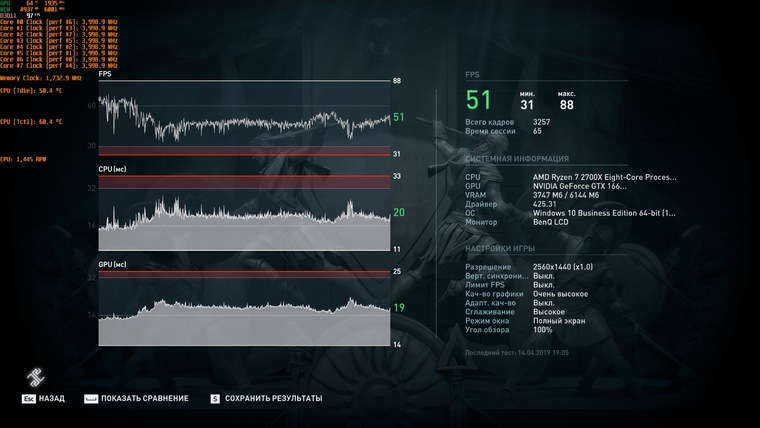
2К, номинальный режим
2К, режим разгона
А в случае разрешения 2K мы говорим о разнице между 51 и 55 FPS. И хотя кажется, что здесь разница столь же незначительна — это отнюдь не так. Пределом комфортной игры считаются стабильные 60 кадров в секунду, и любое изменение, приближающее производительность к этому значению, ощутимо в реальной игре.
Если до 60 FPS не хватает совсем немного — разгон действительно поможет.
Теория работы и разгона видеокарты
Разгон видеокарты — это программное изменение её параметров при помощи специализированных утилит.
При разгоне важно понять пять параметров, которые и придется менять:
1) Частота графического процессора (Core Clock).
Тут, на первый взгляд, все просто: чем выше частота — тем выше производительность. Но с повышением частоты возрастает энергопотребление и нагрев чипа, и одновременно с этим – требования к напряжению на нём.
При разгоне современных видеокарт Nvidia и AMD по графическому чипу вы задаете им отнюдь не конкретное значение частоты, на котором они будут работать.
Для видеокарт Nvidia задается некий модификатор, добавляющий указанное значение к их базовой частоте. Частота под нагрузкой по-прежнему определяется технологией GPU Boost, и может изменяться на меньший шаг, нежели заданное значение.
Для видеокарт AMD семейств Vega и Navi задается уже конкретное значение частоты, но это значение является лишь верхней границей, за которую карта не перешагнет. Фактическая же частота чипа под нагрузкой будет зависеть от его температуры, напряжения и близости к лимиту энергопотребления.
2) Лимит энергопотребления (Power Limit)
Следующий, более важный пункт при разгоне графического процессора — доступный видеокарте лимит энергопотребления.
Как и любой электрический прибор, видеокарта призвана выполнять определенную задачу, затрачивая на это определенное количество энергии. Для современных карт это количество лимитировано, причем ограничение закладывается программным методом на уровне биос.
Для примера, если в BIOS видеокарты заложен лимит энергопотребления в 200 Вт, то в своем штатном состоянии больше 200 Вт она никак не съест, сколько бы противоположных комментариев про нее не было написано на форумах и в карточках товара магазинов. Если фактическое энергопотребление под нагрузкой превысит 200 Вт — карта начнет сбрасывать частоты, чтобы остаться в пределах программного лимита.
На практике это означает, что при разгоне лимит энергопотребления необходимо увеличивать. Как правило, программным методом его можно повысить на 50% от штатного значения, но бывают и исключения. Ещё не факт, что вам потребуется поднимать его до предела — всё будет зависеть от реального потребления карты в режиме разгона.
3) Напряжение на GPU и памяти (Core Voltage)
Уровень энергопотребления любого чипа зависит не только от его тактовой частоты, но и от напряжения, при котором этот чип работает. Чем оно выше — тем выше энергопотребление и сильнее нагрев, но выше и частотный потенциал разгона.
Возьмем, например, видеокарту Radeon RX 5700 в референсном дизайне. В номинале GPU этой видеокарты работает на частоте в 1750 МГц при напряжении в 1.02 В. На этой же частоте GPU стабильно работает и при 0.98 В, но вот разгон до 2100 МГц возможен уже только при поднятии напряжения до 1.19 В.

Штатный режим с понижением напряжения
Разгон с повышением напряжения
Далеко не все видеокарты допускают изменение напряжения программными средствами, что ограничивает предел разгона.
4) Частота памяти (Memory Clock)
С разгоном памяти все просто. Параметры частоты фиксированы, и если вы задаете условные 2000 МГц базовой частоты — то 2000 МГц вы и получаете под нагрузкой.
Нюанс в том, что чипы на видеокарте имеют понятие реальной и эффективной частоты. Эффективная указывается в рекламных материалах, а при разгоне меняется как раз реальная. Для памяти стандарта GDDR5 эффективная частота в 4 раза выше реальной, то есть вышеупомянутые реальные 2000 МГц дают эффективные 8000 МГц. Для памяти GDDR6 умножать надо уже не на 4, а на 8 — эффективные 14 000 МГц на деле оказываются 1750 МГц.
5) Скорость вентилятора (Fan Speed)
Видеокарту нужно разгонять собственным вентилятором, без шуток. Даже если вы правильно настроите напряжение и лимит энергопотребления, карта может не выйти на ожидаемые частоты, если упрется в потолок по температуре.
Повлиять на температуру видеокарты в разгоне можно лишь одним программным способом: задать повышенную скорость вращения вентилятора. Но, разумеется, уровень шума тоже увеличится.
Готовимся к разгону
Прежде всего — удостоверьтесь, что карте обеспечено достаточное охлаждение. Если разгон упрется в программные лимиты по температурам — карта будет снижать частоты, и никакого эффекта от разгона не будет. Проверьте температуру в штатном режиме: если она близка к 90 градусам или даже выше — забудьте о повышении частот и обеспечьте карте более комфортные условия.
Вмешиваться в конструкцию самой карты не придется, но раскрутить системный блок, вероятно, потребуется. Наладьте вентиляцию в корпусе, уложите провода так, чтобы они не мешали движению воздуха, переставьте системный блок подальше от батареи и ни в коем случае не устанавливайте его в глухие ниши «компьютерных» столов, которые не вентилируются.

Если видеокарта уже работает у вас длительное время — стоит хотя бы почистить её радиатор от скопившейся пыли, а лучше — еще заменить термопасту на графическом процессоре и термопрокладки на прочих элементах. Если собственного опыта недостаточно, любые профилактические работы можно сделать в авторизированном сервис-центре — так и гарантия сохранится.
Убедитесь в том, что мощности вашего блока питания достаточно. Стоит изучить данные о фактическом энергопотреблении вашей модели видеокарты в номинале и в разгоне, а также спецификации и обзоры на ваш блок питания. Если запаса по мощности мало, от разгона лучше отказаться.
Современное «железо» обладает завидным запасом прочности и крайне высокой степенью защиты от действий пользователя — вывести из строя ту же видеокарту при разгоне программными методами очень сложно. А вот блок питания, работающий на пределе и уходящий в защиту от перегрузки, это уже серьезная проблема.
Запасаемся инструментами для разгона
В общем случае, потребуются три отдельные утилиты: для изменения параметров видеокарты, мониторинга показателей, проверки результата. На деле же во многие «тюнеры» мониторинг и простые стресс-тесты зачастую уже встроены.
Софт для разгона
Выбор утилиты, с помощью которой вы будете управлять параметрами видеокарты, зависит исключительно от того, в какой программе вам лично удобнее работать: функционал у них примерно одинаков, различия заключаются в интерфейсе и, очень редко, — в перечне поддерживаемых видеокарт.
Для видеокарт AMD дополнительный софт не обязателен — все операции по разгону, изменению напряжений, лимитов энергопотребления, температур и даже скорости вентиляторов, можно выполнить напрямую из драйвера. Точнее, из надстройки Radeon Settings. При желании можно менять параметры, даже находясь в игре — для этого программу можно вызвать в оверлей нажатием комбинации клавиш.
Впрочем, если вы привыкли к другому интерфейсу — никто не запретит использовать сторонние программы. Как фирменные, вроде MSI Afterburner или Sapphire Trixx, так и написанные сторонними энтузиастами, вроде OverdriveNTool.
Для видеокарт Nvidia лучше использовать как раз сторонний софт — MSI Afterburner, Gigabyte AORUS Engine, Asus GPU Tweak или даже EVGA Precision X. Подобные утилиты есть практически у всех вендоров, причем не обязательно, чтобы производитель утилиты соответствовал производителю видеокарты.
Софт для мониторинга
В процессе разгона необходимо вести мониторинг параметров видеокарты, чтобы иметь представление обо всех изменениях, к которым приводят ваши действия. Разумеется, подобный функционал есть и в самих утилитах для разгона, но не всегда они могут прочесть показания всех нужных датчиков. Поэтому оптимальнее использовать специализированное ПО для мониторинга.
Например, GPU-Z или Hwinfo64. Последняя любопытна прежде всего тем, что постоянно обновляется, получая сведения о новых видеокартах и новых датчиках на них. Кроме того, агрегировав её с тем же MSI Afterburner, можно вывести все интересующие вас параметры в оверлей и контролировать частоты и температуры непосредственно из игры.

Софт для тестов
Разгон предполагает не только изменение и мониторинг параметров видеокарты, но и тестирование изменений на стабильность.
Разумеется, проверить стабильность карты можно и в играх — но для этого потребуется больше времени, да и условия могут быть не самыми подходящими. Например, в одной тестовой игре карта может быть абсолютно стабильной, а в другой — вылетать уже на этапе загрузки уровня.
Поэтому лучше использовать специализированные бенчмарки, прямая задача которых — создание экстремальной нагрузки на видеокарту.
В случае сравнительно старых видеокарт пальму первенства здесь удерживает «пушистый бублик» — FurMark до сих пор умудряется нагревать их так, как не может ни одна современная игра или тест видеокарты.
А вот если речь идет о современных графических чипах, оснащенных технологиями энергосбережения, FurMark не помощник — карты воспринимают его как экстремальную нагрузку, и не выходят на максимальные для них частоты.
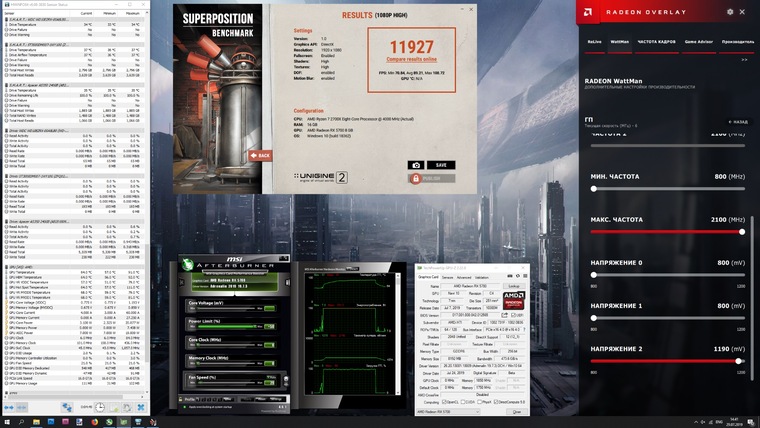
Для проверки современных видеокарт лучше подойдет бенчмарк от компании Unigine — тест Superposition. Он очень быстро грузится и создает достаточно серьезную нагрузку на видеокарту, чтобы выявить возможную нестабильность буквально в первые минуты, а не спустя несколько часов игры.

В приведенных выше картинках обоих бенчмарков тестировался современный Radeon RX 5700 XT. Что примечательно, частота GPU в «пушистом бублике» FurMark лишь чуть выше 1500 МГц, тогда как в Superposition — более 1900 МГц. Разумеется, данные теста Unigine Superposition более достоверные.
Переходим к практике
Рассмотрим изложенные выше тезисы на примере двух современных видеокарт от AMD и Nvidia, относящихся к одному ценовому сегменту и оснащенных сходными по конструкции системами охлаждения — GeForce RTX 2060 и Radeon RX 5700.
GeForce RTX 2060 не имеет заводского разгона, частотная модель полностью соответствует референсному экземпляру: 1365 МГц базовой частоты, динамический разгон до 1680 МГц, но на практике за счет технологии GPU Boost частота в течение теста составляет 1830 МГц.
Память работает на стандартной частоте в 1750 МГц (реальных).
Лимит энергопотребления GeForce RTX 2060 можно увеличить на 20% — и это вполне закономерно, поскольку у нее всего один разъем доппитания, и теоретический лимит энергопотребления составляет 225 Вт (75 по шине PCI-e + 150 Вт через разъем 8-pin). Изменение напряжения на GPU невозможно.
В тесте Superposition получаем результат в 10256 «условных попугаев».
Разгоняем GeForce RTX 2060: поднимаем лимит энергопотребления до максимума — это позволяет добавить 140 МГц к базовой частоте чипа и получить 1505 МГц базовых или 1820 МГц в динамическом разгоне. За счет технологии GPU Boost частота чипа возрастает до 1960–1990 МГц, но упирается уже в лимит температуры — 87 градусов на GPU. Дальнейший разгон возможен либо за счет принудительного повышения оборотов вентилятора, либо замены штатной СО на более эффективную.
К памяти можно добавить 218 реальных МГц — итоговая реальная частота составляет 1968 МГц. Дальнейшее повышение частоты невозможно, это предел потенциала самих чипов.
На разгоне без принудительного включения вентиляторов Superposition выдал 11140 «попугаев» и одно попугайское крылышко.

Radeon RX 5700 является референсным образцом, и его частотная модель полностью соответствует спецификациям AMD. Лимит частоты GPU — 1750 МГц, память работает на тех же 1750 реальных МГц.
Тест производительности выдает 10393 «попугая» в штатном режиме.
Разгоняем Radeon RX 5700: поднимаем напряжение со штатных 1,022 до 1,19 В. Лимит энергопотребления повышаем на 50%, верхний предел частоты GPU — до 2100 МГц, частоту памяти — до 1850 МГц (реальных). Все значения меняем через родной софт от AMD, кроме лимита энергопотребления — его «тюним» через MSI Afterburner. Частота памяти снова уперлась в предел самих чипов, а разгон GPU срезал температурный предел. Частота графического процессора RX 5700 в разгоне под нагрузкой колеблется в пределах 1980-2020 МГц.
Superposition за разгонные заслуги выдал 11927 «попугаев».
Вычисления на графических процессорах | Персональный блог | Дайджест новостей
Вычисления на графических процессорах
Технология CUDA (англ. Compute Unified Device Architecture) — программно-аппаратная архитектура, позволяющая производить вычисления с использованием графических процессоров NVIDIA, поддерживающих технологию GPGPU (произвольных вычислений на видеокартах). Архитектура CUDA впервые появились на рынке с выходом чипа NVIDIA восьмого поколения — G80 и присутствует во всех последующих сериях графических чипов, которые используются в семействах ускорителей GeForce, ION, Quadro и Tesla.
CUDA SDK позволяет программистам реализовывать на специальном упрощённом диалекте языка программирования Си алгоритмы, выполнимые на графических процессорах NVIDIA и включать специальные функции в текст программы на Cи. CUDA даёт разработчику возможность по своему усмотрению организовывать доступ к набору инструкций графического ускорителя и управлять его памятью, организовывать на нём сложные параллельные вычисления.
История
В 2003 г. Intel и AMD участвовали в совместной гонке за самый мощный процессор. За несколько лет в результате этой гонки тактовые частоты существенно выросли, особенно после выхода Intel Pentium 4.
После прироста тактовых частот (между 2001 и 2003 гг. тактовая частота Pentium 4 удвоилась с 1,5 до 3 ГГц), а пользователям пришлось довольствоваться десятыми долями гигагерц, которые вывели на рынок производители (с 2003 до 2005 гг.тактовые частоты увеличились 3 до 3,8 ГГц).
Архитектуры, оптимизированные под высокие тактовые частоты, та же Prescott, так же стали испытывать трудности, и не только производственные. Производители чипов столкнулись с проблемами преодоления законов физики. Некоторые аналитики даже предрекали, что закон Мура перестанет действовать. Но этого не произошло. Оригинальный смысл закона часто искажают, однако он касается числа транзисторов на поверхности кремниевого ядра. Долгое время повышение числа транзисторов в CPU сопровождалось соответствующим ростом производительности — что и привело к искажению смысла. Но затем ситуация усложнилась. Разработчики архитектуры CPU подошли к закону сокращения прироста: число транзисторов, которое требовалось добавить для нужного увеличения производительности, становилось всё большим, заводя в тупик.
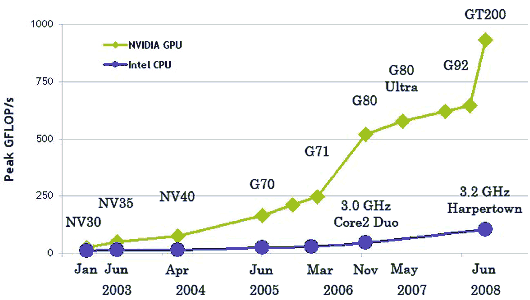
Причина, по которой производителям GPU не столкнулись с этой проблемой очень простая: центральные процессоры разрабатываются для получения максимальной производительности на потоке инструкций, которые обрабатывают разные данные (как целые числа, так и числа с плавающей запятой), производят случайный доступ к памяти и т.д. До сих пор разработчики пытаются обеспечить больший параллелизм инструкций — то есть выполнять как можно большее число инструкций параллельно. Так, например, с Pentium появилось суперскалярное выполнение, когда при некоторых условиях можно было выполнять две инструкции за такт. Pentium Pro получил внеочередное выполнение инструкций, позволившее оптимизировать работу вычислительных блоков. Проблема заключается в том, что у параллельного выполнения последовательного потока инструкций есть очевидные ограничения, поэтому слепое повышение числа вычислительных блоков не даёт выигрыша, поскольку большую часть времени они всё равно будут простаивать.
Работа GPU относительно простая. Она заключается в принятии группы полигонов с одной стороны и генерации группы пикселей с другой. Полигоны и пиксели независимы друг от друга, поэтому их можно обрабатывать параллельно. Таким образом, в GPU можно выделить крупную часть кристалла на вычислительные блоки, которые, в отличие от CPU, будут реально использоваться.
GPU отличается от CPU не только этим. Доступ к памяти в GPU очень связанный — если считывается тексель, то через несколько тактов будет считываться соседний тексель; когда записывается пиксель, то через несколько тактов будет записываться соседний. Разумно организуя память, можно получить производительность, близкую к теоретической пропускной способности. Это означает, что GPU, в отличие от CPU, не требуется огромного кэша, поскольку его роль заключается в ускорении операций текстурирования. Всё, что нужно, это несколько килобайт, содержащих несколько текселей, используемых в билинейных и трилинейных фильтрах.
Первые расчёты на GPU
Самые первые попытки такого применения ограничивались использованием некоторых аппаратных функций, таких, как растеризация и Z-буферизация. Но в нынешнем веке, с появлением шейдеров, начали ускорять вычисления матриц. В 2003 г. на SIGGRAPH отдельная секция была выделена под вычисления на GPU, и она получила название GPGPU (General-Purpose computation on GPU) — универсальные вычисления на GPU).
Наиболее известен BrookGPU — компилятор потокового языка программирования Brook, созданный для выполнения неграфических вычислений на GPU. До его появления разработчики, использующие возможности видеочипов для вычислений, выбирали один из двух распространённых API: Direct3D или OpenGL. Это серьёзно ограничивало применение GPU, ведь в 3D графике используются шейдеры и текстуры, о которых специалисты по параллельному программированию знать не обязаны, они используют потоки и ядра. Brook смог помочь в облегчении их задачи. Эти потоковые расширения к языку C, разработанные в Стэндфордском университете, скрывали от программистов трёхмерный API, и представляли видеочип в виде параллельного сопроцессора. Компилятор обрабатывал файл .br с кодом C++ и расширениями, производя код, привязанный к библиотеке с поддержкой DirectX, OpenGL или x86.
Появление Brook вызвал интерес у NVIDIA и ATI и в дальнейшем, открыл целый новый его сектор — параллельные вычислители на основе видеочипов.
В дальнейшем, некоторые исследователи из проекта Brook перешли в команду разработчиков NVIDIA, чтобы представить программно-аппаратную стратегию параллельных вычислений, открыв новую долю рынка. И главным преимуществом этой инициативы NVIDIA стало то, что разработчики отлично знают все возможности своих GPU до мелочей, и в использовании графического API нет необходимости, а работать с аппаратным обеспечением можно напрямую при помощи драйвера. Результатом усилий этой команды стала NVIDIA CUDA.
Области применения параллельных расчётов на GPU
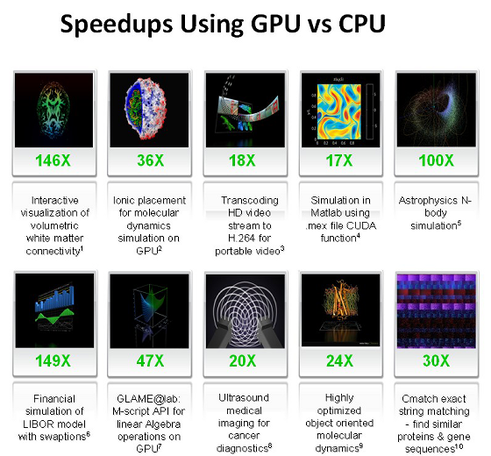
При переносе вычислений на GPU, во многих задачах достигается ускорение в 5-30 раз, по сравнению с быстрыми универсальными процессорами. Самые большие цифры (порядка 100-кратного ускорения и даже более!) достигаются на коде, который не очень хорошо подходит для расчётов при помощи блоков SSE, но вполне удобен для GPU.
Это лишь некоторые примеры ускорений синтетического кода на GPU против SSE-векторизованного кода на CPU (по данным NVIDIA):
• Флуоресцентная микроскопия: 12x.
• Молекулярная динамика (non-bonded force calc): 8-16x;
• Электростатика (прямое и многоуровневое суммирование Кулона): 40-120x и 7x.
Таблица, которую NVIDIA, показывает на всех презентациях, в которой показывается скорость графических процессоров относительно центральных.
Перечень основных приложений, в которых применяются вычисления на GPU: анализ и обработка изображений и сигналов, симуляция физики, вычислительная математика, вычислительная биология, финансовые расчёты, базы данных, динамика газов и жидкостей, криптография, адаптивная лучевая терапия, астрономия, обработка звука, биоинформатика, биологические симуляции, компьютерное зрение, анализ данных (data mining), цифровое кино и телевидение, электромагнитные симуляции, геоинформационные системы, военные применения, горное планирование, молекулярная динамика, магнитно-резонансная томография (MRI), нейросети, океанографические исследования, физика частиц, симуляция свёртывания молекул белка, квантовая химия, трассировка лучей, визуализация, радары, гидродинамическое моделирование (reservoir simulation), искусственный интеллект, анализ спутниковых данных, сейсмическая разведка, хирургия, ультразвук, видеоконференции.
Преимущества и ограничения CUDA
С точки зрения программиста, графический конвейер является набором стадий обработки. Блок геометрии генерирует треугольники, а блок растеризации — пиксели, отображаемые на мониторе. Традиционная модель программирования GPGPU выглядит следующим образом:
Чтобы перенести вычисления на GPU в рамках такой модели, нужен специальный подход. Даже поэлементное сложение двух векторов потребует отрисовки фигуры на экране или во внеэкранный буфер. Фигура растеризуется, цвет каждого пикселя вычисляется по заданной программе (пиксельному шейдеру). Программа считывает входные данные из текстур для каждого пикселя, складывает их и записывает в выходной буфер. И все эти многочисленные операции нужны для того, что в обычном языке программирования записывается одним оператором!
Поэтому, применение GPGPU для вычислений общего назначения имеет ограничение в виде слишком большой сложности обучения разработчиков. Да и других ограничений достаточно, ведь пиксельный шейдер — это всего лишь формула зависимости итогового цвета пикселя от его координаты, а язык пиксельных шейдеров — язык записи этих формул с Си-подобным синтаксисом. Ранние методы GPGPU являются хитрым трюком, позволяющим использовать мощность GPU, но без всякого удобства. Данные там представлены изображениями (текстурами), а алгоритм — процессом растеризации. Нужно особо отметить и весьма специфичную модель памяти и исполнения.
Программно-аппаратная архитектура для вычислений на GPU компании NVIDIA отличается от предыдущих моделей GPGPU тем, что позволяет писать программы для GPU на настоящем языке Си со стандартным синтаксисом, указателями и необходимостью в минимуме расширений для доступа к вычислительным ресурсам видеочипов. CUDA не зависит от графических API, и обладает некоторыми особенностями, предназначенными специально для вычислений общего назначения.
Преимущества CUDA перед традиционным подходом к GPGPU вычислениям
CUDA обеспечивает доступ к разделяемой между потоками памяти размером в 16 Кб на мультипроцессор, которая может быть использована для организации кэша с широкой полосой пропускания, по сравнению с текстурными выборками;
• более эффективная передача данных между системной и видеопамятью;
• отсутствие необходимости в графических API с избыточностью и накладными расходами;
• линейная адресация памяти, и gather и scatter, возможность записи по произвольным адресам;
• аппаратная поддержка целочисленных и битовых операций.
Основные ограничения CUDA:
• отсутствие поддержки рекурсии для выполняемых функций;
• минимальная ширина блока в 32 потока;
• закрытая архитектура CUDA, принадлежащая NVIDIA.
Слабыми местами программирования при помощи предыдущих методов GPGPU является то, что эти методы не используют блоки исполнения вершинных шейдеров в предыдущих неунифицированных архитектурах, данные хранятся в текстурах, а выводятся во внеэкранный буфер, а многопроходные алгоритмы используют пиксельные шейдерные блоки. В ограничения GPGPU можно включить: недостаточно эффективное использование аппаратных возможностей, ограничения полосой пропускания памяти, отсутствие операции scatter (только gather), обязательное использование графического API.
Основные преимущества CUDA по сравнению с предыдущими методами GPGPU вытекают из того, что эта архитектура спроектирована для эффективного использования неграфических вычислений на GPU и использует язык программирования C, не требуя переноса алгоритмов в удобный для концепции графического конвейера вид. CUDA предлагает новый путь вычислений на GPU, не использующий графические API, предлагающий произвольный доступ к памяти (scatter или gather). Такая архитектура лишена недостатков GPGPU и использует все исполнительные блоки, а также расширяет возможности за счёт целочисленной математики и операций битового сдвига.
CUDA открывает некоторые аппаратные возможности, недоступные из графических API, такие как разделяемая память. Это память небольшого объёма (16 килобайт на мультипроцессор), к которой имеют доступ блоки потоков. Она позволяет кэшировать наиболее часто используемые данные и может обеспечить более высокую скорость, по сравнению с использованием текстурных выборок для этой задачи. Что, в свою очередь, снижает чувствительность к пропускной способности параллельных алгоритмов во многих приложениях. Например, это полезно для линейной алгебры, быстрого преобразования Фурье и фильтров обработки изображений.
Удобнее в CUDA и доступ к памяти. Программный код в графических API выводит данные в виде 32-х значений с плавающей точкой одинарной точности (RGBA значения одновременно в восемь render target) в заранее предопределённые области, а CUDA поддерживает scatter запись — неограниченное число записей по любому адресу. Такие преимущества делают возможным выполнение на GPU некоторых алгоритмов, которые невозможно эффективно реализовать при помощи методов GPGPU, основанных на графических API.
Также, графические API в обязательном порядке хранят данные в текстурах, что требует предварительной упаковки больших массивов в текстуры, что усложняет алгоритм и заставляет использовать специальную адресацию. А CUDA позволяет читать данные по любому адресу. Ещё одним преимуществом CUDA является оптимизированный обмен данными между CPU и GPU. А для разработчиков, желающих получить доступ к низкому уровню (например, при написании другого языка программирования), CUDA предлагает возможность низкоуровневого программирования на ассемблере.
Недостатки CUDA
Один из немногочисленных недостатков CUDA — слабая переносимость. Эта архитектура работает только на видеочипах этой компании, да ещё и не на всех, а начиная с серии GeForce 8 и 9 и соответствующих Quadro, ION и Tesla. NVIDIA приводит цифру в 90 миллионов CUDA-совместимых видеочипов.
Альтернативы CUDA
• OpenCL
Фреймворк для написания компьютерных программ, связанных с параллельными вычислениями на различных графических и центральных процессорах. В фреймворк OpenCL входят язык программирования, который базируется на стандарте C99, и интерфейс программирования приложений (API). OpenCL обеспечивает параллелизм на уровне инструкций и на уровне данных и является реализацией техники GPGPU. OpenCL является полностью открытым стандартом, его использование не облагается лицензионными отчислениями.
Цель OpenCL состоит в том, чтобы дополнить OpenGL и OpenAL, которые являются открытыми отраслевыми стандартами для трёхмерной компьютерной графики и звука, пользуясь возможностями GPU. OpenCL разрабатывается и поддерживается некоммерческим консорциумом Khronos Group, в который входят много крупных компаний, включая Apple, AMD, Intel, nVidia, Sun Microsystems, Sony Computer Entertainment и другие.
• CAL/IL(Compute Abstraction Layer/Intermediate Language)
ATI Stream Technology — это набор аппаратных и программных технологий, которые позволяют использовать графические процессоры AMD, совместно с центральным процессором, для ускорения многих приложений (не только графических).
Областями применения ATI Stream являются приложения, требовательные к вычислительному ресурсу, такие, как финансовый анализ или обработка сейсмических данных. Использование потокового процессора позволило увеличить скорость некоторых финансовых расчётов в 55 раз по сравнению с решением той же задачи силами только центрального процессора.
Технологию ATI Stream в NVIDIA не считают очень сильным конкурентом. CUDA и Stream — это две разные технологии, которые стоят на различных уровнях развития. Программирование для продуктов ATI намного сложнее — их язык скорее напоминает ассемблер. CUDA C, в свою очередь, гораздо более высокоуровневый язык. Писать на нём удобнее и проще. Для крупных компаний-разработчиков это очень важно. Если говорить о производительности, то можно заметить, что её пиковое значение в продуктах ATI выше, чем в решениях NVIDIA. Но опять всё сводится к тому, как эту мощность получить.
• DirectX11 (DirectCompute)
Интерфейс программирования приложений, который входит в состав DirectX — набора API от Microsoft, который предназначен для работы на IBM PC-совместимых компьютерах под управлением операционных систем семейства Microsoft Windows. DirectCompute предназначен для выполнения вычислений общего назначения на графических процессорах, являясь реализацией концепции GPGPU. Изначально DirectCompute был опубликован в составе DirectX 11, однако позже стал доступен и для DirectX 10 и DirectX 10.1.
NVDIA CUDA в российской научной среде.
По состоянию на декабрь 2009 г., программная модель CUDA преподается в 269 университетах мира. В России обучающие курсы по CUDA читаются в Московском, Санкт-Петербургском, Казанском, Новосибирском и Пермском государственных университетах, Международном университете природы общества и человека «Дубна», Объединённом институте ядерных исследований, Московском институте электронной техники, Ивановском государственном энергетическом университете, БГТУ им. В. Г. Шухова, МГТУ им. Баумана, РХТУ им. Менделеева, Российском научном центре «Курчатовский институт», Межрегиональном суперкомпьютерном центре РАН, Таганрогском технологическом институте (ТТИ ЮФУ).
Как работает видеокарта — КомпЛайн
Процесс построения трехмерного изображения
Этот процесс – 3D-рендеринг – похож на создание фотографии-натюрморта: большую часть времени занимает расположение объектов в кадре, а затем делается моментальный «снимок», результаты которого выводятся на экран. В отличие от фотографии, процедура рендеринга при синтезе компьютерного изображения в реальном времени – например, в игре – повторяется несколько десятков раз в секунду (другой вариант: рендеринг производится заранее, а в итоге получается статичная картинка или видеоролик с высокой степенью реалистичности).
Исходным материалом для рендеринга является множество треугольников различного размера, из которых складываются все объекты виртуального мира: пейзаж, игровые персонажи, монстры, оружие и т.д. Однако сами по себе модели, созданные из треугольников, выглядят как проволочные каркасы. Поэтому на них накладываются текстуры – цветные двухмерные «обои». И текстуры, и модели помещаются в память графической карты, а дальше, при создании каждого кадра игрового действия выполняется цикл рендеринга, состоящий из нескольких этапов.
1. Игровая программа отправляет графическому процессору информацию, описывающую игровую сцену: состав присутствующих объектов, их окраску, положение относительно точки наблюдения, освещение и видимость. Передаются и дополнительные данные, характеризующие сцену и позволяющую видеокарте увеличить реалистичность получаемого изображения, добавив туман, размытие, блики и т.д.
2. Графический процессор располагает трехмерные модели в кадре, определяет, какие из входящих в них треугольников находятся на виду и отсекает скрытые другими объектами или, например, тенями.
Затем создаются источники света и определяется их влияние на цвет освещаемых объектов. Этот этап рендеринга называется «трансформация и освещение» (T&L – Transformation & Lighting).
3. На видимые треугольники накладываются текстуры с применением различных технологий фильтрации. Билинейная фильтрация предусматривает наложение на треугольник двух версий текстуры с различным разрешением. Результатом ее использования являются хорошо различимые границы между областями четких и размытых текстур, возникающие на трехмерных поверхностях перпендикулярно направлению обзора. Трилинейная фильтрация, использующая три варианта одной текстуры, позволяет создать более мягкие переходы.
Однако в результате использования обеих технологий по-настоящему четко выглядят лишь те текстуры, которые расположены перпендикулярно к оси зрения. При взгляде под углом они сильно размываются. Для того чтобы это предотвратить, используется анизотропная фильтрация.
Такой метод фильтрации текстур задается в настройках драйвера видеоадаптера либо непосредственно в компьютерной игре. Кроме того, можно изменять силу анизотропной фильтрации: 2х, 4х, 8х или 16х – чем больше «иксов», тем более четкими будут изображения на наклонных поверхностях. Но при увеличении силы фильтрации возрастает нагрузка на видеокарту, что может привести к снижению скорости работы и к уменьшению количества кадров, генерируемых в единицу времени.
На этапе текстурирования могут использоваться различные дополнительные эффекты. Например, наложение карт среды (Enironmental Mapping) позволяет создавать поверхности, в которых будет отражаться игровая сцена: зеркала, блестящие металлические предметы и т.д. Другой впечатляющий эффект получается с применением карт неровностей (Bump Mapping), благодаря которому свет, падающий на поверхность под углом, создает видимость рельефа.
Текстурирование является последним этапом рендеринга, после которого картинка попадает в кадровый буфер видеокарты и выводится на экран монитора.
Электронные компоненты видеокарты
Теперь, когда стало понятно, каким образом происходит процесс построения трехмерного изображения, можно перечислить технические характеристики компонентов видеокарты, которые определяют скорость процесса. Главными составными частями видеокарты являются графический процессор (GPU – Graphics Processing Unit) и видеопамять.
Графический процессор
Одной из основных характеристик этого компонента (как и центрального процессора ПК), является тактовая частота. При прочих равных условиях, чем она выше, тем быстрее происходит обработка данных, а следовательно – увеличивается количество кадров в секунду (FPS – frames per second) в компьютерных играх. Частота графического процессора – важный, но не единственный, влияющий на его производительность параметр – современные модели производства Nvidia и ATI, имеющие сопоставимый уровень быстродействия, характеризуются различными частотами GPU.
Для адаптеров Nvidia, обладающих высокой производительностью, характерны тактовые частоты GPU от 550 МГц до 675 МГц. Частоту работы графического процессора меньше 500 МГц имеют «середнячки» и дешевые низкопроизводительные карты.
В то же время GPU «топовых» карт производства ATI имеют частоты от 600 до 800 МГц, и даже у самых дешевых видеоадаптеров частота графического процессора не опускается ниже 500 МГц.
Однако, несмотря на то, что графические процессоры Nvidia обладают меньшей частотой, чем GPU, разработанные ATI, они обеспечивают, по крайней мере, такой же уровень производительности, а зачастую – и более высокий. Дело в том, что не меньшее значение, чем тактовая частота, имеют другие характеристики GPU.
1. Количество текстурных модулей (TMU – Texture Mapping Units) – элементов графического процессора, выполняющих наложение текстур на треугольники. От количества TMU напрямую зависит скорость построения трехмерной сцены.
2. Количество конвейеров рендеринга (ROP – Render Output Pipeline) – блоков, выполняющих «сервисные» функции (пару примеров, pls). В современных графических процессорах ROP, как правило, меньше, чем текстурных модулей, и это ограничивает общую скорость текстурирования. К примеру, чип видеокарты Nvidia GeForce 8800 GTX имеет 32 «текстурника» и 24 ROP. У процессора видеокарты ATI Radeon HD 3870 только 16 текстурных моделей и 16 ROP.
Производительность текстурных модулей выражается в такой величине как филлрейт – скорость текстурирования, измеряемая в текселах за секунду. Видеокарта GeForce 8800 GTX имеет филлрейт в 18,4 млрд текс/с. Но более объективным показателем является филлрейт, измеряемый в пикселах, так как он отражает скорость работы ROP. У GeForce 8800 GTX эта величина равна 13,8 млрд пикс./с.
3. Количество шейдерных блоков (шейдерных процессоров), которые – как следует из названия – занимаются обработкой пиксельных и вершинных шейдеров. Современные игры активно используют шейдеры, так что количество шейдерных блоков имеет решающее значение для определения производительности.
Не так давно графические процессоры имели отдельные модули для выполнения пиксельных и вершинных шейдеров. Видеокарты Nvidia серии GeForce 8000 и адаптеры ATI Radeon HD 2000 первыми перешли на унифицированную шейдерную архитектуру. Графические процессоры этих карт имеют блоки, способные обрабатывать как пиксельные, так и вершинные шейдеры – универсальные шейдерные процессоры (потоковые процессоры). Такой подход позволяет полностью задействовать вычислительные ресурсы чипа при любом соотношении пиксельных и вершинных расчетов в коде игры. Кроме того, в современных графических процессорах шейдерные блоки часто работают на частоте, превышающей тактовую частоту GPU (например, у GeForce 8800 GTX эта частота составляет 1350 МГц против «общих» 575 МГц).
Обращаем ваше внимание на то, что компании Nvidia и ATI по-разному считают количество шейдерных процессоров в своих чипах. К примеру, Radeon HD 3870 имеет 320 таких блоков, а GeForce 8800 GTX – только 128. На самом деле, ATI указывает вместо целых шейдерных процессоров их составные компоненты. В каждом шейдерном процессоре содержится по пять компонентов, так что общее количество шейдерных блоков у Radeon HD 3870 – всего 64, поэтому и работает эта видеокарта медленнее, чем GeForce 8800 GTX.
Память видео карты
Видеопамять по отношению к GPU выполняет те же функции, что и оперативная память – по отношению к центральному процессору ПК: она хранит весь «строительный материал», необходимый для создания изображения – текстуры, геометрические данные, программы шейдеров и т.д.
Какие характеристики видеопамяти влияют на производительность графической карты
1. Объем. Современные игры используют огромное количество текстур с высоким разрешением, и для их размещения требуется соответствующий объем видеопамяти. Основная масса выпускаемых сегодня «топовых» видеоадаптеров и карт среднего ценового диапазона снабжается 512 Мб памяти, которая не может быть увеличена впоследствии. Более дешевые видеокарты оснащаются вдвое меньшим объемом памяти, для современных игр его уже недостаточно.
В случае нехватки памяти графический процессор вынужден постоянно загружать текстуры из оперативной памяти ПК, связь с которой осуществляется гораздо медленнее, в результате производительность может заметно снижаться. С другой стороны, чрезмерно большой объем памяти может не дать никакого увеличения скорости, так как дополнительное «место» просто не будет использоваться. Покупать видеоадаптер с 1 Гб памяти имеет смысл только в том случае, если он принадлежит к «топовым» продуктам (видеокарты ATI Radeon HD 4870, Nvidia GeForce 9800, а также новейшие карты серии GeForce GTX 200).
2. Частота. Этот параметр у современных видеокарт может изменяться от 800 до 3200 МГц и зависит, в первую очередь, от типа используемых микросхем памяти. Чипы DDR 2 могут обеспечить рабочую частоту в пределах 800 МГц и используются только в самых дешевых графических адаптерах. Память GDDR 3 и GDDR 4 увеличивает частотный диапазон вплоть до 2400 МГц. Новейшие графические карты ATI Radeon HD 4870 используют память GDDR-5 с фантастической частотой – 3200 МГц.
Частота памяти, как и частота графического процессора, оказывает большое влияние на производительность видеокарты в играх, особенно при использовании полноэкранного сглаживания. При прочих равных условиях, чем больше частота памяти, тем выше быстродействие, т.к. графический процессор будет меньше «простаивать» в ожидании поступления данных. Частота памяти в 1800 МГц является нижней границей, отделяющей высокопроизводительные карты от менее быстрых.
3. Разрядность шины видеопамяти гораздо сильнее влияет на общую производительность карты, чем частота памяти. Она показывает, сколько данных может передать память за один такт. Соответственно, двукратное увеличение разрядности шины памяти эквивалентно удвоению ее тактовой частоты. Основная масса современных видеокарт имеют 256-битную шину памяти. Уменьшение разрядности до 128 или, тем более, до 64 бит наносит сильный удар по быстродействию. С другой стороны, в самых дорогих видеокартах шина может быть «расширена» до 512 бит (пока этим может похвастаться лишь новейший GeForce GTX 280), что оказывается весьма кстати, принимая во внимание мощность их графических процессоров.
Где найти информацию о технических характеристиках видеокарты
Если графическая карта обладает некими выдающимися параметрами (высокая тактовая частота процессора и памяти, ее объем), то они, как правило, указываются непосредственно на коробке. Но наиболее полные спецификации видеоадаптеров и GPU, на которых они основаны, можно найти только в Интернете. Общая информация выкладывается на корпоративных сайтах производителей графических процессоров: Nvidia (www.nvidia.ru) и ATI (www.ati.amd.com/ru). Подробности можно узнать на неофициальных веб-сайтах, посвященных видеокартам – www.nvworld.ru и www.radeon.ru. Хорошим подспорьем станет электронная энциклопедия Wikipedia (www.ru.wikipedia.org). Пользователи, покупающие карту с прицелом на разгон могут воспользоваться ресурсом www.overclockers.ru.
Одновременное использование двух видеокарт
Для того чтобы получить максимальную производительность, можно установить в компьютер сразу две видеокарты. Производители предусмотрели для этого соответствующие технологии – SLI (Scalable Link Interface, используется картами Nvidia) и CrossFire (разработка ATI). Для того чтобы воспользоваться ими, материнская плата должна не только иметь два слота PCI-E для видеокарт, но и поддерживать одну из названных технологий. Многие «материнки» на чипсетах Intel могут использовать платы ATI в режиме CrossFire, а вот объединить в одну «упряжку» две (или даже три!) видеокарты производства Nvidia могут лишь платы на чипсетах этой же фирмы. В случае, если материнская плата не обладает поддержкой этих технологий, две видеокарты смогут с ней работать, но в играх будет использоваться только одна, а вторая лишь даст возможность выводить изображение на пару дополнительных мониторов.
Заметим, что использование двух видеокарт не приводит к удвоению производительности. Средний результат, на который стоит рассчитывать – 50% прироста скорости. Кроме того, весь потенциал тандема будет раскрыт лишь при использовании мощного центрального процессора и монитора с высоким разрешением.
Что такое шейдеры
Шейдеры – микропрограммы, присутствующие в коде игры, с помощью которых можно изменять процесс построения виртуальной сцены, открывая возможности, недостижимые при использовании традиционных средств 3D-рендеринга. Современная игровая графика без шейдеров немыслима.
Вершинные шейдеры изменяют геометрию трехмерных объектов, благодаря чему можно реализовать естественную анимацию сложных моделей игровых персонажей, физически корректную деформацию предметов или настоящие волны на воде. Пиксельные шейдеры применяются для изменения цвета пикселей и позволяют создавать такие эффекты, как реалистичные круги и рябь на воде, сложное освещение и рельеф поверхностей. Кроме того, с помощью пиксельных шейдеров осуществляется постобработка кадра: всевозможные «кинематографические» эффекты размытия движущихся объектов, сверхъяркого света и т.д.
Существует несколько версий реализации шейдерной модели (Shader Model). Все современные видеокарты поддерживают пиксельные и вершинные шейдеры версии 4.0, обеспечивающие по сравнению с предыдущей – третьей – версией более высокую реалистичность эффектов. Shader Model 4.0 поддерживается API DirectX 10 , которая работает исключительно в среде Windows Vista. Кроме того, сами компьютерные игры должны быть «заточены» под DirectX 10.
Нужна ли AGP-видеокарта старой системе
Если «материнка» вашего ПК оснащена портом AGP, возможности апгрейда видеокарты сильно ограничены. Максимум, который может себе позволить обладатель такой системы – это видеокарты серии Radeon HD 3850 фирмы AMD (ATI).
По современным меркам, они обладают производительностью ниже среднего. Кроме того, подавляющее большинство материнских плат с поддержкой интерфейса AGP предназначено для устаревших процессоров Intel Pentium 4 и AMD Athlon XP, так что общее быстродействие системы все равно будет недостаточно высоким для современной трехмерной графики. Только на материнские платы для процессоров AMD Ahtlon 64 с разъемом Socket 939 стоит устанавливать новые видеокарты с портом AGP. Во всех остальных случаях лучше купить новый компьютер с интерфейсом PCI-E, памятью DDR 2 (или DDR 3) и современным ЦП.
Теги материала: графическая карта, видео, карта, ускоритель, графики
Лучшие видеокарты для 3D графики, моделирования и игр
18 октября 2019 г.
Видеокарты выполняют две роли в современных компьютерах. В играх они обеспечивают красивую графику, быструю смену частоты кадров, взрывы пиротехники, разнообразные визуальные эффекты над которыми работали разработчики.
А для CGI индустрии, включая художников-графиков, дизайнеров, иллюстраторов и профессионалов в области 3D, работающих в таких программах, как Adobe Creative Suite, Photoshop, Blender, Maya, 3DS Max и прочих, мощная видеокарта может иметь огромное значение для рендеринга или моделирования. Некоторые эффекты в этих программах уже не могут даже работать на CPU без помощи видеокарты.

Quadro vs GeForce vs Radeon vs Radeon Pro
Nvidia и AMD выпускают два вида видеокарт, которые ориентировочно предназначены для игр или дизайна. Для Nvidia вы, вероятно, уже знаете игровой бренд GeForce, в то время как карты Quadro предназначены для профессионалов, а с AMD — Radeon для игр и Radeon Pro для творческого программного обеспечения. Суть в том, что карты профессионального уровня стоят намного дороже.
При более высокой цене на Quadros и Radeon Pro вы получаете в основном те же аппаратные характеристики, что и в гораздо более дешевых игровых картах. Они имеют тот же базовый дизайн, ту же архитектуру и схожие спецификации, но с некоторыми принципиальными отличиями. Карты Quadro и Radeon имеют сертифицированные драйвера. Это означает, что они были протестированы на совместимость с конкретным программным обеспечением, предлагают лучшую производительность с программнами для проектирования (при определенных обстоятельствах) и (предположительно) с меньшей вероятностью столкнутся с проблемами. У них есть память ECC для дополнительной точности. И иногда они работают на более низких тактовых частотах, что означает, что они имеют более низкие требования к мощности и меньшие тепловые требования.
Посмотрите на любой обзор видеокарты, и он будет полон трехбуквенных сокращений, которые используются для иллюстрации ожидаемой производительности программного обеспечения. Но это может заставить вас задуматься, какие из этих цифр имеют значение для современной видеокарты.
Ключевыми характеристиками, часто указанными в обзорах и изготовителями, являются объем памяти (емкость, пропускная способность и скорость), количество ядер (в основном аппаратное обеспечение) и тактовая частота карты (в МГц). Эти спецификации различаются для разных поколений графических процессоров и для разных уровней, а ядра в картах Nvidia и AMD не совпадают. Nvidia использует термин ядра Cuda, в то время как AMD ссылается на свои ядра GCN. Производительность между AMD и Nvidia абсолютно не может сравниться, если предположить, что карта AMD имеет больше или меньше ядер, чем карта Nvidia.
Теперь перейдем к нашему обзору лучших видеокарт, доступных сейчас.
Лучшие видеокарты для 3d графики и игр

Nvidia Quadro RTX 8000
Первый в мире графический процессор Ray Tracing.
Ядра графического процессора: 4,608 | Базовая частота: 1,395 МГц | Максимальная тактовая частота: 1,770 МГц | Память: 48 ГБ HDDR6 | Пропускная способность памяти: 384 ГБ/с | Максимальное поддерживаемое разрешение: 7680×4320
Откройте новый рубеж в профессиональной графике с беспрецедентной производительностью и масштабируемостью благодаря 48 ГБ высокоскоростной памяти GDDR6 и NVIDIA NVLink ™. Дизайнеры и художники из разных отраслей теперь могут расширить границы возможного, работая с самыми большими и сложными рабочими нагрузками по трассировке лучей, глубокому обучению и визуальным вычислениям.
С ней вы получаете гораздо большую мощность рендеринга и 3Д моделирования, чем предыдущее поколение Pascal, выводя приложения Cuda и OpenCL на новый уровень и оставляя любую другую видеокарту в сравнительно слабом состоянии.

Nvidia GeForce RTX 2080 Ti
Революция в игровом реализме и производительности.
Ядра графического процессора: 4,352 | Базовая частота: 1,350 МГц | Максимальная тактовая частота: 1,545 МГц | GFLOPS: 13 448 | Память: 11 ГБ GDDR6 | Пропускная способность памяти: 616 ГБ/с
Каждое поколение Nvidia выпускает свою флагманскую модель, а затем вторую версию с улучшенными характеристиками, с высокой ценой, и это действительно то, что пользователи ПК с энтузиазмом рассмотрят RTX 2080 Ti. В настоящее время это самая быстрая видеокарта на планете — 4352 ядра Cuda, почти вдвое увеличивающие аппаратное обеспечение трассировки лучей vanilla RTX 2080 и почти вдвое повышена производительность графической обработки.
Одна только эта карта стоит дороже, чем один обычный ПК среднего класса, но с некоторыми серьезными аппаратными средствами стоит задуматься об инвестициях, в том числе и для дизайнеров, чья рабочая станция превращается в игровой ПК, поскольку производительность Cuda и OpenCL значительно выросла.наряду с игровой производительностью.

Nvidia Titan RTX
Самая быстрая графическая карта для ПК, которая когда-либо создавалась.
Ядра графического процессора: 4,608 | Базовая частота: 1,350 МГц | Максимальная тактовая частота: 1,770 МГц | Память: 24 ГБ GDDR6 | Пропускная способность памяти: 672 ГБ/с
Самым требовательным пользователям нужны лучшие инструменты. TITAN RTX построен на архитектуре NVIDIA Turing GPU и включает новейшие технологии Tensor Core и RT Core для ускорения искусственного интеллекта и трассировки лучей. Он также поддерживается драйверами NVIDIA и SDK, поэтому разработчики, исследователи и создатели могут работать быстрее и получать лучшие результаты.
TITAN RTX, созданный с использованием высокоточных тензорных ядер, обеспечивает непревзойденную производительность FP32, FP16, INT8 и INT4, обеспечивая более быстрое обучение и вывод нейронных сетей. Обладая вдвое большей емкостью памяти, чем у графических процессоров TITAN предыдущего поколения и NVIDIA NVLink ™, TITAN RTX позволяет исследователям и ученым данных экспериментировать с большими нейронными сетями и наборами данных, чем когда-либо прежде, и все это в памяти графического процессора

Nvidia Quadro RTX 4000
Базовая видеокарта профессионального уровня.
Ядра графического процессора: 2,304 | Базовая частота: 1,005 МГц | Максимальная тактовая частота: 1,545 МГц | GFLOPS: 7 100 | Память: 8 ГБ GDDR6 | Пропускная способность памяти: 416 ГБ/с
Это наша главная рекомендация для видеокарт класса рабочих станций по доступной цене с отличной производительностью в дизайнерских приложениях. Она поставляется в элегантном дизайне с одним слотом, который помогает вписаться в небольшие корпуса и требует меньше энергии, чем более объемная карта GeForce.
В частности, приложения OpenCL и Cuda полностью используют новую архитектуру Turing, поэтому RTX 4000 будет иметь огромное значение при работе со всеми видами креативного программного обеспечения, плагинов и фильтров, обеспечивая превосходную производительность при рендеринге изображений, 3D и видео.

QUADRO GV100
Флагманская видеокарта
Ядра графического процессора: 5,120 | Базовая частота: 1200 МГц | Максимальная тактовая частота: 1447 МГц | Память: 32 ГБ GDDR6 | Пропускная способность памяти: 870 ГБ/с | Максимальное поддерживаемое разрешение: 7680×4320
NVIDIA® Quadro® GV100 заново изобретает рабочую станцию, чтобы удовлетворить требования улучшенных рабочих процессов проектирования, моделирования и 3d визуализации. Он работает на базе технологии NVIDIA Volta, обеспечивая невероятную емкость памяти, масштабируемость и производительность, которые дизайнеры, архитекторы и ученые должны создавать, создавать и решать невозможное.
По вычислительной производительности NVIDIA подчеркивает возможность трассировки лучей в реальном времени. На конференции Games Developer Conference несколько дней назад NVIDIA представила интерфейс разработчика под названием RTX, который скоро начнет поддерживаться в играх. Впрочем, трассировка лучей первое время будет использоваться лишь для некоторых эффектов сцены. В профессиональном же окружении трассировка лучей обычно выполняется для всей сцены. И здесь Quadro GV100 должна показать свои сильные стороны.
Новинка по праву может считаться самой производительной профессиональной видеокартой в мире. Сообщается, что пиковая производительность в вычисления с двойной точностью составляет 7.4 Тфлопс, в задачах с одинарной точностью – 14.8 Тфлопс, а в задачах, связанных с глубоким обучением – 118.5 Тфлопс. Последний показатель как раз и обеспечивают «тензорные ядра».

AMD Radeon VII
Новая высокопроизводительная видеокарта AMD — это жесткая конкуренция для Nvidia
Ядра графического процессора: 3840 | Базовая частота: 1400 | Максимальная тактовая частота: 1800 МГц | GFLOPS: 13,824 | Память: 16 ГБ HBM2 | Пропускная способность памяти: 1028 ГБ/с
Видеокарта (под кодовым названием Vega 20) нацелена на рынок высокопроизводительных графических процессоров, нарушая традицию AMD просто предлагать лучший результат по сравнению с предложениями Nvidia. Radeon VII — это GeForce RTX 2070 для игр, и он особенно хорош для творческой работы с высоким разрешением благодаря огромной 16 ГБ сверхбыстрой памяти HBM2 и потрясающей производительности OpenCL.
Это новое поколение карт AMD стоит немного дороже, и, что особенно важно, оно немного шумнее и горячее, чем предложения Nvidia. Также отсутствует аппаратная поддержка трассировки лучей, которая есть у карт RTX, что может стать решающим фактором при принятии решения о покупке, если вас не поколеблёт дополнительный объем памяти Radeon VII.

Nvidia GeForce GTX 1660 Ti
Современная карта, которая заменяет GTX 1060
Ядра GPU: 1,536 | Базовая частота: 1500 | Максимальная тактовая частота: 1770 МГц | GFLOPS: 4,608 | Память: 6 ГБ GDDR6 | Пропускная способность памяти: 288 ГБ/с
С ценой и спецификацией, которая помещает Geforce GTX 1660 Ti . Эта новая карта Nvidia, без сомнения, найдет свой путь в более доступные готовые ПК, чем дорогая высококлассная серия RTX, с возможностями, которые примерно находятся между (все еще впечатляющими) GTX 1070 и GTX 1060.
Она имеет 6 ГБ памяти GDDR6 и скромные 1536 ядер Cuda, и основан на более новой 12-нм архитектуре Turning карт RTX, но без аппаратного обеспечения трассировки лучей.
GTX 1660 Ti, обеспечивающий отличную игровую производительность в 1080p и 1440p, а также множество возможностей для ускорения плагинов и фильтров в креативном программном обеспечении, предлагается по очень хорошей цене и предлагается некоторыми производителями (например, PNY) в очень короткой форме, это может позволить втиснуть ее в крошечные ПК.

AMD Radeon RX 590
Карта среднего класса за отличную цену
Ядра графического процессора: 2,304 | Базовая частота: 1469 МГц | Максимальная тактовая частота : 1,545 МГц | GFLOPS: 7 100 | Память: 8 ГБ GDDR5 | Пропускная способность памяти: 256 ГБ/с
Теперь у AMD появился новый флагманский топовый процессор Radeon VII, более старая RX590 видеокарта упала примерно до ценовой отметки, где она напрямую конкурирует с GeForce GTX 1060 от Nvidia. Но во многих ситуациях RX590 является более выгодной покупкой, превосходя GTX 1060 в некоторых играх и обработке OpenCL. Он обладает большей памятью, пропускной способностью и вычислительной мощностью. Учитывая его низкую цену, это стоит того, чтобы о нем подумать.

AMD Radeon Pro WX8200
Безграничная свобода для воплощения креативных идей.
Ядра графического процессора: 3,384 | Базовая частота: 1,200 МГц | Максимальная тактовая частота: 1,500 МГц | GFLOPS: 10 075 | Память: 8 ГБ HBM2 | Пропускная способность памяти: 512 ГБ/с
AMD выпустила отличную видеокарту профессионального уровня, WX8200. Она по-прежнему основана на текущей архитектуре Vega, но имеет 3584 ядра и 8 ГБ сверхбыстрой памяти HBM2, что обеспечивает отличную производительность в конкретных тестах. Графические ускорители Radeon Pro WX 8200, оснащенные передовыми функциями, ориентированы на профессионалов и сертифицированы для использования со многими наиболее популярными сегодня приложениями. Они являются идеальными решениями для тех, кто ищет высокопрофессиональную графику для таких областей, как проектирование, 3d моделирование, производство, проектно-конструкторские работы, планировка, строительство или мультимедийные и развлекательные приложения.
В зависимости от инструментов, которые вы используете, карты AMD могут предлагать более высокую производительность. Например, 3D-аниматоры, которые полагаются исключительно на Maya или Blender, могут выиграть от выбора AMD вместо Nvidia, хотя мы рекомендуем некоторые дополнительные исследования и рассмотрим ваш рабочий процесс, прежде чем инвестировать. Приложения OpenCL отлично работают с видеокартами AMD, а WX8200 — это лучший выбор для видеокарт профессионального уровня AMD.
Как правильно выбрать видеокарту
Есть несколько основных вещей, которые следует учитывать при покупке. Более высокое разрешение, с которым вы работаете (или играете), требует больше памяти. Если вы собираетесь работать с разрешением 4K на экране или с более крупными текстурами, вам нужна видеокарта с большим объемом памяти. 8 ГБ или больше теперь распространено на картах более высокого уровня.
Количество ядер действительно определяет общую мощность рендеринга карты. Они значительно различаются по различным уровням цены и производительности: от карточек начального уровня 100$ до бегемотов 1000$+.
Тактовая частота графической карты указана в виде базовой цифры и «повышения GPU». Подобно режиму Turbo на процессорах Intel, когда видеокарта находится под большой нагрузкой, она будет работать на более высокой тактовой частоте для повышения производительности, пока не достигнет заранее определенного максимума, который установлен во избежание перегрева.
Не забудьте также рассмотреть дисплей (ы), с которыми вы работаете, и выходные данные видеокарты, которую вы покупаете. Все современные видеокарты используют только цифровые видеовыходы, либо HDMI, либо DisplayPort (это может быть либо маленький квадратный разъем miniDP, либо большой D-образный разъем).
Для дисплеев 4K или 5K все графические карты теперь поддерживают, по крайней мере, стандарты DisplayPort 1.4 и HDMI 2.0, которые предлагают полосу пропускания, необходимую для частоты обновления 60 Гц — что было серьезной проблемой на старых графических картах, когда дисплеи с более высоким разрешением впервые стали популярным предложением для некоторых много лет назад. Когда 8K-дисплеи наконец станут более доступными, эта проблема снова встанет на ноги.
И, наконец, единственная самая большая разница в производительности графических карт, которая может быть очевидна для некоторых читателей, — это аппаратная генерация серии карт, всегда кодируемая для справки. Nvidia называет свои карты в честь ученых — Паскаля, Тьюринга и т. Д., В то время как AMD немного более неясна, с Polaris и более новой архитектурой Vega, которая сейчас представлена на рынке.
Nvidia и AMD выпускают новую серию видеокарт примерно каждые два года, а когда выходит новое поколение, это означает повышение планки во всех технических областях — больше ядер, больше памяти, больше пропускной способности и больше функций, часто сжимая в ту же мощность и тепловые требования карты предыдущего поколения.
Для наилучшей производительности и лучшей перспективы, смотрите только в сторону новых видеокарт.
задействуем возможности GPU для ускорения софта — «Хакер»
Сегодня новости об использовании графических процессоров для общих вычислений можно услышать на каждом углу. Такие слова, как CUDA, Stream и OpenCL, за каких-то два года стали чуть ли не самыми цитируемыми в айтишном интернете. Однако, что значат эти слова, и что несут стоящие за ними технологии, известно далеко не каждому. А для линуксоидов, привыкших «быть в пролете», так и вообще все это видится темным лесом.
Предисловие
В этой статье мы попытаемся разобраться, зачем нужна технология GPGPU (General-purpose graphics processing units, Графический процессор общего назначения) и все связанные с ней реализации от конкретных производителей. Узнаем, почему эта технология имеет очень узкую сферу применения, в которую подавляющее большинство софта не попадает в принципе, и конечно же, попытаемся извлечь из всего этого выгоду в виде существенных приростов производительности в таких задачах, как шифрование, подбор паролей, работа с мультимедиа и архивирование.
Рождение GPGPU
Мы все привыкли думать, что единственным компонентом компа, способным выполнять любой код, который ему прикажут, является центральный процессор. Долгое время почти все массовые ПК оснащались единственным процессором, который занимался всеми мыслимыми расчетами, включая код операционной системы, всего нашего софта и вирусов.
Позже появились многоядерные процессоры и многопроцессорные системы, в которых таких компонентов было несколько. Это позволило машинам выполнять несколько задач одновременно, а общая (теоретическая) производительность системы поднялась ровно во столько раз, сколько ядер было установлено в машине. Однако оказалось, что производить и конструировать многоядерные процессоры слишком сложно и дорого. В каждом ядре приходилось размещать полноценный процессор сложной и запутанной x86-архитектуры, со своим (довольно объемным) кэшем, конвейером инструкций, блоками SSE, множеством блоков, выполняющих оптимизации и т.д. и т.п. Поэтому процесс наращивания количества ядер существенно затормозился, и белые университетские халаты, которым два или четыре ядра было явно мало, нашли способ задействовать для своих научных расчетов другие вычислительные мощности, которых было в достатке на видеокарте (в результате даже появился инструмент BrookGPU, эмулирующий дополнительный процессор с помощью вызовов функций DirectX и OpenGL).
Графические процессоры, лишенные многих недостатков центрального процессора, оказались отличной и очень быстрой счетной машинкой, и совсем скоро к наработкам ученых умов начали присматриваться сами производители GPU (а nVidia так и вообще наняла большинство исследователей на работу). В результате появилась технология nVidia CUDA, определяющая интерфейс, с помощью которого стало возможным перенести вычисление сложных алгоритмов на плечи GPU без каких-либо костылей. Позже за ней последовала ATi (AMD) с собственным вариантом технологии под названием Close to Metal (ныне Stream), а совсем скоро появилась ставшая стандартом версия от Apple, получившая имя OpenCL.
GPU — наше все?
Несмотря на все преимущества, техника GPGPU имеет несколько проблем. Первая из них заключается в очень узкой сфере применения. GPU шагнули далеко вперед центрального процессора в плане наращивания вычислительной мощности и общего количества ядер (видеокарты несут на себе вычислительный блок, состоящий из более чем сотни ядер), однако такая высокая плотность достигается за счет максимального упрощения дизайна самого чипа.
В сущности основная задача GPU сводится к математическим расчетам с помощью простых алгоритмов, получающих на вход не очень большие объемы предсказуемых данных. По этой причине ядра GPU имеют очень простой дизайн, мизерные объемы кэша и скромный набор инструкций, что в конечном счете и выливается в дешевизну их производства и возможность очень плотного размещения на чипе. GPU похожи на китайскую фабрику с тысячами рабочих. Какие-то простые вещи они делают достаточно хорошо (а главное — быстро и дешево), но если доверить им сборку самолета, то в результате получится максимум дельтаплан. Поэтому первое ограничение GPU — это ориентированность на быстрые математические расчеты, что ограничивает сферу применения графических процессоров помощью в работе мультимедийных приложений, а также любых программ, занимающихся сложной обработкой данных (например, архиваторов или систем шифрования, а также софтин, занимающихся флуоресцентной микроскопией, молекулярной динамикой, электростатикой и другими, малоинтересными для линуксоидов вещами).
Вторая проблема GPGPU в том, что адаптировать для выполнения на GPU можно далеко не каждый алгоритм. Отдельно взятые ядра графического процессора довольно медлительны, и их мощь проявляется только при работе сообща. А это значит, что алгоритм будет настолько эффективным, насколько эффективно его сможет распараллелить программист. В большинстве случаев с такой работой может справиться только хороший математик, которых среди разработчиков софта совсем немного.
И третье: графические процессоры работают с памятью, установленной на самой видеокарте, так что при каждом задействовании GPU будет происходить две дополнительных операции копирования: входные данные из оперативной памяти самого приложения и выходные данные из GRAM обратно в память приложения. Нетрудно догадаться, что это может свести на нет весь выигрыш во времени работы приложения (как и происходит в случае с инструментом FlacCL, который мы рассмотрим позже).
Но и это еще не все. Несмотря на существование общепризнанного стандарта в лице OpenCL, многие программисты до сих пор предпочитают использовать привязанные к производителю реализации техники GPGPU. Особенно популярной оказалась CUDA, которая хоть и дает более гибкий интерфейс программирования (кстати, OpenCL в драйверах nVidia реализован поверх CUDA), но намертво привязывает приложение к видеокартам одного производителя.
KGPU или ядро Linux, ускоренное GPU
Исследователи из университета Юты разработали систему KGPU, позволяющую выполнять некоторые функции ядра Linux на графическом процессоре с помощью фреймворка CUDA. Для выполнения этой задачи используется модифицированное ядро Linux и специальный демон, который работает в пространстве пользователя, слушает запросы ядра и передает их драйверу видеокарты с помощью библиотеки CUDA. Интересно, что несмотря на существенный оверхед, который создает такая архитектура, авторам KGPU удалось создать реализацию алгоритма AES, который поднимает скорость шифрования файловой системы eCryptfs в 6 раз.
Что есть сейчас?
В силу своей молодости, а также благодаря описанным выше проблемам, GPGPU так и не стала по-настоящему распространенной технологией, однако полезный софт, использующий ее возможности, существует (хоть и в мизерном количестве). Одними из первых появились крэкеры различных хэшей, алгоритмы работы которых очень легко распараллелить. Также родились мультимедийные приложения, например, кодировщик FlacCL, позволяющий перекодировать звуковую дорожку в формат FLAC. Поддержкой GPGPU обзавелись и некоторые уже существовавшие ранее приложения, самым заметным из которых стал ImageMagick, который теперь умеет перекладывать часть своей работы на графический процессор с помощью OpenCL. Также есть проекты по переводу на CUDA/OpenCL (не любят юниксоиды ATi) архиваторов данных и других систем сжатия информации. Наиболее интересные из этих проектов мы рассмотрим в следующих разделах статьи, а пока попробуем разобраться с тем, что нам нужно для того, чтобы все это завелось и стабильно работало.
GPU уже давно обогнали x86-процессоры в производительности
Во-первых, понадобится видеокарта, поддерживающая технологию CUDA или Stream. Необязательно, чтобы она была топовая, достаточно только, чтобы год ее выпуска был не менее 2009. Полный список поддерживаемых видюшек можно посмотреть в Википедии: en.wikipedia.org/wiki/CUDA и en.wikipedia.org/wiki/AMD_Stream_Processor. Также о поддержке той или иной технологии можно узнать, прочитав документацию, хотя в большинстве случаев будет достаточным взглянуть на коробку из под видеокарты или ноутбука, обычно на нее наклеены различные рекламные стикеры.
Во-вторых, в систему должны быть установлены последние проприетарные драйвера для видеокарты, они обеспечат поддержку как родных для карточки технологий GPGPU, так и открытого OpenCL.
И в-третьих, так как пока дистрибутивостроители еще не начали распространять пакеты приложений с поддержкой GPGPU, нам придется собирать приложения самостоятельно, а для этого нужны официальные SDK от производителей: CUDA Toolkit или ATI Stream SDK. Они содержат в себе необходимые для сборки приложений заголовочные файлы и библиотеки.
Ставим CUDA Toolkit
Идем по вышеприведенной ссылке и скачиваем CUDA Toolkit для Linux (выбрать можно из нескольких версий, для дистрибутивов Fedora, RHEL, Ubuntu и SUSE, есть версии как для архитектуры x86, так и для x86_64). Кроме того, там же надо скачать комплекты драйверов для разработчиков (Developer Drivers for Linux, они идут первыми в списке).
Запускаем инсталлятор SDK:
$ sudo sh cudatoolkit_4.0.17_linux_64_ubuntu10.10.run
Когда установка будет завершена, приступаем к установке драйверов. Для этого завершаем работу X-сервера:
# sudo /etc/init.d/gdm stop
Открываем консоль <Ctrl+Alt+F5> и запускаем инсталлятор драйверов:
$ sudo sh devdriver_4.0_linux_64_270.41.19.run
После окончания установки стартуем иксы:
$ startx
Чтобы приложения смогли работать с CUDA/OpenCL, прописываем путь до каталога с CUDA-библиотеками в переменную LD_LIBRARY_PATH:
$ export LD_LIBRARY_PATH=/usr/local/cuda/lib64
Или, если ты установил 32-битную версию:
$ export LD_LIBRARY_PATH=/usr/local/cuda/lib32
Также необходимо прописать путь до заголовочных файлов CUDA, чтобы компилятор их нашел на этапе сборки приложения:
$ export C_INCLUDE_PATH=/usr/local/cuda/include
Все, теперь можно приступить к сборке CUDA/OpenCL-софта.
Ставим ATI Stream SDK
Stream SDK не требует установки, поэтому скачанный с сайта AMD-архив можно просто распаковать в любой каталог (лучшим выбором будет /opt) и прописать путь до него во всю ту же переменную LD_LIBRARY_PATH:
$ wget http://goo.gl/CNCNo
$ sudo tar -xzf ~/AMD-APP-SDK-v2.4-lnx64.tgz -C /opt
$ export LD_LIBRARY_PATH=/opt/AMD-APP-SDK-v2.4-lnx64/lib/x86_64/
$ export C_INCLUDE_PATH=/opt/AMD-APP-SDK-v2.4-lnx64/include/
Как и в случае с CUDA Toolkit, x86_64 необходимо заменить на x86 в 32-битных системах. Теперь переходим в корневой каталог и распаковываем архив icd-registration.tgz (это своего рода бесплатный лицензионный ключ):
$ sudo tar -xzf /opt/AMD-APP-SDK-v2.4-lnx64/icd-registration.tgz -С /
Проверяем правильность установки/работы пакета с помощью инструмента clinfo:
$ /opt/AMD-APP-SDK-v2.4-lnx64/bin/x86_64/clinfo
ImageMagick и OpenCL
Поддержка OpenCL появилась в ImageMagick уже достаточно давно, однако по умолчанию она не активирована ни в одном дистрибутиве. Поэтому нам придется собрать IM самостоятельно из исходников. Ничего сложного в этом нет, все необходимое уже есть в SDK, поэтому сборка не потребует установки каких-то дополнительных библиотек от nVidia или AMD. Итак, скачиваем/распаковываем архив с исходниками:
$ wget http://goo.gl/F6VYV
$ tar -xjf ImageMagick-6.7.0-0.tar.bz2
$ cd ImageMagick-6.7.0-0
Далее устанавливаем инструменты сборки:
$ sudo apt-get install build-essential
Запускаем конфигуратор и грепаем его вывод на предмет поддержки OpenCL:
$ LDFLAGS=-L$LD_LIBRARY_PATH ./confi gure | grep -e cl.h -e OpenCL
Правильный результат работы команды должен выглядеть примерно так:
checking CL/cl.h usability... yes
checking CL/cl.h presence... yes
checking for CL/cl.h... yes
checking OpenCL/cl.h usability... no
checking OpenCL/cl.h presence... no
checking for OpenCL/cl.h... no
checking for OpenCL library... -lOpenCL
Словом «yes» должны быть отмечены либо первые три строки, либо вторые (или оба варианта сразу). Если это не так, значит, скорее всего, была неправильно инициализирована переменная C_INCLUDE_PATH. Если же словом «no» отмечена последняя строка, значит, дело в переменной LD_LIBRARY_PATH. Если все окей, запускаем процесс сборки/установки:
$ sudo make install clean
Проверяем, что ImageMagick действительно был скомпилирован с поддержкой OpenCL:
$ /usr/local/bin/convert -version | grep Features
Features: OpenMP OpenCL
Теперь измерим полученный выигрыш в скорости. Разработчики ImageMagick рекомендуют использовать для этого фильтр convolve:
$ time /usr/bin/convert image.jpg -convolve '-1, -1, -1, -1, 9, -1, -1, -1, -1' image2.jpg
$ time /usr/local/bin/convert image.jpg -convolve '-1, -1, -1, -1, 9, -1, -1, -1, -1' image2.jpg
Некоторые другие операции, такие как ресайз, теперь тоже должны работать значительно быстрее, однако надеяться на то, что ImageMagick начнет обрабатывать графику с бешеной скоростью, не стоит. Пока еще очень малая часть пакета оптимизирована с помощью OpenCL.
FlacCL (Flacuda)
FlacCL — это кодировщик звуковых файлов в формат FLAC, задействующий в своей работе возможности OpenCL. Он входит в состав пакета CUETools для Windows, но благодаря mono может быть использован и в Linux. Для получения архива с кодировщиком выполняем следующую команду:
$ mkdir flaccl && cd flaccl
$ wget www.cuetools.net/install/flaccl03.rar
Далее устанавливаем unrar, mono и распаковываем архив:
$ sudo apt-get install unrar mono
$ unrar x fl accl03.rar
Чтобы программа смогла найти библиотеку OpenCL, делаем символическую ссылку:
$ ln -s $LD_LIBRARY_PATH/libOpenCL.so libopencl.so
Теперь запускаем кодировщик:
$ mono CUETools.FLACCL.cmd.exe music.wav
Если на экран будет выведено сообщение об ошибке «Error: Requested compile size is bigger than the required workgroup size of 32», значит, у нас в системе слишком слабенькая видеокарта, и количество задействованных ядер следует сократить до указанного числа с помощью флага ‘—group-size XX’, где XX — нужное количество ядер.
Сразу скажу, из-за долгого времени инициализации OpenCL заметный выигрыш можно получить только на достаточно длинных дорожках. Короткие звуковые файлы FlacCL обрабатывает почти с той же скоростью, что и его традиционная версия.
oclHashcat или брутфорс по-быстрому
Как я уже говорил, одними из первых поддержку GPGPU в свои продукты добавили разработчики различных крэкеров и систем брутфорса паролей. Для них новая технология стала настоящим святым граалем, который позволил с легкостью перенести от природы легко распараллеливаемый код на плечи быстрых GPU-процессоров. Поэтому неудивительно, что сейчас существуют десятки самых разных реализаций подобных программ. Но в этой статье я расскажу только об одной из них — oclHashcat.
oclHashcat — это ломалка, которая умеет подбирать пароли по их хэшу с экстремально высокой скоростью, задействуя при этом мощности GPU с помощью OpenCL. Если верить замерам, опубликованным на сайте проекта, скорость подбора MD5-паролей на nVidia GTX580 составляет до 15800 млн комбинаций в секунду, благодаря чему oclHashcat способен найти средний по сложности восьмисимвольный пароль за какие-то 9 минут.
Программа поддерживает OpenCL и CUDA, алгоритмы MD5, md5($pass.$salt), md5(md5($pass)), vBulletin < v3.8.5, SHA1, sha1($pass.$salt), хэши MySQL, MD4, NTLM, Domain Cached Credentials, SHA256, поддерживает распределенный подбор паролей с задействованием мощности нескольких машин.
Автор не раскрывает исходники (что, в общем-то, логично), но у программы есть нормально работающая Linux-версия, которую можно получить на официальной страничке.
Далее следует распаковать архив:
$ 7z x oclHashcat-0.25.7z
$ cd oclHashcat-0.25
И запустить программу (воспользуемся пробным списком хэшей и пробным словарем):
$ ./oclHashcat64.bin example.hash ?l?l?l?l example.dict
oclHashcat откроет текст пользовательского соглашения, с которым следует согласиться, набрав «YES». После этого начнется процесс перебора, прогресс которого можно узнать по нажатию <s>. Чтобы приостановить процесс, кнопаем <p>, для возобновления — <r>. Также можно использовать прямой перебор (например, от aaaaaaaa до zzzzzzzz):
$ ./oclHashcat64.bin hash.txt ?l?l?l?l ?l?l?l?l
И различные модификации словаря и метода прямого перебора, а также их комбинации (об этом можно прочитать в файле docs/examples.txt). В моем случае скорость перебора всего словаря составила 11 минут, тогда как прямой перебор (от aaaaaaaa до zzzzzzzz) длился около 40 минут. В среднем скорость работы GPU (чип RV710) составила 88,3 млн/с.
Выводы
Несмотря на множество самых разных ограничений и сложность разработки софта, GPGPU — будущее высокопроизводительных настольных компов. Но самое главное — использовать возможности этой технологии можно прямо сейчас, и это касается не только Windows-машин, но и Linux.
Info
- Суть технологии GPGPU — произвольные вычисления на видеокартах.
- Существует OpenCL SDK, разрабатываемый компанией Intel, но пока с его помощью можно запускать приложения только на классическом CPU.
- FASTRA II — суперкомпьютер, построенный с использованием 13 видеокарт, мощностью 12TFLOPS.
Links
- bzip2-cuda.github.com — реализация архиватора bzip2с использованием CUDA.
- www.hoopoe-cloud.com — облачный сервис, позволяющий загружать и запускать софт с поддержкой CUDA и OpenCL.
Видеокарта (GPU) против процессора (CPU): что важнее всего для игр на ПК
Некоторые решения для игровых ПК просты. Например, ответ на вопрос о том, следует ли обновить пространство на жестком диске (HDD) или твердотельном диске (SSD). Многие, скорее всего, с энтузиазмом ответят «Да!». Другие решения, однако, намного сложнее. Узнать, следует ли вам обновить ваш процессор или графический процессор, например, гораздо сложнее. Мы здесь, чтобы помочь с этим решением.
Что такое процессор?
Центральный процессор (ЦП), также называемый «процессор», выполняет и управляет инструкциями компьютерной программы, выполняя операции ввода / вывода (I / O), базовую арифметику и логику. Неотъемлемая часть любого компьютера, процессор получает, направляет и обрабатывает данные компьютера. Поскольку это обычно самый важный компонент, его часто называют «мозгом» или «сердцем» настольного или портативного компьютера, в зависимости от того, какую часть тела вы считаете наиболее важной. И когда дело доходит до игр, это довольно важный компонент игровой системы.
Исторически сложилось так, что у процессоров было только одно ядро, которое было бы сосредоточено на одной задаче. Однако современные процессоры имеют от 2 до 28 ядер, каждое из которых ориентировано на уникальную задачу. Таким образом, многоядерный процессор представляет собой один чип, который содержит два или более ядер процессора.
А процессоры с большим количеством ядер более эффективны, чем с меньшим. Двухъядерные (или 2-ядерные) процессоры распространены, но процессоры с 4 ядрами, также называемые четырехъядерными процессорами (например, процессоры Intel® Core ™ 8-го поколения), становятся все более популярными.
Что такое графический процессор?
Графический процессор (GPU), также называемый графической картой или видеокартой, представляет собой специализированную электронную схему, которая ускоряет создание и рендеринг изображений, видео и анимации. Он выполняет быстрые математические вычисления, освобождая процессор для выполнения других задач.
Существует два типа графических процессоров: один представляет собой интегрированный (или встроенный) графический процессор, который живет непосредственно и совместно использует память с процессором. А другой — это дискретный графический процессор, имеющий собственную карту и память.
Графический процессор является чрезвычайно важным компонентом игровой системы, а во многих случаях даже более важным, чем центральный процессор, когда дело доходит до игры в определенные типы игр.
Простое описание: GPU — это однокристальный процессор, который используется главным образом для управления и повышения производительности видео и графики.
В чем «основная» разница между процессором и графическим процессором
В то время как процессор использует несколько ядер, ориентированных на последовательную обработку, графический процессор создан для многозадачности; он имеет от сотен до тысяч меньших ядер для одновременной обработки тысяч потоков (или инструкций). Некоторые процессоры используют технологию многопоточности (в частности, Intel Hyper-Threading), которая позволяет одному ядру процессора работать как два отдельных виртуальных (или «логических») ядра или потока. Идея состоит в том, что они могут разделить рабочую нагрузку между собой и увеличить количество инструкций, действующих на отдельные данные, при одновременном выполнении, что повышает производительность.
Что важнее для игр на ПК: процессор или графический процессор?
Для многих, GPU универсально оценивается как наиболее важный для игр на ПК. Это потому, что GPU — это то, что на самом деле отображает изображения, сцены и анимации, которые вы видите. Большинство современных динамичных игр невероятно требовательны к типу мощности рендеринга, который обеспечивает GPU. В то же время эти игры предназначены для использования преимуществ нескольких ядер и потоков, которые предлагают новые процессоры. И CPU, и GPU важны сами по себе. Для требовательных игр требуется как мощный процессор, так и мощный графический процессор. Но вопрос, насколько они важны для игр на ПК, зависит от того, для чего они будут использоваться в первую очередь, и для каких игр в частности.
Во время игры центральным процессорам даются определенные задачи, которые GPU не так хорошо выполняет, такие как функции искусственного интеллекта (ИИ) неигровых персонажей (NPC). Однако многие задачи лучше выполнять графическому процессору. Некоторые игры работают лучше с большим количеством ядер, потому что они фактически используют их. Другие не могут, потому что они запрограммированы на использование только одного ядра, и игра работает лучше с более быстрым процессором. В противном случае у него не будет достаточно мощности и он будет тормозить. Minecraft, например, работает только с одним ядром, поэтому ему не требуется дополнительная мощность. В этом случае скорость процессора — единственное, что будет влиять на количество кадров в секунду (FPS) во время игры.
Какие типы игр требуют больше труда от процессора?
Современные быстро развивающиеся игры, в том числе шутеры от первого лица (FPS), многопользовательские игры созданы для того, чтобы воспользоваться преимуществами новейших процессоров, их многоядерных процессоров и потоков.
Например, многопользовательская игра-шутер от первого лица Call of Duty: Black Ops 4 рекомендует по крайней мере четырехъядерный процессор: либо Intel i5-2500K, который имеет 4 ядра и 4 потока, либо AMD Ryzen R5 1600X, который имеет 6 ядра и 12 потоков. Но для игроков, использующих мониторы с высокой частотой обновления (1080p), игра фактически рекомендует AMD Ryzen 1800X (8-ядерный процессор с 16 потоками) или Intel i7-8700K (который имеет 6 ядер и 12 потоков). Восьмое поколение Intel i7-8700K является одним из самых быстрых процессоров с одними из самых высоких тактовых частот (ускорение 4,7 ГГц), которые Intel предлагает для игр и потоковой передачи.
Точно так же известная многопользовательская ролевая онлайн-игра (MMORPG) World of Warcraft рекомендует также четырехъядерные процессоры: Intel i7-4770 (4 ядра, 8 потоков) или AMD FX-8310 (8 ядер, 8 потоков) или выше. Чрезвычайно популярная онлайн-игра Grand Theft Auto V с открытым миром рекомендует Intel i5 3470 (4 ядра, 4 потока) или AMD FX-8350 (8 ядер, 8 потоков). А в эпической игре Battle Royale компании Fortnite Battle Royale рекомендуется процессор Intel i5 с тактовой частотой 2,8 ГГц с 4 ядрами и 4 потоками.
Какие типы игр требуют больше труда от GPU?
Большинство современных игр требуют от GPU много, может быть, даже больше, чем от CPU. Для обработки 2D и 3D графики, рендеринга полигонов, отображения текстур и многого другого требуются мощные и быстрые графические процессоры. Чем быстрее ваша графическая / видеокарта (GPU) сможет обрабатывать информацию, тем больше кадров вы будете получать каждую секунду.
Например, для Call of Duty: Black Ops 4 рекомендуется использовать графические карты NVIDIA GeForce GTX 970 4 ГБ, GTX 1060 6 ГБ или Radeon R9 390 / AMD RX 580. Все они считаются картами среднего уровня, подходящими для игр в формате 1080p. и запускать игры на средних или даже высоких настройках с более высоким разрешением. Обозначение 1080p относится к разрешению (Full HD) 1920 x 1080 пикселей.
Для более конкурентоспособных игроков Call of Duty: Black Ops 4 рекомендует видеокарты GeForce GTX 1080 или Radeon RX Vega 64. Они считаются высококлассными картами, которые хороши для игр с разрешением 1440p Quad HD (QHD) или мониторами с более высокой частотой обновления, а также VR-гарнитурами.
Но вам нужно убедиться, что у вас есть монитор, соответствующий этим спецификациям (скажем, с частотой обновления 144 Гц), в противном случае не будет смысла приобретать более дорогую и более дорогую видеокарту. И обратное также верно: если у вас есть монитор с частотой обновления до 60 Гц, он не сможет идти в ногу с более мощной картой с пиксельным подталкиванием.
Для World of Warcraft рекомендуется использовать графический процессор NVIDIA GeForce GTX 960 4 ГБ или AMD Radeon R9 280 или выше. GTX 960 предлагает стабильную производительность 1080p с энергосберегающим потреблением и работает круче и тише, чем предыдущие модели. Хотя R9 280 имеет больше видеопамяти, чем GTX 960, оба графических процессора могут запускать требовательные игры при высоких настройках.
Как приключенческая игра Grand Theft Auto V, так и королевская битва Fortnite Battle Royale рекомендуют NVIDIA GeForce GTX 660 2 ГБ или AMD Radeon HD 7870 2 ГБ. Оба графических процессора по приемлемой цене созданы для быстрой игры в формате 1080p.
Должен ли я обновить свой графический процессор или процессор?
В идеальном мире вы бы просто купили лучшее из обоих. К сожалению, бюджетные ограничения могут привести к необходимости выбора одного или другого, по крайней мере, на данный момент. Многие игры теперь используют больше ядер как само собой разумеющееся (четырехъядерный процессор кажется наиболее распространенным) и, таким образом, имеют более быстрые и лучшие скорости FPS. Так что вы, вероятно, захотите пойти с чуть более дорогими четырехъядерными процессорами, если они не слишком дорогие. Современные двухъядерные процессоры могут стать узким местом для вашей видеокарты и привести к снижению производительности вашей игры, если только ваш графический процессор не является более старой и менее мощной версией.Четырехъядерные процессоры также являются более доступными, более производительными и менее медленными, чем более ранние версии. Все больше и больше новых игр, основанных на нескольких ядрах, а не только на скорости процессора, имеет смысл иметь больше ядер в вашей системе. На самом деле, если вы заядлый геймер и смотрите в будущее и хотите быть уверенным, что сможете запускать самые мощные игры с тройным А (AAA) в будущем — и, что еще важнее, вы можете позволить себе чрезвычайно высокие цены — возможно, имеет смысл использовать премиум-опции в процессорах или графических процессорах.
Что касается процессоров, один из самых мощных процессоров Intel на рынке сегодня — Intel Core i9. Две модели, i9-8950HK и i9-9900K, обе предлагают невероятно высокую производительность и скорость обработки игрового процесса с 8 ядрами и 16 потоками. А если у вас есть или вы планируете купить монитор 4K / Ultra High Definition (UHD), который предлагает более 8 миллионов пикселей, вы можете рассмотреть возможность обновления вашего GPU до карты, подобной NVIDIA GeForce RTX 2080 Ti. Это стоит более 1000 долларов.
Нижняя линия
Графические процессоры могут быть самой дорогой частью вашей игровой сборки, поэтому, если у вас более строгий бюджет, то неплохо было бы сохранить часть этого для своего процессора. Если вы тратите слишком много на графический процессор, не обращая внимания на процессор, то ваш игровой процесс может пострадать с более низкой частотой кадров в секунду.
Обновите свой процессор первым
Если вам нравятся быстро развивающиеся игры, такие как шутеры от первого лица, такие как Call of Duty: Black Ops 4, или стратегические игры в реальном времени, такие как The Age of Empires, или MMORPG, такие как World of Warcraft, то, вероятно, имеет смысл обновить ваш процессор первым.
Обновите свой GPU первым
С другой стороны, если вы в основном играете в онлайн-игры с открытым миром с четко определенной, захватывающей средой и потрясающими визуальными эффектами, такими как Grand Theft Auto V или RPG, такие как The Elder Scrolls V: Skyrim или The Witcher III: Wild Hunt, то сначала обновите GPU.
Что нужно учитывать при обновлении видеокарты
Если вы думаете об обновлении видеокарты, вот несколько вещей, которые следует учитывать:
1. Разрешение монитора. Большинство современных видеокарт соответствуют минимальным игровым требованиям для разрешения 1080p. Тем не менее, вам потребуется карта высокого класса, чтобы соответствовать любому монитору с разрешением 1440 пикселей и выше, включая QHD, WQHD и UHD или 4K.
2. Частота обновления: если ваш монитор имеет частоту обновления 144 Гц или выше, то вам также понадобится карта, которая столь же мощна, чтобы использовать ее потенциал. В то же время монитор с частотой обновления 60 Гц не нуждается в мощной и более дорогой видеокарте.
3. Память: память не только имеет значение в процессоре. Ваш графический процессор должен предлагать не менее 4 ГБ для интенсивных игр с
разрешением 1080p и не менее 8 ГБ, если вы хотите увеличить его до 4K мегаигр.
4. Форм-фактор: проверьте характеристики видеокарты, поскольку высота, длина и обхват — это важные измерения, которые следует учитывать для вашего графического процессора. Вам это нужно, чтобы соответствовать вашей игровой системе или корпусу.
5. AMD FreeSync или NVIDIA G-Sync: эти две технологии синхронизируют частоту обновления между графическим процессором и монитором, чтобы уменьшить или устранить разрывы. Перед покупкой новой видеокарты обязательно проверьте, какую технологию поддерживает ваш монитор.
6. Поддержка VR: Если вы собираетесь использовать одну из двух основных платформ виртуальных игр для ПК — HTC Vive или Oculus Rift — вам понадобятся как минимум карты среднего уровня, такие как NVIDIA GTX 1060/1070/1080. или AMD Radeon RX 570/580.
Знайте свои игровые требования
Обновление вашей игровой системы и, в частности, вашего процессора или графического процессора — это очень субъективная ситуация. Вы можете захотеть сделать это, чтобы играть в определенную игру или игру определенного типа. Вы можете быть случайным игроком, который просто хочет играть в разные типы игр время от времени. Или вы можете быть заядлым геймером, который играет достаточно для того, чтобы получить необходимую обработку и производительность, которые будут соответствовать загруженному графику игр.
Существует также ваш бюджет для рассмотрения. Если у вас есть ограниченное количество средств для работы, но вы можете периодически добавлять в свою игровую систему, тогда может иметь смысл сделать дополнительные, более экономичные обновления. Но если вы знаете, что вы будете играть самые последние и лучшие игры AAA, как только они будут выпущены, и у вас есть доступный бюджет, то переход на высокопроизводительный процессор и графический процессор, который вы можете себе позволить, может стоить того.