
Создаём личный «Архив интернета» / Хабр
Как показала история, сеть из миллиардов связанных между собой документов — очень хрупкая и эфемерная система. Странички живут недолго. Если нашли интересную страницу, сайт или видео — нельзя просто сделать закладку и надеяться, что контент по ссылке останется доступен в будущем. Не останется. Информация исчезнет, ссылки изменятся, домены сменят владельцев, статьи на Хабре спрячут в черновики. У каждой страницы свой срок жизни. Ничто не вечно под луной, и ничего с этим не поделать.
К счастью, у нас есть инструменты, чтобы сохранить информацию на десятилетия. Свой персональный архив, полностью под контролем, со всеми сайтами и актуальными страницами. Отсюда никто ничего не удалит без вашего ведома, никогда.
Вымирание ссылок
Вымирание ссылок — известный феномен. У большинства СМИ и других организаций нет политики долговременного сохранения информации. Они просто публикуют веб-страницы — и забывают про них. На старые страницы всем плевать, сменят они адреса или исчезнут навсегда. Неудивительно, что именно так и происходит.
На старые страницы всем плевать, сменят они адреса или исчезнут навсегда. Неудивительно, что именно так и происходит.
Анализ внешних ссылок New York Times с 1996 по 2019 годы показал вымирание ссылок на уровне примерно 6% в год. По итогу с 1996 года пропало около 70% веб-страниц.
Проверка ссылок в научных статьях показала вымирание 23—53% в статьях с 1993 по 1999 годы.
Проверка проводилась в 2001 году. Наверняка сейчас, двадцать лет спустя, в тех статьях осталось ещё меньше живых ссылок. В 2016 году другая проверка источников в научных статьях с 1997 по 2012 годы показала, что по 75% ссылкам контент исчез или изменился, а снапшоты в веб-архивах остались только для трети пропавших страниц.
Но в Архив интернета попадают далеко не все страницы. В кэш Google попадает больше, но там определённый срок хранения. И никакой гарантии, что сохранится именно нужная информация. Так что лучше взять дело в свои руки — и создать собственный архив.
В кэш Google попадает больше, но там определённый срок хранения. И никакой гарантии, что сохранится именно нужная информация. Так что лучше взять дело в свои руки — и создать собственный архив.
Инструменты для веб-архивирования
Существует ряд опенсорсных программ для веб-архивирования. Возможно, самый полный список таких проектов собран здесь. Есть также таблица со сравнением функциональности инструментов. Вот небольшой список некоторых проектов:
Архивирование целых сайтов
- Archive-It: курируемая служба веб-архивирования. Предлагает годовую подписку на доступ к своему веб-приложению с различными услугами: полнотекстовый поиск, краулинг контента с различной частотой, выдача отчётов и т. д.
- ArchiveWeb.page: десктопная программа и расширение для Chrome для создания веб-архивов. Расширение можно поставить на «запись», то есть на автоматическое сохранение всех страниц, которые открывались в браузере или в конкретной вкладке.
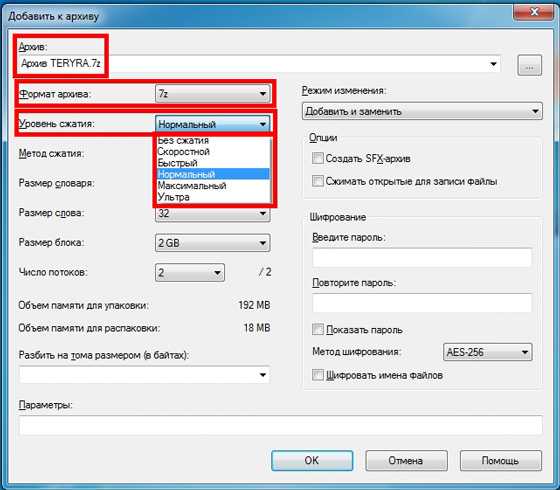 Просматривать архивы в форматах WARC, WACZ, HAR или WBN можно даже в онлайне, для этого создан сайт ReplayWeb.page
Просматривать архивы в форматах WARC, WACZ, HAR или WBN можно даже в онлайне, для этого создан сайт ReplayWeb.page - Brozzler: опенсорсная утилита, которая для скачивания контента использует настоящий браузер (Chrome или Chromium), а также youtube-dl и rethinkdb
- Crawler
- Crawler4j: опенсорсный краулер на Java с простым интерфейсом
- grab-site: предварительно сконфигурированный опенсорсный граббер сайтов, граф ссылок хранит на диске, а не в памяти, поэтому может успешно скачать сайт даже с 10 млн страниц. Результат записывает в формате WARC
- gecco
- Heritrix
- HTTrack
- ItSucks (не поддерживается с 2010 года)
- NetarchiveSuite: разработка Датской королевской библиотеки
- Nutch: краулер с локальным поиском изначально создавался как альтернатива аналогичному корпоративному продукту Google
- Octoparse: проприетарная платная программа, работает только под Windows
- PageFreezer: ещё одна проприетарная система, веб-приложение, специализируется на автоматической архивации сайтов и соцсетей для юридических целей
- simplecrawler: простой API для краулера, не поддерживается
- Squidwarc: ещё один краулер, который работает через браузер (Chrome или Chromium), поэтому умеет выполнять скрипты и извлекать оттуда ссылки для краулинга
- StormCrawler: опенсорсный SDK для построения распределённых, масштабируемых краулеров на Apache Storm
- WAIL (Electron): Web Archiving Integration Layer (WAIL) — графический интерфейс работает поверх многих веб-архиваторов, чтобы упростить пользователям процесс сохранения и последующего просмотра веб-страниц
- WAIL (py): версия на Python
- WebMagic: масштабируемый фреймворк
- Conifer (бывш.
 WebRecorder.io): выделил пользовательскую утилиту WebRecorder в отдельный опенсорсный проект, сам продвигает услугу облачного веб-архивирования с бесплатным лимитом 5 ГБ
WebRecorder.io): выделил пользовательскую утилиту WebRecorder в отдельный опенсорсный проект, сам продвигает услугу облачного веб-архивирования с бесплатным лимитом 5 ГБ - wget: популярная утилита из набора GNU тоже умеет сохранять на диске веб-архивы в виде файлов WARC
- wpull: wget-совместимый веб-архиватор, написанный на Python
Архивирование отдельных страниц
- Archive.is: общедоступный сервис для съёмки снапшотов страниц, которые получают новые URL, сохраняются в архиве для всеобщего просмотра
- curl: известная утилита командной строки для скачивания страничек
- FreezePage: веб-интерфейс для скачивания страничек, сохранять их можно в облаке или на диске
- Paparazzi!: маленькая утилита под macOS, которая делает графические скриншоты страниц
- Perma.cc: сокращатель ссылок и веб-архиватор позиционируется как инструмент для школьников, студентов, юристов и всех остальных, кто хочет получить надёжную ссылку на документ с гарантией, что он не исчезнет и не изменится
- WARCreate: расширение Google Chrome, которое сохраняет любую страницу в формате Web ARChive (WARC)
- webkit2png: утилита командной строки для сохранения скриншотов простой командой типа
webkit2png http://www. google.com/
google.com/
Системы скрапинга данных
Сравнительную таблицу со всеми функциями см. ниже.
Отдельно стоит отметить приложения для хранения закладок с распределением по папкам, категориям, с тегами. Здесь же копии всех веб-страниц. Такие программы можно назвать «архивами закладок». Например, LinkAce или Wallabag.
LinkAce (платная)
ArchiveBox: личный архив
ArchiveBox — одно из самых функциональных решений для архивирования веб-страниц на своём хостинге. Программа отличается тем, что у неё одновременно есть и веб-интерфейс, и продвинутая утилита командной строки (официально поддерживаются macOS, Ubuntu/Debian и BSD). Скоро появится десктопное приложение на электроне под Linux, macOS и Windows (оно пока в альфе).
В ArchiveBox можно скинуть URL и указать формат сохранения: HTML, PDF, скриншот PNG или WARC. Автоматически сохраняется вся контекстная информация вроде заголовков, фавиконов и т.
По умолчанию «для надёжности» все страницы вашего архива сохраняются также на archive.org. Опцию можно (и нужно) отключить.
См. также документацию по форматам сохранения и варианты конфигурации.
Инструмент командной строки работает очень просто.
Добавить ссылку в архив:
archivebox add 'https://example.com'
Добавлять контент раз в день:
archivebox schedule --every=day --depth=1 https://example.com/rss.xml
Аргумент depth=1 означает, что сохраняется эта страница, а также все страницы, на которые она ссылается.
Импорт списка адресов из истории посещённых страниц:
./bin/export-browser-history --chrome archivebox add < output/sources/chrome_history.json # или ./bin/export-browser-history --firefox archivebox add < output/sources/firefox_history.json # или ./bin/export-browser-history --safari archivebox add < output/sources/safari_history.json
Импорт списка адресов из текстового файла:
cat urls_to_archive.txt | archivebox add # или archivebox add < urls_to_archive.txt # или curl https://getpocket.com/users/USERNAME/feed/all | archivebox add
Самые популярные настройки из командной строки:
TIMEOUT=120 # default: 60 добавить больше секунд на скачивание для медленной сети или тормозного сайта CHECK_SSL_VALIDITY=True # default: False True = allow сохранение URL с некорректным SSL SAVE_ARCHIVE_DOT_ORG=False # default: True отключить дублирование на Archive.org MAX_MEDIA_SIZE=1500m # default: 750m увеличить/уменьшить максимальный размер файлов для youtube-dl PUBLIC_INDEX=True # default: True публичный доступ к индексу PUBLIC_SNAPSHOTS=True # default: True публичный доступ к страницам (снапшотам) PUBLIC_ADD_VIEW=False # default: False разрешение/запрет всем пользователям добавлять URL в архив
Как вариант, можно добавлять ссылки через веб-интерфейс на локалхосте:
Сервер с веб-интерфейсом тоже запускается из командной строки:
По сохранённому архиву работает полнотекстовый поиск.archivebox manage createsuperuser archivebox server 0.0.0.0:8000 # открыть http://127.0.0.1:8000 # опции, упомянутые выше archivebox config --set PUBLIC_INDEX=False archivebox config --set PUBLIC_SNAPSHOTS=False archivebox config --set PUBLIC_ADD_VIEW=False
Накопители
На чём хранить личный архив? Теоретически можно сбрасывать архив на компакт-диски или магнитную ленту. Но с ними возникнет проблема поиска в реальном времени. Ведь это основная функция информационного архива — выдавать информацию мгновенно по запросу. Так что самым реалистичным вариантом видится информационное хранилище на HDD (с резервированием по типу RAID).
Многое зависит от объёмов архива. Если у вас скачаны все голливудские фильмы за последние 50 лет в разрешении 4K, то не остаётся вариантов, кроме магнитной ленты. Современные картриджи формата LTO-9 объёмом 45 терабайт стоят не очень дорого.
Копия памяти человека
Кто-то считает, что нужно сохранять в архиве всю информацию, какую человек когда-либо увидел или прочитал, в том числе фотографии, видеоролики, заметки, книги, веб-страницы, статьи.
Такой архив — это своеобразная «цифровая память» человека, копия его жизни, всех событий и воспоминаний, с полнотекстовым поиском. Цифровая копия всего, что попадало в мозг или возникало в нём самопроизвольно. Впрочем, это уже ближе к киберпанку.
НЛО прилетело и оставило здесь промокоды для читателей нашего блога:
- 15% на все тарифы VDS (кроме тарифа Прогрев) — HABRFIRSTVDS.
- — 20% на выделенные серверы AMD Ryzen и Intel Core — HABRFIRSTDEDIC.
Доступно до 31 декабря 2021 г.
Архивирование веб-сайтов / Хабр
Недавно я глубоко погрузился в тему архивирования веб-сайтов. Меня попросили друзья, которые боялись потерять контроль над своими работами в интернете из-за плохого системного администрирования или враждебного удаления. Такие угрозы делают архивирование веб-сайтов важным инструментом любого сисадмина. Как оказалось, некоторые сайты гораздо сложнее архивировать, чем другие. Эта статья демонстрирует процесс архивирования традиционных веб-сайтов и показывает, как он не срабатывает на модных одностраничных приложениях, которые раздувают современный веб.
Такие угрозы делают архивирование веб-сайтов важным инструментом любого сисадмина. Как оказалось, некоторые сайты гораздо сложнее архивировать, чем другие. Эта статья демонстрирует процесс архивирования традиционных веб-сайтов и показывает, как он не срабатывает на модных одностраничных приложениях, которые раздувают современный веб.
Преобразование простых сайтов
Давно прошли дни, когда веб-сайты писались вручную на HTML. Теперь они динамичные и строятся «на лету» с использованием новейших JavaScript, PHP или Python-фреймворков. Как результат, сайты стали более хрупкими: сбой базы данных, ложное обновление или уязвимости могут привести к потере данных. В моей предыдущей жизни в качестве веб-разработчика мне пришлось смириться с мыслью: клиенты ожидают, что веб-сайты будут работать вечно. Это ожидание плохо сочетается с принципом веб-разработки «двигаться быстро и ломать вещи». Работа с системой управления контентом Drupal оказалась особенно сложной в этом отношении, поскольку крупные обновления намеренно нарушают совместимость со сторонними модулями, что подразумевает дорогостоящий процесс обновления, который клиенты редко могут себе позволить. Решение состояло в том, чтобы архивировать эти сайты: взять живой, динамический веб-сайт — и превратить его в простые HTML-файлы, которые любой веб-сервер может выдавать вечно. Этот процесс полезен для ваших собственных динамических сайтов, а также для сторонних сайтов, которые находятся вне вашего контроля, и которые вы хотите защитить.
Решение состояло в том, чтобы архивировать эти сайты: взять живой, динамический веб-сайт — и превратить его в простые HTML-файлы, которые любой веб-сервер может выдавать вечно. Этот процесс полезен для ваших собственных динамических сайтов, а также для сторонних сайтов, которые находятся вне вашего контроля, и которые вы хотите защитить.
С простыми или статичными сайтами отлично справляется почтенная программа Wget. Хотя для зеркалирования всего сайта понадобится настоящее заклинание:
$ nice wget --mirror --execute robots=off --no-verbose --convert-links \
--backup-converted --page-requisites --adjust-extension \
--base=./ --directory-prefix=./ --span-hosts \
--domains=www.example.com,example.com http://www.example.com/
Эта команда загружает содержимое веб-страницы, а также выполняет обход всех ссылок в указанных доменах. Перед запуском этого действия на любимом сайте рассмотрите возможные последствия краулинга. Приведённая выше команда намеренно игнорирует правила robots.txt, как сейчас принято у архивистов, и скачивает сайт на максимальной скорости. У большинства краулеров есть опции для паузы между обращениями и ограничения полосы пропускания, чтобы не создавать чрезмерную нагрузку на целевой сайт.
Приведённая выше команда намеренно игнорирует правила robots.txt, как сейчас принято у архивистов, и скачивает сайт на максимальной скорости. У большинства краулеров есть опции для паузы между обращениями и ограничения полосы пропускания, чтобы не создавать чрезмерную нагрузку на целевой сайт.
Эта команда также получает «реквизиты страницы», то есть таблицы стилей (CSS), изображения и скрипты. Загруженное содержимое страницы изменяется таким образом, что ссылки указывают уже на локальную копию. Результирующий набор файлов может быть размещён на любом веб-сервере, представляя собой статическую копию исходного веб-сайта.
Но это когда всё идёт хорошо. Любой, кто когда-либо работал с компьютером, знает, что вещи редко идут по плану: есть множество интересных способов сорвать процедуру. Например, некоторое время назад на сайтах было модно ставить блоки с календарём. CMS будет генерировать их «на лету» и отправит краулеры в бесконечный цикл, пытаясь получить всё новые и новые страницы. Хитрые архивариусы могут использовать регулярные выражениям (например, в Wget есть опция
Хитрые архивариусы могут использовать регулярные выражениям (например, в Wget есть опция --reject-regex), чтобы игнорировать проблемные ресурсы. Другой вариант: если доступен интерфейс администрирования веб-сайта — отключить календари, формы входа, формы комментариев и другие динамические области. Как только сайт станет статичным, они всё равно перестанут работать, поэтому есть смысл удалить этот беспорядок с исходного сайта.
Кошмар JavaScript
К сожалению, некоторые веб-сайты представляют собой гораздо больше, чем просто HTML. Например, на одностраничных сайтах веб-браузер сам создаёт контент, выполняя небольшую программу JavaScript. Простой пользовательский агент, такой как Wget, будет безуспешно пытаться восстановить значимую статическую копию этих сайтов, поскольку он вообще не поддерживает JavaScript. Теоретически, сайтам следует поддерживать прогрессивное улучшение, чтобы контент и функциональность были доступны без JavaScript, но эти директивы редко соблюдаются, как подтвердит любой, кто использует плагины вроде NoScript или uMatrix.
Традиционные методы архивирования иногда терпят неудачу самым тупым образом. При попытке сделать бэкап местной газеты я обнаружил, что WordPress добавляет строки запросов (например, ?ver=1.12.4) в конце include. Это сбивает с толку обнаружение content-type на веб-серверах, обслуживающих архив, потому что они для выдачи правильного заголовка Content-Type полагаются на расширение файла. Когда такой архив загружается в браузер, тот не может загрузить скрипты, что ломает динамические веб-сайты.
Поскольку браузер постепенно становится виртуальной машиной для запуска произвольного кода, то методам архивирования, основанным на чистом анализе HTML, следует адаптироваться. Решением этих проблем является запись (и воспроизведение) HTTP-заголовков, доставляемых сервером во время краулинга, и действительно профессиональные архивисты используют именно такой подход.
Создание и отображение файлов WARC
В Интернет-архиве Брюстер Кале и Майк Бёрнер в 1996 году разработали формат ARC (ARChive): способ объединить миллионы небольших файлов, созданных в процессе архивирования. В конечном итоге формат стандартизировали как спецификацию WARC (Web ARChive), выпущенную в качестве стандарта ISO в 2009 году и пересмотренную в 2017 году. Усилия по стандартизации возглавил Международный консорциум по сохранению Интернета (IIPC). Согласно Википедии, это «международная организация библиотек и других организаций, созданных для координации усилий по сохранению интернет-контента для будущего», в неё входят такие члены, как Библиотека Конгресса США и Интернет-архив. Последний использует формат WARC в своём Java-краулере Heritrix.
В конечном итоге формат стандартизировали как спецификацию WARC (Web ARChive), выпущенную в качестве стандарта ISO в 2009 году и пересмотренную в 2017 году. Усилия по стандартизации возглавил Международный консорциум по сохранению Интернета (IIPC). Согласно Википедии, это «международная организация библиотек и других организаций, созданных для координации усилий по сохранению интернет-контента для будущего», в неё входят такие члены, как Библиотека Конгресса США и Интернет-архив. Последний использует формат WARC в своём Java-краулере Heritrix.
Файл WARC объединяет в одном сжатом архиве несколько ресурсов, таких как заголовки HTTP, содержимое файла и другие метаданные. Удобно, что этот формат поддерживается и краулером Wget с параметром --warc. К сожалению, браузеры не могут напрямую отображать файлы WARC, поэтому для доступа к архиву необходима специальная программа просмотра. Или его придётся конвертировать. Самая простая программа просмотра, которую я нашёл, — pywb, пакет Python. Она запускает простой веб-сервер с интерфейсом типа Wayback Machine для просмотра содержимого файлов WARC. Следующий набор команд отобразит файл WARC на
Она запускает простой веб-сервер с интерфейсом типа Wayback Machine для просмотра содержимого файлов WARC. Следующий набор команд отобразит файл WARC на http://localhost:8080/:
$ pip install pywb
$ wb-manager init example
$ wb-manager add example crawl.warc.gz
$ waybackКстати, этот инструмент создали разработчики сервиса Webrecorder, который с помощью браузера сохраняет динамическое содержимое страницы.
К сожалению, pywb не умеет загружать WARC-файлы, сгенерированные Wget, потому что он подчиняется некорректным требованиям спецификации WARC 1.0, которые были исправлены в версии 1.1. Пока Wget или pywb не устранят эти проблемы, файлы WARC, созданные Wget, недостаточно надёжны, поэтому лично я начал искать другие альтернативы. Моё внимание привлёк краулер под простым названием crawl. Вот как он запускается:
$ crawl https://example.com/
Программа поддерживает некоторые параметры командной строки, но большинство значений по умолчанию вполне работоспособны: она скачает ресурсы вроде CSS и картинок с других доменов (если не указан флаг -exclude-related), но рекурсия не выйдет за пределы указанного хоста. По умолчанию запускается десять параллельных подключений: этот параметр изменяется флагом
По умолчанию запускается десять параллельных подключений: этот параметр изменяется флагом -c. Но главное, что результирующие файлы WARC отлично загружаются в pywb.
Будущая работа и альтернативы
Есть немало ресурсов по использованию файлов WARC. В частности, есть замена Wget под названием Wpull, специально разработанная для архивирования веб-сайтов. Она имеет экспериментальную поддержку PhantomJS и интеграцию с youtube-dl, что позволит загружать более сложные JavaScript-сайты и скачивать потоковое мультимедиа, соответственно. Программа является основой инструмента архивирования ArchiveBot, разработку которого ведёт «свободный коллектив озорников-архивистов, программистов, писателей и болтунов» из ArchiveTeam в попытке «сохранить историю, прежде чем она исчезнет навсегда». Похоже, что интеграция PhantomJS не так хороша, как хотелось бы, поэтому ArchiveTeam использует ещё кучу других инструментов для зеркалирования более сложных сайтов. Например, snscrape сканирует профили социальных сетей и генерирует списки страниц для отправки в ArchiveBot. Другой инструмент — crocoite, который запускает Chrome в headless-режиме для архивирования сайтов с большим количеством JavaScript.
Например, snscrape сканирует профили социальных сетей и генерирует списки страниц для отправки в ArchiveBot. Другой инструмент — crocoite, который запускает Chrome в headless-режиме для архивирования сайтов с большим количеством JavaScript.
Эта статья была бы неполной без упоминания «ксерокса сайтов» HTTrack. Аналогично Wget, программа HTTrack создаёт локальные копии сайтов, но, к сожалению, не поддерживает сохранение в WARC. Интерактивные функции могут быть более интересны начинающим пользователям, незнакомым с командной строкой.
В том же духе, во время своих исследований я нашёл альтернативу Wget под названием Wget2 с поддержкой многопоточной работы, которая ускоряет работу программы. Однако здесь отсутствуют некоторые функции Wget, в том числе шаблоны, сохранение в WARC и поддержка FTP, зато добавлены поддержка RSS, кэширование DNS и улучшенная поддержка TLS.
Наконец, моей личной мечтой для таких инструментов было бы интегрировать их с моей существующей системой закладок. В настоящее время я храню интересные ссылки в Wallabag, службе локального сохранения интересных страниц, разработанной в качестве альтернативы свободной программы Pocket (теперь принадлежащей Mozilla). Но Wallabag по своему дизайну создаёт только «читаемую» версию статьи вместо полной копии. В некоторых случаях «читаемая версия» на самом деле нечитабельна, и Wallabag иногда не справляется с парсингом. Вместо этого другие инструменты, такие как bookmark-archiver или reminescence, сохраняют скриншот страницы вместе с полным HTML, но, к сожалению, не поддерживают формат WARC, который бы обеспечил ещё более точное воспроизведение.
В настоящее время я храню интересные ссылки в Wallabag, службе локального сохранения интересных страниц, разработанной в качестве альтернативы свободной программы Pocket (теперь принадлежащей Mozilla). Но Wallabag по своему дизайну создаёт только «читаемую» версию статьи вместо полной копии. В некоторых случаях «читаемая версия» на самом деле нечитабельна, и Wallabag иногда не справляется с парсингом. Вместо этого другие инструменты, такие как bookmark-archiver или reminescence, сохраняют скриншот страницы вместе с полным HTML, но, к сожалению, не поддерживают формат WARC, который бы обеспечил ещё более точное воспроизведение.
Печальная правда моего зеркалирования и архивирования заключается в том, что данные умирают. К счастью, архивисты-любители имеют в своём распоряжении инструменты для сохранения интересного контента в интернете. Для тех, кто не хочет заниматься этим самостоятельно, есть Интернет-архив, а также группа ArchiveTeam, которая работает над созданием резервной копии самого Интернет-архива.
Как создавать цифровые архивы с помощью Omeka — Digital Gallatin
Omeka — это система управления контентом (CMS), которая позволяет быстро создавать архивы и цифровые выставки и управлять ими как индивидуально, так и в составе класса или исследовательской группы. Веб-сайты Omeka можно создавать без какого-либо опыта веб-дизайна или программирования, установка занимает очень мало времени и предлагает удобный интерфейс.
36 видов на гору Фудзи — это цифровая галерея, созданная с помощью Omeka вместе с плагинами Omeka Exhibit Builder и Neatline, чтобы дать преподавателям и студентам Галлатина Нью-Йоркского университета представление о том, что возможно с помощью этих инструментов.
Без каких-либо подключаемых модулей Omeka можно использовать для создания обширных баз данных и сложных цифровых архивов, каталогизированных в соответствии с метаданными Dublin Core, набором терминов, которые можно использовать для описания как сетевых, так и физических ресурсов. После установки Omeka пользователи могут добавлять элементы в архив, просто заполняя онлайн-формы и, при необходимости, загружая сопровождающие их файлы. Omeka может включать в себя различные типы элементов без каких-либо изменений в приложении, включая неподвижные изображения, тексты и аудиозаписи.
После установки Omeka пользователи могут добавлять элементы в архив, просто заполняя онлайн-формы и, при необходимости, загружая сопровождающие их файлы. Omeka может включать в себя различные типы элементов без каких-либо изменений в приложении, включая неподвижные изображения, тексты и аудиозаписи.
Посетители сайта могут просматривать элементы в соответствии с коллекциями и тегами, что дает создателям сайта некоторые кураторские полномочия. Дополнительные плагины предоставляют создателям больше возможностей для отображения элементов на сайте (например, создание страницы выставки; см. ниже).
Наш демонстрационный сайт включает базу данных Omeka, содержащую около 50 элементов. Вы можете просмотреть список всех наших предметов, а также кураторскую коллекцию предметов.
Просмотр товаров Omeka на нашем демонстрационном сайте.Плагин Exhibit Builder
Exhibit Builder значительно расширяет возможности творчества и взаимодействия с предметами из коллекции Omeka. Конструктор выставок можно использовать для выделения определенных элементов или наборов элементов, создания повествований вокруг выбранных элементов, а также для включения внешних источников и контекста для элементов. Пользователи могут добавлять интерпретирующий и пояснительный текст к выбранным элементам из архива.
Конструктор выставок можно использовать для выделения определенных элементов или наборов элементов, создания повествований вокруг выбранных элементов, а также для включения внешних источников и контекста для элементов. Пользователи могут добавлять интерпретирующий и пояснительный текст к выбранным элементам из архива.
Примером из образца сайта Омека является выставка «Развитие Эдо». Выставка посвящена серии изображений одного и того же места в Токио. Хотя выставка не является обширной, она выделяет некоторые функции плагина Exhibit Builder, такие как возможность встраивания внешних медиа (с некоторой настройкой настроек) и создание нескольких страниц в рамках одной выставки.
Плагин Neatline
Neatline сочетает в себе архивные возможности Omeka с картографическим инструментом для создания экспонатов на основе карт или изображений. Хотя использование исторических карт возможно с помощью картографических приложений, таких как Map Warper и ArcGIS, для многих проектов достаточно встроенных картографических инструментов. Наш образец выставки Neatline «36 видов на гору Фудзи» был создан с помощью одного плагина и картографических инструментов Neatline.
Наш образец выставки Neatline «36 видов на гору Фудзи» был создан с помощью одного плагина и картографических инструментов Neatline.
Сам Neatline имеет множество плагинов для создания пользовательского интерфейса и организации элементов на выставке. Образец, который мы создали, включает в себя путевые точки, которые позволяют нам создать список элементов, по которым пользователи могут щелкнуть. Другие плагины включают временные шкалы для организации элементов на карте не только географически, но и в хронологическом порядке.
Создание простой выставки Neatline не обязательно должно занимать много времени, если у вас есть архив Omeka, в котором уже есть элементы, которые вы хотите включить. Выставка Neatline, созданная командой Галлатина по образовательным технологиям, включает в себя некоторые функции, на создание которых уходит больше времени, например большие версии изображений и пользовательские цвета для рисунков. Хотя все это не является технически сложным и может быть выполнено в редакторе Neatline, внесение этих правок для 36 элементов добавило много времени к созданию экспоната.
Если вы еще этого не сделали, посетите наш образец сайта Omeka и выставок. И если вы заинтересованы в создании собственной галереи Omeka, свяжитесь с нами! (Вы также можете ознакомиться с нашими инструкциями по началу работы с Omeka).
6 советов по созданию цифрового архива
Столько контента было создано, оплачено и затем использовано только один раз. Создание цифрового архива — отличный способ дать старому контенту новую жизнь, и у него есть множество преимуществ, которые могут быть не очевидны сразу.
Но создание цифрового архива может показаться сложной задачей, особенно если у вас много контента. Иногда просто трудно понять, с чего начать. Чтобы помочь вам в этом, мы создаем новую серию статей о том, как оживить архив вашего журнала. Однако зачастую архивы – это не только печатные материалы.
Помните наш пост о том, как сектор исполнительских искусств использует цифровые архивы, чтобы воплотить в жизнь свои прошлые, но ценные представления? Мы в значительной степени установили, что стирать пыль с архивов и размещать их в Интернете — это, несомненно, хорошая идея.
Отличным примером архива, включающего различные типы контента, является Архив Сиднейского кинофестиваля . Архив кинофестиваля — это замечательная коллекция аудио-, видео- и печатных материалов, отражающих суть кинофестиваля за последние 60 с лишним лет.
Как и в случае с Ричардом Уоттсом , мы гордимся тем, что сохраняем прошлое для сегодняшней аудитории, чтобы пережить и почувствовать то, как потребляли ваши материалы много веков назад. Самое главное, что для любого бизнеса есть деньги в этой практике сделать ценное прошлое доступным одним касанием пальца любого человека со всего мира.
И если вам интересно, как это сделать эффективно, ниже приведены советы Майка Финча из Circus Oz и Риса Холдена из La Boite для тех, кто занимается исполнительским искусством. Мы думаем, что их советы так же полезны для всех других отраслей, а также для людей, которые могут думать о разработке цифровых архивов.
1. Думайте о своей аудитории
Холден подчеркивает важность четкого мышления о своей аудитории. «Аудитория для него имеет решающее значение. Если то, что вы пытаетесь сделать, это привлечь внимание широкой публики, сосредоточьтесь на этом, потому что проект может очень легко выйти из-под контроля. Особенно, если у вас долгая история. Так что сосредоточьтесь на вещах, которые вы хотите каталогизировать, и на том, как вы хотите их каталогизировать, потому что вы никогда не сможете сделать все это.
«Аудитория для него имеет решающее значение. Если то, что вы пытаетесь сделать, это привлечь внимание широкой публики, сосредоточьтесь на этом, потому что проект может очень легко выйти из-под контроля. Особенно, если у вас долгая история. Так что сосредоточьтесь на вещах, которые вы хотите каталогизировать, и на том, как вы хотите их каталогизировать, потому что вы никогда не сможете сделать все это.
2. Вовлекайте свою аудиторию
Вовлекайте свою аудиторию в процесс, сказал Холден. «У нас есть волонтеры, которые регулярно работают с нами над самыми разными проектами, и им нравилось участвовать в этом процессе — сканировании, вводе данных, помощи в хранении архива». архивариус
Может оказаться полезным обратиться за профессиональной помощью для оцифровки вашего архива. Холден рекомендует работать с опытным архивариусом и с коллекционными учреждениями — в случае Ла Бойта с музеем QPAC.
4. Доступ к финансированию
Холден подчеркивает, что создание цифрового архива может быть дорогостоящим, поэтому поиск финансирования может гарантировать успех проекта. «Мы финансировались через городской совет Брисбена, не через какую-либо художественную программу, а через грант на историю сообщества. И я думаю, что если организация играет ключевую роль в городе или в штате, то часто существует программа грантов, чтобы помочь с затратами на развитие.
«Мы финансировались через городской совет Брисбена, не через какую-либо художественную программу, а через грант на историю сообщества. И я думаю, что если организация играет ключевую роль в городе или в штате, то часто существует программа грантов, чтобы помочь с затратами на развитие.
Для создания привлекательного цифрового архива также требуется простой в навигации веб-сайт, который может быть дорогостоящим. «Потому что, если вы хотите получить отличный сайт, оказывается, вам нужен хороший разработчик. Нельзя просто собрать сайт на WordPress и надеяться, что все будет хорошо», — засмеялся он.
5. Найдите подходящих партнеров
Финч также подчеркнул важность правильной поддержки и правильных партнеров для таких проектов: «Я думаю, особенно когда речь идет о видео и больших файлах, движущихся изображениях, это, вероятно, сложнее, чем это кажется, но нам удалось пройти через это — очевидно, с огромной помощью RMIT, которые были нашими основными партнерами. И у нас было серьезное финансирование от Совета Австралии. Так что у нас были ресурсы, чтобы помочь нам сделать это, но это сложно».
И у нас было серьезное финансирование от Совета Австралии. Так что у нас были ресурсы, чтобы помочь нам сделать это, но это сложно».
6. Настойчивость
Финч отмечает, что сложные проекты иногда могут вырасти из самых легкомысленных предложений.
«Сначала я отбросил эту идею как предложение, может быть, сейчас это похоже на 10 лет назад: «Разве не было бы хорошо, если бы мы просто выложили все наши кадры на YouTube? Отдельные акты, по одному акту на клип?», — засмеялся он.
‘Это было именно так, и, знаете, спустя много времени, с большим количеством ресурсов и мозгов, мы, наконец, добились этого, но это сложно. Потратьте время, проведите много консультаций, но это определенно того стоит. Потому что, видя лица людей, которые… в нашем случае есть люди в возрасте 60 лет, которые думали, что никогда не увидят свое выступление, потому что они забыли, что его даже снимали. Сидеть и смотреть, как 20-летние подростки делают эти экстраординарные вещи, стоило того, это было потрясающе — с некоторыми потрясающими работами, которые затем можно сделать из них, если они были правильно записаны и доступны для поиска», — заключил Финч.