
Способы тестирования программного обеспечения / OTUS. Онлайн-образование corporate blog / Habr
Всем привет! Уже на следующей неделе мы запускаем новый поток по курсу «Автоматизация веб-тестирования». Этому и будет посвящен сегодняшний материал.В этой статье рассматриваются различные способы тестирования программного обеспечения, такие как модульное тестирование (unit testing), интеграционное тестирование (integration testing), функциональное тестирование (functional testing), приемочное тестирование (acceptance testing) и т.д.
Есть множество разных типов тестов, которые вы можете применить, чтобы убедиться, что изменения в вашем коде работают по сценарию. Не все типы тестирования идентичны, хотя здесь мы рассмотрим, насколько основные практики тестирования отличаются друг от друга.
Тестирование: ручное или автоматизированное?
Сначала надо понять различия между ручными и автоматизированными тестами. Ручное тестирование проводится непосредственно человеком, который нажимает на кнопочки в приложении или взаимодействует с программным обеспечением или API с необходимым инструментарием. Это достаточно затратно, так как это требует от тестировщика установки среды разработки и выполнения тестов вручную. Имеет место вероятность ошибки за счет человеческого фактора, например опечатки или пропуска шагов в тестовом сценарии.
Автоматизированные тесты, с другой стороны, производятся машиной, которая запускает тестовый сценарий, который был написан заранее. Такие тесты могут сильно варьироваться в зависимости от сложности, начиная от проверки одного единственного метода в классе до отработки последовательности сложных действий в UI, чтобы убедиться в правильности работы. Такой способ считается более надежным, однако его работоспособность все еще зависит от того насколько скрипт для тестирования был хорошо написан.
Автоматизированные тесты – это ключевой компонент непрерывной интеграции (Continuous Integration) и непрерывной доставки (continuous delivery), а также хороший способ масштабировать ваш QA процесс во время добавления нового функционала для вашего приложения. Однако в ручном тестировании все равно есть своя ценность. Поэтому в статье мы обязательно поговорим об исследовательском тестировании (exploratory testing).
Различные типы тестов
Модульные тесты
Модульные тесты считаются низкоуровневыми, близкими к исходному коду вашего приложения. Они нацелены на тестирование отдельных методов и функций внутри классов, тестирование компонентов и модулей, используемых вашей программой. Модульные тесты в целом не требуют особых затрат на автоматизацию и могут отрабатывать крайне быстро, если задействовать сервер непрерывной интеграции (continuous integration server).
Интеграционные тесты
Интеграционные тесты проверяют хорошо ли работают вместе сервисы и модули, используемые вашим приложением. Например, они могут тестировать интеграцию с базой данных или удостоверяться, что микросервисы правильно взаимодействуют друг с другом. Эти тесты запускаются с бОльшими затратами, поскольку им необходимо, чтобы много частей приложения работало одновременно.
Функциональные тесты
Функциональные тесты основываются на требованиях бизнеса к приложению. Они лишь проверяют выходные данные после произведенного действия и не проверяют промежуточные состояния системы во время воспроизведения действия.
Иногда между интеграционными тестами и функциональными тестами возникают противоречия, т.к. они оба запрашивают множество компонентов, взаимодействующих друг с другом. Разница состоит в том, что интеграционные тесты могут просто удостовериться, что доступ к базе данных имеется, тогда как функциональный тест захочет получить из базы данных определенное значение, чтобы проверить одно из требований к конечному продукту.
Сквозные тесты (End-to-end tests)
Сквозное тестирование имитирует поведение пользователя при взаимодействии с программным обеспечением. Он проверяет насколько точно различные пользователи следуют предполагаемому сценарию работы приложения и могут быть достаточно простыми, допустим, выглядеть как загрузка веб-страницы или вход на сайт или в более сложном случае – подтверждение e-mail адреса, онлайн платежи и т.д.
Сквозные тесты крайне полезные, но производить их затратно, а еще их может быть сложно автоматизировать. Рекомендуется проводить несколько сквозных тестов, но все же полагаться больше на низкоуровневое тестирование (модульные и интеграционные тесты), чтобы иметь возможность быстро распознать серьезные изменения.
Приемочное тестирование
Приемочные тесты – это формальные тесты, которые проводятся, чтобы удостовериться, что система отвечает бизнес-запросам. Они требуют, чтобы приложение запускалось и работало, и имитируют действия пользователя. Приемочное тестирование может пойти дальше и измерить производительность системы и отклонить последние изменения, если конечные цели разработки не были достигнуты.
Тесты производительности
Тесты на производительности проверяют поведение системы, когда она находится под существенной нагрузкой. Эти тесты нефункциональные и могут принимать разную форму, чтобы проверить надежность, стабильность и доступность платформы. Например, это может быть наблюдение за временем отклика при выполнении большого количества запросов или наблюдение за тем, как система ведет себя при взаимодействии с большими данными.
Тесты производительности по своей природе проводить достаточно затратно, но они могут помочь вам понять, какие внешние факторы могут уронить вашу систему.
Дымовое тестирование (Smoke testing)
Дымовые тесты – это базовые тесты, которые проверяют базовый функционал приложения. Они отрабатывают достаточно быстро и их цель дать понять, что основные функции системы работают как надо и не более того. Такое тестирование направлено на выявление явных ошибок.
Дымовые тесты могут оказаться полезными сразу после сборки нового билда для проверки на то, можете ли вы запустить более дорогостоящие тесты, или сразу после развёртывания, чтобы убедиться, что приложение работает нормально в новой среде.
Как автоматизировать тесты
Тестировщик может проводить все тесты, указанные выше, вручную, но это будет крайне затратно и непродуктивно. Поскольку люди имеют ограниченную возможность производить большое количество действий с повторениями при этом все еще проводя тестирование надежно. Однако машина может с легкостью воспроизводить эти же действия и проверить, допустим, что комбинация логин/пароль будет работать и в сотый раз без каких-либо нареканий.
Для автоматизации тестирования, вам для начала придется написать их на каком-то из языков программирования с использованием фреймворка для тестирования, который подойдет для вашего приложения. PHPUnit , Mocha, RSpec – это примеры фреймворков для тестирования, которые вы можете использовать для PHP, Javascript и Ruby, соответственно. В них есть множество возможностей для каждого языка, поэтому вам стоит немного позаниматься исследованием самостоятельно и проконсультироваться с сообществами разработчиков, чтобы понять, какой фреймворк подойдет вам лучше всего.
Если ваши тесты могут запускаться с помощью скриптов из терминала, вы можете автоматизировать их, использовав сервер непрерывной интеграции по типу Bamboo или же облачного сервера Bitbucket Pipelines. Эти инструменты будут мониторить ваши репозитории и исполнять наборы тестов, как только новые изменения будут запушены в основной репозиторий.
Если вы новичок в вопросах тестирования, обратитесь к нашему руководству по непрерывной интеграции, чтобы создать свой первый набор тестов.
Исследовательское тестирование
Чем больше функций и улучшений добавляется в ваш код, тем больше возрастает потребность в тестировании, поскольку на каждом этапе вам необходимо убеждаться, что система работает корректно. Также это понадобится каждый раз, когда вы исправляете баг, поскольку было бы не лишним убедиться, что он не вернется снова после нескольких релизов. Автоматизация – это ключ к тому, чтобы это стало возможным; написание тестов рано или поздно станет частью вашей практики разработчика.
Вопрос заключается в том, надо ли вообще в таком случае проводить ручное тестирование? Короткий ответ – да, и оно должно быть сфокусировано на том, что называется «исследовательское тестирование» (exploratory testing), которое помогает выявить неочевидные ошибки.
Сессия исследовательского тестирования не должна превышать двух часов и должна иметь четко ограниченную область действия, чтобы помочь тестировщикам сосредоточиться на определенной области программного обеспечения. После информирования всех тестировщиков о границах проведения тестирования, на их усмотрения остаются действия, которые они будут предпринимать, чтобы проверить, как поведет себя система. Такое тестирование является дорогостоящим по своей природе, но очень полезно для выявления проблем с пользовательским интерфейсом или проверки работоспособности сложных рабочих процессов для пользователей. Такое тестирование важно проводить всякий раз, когда в приложение добавляется кардинально новая функция, чтобы понять, как она поведет себя в пограничных условиях.
Заметка о тестировании
Перед тем, как закончить эту статью, я хочу поговорить о цели тестирования. С одной стороны, очень важно удостовериться, что пользователи смогут использовать ваше приложение («Я не могу войти в систему», «Я не могу сохранить данные» и т.п.), но с другой стороны не менее важно проверить, что ваша система не ломается при вводе неверных данных или неожиданных действиях. Вам нужно предвидеть, что произойдет, когда пользователь сделает опечатку, попытается сохранить неполную форму или использует неправильный API. Вам нужно проверить, сможет ли кто-то из пользователей легко скомпрометировать данные, получить доступ к тому или иному ресурсу, к которому у него не должно быть доступа. Хороший набор тестов должен попытаться сломать ваше приложение и помочь понять предел его возможностей.
И, наконец, тесты – это тоже код! Так что не забывайте о них во время code review, поскольку они могут быть последним этапом перед выпуском продукта на потребительский рынок.
По устоявшейся традиции ждем ваши комментарии и приглашаем всех на день открытых дверей, который уже 18 марта проведет наш преподаватель — ведущий автоматизатор в тестировании в Group-IB — Михаил Самойлов.
Тестирование программ
Тестирование – процесс анализа программы или контролируемого выполнения программы на конечном множестве входных данных с целью обнаружения ошибок
Статическое – анализ текста программы
Динамическое – анализ контролируемого выполнения
Методы тестирования – совокупность правил, регламентирующих последовательность шагов по тестированию
Критерии тестирования – оценки, позволяющие судить о достаточности выполненного тестирования
Результативным считается тест, который приводит к обнаружению ошибки. Тестирование – деструктивный процесс.
Тест – набор входных данных, набор ожидаемых результатов, набор условий, разработанных для проверки определенного пути выполнения программы.
Особенности
1) Частое отсутствие полностью определенного эталона, которому должны соответствовать результаты
2) Высокая сложность программ исключает исчерпывающее тестирование (проверка всех возможных маршрутов выполнения)
3) Невысокая формализация критериев завершения тестирования
Основные принципы тестирования
1) Нельзя планировать тестирование в предположении, что ошибки отсутствуют
2) Следует избегать тестирования программы ее автором
3) Описание предполагаемых значений результатов должно быть неотъемлемой частью теста
4) Тесты для неправильных входных данных следует разрабатывать также тщательно, как и для правильных
5) Следует понимать, сто вероятность наличия необнаруженных ошибок пропорциональна числу уже обнаруженных
6) Не следует выбрасывать тесты, даже если программа уже не используется
Объекты тестирования. Категории тестов
1) Спецификации программных модулей, групп программ и программных комплексов
— полнота и согласованность функций программных компонент
— согласованность интерфейсов программных компонент (для групп программ и комплексов)
2) Программные модули
— структура
— преобразование данных, выполняемое модулем
— полнота функций, выполняемых модулем
3) Группы программ, объединенные для решения законченной функциональной задачи
— то же, что и для модулей
— интерфейс между программами
— тестирование потребления ресурсов
4) Программный комплекс, используемый для решения нескольких функциональных задач
— полнота решения функциональных задач
— функционирование программ в критических ситуациях
— тестирование потребления ресурсов
— оценка надежности работы комплекса
— эффективность защиты от искажения общих данных
5) Программное средство, сдаваемое в опытную эксплуатацию
— то же, что и для 4)
— удобство инсталляции рабочей версии программы
— проверка работы при изменении конфигурации оборудования
— проверка наличия и корректности документации
— испытание на соответствие техническому заданию
6) Программное средство на стадии сопровождения
— удобство модификации, типа расширения функциональности и повышения эффективности

1 – Спецификации
2 – Модули
3 – Группы программ
4 – Программные комплексы на стадии отладки
5 – Программные комплексы как продукты
Виды и методы тестирования
Особенности нисходящего тестирования:
Достоинства:
— с самого начала выполняется проверка главных функций – концептуальная проверка
Недостатки:
— необходимость разработки заглушек, часто достаточно интеллектуальных
— параллельная разработка модулей различных уровней не всегда обеспечивает возможность нужной последовательности тестирования модулей разных уровней
Особенности восходящего тестирования
Достоинства:
— для тестирования используются готовые модули нижних уровней
Недостатки:
— необходимость разработки тест-драйверов для управления работой нижних уровней с верхних
— отложенная проверка основной концепции функционирования комплекса
1) Модульное тестирование. Включает проверку:
— корректности структуры модуля
— корректности основных конструктивных компонент
— полноты и качества реализации функций обработки данных
Структурная корректность проверяется структурными методами по принципу «белого ящика»
2) Интеграционное тестирование. Проверка:
— корректности объединения модулей в группу или комплекс программ
Проводится на основе 2-х подходов:
— монолитное тестирование, при котором модули сразу объединяются в единый комплекс и после этого вместе тестируются
— инкрементальное (пошаговое), модули подключаются друг к другу последовательно (снизу вверх или сверху вниз)
Использует структурную проверку подключаемых модулей и функциональную проверку полноты и качества реализации функций. Функциональные проверки осуществляются по принципу «черного ящика»
3) Системное тестирование. Обеспечивает проверку соответствия программного средства специфицированным требованиям в заданной среде и режимах функционирования. Предусматривает следующие виды тестирования:
— тестирование функциональности
— стрессовое тестирование (тестирование на повышенных нагрузках по использованным ресурсам)
— тестирование безопасности (защита от несанкционированного доступа)
— тестирование восстановления при сбоях
В последнее время стало широко применяться альфа и бета тестирование – это виды тестирования, выполняемые с участием заказчика. Альфа тестирование выполняется на территории разработчика в условиях ограниченного времени (не более недели). Бета тестирование выполняется после введения программы в опытную эксплуатацию на территории заказчика, проводится достаточно долго (норма 1 год).
Статистика ошибок в программных продуктах по типам.
Ошибки спецификации | 8.1 |
Структурные ошибки | 25.2 |
Ошибки представления и обработки данных | 22.4 |
Полнота и корректность функций | 16.2 |
Кодирование | 9.9 |
Интеграция | 9.0 |
Системные | 3.0 |
Прочие | остальные |
Методы тестирования
Все методы делятся на две неравнозначных группы:
— статическое (ручное)
— динамическое (машинное)
Основные методы ручного:
— инспекция кода
— сквозной просмотр
Методы динамического:
— структурные
— функциональные
Методы статического тестирования
Общая черта – они используют визуальный контроль программы по ее тексту группой из 3-4 человек, один из которых автор программы. Целью проверки является обнаружение ошибок, но не их устранение. Основная концепция – наличие ошибок не есть вина автора программы, а несовершенство средств разработки программы и сложность программы как некоторой системы. При нормальном проведении статические методы тестирования позволяют обнаруживать 30-70% первоначальных ошибок в программе. Они, в отличие от машинных, позволяют обнаруживать типовые группы ошибок автора.
Инспекция кода. В группу входит 4 человека: руководитель проведения инспекции, автор программы, проектировщик и тестировщик. За неделю до инспекции руководитель раздает всем участникам листинг программ, которые будут инспектироваться.
2 этапа:
1) автор рассказывает логику работы программы и отвечает на вопросы, преследующие цель обнаружения ошибок
2) программа анализируется по типовому списку часто встречающихся ошибок:
— ошибки обращения к данным (неинициализирование данных, выход индексов за границы массивов, ссылки на пустую память)
— ошибки описания данных, соответствие заданных типов и значений
— ошибки вычислений
— ошибки передач управления (зацикливание, корректность завершения программы)
— ошибки интерфейса (ошибки, связанные с взаимодействием частей друг с другом)
— ошибки ввода/вывода
Результат инспекции кода:
— обнаруженные ошибки
— обучение автора улучшенным методам кодирования программ
Сквозной просмотр. Начинается так же как и инспекции кода, но в процессе заседания группы ознакомление с программой выполняется путем небольшого числа сеансов ручного тестирования программы на простых данных.
Динамическое тестирование
Структурное тестирование программных модулей
При структурном тестировании проверяется
— прохождение тестов по логике программы, в качестве элементов которой выступают вершины, дуги, маршруты, условия и комбинации условий управляющего графа программы
— в последнее время проверяется прохождение потока данных по информационному графу программы, которое выявляет аномалии в обработке данных
Тестирование на основе потока управления

Вводят критерии отбора элементов для тестирования:
1) покрытие операторов (покрытие вершин УГП, покрытие строк кода). Необходимо проверить выполнение каждого оператора хотя бы один раз. Нужно реализовать путь a-c-e (например при тестовом наборе a=2, b=0, x=3, результат x=2.5). Не проверяется прохождение пути a-b-d. Не проверяются отдельные условия, например OR вместо &. Является самым слабым критерием и используется только при первоначальной проверке.
2) Покрытие ветвей (решений). Необходимо проверить каждую дугу выполнения программы. Этот критерий включает в себя предыдущий.
1) Покрытьдугиa-c-e, a-b-d
2) Покрытьдугиa-c-d, a-b-e. A=3, B=0, X=3иA=2, B=1, X=1
Не выполняет обнаружения всех ошибок, например, если вместо x>1 будет x<1. Критерий не является исчерпывающим
3) Критерий покрытия условий. Каждое условие, используемое в программе должно выполняться хотя бы один раз. Используются следующие условия: A>1, B=0, A=2, x>1. Нужно реализовать проверки: A>1, A<=1, B=0, B!=0, A=2, A!=2, x>1, x<=1. Для проверки этого достаточно следующей пары тестов: (A=1, B=0, X=3) идет по пути a-b-e и (A=2, B=1, x=1) идет по пути a-b-e. Оба теста проверяют один и тот же путь.
4) Комбинированный критерий «условий/решений», который должен проверять все условия в программе и хотя бы один раз пройти по каждой дуге.
Следующие тестовые наборы: (A=2, B=0, x=4) a-c-e, (A=1, B=1, x=1) a-b-d.
5) Комбинаторное покрытие условий. Должны быть покрыты следующие комбинации условий:
(1) A>1, B=0
(2) A>1, B!=0
(3) A<=1, B=0
(4) A<=1, B!=0
(5) A=2, x>1
(6) A=2, x<=1
(7) A!=2, x>1
(8) A!=2, x<=1
Тестовые наборы:
(A=2, B=0, x=4) (1,5)
(A=2, B=1, x=1) (2, 6)
(A=1, B=0, x=2) (3, 7)
(A=1, B=1, x=1) (4, 8)
6) Критерий покрытия вызовов. Обеспечивает проверку корректности вызова каждой процедуры или функции в программе.
7) Критерий покрытия путей. Применяется в ограниченном варианте, когда при использовании циклов рассматриваются только отдельные варианты проверки цикла: тело цикла не выполняется ни разу, тело цикла выполняется один раз, тело цикла выполняется k раз (k<=n – максимально возможное число повторений), тело цикла выполняется n раз, тело цикла выполняется n+1 раз. Является очень сложным и громоздким, применяется только при очень тщательном тестировании.
Структурное тестирование на основе потока данных
Работа любой программы представляется как обработка потока данных, передаваемых от ее входа на выход. Если имеется управляющий граф программы вида
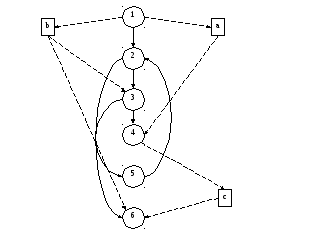
Информационный граф программы представляется пунктирными линиями.
Для каждой вершины i УГП можно определить множество def(i) – данных, определенных в этой вершине и множество use(i) – данных, используемых в этой вершине.
Для тестирования надо выделить DU цепочки, которые имеют следующий вид DU=(Data, i, j), Data – данное, i – вершина, в которой создается данное, j – вершина, в которой используется данное.
Для нашего примера множество DU цепочек:
DU={(a, 1, 4), (b, 1, 3), (b, 1, 6), (c, 4, 6)}.
После формирования набора DU цепочек выполняется отображение DU цепочек во фрагменты УГП, соответствующие путям определения и использования данной цепочки.
Для цепочки (a, 1, 4) путь 1-2-3-4. По информационному графу программы порождается путь в управляющем графе программы, который тестируется. Этот способ называется «стратегия требуемых пар»
Недостаток: трудность выбора минимального количества тестов, обеспечивающих эффективную проверку всех DU цепочек.
Функциональное тестирование (ФТ)
Структурное тестирование не позволяет проверить все функции, возлагаемые на программу, потому что некоторые функции могут просто отсутствовать в предложенной реализации.
Функциональное тестирование – это тестирование, необходимое для проверки соответствия программного продукта функциональным требованиям, заданным в спецификации. При выполнении ФТ логика работы программы игнорируется и все внимание фокусируется на выходных значениях, полученных в результате обработки заданных входных наборов. Обычно ФТ обнаруживаются следующие виды ошибок:
1) некорректные или отсутствующие функции
2) ошибки интерфейса
3) ошибки потребления ресурсов (превышение занимаемых памяти или времени выполнения)
4) ошибки инициализации или завершения программы
Для проведения ФТ необходимо иметь: наборы входных данных, приводящих к аномалиям выполнения программы, наборы выходных данных, позволяющих обнаруживать дефекты в работе программы.
Методы ФТ должны обеспечивать:
1) сокращение необходимого числа тестовых вариантов (проверки выполняются динамически)
2) выявлять классы ошибок, а не отдельные ошибки
Методы ФТ как правило применяются на более поздних стадиях тестирования, чем структурные.
Примеры.
Метод разбиения на классы эквивалентности.
Область входных данных разбивается на классы эквивалентности (КлЭ), представляющие собой набор данных с общими свойствами, обработка которых программой производится совершенно одинаково. При обработке используются одни и те же операторы и одни и те же связи. КлЭ делятся на правильные (допустимые) и неправильные. КлЭ определяются по спецификации на программу, например следующим образом: 20000<=x<=80000, правильный КлЭ — 20000<=x<=80000, 2 неправильных КлЭ – x<20000, x>80000. Разработка тестов состоит из 2 этапов:
1) разбиение на КлЭ
2) построение тестов
Выделение КлЭ по спецификации – процесс эвристический
Рекомендации
1) если проверяемое входное данное представлено в виде диапазона значений, то строится один правильный класс (внутри диапазона) и два неправильных
2) если конкретное значение, то строится один правильный и два неправильных КлЭ
3) если входное условие описывает множество значений m={a,b,c}, то строится по одному правильному классу для каждого из значений и один неправильный класс для значений, не принадлежащих множеству (m!=a)&(m!=b)&(m!=c)
4) если есть основание считать, что элементы КлЭ трактуются программой неодинаково, то этот класс необходимо разбить на меньшие классы с разнесением по-разному трактуемых элементов
Построение тестов.
1) Каждому КлЭ присваивается уникальный номер
2) Строятся тесты для правильных КлЭ, чтобы каждый тест покрывал как можно больше этих классов
3) Строятся тесты для неправильных классов, которые должны быть индивидуальны, поскольку проверки с ошибочными входами могут скрывать друг друга.
Анализ граничных условий.
Метод является развитием предыдущего в том смысле, что под граничными условиями понимаются ситуации, возникающие на границах входных и выходных КлЭ.
Отличается от предыдущего
1) при выборе элементов КлЭ используются значения на и вблизи границ классов -1.0<=x<=1.0 x={-1.0, 1.0, -1.01, 1.01}
2) метод должен рассматривать не только входные, но КлЭ для выходных значений.
Общее правило использования метода:
1) построить тесты для значений, лежащих на границе области, и тесты с неправильными данными, немного выходящих за пределы границ
2) если обрабатывается определенное количество файлов в заданном диапазоне, то построить тесты для граничных значений файлов, на 1 больше и меньше верхней и нижней границы соответственно
3) применить подходы 1, 2 для каждого из выходных значений
4) если проверяется упорядоченное множество значений, то необходимо выполнить проверки первого и последнего элементов.
Недостатками рассмотренных методов является то, что они не позволяют проверять комбинации условий.
Метод функциональных диаграмм (метод диаграмм причинно-следственных связей ДПС)
Метод позволяет формально генерировать результативные тесты, позволяющие обнаруживать неоднозначность требований спецификаций при комбинировании входных условий
Функциональная диаграмма – это формальный графо-аналитический язык, позволяющий описывать спецификации, написанные на естественном языке.
Методика построения функциональных диаграмм
1) спецификация разбивается на «рабочие участки», т.е. такие участки, для которых диаграмма не будет слишком громоздкой
2) спецификации выделяются причины и следствия. Причина – отдельное входное условие или КлЭ входных условий, следствие – выходное условие, результат выполнения программы. Каждой причине и следствию присваивается уникальный номер
3) анализируется семантика информации, заданной в спецификации, и строится булевский граф, связывающий причины и следствия, который является функциональной диаграммой. Каждый узел графа может принимать 2 значения: 1 – присутствует (выполняется)
Для представления диаграмм используются следующие базовые символы:

Пример.
Задана спецификация. Файл обновляется, если символ, считываемый в позиции 1 равен а А или Б, а символ в позиции 2 стоит цифра. Если первый символ ошибочный, то сообщение Х1, если второй не цифра, то сообщение Х2.
Причины
1) символ в позиции 1 равен А
2) символ в позиции 1 равен Б
3) символ в позиции 2 цифра
Следствия
1) файл обновляется
2) выдается сообщение Х1
3) выдается сообщение Х2

В приведенной диаграмме есть проблема: никак не ограничено применение причин 1 и 2.
Для учета невозможных комбинаций причин или следствий предусмотрены дополнительные базовые элементы.

Е – не могут быть одновременно
I – не могут быть одновременно 0
R – требует (a=1, то и b=1)
M – запрещает (a=1, то b=0)
С учетом этого:

Генерация таблицы решений
Использование столбцов таблицы решений в качестве тестов
Генерация таблицы решений:
1) Формируются строки, соответствующие причинам и следствиям
2) Выбирается некоторое следствие, которое имеет значение 1
3) Находятся комбинации причин, которые обеспечивают такое значение следствия
Незаполненные элементы строк причин могут принимать любые значения
1 | 1 | 0 | 0 | |
2 | 0 | 1 | 0 | |
3 | 1 | 1 | 0 | |
4 | 1 | 1 | ||
5 | 1 | |||
6 | 1 |
Используемые тесты будут иметь следующий вид
1) A 2
2) B 2
3) 1 1
4) A A
Метод, основанный на предположении об ошибке (метод отрицательного тестирования)
Сущность основана на опыте тестировщика и идея заключается в перечислении некоторого набора возможных ошибок, для обеспечения которого пишутся тесты. Метод определяет способы как заставить программу сделать ошибку или прекратить выполнение. У проектировщиков выявляются требования для успешного выполнения программы и далее разрабатываются тесты, каждый из которых нарушает одно из требований. Проверяется устойчивость программы к исключительным ситуациям.
1) запуск на другой платформе
2) перестановка значений в файле
3) отсутствие данных в БД
4) неверные или отсутствующие значения параметров конфигурации
Общая стратегия разработки тестов
1) проверить логику программу с помощью методов структурного тестирования по критериям покрытия операторов, покрытия ветвей (условий), покрытие решений условий, комбинаторное покрытие условий
2) проверка функциональности программы с помощью методов ФТ. Если есть комбинации входных условий, то надо начинать с метода функциональных диаграмм, затем разбиение на КлЭ, анализ граничных условий, метод отрицательного тестирования.
Критерии завершения тестирования
Обычно применяется 3 группы
1) критерии, основанные на определенной методологии тестирования, определяющей процент покрытия тестами логики и функциональности программы.
2) критерии, основанные на экспертных оценках возможного числа ошибок, имеющихся в программе данного класса и целевого назначения.
3) критерий, основанный на временной диаграмме тестирования для каждой фазы разработки программы

Тестирование. Фундаментальная теория / Habr
Недавно был на собеседовании на Middle QA на проект, который явно превышает мои возможности. Уделил много времени тому, чего не знал вообще и мало времени повторению простой теории, а зря.Ниже основы основ для повторения перед собеседованием для Trainee and Junior: определение тестирования, качество, верификация / валидация, цели, этапы, тест план, пункты тест плана, тест дизайн, техники тест дизайна, traceability matrix, test case, чек-лист, дефект, error/deffect/failure, баг репорт, severity vs priority, уровни тестирования, виды / типы, подходы к интеграционному тестированию, принципы тестирования, статическое и динамическое тестирование, исследовательское / ad-hoc тестирование, требования, жизненный цикл бага, стадии разработки ПО, decision table, qa/qc/test engineer, диаграмма связей.
Все замечания, корректировки и дополнения очень приветствуются.
Тестирование программного обеспечения — проверка соответствия между реальным и ожидаемым поведением программы, осуществляемая на конечном наборе тестов, выбранном определенным образом. В более широком смысле, тестирование — это одна из техник контроля качества, включающая в себя активности по планированию работ (Test Management), проектированию тестов (Test Design), выполнению тестирования (Test Execution) и анализу полученных результатов (Test Analysis).
Качество программного обеспечения (Software Quality) — это совокупность характеристик программного обеспечения, относящихся к его способности удовлетворять установленные и предполагаемые потребности. [Quality management and quality assurance]
Верификация (verification) — это процесс оценки системы или её компонентов с целью определения удовлетворяют ли результаты текущего этапа разработки условиям, сформированным в начале этого этапа[IEEE]. Т.е. выполняются ли наши цели, сроки, задачи по разработке проекта, определенные в начале текущей фазы.
Валидация (validation) — это определение соответствия разрабатываемого ПО ожиданиям и потребностям пользователя, требованиям к системе [BS7925-1].
Также можно встретить иную интерпритацию:
Процесс оценки соответствия продукта явным требованиям (спецификациям) и есть верификация (verification), в то же время оценка соответствия продукта ожиданиям и требованиям пользователей — есть валидация (validation). Также часто можно встретить следующее определение этих понятий:
Validation — ’is this the right specification?’.
Verification — ’is the system correct to specification?’.
Цели тестирования
Повысить вероятность того, что приложение, предназначенное для тестирования, будет работать правильно при любых обстоятельствах.
Повысить вероятность того, что приложение, предназначенное для тестирования, будет соответствовать всем описанным требованиям.
Предоставление актуальной информации о состоянии продукта на данный момент.
Этапы тестирования:
1. Анализ продукта
2. Работа с требованиями
3. Разработка стратегии тестирования
и планирование процедур контроля качества
4. Создание тестовой документации
5. Тестирование прототипа
6. Основное тестирование
7. Стабилизация
8. Эксплуатация
Тест план (Test Plan) — это документ, описывающий весь объем работ по тестированию, начиная с описания объекта, стратегии, расписания, критериев начала и окончания тестирования, до необходимого в процессе работы оборудования, специальных знаний, а также оценки рисков с вариантами их разрешения.
Отвечает на вопросы:
Что надо тестировать?
Что будете тестировать?
Как будете тестировать?
Когда будете тестировать?
Критерии начала тестирования.
Критерии окончания тестирования.
Основные пункты тест плана
В стандарте IEEE 829 перечислены пункты, из которых должен (пусть — может) состоять тест-план:
a) Test plan identifier;
b) Introduction;
c) Test items;
d) Features to be tested;
e) Features not to be tested;
f) Approach;
g) Item pass/fail criteria;
h) Suspension criteria and resumption requirements;
i) Test deliverables;
j) Testing tasks;
k) Environmental needs;
l) Responsibilities;
m) Staffing and training needs;
n) Schedule;
o) Risks and contingencies;
p) Approvals.
Тест дизайн – это этап процесса тестирования ПО, на котором проектируются и создаются тестовые сценарии (тест кейсы), в соответствии с определёнными ранее критериями качества и целями тестирования.
Роли, ответственные за тест дизайн:
• Тест аналитик — определяет «ЧТО тестировать?»
• Тест дизайнер — определяет «КАК тестировать?»
Техники тест дизайна
• Эквивалентное Разделение (Equivalence Partitioning — EP). Как пример, у вас есть диапазон допустимых значений от 1 до 10, вы должны выбрать одно верное значение внутри интервала, скажем, 5, и одно неверное значение вне интервала — 0.
• Анализ Граничных Значений (Boundary Value Analysis — BVA). Если взять пример выше, в качестве значений для позитивного тестирования выберем минимальную и максимальную границы (1 и 10), и значения больше и меньше границ (0 и 11). Анализ Граничный значений может быть применен к полям, записям, файлам, или к любого рода сущностям имеющим ограничения.
• Причина / Следствие (Cause/Effect — CE). Это, как правило, ввод комбинаций условий (причин), для получения ответа от системы (Следствие). Например, вы проверяете возможность добавлять клиента, используя определенную экранную форму. Для этого вам необходимо будет ввести несколько полей, таких как «Имя», «Адрес», «Номер Телефона» а затем, нажать кнопку «Добавить» — это «Причина». После нажатия кнопки «Добавить», система добавляет клиента в базу данных и показывает его номер на экране — это «Следствие».
• Предугадывание ошибки (Error Guessing — EG). Это когда тестировщик использует свои знания системы и способность к интерпретации спецификации на предмет того, чтобы «предугадать» при каких входных условиях система может выдать ошибку. Например, спецификация говорит: «пользователь должен ввести код». Тестировщик будет думать: «Что, если я не введу код?», «Что, если я введу неправильный код? », и так далее. Это и есть предугадывание ошибки.
• Исчерпывающее тестирование (Exhaustive Testing — ET) — это крайний случай. В пределах этой техники вы должны проверить все возможные комбинации входных значений, и в принципе, это должно найти все проблемы. На практике применение этого метода не представляется возможным, из-за огромного количества входных значений.
• Попарное тестирование (Pairwise Testing) — это техника формирования наборов тестовых данных. Сформулировать суть можно, например, вот так: формирование таких наборов данных, в которых каждое тестируемое значение каждого из проверяемых параметров хотя бы единожды сочетается с каждым тестируемым значением всех остальных проверяемых параметров.
Допустим, какое-то значений (налог) для человека рассчитывается на основании его пола, возраста и наличия детей — получаем три входных параметра, для каждого из которых для тестов выбираем каким-то образом значения. Например: пол — мужской или женский; возраст — до 25, от 25 до 60, более 60; наличие детей — да или нет. Для проверки правильности расчётов можно, конечно, перебрать все комбинации значений всех параметров:
| № | пол | возраст | дети |
|---|---|---|---|
| 1 | мужчина | до 25 | детей нет |
| 2 | женщина | до 25 | детей нет |
| 3 | мужчина | 25-60 | детей нет |
| 4 | женщина | 25-60 | детей нет |
| 5 | мужчина | старше 60 | детей нет |
| 6 | женщина | старше 60 | детей нет |
| 7 | мужчина | до 25 | дети есть |
| 8 | женщина | до 25 | дети есть |
| 9 | мужчина | 25-60 | дети есть |
| 10 | женщина | 25-60 | дети есть |
| 11 | мужчина | старше 60 | дети есть |
| 12 | женщина | старше 60 | дети есть |
А можно решить, что нам не нужны сочетания значений всех параметров со всеми, а мы хотим только убедиться, что мы проверим все уникальные пары значений параметров. Т.е., например, с точки зрения параметров пола и возраста мы хотим убедиться, что мы точно проверим мужчину до 25, мужчину между 25 и 60, мужчину после 60, а также женщину до 25, женщину между 25 и 60, ну и женщину после 60. И точно так же для всех остальных пар параметров. И таким образом, мы можем получить гораздо меньше наборов значений (в них есть все пары значений, правда некоторые дважды):
| № | пол | возраст | дети |
|---|---|---|---|
| 1 | мужчина | до 25 | детей нет |
| 2 | женщина | до 25 | дети есть |
| 3 | мужчина | 25-60 | дети есть |
| 4 | женщина | 25-60 | детей нет |
| 5 | мужчина | старше 60 | детей нет |
| 6 | женщина | старше 60 | дети есть |
Такой подход примерно и составляет суть техники pairwise testing — мы не проверяем все сочетания всех значений, но проверяем все пары значений.
Traceability matrix — Матрица соответствия требований — это двумерная таблица, содержащая соответсвие функциональных требований (functional requirements) продукта и подготовленных тестовых сценариев (test cases). В заголовках колонок таблицы расположены требования, а в заголовках строк — тестовые сценарии. На пересечении — отметка, означающая, что требование текущей колонки покрыто тестовым сценарием текущей строки.
Матрица соответсвия требований используется QA-инженерами для валидации покрытия продукта тестами. МСТ является неотъемлемой частью тест-плана.
Тестовый сценарий (Test Case) — это артефакт, описывающий совокупность шагов, конкретных условий и параметров, необходимых для проверки реализации тестируемой функции или её части.
Пример:
Action Expected Result Test Result
(passed/failed/blocked)
Open page «login» Login page is opened Passed
Каждый тест кейс должен иметь 3 части:
PreConditions Список действий, которые приводят систему к состоянию пригодному для проведения основной проверки. Либо список условий, выполнение которых говорит о том, что система находится в пригодном для проведения основного теста состояния.
Test Case Description Список действий, переводящих систему из одного состояния в другое, для получения результата, на основании которого можно сделать вывод о удовлетворении реализации, поставленным требованиям
PostConditions Список действий, переводящих систему в первоначальное состояние (состояние до проведения теста — initial state)
Виды Тестовых Сценариев:
Тест кейсы разделяются по ожидаемому результату на позитивные и негативные:
• Позитивный тест кейс использует только корректные данные и проверяет, что приложение правильно выполнило вызываемую функцию.
• Негативный тест кейс оперирует как корректными так и некорректными данными (минимум 1 некорректный параметр) и ставит целью проверку исключительных ситуаций (срабатывание валидаторов), а также проверяет, что вызываемая приложением функция не выполняется при срабатывании валидатора.
Чек-лист (check list) — это документ, описывающий что должно быть протестировано. При этом чек-лист может быть абсолютно разного уровня детализации. На сколько детальным будет чек-лист зависит от требований к отчетности, уровня знания продукта сотрудниками и сложности продукта.
Как правило, чек-лист содержит только действия (шаги), без ожидаемого результата. Чек-лист менее формализован чем тестовый сценарий. Его уместно использовать тогда, когда тестовые сценарии будут избыточны. Также чек-лист ассоциируются с гибкими подходами в тестировании.
Дефект (он же баг) – это несоответствие фактического результата выполнения программы ожидаемому результату. Дефекты обнаруживаются на этапе тестирования программного обеспечения (ПО), когда тестировщик проводит сравнение полученных результатов работы программы (компонента или дизайна) с ожидаемым результатом, описанным в спецификации требований.
Error — ошибка пользователя, то есть он пытается использовать программу иным способом.
Пример — вводит буквы в поля, где требуется вводить цифры (возраст, количество товара и т.п.).
В качественной программе предусмотрены такие ситуации и выдаются сообщение об ошибке (error message), с красным крестиком которые.
Bug (defect) — ошибка программиста (или дизайнера или ещё кого, кто принимает участие в разработке), то есть когда в программе, что-то идёт не так как планировалось и программа выходит из-под контроля. Например, когда никак не контроллируется ввод пользователя, в результате неверные данные вызывают краши или иные «радости» в работе программы. Либо внутри программа построена так, что изначально не соответствует тому, что от неё ожидается.
Failure — сбой (причём не обязательно аппаратный) в работе компонента, всей программы или системы. То есть, существуют такие дефекты, которые приводят к сбоям (A defect caused the failure) и существуют такие, которые не приводят. UI-дефекты например. Но аппаратный сбой, никак не связанный с software, тоже является failure.
Баг Репорт (Bug Report) — это документ, описывающий ситуацию или последовательность действий приведшую к некорректной работе объекта тестирования, с указанием причин и ожидаемого результата.
Шапка
Короткое описание (Summary) Короткое описание проблемы, явно указывающее на причину и тип ошибочной ситуации.
Проект (Project) Название тестируемого проекта
Компонент приложения (Component) Название части или функции тестируемого продукта
Номер версии (Version) Версия на которой была найдена ошибка
Серьезность (Severity) Наиболее распространена пятиуровневая система градации серьезности дефекта:
• S1 Блокирующий (Blocker)
• S2 Критический (Critical)
• S3 Значительный (Major)
• S4 Незначительный (Minor)
• S5 Тривиальный (Trivial)
Приоритет (Priority) Приоритет дефекта:
• P1 Высокий (High)
• P2 Средний (Medium)
• P3 Низкий (Low)
Статус (Status) Статус бага. Зависит от используемой процедуры и жизненного цикла бага (bug workflow and life cycle)
Автор (Author) Создатель баг репорта
Назначен на (Assigned To) Имя сотрудника, назначенного на решение проблемы
Окружение
ОС / Сервис Пак и т.д. / Браузера + версия /… Информация об окружении, на котором был найден баг: операционная система, сервис пак, для WEB тестирования — имя и версия браузера и т.д.
…
Описание
Шаги воспроизведения (Steps to Reproduce) Шаги, по которым можно легко воспроизвести ситуацию, приведшую к ошибке.
Фактический Результат (Result) Результат, полученный после прохождения шагов к воспроизведению
Ожидаемый результат (Expected Result) Ожидаемый правильный результат
Дополнения
Прикрепленный файл (Attachment) Файл с логами, скриншот или любой другой документ, который может помочь прояснить причину ошибки или указать на способ решения проблемы
Severity vs Priority
Серьезность (Severity) — это атрибут, характеризующий влияние дефекта на работоспособность приложения.
Приоритет (Priority) — это атрибут, указывающий на очередность выполнения задачи или устранения дефекта. Можно сказать, что это инструмент менеджера по планированию работ. Чем выше приоритет, тем быстрее нужно исправить дефект.
Severity выставляется тестировщиком
Priority – менеджером, тимлидом или заказчиком
Градация Серьезности дефекта (Severity)
S1 Блокирующая (Blocker)
Блокирующая ошибка, приводящая приложение в нерабочее состояние, в результате которого дальнейшая работа с тестируемой системой или ее ключевыми функциями становится невозможна. Решение проблемы необходимо для дальнейшего функционирования системы.
S2 Критическая (Critical)
Критическая ошибка, неправильно работающая ключевая бизнес логика, дыра в системе безопасности, проблема, приведшая к временному падению сервера или приводящая в нерабочее состояние некоторую часть системы, без возможности решения проблемы, используя другие входные точки. Решение проблемы необходимо для дальнейшей работы с ключевыми функциями тестируемой системой.
S3 Значительная (Major)
Значительная ошибка, часть основной бизнес логики работает некорректно. Ошибка не критична или есть возможность для работы с тестируемой функцией, используя другие входные точки.
S4 Незначительная (Minor)
Незначительная ошибка, не нарушающая бизнес логику тестируемой части приложения, очевидная проблема пользовательского интерфейса.
S5 Тривиальная (Trivial)
Тривиальная ошибка, не касающаяся бизнес логики приложения, плохо воспроизводимая проблема, малозаметная посредствам пользовательского интерфейса, проблема сторонних библиотек или сервисов, проблема, не оказывающая никакого влияния на общее качество продукта.
Градация Приоритета дефекта (Priority)
P1 Высокий (High)
Ошибка должна быть исправлена как можно быстрее, т.к. ее наличие является критической для проекта.
P2 Средний (Medium)
Ошибка должна быть исправлена, ее наличие не является критичной, но требует обязательного решения.
P3 Низкий (Low)
Ошибка должна быть исправлена, ее наличие не является критичной, и не требует срочного решения.
Уровни Тестирования
1. Модульное тестирование (Unit Testing)
Компонентное (модульное) тестирование проверяет функциональность и ищет дефекты в частях приложения, которые доступны и могут быть протестированы по-отдельности (модули программ, объекты, классы, функции и т.д.).
2. Интеграционное тестирование (Integration Testing)
Проверяется взаимодействие между компонентами системы после проведения компонентного тестирования.
3. Системное тестирование (System Testing)
Основной задачей системного тестирования является проверка как функциональных, так и не функциональных требований в системе в целом. При этом выявляются дефекты, такие как неверное использование ресурсов системы, непредусмотренные комбинации данных пользовательского уровня, несовместимость с окружением, непредусмотренные сценарии использования, отсутствующая или неверная функциональность, неудобство использования и т.д.
4. Операционное тестирование (Release Testing).
Даже если система удовлетворяет всем требованиям, важно убедиться в том, что она удовлетворяет нуждам пользователя и выполняет свою роль в среде своей эксплуатации, как это было определено в бизнес моделе системы. Следует учесть, что и бизнес модель может содержать ошибки. Поэтому так важно провести операционное тестирование как финальный шаг валидации. Кроме этого, тестирование в среде эксплуатации позволяет выявить и нефункциональные проблемы, такие как: конфликт с другими системами, смежными в области бизнеса или в программных и электронных окружениях; недостаточная производительность системы в среде эксплуатации и др. Очевидно, что нахождение подобных вещей на стадии внедрения — критичная и дорогостоящая проблема. Поэтому так важно проведение не только верификации, но и валидации, с самых ранних этапов разработки ПО.
5. Приемочное тестирование (Acceptance Testing)
Формальный процесс тестирования, который проверяет соответствие системы требованиям и проводится с целью:
• определения удовлетворяет ли система приемочным критериям;
• вынесения решения заказчиком или другим уполномоченным лицом принимается приложение или нет.
Виды / типы тестирования
Функциональные виды тестирования
• Функциональное тестирование (Functional testing)
• Тестирование пользовательского интерфейса (GUI Testing)
• Тестирование безопасности (Security and Access Control Testing)
• Тестирование взаимодействия (Interoperability Testing)
Нефункциональные виды тестирования
• Все виды тестирования производительности:
o нагрузочное тестирование (Performance and Load Testing)
o стрессовое тестирование (Stress Testing)
o тестирование стабильности или надежности (Stability / Reliability Testing)
o объемное тестирование (Volume Testing)
• Тестирование установки (Installation testing)
• Тестирование удобства пользования (Usability Testing)
• Тестирование на отказ и восстановление (Failover and Recovery Testing)
• Конфигурационное тестирование (Configuration Testing)
Связанные с изменениями виды тестирования
• Дымовое тестирование (Smoke Testing)
• Регрессионное тестирование (Regression Testing)
• Повторное тестирование (Re-testing)
• Тестирование сборки (Build Verification Test)
• Санитарное тестирование или проверка согласованности/исправности (Sanity Testing)
Функциональное тестирование рассматривает заранее указанное поведение и основывается на анализе спецификаций функциональности компонента или системы в целом.
Тестирование пользовательского интерфейса (GUI Testing) — функциональная проверка интерфейса на соответствие требованиям — размер, шрифт, цвет, consistent behavior.
Тестирование безопасности — это стратегия тестирования, используемая для проверки безопасности системы, а также для анализа рисков, связанных с обеспечением целостного подхода к защите приложения, атак хакеров, вирусов, несанкционированного доступа к конфиденциальным данным.
Тестирование взаимодействия (Interoperability Testing) – это функциональное тестирование, проверяющее способность приложения взаимодействовать с одним и более компонентами или системами и включающее в себя тестирование совместимости (compatibility testing) и интеграционное тестирование
Нагрузочное тестирование — это автоматизированное тестирование, имитирующее работу определенного количества бизнес пользователей на каком-либо общем (разделяемом ими) ресурсе.
Стрессовое тестирование (Stress Testing) позволяет проверить насколько приложение и система в целом работоспособны в условиях стресса и также оценить способность системы к регенерации, т.е. к возвращению к нормальному состоянию после прекращения воздействия стресса. Стрессом в данном контексте может быть повышение интенсивности выполнения операций до очень высоких значений или аварийное изменение конфигурации сервера. Также одной из задач при стрессовом тестировании может быть оценка деградации производительности, таким образом цели стрессового тестирования могут пересекаться с целями тестирования производительности.
Объемное тестирование (Volume Testing). Задачей объемного тестирования является получение оценки производительности при увеличении объемов данных в базе данных приложения
Тестирование стабильности или надежности (Stability / Reliability Testing). Задачей тестирования стабильности (надежности) является проверка работоспособности приложения при длительном (многочасовом) тестировании со средним уровнем нагрузки.
Тестирование установки направленно на проверку успешной инсталляции и настройки, а также обновления или удаления программного обеспечения.
Тестирование удобства пользования — это метод тестирования, направленный на установление степени удобства использования, обучаемости, понятности и привлекательности для пользователей разрабатываемого продукта в контексте заданных условий. Сюда также входит:
User eXperience (UX) — ощущение, испытываемое пользователем во время использования цифрового продукта, в то время как User interface — это инструмент, позволяющий осуществлять интеракцию «пользователь — веб-ресурс».
Тестирование на отказ и восстановление (Failover and Recovery Testing) проверяет тестируемый продукт с точки зрения способности противостоять и успешно восстанавливаться после возможных сбоев, возникших в связи с ошибками программного обеспечения, отказами оборудования или проблемами связи (например, отказ сети). Целью данного вида тестирования является проверка систем восстановления (или дублирующих основной функционал систем), которые, в случае возникновения сбоев, обеспечат сохранность и целостность данных тестируемого продукта.
Конфигурационное тестирование (Configuration Testing) — специальный вид тестирования, направленный на проверку работы программного обеспечения при различных конфигурациях системы (заявленных платформах, поддерживаемых драйверах, при различных конфигурациях компьютеров и т.д.)
Дымовое (Smoke) тестирование рассматривается как короткий цикл тестов, выполняемый для подтверждения того, что после сборки кода (нового или исправленного) устанавливаемое приложение, стартует и выполняет основные функции.
Регрессионное тестирование — это вид тестирования направленный на проверку изменений, сделанных в приложении или окружающей среде (починка дефекта, слияние кода, миграция на другую операционную систему, базу данных, веб сервер или сервер приложения), для подтверждения того факта, что существующая ранее функциональность работает как и прежде. Регрессионными могут быть как функциональные, так и нефункциональные тесты.
Повторное тестирование — тестирование, во время которого исполняются тестовые сценарии, выявившие ошибки во время последнего запуска, для подтверждения успешности исправления этих ошибок.
В чем разница между regression testing и re-testing?
Re-testing — проверяется исправление багов
Regression testing — проверяется то, что исправление багов, а также любые изменения в коде приложения, не повлияли на другие модули ПО и не вызвало новых багов.
Тестирование сборки или Build Verification Test — тестирование направленное на определение соответствия, выпущенной версии, критериям качества для начала тестирования. По своим целям является аналогом Дымового Тестирования, направленного на приемку новой версии в дальнейшее тестирование или эксплуатацию. Вглубь оно может проникать дальше, в зависимости от требований к качеству выпущенной версии.
Санитарное тестирование — это узконаправленное тестирование достаточное для доказательства того, что конкретная функция работает согласно заявленным в спецификации требованиям. Является подмножеством регрессионного тестирования. Используется для определения работоспособности определенной части приложения после изменений произведенных в ней или окружающей среде. Обычно выполняется вручную.
Подходы к интеграционному тестированию:
• Снизу вверх (Bottom Up Integration)
Все низкоуровневые модули, процедуры или функции собираются воедино и затем тестируются. После чего собирается следующий уровень модулей для проведения интеграционного тестирования. Данный подход считается полезным, если все или практически все модули, разрабатываемого уровня, готовы. Также данный подход помогает определить по результатам тестирования уровень готовности приложения.
• Сверху вниз (Top Down Integration)
Вначале тестируются все высокоуровневые модули, и постепенно один за другим добавляются низкоуровневые. Все модули более низкого уровня симулируются заглушками с аналогичной функциональностью, затем по мере готовности они заменяются реальными активными компонентами. Таким образом мы проводим тестирование сверху вниз.
• Большой взрыв («Big Bang» Integration)
Все или практически все разработанные модули собираются вместе в виде законченной системы или ее основной части, и затем проводится интеграционное тестирование. Такой подход очень хорош для сохранения времени. Однако если тест кейсы и их результаты записаны не верно, то сам процесс интеграции сильно осложнится, что станет преградой для команды тестирования при достижении основной цели интеграционного тестирования.
Принципы тестирования
Принцип 1 – Тестирование демонстрирует наличие дефектов (Testing shows presence of defects)
Тестирование может показать, что дефекты присутствуют, но не может доказать, что их нет. Тестирование снижает вероятность наличия дефектов, находящихся в программном обеспечении, но, даже если дефекты не были обнаружены, это не доказывает его корректности.
Принцип 2 – Исчерпывающее тестирование недостижимо (Exhaustive testing is impossible)
Полное тестирование с использованием всех комбинаций вводов и предусловий физически невыполнимо, за исключением тривиальных случаев. Вместо исчерпывающего тестирования должны использоваться анализ рисков и расстановка приоритетов, чтобы более точно сфокусировать усилия по тестированию.
Принцип 3 – Раннее тестирование (Early testing)
Чтобы найти дефекты как можно раньше, активности по тестированию должны быть начаты как можно раньше в жизненном цикле разработки программного обеспечения или системы, и должны быть сфокусированы на определенных целях.
Принцип 4 – Скопление дефектов (Defects clustering)
Усилия тестирования должны быть сосредоточены пропорционально ожидаемой, а позже реальной плотности дефектов по модулям. Как правило, большая часть дефектов, обнаруженных при тестировании или повлекших за собой основное количество сбоев системы, содержится в небольшом количестве модулей.
Принцип 5 – Парадокс пестицида (Pesticide paradox)
Если одни и те же тесты будут прогоняться много раз, в конечном счете этот набор тестовых сценариев больше не будет находить новых дефектов. Чтобы преодолеть этот “парадокс пестицида”, тестовые сценарии должны регулярно рецензироваться и корректироваться, новые тесты должны быть разносторонними, чтобы охватить все компоненты программного обеспечения,
или системы, и найти как можно больше дефектов.
Принцип 6 – Тестирование зависит от контекста (Testing is concept depending)
Тестирование выполняется по-разному в зависимости от контекста. Например, программное обеспечение, в котором критически важна безопасность, тестируется иначе, чем сайт электронной коммерции.
Принцип 7 – Заблуждение об отсутствии ошибок (Absence-of-errors fallacy)
Обнаружение и исправление дефектов не помогут, если созданная система не подходит пользователю и не удовлетворяет его ожиданиям и потребностям.
Cтатическое и динамическое тестирование
Статическое тестирование отличается от динамического тем, что производится без запуска программного кода продукта. Тестирование осуществляется путем анализа программного кода (code review) или скомпилированного кода. Анализ может производиться как вручную, так и с помощью специальных инструментальных средств. Целью анализа является раннее выявление ошибок и потенциальных проблем в продукте. Также к статическому тестированию относится тестирования спецификации и прочей документации.
Исследовательское / ad-hoc тестирование
Простейшее определение исследовательского тестирования — это разработка и выполнения тестов в одно и то же время. Что является противоположностью сценарного подхода (с его предопределенными процедурами тестирования, неважно ручными или автоматизированными). Исследовательские тесты, в отличие от сценарных тестов, не определены заранее и не выполняются в точном соответствии с планом.
Разница между ad hoc и exploratory testing в том, что теоретически, ad hoc может провести кто угодно, а для проведения exploratory необходимо мастерство и владение определенными техниками. Обратите внимание, что определенные техники это не только техники тестирования.
Требования – это спецификация (описание) того, что должно быть реализовано.
Требования описывают то, что необходимо реализовать, без детализации технической стороны решения. Что, а не как.
Требования к требованиям:
• Корректность
• Недвусмысленность
• Полнота набора требований
• Непротиворечивость набора требований
• Проверяемость (тестопригодность)
• Трассируемость
• Понимаемость
Жизненный цикл бага
Стадии разработки ПО — это этапы, которые проходят команды разработчиков ПО, прежде чем программа станет доступной для широко круга пользователей. Разработка ПО начинается с первоначального этапа разработки (стадия «пре-альфа») и продолжается стадиями, на которых продукт дорабатывается и модернизируется. Финальным этапом этого процесса становится выпуск на рынок окончательной версии программного обеспечения («общедоступного релиза»).
Программный продукт проходит следующие стадии:
• анализ требований к проекту;
• проектирование;
• реализация;
• тестирование продукта;
• внедрение и поддержка.
Каждой стадии разработки ПО присваивается определенный порядковый номер. Также каждый этап имеет свое собственное название, которое характеризует готовность продукта на этой стадии.
Жизненный цикл разработки ПО:
• Пре-альфа
• Альфа
• Бета
• Релиз-кандидат
• Релиз
• Пост-релиз
Таблица принятия решений (decision table) – великолепный инструмент для упорядочения сложных бизнес требований, которые должны быть реализованы в продукте. В таблицах решений представлен набор условий, одновременное выполнение которых должно привести к определенному действию.
QA/QC/Test Engineer
Таким образом, мы можем построить модель иерархии процессов обеспечения качества: Тестирование – часть QC. QC – часть QA.
Диаграмма связей – это инструмент управления качеством, основанный на определении логических взаимосвязей между различными данными. Применяется этот инструмент для сопоставления причин и следствий по исследуемой проблеме.
Источники: www.protesting.ru, bugscatcher.net, qalight.com.ua, thinkingintests.wordpress.com, книга ISTQB, www.quizful.net, bugsclock.blogspot.com, www.zeelabs.com, devopswiki.net, hvorostovoz.blogspot.com.
Ресурсы рекомендованные в комментах Sofiya Novachenko: istqbexamcertification.com www.testingexcellence.com
Основные положения тестирования / Habr
Области применения, цели и задачи тестирования ПО разнообразны, поэтому тестирование оценивается и объясняется по-разному. Иногда и самим тестировщикам бывает сложно объяснить, что такое тестирование ПО ‘as is’. Возникает путаница.Для распутывания этой путаницы Алексей Баранцев (практик, тренер и консалтер в тестировании ПО; выходец из Института системного программирования Российской академии наук) предваряет свои тренинги по тестированию вводным видео про основные положения тестирования.
Мне кажется, что в этом докладе лектор смог наиболее адекватно и взвешенно объяснить «что такое тестирование» с точки зрения ученого и программиста. Странно, что этот текст еще не появлялся на хабре.
Привожу здесь сжатый пересказ этого доклада. В конце текста есть линки на полную версию, а также на упомянутое видео.
Основные положения тестирования
Уважаемые коллеги,
сначала попробуем понять, чем тестирование НЕ является.
Тестирование не разработка,
даже если тестировщики умеют программировать, в том числе и тесты (автоматизация тестирование = программирование), могут разрабатывать какие-то вспомогательные программы (для себя).
Тем не менее, тестирование — это не деятельность по разработке программного обеспечения.
Тестирование не анализ,
и не деятельность по сбору и анализу требований.
Хотя, в процессе тестирования иногда приходится уточнять требования, а иногда приходится их анализировать. Но эта деятельность не основная, скорее, это приходится делать просто по необходимости.
Тестирование не управление,
несмотря на то, что во многих организациях есть такая роль, как «тест-менеджер». Конечно же, тестировщиками надо управлять. Но само по себе тестирование управлением не является.
Тестирование не техписательство,
однако тестировщикам приходится документировать свои тесты и свою работу.
Тестирование нельзя считать ни одной из этих деятельностей просто потому, что в процессе разработки (или анализа требований, или написания документации для своих тестов) всю эту работу тестировщики делают для себя, а не для кого-то другого.
Деятельность значима только тогда, когда она востребована, то есть тестировщики должны что-то производить «на экспорт». Что они делают «на экспорт»?
Дефекты, описания дефектов, или отчеты о тестировании? Частично это правда.
Но это не вся правда.
Главная деятельность тестировщиков
заключается в том, что они предоставляют участникам проекта по разработке программного обеспечения отрицательную обратную связь о качестве программного продукта.
«Отрицательная обратная связь» не несет какой-то негативный оттенок, и не означает, что тестировщики делают что-то плохое, или что они делают что-то плохо. Это просто технический термин, который обозначает достаточно простую вещь.
Но эта вещь очень значимая, и, наверное, единственная наиболее значимая составляющая деятельности тестировщиков.
Существует наука — «теория систем». В ней определяется такое понятие как «обратная связь».
«Обратная связь» это некоторые данные, которые с выхода попадают обратно на вход, или какая-то часть данных, которые с выхода попадают обратно на вход. Эта обратная связь может быть положительной и отрицательной.
И та, и другая разновидности обратной связи равноценно важны.
В разработке программных систем положительной обратной связью, конечно же, является какая-то информация, которую мы получаем от конечных пользователей. Это запросы на какую-то новую функциональность, это увеличение объема продаж (если мы выпускаем качественный продукт).
Отрицательная обратная связь тоже может поступать от конечных пользователей в виде каких-то негативных отзывов. Либо она может поступать от тестировщиков.
Чем раньше предоставляется отрицательная обратная связь, тем меньше энергии необходимо для модификации этого сигнала. Именно поэтому тестировать нужно начинать как можно раньше, на самых ранних стадиях проекта, и предоставлять эту обратную связь и на этапе проектирования, и еще, может быть, раньше, еще на этапе сбора и анализа требований.
К слову, отсюда и произрастает понимание того, что тестировщики не отвечают за качество. Они помогают тем, кто за него отвечает.
Синонимы термина «тестирование»
С точки зрения того, что тестирование — это предоставление отрицательной обратной связи, всемирно известная аббревиатура QA (англ. Quality Assurance — Обеспечение качества) синонимом термина «тестирование» уж совершенно точно НЕ является.
Нельзя считать обеспечением качества простое предоставление отрицательной обратной связи, ведь Обеспечение — это некоторые позитивные меры. Подразумевается, что в этом случае мы именно обеспечиваем качество, своевременно предпринимаем какие-то меры для того, чтобы качество разработки ПО повысилось.
А вот «контроль качества» — Quality Control, можно считать в широком смысле синонимом для термина «тестирование», потому что контроль качества это и есть предоставление обратной связи в самых разных ее разновидностях, на самых разных этапах программного проекта.
Иногда тестирование подразумевается как некоторая отдельная форма контроля качества.
Путаница приходит из истории развития тестирования. В разное время под термином «тестирование» подразумевались различные действия, которые можно разделить на 2 больших класса: внешние и внутренние.
Внешние определения
Определения, которые в разное время дали Майерс, Бейзер, Канер, описывают тестирование как раз с точки зрения его ВНЕШНЕЙ значимости. То есть, с их точки зрения, тестирование — это деятельность, которая предназначена ДЛЯ чего-то, а не состоит из чего-то. Все три этих определения можно обобщить как предоставление отрицательной обратной связи.
Внутренние определения
Это определения, которые приведены в стандарт терминологии, используемой в программной инженерии, например, в стандарт де-факто, который называется SWEBOK.
Такие определения конструктивно объясняют, ЧТО представляет из себя деятельность по тестированию, но не дают ни малейшего представления о том, ДЛЯ ЧЕГО нужно тестирование, для чего потом будут использоваться все полученные результаты проверки соответствия между реальным поведением программы и ее ожидаемым поведением.
Итак,
тестирование — это
- проверка соответствия программы требованиям,
- осуществляемая путем наблюдения за ее работой
- в специальных, искусственно созданных ситуациях, выбранных определенным образом.
Отсюда и далее будем считать это рабочим определением «тестирования».
Общая схема тестирования примерно следующая:
- Тестировщик на входе получает программу и/или требования.
- Он с ними что-то делает, наблюдает за работой программы в определенных, искуственно созданных им ситуациях.
- На выходе он получает информацию о соответствиях и несоответствиях.
- Далее эта информация используется для того, чтобы улучшить уже существующую программу. Либо для того, чтобы изменить требования к еще только разрабатываемой программе.
Что такое тест
- Это специальная, искусственно созданная ситуация, выбранная определенным образом,
- и описание того, какие наблюдения за работой программы нужно сделать
- для проверки ее соответствия некоторому требованию.
Не нужно считать, что ситуация – это нечто одномоментное. Тест может быть достаточно длинным, например, при тестировании производительности вот эта искусственно созданная ситуация это может быть продолжающаяся в течение достаточно продолжительного времени нагрузка на систему. А наблюдения, которые нужно при этом делать, это набор различных графиков или метрик, которые мы измеряем в процессе выполнения этого теста.
Разработчик тестов занимается тем, что он из огромного потенциально бесконечного набора тестов выбирает некоторый ограниченный набор.
Ну и таким образом мы можем заключить, что тестировщик делает в процессе тестирования две вещи.
1.Во-первых, он управляет выполнением программы и создает эти самые искусственные ситуации, в которых мы собираемся проверять поведение программы.
2.И, во-вторых, он наблюдает за поведением программы и сравнивает то, что он видит с тем, что ожидается.
Если тестировщик автоматизирует тесты, то он не сам наблюдает за поведением программы — он делегирует эту задачу специальному инструменту или специальной программе, которую он сам написал. Именно она наблюдает, она сравнивает наблюдаемое поведение с ожидаемым, а тестировщику выдает только некоторый конечный результат — совпадает ли наблюдаемое поведение с ожидаемым, или не совпадает.
Любая программа представляет собой механизм по переработке информации. На вход поступает информация в каком-то одном виде, на выходе информация в некотором другом виде. При этом входов и выходов у программы может быть много, они могут быть разными, то есть у программы может быть несколько разных интерфейсов, и эти интерфейсы могут иметь разные виды:
- Пользовательский интерфейс (UI)
- Программный интерфейс (API)
- Сетевой протокол
- Файловая система
- Состояние окружения
- События
Наиболее распространенные интерфейсы это
- пользовательский,
- графический,
- текстовый,
- консольный,
- и речевой.
Используя все эти интерфейсы, тестировщик:
- каким-то образом создает искусственные ситуации,
- и проверяет в этих ситуациях как программа себя ведет.
Вот это и есть тестирование.
Другие классификации видов тестирования
Чаще всего используется разбиение на три уровня, это
- модульное тестирование,
- интеграционное тестирование,
- системное тестирование.
Под модульным тестированием обычно подразумевается тестирование на достаточно низком уровне, то есть тестирование отдельных операций, методов, функций.
Под системным тестированием подразумевается тестирование на уровне пользовательского интерфейса.
Иногда используются также некоторые другие термины, такие, как «компонентное тестирование», но я предпочитаю выделять именно эти три, по причине того, что технологическое разделение на модульное и системное тестирование не имеет большого смысла. На разных уровнях могут использоваться одни и те же инструменты, одни и те же техники. Разделение условно.
Практика показывает, что инструменты, которые позиционируются производителем как инструменты модульного тестирования, с равным успехом могут применяться и на уровне тестирования всего приложения в целом.
А инструменты, которые тестируют все приложение в целом на уровне пользовательского интерфейса иногда хотят заглядывать, например, в базу данных или вызывать там какую-то отдельную хранимую процедуру.
То есть разделение на системное и модульное тестирование вообще говоря чисто условное, если говорить с технической точки зрения.
Используются одни и те же инструменты, и это нормально, используются одни и те же техники, на каждом уровне можно говорить о тестировании различного вида.
Комбинируем:
То есть, можно говорить о модульном тестировании функциональности.
Можно говорить о системном тестировании функциональности.
Можно говорить о модульном тестировании, например, эффективности.
Можно говорить о системном тестировании эффективности.
Либо мы рассматриваем эффективность какого-то отдельно взятого алгоритма, либо мы рассматриваем эффективность всей системы в целом. То есть технологическое разделение на модульное и системное тестирование не имеет большого смысла. Потому что на разных уровнях могут использоваться одни и те же инструменты, одни и те же техники.
Наконец, при интеграционном тестировании мы проверяем, если в рамках какой-то системы модули взаимодействуют друг с другом корректно. То есть, мы фактически выполняем те же самые тесты, что и при системном тестировании, только еще дополнительно обращаем внимание на то, как именно модули взаимодействуют между собой. Выполняем некоторые дополнительные проверки. Это единственная разница.
Давайте еще раз попытаемся понять разницу между системным и модульным тестированием. Поскольку такое разделение встречается достаточно часто, эта разница должна быть.
И разница эта проявляется тогда, когда мы выполняем не технологическую классификацию, а классификацию по целям тестирования.
Классификацию по целям удобно выполнять с использованием «магического квадрата», который был изначально придуман Брайаном Мариком и потом улучшен Эри Тенненом.
В этом магическом квадрате все виды тестирования располагаются по четырем квадрантам в зависимости от того, чему в этих тестах больше уделяется внимания.
По вертикали — чем выше располагается вид тестирования, тем больше внимания уделяется некоторым внешним проявлениям поведения программы, чем ниже он находится, тем больше мы внимания уделяем ее внутреннему технологическому устройству программы.
По горизонтали — чем левее находятся наши тесты, тем больше внимания мы уделяем их программированию, чем правее они находятся, тем больше внимания мы уделяем ручному тестированию и исследованию программы человеком.
В частности, в этот квадрат можно легко вписать такие термины как приемочное тестирование, Acceptance Testing, модульное тестирование именно в том понимании, в котором оно чаще всего употребляется в литературе. Это низкоуровневое тестирование с большой, с подавляющей долей программирования. То есть это все тесты программируются, полностью автоматически выполняются и внимание уделяется в первую очередь именно внутреннему устройству программы, именно ее технологическим особенностям.
В правом верхнем углу у нас окажутся ручные тесты, нацеленные на внешнее какое-то поведение программы, в частности, тестирование удобства использования, а в правом нижнем углу у нас, скорее всего, окажутся проверки разных нефункциональных свойств: производительности, защищенности и так далее.
Так вот, исходя из классификации по целям, модульное тестирование у нас оказывается в левом нижнем квадранте, а все остальные квадранты — это системное тестирование.
Спасибо за внимание.
Дополнительно
- Полная расшифровка текста со всеми картинками. Рассказывается о тестировании методом черного и белого ящика, о шести аспектах качества верхнего уровня (функциональность, надежность, практичность, эффективность, сопровождаемость, переносимость), о критериях полноты тестирования.
- Видео-версия доклада: тут (ее можно и смотреть, и скачать как .wmv).
- Если интересно: проводится распродажа записей вебинаров Баранцева.
Автоматическое тестирование программ / Habr
Введение
Долгое время считалось, что динамический анализ программ является слишком тяжеловесным подходом к обнаружению программных дефектов, и полученные результаты не оправдывают затраченных усилий и ресурсов. Однако, две важные тенденции развития современной индустрии производства программного обеспечения позволяют по-новому взглянуть на эту проблему. С одной стороны, при постоянном увеличении объема и сложности ПО любые автоматические средства обнаружения ошибок и контроля качества могут оказаться полезными и востребованными. С другой – непрерывный рост производительности современных вычислительных систем позволяет эффективно решать все более сложные вычислительные задачи. Последние исследовательские работы в области динамического анализа такие, как SAGE, KLEE и Avalanche, демонстрируют, что несмотря на присущую этому подходу сложность, его использование оправдано, по крайней мере, для некоторого класса программ.
Динамический vs Статический анализ
В качестве более эффективной альтернативы динамическому анализу часто рассматривают статический анализ. В случае статического анализа поиск возможных ошибок осуществляется без запуска исследуемой программы, например, по исходному коду приложения. Обычно при этом строится абстрактная модель программы, которая, собственно, и является объектом анализа.
При этом следует подчеркнуть следующие характерные особенности статического анализа:
- Возможен раздельный анализ отдельно взятых фрагментов программы (обычно отдельных функций или процедур), что дает достаточно эффективный способ борьбы с нелинейным ростом сложности анализа.
- Возможны ложные срабатывания, обусловленные либо тем, что при построении абстрактной модели некоторые детали игнорируются, либо тем, что анализ модели не является исчерпывающим.
- При обнаружении дефекта возникают, во-первых, проблема проверки истинности обнаруженного дефекта (false positive) и, во-вторых, проблема воспроизведения найденного дефекта при запуске программы на определенных входных данных.
В отличие от статического анализа, динамический анализ осуществляется во время работы программы. При этом:
- Для запуска программы требуются некоторые входные данные.
- Динамический анализ обнаруживает дефекты только на трассе, определяемой конкретными входными данными; дефекты, находящиеся в других частях программы, не будут обнаружены.
- В большинстве реализаций появление ложных срабатываний исключено, так как обнаружение ошибки происходит в момент ее возникновения в программе; таким образом, обнаруженная ошибка является не предсказанием, сделанным на основе анализа модели программы, а констатацией факта ее возникновения.
Применение
Автоматическое тестирование в первую очередь предназначено для программ, для которых работоспособность и безопасность при любых входных данных являются наиважнейшими приоритетами: веб-сервер, клиент/сервер SSH, sandboxing, сетевые протоколы.
Fuzz testing (фаззинг)
Фаззинг – методика тестирования, при которой на вход программы подаются невалидные, непредусмотренные или случайные данные.
Основная идея такого подхода состоит в том, чтобы случайным образом “мутировать”, т.е. изменять ожидаемые программой входные данные в произвольных местах. Все фаззеры работают примерно одинаковым образом, позволяя задавать некоторые ограничения на мутирование входных данных определенными байтами или последовательностью байтов. В качестве примера можно упомянуть:zzuf (linux), minifuzz (Windows), filefuzz (Windows). Фаззеры протоколов: PROTOS(WAP, HTTP-reply, LDAP, SNMP, SIP) (Java), SPIKE (linux) . Фреймворки фаззеров: Sulley (фреймворк для создания сложных структур данных).
Fuzz testing – предтеча автоматического тестирования, метод “грубой силы”. Из преимуществ данного подхода выделяется только его простота. Очевидным же недостатком является то, что фаззер ничего не знает о внутреннем устройстве программы и, в конечном итоге, для полного покрытия кода вынужден перебирать астрономическое количество вариантов (как нетрудно догадаться, полный перебор растет экспоненциально от размера входных данных O(c^n),c>1).
Фаззеры нового поколения (обзор)
Логическим, но не таким простым продолжением идеи автоматического тестирования стало появление подходов и программ, позволяющих накладывать ограничения на мутируемые входные данные с учетом специфики исследуемой программы.
Отслеживание помеченных данных в программе
Вводится понятие символических или помеченных (tainted) данных – данных, полученных программой из внешнего источника (стандартный поток ввода, файлы, переменные окружения и т. д.). Распространенным решением этой задачи является перехват набора системных вызовов: open, close, read, write, lseek (Avalanche,KLEE).
Инструментация кода
Код исследуемой программы приводится к виду, удобному для анализа. Например, используется внутреннее независимое от аппаратной платформы представление valgrind (Avalanche) или анализируется удобный для разбора сам по себе llvm-байткод программы(KLEE).
Инструментированный код позволяет легко находить потенциально опасные инструкции (например, деление на ноль или разыменование нулевого указателя) и их операнды, а также инструкции ветвления, зависящие от помеченных данных. Анализируя инструкции, инструмент составляет логические условия на помеченные данные и передает запрос на выполнимость “решателю” булевских формул (SAT Solver).
Решение булевских ограничений
SAT Solvers – решают задачи выполнимости булевых формул. Отвечают на вопрос: всегда ли выполнена заданная формула, и если не всегда, то выдается набор значений, на котором она ложна. Результаты работы подобных решателей используется широким набором анализирующих программ, от theorem provers до анализаторов генетического кода в биоинформатике. Подобные программы интересны сами по себе и требуют отдельного рассмотрения. Примеры: STP, MiniSAT.
Моделирование окружения
Кроме перехвата системных вызовов, для автоматической генерации условий для “решателя” булевских формул, анализаторам необходимо формализовать задачу. Входной файл, набор регистров и адресное пространство (память) программы представляются c помощью массивов булевского “решателя”.
Перебор путей в программе
Получив ответ от “решателя”, инструмент получает условие на входные данные для инвертирования исследуемого условного перехода или выясняет, что оно всегда истинно или ложно. Каждый вариант условия создает новый независимый путь в программе, и программе приходится рассматривать каждый путь и условия для его выполнения независимо, т.е. пути “форкаются” на каждой инструкции ветвления, зависящей от входных данных. Новые входные данные могут открыть ранее не открытые базовые блоки исследуемой программы и так далее. Для исчерпывающего тестирования необходим полный перебор всех возможных путей в программе. Так как скорость роста количества путей хоть и значительно снизилась по сравнению с методом грубой силы (~O(2^n), где n – количество условных переходов, зависящих от входных данных), но все еще остается значительной. Анализаторы вынуждены использовать различные эвристики для приоритезации анализа некоторых путей. В частности, различают выбор пути, покрывающего наибольшее количество непокрытых (новых) базовых блоков (Avalanche, KLEE) и выбор случайного пути (KLEE).
Avalanche
Avalanche – инструмент обнаружения программных дефектов при помощи динамического анализа. Avalanche использует возможности динамической инструментации программы, предоставляемые Valgrind, для сбора и анализа трассы выполнения программы. Результатом такого анализа становится либо набор входных данных, на которых в программе возникает ошибка, либо набор новых тестовых данных, позволяющий обойти ранее не выполнявшиеся и, соответственно, еще не проверенные фрагменты программы. Таким образом, имея единственный набор тестовых данных, Avalanche реализует итеративный динамический анализ, при котором программа многократно выполняется на различных, автоматически генерированных тестовых данных, при этом каждый новый запуск увеличивает покрытие кода программы такими тестами.
Общая схема работы
Инструмент Avalanche состоит из 4 основных компонент: двух модулей расширения (плагинов) Valgrind – Tracegrind и Covgrind, инструмента проверки выполнимости ограничений STP и управляющего модуля.
Tracegrind динамически отслеживает поток помеченных данных в анализируемой программе и собирает условия для обхода ее непройденных частей и для срабатывания опасных операций. Эти условия при помощи управляющего модуля передаются STP для исследования их выполнимости. Если какое-то из условий выполнимо, то STP определяет те значения всех входящих в условия переменных (в том числе и значения байтов входного файла), которые обращают условие в истину.
- В случае выполнимости условий для срабатывания опасных операций программа запускается управляющим модулем повторно (на этот раз без какой-либо инструментации) с соответствующим входным файлом для подтверждения найденной ошибки.
- Выполнимые условия для обхода непройденных частей программы определяют набор возможных входных файлов для новых запусков программы. Таким образом, после каждого запуска программы инструментом STP автоматически генерируется множество входных файлов для последующих запусков анализа.
- Далее встает задача выбора из этого множества наиболее “интересных” входных данных, т.е. в первую очередь должны обрабатываться входные данные, на которых наиболее вероятно возникновение ошибки. Для решения этой задачи используется эвристическая метрика – количество ранее не обойденных базовых блоков в программе (базовый блок здесь понимается в том смысле, как его определяет фреймворк Valgrind). Для измерения значения эвристики используется компонент Covgrind, в функции которого входит также фиксация возможных ошибок выполнения. Covgrind гораздо более легковесный модуль, нежели Tracegrind, поэтому возможно сравнительно быстрое измерение значения эвристики для всех полученных ранее входных файлов и выбор входного файла с ее наибольшим значением.
Ограничения
- один помеченный входной файл или сокет
- анализ ошибок ограничен разыменованием нулевого указателя и делением на ноль.
Результаты
Эффективность поиска ошибок при помощи Avalanche была исследована на большом числе проектов с открытым исходным кодом.
- qtdump (libquicktime-1.1.3). Три дефекта связаны с разыменованием нулевого указателя, один – с наличием бесконечного цикла, еще в одном случае имеет место обращение по некорректному адресу (ошибка сегментации). Часть дефектов исправлена разработчиком.
- flvdumper (gnash-0.8.6). Непосредственное возникновение дефекта связано с появлением исключительной ситуации в используемой приложением библиотеке boost (один из внутренних указателей библиотеки boost оказывается равен нулю). Поскольку само приложение не перехватывает возникшее исключение, выполнение программы завершается с сигналом SIGABRT. Дефект исправлен разработчиком.
- cjpeg (libjpeg7). Приложение читает из файла нулевое значение и без соответствующей проверки использует его в качестве делителя, что приводит к возникновению исключения плавающей точки и завершению программы с сигналом SIGFPE. Дефект исправлен разработчиком.
- swfdump (swftools-0.9.0). Возникновение обоих дефектов связано с разыменованием нулевого указателя.
KLEE
KLEE несколько отличается от Avalanche тем, что не ищет подозрительные места, а пытается покрыть как можно больше кода и провести исчерпывающий анализ путей в программе. По общей схема KLEE аналогичен Avalanche, но использует другие базовые инструменты для решения задачи, что накладывает свои ограничения и дает свои преимущества.
- Вместо инструментации valgrind’а, которую использует Avalanche, KLEE анализурует программы в llvm-байткоде. Соответственно, это позволяет анализировать программу на любом языке программирования, для которого есть llvm-бэкэнд.
- Для решения задачи булевских ограничений KLEE так же использует STP.
- KLEE так же перехватывает около 50 системных вызовов, позволяя выполняться множеству виртуальных процессов параллельно, не мешая друг другу.
- Оптимизация и кэширование запросов к STP.
KLEE представляет собой символическую виртуальную машину, где параллельно выполняются символические процессы (в рамках терминологии KLEE: states), где каждый процесс представляет собой один из путей в исследуемой программе. Эффективная реализация форков таких процессов (не средствами системы) на каждом ветвлении в программе, позволяет анализировать большое количество путей одновременно.
Для каждого уникального пройденного пути KLEE сохраняет набор входных данных, необходимых для прохождения по этому пути.
Возможности KLEE позволяют с малыми затратами (предоставляется обширный API) проверить эквивалентность любых двух функций (проверка идентичной функциональности по работающему прототипу, рефакторинг) на всем диапазоне заданных входных данных.
Следующий пример иллюстрирует данную функциональность:
unsigned mod_opt(unsigned x, unsigned y) {
if((y & −y) == y) // power of two?
return x & (y−1);
else
return x % y;
}
unsigned mod(unsigned x, unsigned y) {
return x % y;
}
int main() {
unsigned x,y;
make symbolic(&x, sizeof(x));
make symbolic(&y, sizeof(y));
assert(mod(x,y) == mod_opt(x,y));
return 0;
}
Запустив KLEE на данном примере, можно убедится в эквивалентности двух функций во всем диапазоне входных значений (y!=0). Решая задачу на невыполнение условия в ассерте, KLEE на основе перебора всех возможных путей приходит к выводу об эквивалентности двух функций на всем диапазоне значений.
Результаты
Для получения реальных результатов тестирования авторы проанализировали весь набор программ пакета coreutils 6.11. Средней процент покрытия кода составил 94%. Всего программа сгенерировала 3321 набор входных данных, позволяющих покрыть весь указанный процент кода. Так же было найдено 10 уникальных ошибок, которые были признаны разработчиками пакета как реальные дефекты в программах, что является очень хорошим достижением, так как этот набор программ разрабатывается более 20 лет и большинство ошибок было устранено.
Ограничения
- нет поддержки многопоточных приложений, символических данных с плавающей точкой (ограничение STP), ассемблерные вставки.
- тестируемое приложение должно быть собрано в llvm-байт код (так же как и его библиотеки!).
- для эффективного анализа нужно править код.
Предварительные выводы
Безусловно, динамический анализ найдет свою нишу среди инструментов помогающих отдельным программистам и командам программистов решать поставленную задачу, т.к. является эффективным способом нахождения ошибок в программах, а так же доказательством их отсутствия! В в некоторых случаях подобные инструменты просто жизненно необходимы (Mission critical software: RTOS, системы управления производством, авиационное программное обеспечение и так далее).
Заключение
Планируется продолжение тематики статьи (результаты некоторого опыта работы с avalanche и KLEE, а также сравнение KLEE и Avalanche, обзор S2E (https://s2e.epfl.ch) (Selection Symbolic Execution)) при условии положительной обратной связи с читателями Хабра.
Статья содержит фрагменты следующих работ: avalanche_article, KLEE, Применение fuzz-тестирования.
Виды тестирования и подходы к их применению / Habr
Из институтского курса по технологиям программирования я вынес следующую классификацию видов тестирования (критерий — степень изолированности кода). Тестирование бывает:- Блочное (Unit testing) — тестирование одного модуля в изоляции.
- Интеграционное (Integration Testing) — тестирование группы взаимодействующих модулей.
- Системное (System Testing) — тестирование системы в целом.
Блочное (модульное, unit testing) тестирование наиболее понятное для программиста. Фактически это тестирование методов какого-то класса программы в изоляции от остальной программы.
Не всякий класс легко покрыть unit тестами. При проектировании нужно учитывать возможность тестируемости и зависимости класса делать явными. Чтобы гарантировать тестируемость можно применять TDD методологию, которая предписывает сначала писать тест, а потом код реализации тестируемого метода. Тогда архитектура получается тестируемой. Распутывание зависимостей можно осуществить с помощью Dependency Injection. Тогда каждой зависимости явно сопоставляется интерфейс и явно определяется как инжектируется зависимость — в конструктор, в свойство или в метод.
Для осуществления unit тестирования существуют специальные фреймворки. Например, NUnit или тестовый фреймфорк из Visual Studio 2008. Для возможности тестирования классов в изоляции существуют специальные Mock фреймворки. Например, Rhino Mocks. Они позволяют по интерфейсам автоматически создавать заглушки для классов-зависимостей, задавая у них требуемое поведение.
По unit тестированию написано много статей. Мне очень нравится MSDN статья Write Maintainable Unit Tests That Will Save You Time And Tears, в которой хорошо и понятно рассказывается как создавать тесты, поддерживать которые со временем не становится обременительно.
Интеграционное тестирование, на мой взгляд, наиболее сложное для понимания. Есть определение — это тестирование взаимодействия нескольких классов, выполняющих вместе какую-то работу. Однако как по такому определению тестировать не понятно. Можно, конечно, отталкиваться от других видов тестирования. Но это чревато.
Если к нему подходить как к unit-тестированию, у которого в тестах зависимости не заменяются mock-объектами, то получаем проблемы. Для хорошего покрытия нужно написать много тестов, так как количество возможных сочетаний взаимодействующих компонент — это полиномиальная зависимость. Кроме того, unit-тесты тестируют как именно осуществляется взаимодействие (см. тестирование методом белого ящика). Из-за этого после рефакторинга, когда какое-то взаимодействие оказалось выделенным в новый класс, тесты рушатся. Нужно применять менее инвазивный метод.
Подходить же к интеграционному тестированию как к более детализированному системному тоже не получается. В этом случае наоборот тестов будет мало для проверки всех используемых в программе взаимодействий. Системное тестирование слишком высокоуровневое.
Хорошая статья по интеграционному тестированию мне попалась лишь однажды — Scenario Driven Tests. Прочтя ее и книгу Ayende по DSL DSLs in Boo, Domain-Specific Languages in .NET у меня появилась идея как все-таки устроить интеграционное тестирование.
Идея простая. У нас есть входные данные, и мы знаем как программа должна отработать на них. Запишем эти знания в текстовый файл. Это будет спецификация к тестовым данным, в которой записано, какие результаты ожидаются от программы. Тестирование же будет определять соответствие спецификации и того, что действительно находит программа.
| Проиллюстрирую на примере. Программа конвертирует один формат документа в другой. Конвертирование хитрое и с кучей математических расчетов. Заказчик передал набор типичных документов, которые ему требуется конвертировать. Для каждого такого документа мы напишем спецификацию, где запишем всякие промежуточные результаты, до которых дойдет наша программа при конвертировании. 1) Допустим в присланных документах есть несколько разделов. Тогда в спецификации мы можем указать, что у разбираемого документа должны быть разделы с указанными именами:
2) Другой пример. При конвертировании нужно разбивать геометрические фигуры на примитивы. Разбиение считается удачным, если в сумме все примитивы полностью покрывают оригинальную фигуру. Из присланных документов выберем различные фигуры и для них напишем свои спецификации. Факт покрываемости фигуры примитивами можно отразить так:
|
Данный вид тестирования является интеграционным, так как при проверке вызывается код взаимодействия нескольких классов. Причем важен только результат взаимодействия, а не детали и порядок вызовов. Поэтому на тесты не влияет рефакторинг кода. Не происходит избыточного или недостаточного тестирования — тестируются только те взаимодействия, которые встречаются при обработке реальных данных. Сами тесты легко поддерживать, так как спецификация хорошо читается и ее просто изменять в соответствии с новыми требованиями.
Системное — это тестирование программы в целом. Для небольших проектов это, как правило, ручное тестирование — запустил, пощелкал, убедился, что (не) работает. Можно автоматизировать. К автоматизации есть два подхода.
Первый подход — это использовать вариацию MVC паттерна — Passive View (вот еще хорошая статья по вариациям MVC паттерна) и формализовать взаимодействие пользователя с GUI в коде. Тогда системное тестирование сводится к тестированию Presenter классов, а также логики переходов между View. Но тут есть нюанс. Если тестировать Presenter классы в контексте системного тестирования, то необходимо как можно меньше зависимостей подменять mock объектами. И тут появляется проблема инициализации и приведения программы в нужное для начала тестирования состояние. В упомянутой выше статье Scenario Driven Tests об этом говорится подробнее.
Второй подход — использовать специальные инструменты для записи действий пользователя. То есть в итоге запускается сама программа, но щелканье по кнопкам осуществляется автоматически. Для .NET примером такого инструмента является White библиотека. Поддерживаются WinForms, WPF и еще несколько GUI платформ. Правило такое — на каждый use case пишется по скрипту, который описывает действия пользователя. Если все use case покрыты и тесты проходят, то можно сдавать систему заказчику. Акт сдачи-приемки должен подписать.
Методы тестирования программного обеспечения — Блог веб-программиста
- Подробности
- марта 31, 2016
- Просмотров: 153629
Тестирование программного обеспечения — это оценка разрабатываемого программного обеспечения/продукта, чтобы проверить его возможности, способности и соответствие ожидаемым результатам. Существуют различные типы методов, используемые в области тестирования и обеспечения качества о них и пойдет речь в данной статье.
Тестирование программного обеспечения является неотъемлемой частью цикла разработки программного обеспечения.
Что такое тестирование программного обеспечения?
Тестирование программного обеспечения — это не что иное, как испытание куска кода к контролируемым и неконтролируемым условиям эксплуатации, наблюдение за выходом, а затем изучение, соответствует ли он предварительно определенным условиям.
Различные наборы тест-кейсов и стратегий тестирования направлены на достижение одной общей цели — устранение багов и ошибок в коде, и обеспечения точной и оптимальной производительности программного обеспечения.
Методика тестирования
Широко используемыми методами тестирования являются модульное тестирование, интеграционное тестирование, приемочное тестирование, и тестирование системы. Программное обеспечение подвергается этим испытаниям в определенном порядке.
1) Модульное тестирование
2) Интеграционное тестирование
3) Системное тестирование
4) Приемочные испытания
Модульное тестирование
В первую очередь проводится модульный тест. Как подсказывает название, это метод испытания на объектном уровне. Отдельные программные компоненты тестируются на наличие ошибок. Для этого теста требуется точное знание программы и каждого установленного модуля. Таким образом, эта проверка осуществляется программистами, а не тестерами. Для этого создаются тест-коды, которые проверяют, ведет ли программное обеспечение себя так, как задумывалось.
Интеграционное тестирование
Отдельные модули, которые уже были подвергнуты модульному тестированию, интегрируются друг с другом, и проверяются на наличие неисправностей. Такой тип тестирования в первую очередь выявляет ошибки интерфейса. Интеграционное тестирование можно осуществлять с помощью подхода «сверху вниз», следуя архитектурному сооружению системы. Другим подходом является подход «снизу вверх», который осуществляется из нижней части потока управления.
Системное тестирование
В этом тестировании, вся система проверяется на наличие ошибок и багов. Этот тест осуществляется путем сопряжения аппаратных и программных компонентов всей системы, и затем выполняется ее проверка. Это тестирование числится под методом тестирования «черного ящика», где проверяются ожидаемые для пользователя условия работы программного обеспечения.
Приемочные испытания
Это последний тест, который проводится перед передачей программного обеспечения клиенту. Он проводится, чтобы гарантировать, что программное обеспечение, которое было разработано отвечает всем требованиям заказчика. Существует два типа приемо-сдаточных испытаний — то, которое осуществляется членами команды разработчиков, известно, как внутреннее приемочное тестирования (Альфа-тестирование), а другое, которое проводится заказчиком, известно, как внешнее приемочное тестирования.
Если тестирование проводится с помощью предполагаемых клиентов, оно называется приемочными испытаниями клиента. В случае если тестирование проводится конечным пользователем программного обеспечения, оно известно, как приемочное тестирование (бета-тестирование).
Основные тесты
Есть несколько основных методов тестирования, которые формируют часть режима тестирования программного обеспечения. Эти тесты обычно считаются самодостаточными в поиске ошибок и багов во всей системе.
Тестирование методом черного ящика
Тестирование методом черного ящика осуществляется без каких-либо знаний внутренней работы системы. Тестер будет стимулировать программное обеспечение для пользовательской среды, предоставляя различные входы и тестируя сгенерированные выходы. Этот тест также известен как Black-box, closed-box тестирование или функциональное тестирование.
Тестирование методом белого ящика
Тестирование методом «Белого ящика», в отличие от «черного ящика», учитывает внутреннее функционирование и логику работы кода. Для выполнения этого теста, тестер должен иметь знания кода, чтобы узнать точную часть кода, имеющую ошибки. Этот тест также известен как White-box, Open-Box или Glass box тестирование.
Подробнее о тестирование методом белого ящика
Тестирование методом серого ящика
Тестирование методом серого ящика или Gray box тестирование, это что-то среднее между White Box и Black Box тестированием, где тестер обладает лишь общими знаниями данного продукта, необходимыми для выполнения теста. Эта проверка осуществляется посредством документации и схемы информационных потоков. Тестирование проводится конечным пользователем, или пользователям, которые представляются как конечные.
Нефункциональные тесты
Тестирование безопасности
Безопасность приложения является одной из главных задач разработчика. Тестирование безопасности проверяет программное обеспечение на обеспечение конфиденциальности, целостности, аутентификации, доступности и безотказности. Индивидуальные испытания проводятся в целях предотвращения несанкционированного доступа в программный код.
Стресс-тестирование
Стресс-тестирование является методом, при котором программное обеспечение подвергается воздействию условий, которые выходят за рамки нормальных условий работы программного обеспечения. После достижения критической точки, полученные результаты записываются. Этот тест определяет устойчивость всей системы.
Тестирование на совместимость
Программное обеспечение проверяется на совместимость с внешними интерфейсами, такими как операционные системы, аппаратные платформы, веб-браузеры и т.д. Тест на совместимость проверяет, совместим ли продукт с любой программной платформой.
Тестирование эффективности
Как подсказывает название, эта методика тестирования проверяет объем кода или ресурсов, которые используются программой при выполнении одной операции.
Юзабилити-тестирование
Это тестирование проверяет аспект удобства и практичности программного обеспечения для пользователей. Легкость, с которой пользователь может получить доступ к устройству формирует основную точку тестирования. Юзабилити-тестирование охватывает пять аспектов тестирования, — обучаемость, эффективность, удовлетворенность, запоминаемость, и ошибки.
Тесты в процессе разработки программного обеспечения
Каскадная модель
Каскадная модель использует подход «сверху-вниз», независимо от того, используется ли она для разработки программного обеспечения или для тестирования.
Основными шагами, участвующими в данной методике тестирования программного обеспечения, являются:
- Анализ потребностей
- Тест дизайна
- Тест реализации
- Тестирование, отладка и проверка кода или продукта
- Внедрение и обслуживание
В этой методике, вы переходите к следующему шагу только после того, как вы завершили предыдущий. В модели используется не-итерационный подход. Основным преимуществом данной методики является ее упрощенный, систематический и ортодоксальный подход. Тем не менее, она имеет много недостатков, так как баги и ошибки в коде не будут обнаружены до этапа тестирования. Зачастую это может привести к потере времени, денег, и других ценных ресурсов.
Agile Model
Эта методика основана на избирательном сочетании последовательного и итеративного подхода, в дополнение к довольно большому разнообразию новых методов развития. Быстрое и поступательное развитие является одним из ключевых принципов этой методологии. Акцент делается на получение быстрых, практичных, и видимых выходов. Непрерывное взаимодействие с клиентами и участие является неотъемлемой частью всего процесса разработки.
Rapid Application Development (RAD). Методология быстрой разработки приложений
Название говорит само за себя. В этом случае методология принимает стремительный эволюционный подход, используя принцип компонентной конструкции. После понимания различных требований данного проекта, готовится быстрый прототип, а затем сравнивается с ожидаемым набором выходных условий и стандартов. Необходимые изменения и модификации вносятся после совместного обсуждения с заказчиком или группой разработчиков (в контексте тестирования программного обеспечения).
Хотя этот подход имеет свою долю преимуществ, он может быть неподходящим, если проект большой, сложный, или имеет чрезвычайно динамический характер, в котором требования постоянно меняются.
Спиральная модель
Как видно из названия, спиральная модель основана на подходе, в котором есть целый ряд циклов (или спиралей) из всех последовательных шагов в каскадной модели. После того, как начальный цикл будет завершена, выполняется тщательный анализ и обзор достигнутого продукта или выхода. Если выход не соответствует указанным требованиям или ожидаемым стандартам, производится второй цикл, и так далее.
Rational Unified Process (RUP). Рациональный унифицированный процесс
Методика RUP также похожа на спиральную модель, в том смысле, что вся процедура тестирования разбивается на несколько циклов. Каждый цикл состоит из четырех этапов — создание, разработка, строительство, и переход. В конце каждого цикла продукт/выход пересматривается, и далее цикл (состоящий из тех же четырех фаз) следует при необходимости.
Применение информационных технологий растет с каждым днем, также и важность правильного тестирования программного обеспечения выросло в разы. Многие фирмы содержат для этого штат специальных команд, возможности которых находятся на уровне разработчиков.
Читайте также