
что это такое и как она влияет на производительность
И снова здравствуйте! Продолжаем говорить о процессорах и параметрах, на которые стоит обращать внимание при их выборе. Да, у CPU очень много характеристик, и их сложно рассматривать в отдельности друг от друга, ведь всегда нужно учитывать, как они будут влиять на общую картину производительности и помогать CPU работать с другими компонентами ПК. Например, сегодня я расскажу, что такое пропускная способность процессора, для чего она определяется и на что влияет при выборе памяти для компьютера.
Что такое пропускная способность
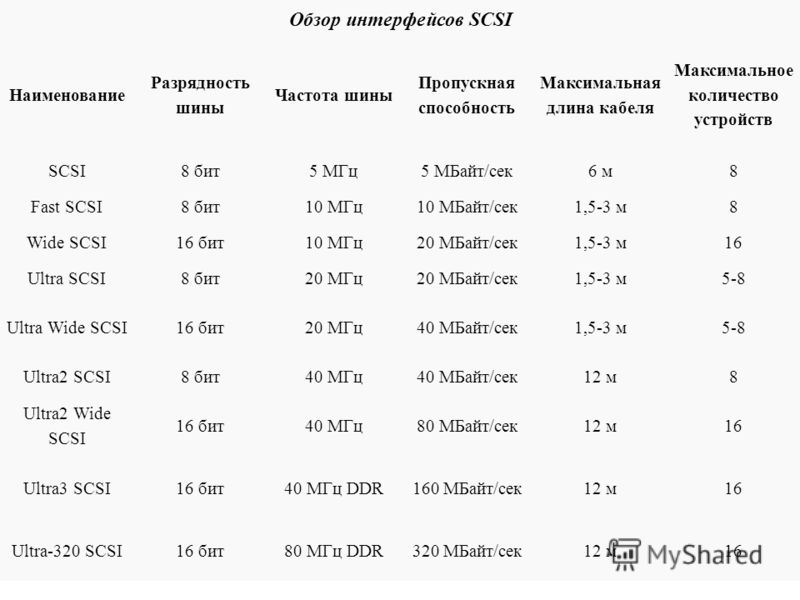
Вы могли видеть такой параметр в спецификациях процессоров. Им обозначается наибольшая скорость, с которой данные сохраняются в памяти или считываются из неё. Так как это скорость, она рассчитывается в Мб/с., Гб/с. или других подобных величинах.
Это одна из основных характеристик, связанных с ОЗУ ПК, наравне с её типом, объёмом, частотой.
Если вы будете искать этот же параметр не у процессора, а памяти, то здесь он будет означать не скорость передачи, а скорость обработки данных. Поэтому, чтобы всё получилось удачно, эти характеристики должны совпадать или быть как можно ближе друг к другу по значениям.
Поэтому, чтобы всё получилось удачно, эти характеристики должны совпадать или быть как можно ближе друг к другу по значениям.
Как она рассчитывается
Этот параметр CPU можно рассчитать, и здесь нет какой-то особенной формулы, только перемножаются некоторые величины, а точнее:
- Базовую тактовую частоту
- Количество передач за такт.
- Число интерфейсов.
- Ширину шины.
Но если вы прямо сейчас пойдёте искать всё это, то обнаружите, что в спецификации будет разве что первое значение. А с остальными возникнут трудности, потому что они редко обозначаются. Но если вы пойдёте искать информацию в статьях в интернете, то можете столкнуться с трудностями даже у их авторов.
И здесь действительно немного запутанная схема, с которой бывает сложно разобраться с первого раза, а если и разобрался — сложно после этого объяснить. Но я попробую как можно проще рассказать, как посчитать максимальную пропускную способность.
Итак, у нас есть 4 множителя. Базовую тактовую частоту вы можете взять в характеристиках памяти, которую присмотрели для своего ПК. Обычно её пишут в МГц, хотя это не очень правильно, но все уже привыкли. С этим проблем не будет.
Базовую тактовую частоту вы можете взять в характеристиках памяти, которую присмотрели для своего ПК. Обычно её пишут в МГц, хотя это не очень правильно, но все уже привыкли. С этим проблем не будет.
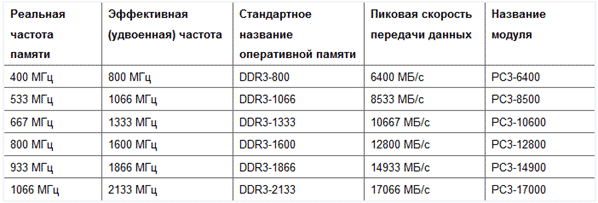
«Количество передач за такт» отсылает к типу памяти. Здесь учитывается основной стандарт DDR, который предполагает удвоенную передачу данных, поэтому, если тип обозначается как «DDR + число», берите для расчётов 2. Не обращайте внимание на число в маркировке, оно обозначает поколение и говорит скорее об увеличенной тактовой частоте, а вот передачи за один такт от этого не зависят.
Число интерфейсов — это сколько устройств памяти ваш процессор позволит вам использовать. Обычно можно установить 2 модуля, и именно столько и устанавливают. Поэтому здесь в большинстве случаев тоже берут 2.
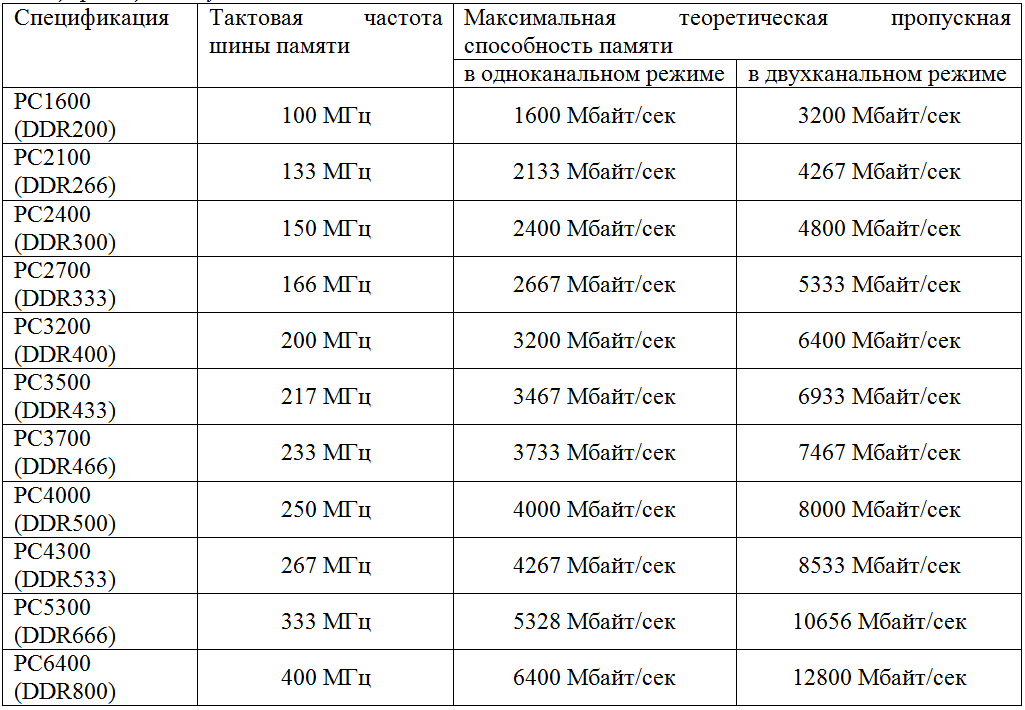
В качестве обозначения размера шины обычно берут 64 бита. Иногда пишут, что она 128 бит. Но это просто значит, что вам сразу говорят, сколько шин будет в 2 модулях памяти, а не в одном, один всё также будет содержать 64 бита.
Допустим, что тактовая частота указана как 3200 МГц. И здесь ещё одна ловушка, потому что это число показывает тактовую частоту, уже умноженную на количество передач за такт, то есть на 2. Это называется «эффективной частотой», и она всегда вдвое больше «реальной». То есть, если тактовая частота 3200 МГц, это 1600 МГц с удвоенной передачей.
Поэтому вам остаётся умножить это значение на 64, а потом на 2 (или сразу на 128). Сначала переведём 3200 МГц в Гц, получим 3 200 000 000 Гц. Умножаем это число на размер шины (64) и количество интерфейсов (2). Получаем 409 600 000 000 бит/с.
Но так как обычно в характеристиках процессоров используются другие величины, результат нужно к ним привести. Например, если использовать Гб/с., то здесь получится 47,68 Гб/с. Это значение вы можете сравнить со спецификацией CPU.
Влияние ли на производительность компьютера
Если говорить просто, при взаимодействии между ПК и пользователем данные, необходимые для обработки запросов последнего, постоянно попадают в ОЗУ. Все входные, выходные, промежуточные данные, а также выполняемые программы занимают память и находятся внутри неё, пока необходимы.
Учитывая это, несложно догадаться, что чем выше скорость передачи данных внутри памяти и вывода этих данных из неё, тем быстрее происходит обработка запросов пользователя. Поэтому чем выше значение этой характеристики, тем лучше. Но только в том случае, если устройства правильно подобраны друг к другу.
Как можно определить и где посмотреть
Сегодня информацию об этом параметре можно взять из спецификации. Бродя по интернет-магазинам в поисках подходящих деталей для своего ПК, вы найдёте его в характеристиках CPU как у Intel, так и у AMD.
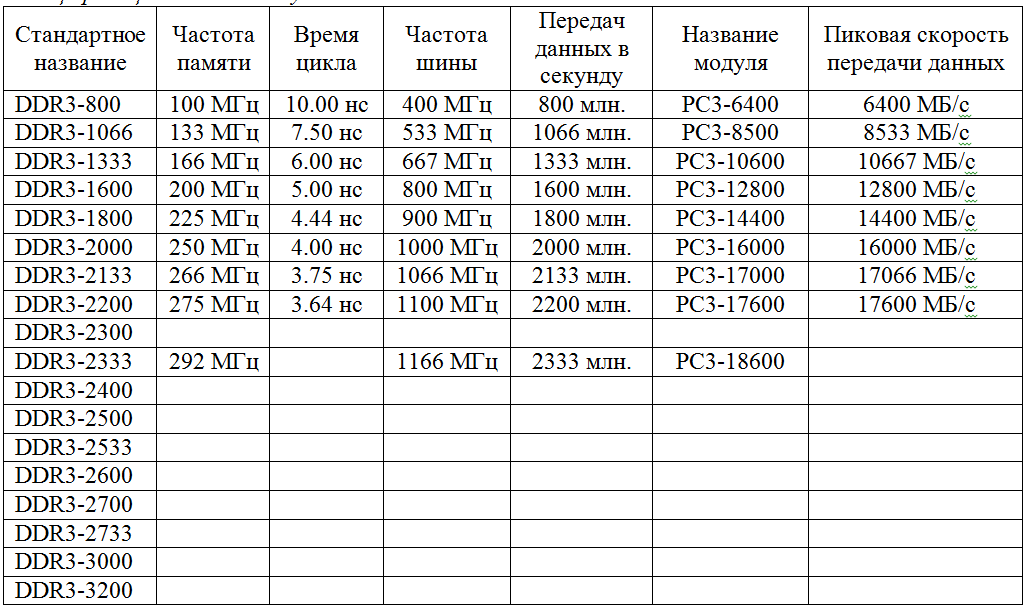
Если вы ищете, как узнать это значение из устройства памяти, то вы можете просто посмотреть на него. Там должна быть наклейка с названием модели и всеми основными маркировками, среди которых пригодится блок, начинающийся с букв PC.
Там должна быть наклейка с названием модели и всеми основными маркировками, среди которых пригодится блок, начинающийся с букв PC.
Цифра, идущая после него, означает поколение, то есть у DDR2 будет PC2, у DDR3 — PC3 и т. д. Вслед за ними, после дефиса, будет длинное число. Это то, что вам нужно, выраженное в байт/с.
Только не забудьте, что это данные только конкретного модуля, поэтому для понимания полной картины, нужно умножать указанные числа на количество устройств.
Как узнать максимальную пропускную способность
Несмотря на то, что в спецификациях системы обычно всё точно, значение, указанное здесь, далеко не всегда соответствует действительности. На деле указанное значение обычно на 10-15% выше, чем есть на самом деле.
Поэтому, определив значение из спецификации, уменьшите указанное количество Гб/с., и ориентируйтесь на второе число, чтобы точнее подобрать устройство.
В целом, разобраться в теме не так трудно, нужно просто быть внимательным и учитывать все параметры, так как здесь нет ничего лишнего. Что такое пропускная способность центрального процессора уже узнали, так что теперь, думаю, вам будет проще хотя бы с этими характеристиками, а об остальных расскажу в другой раз. А не потерять другие материалы по этой теме можно, подписавшись на мои социальные сети, буду рад вас там видеть. Всего хорошего!
Что такое пропускная способность центрального процессора уже узнали, так что теперь, думаю, вам будет проще хотя бы с этими характеристиками, а об остальных расскажу в другой раз. А не потерять другие материалы по этой теме можно, подписавшись на мои социальные сети, буду рад вас там видеть. Всего хорошего!
С уважением, автор блога Андрей Андреев.
Пропускная способность в IP-сетях: расчет и выбор сетевого оборудования
В рубрику «Комплексные решения. Интегрированные системы» | К списку рубрик | К списку авторов | К списку публикаций
В современных IP-сетях с появлением множества новых сетевых приложений оценить требуемую пропускную способность становится все труднее: как правило, необходимо знать, какие приложения планируется применять, какие протоколы передачи данных они используют и каким образом будут осуществлять обмен данными
Илья Назаров
Системный инженер компании «ИНТЕЛКОМ лайн»
После оценки требуемой пропускной способности на каждом из участков IP-сети необходимо определиться с выбором технологий сетевого и канального уровней OSI. В соответствии с выбранными технологиями определяются наиболее подходящие модели сетевого оборудования. Этот вопрос также непростой, поскольку пропускная способность напрямую зависит от производительности оборудования, а производительность, в свою очередь, – от программно-аппаратной архитектуры. Рассмотрим подробнее критерии и методы оценки пропускной способности каналов и оборудования в IP-сетях.
В соответствии с выбранными технологиями определяются наиболее подходящие модели сетевого оборудования. Этот вопрос также непростой, поскольку пропускная способность напрямую зависит от производительности оборудования, а производительность, в свою очередь, – от программно-аппаратной архитектуры. Рассмотрим подробнее критерии и методы оценки пропускной способности каналов и оборудования в IP-сетях.
Критерии оценки пропускной способности
Со времени возникновения теории телетрафика было разработано множество методов расчета пропускных способностей каналов. Однако в отличие от методов расчета, применяемых к сетям с коммутацией каналов, расчет требуемой пропускной способности в пакетных сетях довольно сложен и вряд ли позволит получить точные результаты. В первую очередь это связано с огромным количеством факторов (в особенности присущих современным мультисервисным сетям), которые довольно сложно предугадать. В IP-сетях общая инфраструктура, как правило, используется множеством приложений, каждое из которых может использовать собственную, отличную от других модель трафика.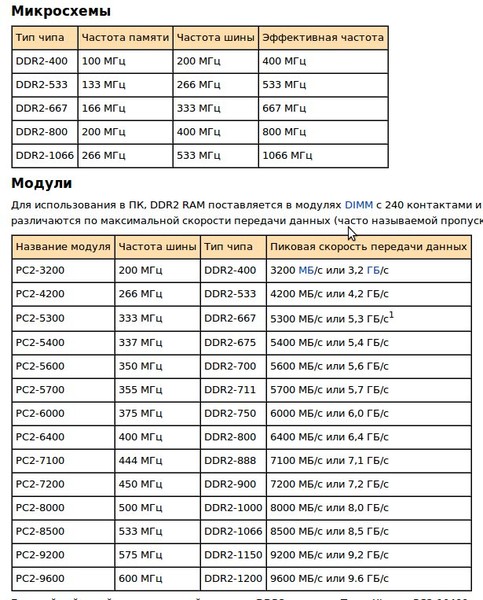 Причем в рамках одного сеанса трафик, передаваемый в прямом направлении, может отличаться от трафика, проходящего в обратном направлении. Вдобавок к этому расчеты осложняются тем, что скорость трафика между отдельно взятыми узлами сети может изменяться. Поэтому в большинстве случаев при построении сетей оценка пропускной способности фактически обусловлена общими рекомендациями производителей, статистическими исследованиями и опытом других организаций.
Причем в рамках одного сеанса трафик, передаваемый в прямом направлении, может отличаться от трафика, проходящего в обратном направлении. Вдобавок к этому расчеты осложняются тем, что скорость трафика между отдельно взятыми узлами сети может изменяться. Поэтому в большинстве случаев при построении сетей оценка пропускной способности фактически обусловлена общими рекомендациями производителей, статистическими исследованиями и опытом других организаций.
Чтобы более или менее точно определить, какая пропускная способность требуется для проектируемой сети, необходимо в первую очередь знать, какие приложения будут использоваться. Далее для каждого приложения следует проанализировать, каким образом будет происходить передача данных в течение выбранных промежутков времени, какие протоколы для этого применяются.
Для простого примера рассмотрим приложения небольшой корпоративной сети.
Пример расчета пропускной способности
Предположим, в сети расположены 300 рабочих компьютеров и столько же IP-телефонов. Планируется использовать такие сервисы: электронная почта, IP-телефония, видеонаблюдение (рис. 1). Для видеонаблюдения применяются 20 камер, с которых видеопотоки передаются на сервер. Попытаемся оценить, какая максимальная пропускная способность потребуется для всех сервисов на каналах между коммутаторами ядра сети и на стыках с каждым из серверов.
Планируется использовать такие сервисы: электронная почта, IP-телефония, видеонаблюдение (рис. 1). Для видеонаблюдения применяются 20 камер, с которых видеопотоки передаются на сервер. Попытаемся оценить, какая максимальная пропускная способность потребуется для всех сервисов на каналах между коммутаторами ядра сети и на стыках с каждым из серверов.
Следует сразу отметить, что все расчеты нужно проводить для времени наибольшей сетевой активности пользователей (в теории телетрафика – ЧНН, часы наибольшей нагрузки), поскольку обычно в такие периоды работоспособность сети наиболее важна и возникающие задержки и отказы в работе приложений, связанные с нехваткой пропускной способности, неприемлемы. В организациях наибольшая нагрузка на сеть может возникать, например, в конце отчетного периода или в сезонный наплыв клиентов, когда совершается наибольшее количество телефонных вызовов и отправляется большая часть почтовых сообщений.
Электронная почта
Возвращаясь к нашему примеру, рассмотрим сервис электронной почты. В нем используются протоколы, работающие поверх TCP, то есть скорость передачи данных постоянно корректируется, стремясь занять всю доступную пропускную способность. Таким образом, будем отталкиваться от максимального значения задержки отправки сообщения – предположим, 1 секунды будет достаточно, чтобы пользователю было комфортно. Далее нужно оценить средний объем отправляемого сообщения. Предположим, что в пиках активности почтовые сообщения часто будут содержать различные вложения (копии счетов, отчеты и т.д.), поэтому для нашего примера средний размер сообщения возьмем 500 кбайт. И наконец, последний параметр, который нам необходимо выбрать, – максимальное число сотрудников, которые одновременно отправляют сообщения. Предположим, во время авралов половина сотрудников одновременно нажмут кнопку «Отправить» в почтовом клиенте. Тогда требуемая максимальная пропускная способность для трафика электронной почты составит (500 кбайт х 150 хостов)/1 с = 75 000 кбайт/с или 600 Мбит/с. Отсюда сразу можно сделать вывод, что для соединения почтового сервера с сетью необходимо использовать канал Gigabit Ethernet.
В нем используются протоколы, работающие поверх TCP, то есть скорость передачи данных постоянно корректируется, стремясь занять всю доступную пропускную способность. Таким образом, будем отталкиваться от максимального значения задержки отправки сообщения – предположим, 1 секунды будет достаточно, чтобы пользователю было комфортно. Далее нужно оценить средний объем отправляемого сообщения. Предположим, что в пиках активности почтовые сообщения часто будут содержать различные вложения (копии счетов, отчеты и т.д.), поэтому для нашего примера средний размер сообщения возьмем 500 кбайт. И наконец, последний параметр, который нам необходимо выбрать, – максимальное число сотрудников, которые одновременно отправляют сообщения. Предположим, во время авралов половина сотрудников одновременно нажмут кнопку «Отправить» в почтовом клиенте. Тогда требуемая максимальная пропускная способность для трафика электронной почты составит (500 кбайт х 150 хостов)/1 с = 75 000 кбайт/с или 600 Мбит/с. Отсюда сразу можно сделать вывод, что для соединения почтового сервера с сетью необходимо использовать канал Gigabit Ethernet. В ядре сети это значение будет одним из слагаемых, составляющих общую требуемую пропускную способность.
В ядре сети это значение будет одним из слагаемых, составляющих общую требуемую пропускную способность.
Телефония и видеонаблюдение
Другие приложения – телефония и видеонаблюдение – в своей структуре передачи потоков схожи: оба вида трафика передаются с использованием протокола UDP и имеют более или менее фиксированную скорость передачи. Главные отличия в том, что у телефонии потоки являются двунаправленными и ограничены временем вызова, у видеонаблюдения потоки передаются в одном направлении и, как правило, являются непрерывными.
Чтобы оценить требуемую пропускную способность для трафика телефонии, предположим, что в пики активности количество одновременных соединений, проходящих через шлюз, может достигать 100. При использовании кодека G.711 в сетях Ethernet скорость одного потока с учетом заголовков и служебных пакетов составляет примерно 100 кбит/с. Таким образом, в периоды наибольшей активности пользователей требуемая пропускная способность в ядре сети составит 10 Мбит/с.
Трафик видеонаблюдения рассчитывается довольно просто и точно. Допустим, в нашем случае видеокамеры передают потоки по 4 Мбит/с каждая. Требуемая пропускная способность будет равна сумме скоростей всех видеопотоков: 4 Мбит/с х 20 камер = 80 Мбит/с.
Витоге осталось сложить полученные пиковые значения для каждого из сетевых сервисов: 600 + 10 + 80 = 690 Мбит/с. Это и будет требуемая пропускная способность в ядре сети. При проектировании следует также предусмотреть и возможность масштабирования, чтобы каналы связи могли как можно дольше обслуживать трафик разрастающейся сети. В нашем примере будет достаточно использования Gigabit Ethernet, чтобы удовлетворить требованиям сервисов и одновременно иметь возможность беспрепятственно развивать сеть, подключая большее количество узлов
Конечно же, приведенный пример является далеко не эталонным – каждый случай нужно рассматривать отдельно. В реальности топология сети может быть гораздо сложнее (рис. 2), и оценку пропускной способности необходимо производить для каждого из участков сети.
Нужно учитывать, что VoIP-трафик (IP-телефония) распространяется не только от телефонов к серверу, но и между телефонами напрямую. Кроме того, в разных отделах организации сетевая активность может различаться: служба техподдержки совершает больше телефонных вызовов, отдел проектов активнее других пользуется электронной почтой, инженерный отдел больше других потребляет интернет-трафик и т.д. В результате некоторые участки сети могут требовать большей пропускной способности по сравнению с остальными.
Полезная и полная пропускная способность
В нашем примере при расчете скорости потока IP-телефонии мы учитывали используемый кодек и размеры заголовка пакета. Это немаловажная деталь, которую нужно иметь в виду. В зависимости от способа кодирования (используемые кодеки), объема данных, передаваемых в каждом пакете, и применяемых протоколов канального уровня формируется полная пропускная способность потока. Именно полная пропускная способность должна учитываться при оценке требуемой пропускной способности сети. Это наиболее актуально для IP-телефонии и других приложений, использующих передачу низкоскоростных потоков в реальном времени, в которых размер заголовков пакета составляет существенную часть от размера пакета целиком. Для наглядности сравним два потока VoIP (см. таблицу). Эти потоки используют одинаковое сжатие, но разные размеры полезной нагрузки (собственно, цифровой аудиопоток) и разные протоколы канального уровня.
Это наиболее актуально для IP-телефонии и других приложений, использующих передачу низкоскоростных потоков в реальном времени, в которых размер заголовков пакета составляет существенную часть от размера пакета целиком. Для наглядности сравним два потока VoIP (см. таблицу). Эти потоки используют одинаковое сжатие, но разные размеры полезной нагрузки (собственно, цифровой аудиопоток) и разные протоколы канального уровня.
Скорость передачи данных в чистом виде, без учета заголовков сетевых протоколов (в нашем случае – цифрового аудиопотока), есть полезная пропускная способность. Как видно из таблицы, при одинаковой полезной пропускной способности потоков их полная пропускная способность может сильно различаться. Таким образом, при расчете требуемой пропускной способности сети для телефонных вызовов в пиковые нагрузки, особенно у операторов связи, выбор канальных протоколов и параметров потоков играет значительную роль.
Выбор оборудования
Выбор протоколов канального уровня обычно не составляет проблемы (сегодня чаще стоит вопрос, какая пропускная способность должна быть у канала Ethernet), но вот выбор подходящего оборудования даже у опытного инженера может вызвать затруднения.
Развитие сетевых технологий одновременно с растущими потребностями приложений в пропускной способности сетей вынуждает производителей сетевого оборудования разрабатывать все новые программно-аппаратные архитектуры. Часто у отдельно взятого производителя встречаются на первый взгляд схожие модели оборудования, но предназначенные для решения разных сетевых задач. Взять, к примеру, коммутаторы Ethernet: у большинства производителей наряду с обычными коммутаторами, используемыми на предприятиях, есть коммутаторы для построения сетей хранения данных, для организации операторских сервисов и т.д. Модели одной ценовой категории различаются своей архитектурой, «заточенной» под определенные задачи.
Кроме общей производительности, выбор оборудования также должен быть обусловлен поддерживаемыми технологиями. В зависимости от типа оборудования определенный набор функций и виды трафика могут обрабатываться на аппаратном уровне, не используя ресурсы центрального процессора и памяти. При этом трафик других приложений будет обрабатываться на программном уровне, что сильно снижает общую производительность и, как следствие, максимальную пропускную способность. Например, многоуровневые коммутаторы, благодаря сложной аппаратной архитектуре, способны осуществлять передачу IP-пакетов без снижения производительности при максимальной загрузке всех портов. При этом если мы захотим использовать более сложную инкапсуляцию (GRE, MPLS), то такие коммутаторы (по крайней мере недорогие модели) вряд ли нам подойдут, поскольку их архитектура не поддерживает соответствующие протоколы, и в лучшем случае такая инкапсуляция будет происходить за счет центрального процессора малой производительности. Поэтому для решения подобных задач можно рассматривать, например, маршрутизаторы, у которых архитектура основана на высокопроизводительном центральном процессоре и в большей степени зависит от программной, нежели аппаратной реализации. В этом случае в ущерб максимальной пропускной способности мы получаем огромный набор поддерживаемых протоколов и технологий, которые не поддерживаются коммутаторами той же ценовой категории.
Например, многоуровневые коммутаторы, благодаря сложной аппаратной архитектуре, способны осуществлять передачу IP-пакетов без снижения производительности при максимальной загрузке всех портов. При этом если мы захотим использовать более сложную инкапсуляцию (GRE, MPLS), то такие коммутаторы (по крайней мере недорогие модели) вряд ли нам подойдут, поскольку их архитектура не поддерживает соответствующие протоколы, и в лучшем случае такая инкапсуляция будет происходить за счет центрального процессора малой производительности. Поэтому для решения подобных задач можно рассматривать, например, маршрутизаторы, у которых архитектура основана на высокопроизводительном центральном процессоре и в большей степени зависит от программной, нежели аппаратной реализации. В этом случае в ущерб максимальной пропускной способности мы получаем огромный набор поддерживаемых протоколов и технологий, которые не поддерживаются коммутаторами той же ценовой категории.
Общая производительность оборудования
В документации к своему оборудованию производители часто указывают два значения максимальной пропускной способности: одно выражается в пакетах в секунду, другое – в битах в секунду. Это связано с тем, что большая часть производительности сетевого оборудования расходуется, как правило, на обработку заголовков пакетов. Грубо говоря, оборудование должно принять пакет, найти для него подходящий путь коммутации, сформировать новый заголовок (если нужно) и передать дальше. Очевидно, что в этом случае играет роль не объем данных, передаваемых в единицу времени, а количество пакетов.
Это связано с тем, что большая часть производительности сетевого оборудования расходуется, как правило, на обработку заголовков пакетов. Грубо говоря, оборудование должно принять пакет, найти для него подходящий путь коммутации, сформировать новый заголовок (если нужно) и передать дальше. Очевидно, что в этом случае играет роль не объем данных, передаваемых в единицу времени, а количество пакетов.
Если сравнить два потока, передаваемых с одинаковой скоростью, но с разным размером пакетов, то на передачу потока с меньшим размером пакетов потребуется больше производительности. Данный факт следует учитывать, если в сети предполагается использовать, например, большое количество потоков IP-телефонии – максимальная пропускная способность в битах в секунду здесь будет гораздо меньше заявленной.
Понятно, что при смешанном трафике, да еще и с учетом дополнительных сервисов (NAT, VPN), как это бывает в подавляющем большинстве случаев, очень сложно рассчитать нагрузку на ресурсы оборудования. Часто производители оборудования или их партнеры проводят нагрузочное тестирование разных моделей при разных условиях и результаты публикуют в Интернете в виде сравнительных таблиц. Ознакомление с этими результатами сильно упрощает задачу выбора подходящей модели.
Часто производители оборудования или их партнеры проводят нагрузочное тестирование разных моделей при разных условиях и результаты публикуют в Интернете в виде сравнительных таблиц. Ознакомление с этими результатами сильно упрощает задачу выбора подходящей модели.
Подводные камни модульного оборудования
Если выбранное сетевое оборудование является модульным, то, кроме гибкой конфигурации и масштабируемости, обещанной производителем, можно получить и множество «подводных камней».
При выборе модулей следует тщательно ознакомиться с их описанием или проконсультироваться у производителя. Недостаточно руководствоваться только типом интерфейсов и их количеством – нужно также ознакомиться и с архитектурой самого модуля. Для похожих модулей нередка ситуация, когда при передаче трафика одни способны обрабатывать пакеты автономно, а другие просто пересылают пакеты центральному процессорному модулю для дальнейшей обработки (соответственно для одинаковых внешне модулей цена на них может различаться в несколько раз).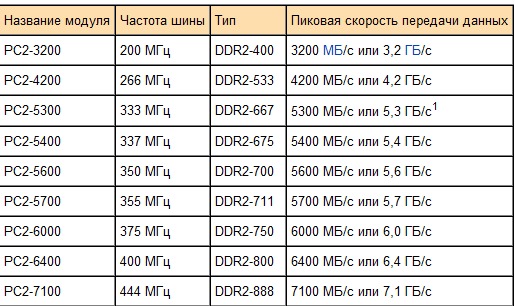 В первом случае общая производительность оборудования и, как следствие, его максимальная пропускная способность оказываются выше, чем во втором, поскольку часть своей работы центральный процессор перекладывает на процессоры модулей.
В первом случае общая производительность оборудования и, как следствие, его максимальная пропускная способность оказываются выше, чем во втором, поскольку часть своей работы центральный процессор перекладывает на процессоры модулей.
Кроме этого, модульное оборудование часто обладает блокируемой архитектурой (когда максимальная пропускная способность ниже суммарной скорости всех портов). Это связано с ограниченной пропускной способностью внутренней шины, через которую модули осуществляют обмен трафиком между собой. Например, если модульный коммутатор имеет внутреннюю шину с пропускной способностью 20 Гбит/с, то для его линейной платы с 48 портами Gigabit Ethernet при полной загрузке можно использовать только 20 портов. Подобные детали нужно также иметь в виду и при выборе оборудования внимательно читать документацию.
Общие рекомендации
При проектировании IP-сетей пропускная способность является ключевым параметром, от которого будет зависеть архитектура сети в целом. Для более точной оценки пропускной способности, можно руководствоваться следующим рекомендациям:
Для более точной оценки пропускной способности, можно руководствоваться следующим рекомендациям:
- Изучайте приложения, которые планируется использовать в сети, применяемые ими технологии и объемы передаваемого трафика. Пользуйтесь советами разработчиков и опытом коллег, чтобы учесть все нюансы работы этих приложений при построении сетей.
- Детально изучайте сетевые протоколы и технологии, которые используются этими приложениями.
- Внимательно читайте документацию при выборе оборудования. Чтобы иметь некоторый запас готовых решений, ознакомьтесь с продуктовыми линейками разных производителей.
В результате при правильном выборе технологий и оборудования можно быть уверенным, что сеть в полной мере удовлетворит требованиям всех приложений и, будучи достаточно гибкой и масштабируемой, прослужит долгое время.
Опубликовано: Журнал «Системы безопасности» #6, 2013
Посещений: 88409
Автор
| |||
В рубрику «Комплексные решения.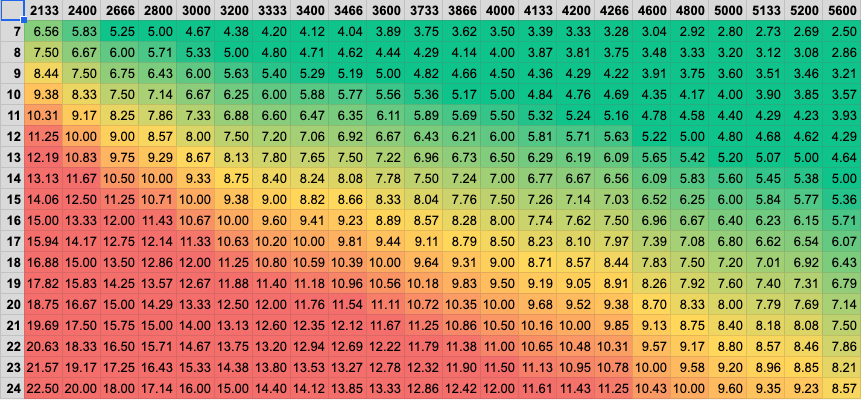 Интегрированные системы» | К списку рубрик | К списку авторов | К списку публикаций
Интегрированные системы» | К списку рубрик | К списку авторов | К списку публикаций
| Редакция 46 © 2012-2022 Зак Смит. Все права защищены.
Моя программа, называемая просто пропускная способность, представляет собой искусственный бенчмарк в первую очередь для измерения пропускной способности памяти на компьютерах на базе x86 и x86_64, полезный для выявления слабых мест в подсистеме памяти компьютера, в архитектуре шины, в архитектуре кэша и в самом процессоре. Эта программа с открытым исходным кодом и под лицензией GPL. Последняя полоса пропускания
Таким образом, он поддерживает четыре процессорные архитектуры:
Для каждой архитектуры я реализовал оптимизированные базовые процедуры на языке ассемблера. Одни и те же базовые процедуры языка ассемблера выполняются на всех компьютерах данной архитектуры.
Это похоже на использование той же физической 12-дюймовой линейки для измерения
несколько предметов. Такой подход жизненно важен. Если бы основные подпрограммы были написаны на C или C++, как некоторые люди сделали в других тестах, окончательный код, который выполняется, может отличаться в зависимости от версии компилятора и варианты компиляции. Поэтому основные подпрограммы никогда не должны быть написаны на языке высокого уровня. Насколько быстр каждый тип памяти в типичной системе? Именно такие детали задают на экзаменах студенты, изучающие компьютерную архитектуру. Компьютер имеет регистры, кэши (обычно 3 уровня), динамическая оперативная память и, конечно же, медленная память. Вот результаты для Core i5 520M с тактовой частотой 2,4 ГГц и оперативной памяти 1066 МГц. от самого медленного к самому быстрому.
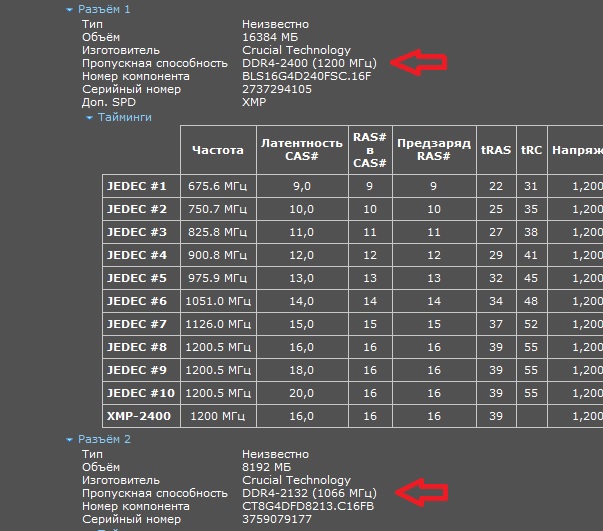
SSD до 4 раз быстрее, чем вращающийся жесткий диск. Первая интересная вещь, на которую следует обратить внимание, — это разница в производительности между 32-, 64- и 128-битными передачами на одном и том же процессоре. Эти различия показывают, что если бы программисты потрудились пересмотреть программное обеспечение для использования 64- или 128-битных передач, где это уместно, и особенно сделать их выровненными по соответствующим границам байтов и последовательным, можно было бы достичь значительного ускорения. Второе замечание касается важности наличия быстрой DRAM. Последняя разогнанная DRAM может дать потрясающие результаты. Третье наблюдение — заметная разница в скорости между типами памяти. В некоторых случаях кэш L1 более чем в два раза быстрее, чем L2, а L1 до 9 раз быстрее, чем основная память, тогда как L2 часто в 3 раза быстрее, чем DRAM. Нажмите здесь, чтобы просмотреть таблицу с примерами выходных значений . Действительно ли пропускная способность В моей двухъядерной системе Core i5 с памятью DDR3 (PC3-8500) максимальная пропускная способность ОЗУ должна составлять 8500 МБ/с. Работает только на одном ядре:
Когда у меня одновременно работают два экземпляра пропускной способности, по одному на каждое ядро, картина немного отличается, но не сильно.
Таким образом, чтобы действительно установить верхний предел производительности основной памяти, серьезному бенчмаркеру надлежит запустить несколько экземпляров пропускной способности и суммировать результаты. Apple M1, 1,3 ГГц, пиковая частота 3,2 ГГц Intel Core i5-1135G7, 2,4 ГГц, пиковая частота 4,2 ГГц Ryzen 5 5500U, 2,1 ГГц, максимальная частота 4 ГГц Intel Core 2 Duo P8600 с тактовой частотой 2,4 ГГц с 3 МБ кэш-памяти второго уровня, под управлением Mac OS/X Snow Leopard, 64-разрядные процедуры: Intel Core i5-540M с тактовой частотой от 2,53 до 3,07 ГГц с 3 МБ кэш-памяти L3, работающий под управлением 64-разрядной версии GNU/Linux: Нажмите здесь, чтобы загрузить 1.11.2d Будь милымВ GNU/Linux я рекомендую использовать nice -n -2 при управлении пропускной способностью. В противном случае ядро может попытаться задушить процесс. Версия 1.11Поддержка AVX-512. Улучшенные шрифты. Исправлена поддержка Win64/Cygwin.Версия 1.10Поддержка ARM64 (AArch64) и улучшенная поддержка ARM32 (AArch42).Версия 1. 9 Больше объектно-ориентированных улучшений. 9 Больше объектно-ориентированных улучшений.Версия 1.8Больше объектно-ориентированных улучшений. Поддержка 64-битной Windows.Версия 1.7Изолированная объектно-ориентированная библиотека C.Версия 1.6Обновлен для использования объектно-ориентированного C. Исправлена поддержка Raspberry pi.Версия 1.5Улучшенные 256-битные подпрограммы. Добавлен —nice переключатель.Версия 1.4Я добавил рандомизированные 256-битные подпрограммы для 64-битных процессоров Intel.Версия 1.3Я добавил вывод CSV. Я обновил код ARM для Raspberry pi 3 (AArch42).Версия 1.2Я вернул свой старый 32-битный код ARM для общих систем ARM.Версия 1.1В этом выпуске добавлен второй, более крупный шрифт.Версия 1.0Это обновление выделяет графическую функциональность. Он также добавляет тесты для инструкций LODS[BWDQ], потому что пока это Общеизвестно, что эти инструкции медленные и бесполезные, иногда широко распространенные убеждения ошибочны, поэтому я добавил этот тест, который доказывает, насколько резко медленными являются инструкции LODS. Версия 0.32Небольшая поддержка AVX.Версия 0.31В этом выпуске добавлена печать информации кэша для процессоров Intel в 32-битном режиме.Версия 0.30В этом выпуске добавлена печать информации о кеше для процессоров Intel в 64-битном режиме.Версия 0.29Дальнейшее улучшение детализации за счет добавления 128-байтовых тестов. Удалена поддержка ARM.Версия 0.28Добавлены правильные проверки функций с помощью инструкции CPUID.Версия 0.27Для процессоров x86 добавлены тесты размера фрагмента по 128 байт для улучшения детализации, особенно в отношении провала в 512 байт, наблюдаемого на процессорах Intel.Номер IntelMax Memory Bandwidth Когда Intel говорит, что вы можете достичь максимальной пропускной способности памяти Это большее число может на первый взгляд показаться маркетинговым трюком Intel, но это число полезно знать, потому что, когда ваша система очень загружена, это верхний предел, который будет ограничивать совместную работу всех ядер. Что Intel также должна сделать, так это указать максимум для каждого ядра вместе с общим максимумом. Почему 256-битные регистры передаются в/из основной памяти не быстрее, чем 128-битные?Путь к основной памяти обычно имеет ширину 128 бит, если у вас два модуля DIMM. Влияние кэша L4Кэши 4-го уровня якобы предназначены для повышения производительности графики, идея заключается в том, что графический процессор разделяет их с центральным процессором. Но влияет ли это на производительность процессора? Пользователь Michael V. с пропускной способностью Последовательный и произвольный доступ к памятиСовременные процессорные технологии оптимизированы для предсказуемого поведения при доступе к памяти, и последовательный доступ, конечно же, таков. Как видно из приведенных выше графиков, неупорядоченные обращения нарушают содержимое кэша, что приводит к снижению пропускной способности. Такой результат больше похож на реальную производительность, хотя и только для программ, интенсивно использующих память. Общие сведения о производительности памяти и регистровЕсть определенные ожидания относительно производительности различных подсистем памяти в компьютере. Моя программа подтверждает это.
Особые архитектурные преимуществаКак видно из приведенных выше графиков, архитектура тоже имеет значение.
Историческое дополнение Одним из факторов, снижающих пропускную способность компьютера, является кэш со сквозной записью, будь то L2 или L1. Сегодняшним эквивалентом является Передача вектора SSE4 в/из регистраХотя передачи между главными регистрами и векторными регистрами XMM с использованием инструкций MOVD и MOVQ выполняются хорошо, передачи с использованием инструкций PINSR* и PEXTR* выполняются медленнее, чем ожидалось. В целом перемещение 64-битного значения в регистр XMM или из него с помощью MOVQ выполняется в два раза быстрее, чем с помощью PINSRQ или PEXTRQ, что указывает на отсутствие оптимизации со стороны Intel в последних инструкциях. Как насчетгруппового режима? Допустим, ваша материнская плата поддерживает работу двухканальной оперативной памяти . Это означает, что ваши два модуля DIMM управляются вместе, предоставляя ЦП то, что выглядит как одно 128-битное запоминающее устройство. Используете ли вы двухканальный режим, зависит не только от вашей материнской платы и набора микросхем, но и от того, настроен ли ваш BIOS для этого. Настройка BIOS по умолчанию для этого, называемая функцией DCT или DCT, часто равна 9.0196 unanged т. е. две карты памяти не работают вместе. Что такое ДКТ? Это относится к контроллеру DRAM. Тот факт, что в неуправляемом режиме каждый канал является независимым, означает, что для каждого канала требуется DCT. Материнская плата и набор микросхем, поддерживающие широкий путь к вашей оперативной памяти, скорее всего, предоставят столько DCT, сколько имеется каналов, необходимых для режима без изменений. В настройках BIOS вы увидите либо простой выбор между режимами группирования и без синхронизации, либо это может относиться к тому, какие фактические контроллеры DRAM назначены тем или иным каналам, например. DCT0 (первый контроллер DRAM) подключается к каналу A, а DCT1 (второй контроллер) управляет каналом B. В: Действительно ли групповой режим увеличивает скорость? В: Если для режима без синхронизации требуется больше кремния (один DCT на канал), но производительность такая же, как и для режима с группировкой, то почему бы не включить группировку по умолчанию и не удалить дополнительные контроллеры DRAM? В: Как реально добиться максимальной производительности? Почему скорость чтения кэша L1 на процессорах XYZ такая высокая?Один пользователь показал мне график пропускной способности i5-2520M, где по какой-то причине загрузка 128-битных значений из кэша L1 последовательно в регистры XMM выполнялась с поразительной скоростью 9.6 ГБ в секунду. Запись в L1 была намного медленнее. После нескольких расчетов стало понятно, почему так происходит:
Поэтому Intel разработала схему таким образом, чтобы два регистра XMM могли быть загружены за один цикл. Кажется вероятным, что либо путь L1-XMM/YMM был расширен до 256 бит, либо чтение из L1 возможно со скоростью два за цикл (двойная скорость передачи данных). Скорее последний случай. Мой Xeon имеет общий L3 объемом 20 МБ. Будет ли это быстро? Общий L3 означает, что если у вас есть n ядер, и на каждом из них выполняется программа, которая очень интенсивно использует память, например, Это было недавно продемонстрировано мне, когда человек с двухпроцессорной системой Xeon 2690 (20 МБ L3, 8 ядер и 4 канала на ЦП) использовал пропускную способность на 8 ядрах из 16, в результате чего каждое ядро фактически имело только 5 МБ L3. . Если бы кто-то использовал AMD Opteron с 10 ядрами и 30 МБ общего L3, в худшем случае каждое ядро имело бы фактически 3 МБ L3, что соответствует Core i5 низкого потребительского уровня. Таким образом, когда Xeon и Opteron используются с приложением, интенсивно использующим память, работающим на каждом ядре, возможно, приоритет должен быть включен:
|



 Каждое отдельное ядро может обеспечить немного меньшую пропускную способность для основной памяти. Это нормально.
Каждое отдельное ядро может обеспечить немного меньшую пропускную способность для основной памяти. Это нормально. Кэш L4 объемом 128 МБ примерно в два раза быстрее основной памяти.
Кэш L4 объемом 128 МБ примерно в два раза быстрее основной памяти.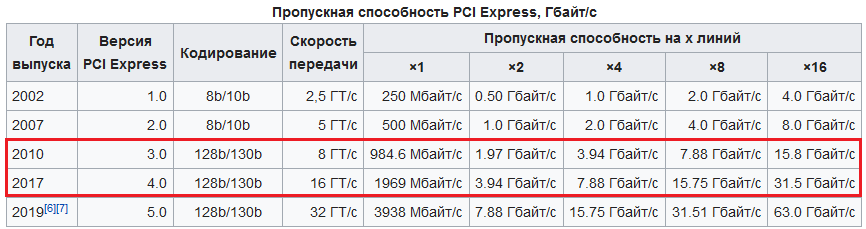 е. в 5 и более раз.
е. в 5 и более раз.
 Они использовались в первых компьютерах на базе Pentium, но были быстро заменены более эффективными кэшами с обратной записью.
Они использовались в первых компьютерах на базе Pentium, но были быстро заменены более эффективными кэшами с обратной записью.

профилирование — Как отслеживать использование полосы пропускания соединения NUMA (QPI/UPI) процессом в Linux?
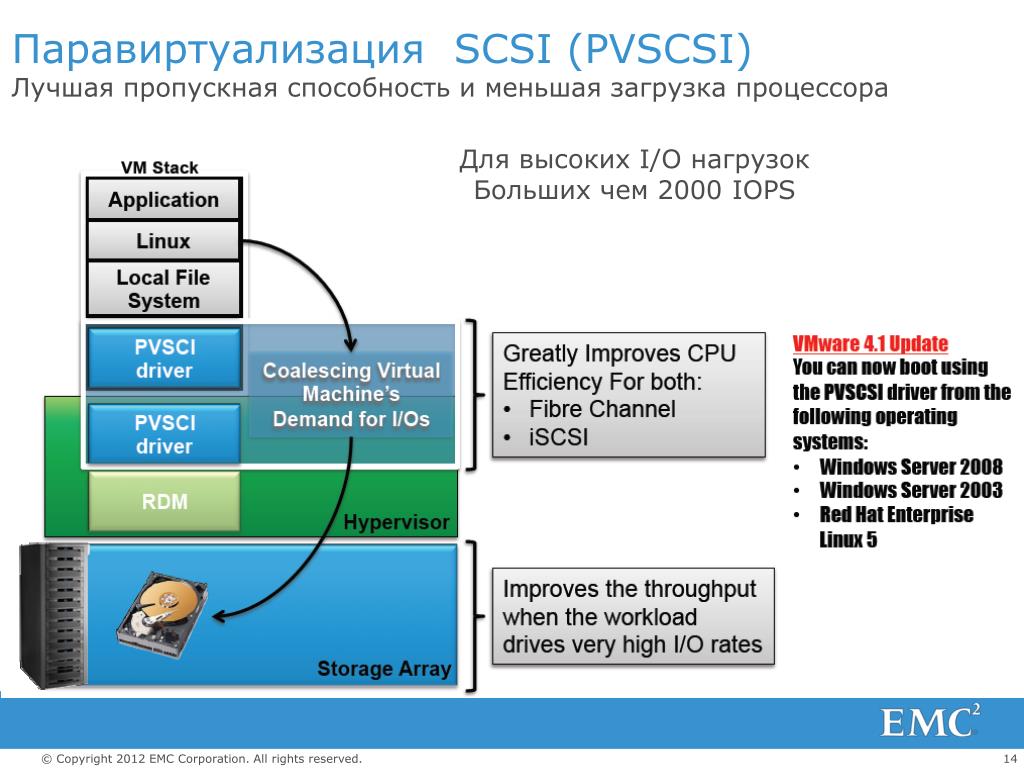
Вы хотите измерить трафик (пропускную способность), генерируемый доступом к памяти между двумя узлами с неоднородным доступом к памяти (NUMA) (он же «удаленный доступ к памяти» или «доступ NUMA»). Когда процессору необходимо получить доступ к данным, которые хранятся в памяти, управляемой другим процессором, используется двухточечное соединение процессора, такое как Intel Ultra Path Interconnect (UPI).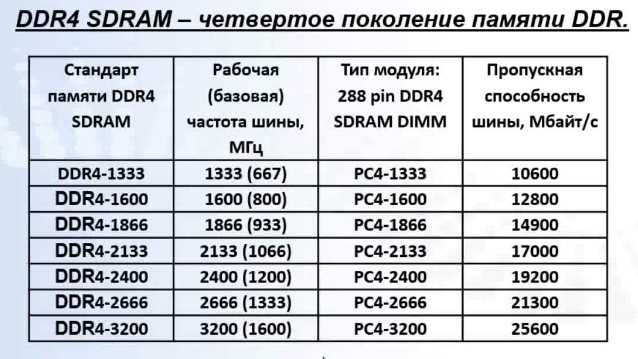
Сбор пропускной способности UPI (или QPI) для определенного процесса/потока может оказаться сложным.
Пропускная способность канала UPI (детализация сокета ЦП)
Монитор счетчика процессора (PCM) предоставляет ряд утилит командной строки для мониторинга в реальном времени. Например, двоичный файл pcm отображает оценку трафика UPI для каждого сокета. В зависимости от требуемой точности (и трафика NUMA, генерируемого другими процессами), этого может быть достаточно, чтобы понять, насыщены ли ссылки UPI.
Средство Intel Memory Latency Checker (MLC) можно использовать в качестве рабочей нагрузки для проверки поведения PCM при создании максимального трафика между двумя узлами NUMA.
Например, используя рабочую нагрузку, созданную ./mlc --bandwidth_matrix -t15 (во время фазы удаленного доступа), PCM отображает следующее с моим серверным узлом с двумя сокетами (Intel Cascade Lake):
Intel(r ) Оценка трафика данных UPI в байтах (трафик данных, поступающий на ЦП/сокет через каналы UPI):
УПИ0 УПИ1 УПИ2 | УПИ0 УПИ1 УПИ2
-------------------------------------------------- -------------------------------------------------- -----------
СКТ 0 17 Г 17 Г 0 | 73% 73% 0%
СКТ 1 6978 К 7184 К 0 | 0% 0% 0%
-------------------------------------------------- -------------------------------------------------- -----------
Общий входящий трафик данных UPI: 34 G трафика данных UPI/трафик контроллера памяти: 0,96
Оценка трафика Intel(r) UPI в байтах (трафик данных и не данных, исходящий от ЦП/сокета через каналы UPI):
УПИ0 УПИ1 УПИ2 | УПИ0 УПИ1 УПИ2
-------------------------------------------------- -------------------------------------------------- -----------
СКТ 0 8475 М 8471 М 0 | 35% 35% 0%
СКТ 1 21 Г 21 Г 0 | 91% 91% 0%
-------------------------------------------------- -------------------------------------------------- -----------
Общий объем исходящих данных UPI и трафика без данных: 59 G
ПАМЯТЬ (ГБ)->| ПРОЧИТАТЬ | НАПИСАТЬ | МЕСТНЫЙ | ПММ РД | ПММ ВР | Энергия процессора | энергия DIMM | LLCRDMISSLAT (нс) UncFREQ (ГГц)
-------------------------------------------------- -------------------------------------------------- -----------
СКТ 0 0,19 0,05 92 % 0,00 0,00 87,58 13,28 582,98 2,38
СКТ 1 36,16 0,01 0 % 0,00 0,00 66,82 21,86 9698,13 2,40
-------------------------------------------------- -------------------------------------------------- -----------
* 36,35 0,06 0 % 0,00 0,00 154,40 35,14 585,67 2,39
Мониторинг трафика NUMA (детализация ядра ЦП)
PCM также отображает удаленный трафик для каждого ядра в МБ/с (т. е. трафик NUMA). См. столбец юаней:
е. трафик NUMA). См. столбец юаней:
.юаней : внешняя пропускная способность кэша L3, удовлетворяющая удаленной памяти (в МБ)
Ядро (SKT) | ИСПОЛНИТЕЛЬ | МПК | ЧАСТОТА | АФРЕК | L3МИСС | L2МИСС | L3HIT | L2HIT | Л3МПИ | L2MPI | L3OCC | ЛКМ | юаней | ТЕМП 0 0 0,04 0,04 1,00 1,00 1720 К 1787 К 0,04 0,55 0,0167 0,0173 800 1 777 49 1 0 0,04 0,04 1,00 1,00 1750 К 1816 К 0,04 0,55 0,0171 0,0177 640 5 776 50 2 0 0,04 0,04 1,00 1,00 1739 К 1828 К 0,05 0,55 0,0169 0,0178 720 0 777 50 3 0 0,04 0,04 1,00 1,00 1721 К 1800 К 0,04 0,55 0,0168 0,0175 240 0 784 51 <фрагмент> -------------------------------------------------- -------------------------------------------------- ----------- СКТ 0 0,04 0,04 1,00 1,00 68 М 71 М 0,04 0,55 0,0168 0,0175 26800 8 31632 48 СКТ 1 0,02 0,88 0,03 1,00 66 К 1106 К 0,94 0,13 0,0000 0,0005 25920 4 15 52 -------------------------------------------------- -------------------------------------------------- ----------- ВСЕГО * 0,03 0,06 0,51 1,00 68 млн 72 млн 0,05 0,54 0,0107 0,0113 Н/Д Н/Д Н/Д Н/Д
Удаленный трафик для каждого ядра можно использовать для сбора трафика NUMA на уровне потока.