
Подбор чипсета блоков растеризации — 48 — МИР NVIDIA
Фильтры- Блоков растеризации — 48
Кодовое имя Условное обозначение графического процессора | GF100 | GF110 |
|---|---|---|
Год выхода | 2010 | |
PCI DeviceID Идентификатор шины PCI графического процессора | 06C0 | 1080 |
Частота вычислительных блоков в режиме 3D, МГц Частота работы шейдерных процессоров (SPU) при использовании 3D функций | 1401 | 1544 |
Частота блоков рендеринга в режиме 3D, МГц Частота работы блоков рендеринга (TMU и ROP) при использовании 3D функций | 700 | 772 |
Транзисторов, млн | 3000 | |
Технологический процесс, нм Технологическая норма изготовления графического процессора | 40 | |
Вычислительных блоков Число шейдерных процессоров (SPU) | 480 | 512 |
Блоков текстурирования Число блоков наложения текстур (TMU) | 60 | 64 |
Блоков растеризации Число блоков растеризации (ROP) | 48 | |
Максимально накладываемых текстур за проход | 60 | 64 |
Вычислительная производительность, гигафлопс Одинарная точность | 1345 | 1581 |
Вычислительная производительность, гигафлопс Двойная точность | 168. 1 1 | 197.6 |
Cкорость заполнения сцены, млн. пикселей/с Fillrate, без текстурирования | 33600 | 37060 |
Cкорость заполнения сцены, млн. текселей/с Fillrate, с текстурированием | 42000 | 49410 |
Тип видеопамяти Поддерживаемые типы видеопамяти | GDDR5 | |
Максимальный объем видеопамяти, МБ Максимальный поддерживаемый графическим процессором объем видеопамяти | 3072 | |
Ширина шины видеопамяти, бит | 384 | |
Частота шины видеопамяти, МГц Опорная частота шины данных, ½ от DDR | 1848 | 2004 |
Полоса пропускания шины видеопамяти, ГБ/с | 177.4 | 192.4 |
Интерфейс шины Поддерживаемые шины компьютера | PCI Express 2.0 x16 | |
Поддержка SLI Поддерживаемые графическим процессором режимы NVIDIA SLI | SLI, 3-Way SLI, 4-Way SLI | |
Универсальные шейдеры, версия Максимальная поддерживаемая версия универсальных шейдеров | 5. 0 0 | |
Тесселяция (tesselation) Поддерживаемые алгоритмы тесселяции | программируемая | |
Кубические карты среды (CEM) | Да | |
Наложение рельефа (Bump mapping) Поддерживаемые алгоритмы наложения рельефа | Emboss, DOT3, EMBM | |
Объемные (3D) текстуры | Да | |
Сжатие текстур Поддерживаемые алгоритмы сжатия текстур | S3TC, RGTC, BCTC | |
Paletted (indexed) текстуры Поддержка текстур с индексированной цветовой палитрой | Нет | |
Текстуры произвольного размера Поддержка текстур с размерами, не кратными 2 | Да | |
Максимальный размер текстур, пикселей | 16384×16384 | |
Форматы буфера глубины Поддерживаемые форматы буфера глубины | Z (16b, 24b fixed, 32b float) | |
UltraShadow, версия Поддержка технологии NVIDIA UltraShadow | 2. 0 0 | |
Степени анизотропной фильтрации (AF) | 2, 4, 8, 16 | |
Степени полноэкранного сглаживания (FSAA) | MSAA RGS 2x, 4x, 8xQ CSAA 8x, 16x, 16xQ, 32x | |
Максимальная глубина цвета на канал, бит Внутренняя для 3D рендеринга | 32 | |
Расширенный динамический диапазон цветопередачи (HDR), бит | 128 | |
Параллельный рендеринг (MRT) Рендеринг одновременно в № буферов | 8 | |
Декодирование MPEG-2 Поддерживаемые уровни декодирования видео | VLD, IDCT, MoComp | |
Декодирование WMV Поддерживаемые уровни декодирования видео | IDCT | |
Декодирование VC-1 Поддерживаемые уровни декодирования видео | VLD, IDCT | |
Декодирование H. Поддерживаемые уровни декодирования видео | VLD_NoFGT | |
Декодирование AVC MVC Ускорение декодирования для Blu-Ray 3D | Да | |
Dual-Stream Поддержка декодирования двух видеопотоков одновременно | Да | |
Устранение чересстрочности (Deinterlacing) Поддерживаемые алгоритмы устранения чересстрочности | PixelAdaptive | |
Поддержка Direct3D, версия Маскимальная поддерживаемая версия API | 11.0 | |
Поддержка OpenGL, версия Маскимальная поддерживаемая версия API | 4.1 | |
Поддержка CUDA, ComputeCapability | 2.0 | |
Поддержка PhysX | Да | |
Поддержка OpenCL, версия Маскимальная поддерживаемая версия API | 1.0 | |
Поддержка DXVA, версия Маскимальная поддерживаемая версия API | 2. 0 0 | |
Поддержка XvMC | Нет | |
Поддержка VDPAU Поддерживаемый набор функций для API, A<B<C | C | |
Частота интегрированного RAMDAC, МГц | 2×400 | |
Максимальное разрешение для VGA | 2048*1536*85 Гц | |
Максимальное разрешение для цифрового подключения | 2560*1600*60 Гц | |
Поддержка TwinView Возможность одновременной работы с двумя дисплеями | Да | |
Поддержка 30-битного режима | нет данных | |
Интегрированная поддержка TV-выхода Аналоговый ТВ-выход (Composite и S-Video) | Нет | |
Интегрированная поддержка HDTV Аналоговый ТВ-выход (Component YPbPr) | Нет | |
Интегрированная поддержка DVI, версия Трансмиттер TMDS | 2xDual-Link | |
Интегрированная поддержка DisplayPort, версия | 1. 1 1 | |
Интегрированная поддержка HDMI | 1.4 | |
Поддержка HDCP Система защиты цифрового сигнала (DRM) | Да | |
HDMI Audio, Вт Поддерживаемые форматы звука | LPCM 7.1, DD 5.1, DD+ 7.1, DTS 5.1, AAC 5.1 | |
Максимальное энергопотребление, Вт | 300 | 260 |
Усиление электропитания Тип коннектора | PCIE 8p + PCIE 6p | |
 264
264AMD представила флагмана профессиональных видеокарт
|
Компания AMD официально представила свою флагманскую профессиональную видеокарту для рабочих станций AMD FirePro W9100 с архитектурой Graphics Core Next, впервые анонсированную в марте. По словам производителя, новая графика AMD FirePro W9100 отличается первой в отрасли ультрабыстрой встроенной памятью GDDR5 объемом 16 ГБ, более 2 TFLOPS вычислительной производительности с двойной точностью и поддержкой нескольких 4K мониторов. Пользователи рабочих станций с такой видеокартой могут выполнять множество задач одновременно на 6 4K мониторах, загружать большие блоки и массивы данных для управления ими, а также редактировать, применять цветокоррекцию или накладывать различные эффекты на 4K видео-проекты в режиме реального времени. Видеокарта получила чип Hawaii с 2816 потоковыми процессорами, 176 текстурными блоками и 64 блоками растеризации. Тактовая частота GPU составляет 930 МГц, а памяти — 5 ГГц. 16 ГБ памяти GDDR5 обладают 512-битным интерфейсом и пропускной способностью в 320 ГБ/с для редактирования 4K видео. Видеокарта обеспечивает 2,62 терафлопс максимальной вычислительной мощности двойной точности и 5,24 терафлопс максимальной вычислительной производительности с одинарной точностью. Предусмотрена возможность сочетать до четырех графических карт AMD FirePro W9100 в одной настольной системе. С помощью шести выходов Mini DisplayPort 1.2, AMD FirePro W9100 может работать на шести 4K экранах. Функции5,24 терафлопс пиковой производительности при обработке чисел одинарной точности с плавающей запятой Память GDDR5 объемом 16Гб Разрешение 4К Поддержка OpenClTM 2.0 Поддержка DirectGMA и SDI Кадровая синхронизация/синхронизация по тактовой частоте Технические характеристикиОперативная память
Производительность вычислений
Параметры вывода
API/Характеристики/Поддержка ОС
Охлаждение/Потребляемая мощность/Форм-фактор
Системные требования
Данные видеокарты доступны под заказ, спрашивайте у вашего менеджера. 1.Требуются 4K дисплеи и контент; производительность зависит от размера файла. Технология AMD Eyefinity поддерживает до шести мониторов DisplayPort™ на задействованной видеокарте. Поддерживаемое количество, тип и разрешение мониторов отличаются в зависимости от модели и конструкции платы. Уточняйте характеристики у производителя перед совершением покупки. Для подключения трех и более мониторов, либо нескольких мониторов к одному выходу, требуется дополнительное оборудование (например, мониторы с поддержкой DisplayPort или концентраторы с поддержкой DisplayPort 1.2 MST). В обычных системах рекомендуется использовать не более двух активных адаптеров. Дополнительная информация представлена на сайте www.amd.com/eyefinityfaq. Уточняйте характеристики у производителя перед совершением покупки. Для подключения трех и более мониторов, либо нескольких мониторов к одному выходу, требуется дополнительное оборудование (например, мониторы с поддержкой DisplayPort или концентраторы с поддержкой DisplayPort 1.2 MST). В обычных системах рекомендуется использовать не более двух активных адаптеров. Дополнительная информация представлена на сайте www.amd.com/eyefinityfaq.2.Видеокарта AMD FirePro™ W9100 обеспечивает 2,62 терафлопса при обработке чисел двойной точности с плавающей запятой, а видеокарта наивысшей производительности компании Nvidia — Quadro K6000, вышедшая на рынок в апреле 2014 года, обладает лишь 1,72 терафлопсами при обработке чисел двойной точности с плавающей запятой. Посетите веб-сайт http://www.nvidia.com/content/PDF/line_card/6660-nv-prographicssolutions-linecard-july13-final-lr.pdf для ознакомления со спецификациями продуктов Nvidia. FP-87, FP-89 3.AMD планирует выпустить драйверы OpenCL 2.  0 для видеокарт AMD FirePro во втором квартале 2014 года; соответственное тестирование запланировано на то же время. 0 для видеокарт AMD FirePro во втором квартале 2014 года; соответственное тестирование запланировано на то же время.4. AMD HD3D — технология, разработанная для поддержки стерео 3D в таких приложениях, как САПР и создания цифрового контента. Для включения стереоскопического 3D требуется дополнительное оборудование (например, панели с поддержкой 3D, очки/излучатель с поддержкой 3D, привод Blu-ray 3D) и/или программное обеспечение (например, диски Blu-ray 3D, промежуточное ПО 3D, приложения). Некоторые функции могут не поддерживаться отдельными компонентами или системами. Пожалуйста, уточните возможности модели и поддерживаемые ей технологии у производителя компонента или системы перед покупкой. |




 2 4096×2160
2 4096×2160 0, интерфейс шины x16
0, интерфейс шины x16|
⇐ ПредыдущаяСтр 3 из 8Следующая ⇒
Эти блоки работают совместно с шейдерными процессорами всех указанных типов, ими осуществляется выборка и фильтрация текстурных данных, необходимых для построения сцены.
Блоки операций растеризации (ROP)
Блоки растеризации осуществляют операции записи рассчитанных видеокартой пикселей в буферы и операции их смешивания (блендинга). Как уже отмечалось выше, производительность блоков ROP влияет на филлрейт и это — одна из основных характеристик видеокарт. И хотя в последнее время её значение несколько снизилось, еще попадаются случаи, когда производительность приложений сильно зависит от скорости и количества блоков ROP.
Объем видеопамяти
Собственная память используется видеочипами для хранения необходимых данных: текстур, вершин, буферов и т.п. Казалось бы, что чем её больше — тем лучше. Но не всё так просто, оценка мощности видеокарты по объему видеопамяти — это наиболее распространенная ошибка! Значение объема памяти неопытные пользователи переоценивают чаще всего, используя его для сравнения разных моделей видеокарт. Оно и понятно — раз параметр, указываемый во всех источниках одним из первых, в два раза больше, то и скорость у решения должна быть в два раза выше, считают они. Реальность же от этого мифа отличается тем, что рост производительности растет до определенного объема и после его достижения попросту останавливается. В каждом приложении есть определенный объем видеопамяти, которого хватает для всех данных, и хоть 4 ГБ туда поставь — у нее не появится причин для ускорения рендеринга, скорость будут ограничивать исполнительные блоки. Частота видеопамяти
Еще одним параметром, влияющим на пропускную способность памяти, является её тактовая частота. А как мы поняли выше, повышение ПСП прямо влияет на производительность видеокарты в 3D приложениях. Частота шины памяти на современных видеокартах бывает от 500 МГц до 2000 МГц, то есть может отличаться в четыре раза. И так как ПСП зависит и от частоты памяти и от ширины ее шины, то память с 256-битной шиной, работающая на частоте 1000 МГц, будет иметь большую пропускную способность, по сравнению с 1400 МГц памятью с 128-битной шиной.
Типы памяти
Все современные типы памяти DDR и GDDR позволяют передавать в два раза большее количество данных на той же тактовой частоте за единицу времени, поэтому цифру её рабочей частоты зачастую указывают удвоенной (умножают на два). Так, если для DDR памяти указана частота 1400 МГц, то эта память работает на физической частоте в 700 МГц, но указывают так называемую «эффективную» частоту, то есть ту, на которой должна работать SDR память, чтобы обеспечить такую же пропускную способность. Основное преимущество DDR2 памяти заключается в возможности работы на больших тактовых частотах, а соответственно — увеличении пропускной способности по сравнению с предыдущими технологиями. Это достигается за счет увеличенных задержек, которые, впрочем, не так важны для видеокарт. GDDR3 — это специально предназначенная для видеокарт память, с теми же технологиями, что и DDR2, но с улучшениями характеристик потребления и тепловыделения, что позволило создать микросхемы, работающие на более высоких тактовых частотах. Ну а GDDR4 — это последнее поколение «графической» памяти, работающее почти в два раза быстрее, чем GDDR3. Основными отличиями GDDR4 от GDDR3, существенными для пользователей, являются в очередной раз повышенные рабочие частоты и сниженное энергопотребление. Технически, память GDDR4 не сильно отличается от GDDR3, это дальнейшее развитие тех же идей. Итак, видеопамять самых современных типов: GDDR3 и GDDR4, отличается от DDR некоторыми деталями, но также работает с удвоенной передачей данных. В ней применяются некоторые специальные технологии, позволяющие поднять частоту работы. Так, GDDR2 память обычно работает на более высоких частотах, по сравнению с DDR, GDDR3 — на еще более высоких, ну а GDDR4 обеспечивает максимальную частоту и пропускную способность.
⇐ Предыдущая12345678Следующая ⇒ |
 Число текстурных блоков в видеочипе определяет текстурную производительность, скорость выборки из текстур. И хотя в последнее время большая часть расчетов осуществляется блоками шейдеров, нагрузка на блоки TMU до сих пор довольно велика, и с учетом упора некоторых приложений в производительность блоков текстурирования, можно сказать, что количество блоков TMU и соответствующая высокая текстурная производительность являются одними из важнейших параметров видеочипов. Особое влияние этот параметр оказывает на скорость при использовании трилинейной и анизотропной фильтраций, требующих дополнительных текстурных выборок.
Число текстурных блоков в видеочипе определяет текстурную производительность, скорость выборки из текстур. И хотя в последнее время большая часть расчетов осуществляется блоками шейдеров, нагрузка на блоки TMU до сих пор довольно велика, и с учетом упора некоторых приложений в производительность блоков текстурирования, можно сказать, что количество блоков TMU и соответствующая высокая текстурная производительность являются одними из важнейших параметров видеочипов. Особое влияние этот параметр оказывает на скорость при использовании трилинейной и анизотропной фильтраций, требующих дополнительных текстурных выборок.
 Именно поэтому почти во всех случаях видеокарта с 320 Мбайт видеопамяти будет работать с той же скоростью, что и карта с 640 Мбайт (при прочих равных условиях). Ситуации, когда больший объем памяти приводит к видимому увеличению производительности, существуют, это очень требовательные приложения в высоких разрешениях и при максимальных настройках. Но такие случаи весьма редки, поэтому, объем памяти учитывать конечно нужно, но не забывая о том, что выше определенного объема производительность просто не растет, есть более важные параметры, такие как ширина шины памяти и ее рабочая частота.
Именно поэтому почти во всех случаях видеокарта с 320 Мбайт видеопамяти будет работать с той же скоростью, что и карта с 640 Мбайт (при прочих равных условиях). Ситуации, когда больший объем памяти приводит к видимому увеличению производительности, существуют, это очень требовательные приложения в высоких разрешениях и при максимальных настройках. Но такие случаи весьма редки, поэтому, объем памяти учитывать конечно нужно, но не забывая о том, что выше определенного объема производительность просто не растет, есть более важные параметры, такие как ширина шины памяти и ее рабочая частота.
 И опять же, несмотря на то, что стандарт был разработан в ATI, первой видеокартой, ее использующей, стала вторая модификация NVIDIA GeForce FX 5700 Ultra, а следующей стала GeForce 6800 Ultra.
И опять же, несмотря на то, что стандарт был разработан в ATI, первой видеокартой, ее использующей, стала вторая модификация NVIDIA GeForce FX 5700 Ultra, а следующей стала GeForce 6800 Ultra.
Ресурсы сжатых текстур — UWP applications
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 2 мин
Карты текстуры — это цифровые изображения, нарисованные на трехмерных фигурах для визуальной детализации. Они сопоставляются с этими фигурами на этапе растеризации, и этот процесс может потреблять большие объемы системной шины и памяти. Чтобы уменьшить объем памяти, потребляемый текстурами, Direct3D поддерживает сжатие поверхностей текстуры. Некоторые устройства Direct3D поддерживают сжатые поверхности текстур по умолчанию. На таких устройствах после того как вы создали сжатую поверхность и загрузили в нее данные, поверхность можно использовать в Direct3D как любую другую поверхность текстуры. Direct3D обрабатывает распаковку, если текстура сопоставлена трехмерному объекту.
Они сопоставляются с этими фигурами на этапе растеризации, и этот процесс может потреблять большие объемы системной шины и памяти. Чтобы уменьшить объем памяти, потребляемый текстурами, Direct3D поддерживает сжатие поверхностей текстуры. Некоторые устройства Direct3D поддерживают сжатые поверхности текстур по умолчанию. На таких устройствах после того как вы создали сжатую поверхность и загрузили в нее данные, поверхность можно использовать в Direct3D как любую другую поверхность текстуры. Direct3D обрабатывает распаковку, если текстура сопоставлена трехмерному объекту.
служба хранилища эффективность и сжатие текстур
Все форматы сжатия текстур являются степенью двух. Это не означает, что текстура обязательно должна быть квадратной, но означает, что значения x и y должны быть степенями двух. Например, если текстура изначально имеет размер 512 на 128 байтов, следующая текстура будет иметь размеры 256 на 64 и так далее, при этом каждый уровень будет уменьшаться на степень двух. На более низких уровнях, где текстура фильтруется до 16 на 2 и 8 на 1, будут присутствовать неиспользованные биты, поскольку блок сжатия — это всегда блок текселей 4 на 4. Неиспользованные части блока отбиваются.
На более низких уровнях, где текстура фильтруется до 16 на 2 и 8 на 1, будут присутствовать неиспользованные биты, поскольку блок сжатия — это всегда блок текселей 4 на 4. Неиспользованные части блока отбиваются.
Несмотря на существование неиспользованных битов на более низких уровнях, совокупное преимущество значительно. В худшем случае в теории можно создать структуру 2000 на 1 (нулевая степень 2). В этом случае шифруется только одна строка пикселей на блок, остальная часть блока не используется.
Смешение форматов в пределах одной текстуры
Обратите внимание, что любая текстура должна указывать, что ее данные хранятся по 64 или 128 битов на группу из 16 текселей. Если 64-разрядные блоки (то есть формат BC1 компрессии блоков) используются для текстуры, можно смешать непрозрачные и 1-разрядные альфа-форматы в блоках одной текстуры. Иными словами, сравнение целочисленной величины без знака color_0 и color_1 выполняется уникальным образом для каждого блока 16 пикселей текстуры.
Однако если используются 128-разрядные блоки, необходимо задать альфа-канал в явном (формат BC2) или интерполированном режиме (формат BC3) для всей текстуры. Как и с цветом, при использовании интерполированного режима (формат BC3) на уровне блоков можно использовать режим восьми или шести интерполированных альфа-каналов. Опять же, сравнение alpha_0 и alpha_1 выполняется уникальным образом для каждого блока.
Direct3D предоставляет службы для сжатия поверхностей, которые служат для текстурирования трехмерных моделей. Этот раздел содержит сведения о создании данных на сжатой поверхности текстуры и работе с этими данными.
В этом разделе
Непрозрачные и 1-разрядные альфа-текстуры | Формат текстуры BC1 предназначен для непрозрачных текстур и текстур с одним прозрачным цветом. |
Текстуры с альфа-каналами | Существует два способа кодирования карт текстур с более сложной прозрачностью. |
Сжатие блоков | Сжатие блоков — это метод сжатия текстур с потерями с целью уменьшения размера текстуры и нагрузки на память и, соответственно, повышения производительности. Текстура, сжатая по блокам, может быть меньше, чем текстура с 32 битами на цвет. |
Форматы сжатых текстур | Этот раздел содержит сведения о внутренней организации форматов сжатых текстур. Эти сведения не нужны для того, чтобы использовать сжатые текстуры, потому что для преобразования форматов можно использовать функции Direct3D. Однако эта информация окажется полезной, если потребуется выполнять операции со сжатыми поверхностными данными напрямую. |
 В каждом случае блок, описывающий прозрачность, предшествует 64-разрядному блоку, который уже был описан. Прозрачность представляется либо в виде точечного рисунка 4×4 с 4 битами на пиксель (явная кодировка) или с меньшим количеством битов и линейной интерполяцией, которая аналогична тому, что используется в кодировании цвета.
В каждом случае блок, описывающий прозрачность, предшествует 64-разрядному блоку, который уже был описан. Прозрачность представляется либо в виде точечного рисунка 4×4 с 4 битами на пиксель (явная кодировка) или с меньшим количеством битов и линейной интерполяцией, которая аналогична тому, что используется в кодировании цвета.
Текстуры
Nvidia Turing GPU | PARALLEL.RU
Паонкин А. В.,
ВМК МГУ,
Москва, 2018
Направление вычислений эволюционирует от «централизованной обработки данных» на центральном процессоре до «совместной обработки» на CPU и GPU. GPU обладает тясячами ядер, позволяя добиваться больших ускорений по сравнению с CPU на некоторых задачах.
NVIDIA GPUs следуют программной архитектуре SIMT (Single-Instruction, Multiple-Thread). NVIDIA GPU состоят из нескольких Streaming Multiprocessors(SMs), способных выполнять сотни потоков (threads) одновременно. Мультипроцессор создает, управляет, ставит в очередь и выполняет потоки группами по 32. Такие группы называются варпами (warps). Каждый поток в варпе начинает исполнение с одинакового программного адреса, но у них свои состояния регистров, счетчики адрессов и поэтому поток может осуществлять ветвление. Варп выполняет одну инструкцию за раз, поэтому максимальная эффективность достигается на участках кода без ветвления. Иначе каждая ветка исполняется по очереди, но всё же параллельно.
GPU позволяют достичь на некоторых задачах впечатляющих результатов, но существуют и принципиальные ограничения, не позволяющие этой технологии стать универсальной. Приведем лишь некоторые из них:
- Ускорить на GPU можно только хорошо параллелящийся по данным код. Одно ядро GPU «слабее» процессорного, GPU не обладает планировщиком для внеочередного исполнения команд.
- GPU использует собственную память. Передача данных между памятью GPU и оперативной памятью довольно затратна.
- Алгоритмы с большим количеством ветвлений работают на GPU неэффективно
Nvidia Turing — последняя на данный момент микроархитектура, разработанная компанией NVIDIA. Предыдущая архитектура Volta фокусировалась на ИИ и высокопроизводительных вычислениях, но большинство поддерживаемых архитектурой функций не были нужны в игровой индустрии. Например, отдельные блоки для арифметики с плавающей точкой. Turing же больше направлен на широкое потребление, чем на HPC. В семействе можно выделить несколько ключевых изменений: появление новых вычислительных блоков: тензорных и RT ядер, новая память и архитектура SM.
Например, отдельные блоки для арифметики с плавающей точкой. Turing же больше направлен на широкое потребление, чем на HPC. В семействе можно выделить несколько ключевых изменений: появление новых вычислительных блоков: тензорных и RT ядер, новая память и архитектура SM.
Рис. 1: TU102 — GPU архитектуры Turing
Старший GPU TU102 в данной архитектуре содержит 6 Graphics Processing Clusters (GPC). Каждый кластер содержит блок растеризации и 6 TPC (Texture Processing Clusters), каждый TPC в свою очередь содержит 2 Streaming multiprocessors. В одном SM насчитывается 64 CUDA ядра. И теперь целочисленные операции (INT32) и операции с плавающей запятой (FP32) выполняются параллельно. Профилирование многих приложений на GPU показывает, что в среднем 36 целочисленных операций приходится на 100 с плавающей точкой. Каждый потоковый мультипроцессор также содержит 8 тензорных ядер для матричных вычислений, регистровые файлы размером 256 KB, 4 текстурных юнита(texture units), 96 KB L1/разделяемой памяти. Трассировка лучей выполняется с помощью новых специальных ядер (RT Cores).
Трассировка лучей выполняется с помощью новых специальных ядер (RT Cores).
Итак, TU102 GPU содержит:
- 4,608 CUDA ядер
- 72 RT ядер
- 576 тензорных ядер
- 288 текстурных юнитов
- 12 32-bit контроллеров памяти GDDR6
TU102 GPU включает 96 Rendering output units и 6144 KB L2 кэша.
Turing SM разбит на четыре блока, каждый с 16 FP32, 16 INT32 и 2 Тензорными ядрами, одним планировщиком(warp scheduler) и одним dispatch unit. Каждый блок включает новый L0 кэш инструкций и регистровый файл размером 64 KB. Четыре блока делят 96 KB кэша данных L1 /разделяемой памяти. Раньше кэшу данных отводилось 64 KB, разделяемой памяти — 32 KB, теперь же распределение происходит динаминически(64/32 или 32/64) и зависит от вычислительной нагрузки.
Рис. 2: Turing TU102/TU104/TU106 Streaming Multiprocessor (SM)
Тензорные ядра — специальные вычислительные блоки для тензорных / матричных операций, являющимися ключевыми в области Глубокого Обучения. Дизайн тензорных ядер был улучшен по сравнению с архитектурой Volta GPUs. Самое главное изменение: добавлены новые режимы работы(INT8 и INT4).
Дизайн тензорных ядер был улучшен по сравнению с архитектурой Volta GPUs. Самое главное изменение: добавлены новые режимы работы(INT8 и INT4).
Turing — первая GPU архитектура, поддерживающая память GDDR6. GDDR6 достигает скорости 14 Gb/s и на 20\% энергоэффективнее по сравнению с памятью GDDR5X, используемой в Pascal GPUs.
Рис. 3: Сравнение Turing RTX 2080 и Pascal GTX 1080
| GPU Architecture | Pascal | Volta | Turing |
| GPU Manufacturer | Nvidia | Nvidia | Nvidia |
| Fabrication Process | 14nm / 16nm | 12nm | 12nm |
| CUDA Cores | Yes | Yes | Yes |
| Tensor Cores | NA | Yes | Yes |
| RT Cores | NA | NA | Yes |
| Memory support | DDR4, GDDR5, GDDR5X, HBM2 | HBM2 | GDDR6 |
| VR Ready | Yes | Yes | Yes |
| VirtualLink (USB Type-C) | NA | NA | Yes |
| Multi-GPU support | Yes (in high end cards), SLI and NVLink | NVLink 2 | NVLink 2 / NVLink SLI |
| Graphics Cards | GeForce 10 series, Nvidia Titan X, Nvidia Titan Xp, Quadro P series workstation graphics cards, Quadro GP100 | Nvidia Titan V, Quadro GV100 | Quadro RTX 8000, Quadro RTX 6000, Quadro RTX 5000 / RTX series graphics cards |
| Applications | Gaming, Workstation | Artificial Intelligence (AI), Workstation, Datacenter | Artificial Intelligence (AI), Workstation, Gaming |
| GPU | FP32 | FP16 |
| GTX 1080 Ti | 207 | NA |
| RTX 2080 | 207 | 332 |
| RTX 2080 Ti | 280 | 437 |
| Titan V | 299 | 547 |
Наиболее известными инструментами создания программ, исполняемых на Turing GPU, являются расширения языков C и C++: OpenCL, CUDA, OpenACC. Первая библиотека полезна для создания программ, способных выполняться на различных конфигурациях из графических и центральных процессоров, а также FPGA. CUDA предназначен исключительно для Nvidia GPU, но предоставляет больше функций и традиционно быстрее программ, написанных на OpenCL, при исполнении на архитектурах NVIDIA. Программная архитектура OpenCL похожа на архитектуру CUDA, что позволяет переписать программу с одной платформы на другую.
Первая библиотека полезна для создания программ, способных выполняться на различных конфигурациях из графических и центральных процессоров, а также FPGA. CUDA предназначен исключительно для Nvidia GPU, но предоставляет больше функций и традиционно быстрее программ, написанных на OpenCL, при исполнении на архитектурах NVIDIA. Программная архитектура OpenCL похожа на архитектуру CUDA, что позволяет переписать программу с одной платформы на другую.
- https://wccftech.com/review/nvidia-geforce-rtx-2080-ti-and-rtx-2080-review/2/
- https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
- https://www.nvidia.com/content/dam/en-zz/Solutions/design-visualization/technologies/turing-architecture/NVIDIA-Turing-Architecture-Whitepaper.pdf
- https://habr.com/post/117021/
- https://www.ixbt.com/news/2018/08/22/nvidia-turing-pascal.html
- https://www.pugetsystems.com/labs/hpc/NVIDIA-RTX-2080-Ti-vs-2080-vs-1080-Ti-vs-Titan-V-TensorFlow-Performance-with-CUDA-10-0-1247/
Как работают видеокарты? — ProGamer.
 Ru
RuСамое время поговорить о видеокартах. Не о их дефиците и коррумпированности производителей и ритейла, а именно о полезных свойствах, которые они обеспечивают. И как так получается, что с определенным типом вычислений видеокарты справляются быстрее процессоров.
С момента, как 3dfx выпустила первый 3D-акселератор Voodoo, ни один другой ПК-компонент так сильно не влиял на то, может ли ваш компьютер считаться хорошей игровой машиной или нет, как видеокарта. Безусловно, другие «запчасти» для ПК тоже важны, но даже если у вас будет топовая система с 32 Гб RAM-памяти, процессором за 4 тысячи долларов и PCIe-накопителем, она всё равно, скорее всего, загнётся в попытке запустить современную AAA-игру на видеокарте 10-летней давности с нынешними разрешением и уровнем детализации. Графические карты (они же GPU – от англ. «graphics processing units», что можно перевести как «модуль для обработки графики») критически важны для игровой производительности и мы пишем о них постоянно. Но вот о том, как они работают, мы рассказывали лишь вскользь.
Это очень широкая тема, так что здесь будет лишь общий обзор функциональности GPU, затрагивающий и AMD, и NVIDIA, и интегрированные карты Intel, и все прочие Intel’овские GPU, которые компания планирует выпустить в будущем. Кроме того, это касается и мобильных GPU от Apple, Imagination Technologies, Qualcomm, ARM и так далее.
Почему бы не рендерить графику на CPU?
Хороший вопрос. По правде говоря, графические данные можно обрабатывать напрямую в CPU. Ранние 3D-игры, которые выходили до нашествия видеокарт – вроде Ultima Underworld – работали полностью на CPU. Эта игра, кстати, служит хорошим примером по множеству разных причин – у неё был более продвинутый рендеринг-движок, чем у игр вроде Doom: в нём была возможность смотреть вверх и вниз, а также ещё более продвинутые функции вроде наложения текстур. Но всё это далось большой ценой – мало у кого был ПК, способный осилить такую игру.
На заре 3D-эпохи у многих игр вроде Half-Life и Quake II был программный обработчик графики, который позволял играть в них тем, у кого не было 3D-ускорителей. Но в дальнейшем от этого решения пришлось отказаться, и причина проста: CPU – это микропроцессоры общего назначения, то есть они лишены специализированного «железа» и функций, которые есть у GPU. Современный CPU с лёгкостью справится с играми, 18 лет назад тормозившими в режиме программного рендеринга, но ни один CPU на планете Земля не способен совладать с современной AAA-игрой, если запустить её в таком режиме. По крайней мере, без значительных изменений в детализации сцен, разрешении и различных визуальных эффектах.
Но в дальнейшем от этого решения пришлось отказаться, и причина проста: CPU – это микропроцессоры общего назначения, то есть они лишены специализированного «железа» и функций, которые есть у GPU. Современный CPU с лёгкостью справится с играми, 18 лет назад тормозившими в режиме программного рендеринга, но ни один CPU на планете Земля не способен совладать с современной AAA-игрой, если запустить её в таком режиме. По крайней мере, без значительных изменений в детализации сцен, разрешении и различных визуальных эффектах.
В качестве забавного примера: вы можете запустить Crysis на Threadripper 3990X в режиме программного рендера, но результат будет далеко не так хорош, как хотелось бы.
Что такое GPU?
GPU – это устройство с аппаратными возможностями, которые разработаны специально под то, как различные 3D-движки обрабатывают свой код, включая настройку и расчет геометрии, наложение текстур, доступ к памяти и шейдеры. То есть существует взаимосвязь между тем, как функционируют 3D-движки, и тем, как производители GPU конструируют своё «железо». Возможно, некоторые из вас помнят, что семейство AMD HD 5000 использовало архитектуру VLIW5, тогда как некоторые топовые GPU в семействе HD 6000 имели архитектуру VLIW4. В архитектуре GCN компания изменила свой подход к параллельным вычислениям – в целях улучшения производительности на тактовый цикл.
Возможно, некоторые из вас помнят, что семейство AMD HD 5000 использовало архитектуру VLIW5, тогда как некоторые топовые GPU в семействе HD 6000 имели архитектуру VLIW4. В архитектуре GCN компания изменила свой подход к параллельным вычислениям – в целях улучшения производительности на тактовый цикл.
В RDNA – архитектуре, которая последовала за GCN – AMD решила поднажать на показатель IPC (от англ. «instructions per cycle», т.е. «количество команд, выполняемых за такт»), в итоге повысив его на 25%. Архитектура RDNA2 унаследовала это улучшение, а также получила дополнительные функции вроде огромного кэша L3, что тоже положительно повлияло на производительность.
Ultima Underworld
Первой термином «GPU» воспользовалась компания NVIDIA при запуске оригинальной GeForce 256, где вычисления, связанные с освещением и трансформацией геометрии, выполнялись аппаратно (примерно в то же время Microsoft выпустила DirectX 7). Встраивание специализированного функционала прямо в «железо» стало отличительной чертой ранних этапов развития технологии GPU. Многие из этих специализированных техник используются до сих пор (в самых разных формах). Быстрее и энергоэффективнее обрабатывать специализированные задачи на встроенных в чип специализированных устройствах, чем пытаться проделать всю работу в одном массиве программных ядер.
Многие из этих специализированных техник используются до сих пор (в самых разных формах). Быстрее и энергоэффективнее обрабатывать специализированные задачи на встроенных в чип специализированных устройствах, чем пытаться проделать всю работу в одном массиве программных ядер.
Между GPU- и CPU-ядрами есть много отличий, но суть в следующем. CPU обычно предназначены для максимально быстрого и эффективного выполнения однопоточного кода. Улучшить это помогают функции вроде SMT/гиперпоточности, но многопоточность можно обеспечить и поместив рядом друг с другом высокоэффективные однопоточные ядра. На данный момент самые большие CPU – это 64-ядерные, 128-поточные процессоры Epyc от AMD. То есть для сравнения – самый слабый GPU на основе NVIDIA-архитектуры Pascal оснащён 384 ядрами, тогда как самое большое количество ядер у x86-процессора на рынке – это 64. Термин «ядро» в терминологии GPU – это гораздо более маленький процессор.
Примечание: Нельзя сравнивать или оценивать относительную игровую производительность GPU от AMD, NVIDIA и Intel лишь на основе количества GPU-ядер. Но если речь об отдельных GPU-семействах (например, о Nvidia GeForce GTX 10 или AMD RX 4xx/5xx), то да, здесь большее количество GPU-ядер означает и более высокую игровую производительность. К слову, терафлопсы – это тоже не лучший способ сравнения GPU друг с другом.
Но если речь об отдельных GPU-семействах (например, о Nvidia GeForce GTX 10 или AMD RX 4xx/5xx), то да, здесь большее количество GPU-ядер означает и более высокую игровую производительность. К слову, терафлопсы – это тоже не лучший способ сравнения GPU друг с другом.
Причина, по которой не стоит делать спешных выводов о производительности GPU разных производителей и семейств, опираясь лишь на количество ядер, заключается в том, что у разных архитектур – разная степень эффективности. В отличие от CPU, GPU предназначены для параллельных вычислений. Видеокарты обеих компаний состоят из вычислительных блоков. NVIDIA называет эти блоки потоковыми мультипроцессорами (SM – от англ. «streaming multiprocessor»), а AMD – вычислительными блоками (CU – от англ. «compute unit»).
Каждый блок состоит из группы ядер, планировщика, регистрового файла, кэша команд, кэша текстур и кэша L1, а также блоков для наложения текстур (их также называют блоками для текстурирования или текстурными блоками). То есть SM/CU – это что-то типа самого маленького функционального блока GPU. В нём находится далеко не всё – движки для декодирования видео, средства для рендеринга изображения на экране и интерфейсы памяти, используемые для коммуникации со встроенной VRAM-памятью находятся за их пределами – но когда AMD говорит, что её APU оснащён 8 или 11 вычислительными блоками Vega, то имеет в виду именно эти блоки. И если взглянуть на схему любого GPU, то можно заметить, что эти SM/CU дублируются в них огромное количество раз.
То есть SM/CU – это что-то типа самого маленького функционального блока GPU. В нём находится далеко не всё – движки для декодирования видео, средства для рендеринга изображения на экране и интерфейсы памяти, используемые для коммуникации со встроенной VRAM-памятью находятся за их пределами – но когда AMD говорит, что её APU оснащён 8 или 11 вычислительными блоками Vega, то имеет в виду именно эти блоки. И если взглянуть на схему любого GPU, то можно заметить, что эти SM/CU дублируются в них огромное количество раз.
Чем больше количество SM/CU в GPU, тем больше параллельных вычислений он способен выполнить за один такт. К слову, рендеринг относится к типу задач, которые иногда называют «чрезвычайно параллельными», что означает, что с увеличением количества вычислительных блоков значительно растёт и улучшение эффективности самого процесса.
Говоря об устройстве GPU, мы часто используем обозначение вроде 4096:160:64. Первое число – это количество GPU-ядер. Чем оно больше, тем быстрее GPU, но с условием, если вы сравниваете GPU из одного и того же семейства (GTX 970 с GTX 980 или GTX 980 Ti, RX 560 с RX 580 и т. д.).
д.).
Наложение текстур и вывод отрендеренного изображения
У GPU есть и два других важных компонента – блоки наложения текстур и блоки рендеринга. От количества блоков наложения текстур зависит количество генерируемых текселей и то, как быстро GPU будет выполнять адресацию и наложение текстур на объекты. В ранних 3D-играх текстурирование использовалось мало, потому что отрисовка трёхмерных полигональных фигур была достаточно сложной задачей. По сути, текстуры – это необязательный элемент 3D-игр, однако сейчас список игр, в которых вообще нет текстур, крайне невелик.
Вторым числом в 4096:160:64 идёт количество блоков наложения текстур. У видеокарт AMD, NVIDIA и Intel это число, как правило, меняется плавно – по мере перехода от самого слабого к самому мощному GPU в семействе. Другими словами, вы вряд ли увидите GPU с 160 текстурными блоками (4096:160:64), а рядом – GPU сразу с 320 текстурными блоками (4096:320:64). В играх наложение текстур может запросто стать бутылочным горлышком, но у более топового GPU в линейке всегда как минимум больше ядер и блоков наложения текстур (будет ли у него больше блоков рендеринга, зависит от семейства и конфигурации карты).
Блоки рендеринга (которые также называют блоками растеризации) – это то, где результат работы GPU собирается в изображение, которое затем будет показано на мониторе или телевизоре. От количества блоков рендеринга и тактовой частоты GPU зависит показатель пиксельной скорости заполнения. Чем больше количество блоков рендеринга, тем больше одновременно отрисовываемых пикселей. Блоки рендеринга также отвечают за сглаживание (AA), поэтому включение AA – особенно SSAA, т.е. избыточной выборки сглаживания – может привести к значительному снижению пиксельной скорости заполнения.
Тензорные ядра – подходящие для задач машинного обучения, и нашедшие применение в играх, например в технологии умного масштабирования разрешения DLSS.
Пропускная способность и ёмкость памяти
Последние две характеристики, которые мы здесь обсудим – это пропускная способность памяти и её объём. Пропускная способность – это то, сколько данных в секунду может быть скопировано в и из VRAM-буфера GPU. Чтобы сохранить приемлемый фреймрейт (количество кадров в секунду), более продвинутым визуальным эффектам (и, как правило, более высокому разрешению) как раз требуется память с более высокой пропускной способностью, поскольку это дополнительная нагрузка, увеличивающая общее количество данных, копируемых в и из GPU-ядер.
Чтобы сохранить приемлемый фреймрейт (количество кадров в секунду), более продвинутым визуальным эффектам (и, как правило, более высокому разрешению) как раз требуется память с более высокой пропускной способностью, поскольку это дополнительная нагрузка, увеличивающая общее количество данных, копируемых в и из GPU-ядер.
В некоторых случаях маленькая пропускная способность может стать серьёзным бутылочным горлышком для GPU. APU производства AMD вроде Ryzen 5 3400G имеют очень маленькую пропускную способность, и это значит, что увеличение тактовой частоты DDR4 может серьёзно повлиять на общую производительность GPU. Выбор игрового движка – и целевого разрешения игры – тоже может оказать большое влияние на то, насколько большая пропускная способность должна быть у GPU, чтобы справиться с этими задачами.
Ещё один критически важный фактор GPU – это общее количество встроенной памяти. Если количество VRAM-памяти, необходимое для запуска с текущим уровнем детализации или разрешением, превосходит доступные ресурсы, игра зачастую запустится, но ей также придётся воспользоваться оперативной памятью для хранения дополнительных текстурных данных. А у GPU уходит гораздо больше времени на вывод данных из DRAM, чем из VRAM-памяти, специально предназначенной для этой цели. Это приводит к серьёзным подвисаниям, так как игра мечется между выводом данных из быстрого пула локальной памяти и общей RAM.
А у GPU уходит гораздо больше времени на вывод данных из DRAM, чем из VRAM-памяти, специально предназначенной для этой цели. Это приводит к серьёзным подвисаниям, так как игра мечется между выводом данных из быстрого пула локальной памяти и общей RAM.
Мы заметили, что иногда производители GPU оснащают карты нижней и средней ценовой категории большей VRAM-памятью, чем у стандартной модели, с целью выручить за этот продукт чуть больше денег. Мы затрудняемся точно сказать, стоит ли покупать такую карту, потому что это очень сильно зависит от конкретного GPU. Но что мы можем сказать наверняка, так это то, что во многих случаях платить больше за карту, оснащённую лишь увеличенной VRAM-памятью, не стоит. Опыт показывает, что GPU нижней ценовой категории склонны упираться в другие бутылочные горлышки, прежде чем дело дойдёт до самой VRAM. Если сомневаетесь, лучше почитайте обзоры на карту и сравните, как 8-гигабайтная версия показывает себя относительно 12-гигабайтной (или какое там количество гигабайт будет в вашем случае). Зачастую – с условием, что во всём остальном карты более-менее идентичны – обнаруживается, что более высокое количество VRAM-памяти не стоит того, чтобы за него переплачивать.
Зачастую – с условием, что во всём остальном карты более-менее идентичны – обнаруживается, что более высокое количество VRAM-памяти не стоит того, чтобы за него переплачивать.
По материалам ExtremeTech
Примеры растеризации в движении
Искать в этом руководстве
Руководство пользователя Motion
- Добро пожаловать
- Что нового в движении 5.6.1
- Что нового в Motion 5.6
- Что нового в Motion 5.5
- Что нового в 5.4.6
- Что нового в 5.4.4
- Что такое движение?
- Рабочий процесс движения
- Интерфейс движения
- Основные компоненты движения
- Использование устройств ввода
- Введение в создание проектов
- Создать новый проект
- Откройте существующий проект
- Поиск проектов из Finder
- Обход браузера проекта
- Создание и изменение пресетов проекта
- Сохранение, автосохранение и восстановление проектов
- Введение в использование шаблонов
- Создание проектов из шаблонов
- Создание стикеров для сообщений
- Введение в зоны сброса
- Создание зон сброса
- Изменить изображения зоны перетаскивания
- Элементы управления зоной сброса
- Контролируйте и открывайте зоны сброса
- Рекомендации по шаблонам
- Организация шаблонов в Диспетчере проектов
- Введение в свойства проекта
- Изменить свойства проекта
- Элементы управления инспектора свойств
- Размер кадра проекта
- Введение в добавление контента и управление им
- Если это ваш первый импорт
- Об импорте мультимедиа
- Импорт медиа
- Импорт многослойных файлов Photoshop
- Поддерживаемые форматы мультимедиа
- Файлы неподвижных изображений с высоким разрешением
- Установите размер импорта больших изображений
- Последовательности изображений
- Анимированные GIF-файлы
- PDF-файлы
- Альфа-каналы
- Аудио файлы
- Текстовые файлы
- Показать библиотеку
- Категории содержимого библиотеки
- Добавить содержимое библиотеки в проект
- Добавляйте музыку и фото файлы
- Сортировка и поиск в библиотеке
- Управление папками и файлами библиотеки
- Когда носитель из библиотеки недоступен
- Работа с темами библиотеки
- Сохранение пользовательских объектов в библиотеке
- Введение в исходные медиа
- Список СМИ
- Отображение, сортировка и поиск в списке мультимедиа
- Показать исходный носитель
- Отображение инспектора мультимедиа
- Элементы управления исходным медиа
- Дублирование и удаление медиафайлов
- Обмен медиа в проекте
- Повторное подключение автономных медиафайлов
- Сетевые устройства и съемные носители
- Введение в воспроизведение проекта
- Воспроизвести проект
- Оптимизируйте воспроизведение с помощью предварительного просмотра RAM
- Использовать полноэкранный режим плеера
- Используйте второй дисплей
- Знакомство с дисплеем времени
- Просмотр информации о сроках проекта
- Переместите точку воспроизведения
- Изменить продолжительность проекта
- Определить диапазон воспроизведения
- Производительность воспроизведения проекта
- Введение в базовый композитинг
- Введение в список слоев
- Выбрать слои и группы
- Показать и скрыть список слоев
- Отображение слоев на холсте
- Добавление и удаление слоев и групп
- Реорганизация слоев и групп
- Показать, скрыть, соло или заблокировать слои
- Общие сведения о вложенных слоях и группах
- Свернуть и развернуть группы
- Группировать, разгруппировать и вкладывать слои
- Ограничить размер группы
- Элементы управления списком слоев
- Контекстное меню списка слоев
- Настроить список слоев
- Введение в преобразование слоев
- Введение в преобразование слоев на холсте
- Преобразование свойств слоя на холсте
- Инструменты преобразования
- Изменение положения, масштаба или поворота слоя
- Перемещение точки привязки слоя
- Добавьте тень к слою
- Искажение или сдвиг слоя
- Обрезать слой
- Изменение формы или маскирование точек
- Преобразование текстовых глифов и других атрибутов объекта
- Выравнивание слоев на холсте
- Преобразование слоев в инспекторе свойств
- Элементы управления инспектора свойств
- Преобразование слоев в HUD
- Преобразование 2D-слоев в 3D-пространство
- Изменить непрозрачность слоя
- Введение в смешивание слоев
- Изменение режима наложения слоя
- Как работают режимы наложения?
- Как режимы наложения влияют на группы?
- Типы режимов наложения
- Режимы наложения альфа-канала
- Масштабирование или панорамирование холста
- Просмотр отзывов о динамическом холсте
- Пользовательские параметры просмотра холста
- Расширенные настройки качества
- Используйте линейки и направляющие
- Введение в 3D-композитинг
- Введение в 3D-координаты
- Относительные координаты
- Преобразование слоев в 3D-пространстве
- Создать 3D-перекресток
- 2D и 3D групповые свойства
- Знакомство с 3D-камерами
- Добавить камеру
- Камеры и виды
- Просмотр 3D-наложений
- Всплывающее меню камеры
- Используйте инструменты 3D-просмотра
- Используйте 3D-компас
- Установите 3D-врезку
- Отображение 3D-сетки
- Отображение значков 3D-сцен
- Макеты 3D видового экрана
- Работа с несколькими камерами
- Масштабирование, положение и анимация камер
- Изолировать объект на холсте
- Управление камерой
- Введение в глубину резкости
- Включить или выключить глубину резкости
- Управление глубиной резкости
- Добавить поведение камеры
- Долли поведение
- Поведение фокуса
- Фрейминг поведения
- Используйте экранные элементы управления кадрированием
- Поведение развертки
- Увеличение/уменьшение поведения
- Поведение масштабируемого слоя
- Введение в 3D-освещение
- Добавить свет
- Управление 3D-освещением
- Дополнительные элементы управления освещением
- Введение в 3D-тени
- Создание 3D-тени
- 3D-управление тенями
- Как тени взаимодействуют с 3D-слоями
- Тени без света
- Бросьте отражение
- Элементы управления отражением
- Как группы влияют на размышления
- Ограничение рекурсивных отражений
- Введение в временную шкалу
- Отображение или изменение размера области синхронизации
- Перетаскивание объектов на временную шкалу
- Перетащите в список слоев временной шкалы
- Перетащите в область трека временной шкалы
- Установить параметры перетаскивания временной шкалы
- Введение в управление слоями и дорожками временной шкалы
- Выберите и организуйте слои временной шкалы
- Разъединить видео и аудио
- Настроить временную шкалу
- Изменить на временной шкале
- Перемещение объектов на временной шкале
- Обрезка объектов на временной шкале
- Перемещайте слои видео на временной шкале
- Разделить объекты на временной шкале
- Удалить объекты на временной шкале
- Скопируйте и вставьте объекты на временной шкале
- Группировать треки на временной шкале
- Редактировать групповой трек на временной шкале
- Навигация по временной шкале
- Отображение и изменение ключевых кадров на временной шкале
- Введение в линейку временной шкалы
- Редактировать диапазон кадров на временной шкале
- Введение в маркеры временной шкалы
- Добавляйте, перемещайте и удаляйте маркеры временной шкалы
- Изменить информацию о маркере временной шкалы
- Навигация с помощью маркеров временной шкалы
- Изменить в мини-хронологии
- Введение в повторную синхронизацию мультимедиа на временной шкале
- Восстановить время мультимедиа на временной шкале
- Контроль времени
- Управление анализом восстановления синхронизации
- Введение в поведение
- Поведение по сравнению с ключевыми кадрами
- Поиск поведения
- Введение в применение поведения
- Добавление, удаление и отключение поведения
- Где появляются прикладные поведения
- Добавить или удалить поведение параметра
- Переназначить поведение параметра
- Где отображаются поведения параметров
- Отключить, заблокировать или переименовать поведение
- Скопируйте, вставьте или переместите поведение
- Введение в тайминг поведения
- Остановить поведение
- Обрезка поведения
- Управление поведением симуляции
- Изменить время поведения
- Время поведения параметра смещения
- Порядок действий
- Сочетание поведения с ключевыми кадрами
- Поведение и ключевые кадры в редакторе ключевых кадров
- Параметры ключевых кадров в поведении
- Преобразование поведения в ключевые кадры
- Введение в корректировку поведения
- Настройте поведение
- Введение в типы поведения
- Введение в основные поведения движения
- Выровнять по поведению
- Поведение Fade In/Fade Out
- Увеличение/уменьшение поведения
- Поведение пути движения
- Работа с поведением пути движения
- Переместить поведение
- Укажите на поведение
- Привязать выравнивание к движению
- Поведение спина
- Поведение броска
- Введение в поведение параметров
- Звуковое поведение
- Среднее поведение
- Поведение зажима
- Пользовательское поведение
- Добавить пользовательское поведение
- Экспоненциальное поведение
- Поведение ссылок
- Логарифмическое поведение
- MIDI-поведение
- Добавить поведение MIDI
- Отменить поведение
- Осциллирующее поведение
- Создайте затухающие колебания
- Поведение с превышением
- Квантование поведения
- Поведение рампы
- Рандомизировать поведение
- Оцените поведение
- Обратное поведение
- Остановить поведение
- Отслеживание поведения
- Извиваться поведение
- Введение в поведение Retiming
- Поведение Flash Frame
- Поведение удержания кадра
- Поведение цикла
- Поведение в пинг-понге
- Повтор поведения
- Обратное поведение
- Поведение обратного цикла
- Скраб поведение
- Установить поведение скорости
- Поведение стробоскопа
- Заикание
- Введение в модели поведения
- Выровнять по движению
- Привлекательное поведение
- Поведение аттрактора
- Поведение перетаскивания
- Дрейф привлекает поведение
- Поведение дрейф-аттрактора
- Поведение при столкновении краев
- Гравитационное поведение
- Орбита вокруг поведения
- Случайное движение
- Отталкивающее поведение
- Отталкиваться от поведения
- Поведение вращательного перетаскивания
- Весеннее поведение
- Поведение вихря
- Поведение ветра
- Дополнительные варианты поведения
- Сохранить настраиваемое поведение
- Удалить настраиваемое поведение
- Перенос поведения на другой компьютер
- Введение в ключевые кадры
- Добавить ключевые кадры
- Добавьте путь анимации на холст
- Изменить пути анимации
- Анимация от инспектора
- Управление меню анимации
- Используйте меню анимации
- Элементы управления ключевыми кадрами в Инспекторе
- Анимация из HUD
- Применение ключевых кадров к поведению
- Объединение ключевых кадров и поведения
- Просмотр ключевых кадров на временной шкале
- Изменить ключевые кадры на временной шкале
- Длительность эффекта и синхронизация ключевого кадра
- Отобразить редактор ключевых кадров
- Элементы управления редактора ключевых кадров
- Добавляйте или удаляйте ключевые кадры в редакторе ключевых кадров.
- Изменение ключевых кадров в редакторе ключевых кадров
- Отменить, заблокировать или отключить ключевые кадры
- Скопируйте и вставьте ключевые кадры и кривые
- Нарисуйте кривую анимации
- Преобразование сегментов кривой
- Применение поведения параметров к кривым
- Сравните снимки кривых
- Добавляйте или удаляйте ключевые кадры в редакторе ключевых кадров.
- Установить интерполяцию кривой
- Методы интерполяции кривой
- Преобразование в интерполяцию Безье
- Установить экстраполяцию кривой
- Методы экстраполяции кривой
- Преобразование экстраполированных кривых в ключевые кадры
- Выберите вид кривой
- Создание пользовательского вида кривой
- Сохранение кривой анимации
- Используйте редактор мини-кривых
- Анимация на лету
- Упростить кривую ключевого кадра
- Введение в шаблоны Final Cut Pro
- Рабочий процесс шаблона
- Заполнители и зоны перетаскивания
- Создать шаблон эффекта
- Изменение эффекта Final Cut Pro
- Пример: изменение эффекта Final Cut Pro
- Создайте шаблон перехода
- Пример: создание размытого перехода
- Создание фона перехода
- Изменение перехода Final Cut Pro
- Создайте шаблон заголовка
- Создайте фон заголовка
- Изменить заголовок Final Cut Pro
- Создайте шаблон генератора
- Изменение генератора Final Cut Pro
- Преобразование проекта Motion в Final Cut Pro
- Преобразование шаблона в другой тип
- Используйте изображения-заполнители в шаблонах
- Добавление элементов управления в шаблоны
- Публикация элементов управления в Final Cut Pro
- Управление элементами управления шаблонами в Motion
- Публикация элементов управления текстом шаблона
- Элементы шаблона, которые нельзя опубликовать
- Введение в шаблонные маркеры
- Добавьте маркеры шаблона
- Руководство по анимации для шаблонов
- Рекомендации по выбору времени для шаблонов
- Установить разрешение шаблона
- Добавляйте в шаблоны несколько соотношений сторон
- Переопределить цветовое пространство Final Cut Pro
- Где сохраняются шаблоны?
- Использование масок в шаблонах
- Рекомендации по улучшению шаблонов
- Введение в такелаж
- Как работает такелаж?
- Соберите простую установку
- Работа с виджетами
- Виджет слайдера
- Виджет всплывающего меню
- Виджет флажка
- Введение в снимки
- Как сохраняются снимки
- Создание снимков и управление ими
- Управляйте ригами из меню анимации
- Как использовать один риг
- Как использовать несколько ригов
- Анимация виджета
- Публикация ригов в Final Cut Pro
- Введение в частицы
- Добавить систему частиц
- Анатомия излучателя частиц
- Изменить системы частиц
- Отрегулируйте частицы из HUD
- Элементы управления HUD излучателя
- Настройка частиц из Инспектора
- Одноклеточные и многоклеточные элементы управления
- Элементы управления эмиттером
- Элементы управления частицами
- Настройка основных свойств эмиттера
- Анимация эмиттеров и ячеек
- Применение поведения к частицам
- Масштабирование в течение жизни
- Управление Spin Over Life
- Просмотр ключевых кадров эмиттера или ячейки
- Создание 3D-частиц
- Время системы частиц
- Использование графики в системах частиц
- Использование фильтров и масок с частицами
- Сохранение пользовательских эффектов частиц
- Введение в репликаторы
- Репликаторы против систем частиц
- Добавить репликатор
- Анатомия репликатора
- Изменить основные атрибуты репликатора
- Удаление репликатора или клетки
- Настройте репликатор из HUD
- Настройка репликатора из Инспектора
- Элементы управления репликатором
- Создайте собственную форму репликатора
- Элементы управления клетками-репликаторами
- Настройка дополнительных свойств репликатора
- Анимация репликаторов
- Применение поведения к репликаторам
- Особенности поведения репликатора
- Применение поведения Sequence Replicator
- Элементы управления Sequence Replicator
- Управление синхронизацией последовательности с ключевыми кадрами
- Использование поведения параметров с Sequence Replicator
- Показать кривые анимации репликатора
- Работа с 3D репликаторами
- Время репликатора
- Использование фильтров и масок с репликаторами
- Сохранить пользовательские репликаторы
- Введение в основной текст
- Задайте настройки перед добавлением текста
- Добавить текст
- Использование файлов TXT и RTF
- Выбор и изменение текста на холсте
- Предварительный просмотр и применение шрифтов
- Используйте предустановленные стили текста
- Введение в редактирование текста
- Отображение инспектора текста или HUD
- Отображение панели форматирования текста
- Форматировать текст
- Элементы управления форматом текста
- Отображение панели «Оформление текста»
- Изменить цвет текста
- Изменить прозрачность текста
- Изменить мягкость текста
- Применение текстуры изображения к тексту
- Добавьте контур текста, свечение или тень
- Элементы управления 3D-текстом
- Элементы управления текстом Face
- Элементы управления контуром текста
- Элементы управления свечением текста
- Элементы управления тенью текста
- Сохранение пользовательского стиля текста
- Отображение панели макета текста
- Создание текста на пути
- Изменение пути текста в 3D-пространстве
- Использование геометрической формы в качестве контура текста
- Анимация текста на пути
- Создание и настройка полей текста
- Добавляйте, удаляйте и изменяйте текстовые вкладки
- Элементы управления макетом текста
- Элементы управления визуализацией текста
- Элементы управления поведением текста
- Тип текста на элементах управления
- Элементы управления параметрами пути к тексту
- Элементы управления текстовыми полями
- Элементы управления текстовыми вкладками
- Введение в текстовые глифы
- Выделите символы с помощью инструмента Transform Glyph
- Изменить текстовый глиф
- Искажение глифа на холсте
- Сбросить глифы
- Элементы управления глифами в текстовом HUD
- Преобразование стандартного текста в 3D-текст
- Проверять орфографию
- Найти и заменить текст
- Использование фильтров с текстом
- Введение в 3D-текст
- Рабочий процесс с 3D-текстом
- Добавить 3D-текст
- Преобразование 2D-текста в 3D-текст
- Применение предустановленного стиля 3D-текста
- Перемещение и вращение 3D-текста
- Изменение формата и макета 3D-текста
- Изменение глубины и веса 3D-текста
- Элементы управления 3D-текстом
- Введение в материалы для 3D-текстовой поверхности
- Применение предустановленного материала к 3D-тексту
- Применение пользовательского материала к 3D-тексту
- Изменение 3D-текстовых материалов
- Добавление или удаление слоев 3D-текстового материала
- Создавайте светящийся 3D-текст
- Применение материалов к граням 3D-текста
- Сохраните измененный текстовый 3D-материал
- Введение в элементы управления 3D-текстовым материалом
- 3D-текст Элементы управления веществом
- Элементы управления 3D-текстом Paint
- Элементы управления отделкой 3D-текста
- Трехмерный текст
- Элементы управления излучением 3D-текста
- Элементы управления размещением 3D-текста
- Пример.
 Настройка металлического градиента
Настройка металлического градиента
- Введение в освещение 3D-текста
- Настройка подсветки 3D-текста
- Изменение освещения среды 3D-текста
- 3D-текст Управление освещением и средой
- Добавьте свечение или тень к 3D-тексту
- Пересечение трехмерного текста
- Введение в анимированный текст
- Применение текстового поведения
- Предустановленное поведение текста
- Настройка предустановленного поведения текста
- Пример: изменение поведения Flare In
- Применение поведения «Текст последовательности»
- Тонкая настройка поведения текста последовательности
- Добавление ключевых кадров в поведение текста последовательности
- Последовательность искажения 2D-текста
- Элементы управления поведением текста последовательности
- Используйте поведение прокрутки текста
- Элементы управления прокруткой текста
- Используйте поведение отслеживания текста
- Элементы управления текстовым отслеживанием
- Используйте поведение Type On
- Тип На элементах управления
- Анимация отдельных текстовых глифов
- Анимация 2D-текста в 3D-пространстве
- Когда использовать ключевые кадры для анимации текста
- Добавление нетекстового поведения к тексту
- Сохранить измененное поведение текста
- Знакомство с фигурами, масками и мазками
- Введение в простые формы и маски
- Рисовать простые фигуры
- Добавить фигуры из библиотеки
- Рисовать простые маски
- Преобразование фигуры или маски в контрольные точки
- Введение в сложные формы и маски
- Рисовать сложные формы и маски
- Знакомство с мазками
- Создайте обводку кистью
- Преобразование контуров в мазки кистью
- Отрегулируйте ширину обводки на холсте
- Элементы управления обводкой в HUD
- Введение в редактирование контрольных точек
- Показать контрольные точки
- Выберите или заблокируйте контрольные точки
- Добавить или удалить контрольные точки
- Переместите контрольные точки, чтобы настроить фигуры
- Редактировать контрольные точки Безье
- Редактировать контрольные точки B-сплайна
- Используйте динамические направляющие и привязку
- Редактировать заливку, контур и растушевку
- Введение в элементы управления формой
- Элементы управления панели стилей
- Элементы управления фильмом на панели стилей
- Элементы управления панелью штрихов
- Расширенные элементы управления панелью
- Элементы управления панели геометрии
- Введение в модели поведения
- Добавить поведение фигуры
- Применение поведения «Нажим пера»
- Настройка поведения скорости пера
- Применить поведение наклона пера
- Осциллировать поведение формы
- Случайное поведение фигуры
- Последовательность действий при отрисовке
- Отслеживание поведения точек
- Поведение фигуры изгиба
- Напишите о поведении
- Контрольные точки формы ключевого кадра
- Введение в маски и прозрачность
- Маска слоя
- Объединение нескольких масок
- Применение фильтров или поведения к маскам
- Ротоскоп формы маски
- Советы по ротоскопированию
- Элементы управления маской в Инспекторе
- Введение в маски изображений
- Применение маски изображения к слою
- Элементы управления маской изображения
- Преобразование между формами и масками
- Использование фильтров и масок с фигурами
- Копировать стили фигур
- Сохранение пользовательских фигур и стилей фигур
- Введение в использование генераторов
- Добавить генератор
- Изменение или анимация генератора
- Органы управления общие для всех генераторов
- Введение в генераторы изображений
- Генератор каустики
- Сотовый генератор
- Генератор шахматной доски
- Генератор облаков
- Генератор сплошных цветов
- Генератор концентрических горошек
- Генератор концентрических форм
- Генератор градиента
- Генератор сетки
- Генератор японских узоров
- Генератор бликов
- Генератор строк манги
- Мембранный генератор
- Генератор шума
- Один генератор цветовых лучей
- Генератор Op Art 1
- Генератор Op Art 2
- Генератор Op Art 3
- Генератор перекрывающихся кругов
- Генератор радиальных стержней
- Генератор мягкого градиента
- Генератор спиралей
- Генератор спирального рисунка
- Используйте экранные элементы управления Spiral Drawing
- Звездный генератор
- Генератор полос
- Генератор солнечных лучей
- Генератор плиток Трюше
- Генератор двухцветных лучей
- Введение в текстовые генераторы
- Генератор файлов
- Генератор чисел
- Генератор даты времени
- Генератор тайм-кода
- Сохраните измененный генератор
- Введение в фильтры
- Просмотр и предварительный просмотр фильтров
- Применение или удаление фильтров
- Введение в настройку фильтров
- Настройте фильтры в Инспекторе или HUD
- Настройка фильтров на холсте
- Типы элементов управления экранными фильтрами
- Введение в типы фильтров
- Введение в фильтры размытия
- Фильтр размытия канала
- Фильтр размытия по кругу
- Составной фильтр размытия
- Фильтр расфокусировки
- Фильтр направленного размытия
- Фильтр размытия по Гауссу
- Фильтр градиентного размытия
- Призменный фильтр
- Фильтр радиального размытия
- Фильтр мягкого фокуса
- Переменный фильтр размытия
- Масштаб Размытие фильтр
- Введение в пограничные фильтры
- Конический фильтр
- Простой фильтр границы
- Фильтр обводки
- Широкоэкранный фильтр
- Введение в цветовые фильтры
- Фильтр яркости
- Фильтр микшера каналов
- Фильтр цветового баланса
- Пример: Цветовой баланс двух слоев
- Цветовые кривые фильтр
- Используйте фильтр «Цветовые кривые».

- Фильтр уменьшения цвета
- Фильтр цветовых кругов
- Используйте фильтр «Цветовые круги»
- Цветной фильтр
- Контрастный фильтр
- Пользовательский фильтр LUT
- Используйте пользовательский фильтр LUT
- Гамма-фильтр
- Фильтр «Градиентное окрашивание»
- Фильтр HDR-инструментов
- Фильтр цветового тона/насыщенности
- Фильтр Кривые оттенка/насыщенности
- Используйте фильтр Кривые оттенка/насыщенности
- Фильтр уровней
- Отрицательный фильтр
- Фильтр карты тонов OpenEXR
- Сепия фильтр
- Пороговый фильтр
- Оттеночный фильтр
- Введение в фильтры искажения
- Фильтр черной дыры
- Выпуклый фильтр
- Фильтр рельефной карты
- Фильтр деформации диска
- Капельный фильтр
- Фильтр землетрясений
- Фильтр «рыбий глаз»
- Флоп-фильтр
- Веселый дом фильтр
- Фильтр из стеклянных блоков
- Искажение стекла
- Фильтр глаз насекомых
- Зеркальный фильтр
- Фильтр скручивания страницы
- Тыкать фильтр
- Полярный фильтр
- Преломляющий фильтр
- Кольцо Фильтр объектива
- Фильтр пульсаций
- Скребковый фильтр
- Масштабный фильтр
- Используйте фильтр Sliced Scale
- Сферический фильтр
- Звездообразный фильтр
- Полосы фильтр
- Целевой фильтр
- Фильтр «Маленькая планета»
- Вращающийся фильтр
- Подводный фильтр
- Волновой фильтр
- Введение в светящиеся фильтры
- Фильтр ауры
- Фильтр Блума
- Ослепляющий фильтр
- Блестящий фильтр
- Мрачный фильтр
- Светящийся фильтр
- Фильтр «Световые лучи»
- Неоновый фильтр
- Фильтр внешнего свечения
- Фильтр овердрайва
- Введение в фильтры Looks
- Отбеливающий фильтр
- Калифорнийский фильтр
- Хром фильтр
- Крутой фильтр
- Затухающий фильтр
- Мгновенный фильтр
- Моно фильтр
- Невадский фильтр
- Нью-йоркский фильтр
- Нуар фильтр
- Технологический фильтр
- Фильтр шестидесятых
- Тональный фильтр
- Фильтр переноса
- Введение в фильтры резкости
- Фильтр резкости
- Фильтр нерезкой маски
- Введение в фильтры стилизации
- Добавить шумовой фильтр
- Плохой пленочный фильтр
- Плохой телевизионный фильтр
- Круговой экранный фильтр
- Фильтр кругов
- Фильтр цветного тиснения
- Комический фильтр
- Кристаллизационный фильтр
- Фильтр краев
- Выдавить фильтр
- Заполнить фильтр
- Полутоновый фильтр
- Заштрихованный сетчатый фильтр
- Фильтр верхних частот
- Фильтр отступов
- Фильтр «Штриховой рисунок»
- Линейный экранный фильтр
- Минмакс фильтр
- Фильтр растворения шума
- Пиксельный фильтр
- Постеризовать фильтр
- Рельефный фильтр
- Щелевой сканирующий фильтр
- Щелевой туннельный фильтр
- Текстурный экранный фильтр
- Фильтр виньетки
- Волнистый сетчатый фильтр
- Введение в мозаичные фильтры
- Калейдоскоп фильтр
- Калейдотильный фильтр
- Смещенный фильтр
- Параллелограмм Мозаика фильтр
- Фильтр «Перспектива»
- Случайный фильтр плитки
- Фильтр плитки
- Фильтр треугольной плитки
- Введение в фильтры времени
- Эхо-фильтр
- Скраб-фильтр
- Строб фильтр
- Фильтр маршрутов
- Фильтр WideTime
- Введение в видео фильтры
- Фильтр безопасного вещания
- Фильтр деинтерлейса
- Анимация параметров фильтра с ключевыми кадрами
- Анимация фильтров с использованием поведения
- Публикация параметров фильтра в Final Cut Pro
- Использование фильтров на альфа-каналах
- Производительность фильтра
- Сохранить пользовательские фильтры
- Введение в цветовую манипуляцию
- Введение в фильтр Кейера
- Используйте фильтр Кейера
- Элементы управления фильтром Кейера
- Анимация ключевых параметров цвета
- Введение в фильтр Luma Keyer
- Элементы управления фильтром Luma Keyer
- Введение в очистку матов
- Обрезать фон с маской мусора
- Восстановить передний план с помощью удерживающей маски
- Матовый волшебный фильтр
- Фильтр подавления разливов
- Применить несколько ключей
- Введение в 3D-объекты
- Добавьте 3D-объект
- Перемещение и вращение 3D-объекта
- Изменение положения точки привязки 3D-объекта
- Введение в изменение 3D-объектов
- Изменение свойств 3D-объекта
- Изменение собственного размера и ориентации 3D-объекта
- Обмен файлом 3D-объекта
- Пересечение 3D-объектов и порядок слоев
- Введение в синхронизацию 3D-объектов
- Изменение синхронизации 3D-объектов в движении
- Использование камер и источников света с 3D-объектами
- Сохранение пользовательских 3D-объектов
- Рекомендации по работе с 3D-объектами
- Работа с импортированными 3D-объектами
- Введение в 360-градусное видео
- 360-градусные проекты
- Создавайте 360-градусные проекты
- Добавьте 360-градусное видео в проект
- Просмотр 360-градусных проектов
- Просмотр 360-градусного видео в гарнитуре VR
- Введение в графику в 360-градусных проектах
- Используйте графику в 360-градусных проектах
- Создайте эффект крошечной планеты
- Переориентация 360-градусных медиа
- Создание 360-градусных шаблонов для Final Cut Pro
- 360-градусные фильтры и генераторы
- Экспортируйте и делитесь 360-градусными проектами
- Руководство по улучшению проектов 360 градусов
- Введение в отслеживание
- Как работает отслеживание движения?
- Анализ и запись движения в клипе
- Введение, чтобы соответствовать переезду
- Соответствие перемещению объекта
- Двухточечное отслеживание
- Угловое закрепление объекта
- Объединение анимации и данных отслеживания
- Стабилизация дрожащего клипа
- Удаление границ из стабилизированных клипов
- Дестабилизация клипа
- Отслеживание фигур, масок и мазков рисованием
- Отслеживание положения фильтра или объекта
- Настройка экранных трекеров
- Загрузить существующие данные отслеживания
- Используйте диапазон кадров для анализа
- Общие сведения о правилах отслеживания
- Основные стратегии отслеживания
- Расширенные стратегии отслеживания
- Отслеживание перспективы, масштаба или поворотных сдвигов
- Отслеживание скрытых или выходящих за рамки точек
- Отслеживание отснятого материала
- Используйте маски с отслеживанием поведения
- Анализ элементов управления движением
- Соответствие элементам управления перемещением
- Стабилизируйте элементы управления
- Нестабилизировать элементы управления
- Элементы управления точками отслеживания
- Элементы управления треком
- Сохраняйте треки в библиотеку
- Введение в аудио
- Просмотр аудиофайлов
- Добавить аудиофайлы
- Воспроизведение аудиофайлов
- Введение в редактирование аудио
- Настроить звук
- Вырезать, копировать, вставлять и удалять аудио
- Скольжение, скольжение и обрезка звука
- Используйте аудио с маркерами
- Работа с выходной звуковой дорожкой
- Выберите каналы вывода звука
- Анимировать уровень звука и панорамирование
- Синхронизируйте аудио и видео
- Переназначить аудио
- Введение в звуковое поведение
- Поведение аудио при автопанорамировании
- Поведение звука нарастания/исчезновения
- Поведение аудиопараметров
- Примените поведение параметра Audio
- Введение в экспорт проектов
- Экспорт фильма QuickTime
- Экспортировать только аудио
- Экспорт неподвижного изображения
- Экспорт последовательности изображений
- Экспорт на устройства Apple
- Экспорт в электронную почту
- Экспорт с использованием компрессора
- Создание пунктов назначения общего доступа
- Настройки рендеринга
- Просмотр состояния общих элементов
- Поделиться уведомлениями
- Знакомство с широкой цветовой гаммой и HDR
- Используйте обработку цветов HDR с широкой гаммой
- Просмотр HDR-медиа
- Настройка HDR-медиа
- Выбирайте с широким цветовым охватом HDR
- Отображение значений яркости HDR в движении
- Советы по широкому цветовому диапазону HDR
- Введение в кинематографический режим видео
- Переместите кинематографические клипы на свой Mac
- Включить настройки видео в кинематографическом режиме
- Настройка точек фокусировки в видеоклипах в кинематографическом режиме в движении
- Отрегулируйте глубину резкости видеоклипов в кинематографическом режиме.

- Введение в настройки и ярлыки
- Изменить настройки предпочтений
- Общие настройки
- Настройки внешнего вида
- Настройки проекта
- Настройки времени
- Настройки кэша
- Настройки холста
- 3D настройки
- Предустановки настроек
- Знакомство с настройками направлений
- Адрес электронной почты в движении
- Сохранить текущий кадр назначения
- Назначение экспорта последовательности изображений в движении
- Место назначения экспорта файла в движении
- Назначение настроек компрессора в движении
- Групповое направление в движении
- Редактор пресетов проекта
- Введение в меню
- Меню приложения (Движение)
- Меню «Файл»
- меню редактирования
- Отметить меню
- Меню объекта
- Меню Избранное
- Меню просмотра
- Окно меню
- Меню справки
- Знакомство с сочетаниями клавиш
- Используйте функциональные клавиши
- Общие сочетания клавиш
- Сочетания клавиш в строке меню
- Сочетания клавиш для меню движения
- Сочетания клавиш для меню «Файл»
- Сочетания клавиш меню редактирования
- Сочетания клавиш меню «Отметить»
- Сочетания клавиш в меню объекта
- Просмотреть сочетания клавиш меню
- Сочетания клавиш для меню «Поделиться»
- Горячие клавиши меню окна
- Горячие клавиши для меню справки
- Сочетания клавиш для списка аудио
- Сочетания клавиш инструментов
- Сочетания клавиш инструмента преобразования
- Сочетания клавиш инструмента «Выделение/преобразование»
- Сочетания клавиш инструмента кадрирования
- Сочетания клавиш инструмента «Редактировать точки»
- Сочетания клавиш для инструментов редактирования фигур
- Сочетания клавиш для инструментов панорамирования и масштабирования
- Сочетания клавиш инструментов формы
- Сочетания клавиш инструмента Безье
- Сочетания клавиш для инструмента B-Spline
- Сочетания клавиш для инструмента «Обводка краской»
- Сочетания клавиш для текстового инструмента
- Сочетания клавиш для инструментов маски формы
- Сочетания клавиш для инструмента «Маска Безье»
- Сочетания клавиш для инструмента Маска B-сплайна
- Сочетания клавиш для управления транспортом
- Просмотр опций сочетания клавиш
- Горячие клавиши HUD
- Горячие клавиши инспектора
- Сочетания клавиш в редакторе ключевых кадров
- Горячие клавиши для слоев
- Сочетания клавиш библиотеки
- Сочетания клавиш для списка мультимедиа
- Сочетания клавиш на временной шкале
- Сочетания клавиш для ключевых кадров
- Сочетания клавиш «Форма» и «Маска»
- 3D сочетания клавиш
- Разные сочетания клавиш
- Введение в редактор команд
- Интерфейс редактора команд
- Поиск сочетаний клавиш
- Создание пользовательских сочетаний клавиш
- Импорт и экспорт сочетаний клавиш
- Ярлыки сенсорной панели
- Переместить активы на другой компьютер
- Общие сведения об элементах управления цветом и градиентом
- Используйте основные элементы управления цветом
- Используйте всплывающую цветовую палитру
- Используйте окно «Цвета»
- Используйте цветную пипетку
- Используйте расширенные элементы управления цветом
- Введение в использование редактора градиентов
- Используйте предустановку градиента
- Изменить цвет и прозрачность градиента
- Изменить направление градиента и распространение
- Изменить теги градиента
- Сохранить градиенты
- Используйте элементы управления градиентом на экране
- Основные элементы управления градиентом
- Элементы управления редактором градиентов
- Введение в растеризацию
- Примеры растеризации
- Как растеризация влияет на текст
- Как растеризация влияет на 3D-текст и 3D-объекты
- Как растеризация влияет на фигуры
- Как растеризация влияет на частицы и репликаторы
- Как растеризация влияет на тени
- Как растеризация влияет на фильтры
- Работа с графическими процессорами
- Глоссарий
- Авторские права
2D-группы и растеризация
На следующей паре изображений показано влияние растеризации на режимы наложения 2D-групп. На обоих изображениях слой одинокого слона, который находится в самой верхней группе в списке слоев, перекрывает часть слоя семейства слонов, который находится в отдельной 2D-группе в списке слоев. В обоих примерах для слоя с одиноким слоном параметр «Режим наложения» установлен на «Яркий свет». В нерастрированном левом примере режим наложения одинокого слона взаимодействует с пикселями группы под ним (семейство слонов). Однако в правильном примере растеризована самая верхняя группа. Следовательно, его режим наложения Vivid Light больше не взаимодействует с пикселями второй группы.
На обоих изображениях слой одинокого слона, который находится в самой верхней группе в списке слоев, перекрывает часть слоя семейства слонов, который находится в отдельной 2D-группе в списке слоев. В обоих примерах для слоя с одиноким слоном параметр «Режим наложения» установлен на «Яркий свет». В нерастрированном левом примере режим наложения одинокого слона взаимодействует с пикселями группы под ним (семейство слонов). Однако в правильном примере растеризована самая верхняя группа. Следовательно, его режим наложения Vivid Light больше не взаимодействует с пикселями второй группы.
Важно: Если режим наложения группы установлен на «Пропустить», а к слоям группы применены разные режимы наложения, слои не растрируются.
3D-группы и растеризация
Следующая пара изображений показывает влияние растеризации на пересечение 3D-групп. На левом изображении, не растрированном примере, две группы (группа A и группа B), содержащие прямоугольные формы, пересекаются в трехмерном пространстве.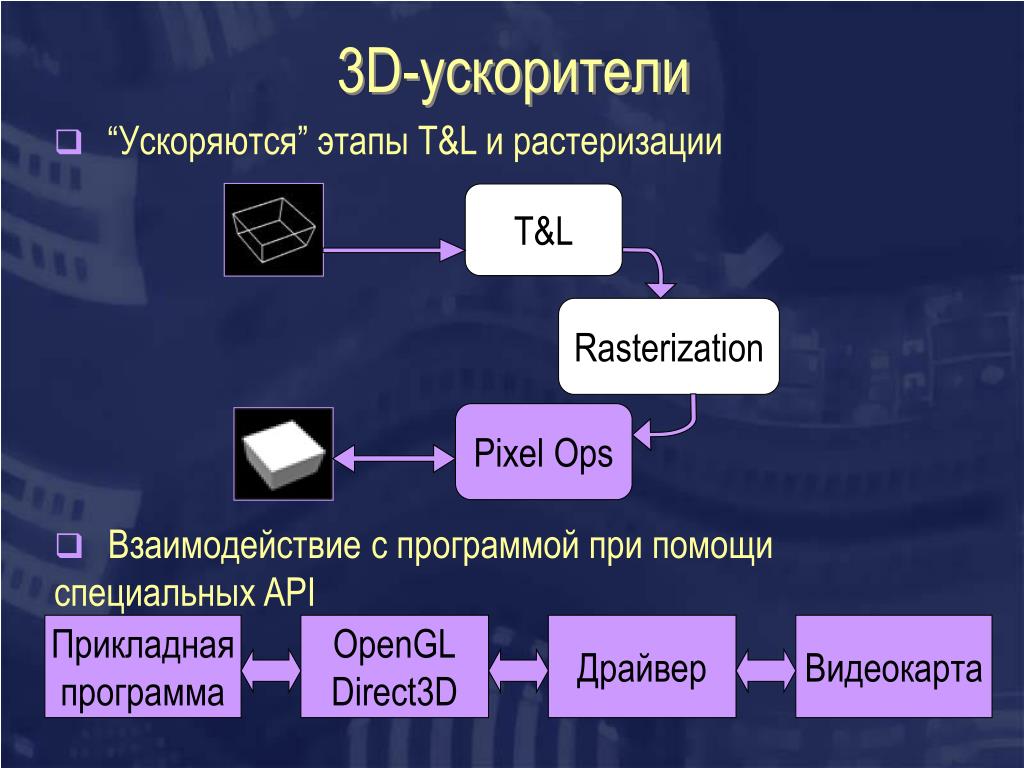 На правом изображении растеризована группа А; следовательно, группа A и группа B больше не пересекаются.
На правом изображении растеризована группа А; следовательно, группа A и группа B больше не пересекаются.
Максимальное количество символов: 250
Пожалуйста, не указывайте личную информацию в своем комментарии.
Максимальное количество символов — 250.
Спасибо за отзыв.
[PDF] Простой алгоритм консервативной и тайловой растеризации
- Идентификатор корпуса: 204855345
title={Простой алгоритм консервативной и мозаичной растеризации},
автор = {Томас Акенин-Мюллер},
год = {2004}
} - T. Akenine-Möller
- Опубликовано в 2004 г.
- Информатика, наука об окружающей среде
Для правильной работы некоторых алгоритмов, использующих графическое оборудование для ускорения обработки, требуется консервативная растеризация. Консервативная растеризация означает либо переоценку, либо недооценку размера треугольников. Переоценка выполняется путем включения всех пикселей, которые хотя бы частично перекрываются треугольником, тогда как недооценка включает только те пиксели, которые полностью находятся внутри треугольника. Ни один или несколько алгоритмов консервативной растеризации не имеют…
Консервативная растеризация означает либо переоценку, либо недооценку размера треугольников. Переоценка выполняется путем включения всех пикселей, которые хотя бы частично перекрываются треугольником, тогда как недооценка включает только те пиксели, которые полностью находятся внутри треугольника. Ни один или несколько алгоритмов консервативной растеризации не имеют…
fileadmin.cs.lth.se
SHOWING 1-10 OF 13 REFERENCES
SORT BYRelevanceMost Influenced PapersRecency
A parallel algorithm for polygon rasterization
- J. Pineda
Computer Science
SIGGRAPH
- 1988
Представлен параллельный алгоритм растеризации полигонов, который особенно хорошо подходит для реализации трехмерной графики с Z-буферизацией и может быть интерполирован с помощью аппаратного обеспечения, аналогичного аппаратному обеспечению, необходимому для интерполяции значений цвета и Z-пикселя.
инкрементное и иерархическое уравнение по краю границы по порядку порядок порядок. блоки, а затем организация растеризации таким образом, чтобы фрагменты генерировались в последовательном порядке блоков, чтобы максимизировать производительность кэша кадрового буфера.
Обход мозаичного полигона с использованием реберных функций полуплоскости
Алгоритм обхода полигона, генерирующий фрагменты тайловым образом, т. е. генерирующий все фрагменты полигона внутри прямоугольника (тайла) перед генерированием каких-либо фрагментов в другом прямоугольнике.
Потоки задержки для графического оборудования
- Timo Aila, V. Miettinen, P. Nordlund
Computer Science
ACM Trans. График
- 2003
Таким образом, ранее использовавшиеся эвристики для коллапса выборок в адаптивной суперсэмплинге заменяются информацией о связности, а требования к памяти для прозрачности, не зависящей от порядка, могут быть существенно снижены за счет использования потоков задержки.
CULLIDE: интерактивное обнаружение столкновений между сложными моделями в больших средах с использованием графического оборудования
Мы представляем новый подход к быстрому обнаружению столкновений между несколькими деформируемыми и разрушаемыми объектами в большой среде с использованием графического оборудования. Наш алгоритм учитывает низкую…
Видимость из региона с аппаратным ускорением с использованием двухлучевого пространства
Описан новый алгоритм видимости из региона, который позволяет проводить удаленные обходы в очень больших виртуальных средах без предварительной обработки и хранения непомерно больших объемов информации о видимости, что устраняет необходимость в предварительной обработке видимости.
Предварительная обработка консервативной видимости с использованием расширенных проекций
- F. Durand, G. Drettakis, J. Thollot, C. Puech
Информатика
SIGGRAPH
- 2000
Метод предварительной обработки видимости, который эффективно вычисляет потенциально видимую геометрию для объемных ячеек просмотра и представляет собой полную реализацию, демонстрирующую значительное ускорение только в отношении отсечения усеченного изображения без вычислительных затрат на отсечение окклюзии в режиме онлайн.
Графика для масс: аппаратная архитектура растеризации для мобильных телефонов
- Т. Акенин-Мёллер, Дж. Стрём
Информатика
АКМ транс. График
- 2003
В этой работе предлагается новая аппаратная архитектура для растеризации текстурированных треугольников, ориентированная на экономию полосы пропускания памяти, поскольку доступ к внешней памяти обычно является одной из самых энергозатратных операций, а мобильные телефоны должны использовать как можно меньше мощность насколько это возможно.
Теневые алгоритмы для компьютерной графики
- Ф. Кроу
Информатика
SIGGRAPH ’77
- 1977
Классификация теневых алгоритмов выделяет три подхода: вычисление теневых копий во время сканирования; разделение поверхностей объекта на затененные и незатененные области перед удалением скрытых поверхностей; включение теневых томов в данные объекта.
Ati Radeon Hyperz Technology
- С. Морейн
Информатика
- 2000
[转]Растеризация на Larrabee — Scan.
Источник: http://software.intel.com/en-us/articles/rasterization-on-larrabee
Рис. 6. Растеризация с разверткой. Начиная с верхней вершины, штамп размером 4×4 пикселя сдвигается влево, пока не выйдет за пределы треугольника, затем вправо, пока не выйдет за пределы треугольника, и, наконец, вниз, а затем процесс повторяется, пока весь треугольник не будет растрирован.
Растеризация с разверткой более векторизуема, чем подход Pixomatic 1, потому что оценка пиксельной метки хорошо подходит для векторизации, но, с другой стороны, требует большого количества плохо предсказанных ветвлений, а также значительного объема работы, чтобы решить, где спускаться. Он также не использует возможности процессоров для принятия разумных и гибких решений, что было нашим лучшим выбором для конкуренции с аппаратной растеризацией, поэтому мы решили, что растеризация с разверткой не является правильным ответом.
Общий вид растеризации Larrabee
Larrabee использует принципиально другой подход, который лучше подходит для векторизации. В подходе Ларраби мы оцениваем 16 блоков пикселей за раз, чтобы выяснить, какие блоки даже касаются треугольника, затем спускаемся в каждый блок, который хотя бы частично покрыт, оценивая 16 меньших блоков внутри него, продолжая спускаться рекурсивно, пока мы идентифицировали все пиксели, которые находятся внутри треугольника. Вот пример того, как это может работать для нашего образца треугольника.
Как я вскоре расскажу, средство визуализации Larrabee использует архитектуру фрагментации. В архитектуре фрагментации наибольшая цель растеризации в любой момент времени — это часть цели рендеринга, называемая тайлом; для этого примера предположим, что плитка имеет размер 64 x 64 пикселя, как показано на рис. 7.
Рис. 7. Треугольник, который нужно растрировать, показан на фоне пикселей в плитке 64 x 64.
Во-первых, мы проверяем, какие из блоков 16×16 (из них 16 — мы проверяем 16 элементов за раз, когда это возможно, чтобы использовать векторные блоки шириной 16), составляющих плитку, касаются треугольника, как показано на рис. 8.
8.
Рис. 8. Проверяются 16 блоков 16 x 16, чтобы определить, к каким из них прикасается треугольник.
Мы обнаруживаем, что касаются только одного блока 16×16, блока, показанного желтым цветом, поэтому мы спускаемся в этот блок, чтобы точно определить, чего касается треугольник, подразделяя его на 16 блоков 4×4 (еще раз, мы проверяем 16 элементов за один раз). время, чтобы быть векторно-дружественным), и оцените, какие из них соприкасаются с треугольником, как показано на рисунке 9.
Рисунок 9: 16 блоков 4×4 проверяются, чтобы увидеть, какие из них соприкасаются с треугольником.
Мы обнаруживаем, что 5 из 4×4 затронуты, поэтому мы обрабатываем каждую из них отдельно, спускаясь на уровень пикселей, чтобы сгенерировать маски для покрытых пикселей. Растрирование пикселей для первого блока показано на рисунке 10.
Рисунок 10: Растрирование пикселей в первом блоке 4×4, которого касается треугольник.
На рис. 11 показан окончательный результат.
Рис. 11. Все 5 блоков 4×4, которых касается треугольник, растеризованы.
Как видите, подход Ларраби обрабатывает блоки 4×4, как и подход с разверткой, но, в отличие от подхода с разверткой, ему не нужно принимать много решений, чтобы выяснить, какие блоки касаются треугольника, благодаря единственному 16-широкий тест, выполняемый перед каждым спуском. Следовательно, этот подход к растеризации обычно выполняет несколько меньше работы, чем метод развертки, чтобы определить, какие блоки 4×4 следует оценивать. Настоящая победа, однако, заключается в том, что он использует преимущества процессора, не выполняя растеризацию, когда это возможно. Мне придется пройтись по подходу растеризации Larrabee, чтобы объяснить, что это значит, но в качестве введения позвольте мне рассказать вам еще одну историю оптимизации.
Много лет назад мне позвонил парень, на которого я когда-то работал. Он хотел, чтобы я поработал консультантом, чтобы ускорить разработку программного обеспечения его новой компании. Я спросил его, что это за программное обеспечение, и он сказал мне, что это программное обеспечение для обработки изображений, и что проблема заключается в сверточном фильтре, работающем на процессоре Sparc. Я сказал ему, что ничего не знаю ни о сверточных фильтрах, ни о Sparcs, поэтому не думал, что смогу чем-то помочь, но он был настойчив, поэтому я наконец согласился попробовать.
Я спросил его, что это за программное обеспечение, и он сказал мне, что это программное обеспечение для обработки изображений, и что проблема заключается в сверточном фильтре, работающем на процессоре Sparc. Я сказал ему, что ничего не знаю ни о сверточных фильтрах, ни о Sparcs, поэтому не думал, что смогу чем-то помочь, но он был настойчив, поэтому я наконец согласился попробовать.
Он связал меня с инженером, работавшим над программным обеспечением, который немедленно сообщил мне, что проблема заключается в том, что сверточный фильтр использует очень много целочисленных умножений, что Sparc делал очень медленно, поскольку в то время он не У вас нет аппаратной инструкции умножения целых чисел. Вместо этого у него была инструкция частичного произведения, которую нужно было выполнять для каждого значащего бита множителя. В скомпилированном коде это было реализовано путем вызова библиотечной подпрограммы, которая перебирала биты множителя, и эта подпрограмма была тем, на что шло все время.
Я предложил развернуть этот цикл в серию инструкций частичного произведения и прыгнуть в развернутый цикл в нужной точке, чтобы выполнить столько частичных произведений, сколько значащих битов, тем самым исключив все накладные расходы цикла. Однако все еще оставался вопрос о том, делать ли значение пикселя или значение ядра свертки множителем; чем меньше множитель, тем меньше частичных продуктов потребуется, поэтому мы хотели выбрать тот из двух, который в среднем был меньше.
Когда я спросил, что меньше, инженер ответил, что разницы нет. Когда я настаивал, он сказал, что они были случайными. Когда я сказал, что сомневаюсь, что они были случайными, поскольку случайность на самом деле трудно найти, он проворчал. Я не знаю, почему он не хотел давать мне эту информацию — я думаю, он думал, что это пустая трата времени — но в конце концов он согласился собрать данные и перезвонить мне.
Однако в тот день он мне не перезвонил. И он не перезвонил мне на следующий день. Когда он не перезвонил мне на третий день, я подумал, что могу покончить с этим, и позвонил ему. Он ответил на звонок и, когда я представился, сказал: «О, привет. Я просто стою здесь со своими менеджерами и смотрю. Мы все очень счастливы».
Когда он не перезвонил мне на третий день, я подумал, что могу покончить с этим, и позвонил ему. Он ответил на звонок и, когда я представился, сказал: «О, привет. Я просто стою здесь со своими менеджерами и смотрю. Мы все очень счастливы».
Когда я спросил, чем именно он был доволен, он ответил: «Ну, когда я посмотрел данные, оказалось, что 90% значений в ядре свертки равны нулю, поэтому я просто поставил if-not-zero вокруг умножить, и теперь вся программа работает в три раза быстрее!»
Не растеризация очень похожа на это, как мы скоро увидим.
Назначение фрагментов
Как отмечалось ранее, Larrabee использует фрагментированный (также известный как binned или tiled) рендеринг, при котором цель делится на несколько прямоугольников, называемых тайлами. Команды рендеринга сортируются в соответствии с плитками, к которым они прикасаются, и сохраняются в соответствующих ячейках, а затем содержимое каждой ячейки визуализируется отдельно для соответствующей плитки. Это немного сложно, но значительно улучшает когерентность кэша и распараллеливание.
Это немного сложно, но значительно улучшает когерентность кэша и распараллеливание.
Для фрагментации растеризация состоит из двух шагов; первый определяет, каких тайлов касается треугольник, а второй растрирует треугольник внутри каждого тайла. Так что это двухэтапный процесс, и я собираюсь обсудить эти два этапа отдельно.
На рис. 12 показан пример треугольника, который должен быть нарисован в мозаичном целевом объекте рендеринга. Светло-голубая область представляет собой цель рендеринга 256×256, разделенную на четыре фрагмента 128×128.
Рис. 12. Треугольник, который нужно нарисовать в цели рендеринга 256 x 256, состоящей из четырех плиток 128 x 128.
В архитектуре фрагментации Ларраби первым шагом в растрировании треугольника на рис. Второй шаг, растеризация внутри тайла, заключается в растеризации треугольника в тайл 1 при рендеринге бина тайла 1 и в растрировании треугольника в тайл 3 при рендеринге бина тайла 3.
Присвоение треугольников плиткам легко может быть выполнено для относительно небольших треугольников — скажем, до размера плитки, покрывающей 90% всех треугольников — путем выполнения тестов ограничивающей рамки. Например, с помощью тестов ограничивающей рамки было бы легко выяснить, в каких двух плитках находится треугольник на рис. 12. В настоящее время плиткам назначаются большие треугольники путем простого обхода ограничивающей рамки и проверки каждой плитки на соответствие треугольнику; это звучит не очень эффективно, но время назначения тайлов, как правило, составляет незначительную часть общего времени рендеринга для больших треугольников, поскольку обычно для этих треугольников требуется много работы по затенению и т.п. Однако, если время присвоения плиток больших треугольников окажется значительным, мы могли бы использовать метод развертки, как обсуждалось ранее, или разновидность иерархического подхода, используемого для растеризации внутри плитки, о чем я расскажу далее. Это хороший пример того, как ЦП позволяет легко использовать два совершенно разных подхода для выполнения 9 задач.0 % — хорошо, а 10 % — адекватно (или хорошо, но по-другому), вместо того, чтобы иметь один размер для всех.
Например, с помощью тестов ограничивающей рамки было бы легко выяснить, в каких двух плитках находится треугольник на рис. 12. В настоящее время плиткам назначаются большие треугольники путем простого обхода ограничивающей рамки и проверки каждой плитки на соответствие треугольнику; это звучит не очень эффективно, но время назначения тайлов, как правило, составляет незначительную часть общего времени рендеринга для больших треугольников, поскольку обычно для этих треугольников требуется много работы по затенению и т.п. Однако, если время присвоения плиток больших треугольников окажется значительным, мы могли бы использовать метод развертки, как обсуждалось ранее, или разновидность иерархического подхода, используемого для растеризации внутри плитки, о чем я расскажу далее. Это хороший пример того, как ЦП позволяет легко использовать два совершенно разных подхода для выполнения 9 задач.0 % — хорошо, а 10 % — адекватно (или хорошо, но по-другому), вместо того, чтобы иметь один размер для всех.
Назначение плиткам больших треугольников выполняется с помощью скалярного кода для простоты и потому, что это не является существенным фактором производительности. Давайте посмотрим, как работает этот скалярный процесс, потому что позже он поможет нам понять векторизованную растеризацию внутри тайла. В качестве примера я буду использовать маленький треугольник для простоты и чтобы цифры были разборчивыми, но, как отмечалось выше, обычно такой маленький треугольник назначается своей плитке или плиткам с помощью тестов ограничивающей рамки.
После того, как мы составили уравнение для ребра (путем вычисления B и C, как обсуждалось при рассмотрении рисунка 1), первое, что мы делаем, — это вычисляем его значение в тривиальном отклоненном углу каждой плитки. Тривиальный отклоненный угол — это угол, в котором уравнение ребра является наиболее отрицательным в пределах плитки; как мы вскоре увидим, выбор тривиального отклонения угла для данного ребра основан на его наклоне. Мы настроили все так, что отрицательное означает внутри, чтобы позволить нам генерировать маски непосредственно из бита знака, поэтому вы можете думать о тривиальном отклоняемом углу как о точке плитки, которая больше всего находится внутри края. Если эта точка не находится внутри края, никакая точка плитки не может быть внутри края, и поэтому весь треугольник для этой плитки можно игнорировать.
Если эта точка не находится внутри края, никакая точка плитки не может быть внутри края, и поэтому весь треугольник для этой плитки можно игнорировать.
На рис. 13 показан тривиальный тест отбраковки в действии. Плитка 0 тривиально отбрасывается за черное ребро и может быть проигнорирована, потому что ее тривиальный отбракованный угол положителен, а значит, вся плитка должна быть положительной и лежать вне треугольника, а остальные три плитки необходимо исследовать дополнительно. Вы можете видеть здесь, как тривиальный угол отклонения — это угол каждой плитки, который больше всего находится внутри черного края; то есть точка с самым отрицательным значением в тайле.
Рисунок 13. Тривиальный тест на отклонение плитки.
Обратите внимание, что угол, который является тривиальным отклоненным углом, будет варьироваться от края к краю, в зависимости от уклона. Например, это будет нижний левый угол каждой плитки для края, показанного красным на рисунке 14, потому что это угол, который больше всего находится внутри этого края.
Рис. 14. Какой угол является тривиальным отклоненным углом, зависит от наклона кромки. Здесь нижний левый угол каждой плитки является тривиальным отклоненным углом.
Если вы понимаете то, что мы только что обсудили, вы на девяносто процентов пути к пониманию всего растеризатора Larrabee. Тривиальный тест на отбраковку на самом деле очень прост, как только вы его поймете — это всего лишь вопрос оценки знака простого уравнения в нужной точке — но это может занять некоторое время, так что вы можете счесть полезным пересмотреть его. прочтите предыдущий раздел, если вы совсем не уверены или запутались.
Итак, это тривиальный тест на отбраковку плитки. Другой тест плитки — это тривиальный тест принятия. Для этого мы берем значение в тривиальном отклоняемом углу (угол, который мы только что обсуждали) и добавляем величину, на которую уравнение ребра изменяется за шаг до диагонально противоположного угла тайла, тривиального приемлемого угла тайла. Это точка тайла, где уравнение ребра наиболее положительное; вы можете думать об этом как о точке плитки, которая больше всего находится за краем. Если тривиальный приемлемый угол для ребра отрицательный, вся плитка тривиально принимается для этой грани, и нет необходимости учитывать эту кромку при растеризации внутри плитки.
Если тривиальный приемлемый угол для ребра отрицательный, вся плитка тривиально принимается для этой грани, и нет необходимости учитывать эту кромку при растеризации внутри плитки.
На рис. 15 показан тривиальный приемочный тест в действии. Поскольку тривиальный допустимый угол — это угол, в котором уравнение ребра является наиболее положительным, если эта точка отрицательна — и, следовательно, находится внутри ребра — все точки плитки должны быть внутри ребра. Таким образом, тайлы 0 и 1 не принимаются за черное ребро тривиально, потому что уравнение для черного ребра положительно в их тривиальных допустимых углах, но тайлы 2 и 3 тривиально принимаются, поэтому растеризация этого треугольника в тайлах 2 и 3 может полностью игнорируйте черный край, экономя приличную часть работы.
Рис. 15. Тривиальный тест приема плитки.
Здесь есть важная асимметрия. Когда мы рассмотрели тривиальное отклонение, мы увидели, что оно применяется ко всему треугольнику в плитке, к которой рисуется, в том смысле, что тривиальное отклонение плитки относительно любого края означает, что треугольник не касается этой плитки, и поэтому треугольник может быть игнорируется в этой плитке. Однако тривиальное принятие применяется только к проверяемому ребру; то есть тривиальное принятие тайла напротив края означает только то, что конкретное ребро не нужно проверять при растеризации треугольника в этот тайл, потому что весь тайл находится внутри этого ребра; это не имеет прямого значения для всего треугольника. Плитка может быть тривиально принята против одного края, но не против других; на самом деле его можно тривиально отклонить от одного или обоих других ребер, и в этом случае треугольник вообще не будет нарисован на тайле. Это проиллюстрировано на рисунке 16, где тайл 3 тривиально принимается по черному краю, поэтому черный край не нужно учитывать при растеризации треугольника для этого тайла, но тайл 3 тривиально отбрасывается по красному краю, и что означает, что треугольник вообще не нужно растрировать до тайла 3.
Однако тривиальное принятие применяется только к проверяемому ребру; то есть тривиальное принятие тайла напротив края означает только то, что конкретное ребро не нужно проверять при растеризации треугольника в этот тайл, потому что весь тайл находится внутри этого ребра; это не имеет прямого значения для всего треугольника. Плитка может быть тривиально принята против одного края, но не против других; на самом деле его можно тривиально отклонить от одного или обоих других ребер, и в этом случае треугольник вообще не будет нарисован на тайле. Это проиллюстрировано на рисунке 16, где тайл 3 тривиально принимается по черному краю, поэтому черный край не нужно учитывать при растеризации треугольника для этого тайла, но тайл 3 тривиально отбрасывается по красному краю, и что означает, что треугольник вообще не нужно растрировать до тайла 3.
Рисунок 16. Плитка 3 тривиально принимается по черному краю, но тривиально отклоняется по красному краю.
На рис. 17, однако, плитка 3 тривиально принимается всеми тремя ребрами, и здесь мы подходим к ключевому моменту.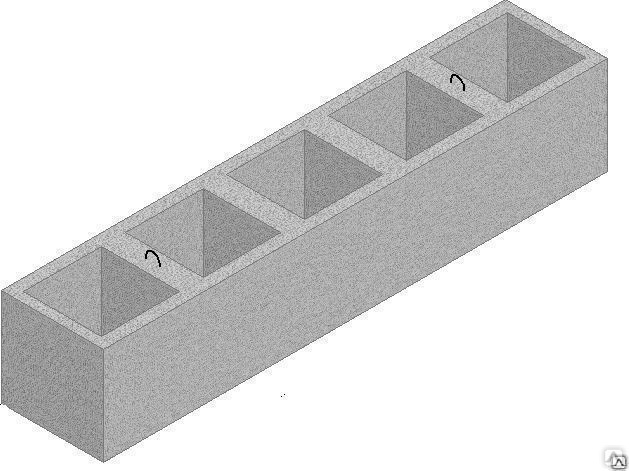
Рисунок 17. Плитка 3 тривиально принимается по всем трем краям.
Если все три ребра имеют отрицательные значения в соответствующих тривиальных допустимых углах, то вся плитка находится внутри треугольника, и дальнейшие тесты растеризации не требуются — и это то, что я имел в виду ранее, когда сказал, что растеризатор использует преимущества ЦП, не растрировать, когда это возможно. Код назначения плитки может просто хранить команду рисования всей плитки в корзине, а код рендеринга корзины может просто выполнять эквивалент двух вложенных циклов вокруг шейдеров, что приводит к скорости растеризации полноэкранного треугольника примерно бесконечной. один из моих любимых исполнительских номеров!
Между прочим, весь этот процесс должен быть знаком 3D-программистам, потому что тестирование ограничивающих прямоугольников относительно плоскостей (например, для отбраковки усеченного конуса) обычно выполняется точно таким же образом, хотя и в трех измерениях, а не в двух. — с
— с
одинаковым использованием знака для обозначения внутри и снаружи для тривиального принятия и отклонения. Кроме того, такие структуры, как октодеревья, используют трехмерную версию иерархической рекурсии, используемую растеризатором Larrabee. Как я уже сказал, это делается как скалярная оценка в конвейере Larrabee, поэтому тривиальные проверки принятия и отклонения для каждой плитки выполняются отдельно. Растеризация внутри тайла, к которой мы обратимся далее, почти такая же, но векторизованная, и именно эта векторизация даст нам представление о применении Новых инструкций Ларраби к полупараллельным задачам.
Внутритайловая растеризация: блоки 16×16
Внутритайловая растеризация начинается на уровне целого тайла. Размер плитки варьируется в зависимости от таких факторов, как размер пикселя, но давайте предположим, что мы работаем с плиткой 64×64. Учитывая этот начальный размер, мы вычисляем значения уравнения ребра в 16 тривиальных углах отклонения и тривиального принятия углов блоков 16×16, составляющих плитку, точно так же, как мы делали это на уровне плитки, но теперь мы делаем эти вычисления по 16 за раз. Начнем с тривиального теста на отбраковку.
Начнем с тривиального теста на отбраковку.
Во-первых, мы вычисляем, какой угол плитки является тривиальным отклоненным углом, вычисляем значение уравнения края в этой точке и настраиваем таблицу, содержащую 16 шагов уравнения края, исходя из значения тривиального угла отклонения плитки. к банальным отклонениям углов блоков 16×16, из которых состоит плитка. Знаки полученных 16 значений говорят нам, какие из блоков полностью находятся за пределами края и поэтому могут быть проигнорированы, а какие хотя бы частично приняты и, следовательно, должны оцениваться дальше.
Например, на рис. 18 мы вычисляем тривиальные значения отбраковки для черного края, исходя из значения, которое мы вычислили ранее для тривиального отбракованного угла плитки, и удаляем пять блоков 16×16, составляющих плитку. Тривиальный отбракованный угол для плитки показан красным, а 16 тривиальных отбракованных углов для блоков показаны белым. Серые блоки — это те, которые отбрасываются по черному краю; вы можете видеть, что все их тривиальные отклоненные углы имеют положительные значения уравнения края. Остальные 11 блоков имеют отрицательные значения в их тривиальных отклоненных углах, поэтому они, по крайней мере, частично находятся внутри черного края.
Остальные 11 блоков имеют отрицательные значения в их тривиальных отклоненных углах, поэтому они, по крайней мере, частично находятся внутри черного края.
Рис. 18. Тривиальные тесты отклонения для 16 блоков 16×16 в тайле.
Чтобы сделать этот процесс более понятным, на рис. 19 стрелки представляют 16 шагов, которые добавляются к тривиальному значению отклонения плитки черного края. Каждый из этих шагов — просто добавление, и мы можем выполнить 16 добавлений с помощью одной векторной инструкции, поэтому требуется только одна векторная инструкция для генерации 16 тривиальных значений отклонения и еще одна векторная инструкция — сравнение — для их проверки.
Рисунок 19. Шаги от тривиального отклонения угла для черного края до тривиального отклонения углов 16 блоков 16×16 для черного края.
Все сводится к установке правильных значений, а затем к выполнению одного векторного сложения и одного векторного сравнения. Помните, что уравнение края имеет форму Bx + Cy; поэтому, чтобы пройти расстояние по плитке, мы просто устанавливаем x и y как горизонтальную и вертикальную составляющие этого расстояния, оцениваем уравнение и добавляем его к начальному значению. Итак, все, что мы делаем на рисунке 19добавляет 16 значений, которые шаг за шагом уравнение края к 16 тривиальным отклонениям углов. Например, чтобы получить значение уравнения края в тривиальном отбракованном углу левого верхнего блока, мы должны начать со значения в тривиальном отбракованном углу плитки и добавить величину, на которую уравнение края изменяется для шага -48. пикселей по x и -48 пикселей по y, как показано желтой стрелкой на рисунке 20. Чтобы получить значение уравнения края в тривиальном отклоненном углу нижнего левого блока, мы должны вместо этого добавить величину, на которую уравнение края изменяет для шага -48 пикселей только по x, как показано фиолетовой стрелкой. И это действительно все, что есть в растеризаторе Larrabee — это всего лишь вопрос пошагового перемещения значений уравнения края вокруг плитки, чтобы определить, какие блоки и пиксели находятся внутри и снаружи краев.
Итак, все, что мы делаем на рисунке 19добавляет 16 значений, которые шаг за шагом уравнение края к 16 тривиальным отклонениям углов. Например, чтобы получить значение уравнения края в тривиальном отбракованном углу левого верхнего блока, мы должны начать со значения в тривиальном отбракованном углу плитки и добавить величину, на которую уравнение края изменяется для шага -48. пикселей по x и -48 пикселей по y, как показано желтой стрелкой на рисунке 20. Чтобы получить значение уравнения края в тривиальном отклоненном углу нижнего левого блока, мы должны вместо этого добавить величину, на которую уравнение края изменяет для шага -48 пикселей только по x, как показано фиолетовой стрелкой. И это действительно все, что есть в растеризаторе Larrabee — это всего лишь вопрос пошагового перемещения значений уравнения края вокруг плитки, чтобы определить, какие блоки и пиксели находятся внутри и снаружи краев.
Рисунок 20: Примеры пошагового выполнения уравнения ребра Bx + Cy.
Еще раз, мы проведем тривиальные тесты приема, а также тривиальные тесты отклонения. На рис. 21 мы вычислили тривиальные допустимые значения и определили, что 6 из блоков 16×16 тривиально принимаются для черного края, а 10 из них тривиально не принимаются. Мы знаем это, потому что значения уравнения черного края в тривиальных допустимых углах 6 розовых блоков отрицательны, поэтому эти блоки полностью находятся внутри края, а значения в тривиальных допустимых углах других 10 блоков положительны. , поэтому эти блоки не полностью находятся внутри черного края. Тривиальные допустимые значения для блоков могут быть вычислены пошагово любым из нескольких различных способов: из тривиального допустимого угла тайла, из тривиального отклоненного угла тайла или из 16 тривиальных значений отклонения для блоков. Несмотря на это, снова требуется только одна векторная инструкция для шага и одна векторная инструкция для проверки результатов. В сочетании с результатами тривиального теста на отбраковку мы также знаем, что 5 блоков частично приняты.
На рис. 21 мы вычислили тривиальные допустимые значения и определили, что 6 из блоков 16×16 тривиально принимаются для черного края, а 10 из них тривиально не принимаются. Мы знаем это, потому что значения уравнения черного края в тривиальных допустимых углах 6 розовых блоков отрицательны, поэтому эти блоки полностью находятся внутри края, а значения в тривиальных допустимых углах других 10 блоков положительны. , поэтому эти блоки не полностью находятся внутри черного края. Тривиальные допустимые значения для блоков могут быть вычислены пошагово любым из нескольких различных способов: из тривиального допустимого угла тайла, из тривиального отклоненного угла тайла или из 16 тривиальных значений отклонения для блоков. Несмотря на это, снова требуется только одна векторная инструкция для шага и одна векторная инструкция для проверки результатов. В сочетании с результатами тривиального теста на отбраковку мы также знаем, что 5 блоков частично приняты.
Рис. 21. Тривиальные тесты приема для 16 блоков 16×16 в плитке.
16 тривиальных значений отклонения и тривиального принятия могут быть рассчитаны всего с двумя сложениями векторов на ребро, используя таблицы, сгенерированные во время установки треугольника, и могут быть протестированы с помощью двух сравнений векторов, которые генерируют регистры маски, описывающие, какие блоки тривиально отвергаются и тривиально принимаются. Мы делаем это для трех ребер, объединяя результаты по И для создания масок для треугольника, выполняем некоторые битовые манипуляции с масками, чтобы они описывали тривиальное и частичное принятие, и сканируем результаты по битам, чтобы найти тривиальные и частично принятые блоки. Каждое 16×16, которое тривиально принимается для всех трех ребер, становится одной командой bin; опять же, дальнейшая растеризация пикселей в тривиально принятых блоках не требуется.
Это неочевидно, так что давайте представим себе процесс. Во-первых, давайте просто посмотрим на одно ребро и тривиально примем.
Для заданного ребра, скажем, ребра номер 1, мы берем значение уравнения ребра в тривиальном приемном углу плитки, передаем его в вектор, и вектор добавляет его к предварительно рассчитанным значениям 16 шагов к тривиальным допустимым углам тайла. блоки 16х16. Это дает нам значения ребра 1 в тривиальных допустимых углах 16 блоков, как показано на рисунке 22. (Показанные значения являются иллюстративными и не взяты из реального треугольника.)
блоки 16х16. Это дает нам значения ребра 1 в тривиальных допустимых углах 16 блоков, как показано на рисунке 22. (Показанные значения являются иллюстративными и не взяты из реального треугольника.)
Рис. 22. Тривиальные тесты приема ребра 1 для 16 блоков 16×16.
Значения шага, показанные во второй строке на рис. 22, вычисляются при построении треугольника с использованием векторного умножения и векторного умножения-сложения. На верхнем уровне растеризатора — тестировании блоков 16×16, составляющих тайл, как показано на рис. 22 — эти инструкции по настройке просто являются прямыми дополнительными затратами на растеризацию, поскольку верхний уровень выполняется только один раз для каждого треугольника, поэтому он Если быть точным, добавьте 6 инструкций к стоимости кода 16×16, который мы вскоре рассмотрим в листингах 1 и 2. Однако по мере нисходящей иерархии таблицы для более низких уровней (16×16-to-4×4 и маска) повторно используются несколько раз. Например, при переходе от блоков 16×16 к блокам 4×4 одна и та же таблица используется для всех неполных блоков 16×16 в тайле. Аналогично, имеется только одна таблица для создания масок для неполных блоков 4×4, поэтому дополнительные затраты на итерацию в листинге 3 из-за настройки таблицы будут равны 2 инструкциям, деленным на количество неполных блоков 4×4 в тайле. Обычно это намного меньше, чем 1 инструкция на блок 4×4 на ребро, хотя чем меньше треугольник, тем больше.
Аналогично, имеется только одна таблица для создания масок для неполных блоков 4×4, поэтому дополнительные затраты на итерацию в листинге 3 из-за настройки таблицы будут равны 2 инструкциям, деленным на количество неполных блоков 4×4 в тайле. Обычно это намного меньше, чем 1 инструкция на блок 4×4 на ребро, хотя чем меньше треугольник, тем больше.
Затем мы сравниваем результаты с 0; как показано на рис. 22, это создает маску, содержащую 1 бит, где тривиальный допустимый угол блока меньше нуля, то есть везде, где тривиальный допустимый угол блока находится внутри края, что означает, что весь блок находится внутри края.
Мы делаем это для каждого из трех ребер, объединяя маски вместе для создания составной маски, как показано на рис. 23. (Объединение И происходит автоматически как часть обновления маски, как мы увидим позже, когда рассмотрим код.) Эта составная маска имеет 1 бит только в том случае, если блок тривиально принимается по всем трем краям, то есть для блоков, которые полностью тривиально принимаются и не требуют дальнейшей растеризации.
Рис. 23. Генерация составной тривиальной маски принятия для трех ребер.
Теперь мы можем побитово сканировать составную маску, выбирая тривиально принятые блоки 16×16 и сохраняя команду рисования блока для каждого из них в выходной очереди растеризатора. Первое битовое сканирование обнаружит, что блок 0 тривиально принят, второе битовое сканирование обнаружит, что блок 4 тривиально принято, а третье битовое сканирование обнаружит, что тривиально принятых блоков больше нет, как показано на рисунке 24.
Рис. 24. Сканирование составной тривиальной маски принятия для поиска тривиально принятых блоков 16×16.
Этот тип преобразования из параллельного в последовательный — эффективное определение и обработка релевантных элементов векторного результата — является ключом к получению хорошей производительности полувекторизуемого кода. Именно поэтому инструкция bsfi была добавлена как часть новых инструкций Larrabee. Bsfi основан на существующей инструкции побитового сканирования, но улучшен, чтобы позволить начинать сканирование с любого бита, а не только с бита 0.
Наконец-то мы готовы взглянуть на реальный код. В листинге 1 показан тривиальный код принятия блоков 16×16 в тайле 64×64; этого будет достаточно, чтобы проиллюстрировать то, что мы обсуждали, и что-либо еще только усложнит объяснение. Давайте сопоставим эти инструкции с шагами, которые мы только что описали.
; При вводе:
; rsi: базовый указатель на данные потока
; v3: шаги от края 1 плитки тривиально принимают угол к углам блоков 16×16
; v4: шаги от края 2 плитки тривиально принимают угол к углам блоков 16×16
; v5: шаги от края 3 плитки тривиально принимают угол к углам блоков 16×16
; Значения шага до краев в 16 блоках 16×16, тривиальные допустимые углы {1to16}
; Проверить, находится ли каждый тривиальный угол приема внутри всех трех ребер
; К1 устанавливается первой инструкцией, затем результат
; вторая инструкция объединяется с k1 и аналогично для третьей инструкции , v2, [rsi+ConstantZero]{1to16}
; Получите маску; 1-биты тривиально принимают углы, равные
; внутри всех трех ребер
кмов eax, k1
; Цикл по 1-битам, выдающий команду draw-16×16-block
; для каждого банально принятого блока 16×16
bsf ecx, eax
jnz TrivialAcceptDone
TrivialAcceptLoop:
; <Сохранить команду draw-16x16-block вместе с расположением (x,y)>
bsfi ecx, eax
jnz TrivialAcceptLoop
TrivialAcceptDone:
Листинг 1: Простой код принятия для блоков 16×16.
Во-первых, есть три вектора, которые добавляют к шагу 3 значения ребер к тривиальным допустимым углам 16x16s; это три инструкции ваддпи.
Во-вторых, есть три векторных сравнения для проверки знаков результатов, чтобы увидеть, тривиально ли блоки принимаются по краям; это три инструкции vcmpltpi. Составная маска накапливается в регистре маски k1.
Затем kmov копирует маску тривиально принятых блоков в регистр eax, и, наконец, существует цикл для побитового сканирования eax для выбора тривиально принятых блоков 16×16 один за другим, чтобы их можно было обрабатывать как блоки без дальнейшая растеризация.
Требуется всего 6 векторных инструкций, одно перемещение маски и две скалярные инструкции для настройки плюс две скалярные инструкции на каждый тривиально принятый блок, чтобы найти все тривиально допустимые 16×16 в тайле.
И, по правде говоря, для этого требуется не так уж много инструкций. То, что показано в листинге 1, представляет собой версию тривиального кода принятия, в котором используются обычные векторные инструкции, но на самом деле существует специальная инструкция, специально разработанная для ускорения растеризации — vaddsetspi — которая одновременно добавляет и устанавливает маску для знака. Я не упомянул об этом, потому что думал, что обсуждение было бы более ясным и более актуальным, если бы я использовал стандартные векторные инструкции, но, как вы можете видеть в листинге 2, если мы используем vaddsetspi, нам нужно всего 3 векторных инструкции, чтобы найти все тривиальные принимаются блоки 16×16.
Я не упомянул об этом, потому что думал, что обсуждение было бы более ясным и более актуальным, если бы я использовал стандартные векторные инструкции, но, как вы можете видеть в листинге 2, если мы используем vaddsetspi, нам нужно всего 3 векторных инструкции, чтобы найти все тривиальные принимаются блоки 16×16.
; При вводе:
; rsi: базовый указатель на данные потока
; v3: шаги от края 1 плитки тривиально принимают угол к углам блоков 16×16
; v4: шаги от края 2 плитки тривиально принимают угол к углам блоков 16×16
; v5: шаги от края 3 плитки тривиально принимают угол к углам блоков 16×16
; Шаг к граничным значениям в 16 блоках 16×16 тривиально принимает углы &
; посмотреть, находится ли каждый тривиальный допустимый угол внутри всех трех ребер
kxnor k1, k1 ; установить маску на 0xFFFF
; Результат каждой инструкции объединяется с k1
vaddsetspi v0 {k1}, v3, [rsi+Edge1TileTrivialAcceptCornerValue]{1to16}
vaddsetspi v1 {k1}, v4, [rsi+Edge2TileTrivialAcceptCornerValue]{1to16}
vaddsetspi v2 {k1}, v5, [rsi+Edge3TileTrivialAcceptCornerValue]{1to16}
; Получите маску; 1-биты тривиально принимают углы, равные
; внутри всех трех ребер
кмов eax, k1
; Цикл по 1-битам, выдающий команду draw-16×16-block
; за каждый банально принятый блок 16х16
bsf ecx, eax
jnz TrivialAcceptDone
TrivialAcceptLoop:
; <Сохранить команду draw-16x16-block вместе с расположением (x,y)>
bsfi ecx, eax
jnz TrivialAcceptLoop
TrivialAcceptDone:
Листинг 2: Простой код принятия для блоков 16×16 с использованием vaddsetspi.
Также может быть меньше активных ребер из-за тривиальных приемов на уровне тайла (помните, ребра, которые тривиально принимаются для тайла, могут игнорироваться — и игнорируются — при растрировании внутри тайла), и это приведет к еще меньшему количеству инструкций ; это еще один случай, когда программное обеспечение может повысить производительность, адаптируясь к данным.
Спуск по иерархии растеризации
Теперь мы закончили растеризацию тривиально принятых блоков 16×16, но нам все еще нужно обрабатывать частично покрытые блоки 16×16, и к этому моменту должно быть очевидно, как это работает; мы спускаемся в каждую часть 16×16, чтобы оценить содержащиеся в ней блоки 4×4, точно так же, как мы спускались в тайл 64×64, чтобы оценить содержащиеся в нем блоки 16×16. Опять же, тривиально принятые полноприводные автомобили мы отправляем прямо в мусорное ведро. Однако частично принятые форматы 4×4 необходимо преобразовать в пиксельные маски. Это делается с помощью векторного добавления предварительно рассчитанной, независимой от позиции таблицы для каждого края, который переходит от тривиального угла отклонения 4×4 к центру самого пикселя; затем знаковые биты могут быть объединены по И вместе, чтобы сформировать пиксельную маску.
На рис. 25 показано вычисление пиксельной маски. Из угла тривиального отклонения 4×4, показанного красным, одно добавление дает значение уравнения для черного края в центрах 16 пикселей. Красные стрелки показывают, как 16 значений в предварительно рассчитанной, независимой от положения таблице шагов для каждого края добавляются к тривиальному отбракованному углу 4×4 для оценки уравнения края в центрах 16 пикселей. Пиксели, показанные синим цветом, имеют отрицательные значения и находятся внутри края. На этом слайде показана фактическая сгенерированная маска с 1 битом для каждого пикселя внутри края и 0 битом для каждого пикселя снаружи.
Рис. 25. Маска пикселя вычисляется в центрах пикселей путем пошаговой обработки относительно тривиального угла отклонения для 4×4.
Рисунок 25 — хорошая демонстрация того, как эффективность векторов может падать при частично векторизуемых задачах, и почему Larrabee использует векторы шириной 16, а не что-то большее. Мы часто проделываем всю работу, необходимую для создания пиксельной маски для 4×4, только для того, чтобы обнаружить, что многие или большинство пикселей не покрыты, так что большая часть работы была потрачена впустую — и чем шире вектор, тем ниже отношение покрытое становится непокрытым в среднем, и тем больше работы тратится впустую.
В листинге 3 показан код для вычисления пиксельных масок для всех частично закрытых блоков 4×4 в частично закрытом блоке 16×16. Обратите внимание, что это единственный случай, когда выполняется попиксельная работа; все случаи сплошного покрытия блоков обрабатываются без создания пиксельной маски.
; При вводе:
; rbx: указатель на выходной буфер
; rsi: базовый указатель на данные потока
; k1: маска частично принятых блоков 4×4 в текущем 16×16
; v0: край 1 тривиально отбрасывает угловые значения для блоков 4×4 в текущем 16×16
; v1: край 2 тривиально отбрасывает угловые значения для блоков 4×4 в текущем 16×16
; v2: край 3 тривиальные значения отклонения углов для блоков 4×4 в текущем 16×16
; Сохраните значения в углах 16 4×4 в 16×16 для индексации в
vstored [rsi+Edge1TrivialRejectCornerValues4x4], v0
vstored [rsi+Edge2TrivialRejectCornerValues4x4], v1
vstored [rsi+Edge3TrivialRejectCornerValues4x4], v2 900; Загрузить таблицы шагов от углов 4×4 до центров пикселей
vloadd v3, [rsi+Edge1PixelCenterTable]
vloadd v4, [rsi+Edge2PixelCenterTable]
vloadd v5, [rsi+Edge3PixelCenterTable]
; Цикл через 1-бит из тривиального теста отклонения в блоке 16×16 (тривиальные приемы были
; ранее выполнено XOR), спускаясь для растеризации каждого частично принятого 4×4
kmov eax, k1
bsf ecx, eax
jnz Partial4x4Done
Partial4x4Loop:
9 ; Посмотрите, находится ли центр каждого из 16 пикселей внутри всех трех краев
; Используйте rcx, индекс из битового сканирования текущего частично принятого 4×4, для индексации в
; тривиальные значения углов отклонения 4×4, сгенерированные на уровне 16×16, и выбор
; тривиальные значения углов отклонения для текущего частично принятого 4×4
; К2 устанавливается первой инструкцией, затем результат
; вторая инструкция объединяется по И с k2, и аналогично для третьей инструкции
vcmpgtpi k2, v3, [rsi+Edge1TrivialRejectCornerValues4x4+rcx*4]{1to16}
vcmpgtpi k2 {k2}, v4, [rsi+Edge2TrivialRejectCornerValues4x4+rcx*4]{ 1to16}
vcmpgtpi k2 {k2}, v5, [rsi+Edge3TrivialRejectCornerValues4x4+rcx*4]{1to16}
; Магазин маски
kmov edx, k2
mov [rbx], dx
; <Сохранение местоположения (x,y) и продвижение rbx>
bsfi ecx, eax
jnz Partial4x4Loop
Partial4x4Done:
Листинг 3. Код маски пикселя для частично закрытых блоков 4×4.
Код маски пикселя для частично закрытых блоков 4×4.
В листинге 3 сначала хранятся тривиальные значения отклоненных углов для 16 блоков 4×4 для трех краев. Это значения, относительно которых мы будем шагать, чтобы сгенерировать окончательные пиксельные маски для каждого частичного 4×4, и они были сгенерированы ранее кодом 16×16, который выполнялся непосредственно перед этим кодом. Это делается с помощью трех vstored-инструкций.
Затем таблицы шагов для трех ребер загружаются с помощью трех инструкций vloadd. (На самом деле, они, вероятно, будут предварительно загружены в регистры при настройке треугольника и останутся там на протяжении всей растеризации треугольника, но их загрузка здесь проясняет, что происходит.)
После завершения настройки код сканирует частичную маску принятия, которая также была сгенерирована ранее кодом 16×16. Сначала маска копируется в eax с помощью инструкции kmov, а затем используется bsfi для поиска каждого частично принятого блока 4×4 по очереди.
Для каждого найденного частично покрытого 4×4, код выполняет три векторных сравнения, чтобы оценить три уравнения ребер в центрах 16 пикселей. Обратите внимание, что каждый vcmpgtpi использует индекс текущего 4×4 для извлечения тривиального значения отклонения угла для этого 4×4 из вектора, сгенерированного на уровне 16×16. Хотя мы могли бы напрямую добавить, а затем проверить знаки уравнений ребра, как я описал ранее, более эффективно вместо этого изменить порядок вычислений, перевернув знаки таблиц шагов, чтобы тестирование можно было выполнить с одним сравнением для каждого ребра. Иными словами, вместо того, чтобы складывать два значения и смотреть, меньше ли результат, чем ноль:
m + n < 0
эквивалентно и более эффективно сравнивать одно значение непосредственно с отрицанием другого значения:
m < -n.
(Если вам интересно, мы не могли использовать этот трюк на уровнях иерархии 16×16 и 64×64, потому что в этих случаях, помимо получения результата теста, нам также нужно сохранить результат теста. добавить, чтобы мы могли передать его вниз по иерархии как новое значение угла.)
добавить, чтобы мы могли передать его вниз по иерархии как новое значение угла.)
Результатом сравнения является окончательная составная пиксельная маска для этого 4×4, которую можно сохранить в выходной очереди растеризации. И все: как только все настроено, стоимость растеризации каждого частичного 4×4 составляет три векторных инструкции, инструкцию маски и несколько скалярных инструкций. Еще раз, если бы вся плитка была тривиально принята против одного или двух ребер, тогда потребовалось бы пропорционально меньше векторных инструкций.
Одна приятная особенность подхода к растеризации Larrabee заключается в том, что MSAA (многосэмпловое сглаживание) выпадает из-за одного дополнительного векторного сравнения на 16 сэмплов на ребро, так как это просто другой шаг, чем тривиальное отклонение угла. (Это для частично принятых блоков 4×4; для всех тривиально принятых блоков нет дополнительных затрат на растеризацию MSAA.) На рис. 26 каждый пиксель делится на четыре выборки, и показан шаг к одной из четырех выборок, а не к центру каждого пикселя; для этого требуется одно сравнение, поэтому для создания полной выборочной маски MSAA для 16 пикселей потребуется четыре сравнения.
Рис. 26. Переход к одному набору образцов для растеризации 4X MSAA частично покрытого 4×4.
Собираем все вместе
Теперь, когда мы прошли весь путь вниз по иерархии растеризации, давайте вернемся и снова посмотрим на обзор спуска растеризации, с которого мы начали, на этот раз с подробным пониманием того, что происходит.
На рис. 27 показаны треугольник и плитка 64×64, на которую должен быть нарисован треугольник, при этом плитка разделена на блоки 16×16; Рисунок 27 повторяет рисунок 8, но на этот раз я добавил пунктирные продолжения краев к границе плитки, чтобы мы могли видеть, какие блоки и пиксели находятся по каким сторонам краев.
Рис. 27. Треугольник, который нужно растрировать, показан на фоне пикселей в плитке 64 x 64. Блоки 16×16, которые не были отклонены банально, выделены зеленым и желтым цветом.
Чтобы растеризовать треугольник на рис. 27, мы сначала вычисляем значения трех уравнений треугольника для ребер в тривиальном допустимом и тривиальном отклоненном углах плитки и обнаруживаем, что плитка не является ни тривиально отклоненной, ни тривиально принятой ни одним краем. (Опять же, на самом деле это будет сделано только для большого треугольника; мы будем использовать тесты ограничивающей рамки для такого маленького треугольника.) Мы настраиваем различные ступенчатые таблицы, которые мы будем использовать, а затем шагаем уравнения ребер до их соответствующих тривиальных значений. принять и тривиально отклонить углы 16 блоков размером 16×16 каждый, составляющих тайл, и составить маску, содержащую признаки результатов.
(Опять же, на самом деле это будет сделано только для большого треугольника; мы будем использовать тесты ограничивающей рамки для такого маленького треугольника.) Мы настраиваем различные ступенчатые таблицы, которые мы будем использовать, а затем шагаем уравнения ребер до их соответствующих тривиальных значений. принять и тривиально отклонить углы 16 блоков размером 16×16 каждый, составляющих тайл, и составить маску, содержащую признаки результатов.
Затем мы сканируем полученную маску по битам, обнаруживаем, что 12 из 16 блоков тривиально отбрасываются, и спускаемся в каждый из оставшихся 4 блоков по очереди. В трех блоках мы в конечном итоге обнаружим, что рисовать нечего, поэтому в целях данного обсуждения мы их проигнорируем и рассмотрим более интересный случай, когда мы спустимся в блок, внутри которого находится треугольник. , блок обведен желтым. (Обратите внимание, что если бы треугольник был достаточно большим, чтобы полностью покрыть блок 16×16, этот блок был бы тривиально принят, и дальнейший спуск в этот блок не потребовался бы. )
)
Прежде чем мы посмотрим, что происходит, когда мы спустимся в блок 16×16, содержащий треугольник, есть еще один момент на рис. 27, на который мы должны обратить внимание. Вы могли заметить, что в более ранней версии этого рисунка, рис. 8, был найден только один желтый блок, а не три зеленых блока. Почему на этот раз битовое сканирование нашло 4 блока, когда треугольник на самом деле целиком содержится в одном блоке? Причина в том, что подход к растеризации Ларраби, обсуждаемый в этой статье, может только устранять блоки, тривиально отбрасывая их, и если вы внимательно посмотрите, то увидите, что ни один из трех зеленых блоков не отбрасывается тривиально ни одним ребром. Это неэффективность этого метода растеризации, хотя есть методы, выходящие за рамки этой статьи, которые устраняют большую часть неэффективности.
Спускаясь по иерархии растеризации, мы берем блок 16×16, содержащий треугольник, разделяем его на 16 блоков 4×4 и оцениваем, какие из них соприкасаются с треугольником, пошагово оценивая уравнение края в каждом из их тривиальных приемных и тривиальных отклоненных углов для каждого ребра, как показано на рис. 28. Мы обнаруживаем, что 10 блоков тривиально отвергаются, и что ни один из 6 оставшихся блоков не принимается тривиально по всем трем ребрам.
28. Мы обнаруживаем, что 10 блоков тривиально отвергаются, и что ни один из 6 оставшихся блоков не принимается тривиально по всем трем ребрам.
Рис. 28. Растрирование образца треугольника в содержащем его блоке 16 x 16. Блоки 4×4, которые не были отклонены тривиально, выделены.
Мы, наконец, достигли нижней части иерархии растеризации, поэтому мы можем выполнить побитовое сканирование маски частичного принятия, сгенерированной для 16×16, найти частично принятые блоки 4×4 и сгенерировать пиксельную маску 4×4 для каждого из блоки по очереди, как показано на рисунке 29.
Рисунок 29. Растеризация пикселей в частичных блоках 4×4, покрывающих треугольник.
Здесь мы снова видим, что зависимость от тривиального отклонения для устранения блоков привела к ложному срабатыванию блока, который на самом деле не касается треугольника (крайний левый блок). Можно выполнить тесты ограничивающей рамки для устранения таких блоков, но неясно, является ли это более эффективным, чем простое тестирование пустых масок — то есть масок без включенных пикселей — и пропуск этих блоков.
После завершения этого блока 16×16 мы возвращаемся к растрированию других блоков 16×16, которые не были тривиально отклонены (в данном случае оказалось, что они не содержат никакого треугольника).
Вот и все!
Замечания по растеризации
Теперь, когда мы поняли основной алгоритм растеризации, давайте кратко рассмотрим некоторые интересные усовершенствования реализации.
В программном обеспечении у нас нет роскоши пользовательских данных и размеров ALU, но у нас есть роскошь адаптации к входным данным, и эта адаптивная растеризация помогает повысить нашу эффективность. Например, в худшем случае для оценки фронта необходимо использовать 48 бит; для этих случаев, будучи программным обеспечением, мы должны использовать 64 бита, поскольку в Larrabee нет поддержки 48-битных целых чисел. Однако нам вовсе не обязательно делать это для 90+% всех треугольников, которые помещаются в ограничивающую рамку 128×128, потому что в этих случаях достаточно 32 бит.
Когда нам нужно выполнить оценку 64-битного края, мы должны использовать его только для назначения плитки. Как оказалось, в тайлах размером до 128×128 (а 128×128 — наш самый большой размер тайла) любое ребро, которое не принимается или не отвергается тайлом тривиально, всегда может быть растрировано с использованием 32 бит.
Как оказалось, в тайлах размером до 128×128 (а 128×128 — наш самый большой размер тайла) любое ребро, которое не принимается или не отвергается тайлом тривиально, всегда может быть растрировано с использованием 32 бит.
Мы также можем обнаруживать треугольники, которые помещаются в ограничительную рамку 16×16, и обрабатывать их с одним меньшим уровнем спуска, меньшими настройками и без тривиальной приемочной проверки (поскольку в таких маленьких треугольниках редко будут тривиально принятые 4×4). Наконец, треугольники, которые помещаются в очень маленькие ограничивающие рамки, могут быть созданы путем прямого вычисления масок для 16 или 32 пикселей, с небольшой настройкой и минимальной обработкой.
На самом деле, для маленьких треугольников мы могли бы даже взять значение z ближайшей вершины и сравнить его с буфером z для ограничивающей рамки треугольника и, возможно, отклонить треугольник по z еще до того, как мы его растрируем!
Есть и другие возможности оптимизации, которые я не буду рассматривать, потому что в этой статье просто нет места, и, конечно, нельзя сказать, насколько хорошо они будут работать, пока мы их не попробуем, но в программном обеспечении есть одна приятная особенность: его легко настроить. запустите эксперименты, чтобы проверить их.
запустите эксперименты, чтобы проверить их.
Заключительные мысли
На этом мы завершаем наш краткий обзор подхода Ларраби к растеризации и изучение того, как векторное программирование можно применить к полупараллельной задаче. Как я упоминал ранее, программная растеризация никогда не будет соответствовать пиковой производительности и энергоэффективности выделенного оборудования для данной области кремния, но пока что она доказала свою достаточную эффективность. У него также есть значительное преимущество, заключающееся в том, что, поскольку он использует ядра общего назначения, те же ресурсы, которые используются для растеризации, могут использоваться для других целей в другое время, и наоборот. Как говорит Том Форсайт, поскольку весь чип является программируемым, мы можем эффективно использовать больше квадратных миллиметров для любой конкретной задачи по мере необходимости — вплоть до всего чипа; другими словами, конвейер может динамически перенастраивать свои ресурсы обработки по мере изменения рабочей нагрузки рендеринга. Если мы получаем большую нагрузку по растеризации, мы можем, при необходимости, задействовать все ядра; это не будет самый эффективный растеризатор на квадратный миллиметр, но это будет чертовски много квадратных миллиметров растеризатора, и все они будут делать то, что наиболее важно в данный момент, в отличие от традиционного графического чипа с аппаратным растеризатором, где большая часть схемы простаивала бы при большой нагрузке по растеризации. Чуть позже, когда нагрузка переключится на шейдер, весь чип Larrabee может стать шейдером, если это необходимо. Программное обеспечение просто предлагает совершенно другой набор сильных и слабых сторон.
Если мы получаем большую нагрузку по растеризации, мы можем, при необходимости, задействовать все ядра; это не будет самый эффективный растеризатор на квадратный миллиметр, но это будет чертовски много квадратных миллиметров растеризатора, и все они будут делать то, что наиболее важно в данный момент, в отличие от традиционного графического чипа с аппаратным растеризатором, где большая часть схемы простаивала бы при большой нагрузке по растеризации. Чуть позже, когда нагрузка переключится на шейдер, весь чип Larrabee может стать шейдером, если это необходимо. Программное обеспечение просто предлагает совершенно другой набор сильных и слабых сторон.
У Ларраби есть чему поучиться и переосмыслить, и у него большой потенциал. Только время покажет, насколько хорошо все это сработает, а между тем, это, безусловно, интересное время для программиста производительности!
Дополнительную информацию о Larrabee можно найти на www.intel.com/software/graphics.
{Примечание редактора ISN: эта статья была первоначально опубликована на портале Dr. Dobbs}
Dobbs}
Как работает рендеринг 3D-игр, более глубокое погружение: растеризация и трассировка лучей
Во второй части нашего более глубокого обзора рендеринга 3D-игр мы сосредоточимся на том, что происходит с 3D-миром после завершения обработки всех вершин. Нам нужно снова стряхнуть пыль с наших учебников по математике, разобраться с геометрией усеченных конусов и обдумать загадку перспективы. Мы также быстро погрузимся в физику трассировки лучей, освещения и материалов — отлично!
Основная тема этой статьи посвящена важному этапу рендеринга, когда трехмерный мир точек, линий и треугольников становится двухмерной сеткой цветных блоков. Это во многом то, что просто «происходит», поскольку процессы, связанные с переходом от 3D к 2D, происходят незаметно, в отличие от нашей предыдущей статьи, где мы могли сразу увидеть эффекты вершинных шейдеров и тесселяции. Если вы не готовы ко всему этому, не беспокойтесь — вы можете начать работу с нашим рендерингом 3D-игр 101. Но как только вы настроитесь, прочитайте наш следующий взгляд на мир 3D-графики.
Но как только вы настроитесь, прочитайте наш следующий взгляд на мир 3D-графики.
Часть 0: Рендеринг 3D-игры 101
Объяснение создания графики
Часть 1. Рендеринг 3D-игры: обработка вершин
Более глубокое погружение в мир 3D-графики
Часть 2. Рендеринг 3D-игр: растеризация и трассировка лучей
От 3D к Flat 2D, POV и освещению
Часть 3. Рендеринг 3D-игры: текстурирование
Билинейная, трилинейная, анизотропная фильтрация, наложение рельефа, дополнительные функции
Часть 4. Рендеринг в 3D-игре: освещение и тени
Математика освещения, SSR, Ambient Occlusion, Shadow Mapping
Часть 5. Рендеринг 3D-игр: сглаживание
SSAA, MSAA, FXAA, TAA и другие
Подготовка к 2-мерному измерению
Подавляющее большинство из вас будет просматривать этот веб-сайт на абсолютно плоском мониторе или экране смартфона; даже если вы спокойно относитесь к детям и у вас причудливый изогнутый монитор, изображения, которые он отображает, состоят из плоской сетки цветных пикселей. И все же, когда вы играете в последнюю версию Call of Mario: Deathduty Battleyard, изображения кажутся трехмерными. Объекты перемещаются в окружающую среду и выходят из нее, становясь больше или меньше по мере движения к камере и от нее.
И все же, когда вы играете в последнюю версию Call of Mario: Deathduty Battleyard, изображения кажутся трехмерными. Объекты перемещаются в окружающую среду и выходят из нее, становясь больше или меньше по мере движения к камере и от нее.
Используя в качестве примера Fallout 4 от Bethesda 2014 года, мы можем легко увидеть, как вершины были обработаны для создания ощущения глубины и расстояния, особенно если запустить его в режиме каркаса (выше).
Если вы выберете любую 3D-игру сегодняшнего дня или последних двух десятилетий, почти каждая из них будет выполнять одну и ту же последовательность событий для преобразования 3D-мира вершин в 2D-массив пикселей. Имя процесса, выполняющего изменение, часто называют 9.3320 растеризация , но это всего лишь один из многих шагов во всей этой хитрости.
Нам нужно разбить некоторые этапы и изучить применяемые методы и математические расчеты, а для справки мы будем использовать последовательность, используемую Direct3D, чтобы выяснить, что происходит. На изображении ниже показано, что делается с каждой вершиной в мире:
На изображении ниже показано, что делается с каждой вершиной в мире:
Конвейер преобразования Direct3D
Мы видели, что было сделано на мировой космической сцене в нашей части 1 статьи: здесь вершины трансформируются и окрашиваются, с помощью многочисленных матричных вычислений. Мы пропустим следующий раздел, потому что все, что происходит с пространством камеры, это то, что преобразованные вершины корректируются после того, как они были перемещены, чтобы сделать камеру опорной точкой.
Следующие шаги слишком важны, чтобы их пропускать, потому что они абсолютно необходимы для перехода от 3D к 2D — если все сделано правильно, наш мозг будет смотреть на плоский экран, но «видеть» сцену с глубиной и масштаб — сделано неправильно, и все будет выглядеть очень странно!
Все дело в перспективе
Первый шаг в этой последовательности включает определение поля зрения, которое видит камера. Это делается путем установки углов для горизонтального и вертикального поля зрения — первый часто можно изменить в играх, поскольку у людей лучше боковое периферийное зрение по сравнению с верхним и нижним.
Мы можем получить представление об этом из этого изображения, показывающего поле зрения человека:
Источник: Zyxwv99 | Wikimedia Commons
Два угла поля зрения (сокращенно fov) определяют форму усеченной пирамиды — трехмерной пирамиды с квадратным основанием, исходящей из камеры. Первый угол соответствует по вертикали fov, второй — по горизонтали ; мы будем использовать символы α и β для их обозначения. Теперь мы не совсем видим мир таким образом, но в вычислительном отношении гораздо проще разработать усеченную пирамиду, чем пытаться создать реалистичный объемный вид.
Источник: MithrandirMage | Wikimedia Commons
Также необходимо определить две другие настройки — положение ближней (или передней) и дальней (задней) плоскостей отсечения . Первый срезает вершину пирамиды, но, по сути, определяет, насколько близко к положению камеры что-либо будет нарисовано; последний делает то же самое, но определяет, как далеко от камеры будут отображаться любые примитивы.
Размер и положение ближней плоскости отсечения важны, так как это становится тем, что называется видовой экран . По сути, это то, что вы видите на мониторе, то есть визуализированный кадр, и в большинстве графических API область просмотра «рисуется» из верхнего левого угла. На изображении ниже точка (a1, b2) будет началом плоскости, и отсюда измеряются ширина и высота плоскости.
Соотношение сторон области просмотра не только имеет решающее значение для того, как будет выглядеть визуализируемый мир, но и должно соответствовать соотношению сторон монитора. В течение многих лет это всегда было 4:3 (или 1,3333… как десятичное значение). Однако сегодня многие из нас играют с такими соотношениями сторон, как 16:9.или 21:9, он же широкоэкранный и сверхширокоэкранный.
Координаты каждой вершины в пространстве камеры необходимо преобразовать так, чтобы все они уместились на ближней плоскости отсечения, как показано ниже: )
Преобразование выполняется с использованием другой матрицы — эта конкретная называется матрицей перспективной проекции . В нашем примере ниже мы используем углы поля зрения и положения плоскостей отсечения для выполнения преобразования; вместо этого мы могли бы использовать размеры области просмотра.
В нашем примере ниже мы используем углы поля зрения и положения плоскостей отсечения для выполнения преобразования; вместо этого мы могли бы использовать размеры области просмотра.
Вектор положения вершины умножается на эту матрицу, что дает новый набор преобразованных координат.
И вуаля! Теперь у нас есть все наши вершины, написанные таким образом, что исходный мир теперь выглядит как вынужденная трехмерная перспектива, поэтому примитивы рядом с передней плоскостью отсечения кажутся больше, чем те, что ближе к дальней плоскости.
Хотя размер области просмотра и углы поля зрения связаны, их можно обрабатывать по отдельности — другими словами, вы можете установить усеченную пирамиду, чтобы получить ближнюю плоскость отсечения, которая отличается по размеру и соотношению сторон от окно просмотра. Для этого требуется дополнительный шаг в цепочке, где вершины в ближней плоскости отсечения необходимо снова преобразовать, чтобы учесть разницу.
Однако это может привести к искажению просматриваемой перспективы. Используя игру Skyrim от Bethesda 2011 года, мы можем увидеть, как регулировка горизонтального угла поля зрения β при сохранении того же соотношения сторон окна просмотра оказывает значительное влияние на сцену:
Используя игру Skyrim от Bethesda 2011 года, мы можем увидеть, как регулировка горизонтального угла поля зрения β при сохранении того же соотношения сторон окна просмотра оказывает значительное влияние на сцену:
На этом первом изображении мы установили β = 75°, и сцена кажется совершенно нормальной. Теперь давайте попробуем это с β = 120°:
Сразу бросаются в глаза два отличия — во-первых, теперь мы можем видеть гораздо больше по сторонам нашего «зрения», а во-вторых, объекты теперь кажутся намного дальше. (особенно деревья). Однако визуальный эффект водной глади сейчас не выглядит, и это потому, что процесс не был рассчитан на это поле зрения.
Теперь предположим, что у нашего персонажа глаза как у пришельца, и установим β = 180°!
Это поле зрения дает нам почти панорамную сцену, но ценой серьезного искажения объектов, визуализируемых по краям поля зрения. Опять же, это потому, что дизайнеры игр не планировали и не создавали игровые ресурсы и визуальные эффекты для этого угла обзора (значение по умолчанию составляет около 70 °).
На приведенных выше изображениях может показаться, что камера сдвинулась, но это не так. Все, что произошло, это то, что форма усеченного конуса была изменена, что, в свою очередь, изменило размеры ближней плоскости отсечения. В каждом изображении соотношение сторон области просмотра осталось прежним, поэтому к вершинам была применена матрица масштабирования, чтобы все снова подошло.
Итак, ты в игре или нет?
После того, как все было правильно преобразовано на этапе проецирования, мы переходим к тому, что называется пространством клипа . Хотя это делается после проекции , легче представить себе, что происходит, если мы сделаем это раньше:
иметь треугольники внутри усеченного конуса; однако другая летучая мышь, самое дальнее дерево и панда находятся за пределами усеченного конуса. Хотя вершины, составляющие эти объекты, уже обработаны, они не будут видны в окне просмотра. Это означает, что они получают вырезано .
В отсечении усеченной пирамиды любые примитивы за пределами усеченной пирамиды полностью удаляются, а те, которые лежат на любой из границ, преобразуются в новые примитивы. Отсечение на самом деле не сильно повышает производительность, так как до этого момента все невидимые вершины обрабатывались вершинными шейдерами и т. д. Саму стадию отсечения также можно пропустить, если это необходимо, но это поддерживается не всеми API (например, стандартный OpenGL не позволит вам пропустить его, тогда как это можно сделать с помощью расширения API) .
Стоит отметить, что положение дальней плоскости отсечения не обязательно совпадает с расстоянием прорисовки в играх, поскольку последнее контролируется самим игровым движком. Что-то еще, что будет делать движок, это отсечение усеченной пирамиды — здесь запускается код, чтобы определить, будет ли объект находиться внутри усеченной пирамиды и/или влиять на все, что будет видимым; если ответ нет , то этот объект не отправляется на рендеринг. Это не то же самое, что отсечение пирамиды видимости, так как хотя примитивы за пределами пирамиды отбрасываются, они все равно проходят стадию обработки вершин. При отбраковке они вообще не обрабатываются, что значительно экономит производительность.
Это не то же самое, что отсечение пирамиды видимости, так как хотя примитивы за пределами пирамиды отбрасываются, они все равно проходят стадию обработки вершин. При отбраковке они вообще не обрабатываются, что значительно экономит производительность.
Теперь, когда мы выполнили все наши преобразования и отсечения, кажется, что вершины, наконец, готовы к следующему этапу всей последовательности рендеринга. Но это не так. Это связано с тем, что все математические операции, выполняемые при обработке вершин и пространственных операциях мирового масштаба, должны выполняться с однородной системой координат (т. е. каждая вершина имеет 4 компонента, а не 3). Однако окно просмотра является полностью двумерным, поэтому API ожидает, что информация о вершинах будет иметь значения только для 9.3320 x, y (хотя значение глубины z сохраняется).
Чтобы избавиться от 4-го компонента, выполняется перспективное деление , где каждый компонент делится на значение w . Эта корректировка блокирует диапазон значений x и y , который может принимать до [-1,1], а z до диапазона [0,1] — они называются нормализованными координатами устройства (сокращенно NDC ).
Эта корректировка блокирует диапазон значений x и y , который может принимать до [-1,1], а z до диапазона [0,1] — они называются нормализованными координатами устройства (сокращенно NDC ).
Если вам нужна дополнительная информация о том, что мы только что рассмотрели, и вы рады углубиться в математику, прочитайте превосходный учебник Сон Хо Ана по этому вопросу. Теперь давайте превратим эти вершины в пиксели!
Освойте этот растр
Как и в случае с преобразованиями, мы остановимся на том, как Direct3D устанавливает правила и процессы для преобразования области просмотра в сетку пикселей. Эта сетка похожа на электронную таблицу со строками и столбцами, где каждая ячейка содержит несколько значений данных (таких как цвет, значения глубины, координаты текстуры и т. д.). Обычно эта сетка называется растром , а процесс ее создания известен как растеризация . В нашей статье о 3D-рендеринге 101 мы очень упростили процедуру:
На приведенном выше изображении создается впечатление, что примитивы просто разбиты на маленькие блоки, но это гораздо больше. Самый первый шаг — выяснить, действительно ли примитив обращен к камере — например, на изображении ранее в этой статье, которое показывает усеченный конус, примитивы, составляющие спину серого кролика, не будут быть видимым. Таким образом, хотя они будут присутствовать в окне просмотра, их не нужно рендерить.
Самый первый шаг — выяснить, действительно ли примитив обращен к камере — например, на изображении ранее в этой статье, которое показывает усеченный конус, примитивы, составляющие спину серого кролика, не будут быть видимым. Таким образом, хотя они будут присутствовать в окне просмотра, их не нужно рендерить.
Примерное представление о том, как это выглядит, можно получить на следующей диаграмме. Куб претерпел различные преобразования, чтобы поместить 3D-модель в 2D-пространство экрана, и с точки зрения камеры некоторые грани куба не видны. Если предположить, что ни одна из поверхностей не является прозрачной, то некоторые из этих примитивов можно игнорировать.
Слева направо: Мировое пространство > Пространство камеры > Пространство проекции > Пространство экрана удалить (также известный как cull ) лицевые или обратные стороны для каждого примитива (или вообще не отбрасывать — например, каркасный режим ). Но откуда он знает, что обращено вперед, а что назад? Когда мы посмотрели на математику при обработке вершин, мы увидели, что треугольники (или, скорее, случай вершин) имеют векторы нормалей, которые сообщают системе, в какую сторону она обращена. С помощью этой информации можно выполнить простую проверку, и если примитив не проходит проверку, он удаляется из цепочки рендеринга.
С помощью этой информации можно выполнить простую проверку, и если примитив не проходит проверку, он удаляется из цепочки рендеринга.
Теперь пришло время начать применять пиксельную сетку. Опять же, это удивительно сложно, потому что система должна определить, помещается ли пиксель внутри примитива — полностью, частично или совсем не помещается. Для этого выполняется процесс под названием тестирование покрытия . На изображении ниже показано, как треугольники растрируются в Direct3D 11:
Источник: документы Microsoft Direct3D
Правило довольно простое: считается, что пиксель находится внутри треугольника, если центр пикселя проходит то, что Microsoft называет «верхним левым». правило. «Верхняя» часть — это проверка горизонтальной линии; центр пикселя должен быть на этой линии. «Левая» часть предназначена для негоризонтальных линий, и центр пикселя должен располагаться слева от такой линии. Существуют дополнительные правила для непримитивов, то есть простых линий и точек, и правила получают дополнительные условия, если используется мультивыборка .
Если мы внимательно посмотрим на изображение из документации Microsoft, мы увидим, что формы, созданные пикселями, не очень похожи на исходные примитивы. Это связано с тем, что пиксели слишком велики для создания реалистичного треугольника — растр содержит недостаточно данных об исходных объектах, что приводит к проблеме, называемой 9.3320 псевдоним .
Давайте воспользуемся UL Benchmark’s 3DMark03, чтобы увидеть алиасинг в действии:
Растр установлен на 720 x 480 пикселей
На первом изображении растр был установлен на очень низкий размер 720 на 480 пикселей. Псевдонимы хорошо видны на перилах, а тень отбрасывает оружие, которое держит главный солдат. Сравните это с растровым изображением, имеющим в 24 раза больше пикселей:
Растр с размером 3840 x 2160 пикселей
Здесь мы видим, что алиасинг на перилах и тени полностью исчез. Больший растр кажется подходящим каждый раз, но размеры сетки должны поддерживаться монитором, на котором будет отображаться кадр, и, учитывая, что эти пиксели должны быть обработаны, после процесса растеризации происходит быть очевидным штрафом за производительность.
Здесь может помочь мультисэмплинг, и вот как он работает в Direct3D:
Источник: документы Microsoft Direct3D
Вместо того, чтобы просто проверять, соответствует ли центр пикселя правилам Вместо этого тестируются подвыборок ) в каждом пикселе, и если какой-либо из них в порядке, то весь этот пиксель образует часть формы. Может показаться, что это не имеет никакой пользы и, возможно, даже усугубляет алиасинг, но при использовании мультисэмплинга информация о том, какие подвыборки покрываются примитивом, и результаты обработки пикселей сохраняются в буфере в памяти.
Затем этот буфер используется для смешивания данных подвыборки и пикселей таким образом, чтобы края примитива были менее блочными. Мы еще раз рассмотрим всю ситуацию с алиасингом в одной из следующих статей, а пока вот что может сделать мультисэмплинг при использовании на растре с небольшим количеством пикселей:
различных форм значительно сократилось. Большой растр, безусловно, лучше, но снижение производительности может способствовать использованию вместо этого мультисэмплинга.
Что-то еще, что можно сделать в процессе растеризации, это тестирование окклюзии . Это необходимо сделать, потому что окно просмотра будет заполнено примитивами, которые будут перекрываться ( occluded ) — например, на изображении выше треугольники, обращенные вперед, которые составляют солидер на переднем плане, перекрывают те же треугольники на переднем плане. другой солдат. Помимо проверки того, покрывает ли примитив пиксель, можно также сравнить относительные глубины, и если один отстает от другого, то его можно пропустить из остального процесса рендеринга.
Однако, если ближний примитив прозрачен, то дальний по-прежнему будет виден, даже если он не прошел проверку окклюзии. Вот почему почти все 3D-движки выполняют проверку окклюзии до того, как отправят что-либо в графический процессор, и вместо этого создают что-то, называемое z-буфером , как часть процесса рендеринга. Здесь кадр создается как обычно, но вместо того, чтобы сохранять в памяти окончательные цвета пикселей, графический процессор сохраняет только значения глубины. Затем это можно использовать в шейдерах для проверки видимости с большим контролем и точностью над аспектами, связанными с перекрытием объектов.
Затем это можно использовать в шейдерах для проверки видимости с большим контролем и точностью над аспектами, связанными с перекрытием объектов.
Источник: -Зевс- | Wikimedia Commons
На приведенном выше изображении чем темнее цвет пикселя, тем ближе этот объект к камере. Кадр рендерится один раз, чтобы создать z-буфер, затем рендерится снова, но на этот раз, когда пиксели обрабатываются, запускается шейдер, чтобы сравнить их со значениями в z-буфере. Если он не виден, то этот цвет пикселя не помещается в окончательный буфер кадра.
На данный момент основной заключительный шаг — выполнить интерполяцию атрибутов вершин — на нашей первоначальной упрощенной диаграмме примитивом был полный треугольник, но не забывайте, что окно просмотра заполнено только углами фигур, а не самой фигурой. Таким образом, система должна определить цвет, глубину и текстуру примитива между вершинами, и это называется интерполяцией . Как вы понимаете, это еще один расчет, и тоже не простой.
Несмотря на то, что растровый экран является 2D, структуры внутри него представляют принудительную 3D перспективу. Если бы линии были действительно двумерными, то мы могли бы использовать простой линейное уравнение для определения различных цветов и т. д. по мере перехода от одной вершины к другой. Но из-за трехмерного аспекта сцены интерполяция должна учитывать перспективу — прочитайте превосходный блог Саймона Юнга на эту тему, чтобы получить больше информации о процессе.
Итак, вот как трехмерный мир вершин становится двухмерной сеткой цветных блоков. Мы еще не совсем закончили.
Все наоборот (за исключением случаев, когда это не так)
Прежде чем мы закончим рассмотрение растеризации, нам нужно сказать кое-что о порядке последовательности рендеринга. Мы не говорим о том, где, например, тесселяция появляется в последовательности; вместо этого мы имеем в виду порядок обработки примитивов. Объекты обычно обрабатываются в том порядке, в котором они появляются в индексном буфере (блоке памяти, который сообщает системе, как вершины сгруппированы вместе), и это может иметь значительное влияние на то, как обрабатываются прозрачные объекты и эффекты.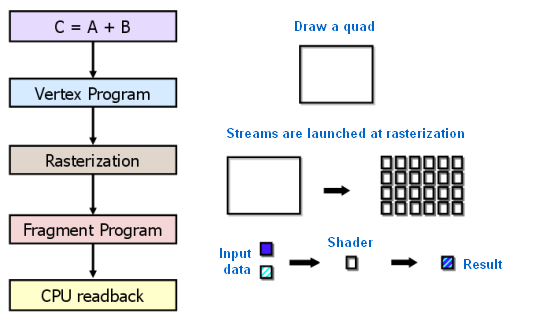
Причина этого в том, что примитивы обрабатываются по одному, и если вы сначала визуализируете те, что находятся впереди, то ни один из тех, что позади них, не будет виден (вот где отсечение окклюзии действительно вступает в силу play) и может быть исключен из процесса (помогая производительности) — это обычно называется « рендерингом вперед-назад» и требует, чтобы индексный буфер был упорядочен таким образом.
Однако, если некоторые из этих примитивов прямо перед камерой прозрачны, то рендеринг спереди назад приведет к тому, что объекты позади прозрачного будут пропущены. Одним из решений является рендеринг всего в обратном порядке, а прозрачные примитивы и эффекты выполняются в последнюю очередь.
Слева направо: порядок сцен, рендеринг спереди назад, рендеринг сзади наперед
Итак, все современные игры делают рендеринг сзади наперед, да? Нет, если это может помочь — не забывайте, что рендеринг каждого отдельного примитива будет иметь гораздо большие затраты производительности по сравнению с рендерингом только тех, которые можно увидеть. Существуют и другие способы обработки прозрачных объектов, но, вообще говоря, универсального решения не существует, и каждая ситуация должна обрабатываться уникальным образом.
Существуют и другие способы обработки прозрачных объектов, но, вообще говоря, универсального решения не существует, и каждая ситуация должна обрабатываться уникальным образом.
Это, по сути, суммирует плюсы и минусы растеризации — на современном оборудовании это действительно быстро и эффективно, но это все еще приблизительное представление о том, что мы видим. В реальном мире каждый объект будет поглощать, отражать и, возможно, преломлять свет, и все это влияет на просматриваемую сцену. Разделив мир на примитивы, а затем прорисовав только некоторые из них, мы получим быстрый, но грубый результат.
Если бы только был другой способ…
Там
есть другой путь: Трассировка лучей Почти пять десятилетий назад ученый-компьютерщик по имени Артур Аппель разработал систему рендеринга изображений на компьютере, при которой один луч света направлялся по прямой линии от камеры до тех пор, пока не попадал на объект. Оттуда свойства материала (его цвет, отражательная способность и т. д.) будут затем изменять интенсивность светового луча. Каждый пиксель в визуализируемом изображении будет иметь один луч, и будет выполняться алгоритм, выполняющий последовательность математических операций для определения цвета пикселя. Процесс Аппеля стал известен как raycasting.
д.) будут затем изменять интенсивность светового луча. Каждый пиксель в визуализируемом изображении будет иметь один луч, и будет выполняться алгоритм, выполняющий последовательность математических операций для определения цвета пикселя. Процесс Аппеля стал известен как raycasting.
Примерно 10 лет спустя другой ученый по имени Джон Уиттед разработал математический алгоритм, который делал то же самое, что и подход Аппеля, но когда луч попадал на объект, он затем генерировал дополнительные лучи, которые распространялись в разных направлениях в зависимости от материала объекта. . Поскольку эта система генерировала новые лучи для каждого взаимодействия с объектом, алгоритм был рекурсивным по своей природе и поэтому был намного сложнее в вычислительном отношении; однако у него было значительное преимущество перед методом Аппеля, поскольку он мог правильно учитывать отражения, преломление и затенение. Название этой процедуры было трассировка лучей (строго говоря, это обратная трассировка лучей , поскольку мы следим за лучом от камеры, а не от объектов) и с тех пор это святой Грааль для компьютерной графики и кино.
Эта процедура называлась трассировкой лучей (строго говоря, обратной трассировкой лучей, поскольку мы следуем за лучом от камеры, а не от объектов), и с тех пор она стала святым Граалем для компьютерной графики и кино.
На изображении выше мы можем получить представление о работе алгоритма Уиттеда. Один луч испускается камерой для каждого пикселя в кадре и движется, пока не достигнет поверхности. Эта конкретная поверхность полупрозрачна, поэтому свет будет отражаться и преломляться через нее. В обоих случаях генерируются вторичные лучи, которые проходят до тех пор, пока не взаимодействуют с поверхностью. Также генерируются дополнительные вторичные, учитывающие цвет источников света и создаваемые ими тени.
Рекурсивная часть процесса заключается в том, что вторичные лучи могут генерироваться каждый раз, когда новый луч пересекает поверхность. Это может легко выйти из-под контроля, поэтому количество генерируемых вторичных лучей всегда ограничено. После завершения пути луча вычисляется его цвет в каждой конечной точке на основе свойств материала этой поверхности. Затем это значение передается вниз по лучу к предыдущему, корректируя цвет этой поверхности и так далее, пока мы не достигнем эффективной начальной точки первичного луча: пикселя в кадре.
Затем это значение передается вниз по лучу к предыдущему, корректируя цвет этой поверхности и так далее, пока мы не достигнем эффективной начальной точки первичного луча: пикселя в кадре.
Это может быть очень сложно, и даже простые сценарии могут привести к большому количеству вычислений. К счастью, кое-что можно сделать, чтобы помочь — например, использовать аппаратное обеспечение, специально предназначенное для ускорения этих конкретных математических операций, точно так же, как это делается для матричных вычислений при обработке вершин (подробнее об этом чуть позже). ). Еще один критический момент — попытаться ускорить процесс, выполняемый для определения того, в какой объект попадает луч и где именно на поверхности объекта происходит пересечение — если объект состоит из большого количества треугольников, это может быть неожиданно. трудно сделать:
Источник: трассировка лучей в реальном времени с Nvidia RTX
Вместо того, чтобы тестировать каждый отдельный треугольник, в каждом отдельном объекте перед трассировкой лучей создается список ограничивающих объемов (BV) — это не что иное, как кубоиды, которые окружает рассматриваемый объект, последовательно генерируя меньшие для различных структур внутри объекта.
Например, первый BV будет для всего кролика. Следующая пара покрывала ему голову, ноги, туловище, хвост и т. д.; каждый из них затем будет другим набором томов для меньших структур в голове и т. д., с последним уровнем томов, содержащим небольшое количество треугольников для тестирования. Затем все эти тома упорядочиваются в упорядоченный список (называемый BV иерархия или BVH для краткости), так что система каждый раз проверяет относительно небольшое количество BV:
Хотя использование BVH технически не ускоряет реальную трассировку лучей, последующий необходимый алгоритм поиска, как правило, намного быстрее, чем необходимость проверять, пересекается ли один луч с одним из миллионов треугольников в трехмерном мире.
Сегодня такие программы, как Blender и POV-ray, используют трассировку лучей с дополнительными алгоритмами (такими как трассировка фотонов и радиосити) для создания высокореалистичных изображений:
Источник: Жиль Тран | Wikimedia Commons
Возникает очевидный вопрос: если трассировка лучей так хороша, почему мы не используем ее повсеместно? Ответы лежат в двух областях: во-первых, даже простая трассировка лучей генерирует миллионы лучей, которые приходится вычислять снова и снова. Система начинает с одного луча на пиксель экрана, поэтому при разрешении всего 800 x 600 генерируется 480 000 первичных лучей, а затем каждый из них генерирует несколько вторичных лучей. Это очень тяжелая работа даже для современных настольных ПК. Вторая проблема заключается в том, что базовая трассировка лучей на самом деле не очень реалистична и что для правильной реализации необходимо включить целый ряд дополнительных, очень сложных уравнений.
Система начинает с одного луча на пиксель экрана, поэтому при разрешении всего 800 x 600 генерируется 480 000 первичных лучей, а затем каждый из них генерирует несколько вторичных лучей. Это очень тяжелая работа даже для современных настольных ПК. Вторая проблема заключается в том, что базовая трассировка лучей на самом деле не очень реалистична и что для правильной реализации необходимо включить целый ряд дополнительных, очень сложных уравнений.
Даже с современным аппаратным обеспечением ПК требуемый объем работы выходит за рамки возможного, чтобы сделать это в режиме реального времени для текущей 3D-игры. В нашей статье о 3D-рендеринге 101 мы увидели в тесте трассировки лучей, что на создание одного изображения с низким разрешением уходят десятки секунд.
Так как же оригинальный Wolfenstein 3D выполнял трассировку лучей еще в 1992 году, и почему такие игры, как Battlefield V и Metro Exodus, выпущенные в 2019 году, предлагают возможности трассировки лучей? Они занимаются растеризацией или трассировкой лучей? Ответ: немного того и другого.
Гибридный подход для настоящего и будущего
В марте 2018 года Microsoft объявила о новом расширении API для Direct3D 12 под названием DXR (DirectX Raytracing). Это был новый графический конвейер, дополняющий стандартные конвейеры растеризации и вычислений. Дополнительная функциональность была обеспечена за счет введения шейдеров, структур данных и т. д., но не требовала какой-либо конкретной аппаратной поддержки, кроме той, которая уже требовалась для Direct3D 12.
На той же конференции разработчиков игр, где Microsoft говорила о DXR, Electronic Arts рассказала о своем проекте Pica Pica — эксперименте с 3D-движком, в котором использовался DXR. Они показали, что трассировку лучей можно использовать, но не для полного кадра рендеринга. Вместо этого для большей части работы будут использоваться традиционные методы растеризации и вычислительных шейдеров, а DXR будет использоваться для определенных областей — это означает, что количество генерируемых лучей намного меньше, чем для всей сцены.
Этот гибридный подход использовался в прошлом, хотя и в меньшей степени. Например, в Wolfenstein 3D для определения того, как будет выглядеть визуализированный кадр, использовалось литье лучей, хотя это делалось с одним лучом на столбец пикселей, а не на пиксель. Это все еще может показаться очень впечатляющим, пока вы не поймете, что игра изначально работала с разрешением 640 x 480, поэтому одновременно работало не более 640 лучей.
Видеокарта начала 2018 года — например, AMD Radeon RX 580 или Nvidia GeForce 1080 Ti — определенно соответствовала аппаратным требованиям для DXR, но даже с их вычислительными возможностями были некоторые опасения, что они будут достаточно мощными, чтобы на самом деле использовать DXR любым осмысленным образом.
Это несколько изменилось в августе 2018 года, когда Nvidia представила свою новейшую архитектуру GPU под кодовым названием Turing. Важнейшей особенностью этого чипа было введение так называемых ядер RT: выделенных логических блоков для ускорения вычислений пересечения лучей и треугольников и обхода иерархии ограничивающих объемов (BVH). Эти два процесса требуют много времени для определения того, где свет взаимодействует с треугольниками, из которых состоят различные объекты в сцене. Учитывая, что ядра RT были уникальными для процессора Turing, доступ к ним можно было осуществить только через проприетарный API Nvidia.
Эти два процесса требуют много времени для определения того, где свет взаимодействует с треугольниками, из которых состоят различные объекты в сцене. Учитывая, что ядра RT были уникальными для процессора Turing, доступ к ним можно было осуществить только через проприетарный API Nvidia.
Первой игрой, которая поддерживала эту функцию, была Battlefield V от EA, и когда мы тестировали использование DXR, нас впечатлило улучшение отражений воды, стекла и металла в игре, но в меньшей степени из-за последующего падения производительности:
Справедливости ради следует отметить, что более поздние патчи несколько улучшили ситуацию, но было (и остается) значительное падение скорости рендеринга кадров. К 2019 году появились некоторые другие игры, которые поддерживали этот API, выполняя трассировку лучей для определенных частей внутри кадра. Мы протестировали Metro Exodus и Shadow of the Tomb Raider и обнаружили похожую историю — там, где он использовался интенсивно, DXR заметно влиял на частоту кадров.
Примерно в то же время UL Benchmarks объявила о тестировании функций DXR для 3DMark:
DXR при использовании на графической карте Nvidia Titan X (Pascal) — да, на протяжении
действительно было 8 кадров в секунду. Изучение игр с поддержкой DXR и тест функций 3DMark доказали, что в отношении трассировки лучей можно с уверенностью сказать: в 2019 году для графического процессора все еще очень тяжелая работа, даже для моделей стоимостью более 1000 долларов. Значит ли это, что у нас нет реальной альтернативы растеризации?
Передовые функции потребительской технологии 3D-графики часто очень дороги, а первоначальная поддержка новых возможностей API может быть довольно неоднородной или медленной (как мы обнаружили, тестируя Max Payne 3 в различных версиях Direct3D примерно в 2012 году) — последнее обычно происходит из-за того, что разработчики игр пытаются включить как можно больше расширенных функций, иногда с ограниченным опытом их использования.
Но если раньше требовались вершинные и пиксельные шейдеры, тесселяция, HDR-рендеринг и окклюзия окружающего пространства на экране, подходящие только для топовых графических процессоров, то теперь их использование стало обычным явлением в играх и поддерживается широким спектром видеокарт. То же самое относится и к трассировке лучей, и со временем она станет еще одним параметром детализации, который будет включен по умолчанию для большинства пользователей.
То же самое относится и к трассировке лучей, и со временем она станет еще одним параметром детализации, который будет включен по умолчанию для большинства пользователей.
Несколько заключительных мыслей
Итак, мы подошли к концу нашего второго глубокого погружения, в ходе которого мы глубже заглянули в мир 3D-графики. Мы рассмотрели, как вершины моделей и миров смещаются из 3-х измерений и трансформируются в плоское 2D-изображение. Мы увидели, как нужно учитывать настройки поля зрения и какой эффект они производят. Мы исследовали процесс превращения этих вершин в пиксели и закончили кратким рассмотрением процесса, альтернативного растеризации.
Как и прежде, мы не могли охватить все и упустить некоторые детали здесь и там — ведь это не учебник! Но мы надеемся, что за это время вы приобрели немного больше знаний и по-новому восхитились программистами и инженерами, которые действительно овладели математикой и наукой, необходимыми для реализации всего этого в ваших любимых 3D-играх.
Мы будем более чем рады ответить на любые ваши вопросы, поэтому не стесняйтесь присылать их нам в разделе комментариев. До следующего.
Читайте также
- Объяснение Wi-Fi 6: следующее поколение Wi-Fi
- И действуй! Экзамен по физике в видеоиграх Сравнение технологий отображения
- : TN, VA и IPS
Титульный заголовок: Монохромная печать растрового реферата Алексея Дерина
На нашем форуме каждый день десятки людей спрашивают совета по самостоятельной модернизации, в чем мы охотно им помогаем. Ежедневно «оценивая сборку» и проверяя выбранные нашими клиентами комплектующие на совместимость, мы стали замечать, что пользователи в основном обращают внимание на другие, бесспорно, важные комплектующие. И редко кто помнит, что при апгрейде компьютера обязательно нужно обновить не менее важную деталь — . «…хочу обновить комп, все летало, купил проц i7-3970X и материнку ASRock X79 Extreme6, плюс видяху RADEON HD 7990 6GB. Что еще нан???? 777 « — примерно так начинается примерно половина всех сообщений, связанных с обновлением стационарного компьютера. Исходя из своего или семейного бюджета, пользователи стараются выбрать самые, самые шустрые и красивые модули памяти. При этом наивно полагая, что их старые 450Вт справятся и с прожорливой видеокартой, и с «горячим» процессором при разгоне одновременно. Со своей стороны мы уже не раз писали о важности блока питания — но, признаемся, наверное, недостаточно ясно. Поэтому сегодня мы исправились, и подготовили для вас памятку о том, что будет, если вы забудете об этом при апгрейде ПК — с картинками и подробными описаниями. Итак, мы решили обновить конфигурацию…Для нашего эксперимента мы решили взять совершенно новый средний компьютер и проапгрейдить его до уровня «игрового автомата». Конфигурацию сильно менять не придется — достаточно поменять память и видеокарту, чтобы мы имели возможность играть в более-менее современные игры с приличными настройками детализации. Начальная конфигурация нашего компьютера выглядит следующим образом:Блок питания: ATX 12V 400W Понятно, что для игр такая конфигурация, мягко говоря, слабовата. Так что пора что-то менять! Начнем с того же, с чего начинают большинство жаждущих «апгрейда» — с. Материнскую плату менять не будем — пока она нас устраивает. Так как материнку решили не трогать, то выберем совместимый сокет FM2 (благо, для этого на сайте НИКС на странице описания материнки есть специальная кнопка). Не будем жадничать — возьмем доступный, но быстрый и мощный процессор с частотой 4,1 ГГц (до 4,4 ГГц в режиме Turbo CORE) и разблокированным множителем — мы тоже любим «разгонять», ничто человеческое нам не чуждо. Вот характеристики выбранного нами процессора:
Одна планка на 4 ГБ — не наш выбор. Во-первых, мы хотим 16Гб, а во-вторых, нам нужно использовать двухканальный режим работы, для чего мы установим в наш компьютер два модуля памяти емкостью 8Гб каждый. Высокая пропускная способность, отсутствие радиаторов и достойная цена делают их самым «вкусным» выбором для нас. Кроме того, с сайта AMD можно скачать программу Radeon RAMDisk, которая позволит нам бесплатно, абсолютно бесплатно создать сверхбыстрый виртуальный диск объемом до 6 ГБ — а бесплатные полезные вещи любят все.
Комфортно проигрывать встроенное видео можно только как «сапер». Стала с 2гб видеопамяти, поддержкой DirectX 11 и OpenGL 4.x. и превосходная система охлаждения Twin Frozr IV. Его производительности должно быть более чем достаточно, чтобы мы могли наслаждаться последними частями самых популярных игровых франшиз, таких как Tomb Raider, Crysis, Hitman и Far Cry. Характеристики избранника следующие:
Неожиданные трудности Теперь у нас есть все необходимое для обновления нашего компьютера. Запускаем — а он не работает. И почему? А потому, что бюджетные блоки питания физически не способны хоть сколько-нибудь запустить компьютер. Дело в том, что в нашем случае для питания требуется два 8-контактных разъема, а блок питания имеет только один 6-контактный разъем питания видеокарты «в базе». Учитывая, что многим нужно еще больше разъемов, чем в нашем случае, становится понятно, что блок питания нужно менять. Но это не так уж и плохо. Только подумайте, разъема питания нет! В нашей тестовой лаборатории были обнаружены довольно редкие переходники с 6-pin на 8-pin и с molex на 6-pin. Вот такие: Стоит отметить, что даже на бюджетных современных блоках питания с каждым новым выпуском разъемов Molex разъемов Molex становится все меньше — так что можно сказать, что нам повезло. На первый взгляд все хорошо, и с помощью некоторых ухищрений мы смогли обновить системный блок до «игровой» конфигурации. Выход есть!Они отплыли. Мы купили дорогие комплектующие для сборки игрового компьютера, но оказалось, что играть на нем невозможно. Это позор. Вывод всем ясен: старый не подходит для нашего игрового компьютера, и его срочно нужно заменить на новый. Но какой? Для нашего модернизированного компьютера мы выбирали по четырем основным критериям: Первое это, конечно, мощность. Мы предпочли выбрать с запасом — хотелось бы еще и разогнать процессор и набрать баллы в синтетических тестах. Второй критерий — надежность … Очень хочется, чтобы тот, что взят «с запасом», пережил следующее поколение видеокарт и процессоров, не сгорел сам и при этом не спалил дорогие комплектующие( вместе с испытательным полигоном). Поэтому наш выбор — только японские конденсаторы, только защита от короткого замыкания и надежная защита от перегрузки по любому из выходов. Третий пункт наших требований — удобство и функциональность. … Начнем с того, что нам нужно — компьютер будет работать часто, а особо шумные блоки питания вкупе с видеокартой и процессорным кулером сведут с ума любого пользователя. Кроме того, нам не чуждо чувство прекрасного, поэтому новый блок питания для нашего игрового компьютера должен быть модульным и иметь разъемные кабели и разъемы. Чтобы не было ничего лишнего. И последнее, но не менее важное: критерий энергоэффективности . Сравнив и проанализировав все требования, мы выбрали среди немногих претендентов, которые полностью удовлетворяли всем нашим требованиям. Он стал мощностью 850 Вт. Отметим, что по ряду параметров он даже превзошел наши требования. Посмотрим его спецификацию:
, один из лучших за эти деньги. Установим его в наш корпус: Потом произошло то, что нас немного смутило. Казалось бы, все собрано правильно, все подключено, все работает — но блок питания молчит! То есть в общем: вентилятор пока стоит на месте, а система исправно запущена и функционирует. Дело в том, что при нагрузке до 50% блок питания работает в так называемом тихом режиме — без раскручивания вентилятора охлаждения. Вентилятор будет гудеть только при большой нагрузке — одновременный запуск архиваторов и Furmark заставлял кулер раскручиваться. Блок питания имеет целых шесть 8-контактных 6-контактных разъемов питания видеокарты, каждый из которых является разборным 8-контактным разъемом, от которого при необходимости можно отстегнуть 2 контакта. Таким образом, он способен питать любую видеокарту без лишних хлопот и сложностей. И даже не один. Модульная система питания позволяет отсоединять лишние и ненужные силовые кабели, что улучшает обдув корпуса, стабильность работы системы и, конечно же, эстетически улучшает вид внутреннего пространства, что позволяет смело рекомендовать мододелы и любители корпусов с окнами. купить надежный и мощный блок питания. В нашем обзоре так и стало. — и, как видите, не случайно. Приобретая такой у НИКС, вы можете быть уверены, что все компоненты вашей высокопроизводительной системы будут обеспечены достаточным и бесперебойным питанием даже при экстремальном разгоне. К тому же, блока питания хватит на несколько лет вперед — лучше с запасом, на случай, если в будущем вы собираетесь обновлять систему компонентами высокого уровня. |
Растеризация | Cortex XSOAR
Эта интеграция является частью пакета
Rasterize Pack.#Преобразует URL-адреса, файлы PDF и сообщения электронной почты в файл изображения или файл PDF.
Рекомендации по безопасности Docker #
Если вы используете интеграцию для растеризации ненадежных URL-адресов или HTML-содержимого, например, полученного из внешних электронных писем, мы рекомендуем следовать инструкциям в разделе «Укрепление сети Docker» в разделе «Блокировка доступа к внутренней сети».
Настройка растеризации на Cortex XSOAR#
- Перейдите к Настройки > Интеграции > Серверы и службы .
- Поиск растеризации.
- Нажмите Добавить экземпляр , чтобы создать и настроить новый экземпляр интеграции.
| Параметр | Описание | Обязательно |
|---|---|---|
| Ошибки возврата. | False | |
| wait_time | Время ожидания перед созданием снимка экрана (в секундах). | False |
| max_page_load_time | Максимальное время ожидания загрузки страницы (в секундах). | False |
| chrome_options | Параметры Chrome (Дополнительно. См. Примечания по настройке .) | False |
| Использовать настройки прокси-сервера 94. 3 | False | |
| rasterize_mode | Режим растеризации. (См. Примечания к конфигурации .) | Ложь |
- Нажмите Проверить , чтобы проверить URL-адреса, токен и подключение.
Примечания к конфигурации:
- Возврат ошибок: Если этот флажок не установлен, вместо ошибки будет возвращено предупреждение.
- Параметры Chrome: разделенный запятыми список параметров Chrome, которые можно добавить или удалить для растеризации. Используйте для расширенного устранения неполадок. Если значение содержит запятую (например, при установке значения пользовательского агента), экранируйте его с помощью обратной косой черты ( \ ) символ. Чтобы удалить используемый по умолчанию параметр, поместите его в квадратные скобки. Например, чтобы добавить параметр —disable-auto-reload и удалить параметр —disable-dev-shm-usage , установите следующее значение:
- Режим растеризации.
 через Chrome WebDriver или Chrome Headless CLI. WebDriver поддерживает больше параметров, чем Headless CLI. Например, поддержка опции
через Chrome WebDriver или Chrome Headless CLI. WebDriver поддерживает больше параметров, чем Headless CLI. Например, поддержка опции offlineвrasterize-emails 9Команда 4559. Есть некоторые URL-адреса, которые плохо растеризуются с помощью WebDriver и могут быть успешно обработаны с помощью Headless CLI. Таким образом, рекомендуется использовать режимWebDriver — Preferred, который будет использовать WebDriver в качестве запуска и отката к Headless CLI в случае сбоя. - Использовать настройки прокси системы: Установите этот флажок, чтобы использовать настройки прокси системы. Важно : эта интеграция не поддерживает прокси-серверы, требующие аутентификации.
Commands#
Вы можете выполнять эти команды из Cortex XSOAR CLI, как часть автоматизации или в playbook. После успешного выполнения команды в War Room появится сообщение DBot с подробностями команды.
rasterize#
Преобразует содержимое URL-адреса в файл изображения или файл PDF.
Base Command#
rasterize
Input#
| Argument Name | Description | Required |
|---|---|---|
| wait_time | Time to wait before taking a screenshot ( в секундах). | Дополнительно |
| max_page_load_time | Максимальное время ожидания загрузки страницы (в секундах). | Дополнительно |
| url | URL для растрирования. Должен быть полный URL, включая префикс http. | Обязательно |
| ширина | Ширина страницы, например, 1024 пикселей. Укажите с суффиксом px или без него. | Дополнительно |
| высота | Высота страницы, например, 800 пикселей. Укажите с суффиксом px или без него. | Дополнительно |
| type | Тип файла, в который нужно преобразовать содержимое URL-адреса. Может быть "pdf" или "png". По умолчанию "png". | Дополнительно |
| имя_файла | Имя, под которым будет сохранен файл. По умолчанию "URL". | Опционально |
| full_screen | Получить полную страницу. Фактическая ширина и высота страницы будут автоматически рассчитаны до максимального значения 8000 пикселей. (Пометка full_screen как true означает, что значения аргументов ширины и высоты могут не учитываться). | Дополнительно |
| режим | Режим растеризации для использования (WebDriver или Headless CLI). Если не указано, будет использоваться в соответствии с настройками экземпляра интеграции. | Optional |
Context Output#
| Path | Type | Description |
|---|---|---|
| InfoFile.Name | string | File name. |
| InfoFile.EntryID | строка | Идентификатор записи файла. |
| InfoFile.Size | номер | Размер файла. |
| InfoFile.Type | string | Тип файла, например, "PE" |
| InfoFile.Info | string | Основная информация о файле |
| InfoFile.Extension | строка | Расширение файла. |
Пример команды №
!rasterize url=http://google.com
Пример контекста#
Удобочитаемый вывод#
!image
rasterize-email#
PDF-файл.
Базовая команда №
Растило-эмала
Вход#
| Аргумент | Описание | Описание | .4529| htmlBody | Текст электронной почты в формате HTML. | Обязательно | ширина | Ширина HTML-страницы, например, 600 пикселей. Укажите с суффиксом px или без него. | Дополнительно | высота | Высота страницы HTML, например, 800 пикселей. Укажите с суффиксом px или без него. | Необязательный | type | Тип файла, в который нужно преобразовать тело сообщения электронной почты. Может быть "pdf" или "png". По умолчанию "png". | Необязательный | офлайн | При значении "true" вся исходящая связь будет заблокирована. | Дополнительно | имя_файла | Имя, под которым будет сохранен файл. По умолчанию "электронная почта". | Опционально | full_screen | Получить полную страницу. Фактическая ширина и высота страницы будут автоматически рассчитаны до максимального значения 8000 пикселей. (Пометка full_screen как true означает, что значения аргументов ширины и высоты могут не учитываться). | Дополнительно | режим | Режим растеризации для использования (WebDriver или Headless CLI). Если не указано, будет использоваться в соответствии с настройками экземпляра интеграции. | Optional | |
|---|
Context Output#
| Path | Type | Description |
|---|---|---|
| InfoFile.Name | string | File name. |
| InfoFile.EntryID | строка | Идентификатор записи файла. |
| InfoFile.Size | номер | Размер файла. |
| InfoFile.Type | string | Тип файла, например, "PE" |
| InfoFile.Info | string | Основная информация о файле |
| InfoFile.Extension | строка | Расширение файла. |
Пример команды №
!rasterize-email htmlBody="< body>
---------- ТЕСТ-ФАЙЛ ----------