
Архивирование веб-сайтов / Habr
Недавно я глубоко погрузился в тему архивирования веб-сайтов. Меня попросили друзья, которые боялись потерять контроль над своими работами в интернете из-за плохого системного администрирования или враждебного удаления. Такие угрозы делают архивирование веб-сайтов важным инструментом любого сисадмина. Как оказалось, некоторые сайты гораздо сложнее архивировать, чем другие. Эта статья демонстрирует процесс архивирования традиционных веб-сайтов и показывает, как он не срабатывает на модных одностраничных приложениях, которые раздувают современный веб.Преобразование простых сайтов
Давно прошли дни, когда веб-сайты писались вручную на HTML. Теперь они динамичные и строятся «на лету» с использованием новейших JavaScript, PHP или Python-фреймворков. Как результат, сайты стали более хрупкими: сбой базы данных, ложное обновление или уязвимости могут привести к потере данных. В моей предыдущей жизни в качестве веб-разработчика мне пришлось смириться с мыслью: клиенты ожидают, что веб-сайты будут работать вечно. Это ожидание плохо сочетается с принципом веб-разработки «двигаться быстро и ломать вещи». Работа с системой управления контентом Drupal оказалась особенно сложной в этом отношении, поскольку крупные обновления намеренно нарушают совместимость со сторонними модулями, что подразумевает дорогостоящий процесс обновления, который клиенты редко могут себе позволить. Решение состояло в том, чтобы архивировать эти сайты: взять живой, динамический веб-сайт — и превратить его в простые HTML-файлы, которые любой веб-сервер может выдавать вечно. Этот процесс полезен для ваших собственных динамических сайтов, а также для сторонних сайтов, которые находятся вне вашего контроля, и которые вы хотите защитить.
$ nice wget --mirror --execute robots=off --no-verbose --convert-links \
--backup-converted --page-requisites --adjust-extension \
--base=./ --directory-prefix=./ --span-hosts \
--domains=www.example.com,example.com http://www.example.com/Эта команда загружает содержимое веб-страницы, а также выполняет обход всех ссылок в указанных доменах. Перед запуском этого действия на любимом сайте рассмотрите возможные последствия краулинга. Приведённая выше команда намеренно игнорирует правила robots.txt, как сейчас принято у архивистов, и скачивает сайт на максимальной скорости. У большинства краулеров есть опции для паузы между обращениями и ограничения полосы пропускания, чтобы не создавать чрезмерную нагрузку на целевой сайт. Эта команда также получает «реквизиты страницы», то есть таблицы стилей (CSS), изображения и скрипты. Загруженное содержимое страницы изменяется таким образом, что ссылки указывают уже на локальную копию. Результирующий набор файлов может быть размещён на любом веб-сервере, представляя собой статическую копию исходного веб-сайта.
Но это когда всё идёт хорошо. Любой, кто когда-либо работал с компьютером, знает, что вещи редко идут по плану: есть множество интересных способов сорвать процедуру. Например, некоторое время назад на сайтах было модно ставить блоки с календарём. CMS будет генерировать их «на лету» и отправит краулеры в бесконечный цикл, пытаясь получить всё новые и новые страницы. Хитрые архивариусы могут использовать регулярные выражениям (например, в Wget есть опция --reject-regex), чтобы игнорировать проблемные ресурсы. Другой вариант: если доступен интерфейс администрирования веб-сайта — отключить календари, формы входа, формы комментариев и другие динамические области. Как только сайт станет статичным, они всё равно перестанут работать, поэтому есть смысл удалить этот беспорядок с исходного сайта.
Кошмар JavaScript
К сожалению, некоторые веб-сайты представляют собой гораздо больше, чем просто HTML. Например, на одностраничных сайтах веб-браузер сам создаёт контент, выполняя небольшую программу JavaScript. Простой пользовательский агент, такой как Wget, будет безуспешно пытаться восстановить значимую статическую копию этих сайтов, поскольку он вообще не поддерживает JavaScript. Теоретически, сайтам следует поддерживать прогрессивное улучшение, чтобы контент и функциональность были доступны без JavaScript, но эти директивы редко соблюдаются, как подтвердит любой, кто использует плагины вроде NoScript или uMatrix.
Традиционные методы архивирования иногда терпят неудачу самым тупым образом. При попытке сделать бэкап местной газеты я обнаружил, что WordPress добавляет строки запросов (например, ?ver=1.12.4) в конце include. Это сбивает с толку обнаружение content-type на веб-серверах, обслуживающих архив, потому что они для выдачи правильного заголовка Content-Type полагаются на расширение файла. Когда такой архив загружается в браузер, тот не может загрузить скрипты, что ломает динамические веб-сайты.
Поскольку браузер постепенно становится виртуальной машиной для запуска произвольного кода, то методам архивирования, основанным на чистом анализе HTML, следует адаптироваться. Решением этих проблем является запись (и воспроизведение) HTTP-заголовков, доставляемых сервером во время краулинга, и действительно профессиональные архивисты используют именно такой подход.
Создание и отображение файлов WARC
В Интернет-архиве Брюстер Кале и Майк Бёрнер в 1996 году разработали формат ARC (ARChive): способ объединить миллионы небольших файлов, созданных в процессе архивирования. В конечном итоге формат стандартизировали как спецификацию WARC (Web ARChive), выпущенную в качестве стандарта ISO в 2009 году и пересмотренную в 2017 году. Усилия по стандартизации возглавил Международный консорциум по сохранению Интернета (IIPC). Согласно Википедии, это «международная организация библиотек и других организаций, созданных для координации усилий по сохранению интернет-контента для будущего», в неё входят такие члены, как Библиотека Конгресса США и Интернет-архив. Последний использует формат WARC в своём Java-краулере Heritrix.
--warc. К сожалению, браузеры не могут напрямую отображать файлы WARC, поэтому для доступа к архиву необходима специальная программа просмотра. Или его придётся конвертировать. Самая простая программа просмотра, которую я нашёл, — pywb, пакет Python. Она запускает простой веб-сервер с интерфейсом типа Wayback Machine для просмотра содержимого файлов WARC. Следующий набор команд отобразит файл WARC на http://localhost:8080/: $ pip install pywb
$ wb-manager init example
$ wb-manager add example crawl.warc.gz
$ waybackКстати, этот инструмент создали разработчики сервиса Webrecorder, который с помощью браузера сохраняет динамическое содержимое страницы.
К сожалению, pywb не умеет загружать WARC-файлы, сгенерированные Wget, потому что он подчиняется некорректным требованиям спецификации WARC 1.0, которые были исправлены в версии 1.1. Пока Wget или pywb не устранят эти проблемы, файлы WARC, созданные Wget, недостаточно надёжны, поэтому лично я начал искать другие альтернативы. Моё внимание привлёк краулер под простым названием crawl. Вот как он запускается:
$ crawl https://example.com/Программа поддерживает некоторые параметры командной строки, но большинство значений по умолчанию вполне работоспособны: она скачает ресурсы вроде CSS и картинок с других доменов (если не указан флаг
-exclude-related-c. Но главное, что результирующие файлы WARC отлично загружаются в pywb.Будущая работа и альтернативы
Есть немало ресурсов по использованию файлов WARC. В частности, есть замена Wget под названием Wpull, специально разработанная для архивирования веб-сайтов. Она имеет экспериментальную поддержку PhantomJS и интеграцию с youtube-dl, что позволит загружать более сложные JavaScript-сайты и скачивать потоковое мультимедиа, соответственно. Программа является основой инструмента архивирования ArchiveBot, разработку которого ведёт «свободный коллектив озорников-архивистов, программистов, писателей и болтунов» из ArchiveTeam в попытке «сохранить историю, прежде чем она исчезнет навсегда». Похоже, что интеграция PhantomJS не так хороша, как хотелось бы, поэтому ArchiveTeam использует ещё кучу других инструментов для зеркалирования более сложных сайтов. Например, snscrape сканирует профили социальных сетей и генерирует списки страниц для отправки в ArchiveBot. Другой инструмент — crocoite, который запускает Chrome в headless-режиме для архивирования сайтов с большим количеством JavaScript. Эта статья была бы неполной без упоминания «ксерокса сайтов» HTTrack. Аналогично Wget, программа HTTrack создаёт локальные копии сайтов, но, к сожалению, не поддерживает сохранение в WARC. Интерактивные функции могут быть более интересны начинающим пользователям, незнакомым с командной строкой.
В том же духе, во время своих исследований я нашёл альтернативу Wget под названием Wget2 с поддержкой многопоточной работы, которая ускоряет работу программы. Однако здесь отсутствуют некоторые функции Wget, в том числе шаблоны, сохранение в WARC и поддержка FTP, зато добавлены поддержка RSS, кэширование DNS и улучшенная поддержка TLS.
Наконец, моей личной мечтой для таких инструментов было бы интегрировать их с моей существующей системой закладок. В настоящее время я храню интересные ссылки в Wallabag, службе локального сохранения интересных страниц, разработанной в качестве альтернативы свободной программы Pocket (теперь принадлежащей Mozilla). Но Wallabag по своему дизайну создаёт только «читаемую» версию статьи вместо полной копии. В некоторых случаях «читаемая версия» на самом деле нечитабельна, и Wallabag иногда не справляется с парсингом. Вместо этого другие инструменты, такие как bookmark-archiver или reminescence, сохраняют скриншот страницы вместе с полным HTML, но, к сожалению, не поддерживают формат WARC, который бы обеспечил ещё более точное воспроизведение.
Печальная правда моего зеркалирования и архивирования заключается в том, что данные умирают. К счастью, архивисты-любители имеют в своём распоряжении инструменты для сохранения интересного контента в интернете. Для тех, кто не хочет заниматься этим самостоятельно, есть Интернет-архив, а также группа ArchiveTeam, которая работает над созданием резервной копии самого Интернет-архива.
Архивирование веб-сайтов — Википедия
Архивирование веб-сайтов — процесс сохранения текущей версии сайта в архиве для последующих исследований историками и обществом. Как правило, для архивирования используется специальное программное обеспечение — веб-сканер.
Крупнейшей компанией в мире в области архивирования интернета является «Internet Archive». С 2001 года работает Международный семинар архивирования интернета (The International Web Archiving Workshop), который позволяет обмениваться опытом. С 2003 года открыт Международный консорциум сохранения интернета (International Internet Preservation Consortium), которые занимаются разработкой стандартов и курируют разработку инструментов с открытым исходным кодом.
Сайты в интернете могут исчезнуть по ряду разных причин. Материалы сайтов изменяются с течением времени — текст может быть переписан или удалён. Срок аренды доменного имени или самого сервера может истечь, сайт может быть закрыт из-за недостатка финансирования и т. д. В связи с этим актуальна проблема сохранения версий сайта. Существует несколько сервисов, ведущих архивацию на постоянной основе.
Веб-сканер призван в первую очередь сохранить текстовое наполнение сайта, но, в зависимости от конфигурации, сканер может сохранять html-разметку, таблицы стилей, динамические скрипты, изображения и видео.
Помимо содержания к архиву записываются метаданные о собранных ресурсах. MIME-типы, длина содержания, время и дата архивирования, доменное имя и адрес страницы, и т. п. Эти данные используются для навигации, а также полезны для установления подлинности и происхождения.
Существует несколько способов архивирования интернета, ниже описана часть из них.
Удалённый сбор[править | править код]
Метод веб-архивирования отдельных сайтов, автоматизирующий сбор веб-страниц.
Примеры веб-сканеров для персональных компьютеров:
Онлайн-сервисы веб-сканеров:
Метод веб-паука[править | править код]
Метод веб-архивирования, которым пользуются поисковые системы при индексации сайтов. Суть способа в том, что паук сканирует документ на предмет гиперссылок и добавляет каждую в очередь, архивирует сайт и переходит по следующей ссылке в очереди.
Архивирование баз данных[править | править код]
Метод веб-архивирования, который основан на архивированию основного содержания сайта из базы данных.
Таким образом работают системы DeepArc и Xinq, разработанные Национальной библиотекой Франции и Национальной библиотекой Австралии, соответственно. Первая программа позволяет, используя реляционную базу данных, отображать информацию в виде XML-схемы; вторая программа позволяет запомнить оригинальное оформление сайта, соответственно создавая точную копию.
Архивирование транзакциями[править | править код]
Метод архивирования, который сохраняет данные, пересылаемые между веб-сервером и клиентом. Используется, как правило, для доказательств содержания, которое было предоставлено на самом деле в определённую дату. Такое программное обеспечение может потребоваться организациям, которые нуждаются в документировании информации такого типа.
Такое ПО, как правило, просто перехватывает все HTTP-запросы и ответы, фильтруя дубликаты ответов.
Сканеры[править | править код]
Для веб-архивов, которые полагаются на веб-сканеры, имеются следующие проблемы:
- Сайт может запретить для просмотра часть сайта как для веб-сканера, так и для пользователей.
- Часть сайта может быть скрыта в deep Web.
- Ловушки для сборщиков (Crawler traps), например, генерируемые календари и телефонные списки, могут привести к чрезвычайно большому или бесконечному количеству страниц.
- За время обхода сайта уже обойдённые страницы могут измениться.
Однако, технологии сбора способны выдавать в результате страницы с полностью работоспособными ссылками.
Общие ограничения[править | править код]
Иногда администратор сайта настраивает сервер так, что тот выдает нормальные документы лишь пользователям обычных браузеров, но генерирует иные данные для ботов, архиваторов, пауков и т. п. автоматических программ. Это делается с целью обмана поисковых систем или же для увеличения пропускной способности канала, чтобы веб-сервер выдавал пригодный для просмотра материал для устройства и не скачивал ничего лишнего.
Веб-архив сталкивается и с юридическими проблемами. Сохранённый в нём документ может оказаться объектом интеллектуальной собственности, и правообладатель может потребовать удалить его. В других случаях веб-архив может подвергнуться преследованию со стороны какого-либо государства. Правовой основой (поводом) такого преследования обычно выступает законодательство об охране приватности либо о запрете распространения информации. Если архив находится в другой стране, юридическая процедура, ведущая к блокировке сайта, может пройти без ведома и участия владельца ресурса, и он теряет возможность защищаться и опротестовывать решение (если такая возможность предусмотрена).
Веб-архивирование, как и любой другой вид деятельности, имеет юридические аспекты, которые необходимо учитывать в работе:
- Сертификация в надёжности и целостности содержания веб-архива.
- Сбор проверяемых веб-активов.
- Предоставление поиска и извлечения из массива данных.
- Сопоставимость содержания коллекции
Ниже представлен набор инструментов, который использует Консорциум по архивированию интернета
- Heretrix — архивация.
- NutchWAX — поиск коллекции.
- Открытый исходный код «Wayback Machine» — поиск и навигация.
- Web Curator Tool — выбор и управление.
Другие инструменты с открытым исходным кодом для манипуляций над веб-архивами:
- WARC-инструменты — для программного создания, чтения, анализа и управления веб-архивами.
Просто бесплатное ПО:
- Инструменты поиска Google — для полнотекстового поиска.
- WSDK — набор утилит, Erlang-модулей для создания WARC-архива.
Архив Интернета[править | править код]
В 1996 году была основана некоммерческая организация «Internet Archive». Архив собирает копии веб-страниц, графические материалы, видео-, аудиозаписи и программное обеспечение. Архив обеспечивает долгосрочное архивирование собранного материала и бесплатный доступ к своим базам данных для широкой публики. Размер архива на 2019 год — более 45 петабайт; еженедельно добавляется около 20 терабайт[1]. На начало 2009 года он содержал 85 миллиардов веб-страниц.[2], в мае 2014 года — 400 миллиардов[3]. Сервер Архива расположен в Сан-Франциско, зеркала — в Новой Александрийской библиотеке и Амстердаме. С 2007 года Архив имеет юридический статус библиотеки. Основной веб-сервис архива — The Wayback Machine. Содержание веб-страниц фиксируется с временны́м промежутком c помощью бота. Таким образом, можно посмотреть, как выглядела та или иная страница раньше, даже если она больше не существует по старому адресу.
В июне 2015 года сайт был заблокирован на территории России по решению Генпрокуратуры РФ за архивы страниц, признанных содержащими экстремистскую информацию[4], позднее был исключён из реестра.
WebCite[править | править код]
Основная статья: WebCite«WebCite» — интернет-сервис, который выполняет архивирование веб-страниц по запросу. Впоследствии на заархивированную страницу можно сослаться через url. Пользователи имеют возможность получить архивную страницу в любой момент и без ограничений, и при этом неважен статус и состояние оригинальной веб-страницы, с которой была сделана архивная копия. В отличие от Архива Интернета, WebCite не использует веб-краулеров для автоматической архивации всех подряд веб-страниц. WebCite архивирует страницы только по прямому запросу пользователя. WebCite архивирует весь контент на странице — HTML, PDF, таблицы стилей, JavaScript и изображения. WebCite также архивирует метаданные о архивируемых ресурсах, такие как время доступа, MIME-тип и длину контента. Эти метаданные полезны для установления аутентичности и происхождения архивированных данных. Пилотный выпуск сервиса был выпущен в 1998 году, возрождён в 2003.
По состоянию на 2013 год проект испытывает финансовые трудности и проводит сбор средств, чтобы избежать вынужденного закрытия.
Peeep.us[править | править код]
Сервис peep.us позволяет сохранить копию страницы по запросу пользования, в том числе и из авторизованной зоны, которая потом доступна по сокращённому URL. Реализован на Google App Engine.
Сервис peeep.us, в отличие от ряда других аналогичных сервисов, получает данные на клиентской стороне — то есть, не обращается напрямую к сайту, а сохраняет то содержимое сайта, которое видно пользователю. Это может использоваться для того, чтобы можно было поделиться с другими людьми содержимым закрытого для посторонних ресурса.
Таким образом, peeep.us не подтверждает, что по указанному адресу в указанный момент времени действительно было доступно заархивированное содержимое. Он подтверждает лишь то, что у инициировавшего архивацию по указанному адресу в указанный момент времени подгружалось заархивированное содержимое[5]. Таким образом, Peeep.us нельзя использовать для доказательства того, что когда-то на сайте была какая-то информация, которую потом намеренно удалили (и вообще для каких-либо доказательств). Сервис может хранить данные «практически вечно», однако оставляет за собой право удалять контент, к которому никто не обращался в течение месяца[6].
Возможность загрузки произвольных файлов делает сервис привлекальным для хостинга вирусов, из-за чего peeep.us регулярно попадаёт в чёрные списки браузеров[7].
Archive.today[править | править код]
Сервис archive.today (ранее archive.is) позволяет сохранять основной HTML-текст веб-страницы, все изображения, стили, фреймы и используемые шрифты, в том числе страницы с Веб 2.0-сайтов, например с Твиттер.
Веб-гётаку[править | править код]
Японский сервис megalodon.jp действует с 2006 года. Следует указаниям robots.txt[источник не указан 1864 дня].
Поисковики собирают страницы интернета для выполнения своего основного предназначения, и многие из них заодно дают доступ к недавно сохранённым копиям, представляя собой поверхностный во временном смысле архив.
Для частного архива можно использовать один из офлайн-браузеров, которые специально спроектированы на преимущественную работу в офлайн-режиме — создании локальных копий веб-страниц и сайтов.
- Brown, A. Archiving Websites: a practical guide for information management professionals (англ.). — London: Facet Publishing, 2006. — ISBN 1-85604-553-6.
- Brügger, N. Archiving Websites. General Considerations and Strategies (англ.). — Aarhus: The Centre for Internet Research, 2005. — ISBN 87-990507-0-6. Архивная копия от 29 января 2009 на Wayback Machine
- Day, M. Preserving the Fabric of Our Lives: A Survey of Web Preservation Initiatives (англ.) // Research and Advanced Technology for Digital Libraries: Proceedings of the 7th European Conference (ECDL) : journal. — 2003. — P. 461—472.
- Eysenbach, G. and Trudel, M. Going, going, still there: using the WebCite service to permanently archive cited web pages (англ.) // Journal of Medical Internet Research (англ.)русск. : journal. — 2005. — Vol. 7, no. 5. — P. e60. — doi:10.2196/jmir.7.5.e60. — PMID 16403724.
- Fitch, Kent (2003). «Web site archiving — an approach to recording every materially different response produced by a website». Ausweb 03. Проверено 2015-01-31. Архивная копия от 20 июля 2003 на Wayback Machine
- Jacoby, Robert Archiving a Web Page (неопр.) (19 августа 2010). Дата обращения 23 октября 2010. Архивировано 3 января 2011 года.
- Lyman, P. Archiving the World Wide Web (неопр.) // Building a National Strategy for Preservation: Issues in Digital Media Archiving. — 2002.
- Masanès, J. (ed.). Web Archiving (неопр.). — Berlin: Springer-Verlag, 2006. — ISBN 3-540-23338-5.
- Toyoda, M., Kitsuregawa, M. The History of Web Archiving (неопр.) // Proceedings of the IEEE (англ.)русск.. — 2012. — Т. 100, № special centennial issue. — doi:10.1109/JPROC.2012.2189920.
- Алексей Кутовенко. Интернет-летописцы. Сервисы кэширования веб-ресурсов // Мир ПК : журнал. — 2011. — № 6. — С. 58—61. — ISSN 02353520.
- Нежурбеда Г. Г. Создание архивов Интернет-документов как новая задача национальных библиотек / IX Конференция Крым-2002 «Библиотеки и ассоциации в меняющемся мире: новые технологии и новые формы сотрудничества», СЕКЦИЯ 3: СЕТЕВЫЕ ТЕХНОЛОГИИ, МУЛЬТИМЕДИА И ИНТЕРНЕТ В БИБЛИОТЕКАХ
- International Internet Preservation Consortium (IIPC) — International consortium whose mission is to acquire, preserve, and make accessible knowledge and information from the Internet for future generations (англ.)
- International Web Archiving Workshop (IWAW) — Annual workshop that focuses on web archiving, 2001—2010 (англ.)
- National Library of Australia, Preserving Access to Digital Information (PADI) (англ.)
- Library of Congress — Web Archiving (англ.)
- Web archiving bibliography — Список архиваторов веб-сайтов, 2004 (англ.)
- Julien Masanès, Bibliothèque Nationale de France — Towards continuous web archiving. First Results and an Agenda for the Future / D-Lib Magazine, December 2002, Volume 8 Number 12. ISSN 1082-9873 (англ.)
- Сравнение веб-архиваторов (англ.)
Как создать архив на компьютере используя архиваторы
Приветствую вас, дорогие мои читатели и подписчики! Если вы решили окончательно и бесповоротно разобраться в архиваторах и понять суть архивов, то эта статья именно для вас. Я доступно и наглядно расскажу вам, как создать архив, как добавить в него файлы и папки, каким образом можно его открыть и нужно ли скачивать для этого вспомогательные программы.
Конечно же я объясню вам, почему так незаменимы архивы и где их удобно использовать. А также прикреплю краткий обзор трех популярных архиваторов: WinZip, WinRAR и 7-Zip. Давайте начнем!
Архивы и их особенности
Будем углубляться в тему постепенно.
Итак, архив – это файл, который может содержать в себе один или более других файлов абсолютно различных форматов и при этом сжимать их в размере.
Изначально архивирование было создано как раз для сжатия размера данных, ведь в таком случае «легкие» файлы удобнее хранить на компьютере и легче передавать по сети. Однако на сегодняшний день цели архивов значительно расширились, а возможностей прибавилось.
Их использую достаточно часто в повседневной жизни не только в рабочем процессе, а и во время обучения и при простом общении в соцсетях или с помощью электронных писем.
Почему это так удобно? На это есть несколько причин:
Можно скомпоновать в один документ множество файлов разных форматов. К примеру, вы решили отправить некое приложение, текстовое руководство к нему и видеозапись с презентацией продукта. По отдельности высылать такое неудобно, да и некоторые передаваемые данные весят слишком много. Поэтому идеальное решение – заархивировать весь проект;
- Достаточно хорошее сжатие данных. Благодаря этому стало доступно пересылать увесистую информацию. Именно поэтому архивы так часто используют для пересылки объемных документов в организациях;
- Кстати об этом. Иногда в организациях возникают такие ситуации, когда нельзя просто передать незащищенные данные. Архивы и тут могут выручить, ведь во всех современных архиваторах файлы можно зашифровать и передать с паролем. Таким образом ваши данные будут в безопасности;
- Архивы могут выступать и в роли дистрибутивных пакетов, т.е. пакетов, в которых содержатся программные продукты для последующей установки. К ним относятся APK для Android, JAR для Java и т.д.;
- Ну и последнее. В архиве хранится структура каталогов и вложенных папок, что также удобно использовать во многих случаях.
Поговорим о типах архивов
Существуют различные форматы заархивированных файлов. И в зависимости от них определяется и тип архива. И сейчас мы разберем каждый из них. Однако не волнуйтесь, несмотря на их разнообразие в жизни используют только несколько из них.
Сжимающие
Такие форматы только сжимают размер всего документа. К ним относятся bzip2, gzip.
Архивирующие
Соединяют выбранные файлы в один. Сюда относится tar.
Дистрибутивные
О них я уже несколько слов сказал. Как вы помните, их используют для создания установочных пакетов. Они, кстати, могут быть самоустанавливающимися. Это APK, JAR, IPA.
Дисковые образы
К ним относятся всем известные NRG, ISO и другие. Такие форматы используются при создании образов дисков.
Многофункциональные
Форматы архивов, входящие в эту категорию, наиболее часто используются в повседневной жизни.
С их помощью можно не только объединять и сжимать данные, а еще и шифровать, запароливать (эти опции можно найти во вкладке «Дополнительно» любой программы), добавлять информацию для опознавания ошибок, создавать самораспаковывающиеся документы и использовать множество других полезных функций.
Это такие известные форматы, как ZIP, 7z и RAR.
Инструменты, без которых не обойтись!
Вот теперь пришло время рассмотреть популярные приложения для упаковки и распаковки заархивированных документов. Данная глава посвящена трем лидерам, один из которых обязательно должен быть установлен на вашем компьютере.
Начну я, пожалуй, с WinRAR.
WinRAR
Данная программа по праву пользуется колоссальной популярностью среди пользователей всего мира. И не зря. Это мощный инструмент, который просто обязан быть в арсенале любого юзера ПК.
Его можно скачать на сайте http://winrar-full.com/ для практически любой операционной системы: Windows (XP, 7,8 и виндовс 10), Linux, Mac OS, Android. Также можно скачать переносную (портативную) версию программы.
Архиватор наделен простым и очень удобным интерфейсом, а после его установки самые полезные функции внедряются в проводник. Поэтому создать архив можно даже при помощи пары кликов: нажать правой кнопкой мыши на файле или выделенных файлах и щелкнуть по пункту «Добавить в архив».
При этом вы можете в настройках указать формат. Заархивировать, к некоторому сожалению, можно только в RAR или ZIP, но вот распаковать можно абсолютно любой формат. Приложение поддерживает все популярные форматы файлов.
Еще одним преимуществом программы является то, что с ее помощью можно создавать самораспаковывающиеся и многотомные архивы. В последнем варианте вы можете сами указать размер томов, на которые разобьется информация.
Если же архивный документ был поврежден, то и это не беда. WinRAR имеет встроенную опцию по восстановлению поврежденных файлов. В добавок к этому вы можете просмотреть содержимое заархивированного файла до его распаковки.
WinZip
Этот архиватор появился достаточно давно и также является фаворитом среди подобных программ. Он быстро проводит сжатие и распаковку данных, немного даже быстрее чем предыдущая программа, позволяет шифровать и запароливать информацию, все также встраивается в проводник и предоставляет пользователям быстрый доступ к основным функциям приложения.
Поэтому вы все также можете создать, открыть и разархивировать документы в два щелчка, нажав на правую кнопку мыши и выбрав необходимый пункт меню. Кстати, при архивировании файлов в дополнительных настройках можно выбрать метод сжатия.
Сжимать информацию можно, к сожалению, только в одном формате – ZIP. А вот распаковывать можно любой файл.
Также в данной программе имеется одна проблема. Несмотря на скорость выполнения операций, степень сжатия у предыдущего архиватора чуть выше, а это значит, что архивы в WinZip будут весить несколько больше. К тому же программа несовместима с некоторыми форматами.
Скачать ее можно по ссылке http://www.winzip.com/win/ru/index.htm.
7Zip
Данный архиватор, в отличие от своих конкурентов, абсолютно бесплатный, а код можно посмотреть в открытом доступе. Он обладает высокой степенью сжатия благодаря компрессии типа LZMA и к тому же проводит упаковку и распаковку данных очень быстро.
Данное приложение также выделяется тем, что заархивировать может намного больше форматов, чем предыдущие программы. А список форматов файлов для распаковки еще шире.
Здесь также можно создавать самораспаковывающиеся и многотомные архивы, шифровать и защищать данные и многое другое. Важные функции встраиваются в проводник.
Программу можно установить на таких операционных системах, как Windows, Linux/Unix, Mac OS и других.
Огромным преимуществом является то, что вы можете выбирать метод компрессии, сжатия и/или шифрования.
Скачать архиватор можно по ссылке http://7-zip.org.ua/ru/download.html.
Помимо перечисленных приложений, существуют и другие программные продукты, которые помогут заархивировать информацию как локально, так и онлайн. Некоторые даже работают с архивами в Outlook 2010, 2013 или 2016. Как говорится на вкус и цвет.
На этом статья подошла к концу. Если вы хотите побольше всего узнать, то вступайте в ряды моих подписчиков. Буду благодарен за репосты публикаций блога. Пока-пока!
С уважением, Роман Чуешов
Загрузка…Прочитано: 71 раз
Как создать архив
![]()
![]() В нашей сегодняшней статье речь пойдет о том, как создать архив. Также мы расскажем, что такое, вообще, архив, для чего он нужен и, как пользоваться. При этом будут рассмотрены сразу несколько вариантов, а вы уже выберете тот, который наиболее удобен для вас. Поэтому, не откладывая, приступаем к делу.
В нашей сегодняшней статье речь пойдет о том, как создать архив. Также мы расскажем, что такое, вообще, архив, для чего он нужен и, как пользоваться. При этом будут рассмотрены сразу несколько вариантов, а вы уже выберете тот, который наиболее удобен для вас. Поэтому, не откладывая, приступаем к делу.
Что такое архив?
Архив — это, по сути, обертка, в которую помещаются какие-либо объекты причем как один, так и несколько. К примеру, вам нужно отправить кому-то 10 000 файлов, а делать это по одному очень неудобно. Для этого мы можем положить их в специальный портфель (которым является архив), а затем отправить как один файл.
Также у архивов есть и вторая роль — это сжатие файлов. При этом степень упаковки варьируется и устанавливается в начале архивации. В результате некоторые типы файлов, например, текстовые документы, теряют в размере более 95%. Однако, такое сжатие неприменимо, например, для музыки или изображений.
Как создать и распаковать архив
По умолчанию операционные системы от Microsoft имеют свой инструмент для работы с архивами. Однако, тут поддерживается только ZIP-формат. О том, что делать, если это вас не устраивает, мы поговорим ниже.
Используем средства Windows
Итак, при помощи операционной системы Windows, без какого-либо дополнительного программного обеспечения мы можем распаковать ZIP-архив. Создать таковой тоже получится. Для распаковки просто запускаем нужный объект двойным левым кликом, а для упаковки, наоборот, делаем правый клик мышью. Из контекстного меню выбираем пункт отправки, а потом сжатую ZIP-папку. Для вашего удобства мы отобрали все это на скриншоте ниже.
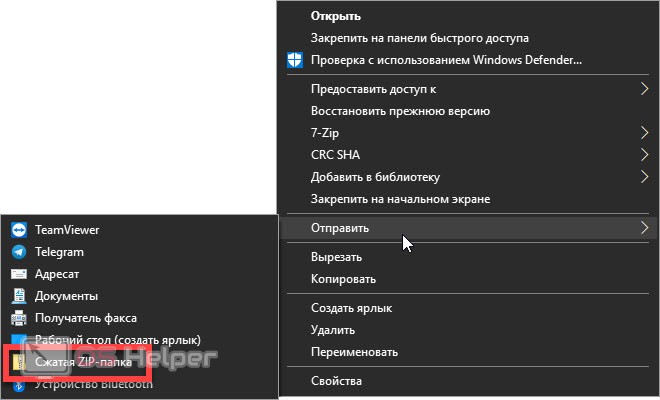
В чем минус работы со штатным инструментом Windows? Дело в том, что он не поддерживает работу с очень многими популярными форматами архивов. И о том, как это исправить, мы поговорим в следующем разделе нашей статьи.
Мнение эксперта
Дарья Ступникова
Специалист по WEB-программированию и компьютерным системам. Редактор PHP/HTML/CSS сайта os-helper.ru. Спросить у ДарьиДля распаковки архивов вы можете просто перетащить все объекты, имеющиеся в них, или какой-то один файл, на рабочий стол. Этот метод называется Drag-n-drop и присутствует любых версиях операционных систем от Microsoft.
При помощи стороннего ПО
Существует огромное количество приложений-архиваторов, однако, мы будем использовать лучшее из них. Это бесплатная утилита под названием 7-ZIP. Давайте рассмотрим, где ее взять, как установить, и как работать.
А делается это следующим образом:
- Сначала переходим на официальный сайт 7-ZIP и бесплатно скачиваем последнюю русскую версию программы оттуда.
- После этого запускаем полученный файл и, согласно подсказкам пошагового мастера, производим установку. В результате программа самостоятельно пропишет все нужные ассоциации со всеми типами архивов.
- Теперь, для того чтобы создать наш архив, делаем правый клик по тому объекту или папке, которые хотим упаковать. В результате вы увидите контекстное меню, в котором выбираем пункт «7-ZIP». Откроется еще одно подменю, а в нем несколько вариантов:
- Добавление к архиву.
- Упаковка и отправка по электронной почте.
- Упаковка в формат 7z.
- Упаковка в формат 7z и отправка по электронной почте.
- Упаковка в формат ZIP.
- Упаковка в формат ZIP и отправка по электронной почте.
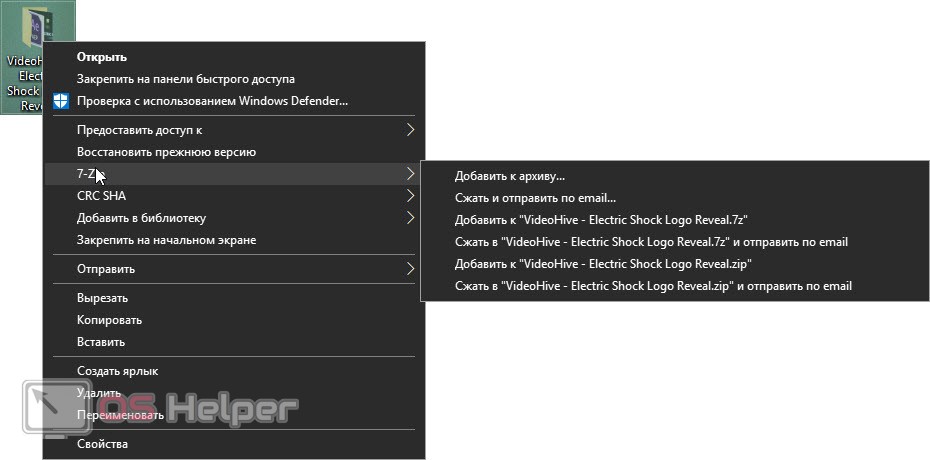
- Используя каждый из этих пунктов, мы можем немножко сэкономить свое время. В данном случае давайте рассмотрим процесс подробнее и выберем первый вариант. Откроется новое окошко, в котором мы можем выбрать параметры архивации:
- Путь конечного файла.
- Формат будущего архива.
- Метод сжатия.
- Размер словаря.
- Размер блока и число потоков.
- Инструмент для разбивки больших файлов на части.
- Опции для работы с файловой системой NTFS.
- Настройки SFX-архива.
- Шифрование.
- Когда все необходимые настройки будут внесены, жмите кнопку «ОК». В результате начнется архивация, длительность которой будет зависеть от производительности компьютера и размера архива.

Если вам не нужны все эти опции, вы просто можете выбрать пункт, создать архив ZIP. Тогда, минуя это окно, программа сразу начнет упаковку.
Видеоинструкция
Также предлагаем дополнительно ознакомиться с видео, в котором все описанное выше, рассмотрено еще более наглядно.
Подводим итоги
Надеемся, вам на 100% понятно, как создать архив и распаковать его в среде операционной системы Windows. Если вам просто нужно работать с архивом, используйте средства самой операционной системы. В том случае, когда нужен более широкий функционал, можно прибегнуть к услугам программы 7-ZIP, а если после прочитанного останутся вопросы, пишите их в комментариях. Форма обратной связи прикреплена ниже и всегда доступна даже для незарегистрированных пользователей.
Как открыть архив
Добавлено: 17.02.2017
Категория: ■ Программы
Просмотров: 2795
Комментариев: 26
 Как открыть архив
Как открыть архив
Многие материалы в интернете хранятся в виде сжатой информации. Выглядит это как архив, который
представляет собой файл, содержащий большое или
небольшое количество других файлов. Это делается для
того, чтобы уменьшить размер хранимой и передаваемой информации.
Если вы получили такой файл и не знаете как открыть архив, то прочитав эту
статью, сделаете это без особого труда. Существует несколько распространенных
программ-архиваторов, такие как RAR, ZIP, CAB. Операционная система Windows
может по умолчанию распаковывать только ZIP архивы.
Самой популярной программой для открытия архивов RAR является программа WinRAR.
Скачать эту программу можно с официального сайта http://www.rarlab.com/download.htm.
Программа устанавливается просто, следуйте инструкциям по установке. Затем
после перезагрузки компьютера, запустите ее.
В открывшемся окне выберите тот архив, который нужно открыть, щелкните по нему
ПКМ. Вы увидите три возможных действия с архивом. Извлечь файлы — кликнув по нему
откроется меню, в котором нужно указать путь, куда будут извлечены файлы.
Извлечь файл в текущую папку — в этом случае файлы будут распакованы в ту папку,
в которой находится в данный момент архив.

Должна заметить, что это не самый лучший вариант распаковки архива, так как
если архив находится в большой папке среди множества других документов и папок,
то он может просто потеряться среди них. Лучше всего использовать третью строчку
Извлечь в (название файла\).
В данном случае все файлы из архива попадут в одну одноименную папку и вам не
придется ничего искать. Можете открывать папку и пользоваться данными.
Можно распаковать архив прямо из окна WinRAR, достаточно выделить нужный
архив и нажать на одну из кнопок меню Мастер или Извлечь…

Если вам нужно создать архив, поместив в него несколько файлов, нужно просто
выделить ЛКМ нужные файлы или папки. Нажать на Добавить в архив, в открывшемся
окне заполнить Имя архива, выбрать формат архива и нажать на ОК. Если вы хотите
добавить еще что-то в созданный архив, откройте его и перетащите мышкой в него нужный
файл.


Сохранить копию сайта в веб архив Internet archive Wayback Machine
В интернете существует очень интересный и полезный проект — веб архив, полностью — Internet archive Wayback Machine.
В веб архиве, расположенным по адресу: http://archive.org/web/, сохраняется прошлое сайтов в виде полноценных и работающих страниц, со всеми ссылками, изображениями, видео. В общем можно увидеть, какой был сайт в прошлом на дату формирования копии.
Боты архив-машины самостоятельно сканируют сайты и формируют их копии, каков их алгоритм — не известно. Поэтому в архиве можно найти много копий своего сайта со всеми страницами или всего одну, да и то искажённую.
Предположить, в каком виде загрузится и отобразится тот или иной сайт — невозможно. Но как правило, машина периодически сохраняет полноценные копии всего сайта и даже может выдать страницы, которых у вас не было никогда.
Если вы не хотите отдавать судьбу своего сайта в руки ботов ресурса, то можно самостоятельно занести страницу в архив, и в случае непредвиденных случайностей, найти и восстановить её.
Как увидеть архив своего сайта
Откройте Internet archive и в строке поиска введите адрес сайта, далее нажмите «browse history»
Здесь будет показано, сколько копий, в каком году и в каком месяце сохранено в архиве.
Выбрав дату и нажав на эти кнопки, можно увидеть копию сайта на тот момент времени.
Как занести сайт в архив
Для этого откройте главную страницу Internet archive Wayback Machine: http:// archive.org/web/.
Далее в рубрике Save Page Now введите адрес архивируемой страницы и нажмите «SAVE PAGE». Через несколько секунд копия буде сохранена.
Как запретить архивировать мой сайт
Что за дело, кто без моего спроса меня сосчитал? Если вы так думаете, то можно запретить веб-машине сохранять копии вашего сайта
Для этого в файле robots.txt нужно прописать запрещающую директиву для ботов wayback machine.
|
User-agent: ia_archiver Disallow: / |
Чтобы позволить архивировать сайт снова, уберите эти строки из файла robots.txt и лучше сразу добавьте главную станицу в архив. Иначе изменений можно дожидаться долго, обновления в системе происходят редко.
***
Как просмотреть позиции модулей Joomla 2.5
Как сделать резервную копию — бекап файлов сайта
Выделение перемещение и копирование
Заработать на бирже Gogetlinks размещая ссылки на сайте
- < Назад
- Вперёд >
Сохранить копию сайта в веб архив Internet archive Wayback Machine
В интернете существует очень интересный и полезный проект — веб архив, полностью — Internet archive Wayback Machine.
В веб архиве, расположенным по адресу: http://archive.org/web/, сохраняется прошлое сайтов в виде полноценных и работающих страниц, со всеми ссылками, изображениями, видео. В общем можно увидеть, какой был сайт в прошлом на дату формирования копии.
Боты архив-машины самостоятельно сканируют сайты и формируют их копии, каков их алгоритм — не известно. Поэтому в архиве можно найти много копий своего сайта со всеми страницами или всего одну, да и то искажённую.
Предположить, в каком виде загрузится и отобразится тот или иной сайт — невозможно. Но как правило, машина периодически сохраняет полноценные копии всего сайта и даже может выдать страницы, которых у вас не было никогда.
Если вы не хотите отдавать судьбу своего сайта в руки ботов ресурса, то можно самостоятельно занести страницу в архив, и в случае непредвиденных случайностей, найти и восстановить её.
Как увидеть архив своего сайта
Откройте Internet archive и в строке поиска введите адрес сайта, далее нажмите «browse history»
Здесь будет показано, сколько копий, в каком году и в каком месяце сохранено в архиве.
Выбрав дату и нажав на эти кнопки, можно увидеть копию сайта на тот момент времени.
Как занести сайт в архив
Для этого откройте главную страницу Internet archive Wayback Machine: http:// archive.org/web/.
Далее в рубрике Save Page Now введите адрес архивируемой страницы и нажмите «SAVE PAGE». Через несколько секунд копия буде сохранена.
Как запретить архивировать мой сайт
Что за дело, кто без моего спроса меня сосчитал? Если вы так думаете, то можно запретить веб-машине сохранять копии вашего сайта
Для этого в файле robots.txt нужно прописать запрещающую директиву для ботов wayback machine.
|
User-agent: ia_archiver Disallow: / |
Чтобы позволить архивировать сайт снова, уберите эти строки из файла robots.txt и лучше сразу добавьте главную станицу в архив. Иначе изменений можно дожидаться долго, обновления в системе происходят редко.
***
Как просмотреть позиции модулей Joomla 2.5
Как сделать резервную копию — бекап файлов сайта
Выделение перемещение и копирование
Заработать на бирже Gogetlinks размещая ссылки на сайте
- < Назад
- Вперёд >