
Механизмы поисковых систем — Поисковые системы в интернете
Понятие «поисковая система» > Механизмы поисковых систем
|

 Чем качественней поиск они смогут
предоставить, тем больше людей будут им пользоваться.
Чем качественней поиск они смогут
предоставить, тем больше людей будут им пользоваться.Поисковые системы Интернета: Яндекс, Google, Rambler, Yahoo — информация, принципы работы
1. Введение
2. Понятие и функции поисковой системы
3. Основные характеристики поисковой системы
4. Краткая история развития поисковых систем
5. Состав и принципы работы поисковой системы
6. Заключение
1. Введение
Поисковые системы уже давно стали неотъемлемой частью российского Интернета. Поисковые системы сейчас – это огромные и сложные механизмы, представляющие собой не только инструмент поиска информации, но и заманчивые сферы для бизнеса.
Большинство пользователей поисковых систем никогда не задумывались (либо задумывались, но не нашли ответа) о принципе работы поисковых систем, о схеме обработки запросов пользователей, о том, из чего эти системы состоят и как функционируют…
Данный материал призван дать ответ на вопрос о том, как работают поисковые системы. Однако вы не найдете здесь факторов, влияющих на ранжирование документов. И тем более не стоит рассчитывать на подробное объяснение алгоритма работы Яндекса. Его, по словам Ильи Сегаловича, директора по технологиям и разработке поисковой машины «Яндекс», можно узнать лишь «под пыткой» самого Ильи Сегаловича.
Однако вы не найдете здесь факторов, влияющих на ранжирование документов. И тем более не стоит рассчитывать на подробное объяснение алгоритма работы Яндекса. Его, по словам Ильи Сегаловича, директора по технологиям и разработке поисковой машины «Яндекс», можно узнать лишь «под пыткой» самого Ильи Сегаловича.
2. Понятие и функции поисковой системы
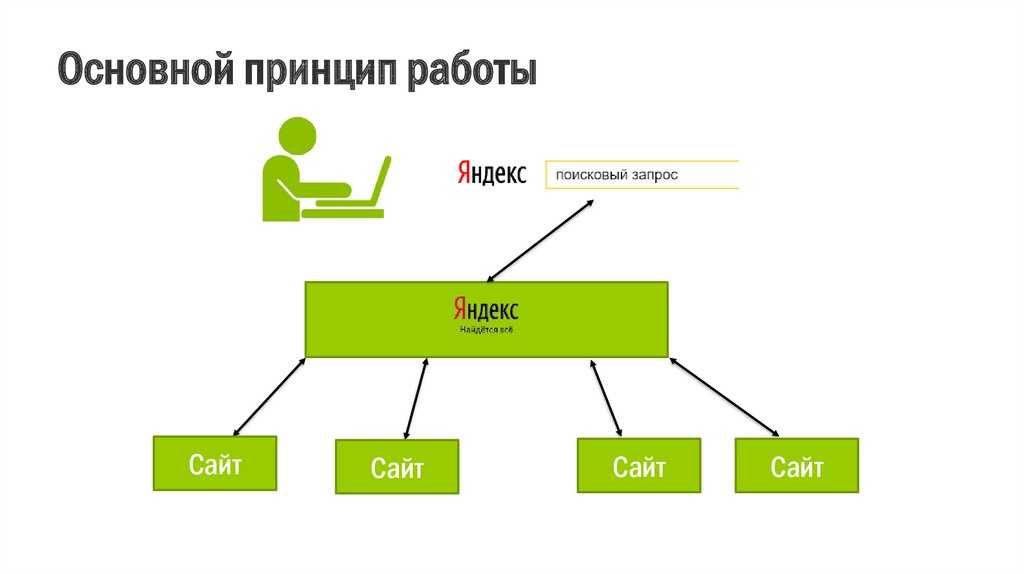
Рассмотрим подробнее понятие поискового запроса на примере поисковой системы «Яндекс». Поисковый запрос должен быть сформулирован пользователем в соответствии с тем, что он хочет найти, максимально кратко и просто. Допустим, мы хотим найти информацию в «Яндексе» о том, как выбрать автомобиль. Для этого, открываем главную страницу «Яндекса», и вводим текст поискового запроса «как выбрать автомобиль». Далее, наша задача сводится к тому, чтобы открыть предоставленные по нашему запросу ссылки на источники информации в Интернет. Однако, вполне можно и не найти нужную нам информацию. Если таковое произошло, то либо нужно перефразировать свой запрос, либо в базе поисковой системе действительно нет никакой актуальной информации по нашему запросу (такое может быть при задании очень «узких» запросов, как, например «как выбрать автомобиль в Архангельске»).
Допустим, мы хотим найти информацию в «Яндексе» о том, как выбрать автомобиль. Для этого, открываем главную страницу «Яндекса», и вводим текст поискового запроса «как выбрать автомобиль». Далее, наша задача сводится к тому, чтобы открыть предоставленные по нашему запросу ссылки на источники информации в Интернет. Однако, вполне можно и не найти нужную нам информацию. Если таковое произошло, то либо нужно перефразировать свой запрос, либо в базе поисковой системе действительно нет никакой актуальной информации по нашему запросу (такое может быть при задании очень «узких» запросов, как, например «как выбрать автомобиль в Архангельске»).
Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут. А научить пользователей делать «правильные» запросы к системе, т.е. запросы, соответствующие принципам работы поисковых систем, невозможно. Поэтому разработчики создают такие алгоритмы и принципы работы поисковых систем, которые бы позволяли находить пользователям искомую ими информацию.
Это означает, поисковая система должна «думать» так же, как думает пользователь при поиске информации. Когда пользователь обращается с запросом к поисковой машине, он хочет найти то, что ему нужно, максимально быстро и просто. Получая результат, он оценивает работу системы, руководствуясь несколькими основными параметрами. Нашел ли он то, что искал? Если не нашел, то сколько раз ему пришлось перефразировать запрос, чтобы найти искомое? Насколько актуальную информацию он смог найти? Насколько быстро обрабатывала запрос поисковая машина? Насколько удобно были представлены результаты поиска? Был ли искомый результат первым или же сотым? Как много ненужного мусора было найдено наравне с полезной информацией? Найдется ли нужная информация, при обращении к поисковой системе, скажем, через неделю, или через месяц?
Для того, чтобы удовлетворить ответами все эти вопросы, разработчики поисковых машин постоянно совершенствуют алгоритмы и принципы поиска, добавляют новые функции и возможности, всячески пытаются ускорить работу системы.
3. Основные характеристики поисковой системы
Опишем основные характеристики поисковых систем:
- Полнота
Полнота – одна из основных характеристик поисковой системы, представляющая собой отношение количества найденных по запросу документов к общему числу документов в сети Интернет, удовлетворяющих данному запросу. К примеру, если в Интернете имеется 100 страниц, содержащих словосочетание «как выбрать автомобиль», а по соответствующему запросу было найдено всего 60 из них, то полнота поиска будет 0,6. Очевидно, что чем полнее поиск, тем меньше вероятность того, что пользователь не найдет нужный ему документ, при условии, что он вообще существует в Интернете.
- Точность
Точность – еще одна основная характеристика поисковой машины, которая определяется степенью соответствия найденных документов запросу пользователя. Например, если по запросу «как выбрать автомобиль» находится 100 документов, в 50 из них содержится словосочетание «как выбрать автомобиль», а в остальных просто наличествуют эти слова («как правильно выбрать магнитолу и установить в автомобиль»), то точность поиска считается равной 50/100 (=0,5).

- Актуальность
Актуальность – не менее важная составляющая поиска, которая характеризуется временем, проходящим с момента публикации документов в сети Интернет, до занесения их в индексную базу поисковой системы. Например, на следующий день после появления интересной новости, большое количество пользователей обратились к поисковым системам с соответствующими запросами. Объективно с момента публикации новостной информации на эту тему прошло меньше суток, однако основные документы уже были проиндексированы и доступны для поиска, благодаря существованию у крупных поисковых систем так называемой «быстрой базы», которая обновляется несколько раз в день.
- Скорость поиска
Скорость поиска тесно связана с его устойчивостью к нагрузкам.
 Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов.
Например, по данным ООО «Рамблер Интернет Холдинг», на сегодняшний день в рабочие часы к поисковой машине Рамблер приходит около 60 запросов в секунду. Такая загруженность требует сокращения времени обработки отдельного запроса. Здесь интересы пользователя и поисковой системы совпадают: посетитель желает получить результаты как можно быстрее, а поисковая машина должна отрабатывать запрос максимально оперативно, чтобы не тормозить вычисление следующих запросов. - Наглядность
Наглядность представления результатов является важным компонентом удобного поиска. По большинству запросов поисковая машина находит сотни, а то и тысячи документов. Вследствие нечеткости составления запросов или неточности поиска, даже первые страницы выдачи не всегда содержат только нужную информацию. Это означает, что пользователю зачастую приходится производить свой собственный поиск внутри найденного списка. Различные элементы страницы выдачи поисковой системы помогают ориентироваться в результатах поиска.
 Подробные пояснения по странице результатов поиска, например у «Яндекса» можно посмотреть по ссылке http:\/\/help\.yandex\.ru\/search\/?id=481937.
Подробные пояснения по странице результатов поиска, например у «Яндекса» можно посмотреть по ссылке http:\/\/help\.yandex\.ru\/search\/?id=481937.
4. Краткая история развития поисковых систем
В начальный период развития Интернет, число его пользователей было невелико, а объем доступной информации сравнительно небольшим. В большинстве своем, доступ к сети Интернет имели лишь сотрудники научно-исследовательской сферы. В это время задача поиска информации в Интернете не была столь актуальной, как в настоящее время.
Одним из первых способов организации доступа к информационным ресурсам сети стало создание открытых каталогов сайтов, ссылки на ресурсы в которых группировались согласно тематике. Первым таким проектом стал сайт Yahoo.com, открывшийся весной 1994 года. После того, как количество сайтов в каталоге Yahoo значительно увеличилось, была добавлена возможность поиска нужной информации по каталогу. В полном смысле это еще не было поисковой системой, так как поисковая область была ограничена только ресурсами, присутствующими в каталоге, а не всеми Интернет ресурсами.
В полном смысле это еще не было поисковой системой, так как поисковая область была ограничена только ресурсами, присутствующими в каталоге, а не всеми Интернет ресурсами.
Каталоги ссылок широко использовались ранее, однако практически полностью утратили свою популярность в настоящее время. Так как даже современные, огромные по своему объему каталоги, содержат информацию лишь о ничтожно малой части сети Интернет. Самый большой каталог сети DMOZ (его еще называют Open Directory Project) содержит информацию о 5 миллионах ресурсов, тогда как база поисковой системы Google состоит из более чем 8 миллиардов документов.
Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
В 1995 году появились поисковые системы Lycos и AltaVista. Последняя долгие годы была лидером в области поиска информации в сети Интернет.
В 1997 году Сергей Брин и Ларри Пейдж создали поисковую машину Google в рамках исследовательского проекта в Стэндфордском университете. В настоящий момент Google –самая популярная поисковая система в мире!
В настоящий момент Google –самая популярная поисковая система в мире!
В сентябре 1997 года была официально анонсирована поисковая система Yandex, являющаяся самой популярной в русскоязычном Интернете.
В настоящее время существуют три основные поисковые системы (международные) – Google, Yahoo и MSN, имеющие собственные базы и алгоритмы поиска. Большинство остальных поисковых систем (коих насчитывается большое количество) использует в том или ином виде результаты трех перечисленных. Например, поиск AOL (search.aol.com) использует базу Google, а AltaVista, Lycos и AllTheWeb – базу Yahoo.
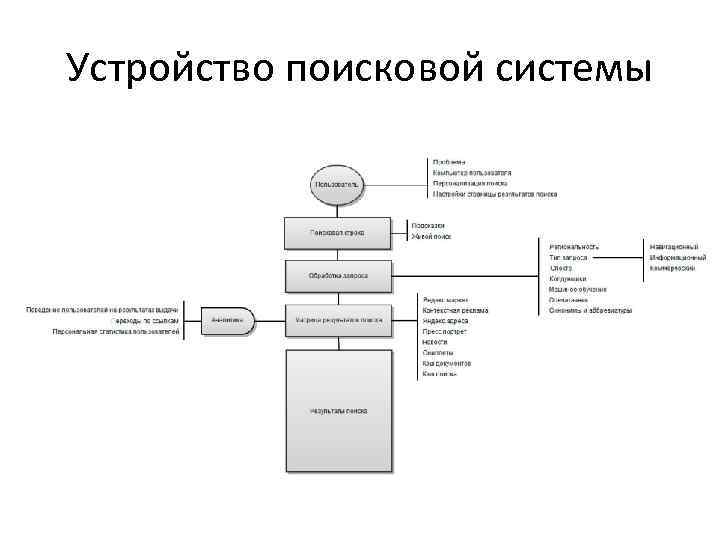
5. Состав и принципы работы поисковой системы
В России основной поисковой системой является «Яндекс», далее – Rambler.ru, Google.ru, Aport.ru, Mail.ru. Причем, на данный момент, Mail.ru использует механизм и базу поиска «Яндекса».
Практически все крупные поисковые системы имеют свою собственную структуру, отличную от других. Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Однако можно выделить общие для всех поисковых машин основные компоненты. Различия в структуре могут быть лишь в виде реализации механизмов взаимодействия этих компонентов.
Модуль индексирования
Модуль индексирования состоит из трех вспомогательных программ (роботов):
Spider (паук) – программа, предназначенная для скачивания веб-страниц. «Паук» обеспечивает скачивание страницы и извлекает все внутренние ссылки с этой страницы. Скачивается html-код каждой страницы. Для скачивания страниц роботы используют протоколы HTTP. Работает «паук» следующим образом. Робот на сервер передает запрос “get/path/document” и некоторые другие команды HTTP-запроса. В ответ робот получает текстовый поток, содержащий служебную информацию и непосредственно сам документ.
Ссылки извлекаются из тэгов a, area, base, frame, frameset, и др. Наряду со ссылками, многими роботами обрабатываются редиректы (перенаправления). Каждая скачанная страница сохраняется в следующем формате:
- URL страницы
- дата, когда страница была скачана
- http-заголовок ответа сервера
- тело страницы (html-код)
Crawler («путешествующий» паук) – программа, которая автоматически проходит по всем ссылкам, найденным на странице. Выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Выделяет все ссылки, присутствующие на странице. Его задача — определить, куда дальше должен идти паук, основываясь на ссылках или исходя из заранее заданного списка адресов. Crawler, следуя по найденным ссылкам, осуществляет поиск новых документов, еще неизвестных поисковой системе.
Indexer (робот- индексатор) – программа, которая анализирует веб-страницы, скаченные пауками. Индексатор разбирает страницу на составные части и анализирует их, применяя собственные лексические и морфологические алгоритмы. Анализу подвергаются различные элементы страницы, такие как текст, заголовки, ссылки структурные и стилевые особенности, специальные служебные html-теги и т.д.
Таким образом, модуль индексирования позволяет обходить по ссылкам заданное множество ресурсов, скачивать встречающиеся страницы, извлекать ссылки на новые страницы из получаемых документов и производить полный анализ этих документов.
База данных
База данных, или индекс поисковой системы — это система хранения данных, информационный массив, в котором хранятся специальным образом преобразованные параметры всех скачанных и обработанных модулем индексирования документов.
Поисковый сервер
Поисковый сервер является важнейшим элементом всей системы, так как от алгоритмов, которые лежат в основе ее функционирования, напрямую зависит качество и скорость поиска.
Поисковый сервер работает следующим образом:
- Полученный от пользователя запрос подвергается морфологическому анализу. Генерируется информационное окружение каждого документа, содержащегося в базе (которое и будет впоследствии отображено в виде сниппета, то есть соответствующей запросу текстовой информации на странице выдачи результатов поиска).
- Полученные данные передаются в качестве входных параметров специальному модулю ранжирования. Происходит обработка данных по всем документам, в результате чего, для каждого документа рассчитывается собственный рейтинг, характеризующий релевантность запроса, введенного пользователем, и различных составляющих этого документа, хранящихся в индексе поисковой системы.
- В зависимости от выбора пользователя этот рейтинг может быть скорректирован дополнительными условиями (например, так называемый «расширенный поиск»).

- Далее генерируется сниппет, то есть, для каждого найденного документа из таблицы документов извлекаются заголовок, краткая аннотация, наиболее соответствующая запросу и ссылка на сам документ, причем найденные слова подсвечиваются.
- Полученные результаты поиска передаются пользователю в виде SERP (Search Engine Result Page) – страницы выдачи поисковых результатов.
Как видно, все эти компоненты тесно связаны друг с другом и работают во взаимодействии, образовывая четкий, достаточно сложный механизм работы поисковой системы, требующий огромных затрат ресурсов.
По информации ООО «Рамблер Интернет Холдинг» обработка поискового запроса в системе «Рамблер» происходит, так, как это изображено на рисунке.
Запрос поступает в поисковую систему через маршрутизатор Cisco 6000 series. Cisco передает его наименее загруженной машине первого уровня — frontend (1.1 — 1.3, на рис. машине 1.3). Frontend, в свою очередь, отправляет запрос дальше, на один из восьми proxy-серверов, также выбирая наиболее свободный сервер (2. 1 — 2.8, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 — 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 — 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, — backends (5.1.х — 5.7.х, на рис. машинам 5.1.2, 5.2.11, 5.3.1 и т.д.) Та же информация отправляется на машины с «быстрой базой» (6.1 — 6.2).
1 — 2.8, на рис. машине 2.2). Одновременно frontend отправляет запрос на машины, осуществляющие поиск по товарам (3.1 — 3.2, на рис. машине 3.1) и по базе Тор 100 (4.1 — 4.2, на рис. машине 4.1). На proxy проводится поиск по ссылочному индексу, и его результаты вместе с поисковым запросом передаются на машины, которые содержат основную индексную базу, — backends (5.1.х — 5.7.х, на рис. машинам 5.1.2, 5.2.11, 5.3.1 и т.д.) Та же информация отправляется на машины с «быстрой базой» (6.1 — 6.2).
На текущий момент в поиск включено 77 backend’ов. Они сгруппированы по 11 машин, и каждая группа содержит копию одной из частей поискового индекса. Таким образом, информация о сайтах, условно входящих в красный сектор Интернета, находится на backend’ах первой группы (5.1.1 — 5.1.11 на рис), оранжевый сектор — на backend’ах второй группы (5.2.1 — 5.2.11) и т.д. Proxy-сервер выбирает наименее загруженный backend в каждой группе машин и отправляет на него поисковый запрос с результатами ссылочного поиска. На backend’ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу.
На backend’ах осуществляется поиск по частям индексной базы и ранжирование с учетом результатов поиска по ссылочному индексу. При ранжировании для всех найденных документов высчитываются веса по конкретному запросу.
После того, как запрос обработан на backend’ах, информация о результатах и ранжировании отдается обратно на proxy-сервер. Туда же поступают отсортированные результаты с машин «быстрой базы». Proxy интегрирует данные, полученные с восьми машин: клеит дубли, объединяет зеркала сайтов, переранжирует документы в общий список по весам, рассчитанным на backend’ах. Так, первым в списке найденного может быть документ с машины 5.3.1, вторым и третьим – с 6.1, четвертым — с 5.5.2 и т.д. На proxy-сервере также реализуется построение цитат к документам и подсветка слов запроса в тексте. Полученные результаты отдаются на frontend.
Помимо информации с proxy-сервера, frontend получает результаты из поиска по товарам и из базы Тор 100, отсортированные, с цитатами и подсветкой слов запроса. Frontend осуществляет окончательное объединение результатов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco, который маршрутизирует информацию пользователю.
Frontend осуществляет окончательное объединение результатов, генерирует html со списком найденного, вставляет баннеры и перевязки (ссылки на различные разделы Рамблера) и отдает html Cisco, который маршрутизирует информацию пользователю.
При написании мастер-класса были использованы материалы и данные ООО «Рамблер Интернет Холдинг», RuSeo.info
6. Заключение
Теперь подытожим все вышесказанное.
- Первоочередная задача любой поисковой системы – доставлять людям именно ту информацию, которую они ищут.
- Основные характеристики поисковых систем:
- Полнота
- Точность
- Актуальность
- Скорость поиска
- Наглядность
- Первой полноценной поисковой системой стал проект WebCrawler, вышедший в свет в 1994 году.
- В состав поисковой системы входят компоненты:
- Модуль индексирования
- База данных
- Поисковый сервер
Надеемся, наш материал позволит вам поближе познакомиться с понятием ПС, лучше узнать основные функции, характеристики и принцип работы поисковых систем.
Методы эффективных интернет-исследований
Методы эффективных интернет-исследований
Проф. Эрик Попкофф, Business Program, Brooklyn College
нажимали здесь и там или следили за тем, что вас интересовало. Вы в
временами ваши поиски походили на охоту за мусором, поглощенную поиском фактов в
разные пятна? Если да, научитесь пользоваться
Интернет для исследований может быть одним из самых полезных навыков, которые
человек может развиваться. Новичку Интернет кажется большой пустыней
где сложно найти что-нибудь полезное; однако интернет-исследования могут
найти оазис в пустыне. При правильном использовании интернет-исследования могут быть
используется для множества целей, таких как: исследование компании, исследование термина
бумаги или просто получить важную информацию, такую как прогноз погоды или местные
Новости. В этой статье будут описаны некоторые из методов, необходимых для проведения
эффективный, быстрый поиск в Интернете и получение необходимой информации.
Первый шаг к эффективному поиску в Интернете
знакомы с терминами, которые вы ищете. Вы ищете термин должен быть как
как можно более кратким, но при этом охватывая область, которую вы хотели бы найти. Ты
следует попытаться сформировать ключевые слова (основная тема исследования), фразы (избегать общих
фразы, если они не заключены в кавычки) и термины, описывающие вашу тему.
В поиске следует использовать существительные и местоимения в качестве ключевых слов, когда это возможно с
самые важные термины ставятся на первое место.
Многие поисковые системы работают с логическими операторами, основанными на теории множеств.
основаны и включают термины и, или и, но среди прочих терминов. За
например, если вы хотите найти текущую цену на нефть в США
Указывает, что поисковый запрос «Нефть» даст слишком много ответов, например
детское масло, многие из которых были бы совершенно непригодны для использования. Хороший поиск должен быть
указано в условиях, которые вы ищете. В этом случае цены на нефть в
Соединенные Штаты были бы лучшим поисковым термином. Помещение поискового запроса в кавычки
запрашивает у поисковой системы соответствие ТОЛЬКО на основе условий в кавычках.
Если выбранная поисковая система не может принимать простой английский язык (что становится все более
количество поисковых систем может) поиск поискового запроса, не заключенного в кавычки
приведет к поиску КАЖДОГО термина в поле поиска. Это, очевидно,
не приводит к эффективному поиску.
В этом случае цены на нефть в
Соединенные Штаты были бы лучшим поисковым термином. Помещение поискового запроса в кавычки
запрашивает у поисковой системы соответствие ТОЛЬКО на основе условий в кавычках.
Если выбранная поисковая система не может принимать простой английский язык (что становится все более
количество поисковых систем может) поиск поискового запроса, не заключенного в кавычки
приведет к поиску КАЖДОГО термина в поле поиска. Это, очевидно,
не приводит к эффективному поиску.
Хорошей отправной точкой для эффективного поиска в Интернете является найти эффективную поисковую систему. Существует множество различных типов поисковых систем. доступны, такие как стандартная поисковая система, такая как www.google.com , невидимый веб-поиск двигатель, такой как www.incywincy.com, Мета-поисковик, такой как www.ez2find.com или специализированную поисковую систему, например www.firstgov.gov. .
Стандартная поисковая система, такая как Google, Yahoo и другие
популярные поисковые системы выполняют множество функций. Может помимо проведения
ищет телефонные номера, создает карты, дает местные новости и другие
функции. В этом смысле это тип поисковой системы швейцарской армии.
нож интернета. Как правило, стандартная поисковая система выполняет поиск по адресу
от плохого до удовлетворительного уровня. Со стандартной поисковой системой вы получаете поиск
возможность из одного источника без каких-либо наворотов, которые присутствуют
из более специализированных поисковых систем. Настоящий профессиональный исследователь
избегайте использования этого типа поисковой системы и вместо этого используйте более подходящий
поисковый механизм. В целом поиск с использованием этого типа поисковой системы дает
много результатов, которые не особенно хорошо организованы, а это означает, что если вы не
найти то, что вам нужно, на первых нескольких страницах результатов у вас не будет времени
просмотреть сотни страниц результатов.
Может помимо проведения
ищет телефонные номера, создает карты, дает местные новости и другие
функции. В этом смысле это тип поисковой системы швейцарской армии.
нож интернета. Как правило, стандартная поисковая система выполняет поиск по адресу
от плохого до удовлетворительного уровня. Со стандартной поисковой системой вы получаете поиск
возможность из одного источника без каких-либо наворотов, которые присутствуют
из более специализированных поисковых систем. Настоящий профессиональный исследователь
избегайте использования этого типа поисковой системы и вместо этого используйте более подходящий
поисковый механизм. В целом поиск с использованием этого типа поисковой системы дает
много результатов, которые не особенно хорошо организованы, а это означает, что если вы не
найти то, что вам нужно, на первых нескольких страницах результатов у вас не будет времени
просмотреть сотни страниц результатов.
Мета-поисковик, такой как ez2find или vivisimo сильно отличается как по возможностям, так и по удобству использования от обычной поисковой системы. Хотя эти поисковые системы не могут выполнять все функции швейцарского
армейский нож общая поисковая система, что делает этот тип поисковой системы
проводить эффективные поиски. Вместо использования одной поисковой системы мета
поисковая система использует несколько поисковых систем и фильтр, чтобы найти лучший
результаты с использованием ВСЕХ поисковых систем. Для иллюстрации некоторых основных
различия между www.google.com и моей поисковой системой с самым высоким рейтингом www.ez2find.com
срок повышения налогов штата Нью-Йорк Google вернул колоссальные 525 000 обращений за
эта тема, многие из которых были не по теме. www.ez2find.com
с его превосходной системой фильтрации возвратил 61 попадание, которое было очень
тема. Очевидно, что анализ 525 000 обращений займет много времени и не будет ненужным.
задача. Кроме того, некоторые мета-поисковые системы, такие как www.ez2find.com и www.vivisimo.com, имеют важную особенность:
встроенная функция кластеризации. Помимо фильтрации результатов поиска
эти поисковые системы показывают точные подкатегории поиска.
Хотя эти поисковые системы не могут выполнять все функции швейцарского
армейский нож общая поисковая система, что делает этот тип поисковой системы
проводить эффективные поиски. Вместо использования одной поисковой системы мета
поисковая система использует несколько поисковых систем и фильтр, чтобы найти лучший
результаты с использованием ВСЕХ поисковых систем. Для иллюстрации некоторых основных
различия между www.google.com и моей поисковой системой с самым высоким рейтингом www.ez2find.com
срок повышения налогов штата Нью-Йорк Google вернул колоссальные 525 000 обращений за
эта тема, многие из которых были не по теме. www.ez2find.com
с его превосходной системой фильтрации возвратил 61 попадание, которое было очень
тема. Очевидно, что анализ 525 000 обращений займет много времени и не будет ненужным.
задача. Кроме того, некоторые мета-поисковые системы, такие как www.ez2find.com и www.vivisimo.com, имеют важную особенность:
встроенная функция кластеризации. Помимо фильтрации результатов поиска
эти поисковые системы показывают точные подкатегории поиска.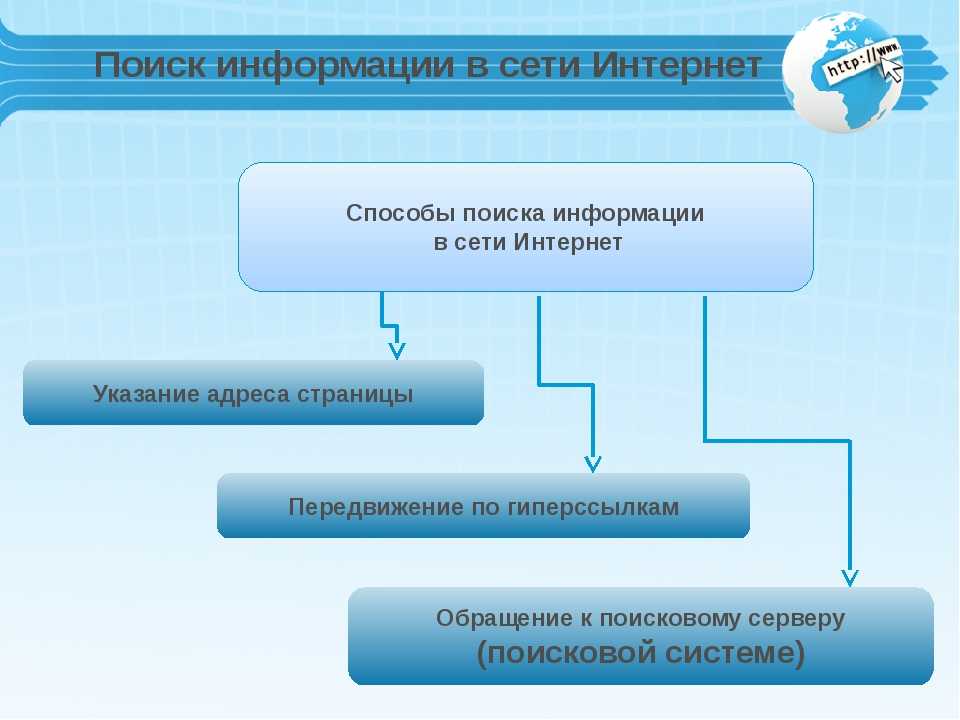 В примере
выше, если бы я хотел только повышения налогов в Нью-Йорке, я мог бы увидеть, что было 19результаты из 61 всего. Это отличная экономия времени, так как я могу использовать это
метод, чтобы быстро сосредоточиться на моем предполагаемом результате. Помимо объединения многих
Мета-поисковики также имеют ранжирование релевантности, основанное на точности
источник найден на заданный вопрос. Например, если бы я спросил, почему собака лает
и первым хитом было кошачье мяуканье, проблемы с рейтингом релевантности для этого
ответ ноль. Это очень полезная функция. Google не имеет релевантности
или кластеризации в своей поисковой системе.
В примере
выше, если бы я хотел только повышения налогов в Нью-Йорке, я мог бы увидеть, что было 19результаты из 61 всего. Это отличная экономия времени, так как я могу использовать это
метод, чтобы быстро сосредоточиться на моем предполагаемом результате. Помимо объединения многих
Мета-поисковики также имеют ранжирование релевантности, основанное на точности
источник найден на заданный вопрос. Например, если бы я спросил, почему собака лает
и первым хитом было кошачье мяуканье, проблемы с рейтингом релевантности для этого
ответ ноль. Это очень полезная функция. Google не имеет релевантности
или кластеризации в своей поисковой системе.
Некоторые поисковые системы выполняют поиск в так называемом невидимом пространстве.
веб. Сеть сама по себе похожа на айсберг. Только 10% веб-сайтов видны большинству
поисковые системы. Полные 90% невидимы для большинства поисковых систем. Невидимый
поисковая система, такая как www.incywincy.com
ищет как в видимой сети (в этой части ищут большие мейнфреймы, называемые
боты) и невидимая сеть, которая является невидимой для ботов частью сети, которая
обычно неизвестны большинству поисковых механизмов. Невидимые веб-поисковики
немного причудливые там результаты. Когда они эффективны, им нет равных в
качество поиска. Однако, когда они не эффективны, поиск
результаты могут быть замечены совершенно не в точку. Оказывается, большинство лучших сайтов
для бизнес-исследований невидимы в Интернете. У хорошей поисковой мета-системы, такой как www.ez2find.com, есть невидимая сеть.
способность. Google и другие стандартные поисковые системы НЕ имеют
невидимая веб-возможность.
Невидимые веб-поисковики
немного причудливые там результаты. Когда они эффективны, им нет равных в
качество поиска. Однако, когда они не эффективны, поиск
результаты могут быть замечены совершенно не в точку. Оказывается, большинство лучших сайтов
для бизнес-исследований невидимы в Интернете. У хорошей поисковой мета-системы, такой как www.ez2find.com, есть невидимая сеть.
способность. Google и другие стандартные поисковые системы НЕ имеют
невидимая веб-возможность.
Подводя итог, я рекомендую при использовании поисковых систем хороший Мета-поисковик, такой как www.ez2find.com или www.vivisimo.com вместе с хорошая невидимая поисковая система, такая как www.incywincy.com. Это должно обеспечить наилучшие общие результаты поиска за минимально возможное время.
Не вся полезная информация в Интернете доступна
через стандартные поисковые системы. Большое количество полезной информации есть
доступны через специализированные механизмы поиска, такие как правительство США
поисковая система www. firstgov.gov. Этот
поисковая система является воротами ко всем веб-сайтам, которые управляются
Правительство США. Этот малоиспользуемый шлюз предлагает полный доступ к множеству
бесплатных, легкодоступных и всеобъемлющих государственных ресурсов. я нашел
Базы данных правительства США будут чрезвычайно полезными. Среди рекомендуемых
базы данных, к которым можно получить доступ через www.firstgov.gov
следующие
firstgov.gov. Этот
поисковая система является воротами ко всем веб-сайтам, которые управляются
Правительство США. Этот малоиспользуемый шлюз предлагает полный доступ к множеству
бесплатных, легкодоступных и всеобъемлющих государственных ресурсов. я нашел
Базы данных правительства США будут чрезвычайно полезными. Среди рекомендуемых
базы данных, к которым можно получить доступ через www.firstgov.gov
следующие
1- Библиотека Конгресса на сайте www.loc.gov — это ворота в один из самые большие коллекции данных, которые варьируются от исторических до правительственных и экономический материал. Еще один отличный ресурс — www.fedstats.gov. Портал в более чем 100 Федеральные агентства, которые собирают и публикуют статистические данные по различным темам. Многие статистические данные, доступные в этой базе данных, недоступны в любой другой базе данных. бесплатный ресурс.
2- Ворота в США.
Министерство торговли в www.commerce.gov оказался чрезвычайно
полезный.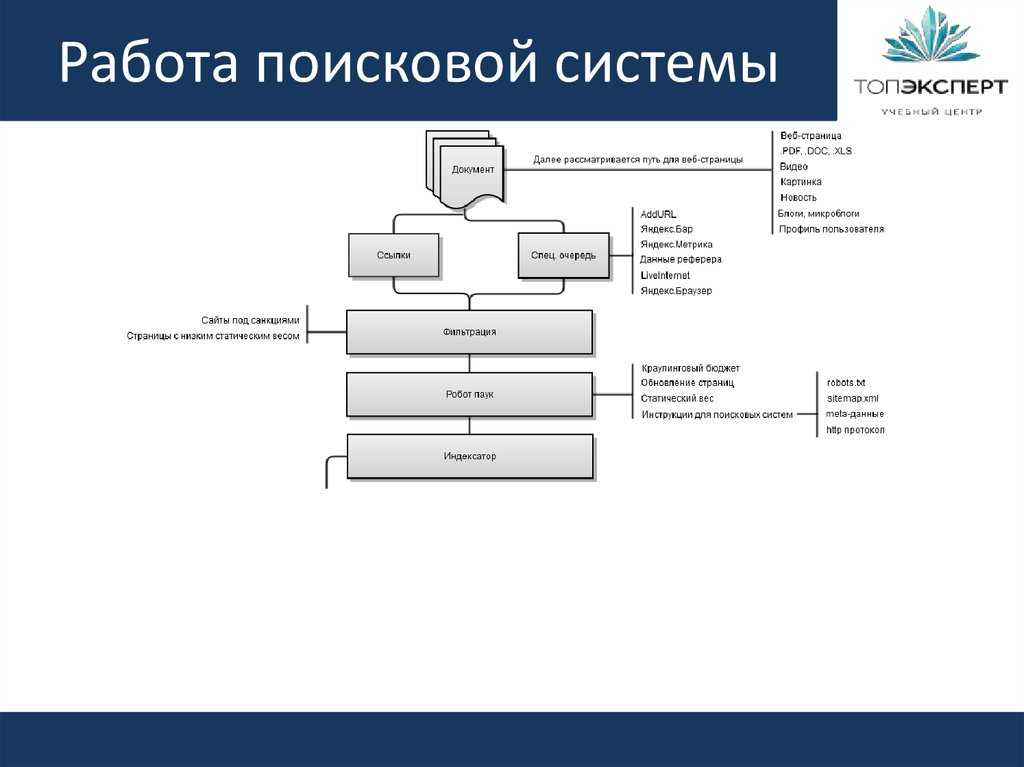
3- Департамент переписи населения США на сайте www.census.gov имеет ссылку на сайт American Factfinder. что дает зрителю возможность получать микростатистику, такую как демографические данные по почтовому индексу. Эти данные могут оказаться чрезвычайно ценными для владелец малого бизнеса, которому необходимо знать демографию района, прежде чем они подумайте об открытии бизнеса.
4- Также доступен для небольших владельцем бизнеса является сайт Администрации малого бизнеса, www.sba.gov. На этом сайте полно отличных ресурсов, связанных с малым бизнесом. Определенный сайт высшего уровня для людей, которые заинтересованы в открытии или поддержании малого бизнеса.
5- Вход в федеральную службу Центр на www.usajobs.opm.gov является отличный сайт, на котором есть список почти всех вакансий с Федеральное правительство. Вакансии сначала публикуются здесь, прежде чем они будут выпущены для любого другой источник.
6- Шлюз в Центральный
Разведывательное управление на сайте www.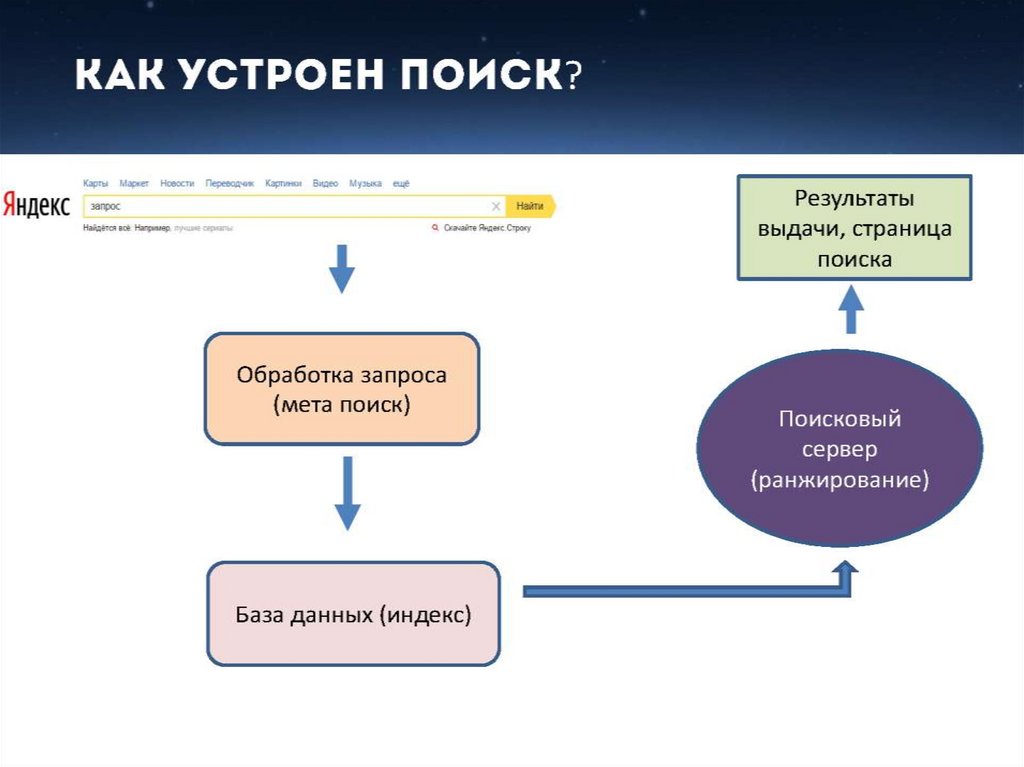 cia.gov. ЦРУ
не только для шпионов кажется. На этом сайте ЦРУ публикует отличные
Всемирная книга фактов, представляющая собой исчерпывающую сводку рассекреченных данных о
каждой нации в мире. Этот ресурс является отличным источником данных для
сведения о других нациях.
cia.gov. ЦРУ
не только для шпионов кажется. На этом сайте ЦРУ публикует отличные
Всемирная книга фактов, представляющая собой исчерпывающую сводку рассекреченных данных о
каждой нации в мире. Этот ресурс является отличным источником данных для
сведения о других нациях.
Этот список сайтов никоим образом не является исчерпывающим, но я считают, что у правительства есть что-то на своих сайтах, что удовлетворит любых исследователей потребности. Я бы также порекомендовал заглянуть на ваши государственные и местные сайты для дальнейшего изучения. данные.
Еще одна проблема, с которой сталкиваются интернет-исследователи, заключается в том, что
материал о компаниях. Иногда трудно понять, куда идти, чтобы стать лучше
полезная информация о компании. Первый момент, который необходимо рассмотреть, заключается в том, является ли
или компания не является публичной или частной. Если компания частная
состоявшейся тогда крайне сложно найти достоверные данные о компании. А
возможным ответом на проблему является база данных Reference USA. это 9В базе данных 0003 pay есть некоторая информация о
большинства частных компаний и может стать хорошей отправной точкой для исследований. Этот
база данных доступна БЕСПЛАТНО на сайте www.brooklynpubliclibrary.org
для всех держателей карт. (Обсуждение библиотечных ресурсов будет включено позже
В этой статье).
А
возможным ответом на проблему является база данных Reference USA. это 9В базе данных 0003 pay есть некоторая информация о
большинства частных компаний и может стать хорошей отправной точкой для исследований. Этот
база данных доступна БЕСПЛАТНО на сайте www.brooklynpubliclibrary.org
для всех держателей карт. (Обсуждение библиотечных ресурсов будет включено позже
В этой статье).
Для публичных компаний исследование намного проще. ВСЕ
публичные компании, за исключением компаний, включенных в «Розовые листы», должны подавать регулярные отчеты в
Комиссия по ценным бумагам и биржам. Эти отчеты, которые являются основой
всех исследований компании доступны на www.sec.gov.
Однако на сайте SEC есть эти отчеты в оригинальном формате, полностью
не обобщается или комментируется. Я обнаружил, что если вы не CPA или SEC
адвоката, у вас могут возникнуть проблемы с чтением этих отчетов. я составил список
хороших сайтов, которые помогают интерпретировать и дополнять данные, сгенерированные SEC.
1- Домашний сайт MSN Money Central по адресу http://moneycentral.msn.com. Этот сайт не только имеет ссылки на веб-сайт SEC, но также имеет данные INDEPTH о почти каждая публичная компания. Перейдя на вкладку акции в верхней части сайта можно увидеть такие данные, как отчет компании, финансовые данные и инсайдерскую торговлю. Я нашел этот сайт отличным источником данных о публичных компаниях.
2- Руководство Business Week по исследованиям компаний на http://bwnt.businessweek.com/company/search.asp. Этот сайт, на котором размещена информация о примерно 4000 акций, не только взят из базу данных рабочей недели, но также и с нескольких других сайтов в Интернете.
3-
Домашняя страница Multex Investor по адресу www.multexinvestor.com. Этот сайт
которая недавно была куплена агентством Reuters, имеет отличную область исследования компании.
во вкладке акции на главной странице сайта. Данные здесь
всеобъемлющий и чрезвычайно полезный.
4- Hoovers Online на сайте www.hoovers.com. Несмотря на то, что лучшие данные на этом сайте платные, достаточно бесплатных данных. включая некоторый конкурентный анализ, который делает этот сайт полезным как потенциальное исследовательское средство.
5- Домашний сайт информации SEC www.secinfo.com. На этом сайте есть не только список ВСЕХ документов SEC, но и включены документы по типу инсайдерской торговли и другие важные данные. ВСЕ ТРЦ отчеты разбиты на подкатегории, поэтому вам не нужно читать весь документ, чтобы получить необходимые данные. Кроме того, сам файл SEC даны перекрестные ссылки для проведения дополнительных исследований. Возможно лучший сайт для информации SEC в Интернете.
6-
Сайт Mergent FIS Online. Этот платный сайт является домом для
инвестиционная служба Moodys; чрезвычайно всеобъемлющий и полезный сайт.
Этот сайт также доступен на домашнем сайте Brooklyn Public.
Библиотека по адресу www. brooklynpubliclibrary.org . Всем держателям карт. ВЫСОКО
рекомендуемый сайт.
brooklynpubliclibrary.org . Всем держателям карт. ВЫСОКО
рекомендуемый сайт.
Теперь я опишу некоторые другие поисковые страницы, которые могут быть полезны. большую помощь во время ваших поисков информации.
1- Магпортал на www.magportal.com Это одна из самых полезных и универсальных поисковых страниц в Интернете. Magportal — поисковая система по журналам, позволяющая найти большое количество источников. быть обысканным. Magportal выполняет поиск в большинстве журналов (включая платные и малоизвестные). те) по любой теме и ранжировать результаты по релевантности. Этот первый класс ресурс находит информацию по теме, когда большинство других типов поиска неуспешный. Результаты поиска могут быть изучены, а выбранная статья может быть распечатывается в оригинальном полнотекстовом виде. А ДОЛЖЕН ИМЕТЬ ресурс .
2-
Система поиска деловых публикаций на сайте www.bpubs.com. Вам когда-нибудь приходилось искать
статья в малоизвестном деловом издании? Bpubs ищет эти компании
публикации материалов, недоступных в других местах.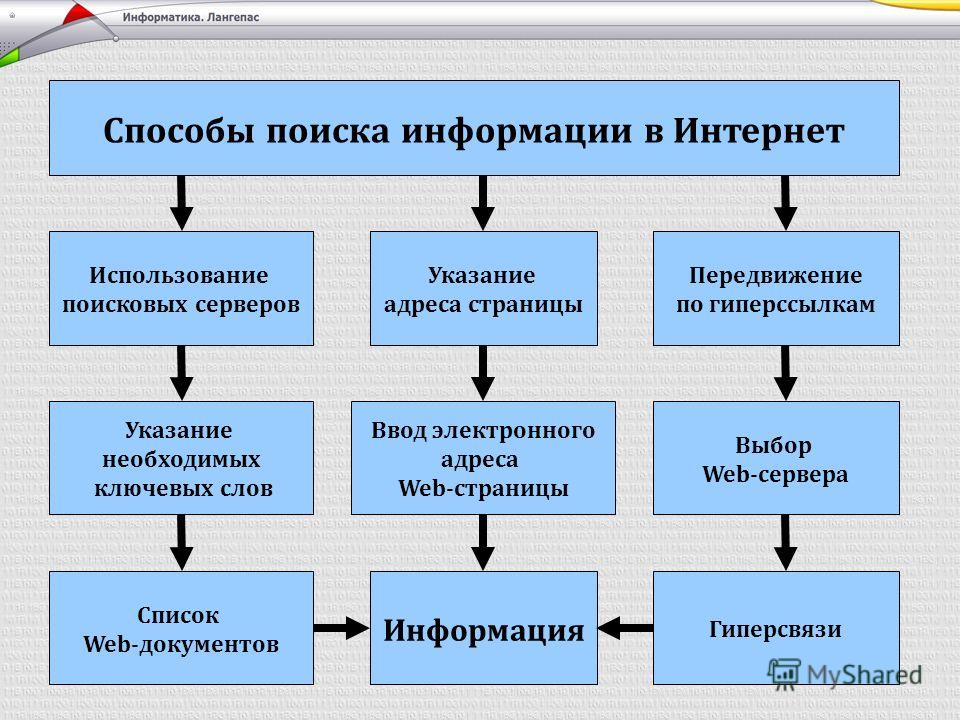 Это
хорошая поисковая система для относительно трудно найти источники исследований.
Это
хорошая поисковая система для относительно трудно найти источники исследований.
3- Генеральный директор Express на www.ceoexpress.com. Вы когда-нибудь НЕ ПОНИМАЛИ, что искать, и понятия не имели, как начать поиск? CEO Express — это поисковая страница, заполненная очень полезными ссылками на другие источники. Используя эту страницу, вы обязательно найдете ссылку, которая либо найти информацию, которую вы ищете, или, по крайней мере, поставить вас в правильном направление. Эта страница также является отличным ресурсом для ссылок на важные веб-сайты.
4-
Если вам нужно следить за темами новостей или компанией, вы можете получить
бесплатная персонализированная новостная служба на сайте www.individual.com.
Этот полнофункциональный сервис подборки новостей собирает новости, которые вас интересуют.
и сопоставляет их в газетном формате. Этот формат можно посмотреть на
либо свою страницу на сайте www.individual.com
или результаты могут быть отправлены вам по электронной почте ежедневно. Как правило вырезка из новостей
услуги в Интернете очень дорогие. Этот бесплатный сайт так же хорош, как и платный
сайты и могут быть легко настроены в соответствии с вашими потребностями. Использование www.individual.com совсем несложно. С помощью www.individual.com легко следовать
любая отрасль, компания или направление.
Как правило вырезка из новостей
услуги в Интернете очень дорогие. Этот бесплатный сайт так же хорош, как и платный
сайты и могут быть легко настроены в соответствии с вашими потребностями. Использование www.individual.com совсем несложно. С помощью www.individual.com легко следовать
любая отрасль, компания или направление.
5- Вы когда-нибудь нуждались в местной информации о малоизвестном страна? Иногда это необходимо для того, чтобы получить качественную информацию для иметь доступ к местной поисковой системе. Сайт www.searchenginecolossus.com. имеет список большинства основных поисковых систем, организованных нацией там источник. Многие из этих поисковых систем на английском языке. Это ценный источник для трудно найти местную информацию.
Еще одна проблема, которая беспокоит исследователей, заключается в том, как найти
платные базы данных бесплатно? Несколько лет назад все в Интернете было бесплатным
и на основе рекламы. Сейчас, к сожалению, почти каждая коммерческая база данных платная. основан. Однако есть способ получить высококачественные коммерческие базы данных по платежам для
бесплатно. Секрет в том, чтобы получить местный читательский билет. Местные библиотеки регулярно
подпишитесь на дорогие, отличные платные базы данных, которые можно использовать в Интернете из
домой, бесплатно их покровителями. Ваш номер читательского билета может быть использован в качестве
ключ, чтобы разблокировать базы данных, лицензированные для библиотеки для домашнего использования. Штрих-код
в нижней части читательского билета находится ключ, открывающий эти базы данных (вы
думал, что это хорошо только для того, чтобы заставить вас заплатить штраф в размере 2 долларов за сверхурочную работу, которую вы должны
библиотека прошлого года). На самом деле многие десятки тысяч долларов
коммерческие базы данных предлагаются бесплатно местными библиотечными системами. Как
Выборка следующих платных коммерческих баз данных предлагается в Бруклине
Сайт публичной библиотеки, расположенный по адресу www.
основан. Однако есть способ получить высококачественные коммерческие базы данных по платежам для
бесплатно. Секрет в том, чтобы получить местный читательский билет. Местные библиотеки регулярно
подпишитесь на дорогие, отличные платные базы данных, которые можно использовать в Интернете из
домой, бесплатно их покровителями. Ваш номер читательского билета может быть использован в качестве
ключ, чтобы разблокировать базы данных, лицензированные для библиотеки для домашнего использования. Штрих-код
в нижней части читательского билета находится ключ, открывающий эти базы данных (вы
думал, что это хорошо только для того, чтобы заставить вас заплатить штраф в размере 2 долларов за сверхурочную работу, которую вы должны
библиотека прошлого года). На самом деле многие десятки тысяч долларов
коммерческие базы данных предлагаются бесплатно местными библиотечными системами. Как
Выборка следующих платных коммерческих баз данных предлагается в Бруклине
Сайт публичной библиотеки, расположенный по адресу www. brooklynpubliclibrary.org.
brooklynpubliclibrary.org.
1- ABI/Inform Dateline — Эта база данных имеет региональные освещение деловых новостей компаний, как больших, так и малых. Эта база данных исчерпывающим и предоставляет информацию, обычно недоступную где-либо еще.
2- ABI/Inform Research — Эта база данных имеет ПОЛНЫЙ текст деловая периодическая база данных, содержащая более 800 журналов и газет, включая Журнал Уолл-Стрит. ОТЛИЧНАЯ БАЗА ДАННЫХ.
3- Academic Search Premier — ПОЛНЫЙ текст, научный коллекция, охватывающая информацию почти во всех областях академических исследований. ОЧЕНЬ ПОЛЕЗНЫЙ.
4- Accunet/AP Photo Archive — Эта база данных содержит библиотека более 700 000 фотографий от гражданской войны до наших дней.
5- Associations Unlimited — Это онлайн-каталог
который охватывает более 400 000 некоммерческих ассоциаций по всему миру во ВСЕХ областях.
6- Business Source Premier — это ПОЛНЫЙ ТЕКСТОВЫЙ ресурс из более чем 2470 научных деловых журналов.
7- Corporate Resource Net — это база данных ПОЛНЫЙ ТЕКСТ статьи из более чем 1300 журналов и журналов, таких как Fortune и Money. Эта база данных также включает подробные данные о 5000 крупнейших в мире компании.
8- Пользовательские газеты — Вы можете искать в коллекции более 150 газет со всего мира.
9- Encyclopedia Britannica — это ПОЛНАЯ платная версия энциклопедии, включая постоянное обновление. ЛЮБИМАЯ БАЗА ДАННЫХ.
10- Ethnic Newswatch — Полная коллекция газет, журналы и журналы, связанные с этническими сообществами. Можно искать на английском или испанский.
11- Learning Express Library — Обеспечивает подготовку к
тексты в академической сфере, при подготовке к колледжу, на государственной службе и в других областях.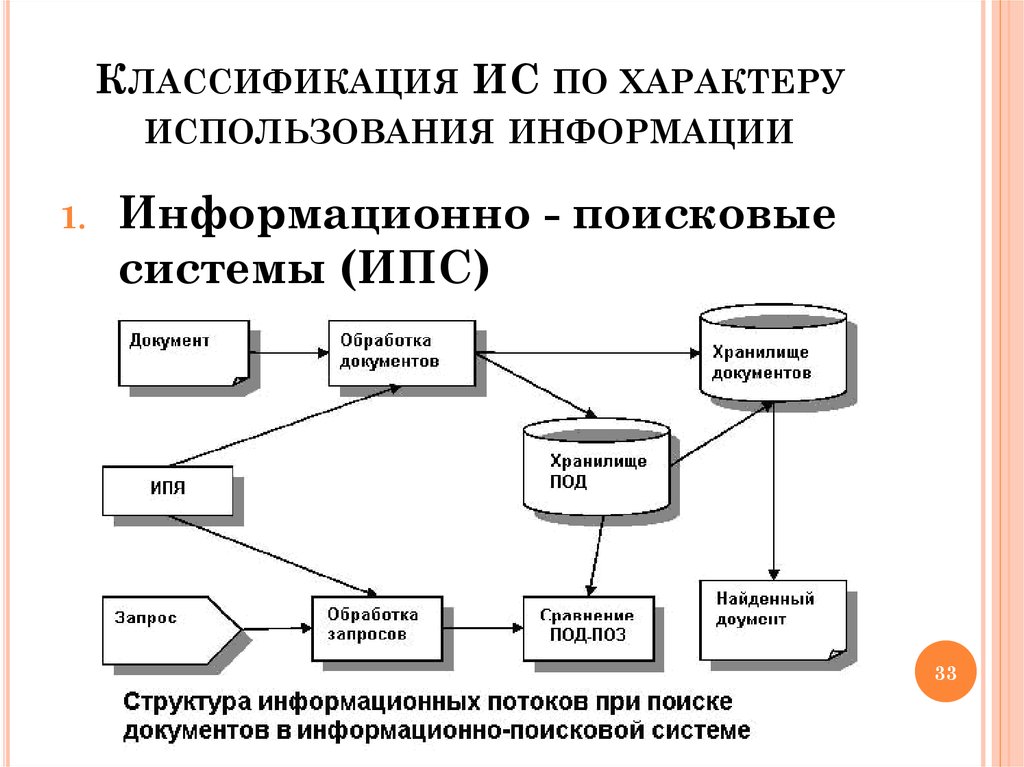 ОЧЕНЬ
ПОЛЕЗНЫЙ.
ОЧЕНЬ
ПОЛЕЗНЫЙ.
12- Masterfile Premier — это ПОЛНОТЕКСТОВАЯ база данных более 2000 общих периодических изданий по многим дисциплинам.
13- Mergent/FIS Online — Эта передовая база данных (которая упоминалось ранее в этой статье) дает полный доступ к подробным информация о более чем 10 000 компаний США, входящих в список Moodys Financial Услуги.
14- Источник газеты — Эта база данных содержит ПОЛНЫЙ текст охват более 240 газет и других источников новостей.
15- Газеты штата Нью-Йорк — База данных 10 основных газеты, издаваемые в штате Нью-Йорк, включая New York Times и New Йорк Пост.
16- Proquest — Полнотекстовая база данных с возможностью поиска из нескольких
газет, в том числе New York Times, которая выходит около 2 лет назад. Несколько
другие библиотеки подписываются на исторические газеты Proquest, что дает ПОЛНЫЙ ТЕКСТ
доступ к New York Times до 1850 года. ОТЛИЧНАЯ БАЗА ДАННЫХ.
ОТЛИЧНАЯ БАЗА ДАННЫХ.
17- Reference USA — Еще одна отличная база данных (эта база данных также была описана ранее в этой статье), которая имеет базовый бизнес и списки жилых помещений. Охватывает более 12 миллионов компаний в США. ОЧЕНЬ ПОЛЕЗНО и ПОЛНЫЙ.
18- Региональные деловые новости — База данных, охватывающая 75 предприятий журналы и новостные ленты.
19- SIRS Researcher — В этой базе данных есть ссылки на тысячи полнотекстовых статей по ряду вопросов, выбранных из более чем 1200 источники.
Это лишь некоторые из баз данных, доступных на
Сайт Бруклинской публичной библиотеки в электронных ресурсах. я оцениваю стоимость
из этих ресурсов превысит 25 000 долларов в год. Кроме того, королевы
Библиотека на www.queenslibrary.org
имеет некоторые из этих баз данных с одним примечательным дополнением: bigchalk/eLibrary .
Эта база данных, содержащая несколько миллиардов ссылок во многих категориях, таких как
газеты, книги и телепередачи ПОЛНЫЙ ТЕКСТ. Он также доступен для поиска по простому
Английский поиск (растущий тренд). В прошлом я обнаружил, что это
база данных может получить информацию, которую трудно или невозможно найти в других
места. Хотя временами результаты с этой базой данных могут быть странными,
это НЕОБХОДИМЫЙ ресурс.
Он также доступен для поиска по простому
Английский поиск (растущий тренд). В прошлом я обнаружил, что это
база данных может получить информацию, которую трудно или невозможно найти в других
места. Хотя временами результаты с этой базой данных могут быть странными,
это НЕОБХОДИМЫЙ ресурс.
Как житель определенных районов вы можете подать заявку и получить одну или несколько библиотечных карточек. В Нью-Йорке житель может подать заявку на получение до 3 читательские билеты (Бруклин, Квинс и Манхэттен) и получить доступ ко всем эти библиотечные системы. Поскольку доступные ресурсы несколько отличаются от библиотечных от системы к библиотечной системе Я НАСТОЯТЕЛЬНО призываю читателей получить ВСЮ библиотеку карты, на которые они имеют право, включая любой колледж или другие системы, которые они могут быть зачисленным.
В дополнение ко всем вышеупомянутым ресурсам есть
другие доступные инструменты, которые могут оказать помощь интернет-исследователю. Одним из моих любимых инструментов является Newsnose, который можно загрузить с сайта www.bangstudios.com. Это фантастическое
ресурс, после установки, обеспечивает ПОЛНЫЙ ТЕКСТОВЫЙ доступ к новостям вокруг
Мир. Программа проста в использовании, позволяет осуществлять поиск по 3 параметрам.
Эта программа MUST HAVE — отличный способ получать актуальные новостные статьи по ЛЮБОЙ
предмет. Еще один отличный инструмент — панель инструментов Vivisimo Internet Explorer.
доступны на сайте www.vivisimo.com. У них есть
было распространение панелей инструментов, доступных для Internet Explorer. Этот в
по крайней мере, поддерживается отличной поисковой системой и выполняет те же
работает как другие панели инструментов, такие как блокировка всплывающих окон. Еще один полезный интернет
Панель инструментов проводника Alexa доступна на www.alexa.com.
Эта панель инструментов позволяет пользователю видеть сайты, связанные с тем, которым вы являетесь.
смотря на. Это позволяет использовать поисковую сеть, которая, по сути, позволяет
создание связанных поисков на основе исходного веб-поиска.
Одним из моих любимых инструментов является Newsnose, который можно загрузить с сайта www.bangstudios.com. Это фантастическое
ресурс, после установки, обеспечивает ПОЛНЫЙ ТЕКСТОВЫЙ доступ к новостям вокруг
Мир. Программа проста в использовании, позволяет осуществлять поиск по 3 параметрам.
Эта программа MUST HAVE — отличный способ получать актуальные новостные статьи по ЛЮБОЙ
предмет. Еще один отличный инструмент — панель инструментов Vivisimo Internet Explorer.
доступны на сайте www.vivisimo.com. У них есть
было распространение панелей инструментов, доступных для Internet Explorer. Этот в
по крайней мере, поддерживается отличной поисковой системой и выполняет те же
работает как другие панели инструментов, такие как блокировка всплывающих окон. Еще один полезный интернет
Панель инструментов проводника Alexa доступна на www.alexa.com.
Эта панель инструментов позволяет пользователю видеть сайты, связанные с тем, которым вы являетесь.
смотря на. Это позволяет использовать поисковую сеть, которая, по сути, позволяет
создание связанных поисков на основе исходного веб-поиска. ДОЛЖЕН ИМЕТЬ
РЕСУРС. Другим доступным ресурсом является метапоиск Copernic, который
доступны для скачивания на сайте www.copernic.com.
Этот умный маленький инструмент, который находится на панели инструментов пользователя в нижней части
экран позволяет пользователю проводить полноценный метапоиск высокого качества напрямую
с панели инструментов. Это позволяет осуществлять поиск при выполнении любой задачи на
Интернет даже в игре. Коперник до сих пор остается одним из лучших поисковых
механизмов, доступных в Интернете.
ДОЛЖЕН ИМЕТЬ
РЕСУРС. Другим доступным ресурсом является метапоиск Copernic, который
доступны для скачивания на сайте www.copernic.com.
Этот умный маленький инструмент, который находится на панели инструментов пользователя в нижней части
экран позволяет пользователю проводить полноценный метапоиск высокого качества напрямую
с панели инструментов. Это позволяет осуществлять поиск при выполнении любой задачи на
Интернет даже в игре. Коперник до сих пор остается одним из лучших поисковых
механизмов, доступных в Интернете.
Несмотря на то, что я не люблю платить за информацию, я
хотел бы порекомендовать платежную базу данных, которая дает вам ценность ваших денег. Этот
база данных доступна на сайте www.questia.com (это
стоит 120 долларов в год по предоплате) — это единственная в своем роде библиотека из более чем 47 000 книг и
другие источники, недоступные больше нигде в Интернете. Квестия
позволяет осуществлять поиск и полнотекстовую печать всей книги. Квестия
также будет искать и выделять раздел книги, относящийся к
Результат поиска. Questia также добавляет в поиск все журналы, журналы и
газеты, которые относятся к вашему поисковому запросу. Добавление этой невидимой паутины
resources делает Questia НЕОБХОДИМОЙ базой данных.
Questia также добавляет в поиск все журналы, журналы и
газеты, которые относятся к вашему поисковому запросу. Добавление этой невидимой паутины
resources делает Questia НЕОБХОДИМОЙ базой данных.
Наконец, я также хотел бы порекомендовать два браузера, которые могут использовать вместо Internet Explorer для поиска в Интернете. я недавно выставил много жалоб на скорость, надежность и удобство использования Интернета Исследователь. Стало важно рекомендовать потенциальные альтернативные браузеры которые более надежны, чем Internet Explorer. Я рекомендую два отличных альтернативные браузеры, оба из которых доступны на www.download.com. Первый браузер Avant это полнофункциональный браузер, который прост в использовании и не потребляет много ресурсов. Этот Браузер выглядит и работает как Internet Explorer. Второй браузер Myie2 это еще один отличный альтернативный браузер, который также выглядит и работает как Интернет Проводник и очень прост в использовании.
Любые вопросы по статье можно направлять автору
Проф. Эрик Попкофф, [email protected]
или со мной также можно связаться на экономическом факультете Бруклинского колледжа по адресу
718-951-5000. А пока я надеюсь, что все ваши поиски будут плодотворными.
Эрик Попкофф, [email protected]
или со мной также можно связаться на экономическом факультете Бруклинского колледжа по адресу
718-951-5000. А пока я надеюсь, что все ваши поиски будут плодотворными.
Эффективный поиск в Интернете | Girton College
Выбор правильной поисковой системы
Для многих из нас поиск в Интернете стал стандартным механизмом поиска информации. Это не значит, что мы обязательно знаем, как это сделать лучше всего! Например, если вы ищете научную информацию, мы должны помнить, что журнальные статьи, книги и другие научные источники могут быть защищены платными стенами и могут не отображаться в результатах поиска (или быть доступными для нас, даже если они отображают вверх). Вместо этого вам нужно спланировать стратегию поиска и выбрать поисковую систему.
К основным поисковым системам относятся:
- Google – поиск изображений, видео, карт, новостей, покупок и т.
 д. Справляется с орфографическими ошибками и переводит неанглоязычные страницы.
д. Справляется с орфографическими ошибками и переводит неанглоязычные страницы. - Bing — собственная поисковая система Microsoft. Движок по умолчанию в Edge.
- Yahoo – использует результаты из Bing с дополнительными функциями Yahoo.
- DuckDuckGo — подчеркивает конфиденциальность. Он не отслеживает и не профилирует пользователей, а это означает, что все, кто выполняет один и тот же поиск, увидят одни и те же результаты.
- Яндекс – одна из самых популярных поисковых систем в Европе.
- Baido — одна из самых популярных поисковых систем в Китае.
Если вам нужно найти рецензируемые или научные источники, обычная поисковая система будет не самым подходящим местом для поиска. Альтернативные варианты включают:
- iDiscover для поиска в фондах Кембриджского университета, включая статьи в журналах и онлайн-ресурсах. Для получения дополнительной информации ознакомьтесь со многими доступными справочными руководствами по iDiscover или ознакомьтесь с нашим собственным руководством по поиску в iDiscover.
- Библиографические базы данных. Большинство академических предметов имеют библиографические базы данных по конкретным предметам, что позволяет вам искать литературу по вашему предмету и создавать собственные списки для чтения. Просмотрите все базы данных по вашему предмету, на которые подписан университет.
- Чтобы получить представление об огромном количестве академических ресурсов, см. этот список в Википедии!
Эффективное использование Google
Google — это больше, чем просто окно поиска на главной странице.
- Google Scholar — поиск в научной литературе, такой как статьи и тезисы, но особенно полезен для «серой литературы», т. е. исследований, проводимых организациями за пределами обычных академических и коммерческих издательских маршрутов, таких как отраслевые публикации и правительственные отчеты. Чтобы ограничить поиск ресурсами, доступными для членов Кембриджского университета, перейдите в «Настройки» и «Ссылки на библиотеки» и выполните поиск «Кембриджский университет».

- Google Scholar Metrics предоставляет авторам простой способ оценить заметность и влияние последних статей в научных публикациях путем суммирования недавних цитат. Однако он охватывает только статьи, опубликованные в период с 2014 по 2018 год, которые были проиндексированы Google Scholar до июля 2019 года..
- Чтобы быть в курсе последних событий, вы можете использовать Оповещения Google, чтобы отправлять вам электронные письма, когда находят новые результаты, такие как веб-страницы, газетные статьи, блоги или научные исследования, которые соответствуют вашему поисковому запросу.
- Вы также можете просмотреть все действия, которые вы выполняли при входе в Google, посетив Мои действия. Это может быть полезно, например, если вы хотите повторно выполнить поиск в Google, который вы выполняли, но также очень страшно видеть, сколько информации хранится о вас. Вы можете удалить активность.
Советы по эффективной стратегии поиска в Интернете
Тщательно спланируйте поиск, и вы, скорее всего, быстрее найдете более релевантные материалы. Если ваш поиск находит слишком много сайтов или в значительной степени нерелевантных сайтов, вам нужно будет пересмотреть свою стратегию поиска. Все основные поисковые системы имеют очень подробные рекомендации по методам поиска, а некоторые из них имеют расширенные средства поиска. Точный способ ввода слов или фраз темы может варьироваться от одной поисковой системы к другой.
Если ваш поиск находит слишком много сайтов или в значительной степени нерелевантных сайтов, вам нужно будет пересмотреть свою стратегию поиска. Все основные поисковые системы имеют очень подробные рекомендации по методам поиска, а некоторые из них имеют расширенные средства поиска. Точный способ ввода слов или фраз темы может варьироваться от одной поисковой системы к другой.
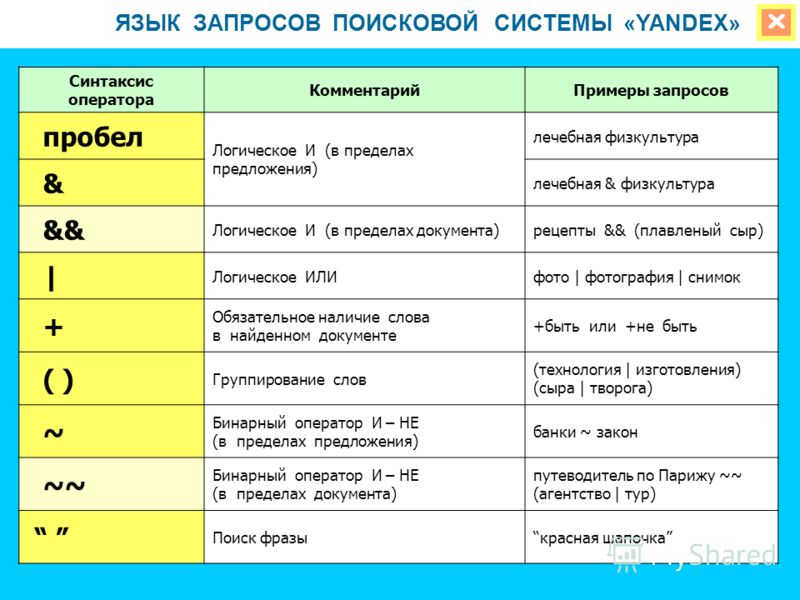
Комбинирование слов при поиске (логический поиск)
Ищите опцию расширенного поиска, так как это обеспечивает большую гибкость при комбинировании поисковых слов, например. https://www.google.co.uk/advanced_search. Если вы используете Bing, вы можете использовать символы для объединения слов, чтобы сделать поиск более точным:
- + (И) — используйте для указания слов, которые должны быть включены, например. Американец + Президент
- | (ИЛИ) — используйте, чтобы расширить поиск и найти больше сайтов, например. американский | Президент
- — (НЕ) — используйте с осторожностью, чтобы исключить нежелательные поисковые слова, например.
 Американец-президент
Американец-президент - Используйте точную фразу (кавычки) для поиска точной фразы, например. «Американский президент»
Поиск слов с похожими окончаниями
Большинство поисковых систем позволяют ввести первую часть слова, а затем использовать символ, например, . * или или ? (он варьируется от одной поисковой системы к другой), чтобы заменить последующие буквы. Итак, чтобы найти американца, Америки, американца, вы можете ввести America*
Уточнение поиска
Вы можете сделать поиск более точным, включив в условия поиска:
- Сайт: – используйте для поиска информации на определенном сайте, например, Сайт студенческих стипендий: cam.ac.uk. Вы также можете исключить определенный сайт или домен, например. – сайт: shef.ac.uk
- Связанные: — используйте для поиска сайтов, похожих на те, которые вы уже используете, например, related:pixabay.com
- Тип файла: — используйте для поиска определенного типа документа, например.
 Барбара Бодишон тип файла: pdf
Барбара Бодишон тип файла: pdf - Number…Number – поиск в определенном числовом диапазоне, например. женщины-авторы 1800…1900
- Intitle:/intext:/inurl: – поиск слова в заголовке, тексте или URL, например. название: Гертон
Вы также можете уточнить результаты, например, чтобы исключить более ранние результаты. В Google вы делаете это, выбирая «Инструменты» и используя раскрывающиеся меню.
Поиск изображений
Подавляющее большинство магов в Интернете защищены авторским правом; то, что изображение есть, и вы можете сохранить его на своем устройстве, не означает, что вы можете его использовать. Некоторые рекомендуемые способы поиска изображений, которые вы можете использовать, включают:
- Wikimedia Commons — это онлайн-репозиторий свободно используемых мультимедиа и изображений.
- Google Images позволяет ограничивать результаты поиска по правам использования; перейдите в «Инструменты» и выберите «Права на использование».
 Вы также можете выполнять обратный поиск изображения (т. е. поиск существующего изображения), щелкнув значок камеры в строке поиска. (Полезно, например, если вы хотите искать поддельные версии ваших собственных учетных записей в социальных сетях, хотя TinEye
Вы также можете выполнять обратный поиск изображения (т. е. поиск существующего изображения), щелкнув значок камеры в строке поиска. (Полезно, например, если вы хотите искать поддельные версии ваших собственных учетных записей в социальных сетях, хотя TinEye - Librestock выполняет поиск на веб-сайтах с бесплатными фотографиями, таких как Pixabay, чтобы найти изображения, которые можно использовать бесплатно, в основном с лицензиями Creative Commons 0.
Поиск в социальных сетях
Большинство платформ социальных сетей имеют свои собственные внутренние функции поиска, но существуют также поисковые системы социальных сетей, такие как:
Социальный поисковик выполняет поиск в нескольких социальных сетях без необходимости входа в них и предоставляет аналитические данные. Вы можете настроить оповещения по электронной почте, чтобы оставаться в курсе. Он также имеет инструмент поиска Google Social Media, который выполняет поиск в социальных сетях через Google. Каждый сайт (например, Twitter и Facebook) представлен в отдельной легко читаемой колонке.
Он также имеет инструмент поиска Google Social Media, который выполняет поиск в социальных сетях через Google. Каждый сайт (например, Twitter и Facebook) представлен в отдельной легко читаемой колонке.
Оценка результатов поиска
Поисковые системы по-разному контролируют качество перечисленных сайтов. Многие поисковые системы «гарантируют» более высокий рейтинг в обмен на оплату, а результаты, помеченные как рекламные, часто появляются вверху.
Вам нужно будет критически взглянуть на сайты, которые вы найдете. Аспекты, на которые следует обратить внимание при оценке сайтов, включают:
- Авторство – кто несет ответственность за сайт? Человек или учреждение или организация?
- Целевая аудитория – академики? Дети? Кто-нибудь? Не понятно?
- Точность – все ссылки работают? Есть ли ошибки?
- Последнее изменение — регулярно ли обновляется сайт? Найдите дату внизу страницы.
- Объективность – насколько объективно автор представил информацию?
В рамках вашей оценки авторства посмотрите, что это за сайт.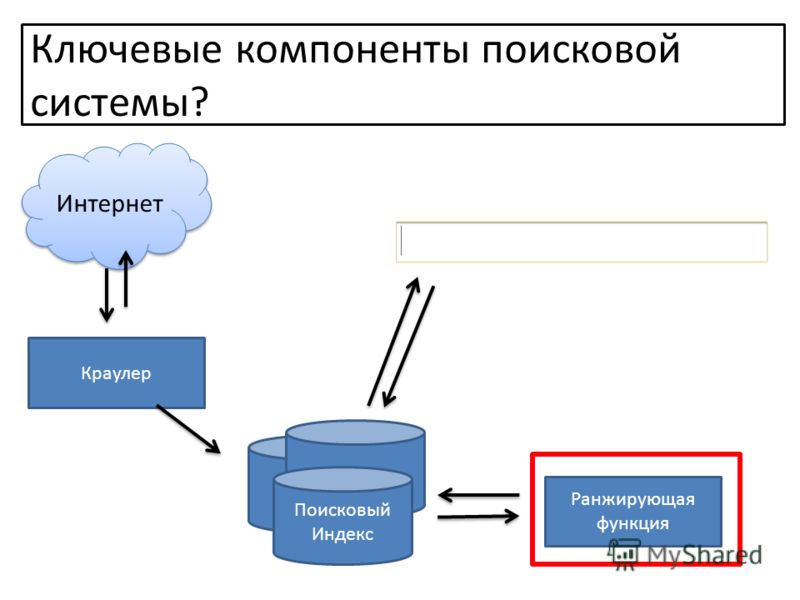
Вы можете проверить URL-адрес (унифицированный указатель ресурсов) веб-страницы, чтобы определить, с какого сайта поступает информация:
- .edu означает, что страницы созданы учебным заведением
- .gov означает, что страница создана государственным ведомством или органом .
- .org означает, что страница создана организацией (обычно некоммерческой или благотворительной).
- .com или .co.xx означает коммерческий сайт .
Достоверность информации не должна оцениваться исключительно на основе конкретного типа сайта, с которого она получена, но знание типа сайта может помочь представить предоставленную информацию в контексте.
Неудачный поиск?
- Попробуйте другую поисковую систему или две, чтобы убедиться, что ваш поиск исчерпывающий. Не стоит полагаться только на одну поисковую систему. Чтобы обойти это, вы можете использовать мультипоисковик или мета-поисковик, который выполняет поиск по вашему запросу в нескольких поисковых системах.
