
средняя наработка на отказ. Как спрогнозировать поломку жесткого диска
Как можно узнать срок работы жесткого диска; где та грань износа, по достижению которой HDD необходимо срочно менять? На помощь приходит MTBF — показатель наработки на отказ
Мы все хорошо понимаем, что потеря данных может повлиять на каждого их нас весьма и весьма негативно. Для многих из нас, потеря значимой информации происходит в виде поломки жесткого диска (HDD). Это могут быть различные механические и электронные дефекты, которые делают информацию, хранящуюся на жестком диске, недоступной для чтения. Есть десятки возможных причин для этого типа неисправности, начиная от логических ошибок программного обеспечения до очевидных или неявных физических повреждений HDD. Вместе с тем, мы не можем не упомянуть, что все устройства хранения данных имеют ограниченную продолжительность жизни.
Большинство из нас может назвать некоторые признаки того, что жесткий диск на грани выхода из строя. Например, если ваш HDD диск издает звуки – от приятного уху жужжания, шума шлифовки, то это признак того, что жесткий диск собирается «склеить ласты». Кроме того, если доступ к данным на ПК замедляется или начинают проявляться странные действия или явления (поврежденные данные, bad-сектора и пропавшие без вести файлы) – это все надежные индикаторы некорректной работы жесткого диска.
К сожалению, нет так называемых научных показателей для выявления неисправности HDD и его будущих поломок или выхода из строя — хотя это помогло бы предупредить потерю информации и вовремя прибегнуть к срочному ремонту HDD. В то же время, существуют способы мониторинга различных «странностей», происходящих с вашим ноутбуком или настольным ПК. Также можно применить ту же методологию к дисковым массивам для независимых дисков (RAID), через удаленный центр обработки данных.
Итак, как можно бизнес-пользователям, корпоративным и персональным пользователям предсказать, когда их жесткие диски достигнут грани работоспособности? Первый шаг – проверить смету изготовителей касательно продолжительности жизни устройства. Эти оценки, как правило, указаны как среднее время между отказами, или же наработка на отказ (MTBF). Это общий ориентир для жестких дисков. Что это означает в действительности и рассчитывается рейтинг наработки отказа, то есть MTBF?
Что такое среднее время наработки на отказ, т.е. примерный срок его службы
Рейтинг MTBF расшифровывается, как и звучит. Это средний период времени между одной присущей ошибкой и следующий в продолжительности жизни одного компонента. Другими словами, если была найдена неисправность и после этого отремонтирована, наработка на отказ – цифра, количество часов, когда можно ожидать функционирование жесткого диска в нормальном режиме, прежде чем он сломается снова или будет найдена малейшая неисправность.
В случае с потребительскими жесткими дисками, не редкость увидеть MTBF в промежутке около 300 000 часов. Это 12500 дней, или чуть более 34 лет. Между тем, жесткие диски более высокого класса рекламируются с MTB до 1,5 миллиона часов, что составляет около 175 лет. хотелось бы вы представить себе, как жесткий диск надежно работает в течение сотни лет? Это было бы сказкой для IT-менеджеров!
К сожалению, есть разница между средней наработки на отказ метрики и реальных продолжительности жизни. Метрика MTBF имеет долгую и выдающуюся родословную в военной и авиационно-космической техники. Цифры взяты из частоты ошибок в статистически значимого количества приводами, работающими в течение недель или месяцев, в то время.
Исследования показали, что, как правило, средняя наработка на отказ (MTBF) в реальности имеет более низкий показатель. В 2007 году исследователи из Университета Карнеги-Меллона исследовали образцы 100000 винчестеров с установленным MTB при условии диапазонов наработки на отказ от одного миллиона до 1,5 миллиона часов. Это приводит к ежегодному отказу (AFR) 0,88 процента. Однако данное исследование показало, что индекс, как правило, превышает один процент – от 3:58 процентов до 13 процентов в некоторых системах хранения информации.
Производители не закрывают глаза на несоответствие показателя MTBF к реальному сроку службы HDD накопителя. Недавно производители Seagate и Western Digital прекратили использовать метрики средней наработка на отказдля своих жестких дисков. Вместо этого пользователь вынужден использовать сторонний софт для диагностики (например, Victoria) либо исследовать диагностические показатели SMART (о чем читайте ниже).
Почему средняя наработка на отказ – неэффективный показатель износа HDD?
Вообще, показатель MTBF имеет смысл только тогда, когда устройство имеет постоянную интенсивность отказов, т.е. отказы распределены экспоненциально. Жесткие диски, в первую очередь, механические устройства, с механическими отказами. Т. е., механические отказов, как правило распределены.
Если мы предположим, что приложение использует большое количество жестких дисков, и ошибки распределены экспоненциально, число отказов в любых двух интервалах одинакового размера будет то же самое. Жесткий диск будет генерировать ошибки в 100-день, как и в 10000-день. Жесткие диски в реальных условиях эксплуатации имеют другой износ. После первоначальной фазы «младенческой смертности» (когда ошибки будут незначительны) произойдет какой-то момент времени, когда интенсивность отказов резко увеличится. Для типичных механических жестких дисков износ точка находится в возрасте от 3 до 5 лет непрерывной работы.
Как проверить жесткий диск на ошибки?
Вследствие, поскольку индекс средней наработки на отказ – относительно ненадежный индикатор здоровья жесткого диска, каким еще образом мы можем предсказать конец срока службы жесткого диска или другого устройства хранения данных? Далее мы будем обсуждать плюсы и минусы использования SMART – инструмента диагностики, который позволит определить время износа жесткого диска.
Информация по мотивам блога http://thedatarecoveryblog.com/
MTBF — откуда берется «миллион часов MTBF» / Habr
Просто удивительно то, насколько велико непонимание вокруг такого широко распространенного понятия, как MTBF (Mean Time Between Failure — «Время между сбоями» или «наработка на отказ» ), насколько смысла этой величины не понимают, зачастую, даже специалисты в области хранения данных.
Казалось бы — что может быть проще. «Наработка на отказ» это время беспроблемной работы, от первого включения нового диска, до момента отказа, посчитанная в часах.
Почти любой, кто поинтересуется значением, приводимым производителями, в качестве MTBF современных дисков, и с легкостью сделает несложные подсчеты, будет удивлен странной его величиной.
На сегодня величина MTBF приводится в миллион или даже полтора миллиона часов.
В году — примерно 8760 часов, значит, исходя из нашего понимания «физического смысла» этого значения, производитель планирует «наработку на отказ» для любого такого диска более ста лет (114 лет, для миллиона часов MTBF), что является очевидной нелепостью для каждого, у кого подыхали жесткие диски.
Тогда что это за «миллион часов», где и каким образом он измерен?
Дело в том, что MTBF измеряется для всей эксплуатируемой «дисковой популяции», и распространяется на период объявленного гарантийного срока для данного типа дисков. Оба выделенных момента являются важными, и часто опускаются в описании, что и приводит к принципиальному непониманию.
Представим себе, что мы поставили в сервер жесткий диск, который проработал 3 года гарантийного срока, и, будучи исправным, был заменен на новый. Следующий проработал три года, и был заменен по истечении гарантийного срока, и так далее. И вот на 38-м диске вы вправе ожидать, что до конца гарантийного срока он не доработает.
Или же представим себе чуть более приближенную к реальности ситуацию.
Допустим, для простоты подсчета, у нас есть система хранения на 115 дисков. Для каждого диска производитель приводит MTBF равный миллиону часов. Но надо принять во внимание то, что в большой дисковой популяции общий MTBF, то есть вероятность отказа, растет, с увеличением количества используемых дисков.
Этот вариант уже куда более похож на правду.
Строго говоря, на практике, вместо MTBF гораздо практичнее пользоваться параметром AFR — Annual Failure Rate, или «ежегодная вероятность сбоев», выводимом из MTBF.
Он вычисляется как: AFR = 1-exp(-8760/MTBF)
Величина AFR для диска с миллионом часов MTBF составляет 0,87%, что, в принципе, хоть и чуть завышено (Google в известном исследовании 2007 года показывает для новых дисков в пределах гарантийного срока как раз AFR в районе 1%), но, все же уже довольно хорошо согласуется с практикой.
Любопытно, что, например, такой производитель жестких дисков как WD теперь вовсе перестал указывать величину MTBF, перейдя на указание другого параметра: «power on/off cycles», по видимому не в последнюю очередь именно в связи с явно видимым непониманием и неочевидностью применения указываемой величины MTBF пользователями.
Ресурс современных жестких дисков. Longread о внезапном / Overclockers.ua
В прошлый раз мы рассмотрели этапы борьбы за господство в «дисковой» подсистеме твердотельных накопителей и традиционных жестких дисков. Там же мы коротко осветили нюансы ресурса твердотельных накопителей. Сегодня мы попытаемся рассмотреть вопрос практической надежности дисков жестких. Казалось бы, несколько запоздало, но не будем забывать, что ближайшие не менее чем 10–20 (а скорее всего и гораздо больше — об этом мы еще поговорим) лет этот вид продуктов будет гарантированно доступен на рынке в массовом сегменте по причине наличия немаленьких ниш, где скоростные достижения твердотельных накопителей избыточны, а хранимые данные относительно холодны. Да и перспективные объемы жестких дисков в ближайшее время твердотельным накопителям по адекватным ценам не догнать.
Теоретизировать на этот счет можно, конечно, долго. Можно вспоминать явно неудачные решения производителей, например, с чересчур частой парковкой головок или особо громкие изделия, но основной критерий в вопросе констатирования, как мне кажется, должен быть статистически-прикладным, особенно на фоне того, что в отличие от ситуации с SSD, найти утвержденные современные стандарты выносливости для классических винтов вряд ли получится.
Вопросы классификации
Напомним, что внешне и физически современные актуальные жесткие диски бывают по форм-фактору в основном 2,5″ и 3,5″. Исполнение бывает как внутренним, так и внешним.
Внутри мобильных внешнеподключаемых накопителей лежат обычные 2,5-дюймовые жесткие диски, которые в большинстве случаев можно достать и подключить к ноутбуку или десктопу напрямую, если те обладают нужными интерфейсами. И наоборот — можно положить в такой карман подходящие по толщине имеющиеся диски, сделав их мобильными и внешнеподключаемыми.
В случае с 2,5 дюймами встречается толщина 12,5, 9,5, 7 и даже 5 мм. Электрически они будут совместимы, но физические размеры, как понимаем, будут отличаться. Выглядит вот так:
Контактные группы одинаковы, но толщина разная. 2,5-дюймовые варианты жестких дисков чаще используются в портативной технике. Чем тоньше ноутбук, тем более внимательно надо смотреть, какой толщины накопитель предусмотрел туда изготовитель. Тонкие диски в места для толстых поставить не проблема — они часто продаются с утолщителями в виде пластиковой рамки, чтобы не болтались в посадочных местах для более толстых коллег. В отсутствии рамки проложить их можно чем угодно — хоть картоном по углам. А вот более толстые затолкать в места для худых не выйдет — будьте внимательны!
Были и 1,8- и 1,3- и даже 1-дюймовые Microdrive в формате Сompact flash II — вообще левшовые практически изделия. Но это уже история, т.к. в ультракомпактном сегменте всех разогнал привычный флэш.
Типы интерфейсов
Интерфейсы сегодня в быту бывают SATA и все еще IDE, в профессиональном использовании есть и SAS. В вопросы параллельности и последовательности, а также понятия шин в рамках этого материала погружаться не будем.
IDE, он же АТА, они же аббревиатуры от Integrated Drive Electronics и Advanced Technology Attachment, растет корнями из 90-х и уже уходит в прошлое. Новых массовых материнских плат с ним не делают уже лет 10 наверно, но в наличном парке его еще полно. Пропускает 133 мегабайт в секунду и выглядит разъемом конкретно вот так на накопителе. Крайнее слева — питание, справа — данные. И соответственно на материнской плате. Подключается плоским шлейфом обычно серого или черного цвета. Вот таким.
Рассмотрели мы это чисто для исторической справки.
Мейнстримом же сегодня является SATA. Типично для 2,5- и 3,5-дюймовых решений выглядит вот так:
Справа контактная группа питания, слева — данных. Вид: накопители вверх дном. Между собой совместимо. Подключается как на картинке.
Ревизии и пропускные способности мы рассмотрели в прошлый раз и здесь останавливаться не будем. Отметим только, что есть разновидности типа eSATA для внешних устройств и slimline SATA для компактных внутренних. И да — SATA заточен под горячую замену, т.е. на ходу без перезагрузки. Разве что в диспетчере устройств может понадобиться нажать кнопку «обновить» в случае Windows.
Существуют переходники для питания и возможностей подключить IDE в SATA и наоборот, но мы не об этом.
SAS это Serial Attached SCSI и используется в основном в профессиональной сфере, обратно совместим с SATA и имеет пропускную способность 12–24 Гбит в секунду. Выглядит похоже на SATA, но разъемом отличается. Обороты большие — до 15000, коррекция ошибок, multipath — как «в лучших домах Парижу и ЛондОну», но дорого и в быту не воткнуть. А еще греется так, что на некоторые модели радиаторы килограммовые нужны.
Но вернемся к вопросу.
Проблемы технологий
Сегодняшние массовые жесткие диски находятся на излете традиционных технологических возможностей. Плотность данных на одну
Оценка надежности накопителей, установленных в настольных компьютерах и бытовых электронных устройствах
Введение
Устройства хранения информации на жестких дисках традиционно устанавливались главным образом на настольных компьютерах, однако в последнее время накопители все чаще находят применение и в бытовой электронике. В настоящей статье описываются способы оценки надежности накопителей, установленных в настольных компьютерах и бытовых электронных устройствах, с использованием результатов стандартных лабораторных испытаний компании Seagate.
Определения
Под наработкой на отказ Seagate подразумевает отношение времени РОН (Power-On Hours — время в часах, в течение которого накопитель находился во включенном состоянии) в течение года к усредненной интенсивности отказов AFR (Annualized Failure Rate — годовая интенсивность отказов) за первый год. Такой метод дает достаточную точность при малом количестве отказов, поэтому мы используем его для расчета наработки на отказ «первого года». Усредненная годовая интенсивность отказов для накопителя рассчитывается на основе данных о времени безотказной работы, полученных в ходе испытаний RDT (Reliability-Demonstration Test — демонстрационные испытания надежности). По той же методике проводятся и заводские испытания FRDT (Factory Reliability-Demonstration Test — заводские демонстрационные испытания надежности), однако здесь проверяются серийные накопители из производственных серий. В рамках настоящего документа мы будем исходить из того, что любая концепция, применимая в отношении RDT, справедлива также и для FRDT.
Испытания на надежность, проводимые Seagate
В Группе персональных устройств хранения Seagate со штаб-квартирой в г. Лонгмонт (шт. Колорадо) испытания накопителей для настольных систем на надежность обычно проводятся в термокамерах при температуре окружающей среды +42 градуса по Цельсию, что повышает интенсивность отказов. Кроме того, накопители при этом эксплуатируются с максимально возможной продолжительностью включения (под продолжительностью включения дисковода понимается количество поисков данных, их считывания и записи в течение заданного отрезка времени). Это делается для того, чтобы выявить как можно больше причин отказа еще на стадии разработки изделия. Устранив проблемы, отмеченные на этом этапе, мы можем быть уверены, что наши пользователи с ними больше не столкнутся.
Оценка параметров по Weibull
Предположим, что испытанию RDT были подвергнуты 500 накопителей, каждый из которых проработал 672 часа при температуре окружающей среды 42°С. Допустим также, что в ходе испытания было отмечено три отказа (после 12, 133 и 232 часов работы). Это означает, что из 500 проверенных накопителей успешно прошли испытание 497. Для анализа и экстраполяции полученных результатов мы применяем моделирование по Weibull, используя для этого пакет программ SuperSmith фирмы Fulton Findings1. В частности, с помощью метода максимального правдоподобия производится оценка таких параметров распределения Weibull, как бета (форм-фактор) и эта (масштабный коэффициент).
(То есть априори предполагается, что отказы распределены согласно Weibull. Для тех, кто знаком с математической статистикой, приведу формулу плотности вероятности для этого распределения:
Смысл проводимых испытаний — оценить параметры распределения. При этом считается, что при заданном значении бета параметр эта равен времени в часах, за которое выйдут из строя 90% тестируемых накопителей. (Обсуждение данной математической модели требует серьезных познаний в математической статистике и выходит за рамки данной статьи, поэтому предлагается принять ее как факт) — прим. редактора).
Если в ходе испытания отмечено пять или менее отказов, точно определить параметр бета по полученным данным невозможно. Поскольку такие результаты испытаний встречаются довольно часто, мы анализируем их с помощью метода WeiBayes2, в основу которого положена оценка параметра бета по статистическим данным. В лаборатории продукции для настольных компьютеров мы сейчас принимаем бета = 0,55. Такое значение получено на основе производственных данных, представленных ниже в таблице. Она составлена на основании испытания всех накопителей для настольных систем, прошедших проверку до марта 1999 г.
| Место производства накопителей | База данных | Среднее значение бета | Стандартное отклонение бета |
|---|---|---|---|
| Лонгмонт | 37 RDT, 5 FRDT | 0,546 | 0,176 |
| Пераи | 2 RDT, 4 FRDT | 0,617 | 0,068 |
| Вузи | 1 RDT | 0,388 | нет данных |
| Обобщенные данные по настольным системам | 49 испытаний | 0,552 | 0,167 |
Приведенный ниже график отображает результаты анализа Weibull и WeiBayes. Сплошная линия соответствует параметрам бета и эта по Weibull (бета = 0,443, эта = 69 331 860), рассчитанным по методу MLE (Maximum Likelihood — максимальное правдоподобие)3 всего для 3 отказов на 500 накопителей. Как уже отмечалось, такие результаты считаются не столь точными, как полученные по методу WeiBayes для небольшой интенсивности отказов.
Результаты, полученные методом WeiBayes (для бета = 0,55), представлены на графике пунктирной линией. Поскольку 672 часа работы при температуре 42°С для испытания RDT вполне достаточно, мы использовали свой внутренний параметр «доверительная вероятность прекращения испытаний»4, который для анализа WeiBayes принят равным 63,2%. Расчет по методу WeiBayes показал, что при температуре 42°С и статистическом значении бета = 0,55 приемлемое значение эта составляет 3 787 073 часа.
Легенда к графику «Примеры анализа по методам Weibull и WeiBayes»W/mle = Доверительная вероятность прекращения испытаний
WeiBayes fit = Аппроксимация WeiBayes
Observed Weibull fit via MLE = Аппроксимация данных исследования по Weibull методом максимального правдоподобия
Eta = эта
Beta = бета
n/s = (всего/исправных накопителей)
Следующий этап анализа состоит в пересчете параметра эта, полученного в результате тестов при 42°С, в значение, соответствующее нашей стандартной рабочей температуре (25°С). Опираясь на модель Arrhenius5, для учета температурных различий можно принять коэффициент учащения отказов равным 2,2208. Таким образом, значение эта для 25°С (эта25) будет равным значению этого параметра для 42°С (эта42), умноженному на 2,2208, то есть, 8 410 332 часа.
Оценка среднего времени наработки на отказ в течение первого года на основании параметров Weibull
На основании параметров бета и эта Weibull, полученных после температурной коррекции, в любой момент можно рассчитать суммарный процент отказов. Чтобы оценить процент накопителей, которые могут выйти из строя при температуре 25°С в промежутке времени от t1 до t2, достаточно произвести вычитание значений суммарного процента отказа в моменты t1 и t2, а затем воспользоваться соответствующими значениями бета и эта25.
Для оценки усредненной интенсивности отказов (параметр AFR) за первый год эксплуатации накопителя, установленного в настольном компьютере, примем, что у пользователя устройство находится во включенном состоянии 2 400 часов в год. Допустим также, что еще 24 часа оно эксплуатировалось на заводе на этапе интеграции. Поскольку все накопители, вышедшие из строя в течение этого периода, возвращаются в Seagate и к конечному пользователю не попадают, при расчете AFR и наработки на отказ за первый год они не учитываются.
С учетом приведенного выше (продолжительность включения 100%, эта25 = 8 410 332 час, бета = 0,55 и общее время работы за год 2 400 час) относительную интенсивность отказов за первый год можно рассчитать как интенсивность отказов, произошедших в период между 24 час (t1) и 2 424 час (t2). Результаты такого расчета приведены ниже в таблице, построенной на основе наработки на отказ в течение первого года и данных, полученных в ходе испытаний RDT.
| Исходные данные: 2 400 час/год | |
|---|---|
| Форм-фактор по Weibull (бета): | 0,55 |
| Масштабный коэффициент по Weibull (эта): | 8 410 332 |
| Р(отказов) от 0 до 2 400 час/год: | 1,123% |
| Р(отказов) от 0 до 24 час: | 0,089% |
| | |
| AFR за первый год | 1,0338% (до округления) |
| Наработка за год: | 2 400 час |
| AFR за первый год: | 0,010338 |
| | |
| Наработка на отказ за первый год по Weibull: | 232 140 час |
(Р(отказов) вычисляются на основании распределения Weibull — см. график. Далее понятно: Наработка на отказ за первый год = Наработка за год / AFR за первый год — прим. редактора).
Учет реальных условий использования
Как показывают приведенные выше расчеты, если накопитель используется при температуре 25°С и находится во включенном состоянии 2 400 часов в год, можно ожидать, что при работе у пользователя средняя наработка на отказ составит 232 140 часов. Однако такие условия соблюдаются в бытовой электронике не всегда. В некоторых бытовых приборах, скажем, накопитель может работать почти непрерывно, поэтому время его работы за год намного превысит 2 400 часов. В других же устройствах, например, игровых видеоприставках, этот показатель может оказаться значительно ниже. В последующих разделах описано, как именно можно скорректировать расчетное значение наработки на отказ для различной интенсивности использования, продолжительности включения и окружающей температуры.
Интенсивность использования
Учесть изменения средней наработки на отказ, вызванные различиями в интенсивности использования накопителя, можно с помощью приведенного графика.
Легенда к графику «Коррекция среднего времени наработки на отказ в зависимости от ожидаемого времени работы накопителя за год»Название вертикальной оси — Корректирующий множитель для наработки на отказ
Название горизонтальной оси — Ожидаемое время работы накопителя за год
Например, если известна наработка на отказ для 2 400 рабочих часов в год, а реальное рабочее время за год составляет 8 760 часов, то среднее время наработки на отказ снизится примерно вдвое. И наоборот: когда накопитель работает мало, как это бывает в некоторых игровых видеоприставках, то наработка на отказ может почти удвоиться.
Температура
Теперь давайте посмотрим, как изменяется время наработки на отказ при повышении рабочей температуры. Для построения графика температурного коэффициента времени наработки на отказ можно применить ту же модель Arrhenius, которую мы использовали для определения коэффициента учащения отказов. Представленная ниже таблица показывает, как снижается наработка на отказ за первый год (если продолжительность включения составляет 100%) при температуре окружающей среды выше 25°С.
| Температура, °С | Коэффициент учащения отказов | Температурный коэффициент снижения времени наработки на отказ | Скорректи- рованное время наработки на отказ |
|---|---|---|---|
| 25 | 1,0000 | 1,00 | 232 140 |
| 26 | 1,0507 | 0,95 | 220 533 |
| 30 | 1,2763 | 0,78 | 181 069 |
| 34 | 1,5425 | 0,65 | 150 891 |
| 38 | 1,8552 | 0,54 | 125 356 |
| 42 | 2,2208 | 0,45 | 104 463 |
| 46 | 2,6465 | 0,38 | 88 123 |
| 50 | 3,1401 | 0,32 | 74 284 |
| 54 | 3,7103 | 0,27 | 62 678 |
| 58 | 4,3664 | 0,23 | 53 392 |
| 62 | 5,1186 | 0,20 | 46 428 |
| 66 | 5,9779 | 0,17 | 39 464 |
| 70 | 6,9562 | 0,14 | 32 500 |
Как видно из таблицы, по мере роста окружающей температуры температурный коэффициент снижения времени наработки на отказ и скорректированная наработка на отказ значительно сокращаются. Так, при 42°С коэффициент учащения отказов составляет 2,2208 (как и было определено в ходе настоящего анализа ранее). А коэффициент коррекции времени наработки на отказ для этой же температуры равен 0,45, то есть среднее время наработки на отказ при температуре 42°С оказывается в два с лишним раза меньше, чем при температуре 25°С.
Продолжительность включения
Продолжительность включения большинства накопителей, установленных в персональных компьютерах, составляет от 20 до 30%, тогда как в бытовых электронных устройствах этот показатель может быть выше или ниже. Измерив объем данных, который пересылается внутри современных устройств бытовой электроники за сутки, специалисты Seagate установили, что продолжительность включения накопителей в них составляет всего 2,5%.
Чтобы определить, как изменяется наработка на отказ при продолжительности включения 2,5% по сравнению со 100% (такое значение характерно для испытаний RDT), нужно выяснить, какое влияние на этот процесс оказывают те компоненты накопителей, состояние которых зависит от продолжительности включения, а какое — другие его элементы. Количество зависимых компонентов в накопителе прямо пропорционально количеству пластин жестких дисков в нем. Взаимоотношение между числом жестких дисков и усредненной интенсивности отказов за первый год отображено на следующей иллюстрации. Пространство под пунктирной линией на этом графике соответствует «базовой», — то есть, не зависящей от того, как долго работает устройство, — интенсивности отказов гипотетического накопителя с нулевым количеством жестких дисков (или накопителя, который не производит чтения, записи и поиска информации). Сплошной линией отмечена ожидаемая интенсивность отказов как функция количества жестких дисков.
Легенда к графику «Зависимость общей и базовой усредненной интенсивности отказов от количества жестких дисков в накопителе»Название вертикальной оси — Нормализованное значение AFR
Название горизонтальной оси — Количество пластин жестких дисков (не более 4)
Total AFR = Общая усредненная интенсивность отказов
Base AFR = Базовая усредненная интенсивность отказов
Как видно из графика, уменьшение продолжительности включения снижает количество только тех отказов, которые связаны со временем работы накопителя (пространство между пунктирной и сплошной линиями). Зная соотношение между количеством отказов, зависящих от продолжительности включения, и их общим числом, можно оценить влияние продолжительности включения на усредненную интенсивность отказов AFR. Так, для накопителя с четырьмя жесткими дисками общая интенсивность отказов составит 1,4%, а базовая — 0,6%. Снижение продолжительности включения уменьшит вероятность отказа на [(1,4 — 0,6)/1,4] = 57%. Таким образом, снижая время работы четырехдискового накопителя, мы можем уменьшить вероятность отказа только на 57%, остальная доля неполадок от продолжительности включения не зависит.
Изменение коэффициента наработки на отказ для накопителей с разным количеством жестких дисков представлено на следующем графике.
Легенда к графику «Зависимость коэффициента наработки на отказ от продолжительности включения накопителя и количества жестких дисков в нем»Название вертикальной оси — Коэффициент наработки на отказ
Название горизонтальной оси — Продолжительность включения
1-disk… = Для дисковода минимальной емкости с 1 жестким диском
2-disk… = Для дисковода с 2 жесткими дисками
3-disk… = Для дисковода с 3 жесткими дисками
4-disk… = Для дисковода максимальной емкости с 4 жесткими дисками
Комплексный учет нескольких факторов
Продолжая анализ, оценим комбинированное воздействие различных значений продолжительности включения и температурных коэффициентов сокращения наработки на отказ для нескольких накопителей. На графике внизу слева представлены коэффициенты коррекции наработки на отказ для накопителя высокой емкости с 4 жесткими дисками при разных комбинациях продолжительности включения и температуры окружающей среды. Рисунок справа отображает такие же коэффициенты для накопителя, оснащенного только одним жестким диском. Как видно из этих графиков, в зависимости от продолжительности включения и рабочей температуры накопителя, установленного в ПК, эффективная наработка на отказ за первый год может оказаться выше, равной или ниже, чем ожидаемое значение этого параметра, рассчитанное по результатам заводских испытаний. При этом на накопителе с одним жестким диском изменение продолжительности включения и окружающей температуры сказывается слабее, а коэффициенты коррекции здесь значительно меньше.
Легенда к графикам «Снижение времени наработки на отказ в зависимости от температуры и продолжительности включения (для накопителя максимальной емкости с 4 жесткими дисками/минимальной емкости с 1 жестким диском)»Название вертикальной оси — Коэффициент снижения времени наработка на отказ
Название горизонтальной оси — Окружающая температура, °С
DF@100%… = Продолжительность включения = 100%
DF@30%… = Продолжительность включения = 30%
DF@20%… = Продолжительность включения = 20%
DF@10%… = Продолжительность включения = 10%
DF@5%… = Продолжительность включения = 5%
DF@1%… = Продолжительность включения = 1%
Надежность после первого года эксплуатации
Согласно распределению Weibull, описывающему зависимость наработки на отказ от срока эксплуатации, при значении бета меньше единицы вероятность отказов оборудования со временем снижается. По этой причине интенсивность отказов накопителей на первом году эксплуатации должна быть выше, чем в последующие годы. Но какова будет интенсивность отказов или среднее время наработки на отказ, если усреднить эти показатели за все время эксплуатации накопителя? Ниже приведены три метода оценки надежности, позволяющие ответить на этот вопрос.
- Можно с помощью анализа Weibull (бета, эта25) оценить количество возможных отказов после первого года эксплуатации. Однако для этого потребовалось бы получить дополнительные данные демонстрационных испытаний надежности, увеличив длительность самих испытаний на порядок или больше. Такой подход едва ли можно признать целесообразным.
- Можно использовать информацию о гарантийном обслуживании из базы данных Seagate. Она позволит оценить соотношение накопителей, возвращенных на втором и третьем году эксплуатации, и устройств, в которых возникли сбои в течение первого года. Однако такие данные имеются только за первые три года эксплуатации — именно на этот срок распространяется действие большинства гарантийных обязательств Seagate на накопители для настольных компьютеров. Правда, серьезным преимуществом этого подхода является то, что все данные относятся исключительно к продукции Seagate для настольных систем.
- Можно принять так называемую «плоскую» модель, предполагающую, что после завершения первого года эксплуатации интенсивность отказов остается на постоянном уровне. Это означает, что во все годы после первого интенсивность отказов будет такой же, как и на втором году эксплуатации. Поскольку вероятность отказа со временем уменьшается, данный метод дает осторожную оценку средней наработки на отказ для всего срока эксплуатации.
| МОДЕЛЬ: | |||||||
|---|---|---|---|---|---|---|---|
| Weibull | По данным гарантийного обслуживания (только по OEM) | »Плоская» модель | |||||
| Год эксплу- атации | Суммарная продолжи- тельность включения (час) | Интен- сив- ность отказов за год | Суммар- ная интенсив- ность отказов | Интен- сив- ность отказов за год | Суммар- ная интенсив- ность отказов | Интен- сив- ность отказов за год | Суммар- ная интенсив- ность отказов |
| 1 | 2 400 | 1,20% | 1,20% | 1,20% | 1,20% | 1,20% | 1,20% |
| 2 | 4 800 | 0,55% | 1,75% | 0,78% | 1,98% | 0,55% | 1,75% |
| 3 | 7 200 | 0,43% | 2,18% | 0,39% | 2,37% | 0,55% | 2,30% |
| 4 | 9 600 | 0,37% | 2,55% | 0,55% | 2,86% | ||
| 5 | 12 000 | 0,33% | 2,88% | 0,55% | 3,41% | ||
| 6 | 14 400 | 0,30% | 3,18% | 0,55% | 3,96% | ||
| 7 | 16 800 | 0,28% | 3,46% | 0,55% | 4,51% | ||
| 8 | 19 200 | 0,26% | 3,72% | 0,55% | 5,06% | ||
| 9 | 21 600 | 0,24% | 3,96% | 0,55% | 5,62% | ||
| 10 | 24 000 | 0,23% | 4,19% | 0,55% | 6,17% | ||
Чтобы нагляднее продемонстрировать различия между моделями, мы приводим график суммарной относительной интенсивности отказов, построенный на основании каждой из них (время наработка на отказ для первого года эксплуатации принято равным 200 000 часов).
Легенда к графику «Суммарная годовая интенсивность отказов, рассчитанная по Weibull и «плоской» модели, в сравнении с данными гарантийного обслуживания»Название вертикальной оси (между цифрами точки заменить на запятые) — Суммарная интенсивность отказов за год эксплуатации пользователем
Название горизонтальной оси — Год эксплуатации пользователем
Weibull analysis = Анализ по Weibull
«Flatline» model = «Плоская» модель
Model based… = Модель оценки по данным гарантийного обслуживания
Как видно из приведенного выше графика, «плоская» модель дает более осторожную оценку, чем «чистый» анализ по Weibull, и очень близка к оценке по данным гарантийного обслуживания Seagate за первые три года. Для простоты анализа, а также для того, чтобы получить более осторожные оценки, мы решили применять в своих расчетах «плоскую» модель.
При использовании «плоской» модели суммарные результаты отношения между наработкой на отказ за все время эксплуатации к этому параметру за первый год могут выглядеть следующим образом:
| Средние значения за первые три года: | |
|---|---|
| Отказов в год: | 0,768% |
| Наработка на отказ: | 312 500 час |
| Прирост по сравнению с некорректированным значением наработки на отказ (232 140 час): | 1,56 |
| Средние значения за первые пять лет: | |
| Отказов в год: | 0,682% |
| Наработка на отказ: | 352 113 час |
| Прирост по сравнению с некорректированным значением наработки на отказ (232 140 час): | 1,76 |
| Средние значения за первые десять лет: | |
| Отказов в год: | 0,617% |
| Наработка на отказ: | 389 105 час |
| Прирост по сравнению с некорректированным значением наработки на отказ (232 140 час): | 1,95 |
Проведенные расчеты показывают, что для оценки среднего времени наработки на отказ за три года эксплуатации дисковода нужно умножить исходный показатель за первый год (для той же продолжительности включения и окружающей температуры) на коэффициент 1,56. Аналогично можно рассчитать и среднее время наработки на отказ за пять и десять лет, умножив значение исходного параметра за первый год на 1,76 и 1,95 соответственно.
Окончательный расчет
На основе всех коэффициентов, рассчитанных выше, мы можем преобразовать наработку на отказ, указываемую фирмой Seagate (на первый год эксплуатации, при 2 400 рабочих часах в год и продолжительности включения 100%) в среднее время наработки на отказ для накопителя, установленного в устройстве конечного пользователя и работающего при конкретной окружающей температуре с определенной продолжительностью включения. После этого можно также оценить и среднее время наработки на отказ за все время службы накопителя.
Ниже приведен пример расчета среднего времени наработки на отказ в течение первого года и всего срока эксплуатации для накопителя, работающего в течение 2 400 часов в год при температуре 34°С, продолжительности включения 30% и рассчитанного на срок службы 5 лет.
| Наработка на отказ за первый год: | 232 140 час | (на основе параметров бета и эта25 по Weibull) |
| х 0,90 | (температурный коэффициент для 38°С и продолжительности включения 30%) | |
| Наработка на отказ за первый год в устройстве пользователя: | 208 926 час | |
| Наработка на отказ в устройстве пользователя: | 208 926 час | |
| х 1,76 | (коэффициент усреднения за пятилетний период) | |
| Наработка на отказ за весь срок эксплуатации в устройстве пользователя: | 367 710 час |
В качестве завершающего примера рассмотрим накопитель Seagate с одним жестким диском, для которого наработка на отказ в течение первого года составляет 444 000 час. Допустим, он установлен в бытовом электронном устройстве, используется 2 920 часов в год (8 часов в день, 7 дней в неделю) при окружающей температуре 42°С и продолжительности включения 5%.
| Наработка на отказ за первый год: | 444 000 час | (на основе параметров бета и эта25 по Weibull) |
| х 0,92 | (коррекция для 2 920 час/год) | |
| х 0,59 | (температурный коэффициент для 42°С и продолжительности включения 5%) | |
| х 1,95 | (коэффициент усреднения за 10-летний период) | |
| Наработка на отказ в устройстве пользователя в течение первого года: | 469 956 час |
Заключение
Описанный выше метод позволяет использовать данные лабораторных испытаний Seagate для оценки надежности накопителей, установленных в настольных компьютерах и бытовых электронных приборах, которые работают в условиях «реального мира». Вкратце этот метод сводится к следующему:
- С помощью анализа Weibull или статистических данных испытаний RDT/FRDT оцените параметры Weibull для лабораторных условий.
- Используя методику WeiBayes, проанализируйте данные испытаний для конкретного типа накопителя; определите значения усредненной интенсивности отказов AFR за первый год и наработку на отказ при проведении испытаний RDT.
- Откорректируйте полученные результаты с учетом отличия лабораторных условий RDT от реальной температуры и продолжительности включения, при которых будет работать накопителей, установленный в аппаратуре конечного пользователя.
- Исходя из осторожного предположения, что после первого года эксплуатации интенсивность отказов останется постоянной, пролонгируйте оценку надежности за первый год на трех- и десятилетний срок службы накопителя.
Примечания:
1 SuperSmith, Fulton Findings, WinSMITH и WinSMITH Weibull являются зарегистрированными товарными знаками фирмы Fulton Findings (1251 W. Sepulveda Blvd., #800, Torrance, CA 90502, США).
2 Abernethy, Dr. Robert B., The New Weibull handbook, Second Edition, авторское издание, 1996, глава 5.
3 Abernethy, Dr. Robert B., The New Weibull handbook, Second Edition, авторское издание, 1996, приложение D.
4 Чтобы компенсировать неопределенность оценки параметров по Weibull из-за ограниченности времени работы дисководов, можно повысить доверительный уровень при проведении испытаний RDT.
5 Nelson, Wayne, Applied Life Data Analysis, John Wiley & Sons, 1982.
Время наработки на отказ hdd
Как можно узнать срок работы жесткого диска; где та грань износа, по достижению которой HDD необходимо срочно менять? На помощь приходит MTBF — показатель наработки на отказ
Мы все хорошо понимаем, что потеря данных может повлиять на каждого их нас весьма и весьма негативно. Для многих из нас, потеря значимой информации происходит в виде поломки жесткого диска (HDD). Это могут быть различные механические и электронные дефекты, которые делают информацию, хранящуюся на жестком диске, недоступной для чтения. Есть десятки возможных причин для этого типа неисправности, начиная от логических ошибок программного обеспечения до очевидных или неявных физических повреждений HDD. Вместе с тем, мы не можем не упомянуть, что все устройства хранения данных имеют ограниченную продолжительность жизни.
Большинство из нас может назвать некоторые признаки того, что жесткий диск на грани выхода из строя. Например, если ваш HDD диск издает звуки – от приятного уху жужжания, шума шлифовки, то это признак того, что жесткий диск собирается «склеить ласты». Кроме того, если доступ к данным на ПК замедляется или начинают проявляться странные действия или явления (поврежденные данные, bad-сектора и пропавшие без вести файлы) – это все надежные индикаторы некорректной работы жесткого диска.
К сожалению, нет так называемых научных показателей для выявления неисправности HDD и его будущих поломок или выхода из строя — хотя это помогло бы предупредить потерю информации и вовремя прибегнуть к срочному ремонту HDD. В то же время, существуют способы мониторинга различных «странностей», происходящих с вашим ноутбуком или настольным ПК. Также можно применить ту же методологию к дисковым массивам для независимых дисков (RAID), через удаленный центр обработки данных.
Итак, как можно бизнес-пользователям, корпоративным и персональным пользователям предсказать, когда их жесткие диски достигнут грани работоспособности? Первый шаг – проверить смету изготовителей касательно продолжительности жизни устройства. Эти оценки, как правило, указаны как среднее время между отказами, или же наработка на отказ (MTBF). Это общий ориентир для жестких дисков. Что это означает в действительности и рассчитывается рейтинг наработки отказа, то есть MTBF?
Что такое среднее время наработки на отказ, т.е. примерный срок его службы
Рейтинг MTBF расшифровывается, как и звучит. Это средний период времени между одной присущей ошибкой и следующий в продолжительности жизни одного компонента. Другими словами, если была найдена неисправность и после этого отремонтирована, наработка на отказ – цифра, количество часов, когда можно ожидать функционирование жесткого диска в нормальном режиме, прежде чем он сломается снова или будет найдена малейшая неисправность.
В случае с потребительскими жесткими дисками, не редкость увидеть MTBF в промежутке около 300 000 часов. Это 12500 дней, или чуть более 34 лет. Между тем, жесткие диски более высокого класса рекламируются с MTB до 1,5 миллиона часов, что составляет около 175 лет. хотелось бы вы представить себе, как жесткий диск надежно работает в течение сотни лет? Это было бы сказкой для IT-менеджеров!
К сожалению, есть разница между средней наработки на отказ метрики и реальных продолжительности жизни. Метрика MTBF имеет долгую и выдающуюся родословную в военной и авиационно-космической техники. Цифры взяты из частоты ошибок в статистически значимого количества приводами, работающими в течение недель или месяцев, в то время.
Исследования показали, что, как правило, средняя наработка на отказ (MTBF) в реальности имеет более низкий показатель. В 2007 году исследователи из Университета Карнеги-Меллона исследовали образцы 100000 винчестеров с установленным MTB при условии диапазонов наработки на отказ от одного миллиона до 1,5 миллиона часов. Это приводит к ежегодному отказу (AFR) 0,88 процента. Однако данное исследование показало, что индекс, как правило, превышает один процент – от 3:58 процентов до 13 процентов в некоторых системах хранения информации.
Производители не закрывают глаза на несоответствие показателя MTBF к реальному сроку службы HDD накопителя. Недавно производители Seagate и Western Digital прекратили использовать метрики средней наработка на отказдля своих жестких дисков. Вместо этого пользователь вынужден использовать сторонний софт для диагностики (например, Victoria) либо исследовать диагностические показатели SMART (о чем читайте ниже).
Почему средняя наработка на отказ – неэффективный показатель износа HDD?
Вообще, показатель MTBF имеет смысл только тогда, когда устройство имеет постоянную интенсивность отказов, т.е. отказы распределены экспоненциально. Жесткие диски, в первую очередь, механические устройства, с механическими отказами. Т. е., механические отказов, как правило распределены.
Если мы предположим, что приложение использует большое количество жестких дисков, и ошибки распределены экспоненциально, число отказов в любых двух интервалах одинакового размера будет то же самое. Жесткий диск будет генерировать ошибки в 100-день, как и в 10000-день. Жесткие диски в реальных условиях эксплуатации имеют другой износ. После первоначальной фазы «младенческой смертности» (когда ошибки будут незначительны) произойдет какой-то момент времени, когда интенсивность отказов резко увеличится. Для типичных механических жестких дисков износ точка находится в возрасте от 3 до 5 лет непрерывной работы.
Вследствие, поскольку индекс средней наработки на отказ – относительно ненадежный индикатор здоровья жесткого диска, каким еще образом мы можем предсказать конец срока службы жесткого диска или другого устройства хранения данных? Далее мы будем обсуждать плюсы и минусы использования SMART – инструмента диагностики, который позволит определить время износа жесткого диска.
При оценке реальной надежности жестких дисков в вычислительных центрах часто высказывается мнение, что производители дисковых накопителей имеют склонность завышать показатель MTBF (Mean Time Between Failures — среднее время наработки на отказ). Вот только кто верит их данным?
Технические спецификации жестких дисков всегда содержали информацию о надежности, оговаривая, сколько часов может проработать каждое из этих устройств. Такой показатель называется «средним временем наработки на отказ», или MTBF, но иногда используется более короткий термин «наработка на отказ». Разницы между ними, впрочем, особой нет, разве что в первом случае исходят из того, что диск можно отремонтировать, а во втором — что его нужно заменить. На сегодняшний день для «корпоративных» жестких дисков данный показатель составляет порядка 1 млн. ч, а для некоторых — даже 1,5 млн.
MTBF — параметр чисто статистический, рассчитанный путем экстраполяции данных
за сравнительно короткий промежуток времени.
Такие цифры просто не могут не впечатлять! В конце концов, в году всего 8760 ч, а значит, один миллион их соответствует 114 годам непрерывной работы. У некоторых, правда, подобные цифры вызовут недоумение, ведь жестким дискам всего-то от роду полсотни лет. Да и то если считать с момента, как IBM выпустила гигантский 350 Disk Storage Unit для своего компьютера RAMAC. Ну как тут не почесать в затылке?
Однако следует иметь в виду, что MTBF — параметр чисто статистический, рассчитанный путем экстраполяции данных за сравнительно короткий промежуток времени. И приведенные выше показатели свидетельствуют об очень высокой надежности жестких дисков: вероятность отказа любого из них в течение года не превышает 1%. Да торжествует хранение данных!
Вот только восторг перед MTBF несколько бледнеет, когда знакомишься с результатами последних исследований в данной области, представленными на конференции FAST’07. Это мероприятие, посвященное компьютерным файлам и их хранению, организовала и недавно провела в калифорнийском Сан-Хосе американская ассоциация передовых вычислительных систем USENIX.
Приз за лучший документ здесь получила работа Бьянки Шредер и Гарта Гибсона из питсбургского университета Карнеги — Меллона под названием «Disk Failures in the Real World: What Does an MTBF of 1,000,000 Hours Mean to You?» («Отказы жестких дисков в реальном мире: что значит для вас наработка в миллион часов?»).
Исследователи проанализировали показатели огромного количества жестких дисков, используемых в центрах массового хранения данных, в том числе на суперкомпьютерах и Web-серверах. И полученные результаты дали основания полагать, что общепринятое представление о надежности дисков вовсе не соответствует истине. Оказалось, скажем, что ежегодно приходится заменять не 1% жестких дисков, как следует из MTBF, а от 2 до 4%. Более того, в некоторых центрах эта цифра доходит даже до 13%. Приехали, что называется!
Противоречат выводы исследования и широко распространенному мнению, будто частота отказов дисков соответствует так называемой «кривой надежности». Из этой теории следует, что проблемы с любым электронным устройством, включая и жесткие диски, активно возникают в самом начале эксплуатации (Шредер и Гибсон назвали подобное явление «эффектом детской смертности»), затем их частота снижается и начинает снова нарастать через определенное время вследствие старения компонентов. Вот только практика показала иное. Согласно исследованию отказы дисков начинаются вовсе не через 5-10 лет эксплуатации, а уже в первые ее годы, после чего их уровень непрерывно растет.
Причем исследователи отметили «минимальные различия в частоте замены жестких дисков с интерфейсами SCSI, Fibre Channel и SATA». А это, по их мнению, «может указывать на то, что внешние факторы, например условия эксплуатации, оказывают на надежность дисков большее влияние, чем внутренняя конфигурация устройств».
Такие выводы, несомненно, вызовут бурю негодования в маркетинговых подразделениях производителей систем хранения и жестких дисков. Ведь корпоративные устройства оснащаются лучшими по сравнению с SATA механизмами, шпинделями с повышенной скоростью и более надежными компонентами (потому и стоят дороже). Если же уровень отказов определяется не этим, производителям есть над чем задуматься.
На той же самой конференции FAST еще один доклад на сходную тему прочитали инженеры Google. Их работа носит название «Failure Trends in a Large Disk Drive Population» («Тенденции отказов в средах с большим количеством дисков») и уже опубликована в формате PDF по адресу: http://labs.google.com/papers/disk_failures.pdf. Здесь основное внимание обращено на то, в какой степени созданные на базе технологии SMART (Self-Monitoring, Analysis and Reporting Technolo-gy — технология самопроверки, анализа и отчетности) микропрограммы жестких дисков способны прогнозировать выход такого оборудования из строя.
Технология SMART предусматривает анализ целого ряда механических и электрических показателей работы жесткого диска — что-то вроде системы предупреждения о нехватке масла в вашем автомобиле. Последняя постоянно следит за уровнем масла, и когда он опускается ниже заранее заданного порога, подает сигнал предупреждения, помогающий водителю избежать катастрофических для двигателя последствий.
Вот только специалисты Google — Эдуардо Пинейро, Вольф-Дитрих Вебер и Луис Андре Барросо — выяснили, что повышение температуры диска и потребляемой мощности вовсе не обязательно свидетельствует о намечающемся отказе. А SMART именно так и воспринимает эти симптомы.
С другой стороны, жесткие диски, у которых SMART начинает отмечать ошибки сканирования и переноса данных, выходят из строя на протяжении ближайшей пары месяцев в 39 раз чаще, чем диски без таких ошибок. Следовательно, «первые ошибки» можно считать надежным признаком приближающегося отказа.
Тем не менее, как считают исследователи, технология SMART со своей задачей справляется не слишком-то успешно. Вот что они пишут: «Несмотря на сильную корреляцию с количеством ошибок сканирования и переноса данных, сама по себе модель прогнозирования сбоев на основе параметров SMART страдает невысокой точностью. Подтверждением здесь может служить то, что значительная часть вышедших из строя дисков не подавала сигналов ни о каких ошибках».
Множество вопросов относительно надежности дисков задается компаниям-производителям и на блогах. На сайте StorageMojo, скажем, опубликовано довольно интересное открытое письмо Робина Харриса, призывающего разработчиков жестких дисков признать несостоятельность параметра MTBF. Описанные в нем случаи ставят под сомнение заявленный высокий уровень надежности некоторых массивов RAID. Вот что мы прочли в документе: «Многие читатели этого письма, думаю, согласятся со мной в том, что компании, которым ситуация известна лучше, чем кому бы то ни было (по крайней мере должна быть известна лучше), либо игнорируют неудобные для них факты, либо искажают их смысл. Взять, скажем, дискуссию относительно массива RAID-DP. Аргументация здесь основана на частоте необратимых ошибок считывания данных и не учитывает, например, того, что вероятность одновременного отказа сразу двух жестких дисков массива может оказаться больше предполагаемой. Зная, что в реальном мире диски выходят из строя в несколько раз чаще, чем обещают их производители, я поневоле ставлю под сомнение и расчетную вероятность битовых ошибок».
Дыма без огня, конечно, не бывает, однако здесь затронута очень сложная проблема. Невозможно найти два сайта, сервера или две среды, где условия работы жестких дисков были бы совершенно идентичными. Не говоря уже о том, что реальная эксплуатация существенно отличается от тестовых процедур изготовителя. А статистическая экстраполяция MTBF только умножает эти различия.
Вывод из представленных на конференции FAST исследований может быть только один: как бы высока ни была средняя наработка на отказ, в ИТ-бюджете необходимо обязательно предусматривать средства на замену жестких дисков. Это, правда, может урезать расходы на развертывание новых систем хранения, которые гораздо больше по душе менеджерам по информатизации и производителям таких устройств.
Здесь, думаю, уместно привести высказывание насчет MTBF, которое прозвучало на встрече группы пользователей сетевых хранилищ в Сан-Франциско. Один из выступивших здесь реселлеров прямо призвал производителей «не публиковать чушь».
Следовать этому призыву маркетинговые подразделения наверняка не станут, так что нам остается только одно: воспринимать публикуемые данные о средней наработке на отказ более реалистично.
| 30 января 2013 |
⇡#Технологии будущего: Shingled Recording, Heat-Assisted Recording, Bit-Patterned Media
3DNews : В новостях уже мелькают технологии под названиями Shingled Recording, Heat-Assisted Recording, Bit-Patterned Media, которые позволят плотности записи на HDD расти в будущем. В чем их сущность и как скоро можно ожидать появления коммерческих продуктов, в которых они будут внедрены?
Алекс Блеквелл: Shingled Recording — это такая странная технология, которая заимствует кое-что у SSD. Идея в том, чтобы, как и сейчас, записывать данные последовательно на магнитную пластину, только вместо одной дорожки здесь и одной там с промежутком между ними мы будем накладывать дорожки одна на другую. Но нам придется быть очень осторожными в том, как применять эту технологию. Потому что Shingled Recording повлияет на то, как хост-контроллер будет использовать привод. И в конце концов она может оказаться всего лишь нишевым решением для конкретного рынка, который будет в ней заинтересован.
Прим. автора: коль скоро дорожки накладываются друг на друга, при необходимости записать фрагмент данных на одной дорожке придется сначала прочитать и сохранить все данные из пересекающихся дорожек, а затем записать все это обратно на диск. Другой вариант — стараться производить запись на свободные участки, что приведет к сильной фрагментации файлов. Все это действительно очень похоже на то, как работает SSD с NAND-памятью, которая также позволяет освобождать ячейки для перезаписи только в виде крупных блоков (скажем, по 128 Кбайт). Поскольку у жестких дисков и так плохи дела с произвольным доступом, то похоже, что дискам с Shingled Recording уготована судьба хранилищ больших объемов данных с преимущественно последовательной записью.
Cледующая технология — Heat-Assisted Recording. Возьмем кусок масла. Вы достаете его из холодильника и кладете на стол в теплый день. Тогда оно становится очень мягким, и в нем можно проделать дырку пальцем. Но чтобы сделать дырку в куске сразу из холодильника, нужно что-то очень острое. Точно так же удобно представить свойство магнитного носителя — coercivity.
Коэрцитивная сила — такое размагничивающее внешнее магнитное поле напряженностью H, которое необходимо приложить к ферромагнетику, предварительно намагниченному до насыщения, чтобы довести до нуля его намагниченность I или индукцию магнитного поля B внутри (Wikipedia).
Для диска с малой плотностью записи подходит мягкое масло (низкое coercivity) и толстый палец (большое расстояние между головкой и носителем). Для диска с большой плотностью записи, чтобы удерживать намагниченные участки, нужно твердое масло (высокое coercivity), а чтобы производить запись — очень, очень острый «палец»: большая напряженность магнитного поля и меньший зазор между записывающей головкой и носителем.
Возьмем жесткий диск IBM из 1950-х. Можно было разглядеть провода, накрученные на головке, и расстояние до носителя. Теперь головки изготавливаются как интегральные схемы, из тонкопленочных материалов. Но я, вероятно, буду вынужден вас убить, если расскажу о головках слишком много. Головки — это технология, которая держит нас в бизнесе.
Итак, мы можем развить только ограниченную напряженность магнитного поля. И приблизить головку к носителю тоже уже не можем. Но мы можем сделать намагниченный носитель «тверже». Нам нужен небольшой лазер, чтобы сделать масло мягким, проделать в нем дырку и положить обратно в холодильник. Вы можете ожидать, что эта технология станет коммерчески доступной в течение двух-трех лет. Но сначала — Shingled Recording, которая может как сочетаться с Heat-Assisted Recording, так и применяться отдельно.
Heat-Assisted Magnetic Recording (HAMR)
Другая технология, которая значится в нашем технологическом roadmap’е после HAMR, — это Bit-Patterned Media. HAMR, как и сейчас, все еще подразумевает использование непрерывного носителя, хотя и из экзотических материалов. А Bit-Patterned Media означает запись индивидуальных битов данных, окруженных пустотой. Тогда намагниченные участки смогут располагаться очень близко друг к другу, не вызывая интерференции. Проблема в том, чтобы создать структуры такого размера. Существующая литография не дает нам даже той плотности записи, которую мы имеем с непрерывным носителем. Должны произойти большие улучшения в литографии, чтобы за счет Bit-Patterned Media произошло увеличение плотности записи.
⇡#«Нативная» поддержка секторов 4 Кбайт
3DNews : Ну когда уже?
Алекс Блеквелл: Мы хотели бы увидеть «нативную» поддержку секторов 4 Кбайт. Они уже дали нам преимущество на уровне самого накопителя: форматирование стало на 10% эффективнее, коррекция ошибок — проще. Но только представьте, столько денег уже вложено в инфраструктуру, построенную вокруг секторов 512 бит…
Я бы показал вам диск WD с «нативной» поддержкой секторов 4 Кбайт прямо сейчас (нужно только сначала заказать из США). А как только рынок будет к этому готов, мы тут же можем начать их продавать. Достаточно одного-двух месяцев на подготовку.
⇡#Жесткие диски с гелием. До семи пластин в корпусе
3DNews : HGST не так давно продемонстрировала жесткий диск, вместо воздуха заполненный гелием. Будут ли за счет этого действительно коммерчески производиться жесткие диски с семью магнитными пластинами?
Алекс Блеквелл: Гелий хорош тем, что он менее плотный по сравнению с воздухом. Из-за меньшей плотности можно сделать магнитные пластины тоньше и легче, можно поместить больше пластин в корпус, вплоть до семи. Подумайте о компаниях, которые хотят получить максимальную плотность данных на квадратный метр. Вот им понравятся такие диски.
3DNews : А нельзя ли было с таким же успехом просто разрядить воздух внутри корпуса?
Алекс Блеквелл: Мы все используем аэродинамическую технику, чтобы контролировать расстояние от головки до поверхности носителя. И я не знаю, какова будет физика при использовании разряженного воздуха. Я также думал об использовании водорода вместо гелия. И об этом я также не могу ничего сказать. Водород легче получить, чем гелий, — путем электролиза воды. А вот ресурс гелия ограничен, и, чтобы получить больше, нам нужен токамак — установка для термоядерного синтеза. Хотя если гелия хватает для наполнения шариков, то, предполагаю, будет достаточно и для жестких дисков.
На самом деле, мы сейчас уже используем гелий в процессе производства. Привод заполняется гелием на стадии, которая требует большой точности позиционирования головок. Сложность при внедрении гелия в коммерческих продуктах состоит в том, чтобы удержать его внутри по меньшей мере в течение гарантийного срока. Молекула газа очень маленькая, поэтому легко выходит через мельчайшие поры. Я не знаю подробностей о том, как это сделала HGST, но если вы посмотрите на конструкцию жесткого диска, то увидите элементы, на которые для этого нужно обратить особое внимание.
Первая вещь — нужно заблокировать воздушный фильтр. Привод превратится в сосуд под давлением. Вторая — нужно убедиться, что прокладка между крышкой и корпусом не является пористой для гелия. Это задача по части материалов.
3DNews : Появятся ли когда-нибудь диски с гелием под брендом WD?
Алекс Блеквелл: Я никогда не говорю «никогда». Мы уже используем гелий в производстве и знаем, какие технологии для этого нужны. Кроме того, преимущество в нашей индустрии часто измеряется в месяцах, а не в годах.
⇡#Про надежность, долговечность и статистику
3DNews : Каков расчетный срок жизни отдельно взятого привода? Возьмем жесткий диск с MTBF (mean time between failures, «среднее время наработки на отказ») на уровне 1 млн часов. В пересчете на годы это даст совершенно нереальный срок жизни в 114 лет. Похоже, что так просто MTBF в срок жизни не переводится…
Алекс Блеквелл: На самом деле MTBF не является утверждением о долговечности отдельно взятого диска. Это статистическое утверждение о популяции дисков. Миллион часов MTBF говорит мне, что я, будучи менеджером дата-центра с сотней тысяч дисков, могу ожидать, что один из них будет отказывать каждые 10 часов. Что даст мне возможность понять, сколько запасных приводов нужно иметь на руках.
MTBF вычисляется с помощью такого теста. Если вам нужно получить MTBF 2 млн часов, вы должны сгенерировать больше 2 млн часов работы. Наполняете стойки тысячей дисков и гоняете в течение тысячи часов (шесть недель). Так и получается миллион часов. А еще мы можем повысить температуру тестового стенда, ускоряя в четыре раза амортизацию дисков. Вот уже 4 млн часов работы. Если за это время два диска отказали, то и получается MTBF 2 млн часов. На самом деле мы начали удалять MTBF из наших документов на устройства, ибо люди зачастую неправильно понимают, что означают эти числа.
И все же, какова сервисная жизнь отдельно взятого диска? По консервативной оценке, она составляет не меньше 5 лет. Вы сами вряд ли знаете кого-то, кто использовал бы компьютер старше этого срока. Проживет ли диск дольше — зависит эксплуатации. Это как машина. Если каждый день ездишь по сотне километров, то она износится быстрее, чем машина, которая выходит из гаража только в выходные.
Более точную оценку продолжительности жизни дать трудно, так как сейчас в ходу мало дисков десятилетнего возраста. Диск такой давности имеет объем всего 10-40 Гбайт, большинство из них находятся в снятых с гарантии и более неиспользуемых компьютерах. Нет данных. Все, что у нас есть на этот счет, — это частные, иногда анекдотические свидетельства. Например, один из моих клиентов недавно списал массив дисков WD, которые были куплены пять лет назад, и все до единого еще работали. А это был дата-центр с режимом работы 24/7.
Корпоративные жесткие диски изначально проектируются с упором на надежность. Это и подбор компонентов, и конструкция. Например, в дисках форм-фактора 2,5 дюйма на 15 000 об/мин используются пластины емкостью 300 Гбайт. В то время как высшая на сегодня емкость пластины этого размера — 500 Гбайт. Надежность — серьезная дисциплина. У нас в Western Digital этим занимаются множество людей со степенью PhD.
Важный фактор, который вносит вклад в надежность жесткого диска, — это температура. Чем она выше, тем чаще они ломаются. Температура — это все. У нас есть модель связи количества отказов и так называемой эффективной активационной энергии, в которую вносит свой вклад и температура. Похожие модели есть и у Seagate, HGST, Toshiba. Они очень точные, все это легко измерить и проверить. Для владельцев дата-центров мой совет: держите жесткие диски в диапазоне 40–50 °C.
⇡#Балансировка магнитных пластин
3DNews : Одна из технологий, которые отличают недавно вышедшие диски серии WD Red, как и корпоративные винчестеры WD, — 3D Active Balance Plus. Что это значит?
Алекс Блеквелл: Как на колесо машины, на блок магнитных пластин на шпинделе действуют дисбалансирующие силы в двух направлениях: одна трясет (вектор в плоскости пластин), другая качает (вектор перпендикулярный). Чтобы компенсировать силу типа «трясет», мы помещаем кусочек проволоки в виде круга с разрывом в узел мотора. Чтобы справиться с той, которая «качает», мы помещаем «пробку» в одно из отверстий на шпинделе. Такой мелкий цветной кусочек пластика.
Post Views:
Наработка на отказ — Википедия
Материал из Википедии — свободной энциклопедии
Сре́дняя нарабо́тка на отка́з (англ. Mean time between failures, MTBF) — технический параметр, характеризующий надёжность восстанавливаемого прибора, устройства или технической системы.
Средняя продолжительность работы устройства между отказами, то есть показывает, какая наработка в среднем приходится на один отказ. Выражается в часах.
- T=∑1mtim{\displaystyle T={\sum _{1}^{m}t_{i} \over m}}
где ti — наработка до наступления отказа i; m — число отказов.
Измеряется статистически, путём испытания множества приборов, или вычисляется методами теории надёжности.
Для программных продуктов обычно подразумевается срок до полного перезапуска программы или полной перезагрузки операционной системы.
Средняя наработка до отказа (англ. Mean time to failure, MTTF) — эквивалентный параметр для неремонтопригодного устройства. Поскольку устройство не восстанавливаемое, то это просто среднее время, которое проработает устройство до того момента, как сломается.
Наработка — продолжительность или объем работы объекта, измеряемая в часах, мото-часах, гектарах, километрах пробега, циклах включения-выключения и др.
ГОСТ 27.002-89 определяет данные параметры следующим образом:
- Наработка между отказами (англ. Operating time between failures) — наработка объекта от окончания восстановления его работоспособного состояния после отказа до возникновения следующего отказа.
- Наработка до отказа (англ. Operating time to failure) — наработка объекта от начала эксплуатации до возникновения первого отказа.
- Средняя наработка на отказ (англ. Mean operating time between failures) — отношение суммарной наработки восстанавливаемого объекта к математическому ожиданию числа его отказов в течение этой наработки.
- Средняя наработка до отказа (англ. Mean operating time to failure) — математическое ожидание наработки объекта до первого отказа.
В английской литературе MTBF (англ. Mean time between failures — среднее время между отказами, наработка на отказ) — среднее время между возникновениями отказов.[1]; термин обычно касается работы оборудования. Единица размерности — час.
Системы, связанные с обеспечением безопасности, можно условно подразделить на две категории:
- работающие в режиме низкой частоты запросов;
- и в режиме высокой частоты запросов (непрерывно).
IEC 61508 (англ.)русск. количественно определяет эту классификацию, устанавливая, что частота запросов на работу системы обеспечения безопасности не превышает одного раза в год в режиме низкой частоты запросов, и более раза в год в режиме высокой частоты запросов (непрерывной работы).
Значение SIL (англ.)русск. для систем обеспечения безопасности с низкой частотой запросов непосредственно зависит от диапазонов порядков средней вероятности того, что она не сможет удовлетворительно выполнить свои функции по обеспечению безопасности по запросу, или, проще говоря, от вероятности отказа при запросе (PFD). Значение SIL для систем обеспечения безопасности, работающих в режиме высокой частоты запросов (непрерывно) непосредственно зависит от вероятности возникновения опасного отказа в час (PFH).
- PFD (Probability of Failure on Demand, Вероятность отказа при запросе) — средняя вероятность того, что система не выполнит свою функцию по запросу.
- PFH (Probability of Failure per Hour, Вероятность возникновения отказа за час) — вероятность возникновения в системе опасного отказа в течение часа.
- MTTR (Mean Time to Restoration, Среднее время до восстановления работоспособности) — среднее время, необходимое для восстановления нормальной работы после возникновения отказа.
- DC (Diagnostic Coverage, Диагностическое покрытие) — отношение количества обнаруженных отказов к общему числу отказов.
В свою очередь, λ = частота отказов = 1/MTBF (для экспоненциального распределения отказов)
Для устройства с технической характеристикой MTTF, равной 1 000 000 часов[2][править | править код]
Для одного устройства:
- Техническая характеристика MTTF устройства 1 000 000 часов
- Расчётная вероятность отказа устройства для времени 1 000 000 часов (~114 лет) равна: 50,000 %
- Расчётная вероятность отказа устройства для времени 100 000 часов (~11 лет) равна: 6,697 %
- Расчётная вероятность отказа устройства для времени 87660 часов (10 лет) равна: 5,895 %
- Расчётная вероятность отказа устройства для времени 43830 часов (5 лет) равна: 2,992 %
- Расчётная вероятность отказа устройства для времени 8766 часов (1 год) равна: 0,606 %
Для двух устройств. Отказ хотя бы одного устройства:
- Техническая характеристика MTTF устройства 1 000 000 часов
- Расчётная вероятность отказа хотя бы одного из двух устройств для времени 1 000 000 часов (114 лет) равна: 75,000 %
- Расчётная вероятность отказа хотя бы одного из двух устройств для времени 100 000 часов (~11 лет) равна: 12,945 %
- Расчётная вероятность отказа хотя бы одного из двух устройств для времени 87660 часов (10 лет) равна: 11,443 %
- Расчётная вероятность отказа хотя бы одного из двух устройств для времени 43830 часов (5 лет) равна: 5,895 %
- Расчётная вероятность отказа хотя бы одного из двух устройств для времени 8766 часов (1 год) равна: 1,208 %
Для двух устройств. Отказ всех устройств:
- Техническая характеристика MTTF устройства 1 000 000 часов
- Расчётная вероятность отказа сразу 2 устройств для времени 1 000 000 часов (114 лет) равна: 25,000 %
- Расчётная вероятность отказа сразу 2 устройств для времени 100 000 часов равна: 0,448 %
- Расчётная вероятность отказа сразу 2 устройств для времени 87660 часов (~11 лет) (10 лет) равна: 0,348 %
- Расчётная вероятность отказа сразу 2 устройств для времени 43830 часов (5 лет) равна: 0,09 %
- Расчётная вероятность отказа сразу 2 устройств для времени 8766 часов (1 год) менее 0,0003 %
Для 10 устройств: Отказ хотя бы одного устройства:
- Техническая характеристика MTTF устройства 1 000 000 часов
- Расчётная вероятность отказа хотя бы одного из 10 устройств для времени 1 000 000 часов (114 лет) равна: 99,902 %
- Расчётная вероятность отказа хотя бы одного из 10 устройств для времени 100 000 часов (~11 лет) равна: 50%
- Расчётная вероятность отказа хотя бы одного из 10 устройств для времени 87660 часов (10 лет) равна: 45,535 %
- Расчётная вероятность отказа хотя бы одного из 10 устройств для времени 43830 часов (5 лет) равна: 26,2 %
- Расчётная вероятность отказа хотя бы одного из 10 устройств для времени 8766 часов (1 год) равна: 5,895 %
Для 100 устройств: Отказ хотя бы одного устройства:
- Техническая характеристика MTTF устройства 1 000 000 часов
- Расчётная вероятность отказа хотя бы одного из 100 устройств для времени 1 000 000 часов (114 лет) близка к 100 %
- Расчётная вероятность отказа хотя бы одного из 100 устройств для времени 100 000 часов (~11 лет) равна: 99,902 %
- Расчётная вероятность отказа хотя бы одного из 100 устройств для времени 87660 часов (10 лет) равна: 99,77 %
- Расчётная вероятность отказа хотя бы одного из 100 устройств для времени 43830 часов (5 лет) равна: 95,207 %
- Расчётная вероятность отказа хотя бы одного из 100 устройств для времени 8766 часов (1 год) равна: 45,535 %
- ↑ Использование ControlLogix в приложениях SIL2. Справочное руководство по обеспечению безопасности Rockwell Automation. Публикация 1756-RM001C-EN-P- Апрель 2004
- ↑ С равномерным распределением во времени вероятности отказа
то, о чем вы даже не подозревали / Аналитика
⇡#Технологии будущего: Shingled Recording, Heat-Assisted Recording, Bit-Patterned Media
3DNews: В новостях уже мелькают технологии под названиями Shingled Recording, Heat-Assisted Recording, Bit-Patterned Media, которые позволят плотности записи на HDD расти в будущем. В чем их сущность и как скоро можно ожидать появления коммерческих продуктов, в которых они будут внедрены?
Алекс Блеквелл: Shingled Recording — это такая странная технология, которая заимствует кое-что у SSD. Идея в том, чтобы, как и сейчас, записывать данные последовательно на магнитную пластину, только вместо одной дорожки здесь и одной там с промежутком между ними мы будем накладывать дорожки одна на другую. Но нам придется быть очень осторожными в том, как применять эту технологию. Потому что Shingled Recording повлияет на то, как хост-контроллер будет использовать привод. И в конце концов она может оказаться всего лишь нишевым решением для конкретного рынка, который будет в ней заинтересован.
Прим. автора: коль скоро дорожки накладываются друг на друга, при необходимости записать фрагмент данных на одной дорожке придется сначала прочитать и сохранить все данные из пересекающихся дорожек, а затем записать все это обратно на диск. Другой вариант — стараться производить запись на свободные участки, что приведет к сильной фрагментации файлов. Все это действительно очень похоже на то, как работает SSD с NAND-памятью, которая также позволяет освобождать ячейки для перезаписи только в виде крупных блоков (скажем, по 128 Кбайт). Поскольку у жестких дисков и так плохи дела с произвольным доступом, то похоже, что дискам с Shingled Recording уготована судьба хранилищ больших объемов данных с преимущественно последовательной записью.
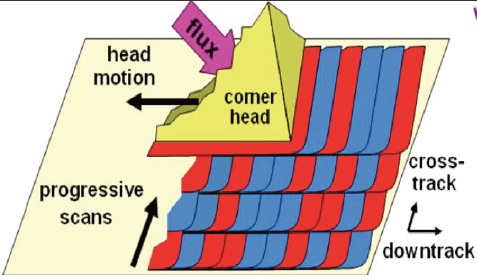
Shingled Recording
Cледующая технология — Heat-Assisted Recording. Возьмем кусок масла. Вы достаете его из холодильника и кладете на стол в теплый день. Тогда оно становится очень мягким, и в нем можно проделать дырку пальцем. Но чтобы сделать дырку в куске сразу из холодильника, нужно что-то очень острое. Точно так же удобно представить свойство магнитного носителя — coercivity.
Коэрцитивная сила — такое размагничивающее внешнее магнитное поле напряженностью H, которое необходимо приложить к ферромагнетику, предварительно намагниченному до насыщения, чтобы довести до нуля его намагниченность I или индукцию магнитного поля B внутри (Wikipedia).
Для диска с малой плотностью записи подходит мягкое масло (низкое coercivity) и толстый палец (большое расстояние между головкой и носителем). Для диска с большой плотностью записи, чтобы удерживать намагниченные участки, нужно твердое масло (высокое coercivity), а чтобы производить запись — очень, очень острый «палец»: большая напряженность магнитного поля и меньший зазор между записывающей головкой и носителем.
Возьмем жесткий диск IBM из 1950-х. Можно было разглядеть провода, накрученные на головке, и расстояние до носителя. Теперь головки изготавливаются как интегральные схемы, из тонкопленочных материалов. Но я, вероятно, буду вынужден вас убить, если расскажу о головках слишком много. Головки — это технология, которая держит нас в бизнесе.
Итак, мы можем развить только ограниченную напряженность магнитного поля. И приблизить головку к носителю тоже уже не можем. Но мы можем сделать намагниченный носитель «тверже». Нам нужен небольшой лазер, чтобы сделать масло мягким, проделать в нем дырку и положить обратно в холодильник. Вы можете ожидать, что эта технология станет коммерчески доступной в течение двух-трех лет. Но сначала — Shingled Recording, которая может как сочетаться с Heat-Assisted Recording, так и применяться отдельно.

Heat-Assisted Magnetic Recording (HAMR)
Другая технология, которая значится в нашем технологическом roadmap’е после HAMR, — это Bit-Patterned Media. HAMR, как и сейчас, все еще подразумевает использование непрерывного носителя, хотя и из экзотических материалов. А Bit-Patterned Media означает запись индивидуальных битов данных, окруженных пустотой. Тогда намагниченные участки смогут располагаться очень близко друг к другу, не вызывая интерференции. Проблема в том, чтобы создать структуры такого размера. Существующая литография не дает нам даже той плотности записи, которую мы имеем с непрерывным носителем. Должны произойти большие улучшения в литографии, чтобы за счет Bit-Patterned Media произошло увеличение плотности записи.

Bit-Patterned Media
⇡#«Нативная» поддержка секторов 4 Кбайт
3DNews: Ну когда уже?
Алекс Блеквелл: Мы хотели бы увидеть «нативную» поддержку секторов 4 Кбайт. Они уже дали нам преимущество на уровне самого накопителя: форматирование стало на 10% эффективнее, коррекция ошибок — проще. Но только представьте, столько денег уже вложено в инфраструктуру, построенную вокруг секторов 512 бит…
Я бы показал вам диск WD с «нативной» поддержкой секторов 4 Кбайт прямо сейчас (нужно только сначала заказать из США). А как только рынок будет к этому готов, мы тут же можем начать их продавать. Достаточно одного-двух месяцев на подготовку.
⇡#Жесткие диски с гелием. До семи пластин в корпусе
3DNews: HGST не так давно продемонстрировала жесткий диск, вместо воздуха заполненный гелием. Будут ли за счет этого действительно коммерчески производиться жесткие диски с семью магнитными пластинами?
Алекс Блеквелл: Гелий хорош тем, что он менее плотный по сравнению с воздухом. Из-за меньшей плотности можно сделать магнитные пластины тоньше и легче, можно поместить больше пластин в корпус, вплоть до семи. Подумайте о компаниях, которые хотят получить максимальную плотность данных на квадратный метр. Вот им понравятся такие диски.

3DNews: А нельзя ли было с таким же успехом просто разрядить воздух внутри корпуса?
Алекс Блеквелл: Мы все используем аэродинамическую технику, чтобы контролировать расстояние от головки до поверхности носителя. И я не знаю, какова будет физика при использовании разряженного воздуха. Я также думал об использовании водорода вместо гелия. И об этом я также не могу ничего сказать. Водород легче получить, чем гелий, — путем электролиза воды. А вот ресурс гелия ограничен, и, чтобы получить больше, нам нужен токамак — установка для термоядерного синтеза. Хотя если гелия хватает для наполнения шариков, то, предполагаю, будет достаточно и для жестких дисков.
На самом деле, мы сейчас уже используем гелий в процессе производства. Привод заполняется гелием на стадии, которая требует большой точности позиционирования головок. Сложность при внедрении гелия в коммерческих продуктах состоит в том, чтобы удержать его внутри по меньшей мере в течение гарантийного срока. Молекула газа очень маленькая, поэтому легко выходит через мельчайшие поры. Я не знаю подробностей о том, как это сделала HGST, но если вы посмотрите на конструкцию жесткого диска, то увидите элементы, на которые для этого нужно обратить особое внимание.
Первая вещь — нужно заблокировать воздушный фильтр. Привод превратится в сосуд под давлением. Вторая — нужно убедиться, что прокладка между крышкой и корпусом не является пористой для гелия. Это задача по части материалов.
3DNews: Появятся ли когда-нибудь диски с гелием под брендом WD?
Алекс Блеквелл: Я никогда не говорю «никогда». Мы уже используем гелий в производстве и знаем, какие технологии для этого нужны. Кроме того, преимущество в нашей индустрии часто измеряется в месяцах, а не в годах.
⇡#Про надежность, долговечность и статистику
3DNews: Каков расчетный срок жизни отдельно взятого привода? Возьмем жесткий диск с MTBF (mean time between failures, «среднее время наработки на отказ») на уровне 1 млн часов. В пересчете на годы это даст совершенно нереальный срок жизни в 114 лет. Похоже, что так просто MTBF в срок жизни не переводится…
Алекс Блеквелл: На самом деле MTBF не является утверждением о долговечности отдельно взятого диска. Это статистическое утверждение о популяции дисков. Миллион часов MTBF говорит мне, что я, будучи менеджером дата-центра с сотней тысяч дисков, могу ожидать, что один из них будет отказывать каждые 10 часов. Что даст мне возможность понять, сколько запасных приводов нужно иметь на руках.
MTBF вычисляется с помощью такого теста. Если вам нужно получить MTBF 2 млн часов, вы должны сгенерировать больше 2 млн часов работы. Наполняете стойки тысячей дисков и гоняете в течение тысячи часов (шесть недель). Так и получается миллион часов. А еще мы можем повысить температуру тестового стенда, ускоряя в четыре раза амортизацию дисков. Вот уже 4 млн часов работы. Если за это время два диска отказали, то и получается MTBF 2 млн часов. На самом деле мы начали удалять MTBF из наших документов на устройства, ибо люди зачастую неправильно понимают, что означают эти числа.
И все же, какова сервисная жизнь отдельно взятого диска? По консервативной оценке, она составляет не меньше 5 лет. Вы сами вряд ли знаете кого-то, кто использовал бы компьютер старше этого срока. Проживет ли диск дольше — зависит эксплуатации. Это как машина. Если каждый день ездишь по сотне километров, то она износится быстрее, чем машина, которая выходит из гаража только в выходные.
Более точную оценку продолжительности жизни дать трудно, так как сейчас в ходу мало дисков десятилетнего возраста. Диск такой давности имеет объем всего 10-40 Гбайт, большинство из них находятся в снятых с гарантии и более неиспользуемых компьютерах. Нет данных. Все, что у нас есть на этот счет, — это частные, иногда анекдотические свидетельства. Например, один из моих клиентов недавно списал массив дисков WD, которые были куплены пять лет назад, и все до единого еще работали. А это был дата-центр с режимом работы 24/7.
Корпоративные жесткие диски изначально проектируются с упором на надежность. Это и подбор компонентов, и конструкция. Например, в дисках форм-фактора 2,5 дюйма на 15 000 об/мин используются пластины емкостью 300 Гбайт. В то время как высшая на сегодня емкость пластины этого размера — 500 Гбайт. Надежность — серьезная дисциплина. У нас в Western Digital этим занимаются множество людей со степенью PhD.
Важный фактор, который вносит вклад в надежность жесткого диска, — это температура. Чем она выше, тем чаще они ломаются. Температура — это все. У нас есть модель связи количества отказов и так называемой эффективной активационной энергии, в которую вносит свой вклад и температура. Похожие модели есть и у Seagate, HGST, Toshiba. Они очень точные, все это легко измерить и проверить. Для владельцев дата-центров мой совет: держите жесткие диски в диапазоне 40–50 °C.
⇡#Балансировка магнитных пластин
3DNews: Одна из технологий, которые отличают недавно вышедшие диски серии WD Red, как и корпоративные винчестеры WD, — 3D Active Balance Plus. Что это значит?
Алекс Блеквелл: Как на колесо машины, на блок магнитных пластин на шпинделе действуют дисбалансирующие силы в двух направлениях: одна трясет (вектор в плоскости пластин), другая качает (вектор перпендикулярный). Чтобы компенсировать силу типа «трясет», мы помещаем кусочек проволоки в виде круга с разрывом в узел мотора. Чтобы справиться с той, которая «качает», мы помещаем «пробку» в одно из отверстий на шпинделе. Такой мелкий цветной кусочек пластика.

Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.