Как быстро реализовать поиск на корпоративном портале / Хабр
Привет, меня зовут Антон Щербак, я разработчик корпоративного портала Selectel. Это внутренняя система, где можно узнать новости компании, поучаствовать в Selectel Game (это наша собственная геймификация рабочих достижений) и, конечно, найти необходимого коллегу или структуру.
Нас уже более 700, и иногда поиск человека превращается в выпуск ток-шоу «Жди меня». Поэтому у нас была задача сделать его более удобным и приводящим к нужному результату. Под катом рассказываю, к какому решению мы в итоге пришли и как реализовали.
Итак, наша цель — сделать поиск на портале более удобным и функциональным. Пользователи — сотрудники компании — хотели бы искать коллег по:
- ФИО,
- департаменту,
- телеграм-аккаунту,
- номеру телефона,
- логину,
- должности.
Причем частенько сотрудники ищут кого-то с неправильной раскладкой клавиатуры.
О базе данных
В работе наша команда использует СУБД PostgreSQL, которую админят DevOps-инженеры Selectel. По сути, мы пользуемся облачными базами данных, которые доступны и нашим клиентам.
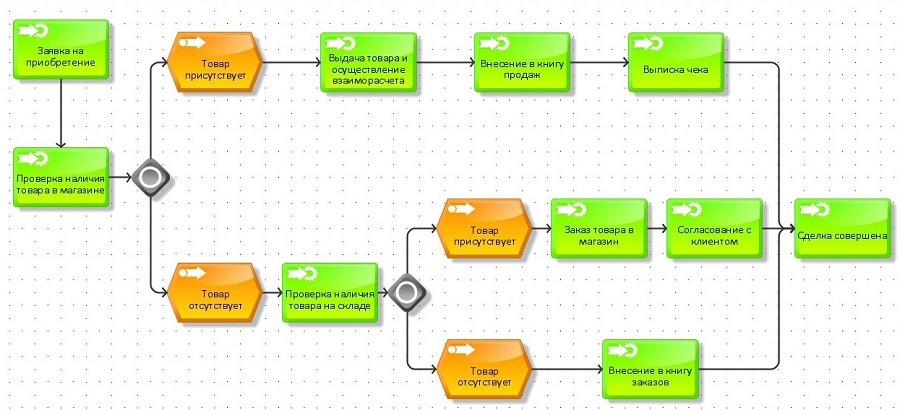
Структура базы данных, которая затрагивается в этой задаче, выглядит примерно так:
Что мы имеем? Данные расположены в разных табличках и связаны отношениями М2М. Всего в поиске задействовано 7 таблиц, и каждая имеет поле активных записей.
Количество записей в каждой из таблиц не более 2 000, и в ближайшее время это число не вырастет. Хоть Selectel и нанимает неплохое число новых сотрудников каждую неделю, но +1 000 людей в ближайшее время точно не наймет. А значит, изменений в числе запросов пока не предвидится.
Осталось разобраться, какой способ организации поиска выбрать, чтобы собрать все данные в простую строчку.
Краткий обзор подходов к поиску
Поиск с использованием ILIKE
Описание этого подхода довольно простое: «А давайте просто сделаем SELECT … FROM … WHERE column ILIKE ‘%pattern%’»
Для тех, кто мало с ним знаком, ILIKE — это оператор регистронезависимого сравнения по шаблону. Если паттерн совпал со значением в колонке, он возвращает TRUE.
Преимущества
- Подход очень удобен, когда данных не очень много.
- Не требует дополнительных настроек для работы.
- Такой вариант хорошо использовать, когда данные экранированы и не подвергаются всяким склонениям и прочим морфологическим изменениям.
- И в целом для организации простого поиска он подходит как нельзя лучше.
Недостатки
- Эффективность поиска падает при росте количества данных.
- Очень сложно как-то расширять и усложнять поиск (если например требуется учет морфологии, либо поиск с опечатками)
- Есть небольшие нюансы, связанные с сортировкой данных после поиска. О них я расскажу далее.
Полнотекстовый поиск на PostgreSQL
PostgreSQL обладает отличным встроенным полнотекстовым движком с хорошей документацией и шикарным API. Полнотекстовый поиск очень полезен в двух случаях:
- требуется искать по тексту с учетом морфологии слова. К примеру, по запросу «собака» поиск должен также найти слова «собачий», «собачка» и т.д.,
- требуется неточный поиск (fuzzy search), когда в тексте могут быть опечатки.
Для организации полнотекстового поиска в PostgreSQL нужно создать новый столбец векторного типа. В нем будут храниться векторы, созданные из лексем слов текста для каждой строки в таблице. Потом по этому вектору строится GIN-индекс, чтобы поиск работал быстро, и пишется триггер, который будет создавать поисковый вектор для каждой новой записи. Также можно использовать автогенерируемые колонки для PostgreSQL 12 версии и старше.
Также можно использовать автогенерируемые колонки для PostgreSQL 12 версии и старше.
Преимущества
- Простая настройка, так как в наших проектах используется PostgreSQL и не требуется подключение дополнительного инструментария.
- Поддержка морфологии и поиска с опечатками. Это позволит расширять сложность поиска.
- Лучшая поддержка консистентности данных за счет хранения векторов в той же базе данных. Меньше головной боли.
- По производительности превосходит оператор LIKE.
Недостатки
- Производительность падает при аналитике больших документов.
- Масштабирование нагрузки поиска и его индексации приходится делать в том же сервисе.
Полнотекстовый поиск с использованием NoSQL поисковых движков по типу ElasticSearch
ElasticSearch — это мощный инструмент поиска документов. Решение делалось специально для поиска и особо эффективно, когда данных очень много.
Преимущества
- Недостатки PostgreSQL тут не актуальны.
- Хорошая устойчивость к изменениям в модели, так как решение отделено от основного хранилища данных.
Недостатки
- Нужно передавать содержимое базы данных внешним поисковым системам.
- Нужно следить за согласованностью данных. Могут быть ситуации, когда поиск находит уже удаленные или деактивированные в БД данные.
Для организации поиска на корпоративном портале (не путать с основным сайтом selectel.ru) больше всего подходит написание запроса с использованием ILIKE. Выбор обусловлен тем, что:
- Данных мало.
- Данные экранированы, а значит, морфологический разбор нам не нужен.

- Хочется сохранить консистентность данных на высоком уровне.
- Должности, департаменты и логины в социальных сетях часто меняются.
- Этот вариант наименее трудозатратен и не требует дополнительных настроек.
- Лучшая производительность полнотекстового поиска PostgreSQL не раскрывается в полной мере на маленьком количестве данных.
Программная реализация
Первым делом напишем запрос для базы данных, который будет отдавать информацию по поисковому запросу.
Будем писать его, разбив на части и постепенно наращивая объем. Так будет понятно, какая из частей какую задачу решает.
Начнем с простого и выполним поиск по ФИО. Он должен выдавать нам результаты на поисковые запросы вида:
антон
щербак
антон щербак
щербак антон
щербак а
антон щ
Запрос:
select users.id, concat_ws(' ', users.surname, users. name) as display_name
from users
where concat_ws(' ', users.surname, users.name) ilike :pattern
or concat_ws(' ', users.name, users.surname) ilike :pattern
name) as display_name
from users
where concat_ws(' ', users.surname, users.name) ilike :pattern
or concat_ws(' ', users.name, users.surname) ilike :patternPattern будет равен ‘{string}%’ (например ‘антон%’), чтобы искать строки, которые начинаются на заданный шаблон. В этом случае наш поиск не будет отдавать нерелевантные данные, если пользователь ввел, например «наст», а получил пользователя «Конастов Виктор».
Но если это не критично, то, думаю, можно использовать шаблон ‘%{string}%’ для получения полного объема данных, который совпадает с шаблоном. Либо же для каких-то полей искать только те строки, где одинаковое именно начало шаблона, а уже в других полное вхождение.
Пример:
departments.name ilike ‘%корп%’ or users.surname ilike ‘корп%’
В примере выше поиск найдет например «Отдел разработки корпоративного портала», но не найдет пользователя в фамилией «Стокорпин».
Теперь добавим поиск по департаменту. Для этого нужно приклеить новую табличку:
Для этого нужно приклеить новую табличку:
select users.id, concat_ws(' ', users.surname, users.name) as display_name
from users
join users_departments on (users_departments.is_active = true and users_departments.user_id = users.id)
join departments on (users_departments.department_id = departments.id)
where (
(concat_ws(' ', users.surname, users.name) ilike :pattern
or concat_ws(' ', users.name, users.surname) ilike :pattern)
or
departments.name ilike :pattern
)
Поле is_active со значением true одно в департаментах и должностях, поэтому дубликатов при склейке не возникает и необходимость outerjoin также пропадает.
Добавим поиск по телеграм-аккаунту к нашему запросу:
select users.id, concat_ws(' ', users.surname, users.name) as display_name
from users
join users_departments on (users_departments.is_active = true and users_departments.user_id = users.id)
join departments on (users_departments.department_id = departments. id)
join users_socials on (users_socials.is_active = true and users_socials.user_id = users.id and users_socials.social_id=:telegram_social_id)
where (
(concat_ws(' ', users.surname, users.name) ilike :pattern or concat_ws(' ', users.name, users.surname) ilike :pattern)
or
departments.name ilike :pattern
or
users_socials.social_login ilike :pattern
)
id)
join users_socials on (users_socials.is_active = true and users_socials.user_id = users.id and users_socials.social_id=:telegram_social_id)
where (
(concat_ws(' ', users.surname, users.name) ilike :pattern or concat_ws(' ', users.name, users.surname) ilike :pattern)
or
departments.name ilike :pattern
or
users_socials.social_login ilike :pattern
)
И оставшиеся поля:
select users.id, concat_ws(' ', users.surname, users.name) as display_name
from users
join users_departments on (users_departments.is_active = true and users_departments.user_id = users.id)
join departments on (users_departments.department_id = departments.id)
join users_socials on (users_socials.is_active = true and users_socials.user_id = users.id and users_socials.social_id=:telegram_social_id)
join users_positions on (users_positions.is_active = true and users.id=users_positions.user_id)
join positions on users_positions.position_id = positions.id
where (
(concat_ws(' ', users.
surname, users.name) ilike :pattern or concat_ws(' ', users.name, users.surname) ilike :pattern)
or
departments.name_ru ilike :pattern
or
users_socials.social_login ilike :pattern
or
positions.name ilike :pattern
or
users.login ilike :pattern
or
users.phone ilike :pattern
)Теперь мы можем находить наших пользователей! Чтобы поиск был еще удобнее и полезнее, к нему нужно добавить сортировку данных. Обычно люди при вводе информации хотят сначала увидеть, к примеру, подходящие под шаблон фамилии, а потом уже ник в Telegram.
Мы выбрали следующий порядок приоритетов:
- Фамилия
- логин в Telegram
- телефон
- логин на портале
- имя
- департамент
- должность
Чтобы выполнить сортировку, есть один трюк, который мы разберем на примере совпадения фамилии.
Добавим к нашему запросу новый оператор:
order by (not users.surname ilike :pattern)
Как это работает? Если шаблон совпал с фамилией пользователя, будет true (или единица). Получится так, что у нас будет сортировка по числовому столбцу, состоящему из нулей и единиц. Чтобы совпадающие фамилии были вверху, нужно инвертировать значение (т.к. 0 < 1).
Теперь если мы добавим в сортировку еще и имя, то фамилия все равно будет в приоритете. Но и результаты поиска изменятся — будут в том виде, в котором нам нужно.
Дополним наш запрос сортировкой:
select users.id, concat_ws(' ', users.surname, users.name) as display_name
from users
join users_departments on (users_departments.is_active = true and users_departments.user_id = users.id)
join departments on (users_departments.department_id = departments.id)
join users_socials on (users_socials.is_active = true and users_socials.user_id = users.id and users_socials.social_id=:telegram_social_id)
join users_positions on (users_positions. is_active = true and users.id=users_positions.user_id)
join positions on users_positions.position_id = positions.id
where (
(concat_ws(' ', users.surname, users.name) ilike :pattern or concat_ws(' ', users.name, users.surname) ilike :pattern)
or
departments.name_ru ilike :pattern
or
users_socials.social_login ilike :pattern
or
positions.name ilike :pattern
or
users.login ilike :pattern
or
users.phone ilike :pattern
)
order by
(not users.surname ilike :pattern),
(not COALESCE(users_socials.social_login, '') ilike :pattern),
(not users.phone ilike :pattern),
(not users.login ilike :pattern),
(not users.name ilike :pattern),
(not departments.name_ru ilike :pattern),
(not positions.name ilike :pattern),
users.id
is_active = true and users.id=users_positions.user_id)
join positions on users_positions.position_id = positions.id
where (
(concat_ws(' ', users.surname, users.name) ilike :pattern or concat_ws(' ', users.name, users.surname) ilike :pattern)
or
departments.name_ru ilike :pattern
or
users_socials.social_login ilike :pattern
or
positions.name ilike :pattern
or
users.login ilike :pattern
or
users.phone ilike :pattern
)
order by
(not users.surname ilike :pattern),
(not COALESCE(users_socials.social_login, '') ilike :pattern),
(not users.phone ilike :pattern),
(not users.login ilike :pattern),
(not users.name ilike :pattern),
(not departments.name_ru ilike :pattern),
(not positions.name ilike :pattern),
users.id
COALESCE нужен на случай, если логина у пользователя нет. Он выставляет в значение по умолчанию пустую строку, которая не влияет на результаты выборки.
Запрос готов! Осталось только решить задачку с неправильной раскладкой клавиатуры. Тут мы не придумали ничего лучше, чем просто написать маленькую функцию на питоне (наш бэк написан на Python), которая возвращает текст на другой раскладке.
Тут мы не придумали ничего лучше, чем просто написать маленькую функцию на питоне (наш бэк написан на Python), которая возвращает текст на другой раскладке.
def translate_text(s: str):
eng_layout = "qwertyuiop[]asdfghjkl;'zxcvbnm,./`QWERTYUIOP{}ASDFGHJKL:\"ZXCVBNM<>?~"
rus_layout = "йцукенгшщзхъфывапролджэячсмитьбю.ёЙЦУКЕНГШЩЗХЪФЫВАПРОЛДЖЭЯЧСМИТЬБЮ,Ё"
if s[0] in eng_layout:
table = str.maketrans(eng_layout, rus_layout)
else:
table = str.maketrans(rus_layout, eng_layout)
return s.translate(table)
И в итоге просто искать по двум шаблонам.
Заключение
Итак, мы рассмотрели реализацию довольно простого поиска по небольшой базе. Безусловно, если ваша база данных сложнее и больше, вам нужна другая система поиска. Надеюсь, вам было полезно описание этой технической задачки. Пишите в комментариях, с каким поиском имели дело вы.
Возможно, эти тексты тоже вас заинтересуют:→ Как мы решали задачу с «нарезкой» vCPU
→ Как мы сделали самописный длиномер для работы в дата-центрах
→ Обзор на разработчика: как айтишники попробовали себя в стендапе
Поиск с помощью Spotlight на Mac
Spotlight помогает быстро находить приложения, документы, электронные письма и другие объекты на Mac. Если включены Предложения Siri, Вы также можете находить новости и просматривать результаты спортивных матчей, прогноз погоды, цены на акции и многое другое. Кроме того, Spotlight может выполнять вычисления и преобразования.
Если включены Предложения Siri, Вы также можете находить новости и просматривать результаты спортивных матчей, прогноз погоды, цены на акции и многое другое. Кроме того, Spotlight может выполнять вычисления и преобразования.
Siri. Произнесите, например: «Сколько сантиметров в дюйме?» или «Что такое бланширование?» Узнайте, как использовать Siri.
Поиск
На компьютере Mac выполните одно из указанных ниже действий.
Нажмите значок Spotlight (если он отображается) в строке меню.
Нажмите сочетание клавиш Command-пробел.
Нажмите в ряду функциональных клавиш на клавиатуре (при наличии).
Окно Spotlight можно перетянуть в любое место рабочего стола.
В поле поиска начните вводить запрос — результаты появляются уже при вводе текста.
Spotlight отображает топ-результаты вверху списка; нажмите топ-результат, чтобы просмотреть или открыть его.
 Spotlight также предлагает варианты для поиска на основе Вашего запроса; Вы можете просмотреть эти результаты в Spotlight или в интернете.
Spotlight также предлагает варианты для поиска на основе Вашего запроса; Вы можете просмотреть эти результаты в Spotlight или в интернете.В списке результатов можно сделать следующее.
Просмотр результатов поиска предлагаемого запроса в Spotlight. Нажмите объект, перед которым отображается значок Spotlight .
Просмотр результатов поиска предлагаемого запроса в интернете. Нажмите объект, перед которым отображается значок Safari .
Открытие объекта: Дважды нажмите ее. Можно также выбрать объект и нажать клавишу Return.
Просмотр местоположения файла на Mac: Выберите файл, затем нажмите и удерживайте клавишу Command. Местоположение файла отображается внизу окна предварительного просмотра.
Копирование объекта: Перетяните файл на рабочий стол или в окно Finder.
Просмотр всех результатов на Вашем Mac в Finder: Выполните прокрутку до конца списка результатов, затем нажмите «Найти в Finder».
 Чтобы уточнить результаты в Finder, см. раздел Сужение результатов поиска.
Чтобы уточнить результаты в Finder, см. раздел Сужение результатов поиска.
Если включен режим покоя или Вы превысили лимит, заданный для приложений в настройках Экранного времени, значки приложений в результатах затемняются и отображается значок песочных часов . См. раздел Управление временем покоя.
Выполнение вычислений и преобразований в Spotlight
Можно ввести математическое выражение, сумму в валюте, температуру или величину с единицами измерения в поле поиска Spotlight и получить результат преобразования или вычисления прямо в поле поиска.
Вычисления. Введите математическое выражение, например «956*23,94» или «2020/15».
Конвертация валют. Введите сумму в валюте, например «100 долларов США», «100 йен» или «300 крон в евро».
Преобразование температур. Введите температуру, например «98,8 фаренгейт», «32 цельсий» или «340 кельвинов в фаренгейты».

Преобразование единиц измерения. Введите величину, например «25 фунтов», «54 ярда», «23 стоуна» или «32 фута в метры».
Можно исключить из поиска Spotlight определенные папки, диски и типы информации (например, электронные письма или сообщения), задав соответствующие настройки. См. раздел Изменить параметры настроек «Siri и Spotlight».
Если Вы хотите, чтобы поиск Spotlight выполнялся только на компьютере Mac и не включал результаты из интернета, Вы можете выключить Предложения Siri для Spotlight.
См. такжеСочетания клавиш Spotlight на MacЕсли поиск на компьютере Mac дает неожиданные результатыПоиск слов на Mac
FAST (Многогранное применение предметной терминологии)
О FAST
FAST (Многогранное применение предметной терминологии) основан на предметных рубриках Библиотеки Конгресса (LCSH), одной из наиболее широко используемых схем предметной терминологии в библиотечном домене. Разработка FAST была результатом сотрудничества OCLC Research и Библиотеки Конгресса. Работа над FAST началась в конце 1998 г.
Работа над FAST началась в конце 1998 г.
FAST была разработана в значительной степени для удовлетворения потребности в общеупотребительной схеме предметной терминологии, а именно:
- простой в освоении и применении,
- граненая навигация и
- современный по своему дизайну.
Общей целью адаптации LCSH с упрощенным синтаксисом для создания FAST является сохранение очень богатого словаря LCSH при одновременном упрощении понимания, контроля, применения и использования схемы. Схема поддерживает восходящую совместимость с LCSH, и любой действительный набор предметных заголовков LC может быть преобразован в заголовки FAST.
FAST — это словарь из девяти аспектов, включающий примерно 1,8 миллиона заголовков по всем аспектам. Фасетки предназначены для использования в тандеме, но каждую из них можно использовать и по отдельности. Правила применения очень просты.
История вопроса
С быстрым ростом цифровой информации возникла потребность в упрощенной схеме индексации, которую могли бы назначать и использовать непрофессиональные каталогизаторы или индексаторы.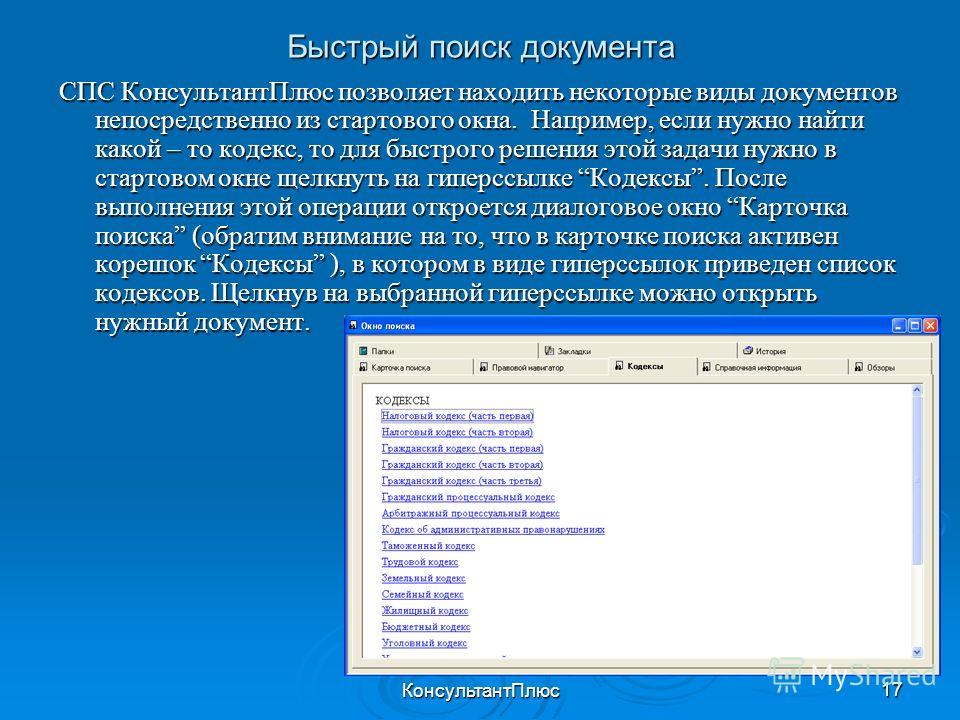
Происхождение FAST можно проследить по наблюдениям исследовательского персонала OCLC, участвовавшего в проекте OCLC Cooperative Online Resource Catalog (CORC), который сосредоточился на каталогизации веб-ресурсов. Участники CORC обычно хотели иметь возможность применять простые, недорогие и не требующие больших усилий подходы к описанию веб-ресурсов (например, с использованием Dublin Core). В ходе проекта CORC стало ясно, что существенным препятствием для описания ресурсов с минимальными усилиями является отсутствие легкого для изучения и применения общепредметного словаря.
Кроме того, работа Подкомитета по метаданным и предметному анализу Комитета по предметному доступу Ассоциации библиотечных коллекций и технических служб в тот же период определила конкретные функциональные требования предметных данных в записи метаданных (ALCTS 1999), и эти требования хорошо соответствовали предполагаемым результатам того, что станет проектом FAST.
Impact
Семейство из девяти модульных взаимодополняющих словарей, предназначенных для многогранного поиска, FAST представляет собой хорошо разработанный, профессионально контролируемый набор словарей, который требует небольшого начального обучения и операционных накладных расходов, сравнимых с индексированием ключевых слов. Эта комбинация атрибутов вместе с дизайном и реализацией, которые делают FAST хорошо подходящим для приложений со связанными данными, обеспечивают жизнеспособную и намного лучшую альтернативу индексированию по ключевым словам или другим неконтролируемым подходам.
Эта комбинация атрибутов вместе с дизайном и реализацией, которые делают FAST хорошо подходящим для приложений со связанными данными, обеспечивают жизнеспособную и намного лучшую альтернативу индексированию по ключевым словам или другим неконтролируемым подходам.
FAST используется различными библиотеками и другими организациями для предметного индексирования печатных и цифровых ресурсов.
Подробнее
При разработке FAST основными задачами были (1) совместимость с существующими метаданными, (2) простота назначения, (3) эффективность поиска, (4) стоимость обслуживания и (5) семантическая интероперабельность. Группа разработчиков определила, что этим целям лучше всего может соответствовать полностью перечисляющая многогранная схема предметных рубрик, полученная из предметных рубрик Библиотеки Конгресса.
Отдельные термины в словаре FAST разделены на девять отдельных категорий или аспектов: личные имена, корпоративные названия, названия собраний, географические названия, события, заголовки, периоды времени, темы и форма/жанр.
Поскольку система является полностью перечислительной, все предметные рубрики создаются с помощью авторитетных записей, что устраняет необходимость синтезировать заголовки в соответствии со сложным набором синтаксических правил.
Авторитетный файл FAST содержит более 1 800 000 авторитетных записей
Краткое руководство
Краткое руководство FAST, подготовленное Комитетом по политике и связям с общественностью FAST в 2022 году, предназначено для всех, кто хочет использовать FAST в качестве тематического словаря.
Просмотреть руководство
Загрузка набора данных FAST
Последнее обновление
- Последний раз FAST обновлялся 22 июля 2022 г.
Скачать
- MARC XML
- Все файлы (.zip: 198 МБ)
- По аспекту
- Личные имена (.zip: 85 МБ)
- Корпоративные названия (.zip: 44 МБ)
- Событие (.zip: 1 МБ)
- Унифицированные заголовки (.
 zip: 7MB)
zip: 7MB) - Хронологический (.zip: 32k)
- Актуальный (.zip: 35 МБ)
- Географический (.zip: 24 МБ)
- FormGenre (.zip: 270k)
- Встреча (.zip: 1 МБ)
- RDF (формат связанных данных N-троек)
- Все файлы (.zip: 266 МБ)
- По аспекту
- Личные имена (.zip: 111 МБ)
- Корпоративные названия (.zip: 67 МБ)
- Событие (.zip: 2 МБ)
- Унифицированные заголовки (.zip: 9 МБ)
- Хронологический (.zip: 48k)
- Актуальный (.zip: 46 МБ)
- Географический (.zip: 28 МБ)
- FormGenre (.zip: 343k)
- Встреча (.zip 1 МБ)
- МАРК ИСО
- Все файлы (.zip: 203 МБ)
- По фасету (более длинные фасеты находятся в нескольких файлах)
- Личные имена 0 1 2 3 4 5 6 7 8 9 (.
 zip: все меньше 10 МБ)
zip: все меньше 10 МБ) - Корпоративные названия 0 1 2 3 4 (.zip: все меньше 10 МБ)
- Событие (.zip: 1 МБ)
- Унифицированные заголовки (.zip: 7MB)
- Хронологический (.zip: 29k)
- Актуальные 0 1 2 3 4 (.zip: все меньше 10 МБ)
- Географический 0 1 2 (.zip: все меньше 10 МБ)
- FormGenre (.zip: 296k)
- Встреча (.zip: 1 МБ)
- Личные имена 0 1 2 3 4 5 6 7 8 9 (.
По вопросам о базе данных или для описания того, как вы использовали данные, свяжитесь с нами.
Лицензия
Эти файлы данных FAST (Faceted Application of Subject Terminology) предоставляются OCLC в соответствии с лицензией Open Data Commons Attribution License (ODC-By): https://www.oclc.org/research/activities/fast/ odcby.html.
Лицензия позволяет использовать данные для обучения и исследований, среди прочего, с указанием авторства в работах, созданных на основе базы данных.