
Как узнать местоположение пользователя, зная только его email-адрес / Habr
В статье описан очень простой и банальный метод, позволяющий определить IP-адрес получателя письма. Как все мы с вами знаем — имея IP-адрес, вычислить скрытую за ним персону не составит труда, особенно если вы сотрудник министерства Правды.Статья не откроет ничего нового для людей, знакомых с принципом работы HTML, HTTP и почтовых клиентов, но, возможно, покажет, как этим можно пользоваться с другой точки зрения. Для “просто”-пользователей ПО, мобильных устройств и электронной почты статья может показать на сколько важно соблюдать интернет-гигиену и оберегать свои персональные данные (к которым относиться email-адрес) в сети «Интернет».
Метод
Всем известно, что в современном мире можно отправить письмо c заголовком
Content-Type: text/html;, что позволяет придать письму “правильный” внешний вид, подключить стили и картинки. Стили и картинки могут быть как вложенными, так и ссылающимися на внешние ресурсы. Если отправленное письмо пройдет мимо “спам”-фильтра, прикрепленные файлы будут подгружены автоматически при открытии письма.Более того, многие почтовые клиенты на ПК, Mac и мобильных устройствах подгружают прикрепленные файлы заблаговременно, то есть в момент получения письма и до его фактического открытия и прочтения пользователем, например, в момент подключения к Wi-Fi или 3G (в зависимости от почтового клиента и его настроек).
Дело в том, что при обращении к прикрепленному файлу происходит HTTP-запрос на сервер, где файл физически расположен. При входящем обращении, оба хоста обмениваются данными о себе, в том числе IP-адресами, соотвественно — почтовый клиент, обратившись за ccs-фалом или графическим изображением вложенным в письмо, моментально передает IP-адрес получателя письма.
Что делать с полученным IP-адресом
Для Хабражителей данный вопрос не актуален, но тем не менее поясню. Имея IP-адрес его можно передать в министерство Правды, там дальше сами разберутся.
Дополнительно можно воспользоваться поиском по IP-адресам (whois) и выяснить кому он принадлежит, редко, но может оказаться так, что искомый нами IP-адрес выдан физическому лицу. Далее как с доменом — все явки (ФИО, адрес и др. данные) указаны в whois информации. В случае, если IP-адрес принадлежит интернет-провайдеру (в том числе оператору мобильной связи), за которым скрыт наш получатель письма, можно обратится к оператору напрямую или через МВД (в случае помощи в каком-либо расследовании или его ведении).
При обращении к интернет-провайдеру помимо IP-адреса и причины обращения, необходимо указать точное время, когда к пользователю был привязан данный IP-адрес.
Имея IP-адрес через whois всегда можно узнать город, а часто и административный округ, в котором находится получатель письма.
Как оформить письмо и откуда его отправить
Для составления письма возьмите любой текст, который будет выглядеть как “спам” для получателя письма, что бы он не обратил на него внимания. Но при этом не стоит брать текст из “спам”-писем, пришедших на Вашу почту, и тем более в “спам”-папку — для минимизации шансов попадания отправленного нами письма в поле зрения “спам”-фильтра на стороне получателя.
Для отправки письма воспользуйтесь любым сервисом, предоставляющим возможность анонимной отправки писем. При этом рекомендую выходить в интернет используя различные анонимайзеры, VPN, Tor и браузер в порно приватном-режиме (без сохранения cookie, localStorage и т.п.), и с публичного Wi-Fi (в кепке, очках и темной неприметной одежде).
Что необходимо для сохранения заголовка REMOTE_ADDR
Вам необходим доступ на публично-доступный сервер или хостинг. Желательно с ненужным IP-адресом или доменным именем, который не жалко сменить или который никак к Вам не относится. Можно воспользоваться динамическим DNS, который временно будет перенаправлять все запросы с временного IP-адреса на Ваш хост.
Для уменьшения подозрительности возвращаем реальные файлы с правильными заголовками и Content-Type соответствующим запрошенным файлам (некоторые почтовые-клиенты и их браузерные версии проверяют прикрепленные файлы на соответствие).
При отправке писем по множеству адресов можно прикрепить GET-параметр для идентификации каждого из получателей.
В каких случаях это не работает
- Если получатель письма пользуется каким-либо анонимайзером, VPN или Tor;
- Большинство браузерных версий почтовых-клиентов кешируют прикрепленные файлы на своей стороне — в данном случае Вы получите IP-адрес почтового сервиса;
- При попадании письма в “спам”.
Когда это работает
В 70% случаях при использовании получателем письма почтового клиента на мобильном устройстве, благо количество пользователей смартфонов и мобильного-интернета растет.
Спасибо. Соблюдайте интернет-гигиену и обрегайте свои персональные данные.
Структура формирования url-адресов в Интернет.
Когда мы хотим обратиться к какому-то ресурсу в Интернет, нам нужно знать его адрес. Адреса в Интернет формируются в виде URL-адресов. Это формат, с помощью которого можно обратиться к любому ресурсу в Интернет.
Давайте рассмотрим, как можно сформировать этот адрес. Какая структура и синтаксис эти URL-адресов.
Предположим, что у нас есть компьютер, на котором мы работает и для обращения к ресурсу в Интернет, мы должны зайти в программу на этом компьютере, которая умеет обрабатывать эти адреса (например, браузер или FTP-клиент), обращаемся по определенному URL-адресу и получаем доступ к какому-то ресурсу, который располагается в сети Интернет.
Задача сейчас разобраться, как можно создавать эти URL-адреса и как их можно формировать.
Вот структура любого URL-адреса:
<схема>:[//[<логин>[:<пароль>]@]<хост>[:<порт>]][/<URL-путь>][?<параметры>][#<якорь>]
[] — опциональные параметры. Т.е. их может не быть.
Единственно, что обязательно в этом формате — это схема и хост.
Что такое схема?
Под схемой понимается тот протокол, по которому мы хотим обратиться к ресурсу (http, https, ftp). Это те правила, по которым будет обрабатываться наш запрос.
Что такое хост?
Это то доменное имя сайта (например, abc.ru) или IP адрес какого-то ресурса (172.217.168.195).Бывают также ситуации, что сервер для доступа к своим ресурсам может потребовать логин и пароль. Это просто данные об имени пользователя, который зарегистрирован на этом сайте и его пароле.
Что такое параметр порт?
Это некое уникальное число от 0 до 255, которое указывает к какой конкретно службе на хосте мы обращаемся.
Для веб-сервера портом по умолчанию является 80.
URL-путь дает возможность обращаться к какому-то конкретному файлу или папке на удаленном ресурсе.
Этот адрес указывается в формате
/имя1/имя2/…
или
/имя1/имя2/имя_файла
C помощью такой структуры вы можете указать уникальный адрес к конкретной веб-странице, которую вы хотите посмотреть.
Следующая часть URL-адреса — это параметры.
Это дополнительные данные, которые можно передать серверу, через адресную строку.
Формат:
имя_параметра = значение
Параметры разделяются знаком &. Подробнее см. в виде выше.
С помощью этих параметров мы можем передать информацию откуда пришел посетитель, по какому источнику, и.т.д.
Последняя составляющая в URL-адресе — это якорь.
Якорь — это часть адреса, которая указывается последней и начинается с символа #. Добавив якорь мы говорим браузеру какое конкретное место на веб-странице он должен отобразить при переходе на какую-то определенную страницу.
Более подробно обо всем этом посмотрите в видео вначале страницы.
Как найти email нужного человека: инструменты, хитрости, тактика

Евгений Бойченко
Руководитель отдела маркетинга студии мобильной разработки Live Typing.
Нас всех раздражают телефонные продавцы: они звонят в неудобное время, предлагают ненужную фигню, говорят как роботы, их заученные вступления приходится терпеливо слушать, поскольку послать сразу не позволяет воспитание. Но как быть, когда нам самим надо взять и продать что-нибудь: продукт стартапа, услугу компании, себя в качестве специалиста?
Как человек, практикующий email-продажи в течение нескольких лет, могу ответственно заявить: они работают. И если ваш потенциальный покупатель — человек из мира digital, в котором, как мы знаем, звонить считается неприличным, то вам обязательно нужно протестировать канал продаж через электронную почту.
Достигнуть успеха помогут несколько вещей: список потенциальных клиентов; понятный и востребованный рынком продукт; способность чётко и без фамильярности изложить своё предложение в двух абзацах; хорошая презентация во вложении; электронная почта человека, который принимает решения. В этой статье мы поговорим о том, как её найти.
На сайте
Сделаем допущение, что среди читателей есть люди, которые вообще не знакомы с темой, и начнём с азов. Вы попали на сайт некой компании и поняли, что это ваш потенциальный клиент, и даже нашли на страничке контактов ящик вида [email protected]. Не спешите на него писать: в большинстве случаев это будет письмо в никуда.
Пишите на общий ящик в последнюю очередь, если никакие советы из этой инструкции вам не помогли.
Изучите сайт внимательнее: просмотрите полностью страницы контактов, о компании, о команде. Вполне возможно, вам удастся найти имя и почту руководителя, ответственного за нужное вам направление. Современные директора часто выкладывают личную почту в открытый доступ, намекая на свою доступность при возникновении проблем.
Если с сайта можно скачать пресс-кит, презентацию или отчёт компании, пролистайте их: на последнем слайде можно найти контакты ключевых персон. Также имеет смысл изучить блог компании и просмотреть профили авторов постов или раздел «Пресса о нас». Часто там размещаются публикации с упоминанием первых лиц компании, из таких постов вы узнаете их имена, а это уже полдела.
Не лишним будет прочитать и политику конфиденциальности: в ней часто указывают полные реквизиты компании, возможно, там будет и email руководителя.
Ещё на многих сайтах сейчас размещены онлайн-чаты с живым консультантом. Если повезёт, он сможет подсказать вам нужного человека и его контакты. Не стесняйтесь спрашивать.
В соцсетях
Если на сайте ничего найти не удалось, попробуйте заглянуть в соцсети компании: Facebook, VK, Instagram, LinkedIn, Twitter — обычно ссылки на них прячутся в футере сайта. В соцсетях компании рассказывают о своей жизни, хвастаются публикациями в прессе, постят вакансии, поздравляют коллег с днём рождения. Если у компании более-менее налажен SMM, найти имена ключевых людей в её соцсетях не составит большого труда.
В Facebook часто можно встретить посты вида «Если вам интересна наша вакансия, пишите руководителю отдела N на адрес [email protected]». Также здесь любят упоминать конкретных сотрудников в постах, что автоматически создаёт ссылку на их Facebook-профиль. В таком случае вы можете написать человеку личное сообщение, а не email, но перед этим убедитесь, что ваш собственный профиль выглядит адекватно.
Ещё стоит помнить, что если у вас с потенциальным клиентом нет общих друзей, то ваше сообщение попадёт в папку «Другое», эквивалентную папке «Спам». На этот случай полезно иметь в друзьях несколько популярных «тысячников»: наверняка через кого-то из них вы попадёте в общие друзья нужного вам лица.
ВКонтакте
В VK релевантно всё то же, что и в Facebook, но ещё добавляется возможность найти имена руководителей в блоке «Контакты», который есть почти на каждой бизнес-странице справа внизу.
В Instagram вам может попасться общее фото сотрудников, при тапе на которое всплывают ссылки на их личные аккаунты. Такие аккаунты можно прокликать и изучить раздел Bio, там вполне может оказаться должность, имя, ссылка на другую соцсеть.
В LinkedIn всё ещё проще, так как эта соцсеть заточена на бизнес-знакомства. Найдя профиль компании или набрав её название в поиске, вы увидите список её сотрудников с именами и должностями. В большинстве случаев их почта не будет видна вам, если вы не в друзьях или у вас нет платной подписки. Но есть маленькая хитрость, о которой я расскажу ниже, — плагин для Chrome от Hunter.io. Если прибегать к хитростям лень, можно купить специальный тарифный план соцсети. Он позволяет писать сообщения любым незнакомым людям с гарантией прочтения.
Особенность Twitter в том, что здесь люди и аккаунты компаний частенько переписываются публично со своими коллегами по цеху и клиентами и не стесняются светить email. Найти их вам поможет расширенный поиск: в поле «Все из этих слов» вводите (at), (dot), @company.ru, а в поле «От этих пользователей» — название интересующего вас Twitter-аккаунта.
Нишевые соцсети
- Slideshare — компании и публичные лица загружают сюда свои презентации с вебинаров и конференций. На последнем слайде, как правило, можно найти личную почту.
- Angel.co, Crunchbase.com — каталоги digital-компаний и стартапов со всего мира с подробным перечислением имён ключевых лиц и их должностей.
- Habr, GitHub, «Мой круг» — помогут в поиске контактов технических специалистов и разработчиков. Чтобы найти их, используйте поиск по названию компании.
В поисковиках
Если название искомой компании уникальное и она имеет более-менее известный бренд (ну, например, LaModa, а не ООО «Прогресс», которых в каждом городе по несколько штук), то можно идти в поисковики и делать запросы вида «директор по маркетингу LaModa». Если повезёт, вы увидите в выдаче ссылки на интервью с этим человеком или упоминания его имени в отраслевых новостях, с большой вероятностью на первой странице будет также ссылка на его профиль в LinkedIn.
Информация в поиске имеет свойство устаревать, а люди могут менять работу, так что проверяйте актуальность дат в найденных материалах.
Также вы можете воспользоваться расширенным поиском «Яндекса» или Google. Для начала попробуйте построить запрос по таким формулам:
- [имя] + email / email address / почта / адрес;
- [имя] + contact / contact information / contact me / контакты.
Если это не помогло, нужно подойти к вопросу более креативно, прибегнув к помощи поисковых операторов. Попробуйте поискать нужную информацию на сайте компании, например:
- site:companywebsite.com + [имя] + email;
- site:companywebsite.com + [имя] + contact.
Все вышеперечисленные способы являются азами поиска информации и позволят вам найти если не адрес электронной почты, то по крайней мере имя нужного человека. А дальше в ход идут хитрости и инструменты продвинутого поиска email, известные опытным digital-продавцам и рекрутерам, но не широкой публике. Сейчас мы немножко восстановим справедливость и расскажем о таких трюках.
Тактики продвинутого поиска
Основная хитрость с выяснением электронных адресов заключается в том, что если это корпоративные адреса, то все они строятся по определённым шаблонам, в которых комбинируются разные варианты написания имени и фамилии. Приведём в пример самые популярные:
- [email protected];
- [email protected];
- [email protected];
- [email protected];
- [email protected];
- [email protected];
- [email protected];
- [email protected];
- [email protected];
- [email protected].
Зная имя и фамилию адресата, а также сайт компании, вы сможете с высокой долей вероятности подобрать адрес человека, пользуясь этими шаблонами. Чтобы вычислить, какой именно тип шаблона используется в нужной вам организации, можно сделать три вещи:
- Пользуясь обозначенными выше советами, найти email любого работника компании, не обязательно топ-менеджера, и посмотреть, как он устроен. Если этот адрес имеет вид [email protected], скорее всего, адрес нужного вам человека будет строиться так же.
- Вбить адрес сайта компании в сервис Hunter.io и посмотреть, какие адреса на этом домене он знает.
- Воспользоваться справочными сервисами, такими как Email-format.com или Emails4corporations. Это базы данных с шаблонами email, которые используются в средних и крупных предприятиях, в основном западных. Искать ящики небольших российских компаний с помощью этих сервисов бессмысленно, но если вы хотите выйти на представителя западной корпорации или крупного российского бизнеса, стоит проверить эти ресурсы. На них, к примеру, есть шаблоны адресов «Газпрома», «Тинькофф-банка» и «Касперского».
Итак, вы нашли имя человека и шаблон, по которому строится его электронный адрес. Например, имя — Евгений Бойченко, сайт компании — Livetyping.com, а вероятная почта, судя по адресам других сотрудников, найденных на Hunter.io, — [email protected].
Следующий этап — проверка предполагаемого адреса на работоспособность. Для этого вам нужно воспользоваться сервисами по проверке валидности почты. Погуглите по запросу email checker или проверка имейла на существование; выберите сайт, который вам больше нравится по дизайну, и добавьте его в закладки. Я пользуюсь сайтами Tools.verifyemailaddress.io или Mailtester.com, но в Cети есть сотни других.
Теперь идём на выбранный сайт и вбиваем в форму предполагаемый email:
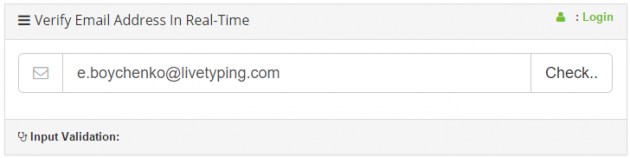
Жмём на кнопку Check и получаем результат:
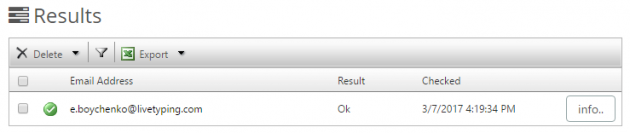
Ура, зелёный огонёк! Это значит, что адрес валиден и на него можно писать заветное продающее письмо.
Теперь рассмотрим случай посложнее.
Если вы нигде не нашли шаблона адреса, который используется в компании, придётся действовать методом перебора: взять пачку всех возможных шаблонов адресов и проверить их на существование. Автоматизировать ваш труд поможет распространённая в Сети табличка, которую я дополнил полезными ссылками и инструкциями. Она сгенерирует для вас практически все возможные варианты написания адресов рабочей почты, которые встречаются в природе. Если вам по какой-то причине не подходит табличка, вы можете воспользоваться её заменителем.
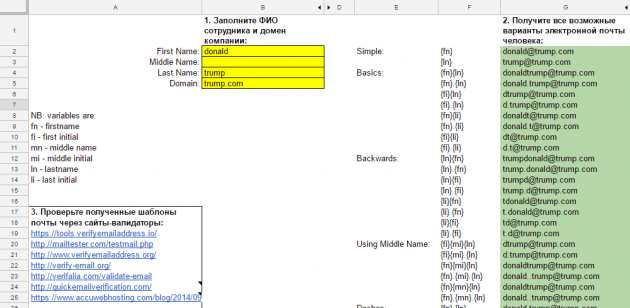
Вбейте в таблицу ФИ или ФИО человека и домен компании, где он работает. В правой части таблицы вы увидите список всех возможных адресов его почты. Скопируйте список и вставьте в текстовый файл.
Теперь вам нужен сервис массовой проверки валидности email. Таких сервисов на рынке меньше, и чаще всего они платные или условно-бесплатные. Мне повезло найти не совсем удобный, но щедрый сервис Quickemailverification.com. Он позволяет массово проверять до 100 адресов в день бесплатно, мне хватает. Заведите аккаунт на таком сервисе и загрузите список адресов. Сервис проверит все гипотетические варианты и вычислит один валидный адрес.
Следующий трюк — поиск адресов с помощью расширения для Google Chrome от упомянутого ранее сервиса Hunter.io.

Этот инструмент работает просто, быстро и эффективно:
- Зайдите на сайт компании, в LinkedIn-профиль нужного человека или в поисковую выдачу LinkedIn, отфильтрованную по заданным вами параметрам.
- Нажмите на иконку расширения с оранжевой лисой.
- Получите все найденные адреса во всплывающем окне на этой же странице.
Иногда почта компании располагается на отдельном домене, который не является сайтом, а при попытке зайти на него перебрасывает вас на основной сайт или показывает ошибку. Например, почта некоторых сотрудников социальной сети «ВКонтакте» находится на домене corp.vk.com, который перебрасывает на адрес vk.com/team. Чтобы вычислить адреса на домене corp.vk.com, зайдите на главную Hunter.io и впишите адрес в поисковую форму.
К сожалению, сервис даёт бесплатно ограниченное число поисков: 150 проверок на три недели. Если ваша деятельность включает ежедневный поиск множества адресов, придётся использовать платный тариф за несколько десятков долларов в месяц. Но это того стоит.
Ещё один платный, но очень классный сервис — Voilanorbert.com. Он умеет не только находить почту по имени и домену компании, но и даёт отличные инструменты для хранения и сортировки контактов, а также позволяет автоматизировать и шаблонизировать работу с холодными письмами. После регистрации в сервисе вы получите 50 бесплатных проверок, за остальные придётся заплатить.
Вообще, западная индустрия пестрит стартапами в области автоматизации email-продаж и работы с лидами. Сервисы получают многомиллионные инвестиции, превращаются из простых email-чекеров в монструозные CRM, покупают друг друга и делают, в принципе, одно и то же, но каждый со своей фишкой.
Я не буду подробно останавливаться на разборе таких сервисов, так как большинство из них ориентированы на американский рынок, но если ваши продажи тоже ориентированы на американский рынок, то вот вам ссылки для самостоятельного изучения:
- Findthatlead.com — аналог Hunter.io.
- Sellhack.com — ещё один подобный инструмент, но более навороченный (кстати, с классным блогом о продажах с помощью писем).
- Fullcontact.com — менеджер бизнес-контактов с базой данных контактов ЛПР.
- Conspire.com — сервис, который просканирует вашу базу знакомств и подскажет, кто может вас познакомить с нужным человеком.
- Toutapp.com — сервис для автоматизации и шаблонизации отправки холодных писем, который показывает, что происходит с письмом после отправки: открыл ли адресат письмо и кликнул ли в нём на ссылку.
- Yesware.com — ещё один.
- Persistiq.com — мощный инструмент для автоматизации email-продаж, умеет превращать список имён и один шаблон письма в кучу персонализированных писем и много что ещё.
- Rapportive.com — поглощённый LinkedIn сервис, который интегрирует LinkedIn с Gmail-почтой. С его помощью можно вычислять валидность адресов. Нужно сгенерировать список адресов почты, вставить их в адресную строку Gmail и, наводя курсор на каждый вариант, ждать всплывающего окошечка от Rapportive, подтверждающего, что такой адрес существует и имеет привязанный аккаунт в LinkedIn. Странный способ, но в западном вебе он часто рекомендуется.
- Streak.com — CRM для холодных продаж письмами со встроенным email-трекером. Работает как расширение функциональности Gmail-почты.
Что ещё?
В завершение обзора затрону несколько запасных методов поиска, которые не всегда приводят к успеху, но тоже могут быть полезны.
- Найти почту, на которую зарегистрирован домен компании. Выберите при помощи Google любой whois-сервис и вбейте в него домен компании. Сервис покажет, на какую почту зарегистрирован этот домен. Вполне возможно, это почта владельца.
- Спросить у рядового сотрудника компании почту руководителя. Если в компании нет внутренних инструкций на нераспространение такой информации, вам вполне могут ответить.
- Спросить у другого поставщика или подрядчика, который уже работает с нужной вам компанией и знает её руководство.
- Купить доступ к базам данных с контактами ЛПР.
- Проследить по анонсам компании, на каких конференциях выступают её представители, и познакомиться лично.
- Можно просто позвонить в компанию и пригласить к телефону нужного человека. Если назвать секретарю его имя и отчество и говорить уверенным тоном, при этом ничего не продавая и не предлагая, вас могут соединить. Но чаще всего пригласят написать на почту для спама.
Вот, пожалуй, и все известные нам рабочие методы поиска почты. Знаете другие? Поделитесь в комментариях!
Что на самом деле происходит, когда пользователь вбивает в браузер адрес google.com
Эта статья является попыткой ответа на старый вопрос для собеседований: «Что же случается, когда вы печатаете в адресной строке google.com и нажимаете Enter?» Мы попробуем разобраться в этом максимально подробно, не пропуская ни одной детали.
Примечание: публикация основана на содержании репозитория What happens when…
Представленный контент изобилует большим количеством терминов, в переводе некоторых из них могут присутствовать различные неточности. Если вы обнаружите какую-то ошибку в нашем переводе — напишите личным сообщением, и мы всё исправим.
Мы перенесли перевод в репозиторий GitHub и отправили Pull Request автору материала — оставляйте свои правки к тексту, и вместе мы сможем значительно улучшить его.
1. Нажата клавиша «g»
Далее в статье содержится информация о работе физической клавиатуры и прерывания операционной системы. Но много чего происходит и помимо этого — когда вы нажимаете клавишу «g», браузер получает событие и запускается механизм автоподстановки. В зависимости от алгоритма браузера и его режима (включена ли функция «инкогнито») в выпадающем окне под строкой URL пользователю будет предложено определённое количество вариантов для автоподстановки.
Большинство алгоритмов автоподстановки ранжируют рекомендации в зависимости от истории поиска и оставленных закладках. Некоторые браузеры (например, Rockmelt) даже предлагают профили друзей на Facebook. Когда пользователь планирует напечатать в адресной строке «google.com», ничего из вышеперечисленного не играет роли, но тем не менее выполнится большое количество кода, а рекомендации будут обновляться с каждой новой напечатанной буквой. Возможно, браузер предложит перейти на google.com, до того, как пользователь вобьёт адрес целиком.
2. Клавиша «enter» нажата до конца
В качестве некой нулевой точки можно выбрать момент, когда клавиша Enter на клавиатуре нажата до конца и находится в нижнем положении. В этой точке замыкается электрическая цепь этой клавиши и небольшое количество тока отправляется по электросхеме клавиатуры, которая сканирует состояние каждого переключателя клавиши и конвертирует сигнал в целочисленный код клавиши (в данном случае — 13). Затем контроллер клавиатуры конвертирует код клавиши для передачи его компьютеру. Как правило, сейчас передача происходит через USB или Bluetooth, а раньше клавиатура подключалась к компьютеру с помощью коннекторов PS/2 или ADB.
В случае USB-клавиатуры:
- Для работы USB-контуру клавиатуры требуется 5 вольт питания, которые поступают через USB-контроллер на компьютере.
- Сгенерированный код клавиши хранится в регистре внутренней памяти клавиатуры, который называется «конечной точкой» (endpoint).
- USB-контроллер компьютера опрашивает эту конечную точку каждые 10 микросекунд и получает хранящийся там код клавиши.
- Затем это значение поступает в USB SIE (Serial Interface Engine) для конвертации в один или более USB-пакетов, которые формируются по низкоуровневому протоколу USB.
- Эти пакеты затем пересылаются с помощью различных электрических сигналов через D+ и D- контакты с максимальной скоростью 1,5 Мб/сек — поскольку HID-устройства (Human Interface Device) всегда были «низкоскоростными».
- Этот последовательный сигнал далее декодируется в USB-контроллере компьютера и интерпретируется универсальным драйвером HID-устройства (клавиатуры). Затем значение кода клавиши передаётся на «железный» уровень абстракции операционной системы.
В случае виртуальной клавиатуры (тачскрин):
- Когда пользователь прикладывает палец к современному ёмкостному тач-экрану, небольшое количество тока передаётся к пальцу. Это замыкает цепь через электростатическое поле проводящего слоя и создаёт падение напряжения в этой точке экрана. Экранный контроллер затем инициирует прерывание, сообщающее координату «клика».
- Затем мобильная ОС оповещает текущее открытое приложение о событии клика в одном из GUI-элементов (в этом случае — кнопках виртуальной клавиатуры).
- Виртуальная клавиатура вызывает программное прерывание для отправки сообщения «клавиша нажата» обратно в ОС.
- Это прерывание оповещает текущее открытое приложение о возникновении события «нажатия клавиши».
2.1 Возникло прерывание [не для USB-клавиатур]
Клавиатура отправляет сигналы в свою «линию запросов прерываний» (IRQ), которая затем сопоставляется с «вектором прерывания» (целое число) контроллером прерываний. Процессор использует «таблицу дескрипторов прерываний» (IDT) для сопоставления векторов прерываний с функциями («обработчики прерываний») ядра. Когда появляется прерывание, процессор (CPU) обновляет IDT вектором прерывания и запускает соответствующий обработчик. Таким образом, в дело вступает ядро.
2.2 (На Windows) Сообщение WM_KEYDOWN отправлено приложению
HID передаёт событие нажатой клавиши драйверу
KBDHID.sys, который конвертирует его в скан-код (scancode). В данном конкретном случае скан-код — VK_RETURN (0x0D). Драйвер KDBHID.sys связывается с драйвером KBDCLASS.sys (драйвер классов клавиатуры). Он отвечает за безопасную обработку всего ввода с клавиатуры. В дальнейшем этот драйвер вызывает Win32K.sys (после возможной передачи сообщения через установленные сторонние клавиатурные фильтры). Все это происходит в режиме ядра.Win32K.sys определяет, какое окно активно в данный момент, с помощью функции GetForegroundWindow(). Этот API обеспечивает обработку окна адресной строки в браузере. Затем главный «насос сообщений» Windows вызывает SendMessage(hWnd, WM_KEYDOWN, VK_RETURN, lParam). lParam — это битовая маска, которая указывает на дальнейшую информацию о нажатии клавиши: счётчик повторов (в этом случае 0), актуальный скан-код (может зависеть от OEM, но VK_RETURN обычно не зависит от этого), информацию о том, были ли нажаты дополнительные клавиши (например, Alt, Shift, Ctrl — в нашем случае не были) и некоторые другие данные.
В API Windows есть функция SendMessage, которая помещает сообщение в очередь для конкретного обработчика окон (hWnd). После этого для обработки всех сообщений очереди вызывается главная функция обработки сообщений (WindowProc), присвоенная обработчику hWnd.
Окно (hWnd), активное в данный момент, представляет из себя контрол обработки и в этом случае у WindowsProc есть обработчик для сообщений WM_KEYDOWN. Этот код изучает третий параметр, который поступил в SendMessage (wParam) и, поскольку это VK_RETURN, понимает, что пользователь нажал клавишу ENTER.
2.3 (В OS X) Событие NSEVent KeyDown отправлено приложению
Сигнал прерывания активирует событие прерывания в драйвере I/O Kit клавиатуры. Драйвер переводит сигнал в код клавиатуры, который затем передаётся процессу OS X под названием
WindowServer. В результате, WindowsServer передаёт событие любому подходящему (активному или «слушающему») приложению через Mach-порт, в котором событие помещается в очередь. Затем события могут быть прочитаны из этой очереди потоками с достаточными привилегиями, чтобы вызывать функцию mach_ipc_dispatch. Чаще всего это происходит и обрабатывается с помощью основного цикла NSApplication через NSEvent в NSEventype KeyDown.2.4 (В GNU/Linux) Сервер Xorg слушает клавиатурные коды
В случае графического X server, для получения нажатия клавиши будет использован общий драйвер событий
evdev. Переназначение клавиатурных кодов скан-кодам осуществляется с помощью специальных правил и карт X Server. Когда маппинг скан-кода нажатой клавиши завершён, X server посылает символ в window manager (DWM, metacity, i3), который затем отправляет его в активное окно. Графический API окна, получившего символ, печатает соответствующий символ шрифта в нужном поле.3. Парсинг URL
Теперь у браузера есть следующая информация об URL:
Protocol «HTTP»
Использовать «Hyper Text Transfer Protocol»Resource «/»
Показать главную (индексную) страницу
3.1 Это URL или поисковый запрос?
Когда пользователь не вводит протокол или доменное имя, то браузер «скармливает» то, что человек напечатал, поисковой машине, установленной по умолчанию. Часто к URL добавляется специальный текст, который позволяет поисковой машине понять, что информация передана из URL-строки определённого браузера.
3.2 Список проверки HSTS
- Браузер проверяет список «предзагруженных HSTS (HTTP Strict Transport Security)». Это список сайтов, которые требуют, чтобы к ним обращались только по HTTPS.
- Если нужный сайт есть в этом списке, то браузер отправляет ему запрос через HTTPS вместо HTTP. В противном случае, начальный запрос посылается по HTTP. (При этом сайт может использовать политику HSTS, но не находиться в списке HSTS — в таком случае на первый запрос по HTTP будет отправлен ответ о том, что необходимо отправлять запросы по HTTPS. Однако это может сделать пользователя уязвимым к downgrade-атакам — чтобы этого избежать, в браузеры и включают список HSTS).
3.3 Конвертация не-ASCII Unicode символов в название хоста
- Браузер проверяет имя хоста на наличие символов, отличных от
a-z,A-Z,0-9,-, или.. - В случае доменного имени google.com никаких проблем не будет, но если бы домен содержал не-ASCII символы, то браузер бы применил кодировку Punycode для этой части URL.
4. Определение DNS
- Браузер проверяет наличие домена в своём кэше.
- Если домена там нет, то браузер вызывает библиотечную функцию
gethostbyname(отличается в разных ОС) для поиска нужного адреса. - Прежде, чем искать домен по DNS
gethostbynameпытается найти нужный адрес в файлеhosts(его расположение отличается в разных ОС). - Если домен нигде не закэширован и отсутствует в файле
hosts,gethostbynameотправляет запрос к сетевому DNS-серверу. Как правило, это локальный роутер или DNS-сервер интернет-провайдера. - Если DNS-сервер находится в той же подсети, то ARP-запрос отправляется этому серверу.
- Если DNS-сервер находится в другой подсети, то ARP-запрос отправляется на IP-адрес шлюза по умолчанию (default gateway).
4.1 Процесс отправки ARP-запроса
Для того, чтобы отправить широковещательный ARP-запрос необходимо отыскать целевой IP-адрес, а также знать MAC-адрес интерфейса, который будет использоваться для отправки ARP-запроса.
Кэш ARP проверяется для каждого целевого IP-адреса — если адрес есть в кэше, то библиотечная функция возвращает результат: Target IP = MAC.
Если же записи в кэше нет:
- Проверяется таблица маршрутизации — это делается для того, чтобы узнать, есть ли искомый IP-адрес в какой-либо из подсетей локальной таблицы. Если он там, то запрос посылается с помощью интерфейса, связанного с этой подсетью. Если адрес в таблице не обнаружен, то используется интерфейс подсети шлюза по умолчанию.
- Определяется MAC-адрес выбранного сетевого интерфейса.
- Отправляется ARP-запрос (второй уровень стека):
ARP-запрос:
Sender MAC: interface:mac:address:hereSender IP: interface.ip.goes.hereTarget MAC: FF:FF:FF:FF:FF:FF (Broadcast)Target IP: target.ip.goes.here
В зависимости от того, какое «железо» расположено между компьютером и роутером (маршрутизатором):
Прямое соединение:
- Если компьютер напрямую подключён к роутеру, то это устройство отправляет ARP-ответ (ARP Reply).
Между ними концентратор (Хаб):
- Если компьютер подключён к сетевому концентратору, то этот хаб отправляет широковещательный ARP-запрос со всех своих портов. Если роутер подключён по тому же «проводу», то отправит ARP-ответ.
Между ними коммутатор (свитч):
- Если компьютер соединён с сетевым коммутатором, то этот свитч проверит локальную CAM/MAC-таблицу, чтобы узнать, какой порт в ней имеет нужный MAC-адрес. Если нужного адреса в таблице нет, то он заново отправит широковещательный ARP-запрос по всем портам.
- Если в таблице есть нужная запись, то свитч отправит ARP-запрос на порт с искомым MAC-адресом.
- Если роутер «на одной линии» со свитчем, то он ответит (ARP Reply).
ARP-ответ:
Sender MAC: target:mac:address:hereSender IP: target.ip.goes.hereTarget MAC: interface:mac:address:hereTarget IP: interface.ip.goes.here
Теперь у сетевой библиотеки есть IP-адрес либо DNS-сервера либо шлюза по умолчанию, который можно использовать для разрешения доменного имени:
- Порт 53 открывается для отправки UDP-запроса к DNS-серверу (если размер ответа слишком велик, будет использован TCP).
- Если локальный или на стороне провайдера DNS-сервер «не знает» нужный адрес, то запрашивается рекурсивный поиск, который проходит по списку вышестоящих DNS-серверов, пока не будет найдена SOA-запись, а затем возвращается результат.
5. Открытие сокета
Когда браузер получает IP-адрес конечного сервера, то он берёт эту информацию и данные об используемом порте из URL (80 порт для HTTP, 443 для HTTPS) и осуществляет вызов функции
socket системной библиотеки и запрашивает поток TCP сокета — AF_INET и SOCK_STREAM.- Этот запрос сначала проходит через транспортный уровень, где собирается TCP-сегмент. В заголовок добавляется порт назначения, исходный порт выбирается из динамического пула ядра (
ip_local_port_rangeв Linux). - Получившийся сегмент отправляется на сетевой уровень, на котором добавляется дополнительный IP-заголовок. Также включаются IP-адрес сервера назначения и адрес текущей машины — после этого пакет сформирован.
- Пакет передаётся на канальный уровень. Добавляется заголовок кадра, включающий MAC-адрес сетевой карты (NIC) компьютера, а также MAC-адрес шлюза (локального роутера). Как и на предыдущих этапах, если ядру ничего не известно о MAC-адресе шлюза, то для его нахождения отправляется широковещательный ARP-запрос.
На этой точке пакет готов к передаче через:
В случае интернет-соединения большинства частных пользователей или небольших компаний пакет будет отправлен с компьютера, через локальную сеть, а затем через модем (
MOdulator/DEModulator), который транслирует цифровые единицы и нули в аналоговый сигнал, подходящий для передачи по телефонной линии, кабелю или беспроводным телефонным соединениям. На другой стороне соединения расположен другой модем, который конвертирует аналоговый сигнал в цифровые данные и передаёт их следующему сетевому узлу, где происходит дальнейший анализ данных об отправителе и получателе.В конечном итоге пакет доберётся до маршрутизатора, управляющего локальной подсетью. Затем он продолжит путешествовать от одного роутера к другому, пока не доберётся до сервера назначения. Каждый маршрутизатор на пути будет извлекать адрес назначения из IP-заголовка и отправлять пакет на следующий хоп. Значение поля TTL (time to live) в IP-заголовке будет каждый раз уменьшаться после прохождения каждого роутера. Если значение поля TTL достигнет нуля, пакет будет отброшен (это произойдёт также если у маршрутизатора не будет места в текущей очереди — например, из-за перегрузки сети).
Во время TCP-соединения происходит множество подобных запросов и ответов.
5.1 Жизненный цикл TCP-соединения
a. Клиент выбирает номер начальной последовательности (ISN) и отправляет пакет серверу с установленным битом SYN для открытия соединения.
b. Сервер получает пакет с битом SYN и, если готов к установлению соединения, то:
- Выбирает собственный номер начальной последовательности;
- Устанавливает SYN-бит, чтобы сообщить о выборе начальной последовательности;
- Копирует ISN клиента +1 в поле ACK и добавляет ACK-флаг для обозначения подтверждения получения первого пакета.
c. Клиент подтверждает соединение путём отправки пакета:
- Увеличивает номер своей начальной последовательности;
- Увеличивает номер подтверждения получения;
- Устанавливает поле ACK.
d. Данные передаются следующим образом:
- Когда одна сторона отправляет N байтов, то увеличивает значение поля SEQ на это число.
- Когда вторая сторона подтверждает получение этого пакета (или цепочки пакетов), она отправляет пакет ACK, в котором значение поля ACK равняется последней полученной последовательности.
e. Закрытие соединения:
- Сторона, которая хочет закрыть соединение, отправляет пакет FIN;
- Другая сторона подтверждает FIN (с помощью ACK) и отправляет собственный FIN-пакет;
- Инициатор прекращения соединения подтверждает получение FIN отправкой собственного ACK.
6. TLS handshake
- Клиентский компьютер отправляет сообщение
ClientHelloсерверу со своей версией протокола TLS, списком поддерживаемых алгоритмов шифрования и методов компрессии данных. - Сервер отвечает клиенту сообщением
ServerHello, содержащим версию TLS, выбранный метод шифрования, выбранные методы компрессии и публичный сертификат сервиса, подписанный центром сертификации. Сертификат содержит публичный ключ, который будет использоваться клиентом для шифрования оставшейся части процедуры «рукопожатия» (handshake), пока не будет согласован симметричный ключ. - Клиент подтверждает сертификат сервера с помощью своего списка центров сертификации. Если сертификат подписан центром из списка, то серверу можно доверять, и клиент генерирует строку псевдослучайных байтов и шифрует её с помощью публичного ключа сервера. Эти случайные байты могут быть использованы для определения симметричного ключа.
- Сервер расшифровывает случайные байты с помощью своего секретного ключа и использует эти байты для генерации своей копии симметричного мастер-ключа.
- Клиент отправляет серверу сообщение
Finished, шифруя хеш передачи с помощью симметричного ключа. - Сервер генерирует собственный хеш, а затем расшифровывает полученный от клиента хеш, чтобы проверить, совпадёт ли он с собственным. Если совпадение обнаружено, сервер отправляет клиенту собственный ответ
Finished, также зашифрованный симметричным ключом. - После этого TLS-сессия передаёт данные приложения (HTTP), зашифрованные с помощью подтверждённого симметричного ключа.
7. Протокол HTTP
Если используемый браузер был создан Google, то вместо отправки HTTP-запроса для получения страницы, он отправит запрос, чтобы попытаться «договориться» с сервером об «апгрейде» протокола с HTTP до SPDY («спиди»).
Если клиент использует HTTP-протокол и не поддерживает SPDY, то отправляет серверу запрос следующей формы:
GET / HTTP/1.1Host: google.comConnection: close[другие заголовки]
где [другие заголовки] — это серия пар «ключ: значение», разбитых переносом строки. (Здесь предполагается, что в использованном браузере нет никаких ошибок, нарушающих спецификацию HTTP. Также предполагается, что браузер использует HTTP/1.1, в противном случае он может не включать заголовок Host в запрос и версия, отданная в ответ на GET-запрос может быть HTTP/1.0 или HTTP/0.9).
HTTP/1.1 определяет опцию закрытия соединения («close») для отправителя — с её помощью происходит уведомление о закрытии соединения после завершения ответа. К примеру:
Connection: close
Приложения
HTTP/1.1, которые не поддерживают постоянные соединения, обязаны включать опцию «close» в каждое сообщение.После отправки запроса и заголовков, браузер отправляет серверу единичную пустую строку, сигнализируя о том, что содержимое сообщения закончилось.
Сервер отвечает специальным кодом, который обозначает статус запроса и включает ответ следующей формы:
200 OK[заголовки ответа]
После этого посылается пустая строка, а затем оставшийся контент HTML-страницы www.google.com. Сервер может затем закрыть соединение, или, если того требуют отправленные клиентом заголовки, сохранять соединение открытым для его использования следующими запросами.
Если HTTP-заголовки отправленные веб-браузером включают информацию, которой серверу достаточно для определения версии файла, закэшированного в браузере и этот файл не менялся со времени последнего запроса, то ответ может принять следующую форму:
304 Not Modified[заголовки ответа]
и, соответственно, клиенту не посылается никакого контента, вместо этого браузер «достаёт» HTML из кэша.
После разбора HTML, браузер (и сервер) повторяет процесс загрузки для каждого ресурса (изображения, стили, скрипты, favicon.ico и так далее), на который ссылается HTML-страница, но при этом изменяется адрес каждого запроса c GET / HTTP/1.1 на GET /$(относительный URL ресурса www.google.com) HTTP/1.1.
Если HTML ссылается на ресурс, размещённый на домене, отличном от google.com, то браузер возвращается к шагам, включающим разрешение доменного имени, а затем заново проходит процесс до текущего состояния, но уже для другого домена. Заголовок Host в запросе вместо google.com будет установлен на нужное доменное имя.
7.1 Обработка HTTP-запросов на сервере
HTTPD (HTTP Daemon) является одним из инструментов обработки запросов/ответов на стороне сервера. Наиболее популярные HTTPD-серверы это Apache или Nginx для Linux и IIS для Windows.— HTTPD (HTTP Daemon) получает запрос.
— Сервер разбирает запрос по следующим параметрам:
- Метод HTTP-запроса (
GET,POST,HEAD,PUTилиDELETE). В случае URL-адреса, который пользователь напечатал в строке браузера, мы имеем дело с GET-запросом. - Домен. В нашем случае — google.com.
- Запрашиваемые пути/страницы, в нашем случае —
/(нет запрошенных путей,/— это путь по умолчанию).
— Сервер проверяет существование виртуального хоста, который соответствует google.com.
— Сервер проверяет, что google.com может принимать GET-запросы.
— Сервер проверяет, имеет ли клиент право использовать этот метод (на основе IP-адреса, аутентификации и прочее).
— Если на сервере установлен модуль перезаписи (mod_rewrite для Apache или URL Rewrite для IIS), то он сопоставляет запрос с одним из сконфигурированных правил. Если находится совпадающее правило, то сервер использует его, чтобы переписать запрос.
— Сервер находит контент, который соответствует запросу, в нашем случае он изучит индексный файл.
— Далее сервер разбирает («парсит») файл с помощью обработчика. Если Google работает на PHP, то сервер использует PHP для интерпретации индексного файла и направляет результат клиенту.
8. За кулисами браузера
Задача браузера заключается в том, чтобы показывать пользователю выбранные им веб-ресурсы, запрашивая их с сервера и отображая в окне просмотра. Как правило такими ресурсами являются HTML-документы, но это может быть и PDF, изображения или контент другого типа. Расположение ресурсов определяется с помощью URL.
Способ, который браузер использует для интерпретации и отображения HTML-файлов описан в спецификациях HTML и CSS. Эти документы разработаны и поддерживаются консорциумом W3C (World Wide Wib Consortium), которая занимается стандартизацией веба.
Интерфейсы браузеров сильно похожи между собой. У них есть большое количество одинаковых элементов:
- Адресная строка, куда вставляются URL-адреса;
- Кнопки возврата на предыдущую и следующую страницу;
- Возможность создания закладок;
- Кнопки обновления страницы (рефреш) и остановки загрузки текущих документов;
- Кнопка «домой», возвращающая пользователя на домашнюю страницу.
Высокоуровневая структура браузера
Браузер включает следующие компоненты:
- Пользовательский интерфейс: В него входит адресная строка, кнопки продвижения вперёд/назад, меню закладок и так далее. Сюда относятся все элементы, кроме окна, в котором собственно отображается веб-страница.
- «Движок» браузера: Распределяет действия между движком рендеринга и интерфейсом пользователя.
- «Движок» рендеринга: Отвечает за отображение запрашиваемого контента. К примеру, если запрашивается HTML, то «движок» разбирает код HTML и CSS, а затем отображает полученный контент на экране.
- Сетевая часть: с помощью сетевых функций браузер обрабатывает вызовы, вроде HTTP-запросов, с применением различных реализаций для разных платформ.
- Бэкенд интерфейса (UI): Используется для отрисовки базовых виджетов, вроде комбо-боксов и окон.
- Интерпретатор JavaScript: Используется для парсинга и выполнения JavaScript-кода.
- Хранилище данных: Браузеру может понадобиться локально хранить некоторые данные (например, cookie). Кроме того, браузеры поддерживают различные механизмы хранения, такие как
localStorage,IndexedDB,WebSQLиFileSystem.
9. Парсинг HTML
Движок рендеринга начинает получать содержимое запрашиваемого документа от сетевого механизма браузера. Как правило, контент поступает кусками по 8Кб. Главной задачей HTML-парсера является разбор разметки в специальное дерево.
Получающееся на выходе дерево («parse tree») — это дерево DOM-элементов и узлов атрибутов. DOM — сокращение от Document Object Model. Это модель объектного представления HTML-документа и интерфейс для взаимодействия HTML-элементов с «внешним миром» (например, JavaScript-кодом). Корнем дерева является объект «Документ».
Алгоритм разбора
HTML-нельзя «распарсить» с помощью обычных анализаторов (нисходящих или восходящих). Тому есть несколько причин:
- Прощающая почти что угодно природа языка;
- Тот факт, что браузеры обладают известной толерантностью к ошибкам и поддерживают популярные ошибки в HTML.
- Процесс парсинга может заходить в тупик. В других языках код, который требуется разобрать, не меняется в процессе анализа, в то время как в HTML с помощью динамического кода (например, скриптовые элементы, содержащие вызовы
document.write()) могут добавляться дополнительные токены, в результате чего сам процесс парсинга модифицирует вывод.
Невозможность использования привычных технологий парсинга приводит к тому, что разработчики браузеров реализуют собственные механизмы разбора HTML. Алгоритм парсинга подробно описан в спецификации HTML5.
Алгоритм состоит из двух этапов: токенизации и создания дерева.
Действия после завершения парсинга
После этого браузер начинает подгружать внешние ресурсы, связанные со страницей (стили, изображения, скрипты и так далее).
На этом этапе браузер помечает документ, как интерактивный и начинает разбирать скрипты, находящиеся в «отложенном» состоянии: то есть те из них, что должны быть исполнены после парсинга. После этого статус документа устанавливается в состояние «complete» и инициируется событие загрузки («load»).
Важный момент: ошибки «Invalid Syntax» при разборе не может быть, поскольку браузеры исправляют любой «невалидный» контент и продолжают работу.
10. Интерпретация CSS
- Во время разбора браузер парсит CSS-файлы, содержимое тегов
<style>и атрибутов «style» c помощью «лексической и синтаксической грамматики CSS». - Каждый CSS-файл разбирается в объект
StyleSheet, каждый из таких объектов содержит правила CSS с селекторами и объектами в соответствии с грамматикой CSS. - Парсер CSS может быть как восходящим, так и нисходящим.
11. Рендеринг страниц
- Путём перебора DOM-узлов и вычисления для каждого узла значений CSS-стилей создаётся «Дерево рендера» (Render Tree или Frame Tree).
- Вычисляется предпочтительная ширина каждого узла в нижней части дерева — для этого суммируются значения предпочтительной ширины дочерних узлов, а также горизонтальные поля, границы и отступы узлов.
- Вычисляется реальная ширина каждого узла сверху-вниз (доступная ширина каждого узла выделяется его потомкам).
- Вычисляется высота каждого узла снизу-вверх — для этого применяется перенос текста и суммируются значения полей, высоты, отступов и границ потомков.
- Вычисляются координаты каждого узла (с использованием ранее полученной информации).
- Если элементы плавающие или спозиционированы абсолютно или относительно, предпринимаются более сложные действия. Более подробно они описаны здесь и здесь.
- Создаются слои для описания того, какие части страницы можно анимировать без необходимости повторного растрирования. Каждый объект (фрейма или рендера) присваивается слою.
- Для каждого слоя на странице выделяются текстуры.
- Объекты (рендеры/фреймы) каждого слоя перебираются и для соответствующих слоёв выполняются команды отрисовки. Растрирование может осуществляться процессором или возможна отрисовка на графическом процессоре (GPU) через D2D/SkiaGL.
- Все вышеперечисленные шаги могут требовать повторного использования значений, сохранённых с последнего рендеринга страницы, такая инкрементальная работа требует меньше затрат.
- Слои страницы отправляются процессу-компоновщику, где они комбинируются со слоями для другого видимого контента (интерфейс браузера, iframe-элементы, addon-панели).
- Вычисляются финальные позиции слоёв и через Direct3D/OpenGL отдаются композитные команды. Командные буферы GPU освобождаются для асинхронного рендеринга и фрейм отправляется для отображения на экран.
12. Рендеринг GPU
- Во время процесса рендеринга уровни графических вычислений могут использовать процессор компьютера или графический процессор (GPU).
- Во втором случае уровни графического программного обеспечения делят задачу на множество частей, что позволяет использовать параллелизм GPU для вычисления плавающей точки, которое требуется для процесса рендеринга.
13. Вызванное пользователем и пост-рендеринговое исполнение
После завершения рендеринга, браузер исполняет JavaScript-код в результате срабатывания некоего часового механизма (так работают дудлы на странице Google) или в результате действий пользователя (ввод поискового запроса в строку и получение рекомендаций в ответ). Также могут срабатывать плагины вроде Flash или Java (но не в рассматриваемом примере с домашней страницей Google). Скрипты могут потребовать обработки дополнительных сетевых запросов, изменять страницу или её шаблон, что приведёт к следующему этапу рендеринга и отрисовки.
Как определить IP-адрес компьютера клиента

От автора: Идею для этого урока я взял из комментариев пользователей ресурса http://webformyself.com/. В частности, интересовал такой вопрос: «Как определить IP-адрес компьютера?». Попробуем разобраться, как это можно сделать, и заодно узнаем еще несколько вещей, которые, безусловно, могут пригодиться Вам в создании веб-приложений.
Время ролика: 19:50
Ссылка для скачивания исходников: Скачать одним архивом
Ссылка для скачивания всего архива (видео+исходники): Скачать одним архивом. Размер: 33.1 mb.

Бесплатный курс по PHP программированию
Освойте курс и узнайте, как создать динамичный сайт на PHP и MySQL с полного нуля, используя модель MVC
В курсе 39 уроков | 15 часов видео | исходники для каждого урока
Получить курс сейчас!Итак сразу скажу, для того чтобы понять как определить IP-адрес, много кода писать не придется ибо все уже написано до нас. Нам же остается просто знать, как это использовать. Под «этим» в данном случае понимается суперглобальный массив $_SERVER, в который интерпретатор PHP помещает переменные, полученные от сервера. О том, что такое массив, я подробно рассказываю и показываю в уроке по созданию галереи. Вкратце можно сказать, что массив — это своеобразная большая переменная, в которой можно хранить обычные переменные. Переменных в глобальном массиве $_SERVER довольно много. Мы же сегодня поговорим лишь о некоторых из них. Эти переменные, кстати, еще называются также элементами массива. И первые два элемента, о которых мы поговорим — это элементы, благодаря которым можно получить имя сервера, на котором выполняется скрипт.
1. Имя сервера
Создадим страницу (у меня это index.php) и напишем в нее следующий код:
<?php echo $_SERVER[‘SERVER_NAME’]; ?>
<?php echo $_SERVER[‘SERVER_NAME’]; ?> |
Здесь мы выводим на экран элемент массива $_SERVER по имени SERVER_NAME, в котором как раз и содержится информация о сервере. Если Вы тестируете скрипт на локальном сервере, то в качестве имени сервера получим — «localhost».
Аналогичный результат можно получить при обращении к элементу HTTP_HOST:
<?php echo $_SERVER[‘HTTP_HOST’]; ?>
<?php echo $_SERVER[‘HTTP_HOST’]; ?> |
Где может пригодиться использование этих элементов массива $_SERVER?. Допустим, у нас есть сайт на домене http://mydomen.ru. Соответственно, если на этом сайте используются абсолютные ссылки, то мы столкнемся с определенными трудностями при переносе сайта на новый домен, к примеру, http://newdomen.ru. Нам придется менять все абсолютные ссылки. Вот здесь нам как раз и могут пригодиться эти элементы.
2. Откуда пришел пользователь
Часто нам необходимо узнать с какой именно страницы к нам попал пользователь. В этом нам может помочь элемент по имени HTTP_REFERER. В этом элементе как раз и содержится адрес страницы, с которой пользователь попал на страницу, на которой мы вызываем элемент HTTP_REFERER. Переход, соответственно, должен происходить по ссылке. Создадим еще одну страницу, например test.php, и в ней пропишем ссылку на страницу index.php. На странице index.php пропишем код:
<?php echo $_SERVER[‘HTTP_REFERER’]; ?>
<?php echo $_SERVER[‘HTTP_REFERER’]; ?> |
Теперь попробуем перейти по ссылке. В своем случае я получу такой адрес страницы — http://localhost/arr_server/test.php (обе страницы у меня в каталоге arr_server, а сам скрипт тестируется на локальном сервере).
3. Информация о клиенте
Если нам необходимо собирать статистическую информация, например, пользователи с какими браузерами посещают наш сайт, то мы можем использовать для этих целей элемент HTTP_USER_AGENT:
<?php echo $_SERVER[‘HTTP_USER_AGENT’]; ?>
<?php echo $_SERVER[‘HTTP_USER_AGENT’]; ?> |
Бесплатный курс по PHP программированию
Освойте курс и узнайте, как создать динамичный сайт на PHP и MySQL с полного нуля, используя модель MVC
В курсе 39 уроков | 15 часов видео | исходники для каждого урока
Получить курс сейчас!В результате на экран в моем случае будет выведена строка — «Mozilla/5.0 (Windows; U; Windows NT 5.1; ru; rv:1.9.2.15) Gecko/20110303 AskTbPTV2/3.9.1.14019 Firefox/3.6.15″. Из нее можно узнать, что я использую браузер Firefox версии 3.6.15. Также можно узнать, что версия моей операционной системы — Windows XP — об этом говорит эта часть строки — Windows NT 5.1.
Определение IP-адреса клиента
А теперь собственно то, для чего мы и затеяли данный урок — определение IP-адреса компьютера пользователя, заполнявшего нашу форму. Информация об этом адресе содержится в элементе REMOTE_ADDR:
<?php echo $_SERVER[‘REMOTE_ADDR’]; ?>
<?php echo $_SERVER[‘REMOTE_ADDR’]; ?> |
Если Вы тестирует скрипт на локальном сервере, то получите такой IP-адрес — 127.0.0.1. Если тестируете в сети — получите IP-адрес, под которым зашли в сеть. Как же нам передать IP-адрес клиента, который заполнял форму? Сам он его, конечно же, вряд ли вводить будет, поэтому нам остается определить этот адрес при помощи элемента REMOTE_ADDR массива $_SERVER и скрытно от клиента отослать его. Сделать это можно несколькими способами. Мы будем использовать скрытое поле формы. Создадим простую форму на странице test.php:
<form method=»post» action=»index.php»> <input type=»text» name=»name» /> <input type=»submit» name=»submit» /> </form>
<form method=»post» action=»index.php»> <input type=»text» name=»name» /> <input type=»submit» name=»submit» /> </form> |
Данные из этой формы будут передаваться методом POST, в качестве обработчика данных мы указали файл index.php (детально обо всем этом я рассказываю в мини-курсе по созданию полноценной формы обратной связи). На странице index.php давайте будем принимать эти данные и выводить их:
<?php if($_POST[‘submit’]){ echo ‘Введено имя: ‘ .$_POST[‘name’]. ‘<br />’; echo ‘<a href=»‘ .$_SERVER[‘HTTP_REFERER’]. ‘»>Назад</a>’; } ?>
<?php if($_POST[‘submit’]){ echo ‘Введено имя: ‘ .$_POST[‘name’]. ‘<br />’; echo ‘<a href=»‘ .$_SERVER[‘HTTP_REFERER’]. ‘»>Назад</a>’; } ?> |
Здесь мы проверили, была ли нажата кнопка формы и, если она нажата, мы выводим то, что получили в качестве имени. А ниже мы прописали ссылку на ту страницу, откуда пришли, т.е., на страницу с формой. Об условиях, глобальном массиве $_POST и прочих вещах, которые мы только что использовали, я также детально рассказывал в мини-курсе по созданию формы обратной связи. Мы все делаем максимально упрощенно, без особых проверок, поскольку целью урока является простая передача IP-адреса клиента и не больше.
Итак, имя мы получаем. Теперь осталось передать скрытно от пользователя его IP-адрес. Для этого допишем на странице с формой еще одно поле, типом которого укажем hidden (т.е., скрытое), а в качестве его значения укажем элемент REMOTE_ADDR:
<form method=»post» action=»index.php»> <input type=»text» name=»name» /> <input type=»hidden» name=»ip» value=»<?php echo $_SERVER[‘REMOTE_ADDR’]; ?>» /> <input type=»submit» name=»submit» /> </form>
<form method=»post» action=»index.php»> <input type=»text» name=»name» /> <input type=»hidden» name=»ip» value=»<?php echo $_SERVER[‘REMOTE_ADDR’]; ?>» /> <input type=»submit» name=»submit» /> </form> |
Если мы сейчас обновим страницу с формой, то ничего не изменится… но если мы посмотрим исходный код этой страницы, то увидим следующее:
<form method=»post» action=»index.php»> <input type=»text» name=»name» /> <input type=»hidden» name=»ip» value=»127.0.0.1″ /> <input type=»submit» name=»submit» /> </form>
<form method=»post» action=»index.php»> <input type=»text» name=»name» /> <input type=»hidden» name=»ip» value=»127.0.0.1″ /> <input type=»submit» name=»submit» /> </form> |
Интерпретатор PHP в качестве значения скрытого поля прописал IP-адрес клиента, который и будет отправлен на страницу index.php, и этот адрес будет находиться в переменной ip глобального массива $_POST. Осталось дописать вывод в файле index.php:
<?php if($_POST[‘submit’]){ echo ‘Введено имя: ‘ .$_POST[‘name’]. ‘<br />’; echo ‘IP пользователя: ‘ .$_POST[‘ip’]. ‘<br />’; echo ‘<a href=»‘ .$_SERVER[‘HTTP_REFERER’]. ‘»>Назад</a>’; } ?>
<?php if($_POST[‘submit’]){ echo ‘Введено имя: ‘ .$_POST[‘name’]. ‘<br />’; echo ‘IP пользователя: ‘ .$_POST[‘ip’]. ‘<br />’; echo ‘<a href=»‘ .$_SERVER[‘HTTP_REFERER’]. ‘»>Назад</a>’; } ?> |
Вот, в принципе, и все. Вот так вот просто при помощи элементов массива $_SERVER мы можем получить массу служебной информации, которую затем можем использовать в своих веб-приложениях. Мы рассмотрели только пять элементов массива $_SERVER, на самом деле их, как уже говорилось выше, гораздо больше и без них часто сложно организовать функционирование достаточно серьезного проекта.
На этом, урок по определению IP-адреса компьютера окончен. До новых встреч!
Бесплатный курс по PHP программированию
Освойте курс и узнайте, как создать динамичный сайт на PHP и MySQL с полного нуля, используя модель MVC
В курсе 39 уроков | 15 часов видео | исходники для каждого урока
Получить курс сейчас!
Хотите узнать, что необходимо для создания сайта?
Посмотрите видео и узнайте пошаговый план по созданию сайта с нуля!
Смотретьсмешивать, но не взбалтывать / Сервер Молл corporate blog / Habr
В очередном «конспекте админа» остановимся на еще одной фундаментальной вещи – механизме разрешения имен в IP-сетях. Кстати, знаете почему в доменной сети nslookup на все запросы может отвечать одним адресом? И это при том, что сайты исправно открываются. Если задумались – добро пожаловать под кат..
Для преобразования имени в IP-адрес в операционных системах Windows традиционно используются две технологии – NetBIOS и более известная DNS.
NetBIOS (Network Basic Input/Output System) – технология, пришедшая к нам в 1983 году. Она обеспечивает такие возможности как:
регистрация и проверка сетевых имен;
установление и разрыв соединений;
связь с гарантированной доставкой информации;
связь с негарантированной доставкой информации;
- поддержка управления и мониторинга драйвера и сетевой карты.
В рамках этого материала нас интересует только первый пункт. При использовании NetBIOS имя ограниченно 16 байтами – 15 символов и спец-символ, обозначающий тип узла. Процедура преобразования имени в адрес реализована широковещательными запросами.
Небольшая памятка о сути широковещательных запросов.
Широковещательным называют такой запрос, который предназначен для получения всеми компьютерами сети. Для этого запрос посылается на специальный IP или MAC-адрес для работы на третьем или втором уровне модели OSI.
Для работы на втором уровне используется MAC-адрес FF:FF:FF:FF:FF:FF, для третьего уровня в IP-сетях адрес, являющимся последним адресом в подсети. Например, в подсети 192.168.0.0/24 этим адресом будет 192.168.0.255
Интересная особенность в том, что можно привязывать имя не к хосту, а к сервису. Например, к имени пользователя для отправки сообщений через net send.
Естественно, постоянно рассылать широковещательные запросы не эффективно, поэтому существует кэш NetBIOS – временная таблица соответствий имен и IP-адреса. Таблица находится в оперативной памяти, по умолчанию количество записей ограничено шестнадцатью, а срок жизни каждой – десять минут. Посмотреть его содержимое можно с помощью команды nbtstat -c, а очистить – nbtstat -R.
Пример работы кэша для разрешения имени узла «хр».
Что происходило при этом с точки зрения сниффера.
В крупных сетях из-за ограничения на количество записей и срока их жизни кэш уже не спасает. Да и большое количество широковещательных запросов запросто может замедлить быстродействие сети. Для того чтобы этого избежать, используется сервер WINS (Windows Internet Name Service). Адрес сервера администратор может прописать сам либо его назначит DHCP сервер. Компьютеры при включении регистрируют NetBIOS имена на сервере, к нему же обращаются и для разрешения имен.
В сетях с *nix серверами можно использовать пакет программ Samba в качестве замены WINS. Для этого достаточно добавить в конфигурационный файл строку «wins support = yes». Подробнее – в документации.
В отсутствие службы WINS можно использовать файл lmhosts, в который система будет «заглядывать» при невозможности разрешить имя другими способами. В современных системах по умолчанию он отсутствует. Есть только файл-пример-документация по адресу %systemroot%\System32\drivers\etc\lmhost.sam. Если lmhosts понадобится, его можно создать рядом с lmhosts.sam.
Сейчас технология NetBIOS не на слуху, но по умолчанию она включена. Стоит иметь это ввиду при диагностике проблем.
DNS (Domain Name System) – распределенная иерархическая система для получения информации о доменах. Пожалуй, самая известная из перечисленных. Механизм работы предельно простой, рассмотрим его на примере определения IP адреса хоста www.google.com:
если в кэше резолвера адреса нет, система запрашивает указанный в сетевых настройках интерфейса сервер DNS;
сервер DNS смотрит запись у себя, и если у него нет информации даже о домене google.com – отправляет запрос на вышестоящие сервера DNS, например, провайдерские. Если вышестоящих серверов нет, запрос отправляется сразу на один из 13 (не считая реплик) корневых серверов, на которых есть информация о тех, кто держит верхнюю зону. В нашем случае – com.
после этого наш сервер спрашивает об имени www.google.com сервер, который держит зону com;
- затем сервер, который держит зону google.com уже выдает ответ.
Наглядная схема прохождения запроса DNS.
Разумеется, DNS не ограничивается просто соответствием «имя – адрес»: здесь поддерживаются разные виды записей, описанные стандартами RFC. Оставлю их список соответствующим статьям.
Сам сервис DNS работает на UDP порту 53, в редких случаях используя TCP.
DNS переключается на TCP с тем же 53 портом для переноса DNS-зоны и для запросов размером более 512 байт. Последнее встречается довольно редко, но на собеседованиях потенциальные работодатели любят задавать вопрос про порт DNS с хитрым прищуром.
Также как и у NetBIOS, у DNS существует кэш, чтобы не обращаться к серверу при каждом запросе, и файл, где можно вручную сопоставить адрес и имя – известный многим %Systemroot%\System32\drivers\etc\hosts.
В отличие от кэша NetBIOS в кэш DNS сразу считывается содержимое файла hosts. Помимо этого, интересное отличие заключается в том, что в кэше DNS хранятся не только соответствия доменов и адресов, но и неудачные попытки разрешения имен. Посмотреть содержимое кэша можно в командной строке с помощью команды ipconfig /displaydns, а очистить – ipconfig /flushdns. За работу кэша отвечает служба dnscache.
На скриншоте видно, что сразу после чистки кэша в него добавляется содержимое файла hosts, и иллюстрировано наличие в кэше неудачных попыток распознавания имени.
При попытке разрешения имени обычно используются сервера DNS, настроенные на сетевом адаптере. Но в ряде случаев, например, при подключении к корпоративному VPN, нужно отправлять запросы разрешения определенных имен на другие DNS. Для этого в системах Windows, начиная с 7\2008 R2, появилась таблица политик разрешения имен (Name Resolution Policy Table, NRPT). Настраивается она через реестр, в разделе HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Microsoft\Windows NT\DnsClient\DnsPolicyConfig или групповыми политиками.
Настройка политики разрешения имен через GPO.
При наличии в одной сети нескольких технологий, где еще и каждая – со своим кэшем, важен порядок их использования.
Операционная система Windows пытается разрешить имена в следующем порядке:
проверяет, не совпадает ли имя с локальным именем хоста;
смотрит в кэш DNS распознавателя;
если в кэше соответствие не найдено, идет запрос к серверу DNS;
если имя хоста «плоское», например, «servername», система обращается к кэшу NetBIOS. Имена более 16 символов или составные, например «servername.domainname.ru» – NetBIOS не используется;
если не получилось разрешить имя на этом этапе – происходит запрос на сервер WINS;
если постигла неудача, то система пытается получить имя широковещательным запросом, но не более трех попыток;
- последняя попытка – система ищет записи в локальном файле lmhosts.
Для удобства проиллюстрирую алгоритм блок-схемой:
Алгоритм разрешения имен в Windows.
То есть, при запуске команды ping server.domain.com NetBIOS и его широковещательные запросы использоваться не будут, отработает только DNS, а вот с коротким именем процедура пойдет по длинному пути. В этом легко убедиться, запустив простейший скрипт:
@echo off
echo %time%
ping hjfskhfjkshjfkshjkhfdsjk.com
echo %time%
ping xyz
echo %time%
pauseВыполнение второго пинга происходит на несколько секунд дольше, а сниффер покажет широковещательные запросы.
Сниффер показывает запросы DNS для длинного имени и широковещательные запросы NetBIOS для короткого.
Отдельного упоминания заслуживают доменные сети – в них запрос с коротким именем отработает чуть по-другому.
Active Directory тесно интегрирована с DNS и не функционирует без него. Каждому компьютеру домена создается запись в DNS, и компьютер получает полное имя (FQDN — fully qualified domain name) вида name.subdomain.domain.com.
Для того чтоб при работе не нужно было вводить FQDN, система автоматически добавляет часть имени домена к хосту при различных операциях – будь то регистрация в DNS или получение IP адреса по имени. Сначала добавляется имя домена целиком, потом следующая часть до точки.
При попытке запуска команды ping servername система проделает следующее:
При этом к составным именам типа www.google.com суффиксы по умолчанию не добавляются. Это поведение настраивается групповыми политиками.
Настройка добавления суффиксов DNS через групповые политики.
Настраивать DNS суффиксы можно также групповыми политиками или на вкладке DNS дополнительных свойств TCP\IP сетевого адаптера. Просмотреть текущие настройки удобно командой ipconfig /all.
Суффиксы DNS и их порядок в выводе ipconfig /all.
Однако утилита nslookup работает немного по-другому: она добавляет суффиксы в том числе и к длинным именам. Посмотреть, что именно происходит внутри nslookup можно, включив диагностический режим директивой debug или расширенный диагностический режим директивой dc2. Для примера приведу вывод команды для разрешения имени ya.ru:
nslookup -dc2 ya.ru
------------
Got answer:
HEADER:
opcode = QUERY, id = 1, rcode = NOERROR
header flags: response, want recursion, recursion avail.
questions = 1, answers = 1, authority records = 0, additional = 0
QUESTIONS:
4.4.8.8.in-addr.arpa, type = PTR, class = IN
ANSWERS:
-> 4.4.8.8.in-addr.arpa
name = google-public-dns-b.google.com
ttl = 86399 (23 hours 59 mins 59 secs)
------------
╤хЁтхЁ: google-public-dns-b.google.com
Address: 8.8.4.4
------------
Got answer:
HEADER:
opcode = QUERY, id = 2, rcode = NOERROR
header flags: response, want recursion, recursion avail.
questions = 1, answers = 1, authority records = 0, additional = 0
QUESTIONS:
ya.ru.subdomain.domain.com, type = A, class = IN
ANSWERS:
-> ya.ru.subdomain.domain.com
internet address = 66.96.162.92
ttl = 599 (9 mins 59 secs)
------------
Не заслуживающий доверия ответ:
------------
Got answer:
HEADER:
opcode = QUERY, id = 3, rcode = NOERROR
header flags: response, want recursion, recursion avail.
questions = 1, answers = 0, authority records = 1, additional = 0
QUESTIONS:
ya.ru.subdomain.domain.com, type = AAAA, class = IN
AUTHORITY RECORDS:
-> domain.com
ttl = 19 (19 secs)
primary name server = ns-2022.awsdns-60.co.uk
responsible mail addr = awsdns-hostmaster.amazon.com
serial = 1
refresh = 7200 (2 hours)
retry = 900 (15 mins)
expire = 1209600 (14 days)
default TTL = 86400 (1 day)
------------
╚ь : ya.ru.subdomain.domain.com
Address: 66.96.162.92Из-за суффиксов утилита nslookup выдала совсем не тот результат, который выдаст например пинг:
ping ya.ru -n 1
Обмен пакетами с ya.ru [87.250.250.242] с 32 байтами данных:
Ответ от 87.250.250.242: число байт=32 время=170мс TTL=52Это поведение иногда приводит в замешательство начинающих системных администраторов.
Лично сталкивался с такой проблемой: в домене nslookup выдавал всегда один и тот же адрес в ответ на любой запрос. Как оказалось, при создании домена кто-то выбрал имя domain.com.ru, не принадлежащее организации в «большом интернете». Nslookup добавляла ко всем запросам имя домена, затем родительский суффикс – com.ru. Домен com.ru в интернете имеет wildcard запись, то есть любой запрос вида XXX.com.ru будет успешно разрешен. Поэтому nslookup и выдавал на все вопросы один ответ. Чтобы избежать подобных проблем, не рекомендуется использовать для именования не принадлежащие вам домены.
При диагностике стоит помнить, что утилита nslookup работает напрямую с сервером DNS, в отличие от обычного распознавателя имен. Если вывести компьютер из домена и расположить его в другой подсети, nslookup будет показывать, что всё в порядке, но без настройки суффиксов DNS система не сможет обращаться к серверам по коротким именам.
Отсюда частые вопросы – почему ping не работает, а nslookup работает.
В плане поиска и устранения ошибок разрешения имен могу порекомендовать не бояться использовать инструмент для анализа трафика – сниффер. С ним весь трафик как на ладони, и если добавляются лишние суффиксы, то это отразится в запросах DNS. Если запросов DNS и NetBIOS нет, некорректный ответ берется из кэша.
Если же нет возможности запустить сниффер, рекомендую сравнить вывод ping и nslookup, очистить кэши, проверить работу с другим сервером DNS.
Кстати, если вспомните любопытные DNS-курьезы из собственной практики – поделитесь в комментариях.
Как найти человека по адресу электронной почты?
Содержание:
Думаю, Вам знакома ситуация, когда Вы в очередной раз просматриваете свою электронную почту и с удивлением обнаруживаете письмо от неизвестного отправителя. И не важно, что написано в теме письма: «Вы выиграли миллион» или «Приглашение на собеседование», перед тем, как открыть письмо и отправить ответ, важно правильно идентифицировать человека (или робота), связанного с этой электронной почтой.
В этой статье я перечислила 6 советов, которые можно использовать, чтобы пробить человека по адресу электронной почты.
Как найти человека по электронной почте?
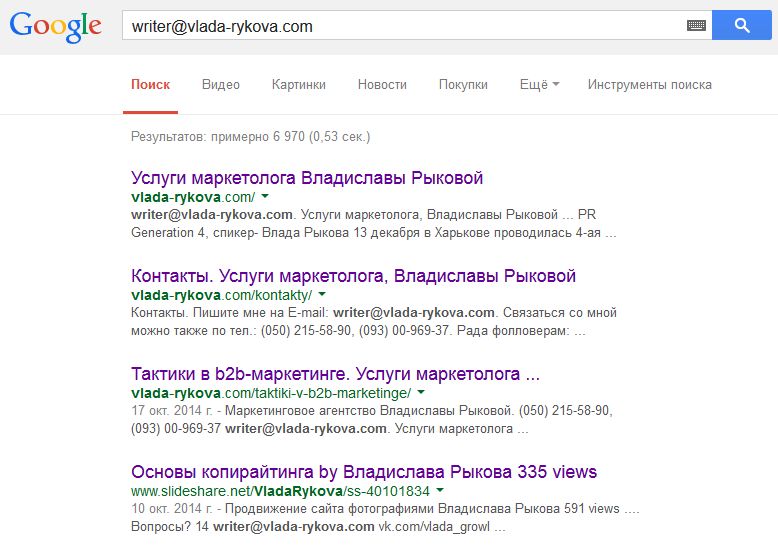
1. Гуглите!
Самый простой и верный способ узнать о человеке – просто поискать его в Google. Как говорится, жизнь нужно прожить так, чтобы об этом знал Google, но главное чтоб об этом не узнал YouTube! Т.е. копируем e-mail адрес и вставляем его в строку поиска. Наслаждаемся результатами. Если вы не нашли информацию об этом адресе в Google, то перейдите к советам, описанным ниже.
2. Определяем спам и мошенничество
Если Вы подозреваете, что отправитель спамщик или мошенник, то об этом могут свидетельствовать следующие признаки:
- Адрес электронной почты отправителя не соответствует адресу сайта организации. Например, сайт vlada-rykova.com, а письмо отправлено с [email protected].
- Письмо отправлено c бесплатного почтового сервиса.
- Ваше имя либо не используется в теме письма, либо искажено.
- Письмо содержит информацию о срочном ответе адресату.
- Письмо содержит ссылку на сайт, на который нужно обязательно перейти. Эта ссылка может быть подделана или похожа на соответствующий адрес какого-либо официального сайта, где Вас просят ввести такую личную информацию, как имя пользователя, пароли и пр.
3. Используйте Facebook, чтобы подтвердить личность человека
Для того, чтобы зарегистрироваться в социальной сети, нужно оставить свой адрес электронной почты. Таким образом, существует большая вероятность, что вы сможете найти (пробить) владельца e-mail через Facebook. Просто скопируйте и вставьте адрес электронной почты отправителя в строке поиска Facebook.
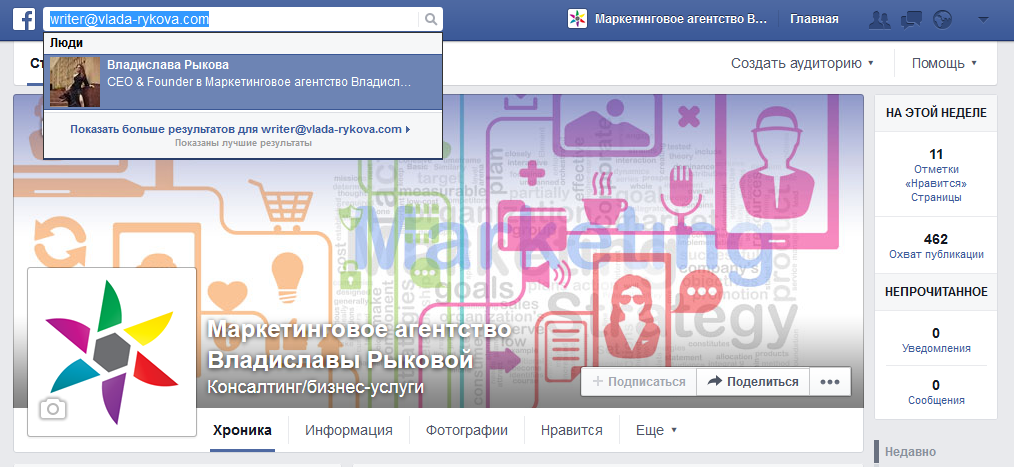
4. Поиск с помощью специальных сервисов
Помимо Facebook есть еще огромное количество социальных сетей, в которых можно проверить e-mail-адрес отправителя, но поверьте, на это Вы потратите очень-очень много времени. Чтоб как-то автоматизировать процесс, предлагаю воспользоваться специальными сервисами. Они помогут вам в поисках на популярных соц. сетях и блогах по имени, адресу электронной почты, никнейму, номеру телефона.
1. Pipl – зарубежный сервис, поэтому данные по адресам из СНГ ищутся не всегда корректно.
2. Spokeo – платный сервис. Стоимость полугодовой подписки 3,95 долл. в месяц.
3. EmailSherlock — бесплатные сервис, который проверяет привязку email к социальным сетям, но и он не всегда корректно ищет.
4. PeekYou – находит людей из разных соц сетей по имени, email, номеру телефона, местоположению.
5. Vebidoo – немецкий сервис поиска людей.
6. Spysee – японский сервис поиска людей (закрылся)
7. ZabaSearch — американский сервис поиска людей (поиск по номеру телефона или имени).
8. WhitePages.com — еще один американский сервис поиска людей (ищет по имени, номеру телефона и физическому адресу проживания).
9. AddressSearch.com — сервис по поиску людей в США. Есть возможность искать только по email или адресу проживания.
10. CriminalSearches.com — интересный сервис, заточенный на поиск информации о людях в США, которые совершали какие-то преступления (поиск к сожалению только по имени).
11. FindPeopleSearch — еще один сервис под Америку. Поиск по имени и email. Кроме стандартного функционала Вы также можете отправить им электронное письмо, удалить их информацию и настроить уведомления для получения дополнительной информации о человеке.
12. MyLife — поиск исключительно по людям из США и только по имени и городу, к тому же, чтоб получить результаты поиска, нужно быть обязательно зарегистрированным пользователем.
13. BeenVerified — международный платный сервис. Ищет по email, имени, номеру телефона, адресу проживания.
14. Lullar — поиск человека по имени, email или нику, заточен в первую очередь для поиска людей в социальных сетях: Facebook, Google Plus, Twitter, YouTube, Instagram, Pinteres и др. Как по мне, то поиск не очень качественный.
15. Infobel — международный поиск людей по компаниям в которых они работают. Т.е. сначала выбираем страну, потом вводим имя и город, потом получаем информацию, в какой компании работает данный человек. Ну и качество поиска для стран СНГ оставляет желать лучшего.
16. Yasni.com — очень качественный поиск людей по имени, нику, профессии с русским интерфейсом.
17. PersonLookUp — неудобный для пользователя интерфейс этого сервиса в целом позволяет искать людей по разным параметрам: имени, адресу, email. Качество поиска также мягко говоря «не очень».
Также есть специальные расширения для браузеров, которые помогут Вам в поисках людей в социальных сетях по email, например, Rapportive (для Firefox и Chrome). Cервис работает только для Gmail.
Воспользуйтесь также специальным мобильным приложением для быстрого поиска человека по номеру телефона — Intelius (для Android) и Charlie (для iOS).
5. Как вычислить электронную почту по IP в email? Узнаем IP-адрес e-mail отправителя
Каждое электронное письмо содержит в себе информацию, которую не видно на первый взгляд. Это IP-адрес отправителя, по которому Вы можете узнать страну и город, откуда к Вам пришло это письмо, т.е. можно пробить местоположение по почтовому ящику.
Чтобы найти IP-адрес письма полученного на Mail.ru, следуйте следующему алгоритму:
- Откройте письмо отправителя.
- Нажмите кнопку «Еще» и в выпадающем списке нажмите «Служебные заголовки».
- Воспользовавшись поиском по странице (Ctrl+F) найдите «Received: from». То, что будет в квадратных скобках и есть интересующий нас IP-адрес.
Если Вы пользуетесь почтовым сервисом от Яндекса, то проделайте следующее:
- Открываем письмо отправителя.
- Нажимаем на ссылку «Подробнее» и дальше выбираем «Свойства письма».
- По аналогии с предыдущим почтовым сервисом ищем «Received: from». В квадратных скобках — IP-адрес отправителя.
P.S. Сейчас Яндекс сам подтягивает информацию о человеке в почтовый интерфейс. Подробнее можно почитать здесь.
Для Gmail мануал такой:
- Открываем письмо.
- Нажимаем в правом верхнем углу на стрелочку и в выпадающем меню выбираем «Показать оригинал».
- Последний пункт идентичный 2 предыдущим почтовым сервисам. Ищем «Received: from».
Узнать IP отправителя на rambler.ru
- Открываем письмо.
- Нажимаем на кнопку «Другие действия», выбираем «Код письма».
- Ищем строку: Received: from [134.1.1.0], где вместо 134.1.1.0 будет IP-адрес отправителя.
Чтобы узнать точное географическое положение полученного IP-адреса, используйте один из сервисов: Speed-Tester.info или 2ip.ru.
Обращаю внимание, что данные могут быть далеко не точные, особенно, если отправитель пользуется бесплатными почтовыми сервисами. Но такой метод прекрасно работает в b2b-маркетинге, когда Вам нужно знать из какого региона к Вам обратился потенциальный покупатель и сразу предлагать ему товар или услугу в зависимости от локации.
Читайте также: Лидогенерация в b2b-маркетинге или Лид-скоринг.
6. Ищем человека по фотографии
Если Вы нашли фотографию человека любым из перечисленных выше способов, Вы сможете найти больше информации о нем в Интернете использовав такие инструменты, как Google Images или Яндекс.Картинки. Для этого загрузите фотографию с помощью иконки фотоаппарата справа в строке поиска и нажмите «найти». Поисковая система выдаст Вам ряд сайтов, на которых использовалась эта картинка.
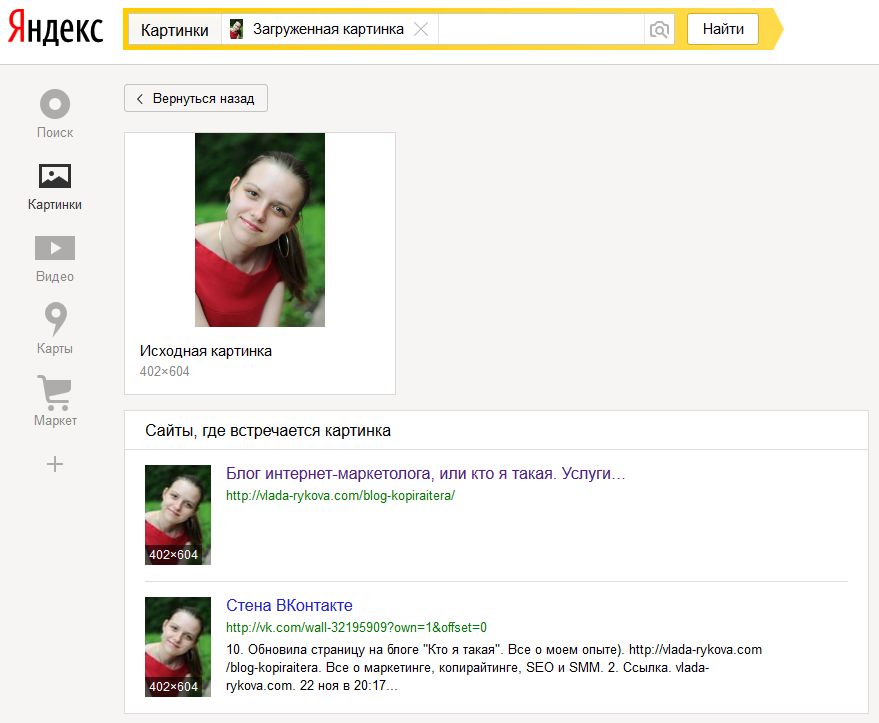
Как найти человека в Интернете? Что можно вычислить по email?
Актуальной темой для обсуждений является поиск людей в интернете. Как это сделать и какой информацией необходимо обладать для этого, мы расскажем в этой статье.
Как найти человека по адресу проживания бесплатно в интернете?
Сразу же следует заметить, что чем больше информации у вас есть о человеке, тем быстрее и легче будет его найти. Вам могут пригодиться следующие данные:
- Телефон, email и другая контактная информация;
- Адрес проживания и прописки;
- Фотографии;
- Номер паспорта, ИНН;
- Профили в соцсетях.
Базы данных. Они являются одним из самых распространенных видов поиска, однако надежность полученной информации – сомнительна. Имейте в виду, что под такими поисковыми сервисами часто скрываются мошенники, поэтому если вас просят перевести куда-либо деньги, отправить смс, лучше откажитесь от их услуг. Вы можете искать людей по следующим базам данным:
- На данном портале можно найти человека, зная фамилию, имя, отчество, адрес проживания (Украина).
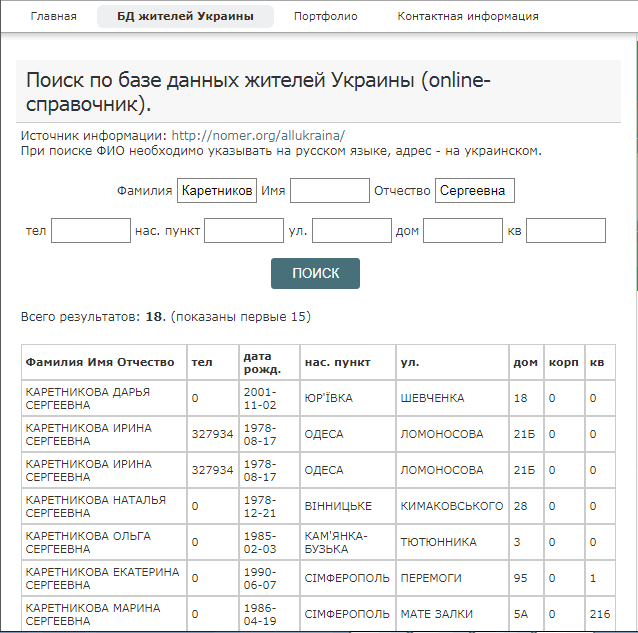
- Более специализированные поисковики Вы можете найти, перейдя по данной ссылке (Украина).
- Поиск по нику в базах данных социальных сетей.
Общедоступная информация. К ней относится вся публикуемая Вами информация на различных сайтах. В основном это касается соцсетей, поскольку именно там указывается информация, по которой можно найти человека в интернете. Также к общедоступной информации относятся справочные бюро, телефонные и адресные книги, ГИБДД (только Россия).
ФМС (Россия) – это довольно легкий способ найти человека по прописке. Для получения информации, нужно:
- прийти в местную миграционную службу;
- предоставить свой паспорт;
- заполнить заявление, указав информацию о человеке;
- получить результаты поисков.
Полиция. Обращение в полицию – еще один вариант поиска человека, однако нет никаких гарантий, что служащий скажет нужную Вам информацию. Это уже зависит от связей и его расположения к Вам.
Услуги частного детектива. Данный вид поиска является наиболее эффективным, поскольку детектив может выяснить необходимую информацию о человеке, а также проследить за ним в случае необходимости. Следует заметить, что его услуги не всем могут оказаться по карману.
Как найти человека по адресу прописки в интернете?
Это возможно осуществить, сделав электронный запрос в интернете, введя в него паспортные данные искомого человека. А также с помощью данного сервиса (поддерживает практически все страны СНГ).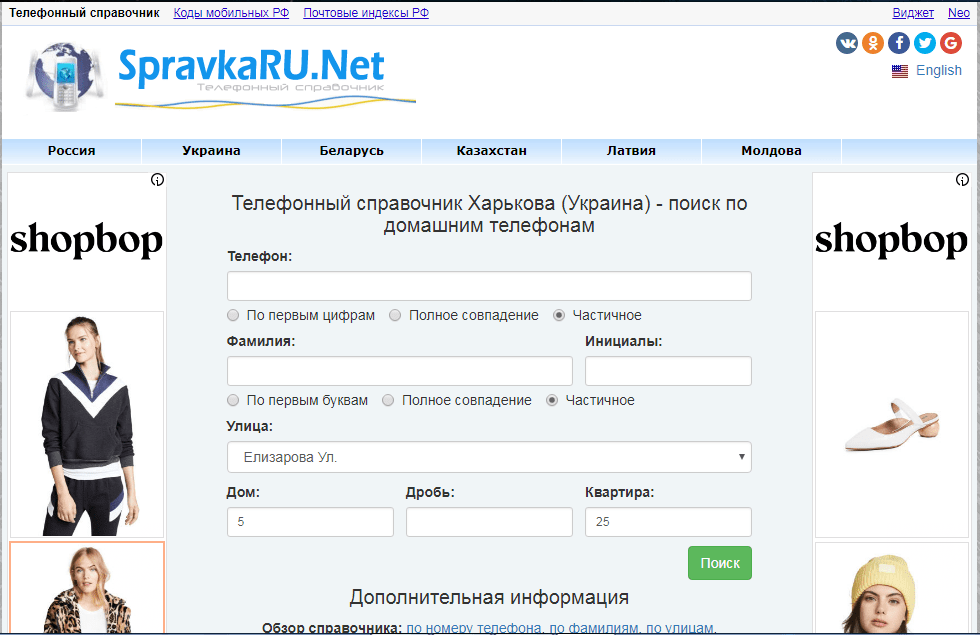
Как найти человека во Вконтакте или других соцсетях?
Поиск в соцсетях – один из самых удобных и легких видов поиска. Большинство людей сейчас спокойно предоставляют такую информацию как: ФИО, дата рождения, место проживания, семейное положение, номер телефона и т.д. Также большинство ресурсов поддерживает функцию геоданных. То есть, публикуя какое-либо фото, человек указывает свое точное местонахождение, что помогает его найти.
Одними из самых популярных соцсетей являются: Вконтакте, Твиттер, Фейсбук, Инстаграм. Рассмотрим каждую соцсеть подробнее, а про Фейсбук смотрите выше.
- Вконтакте. Для того чтобы найти человека в ВКонтакте, нужно выполнить следующие действия:
- Зарегистрироваться или авторизоваться, если у Вас уже есть аккаунт.
- Перейти во вкладку «поиск людей». Слева отобразиться окошко с параметрами поиска, где нужно ввести всю информацию, которой Вы обладаете о человеке. Следует заметить, что некоторые регистрируются под фейковыми (выдуманными) именами. Это может несколько усложнить поиск.
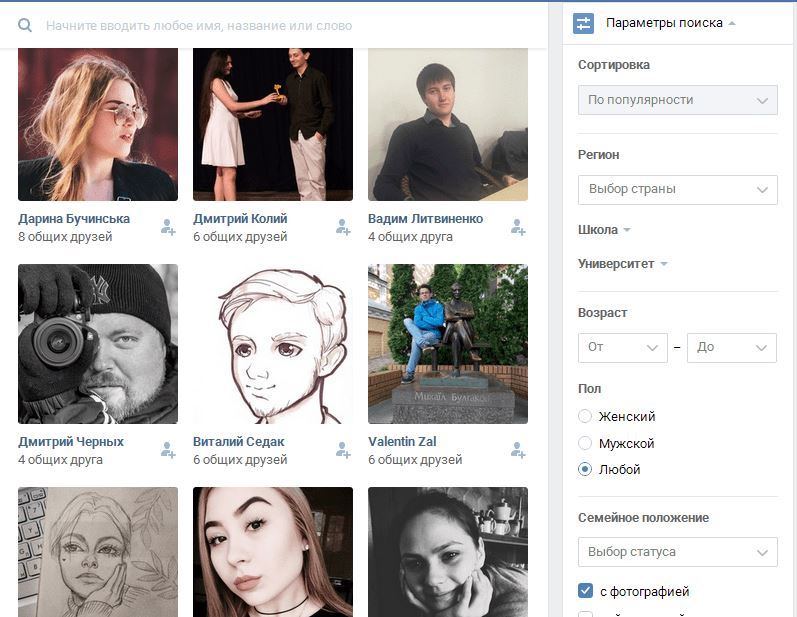
- Еще один способ поиска в ВКонтакте – поиск через общих друзей. Сеть предлагает варианты возможных знакомых, основываясь на персональных данных и ваших друзьях.
- Также можно поместить объявление о поиске человека в местных группах города. Возможно, кто-то из его родственников и друзей поможет с ним связаться.
- Найти человека в твиттере и инстаграм можно, зная имя пользователя, под которым он зарегистрирован. Для этого нужно в поисковике ввести имя и посмотреть результаты поиска.
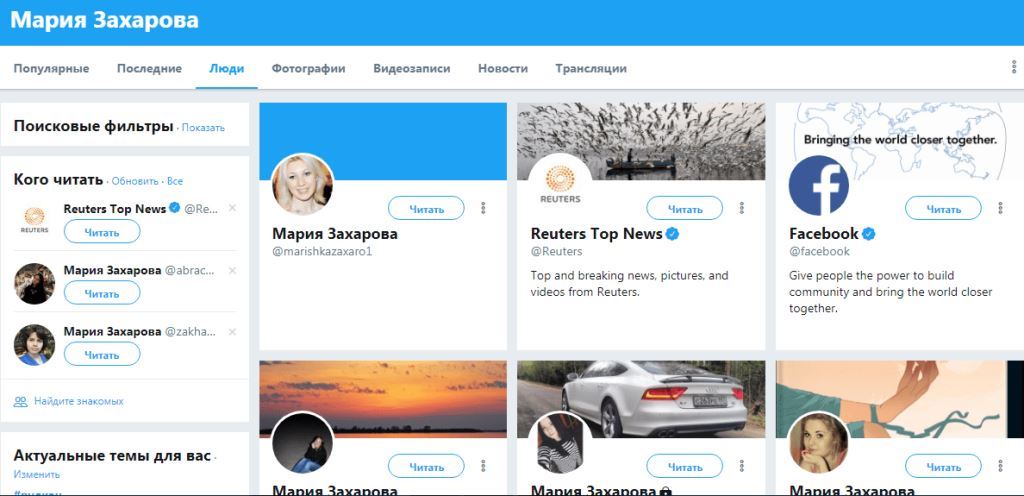
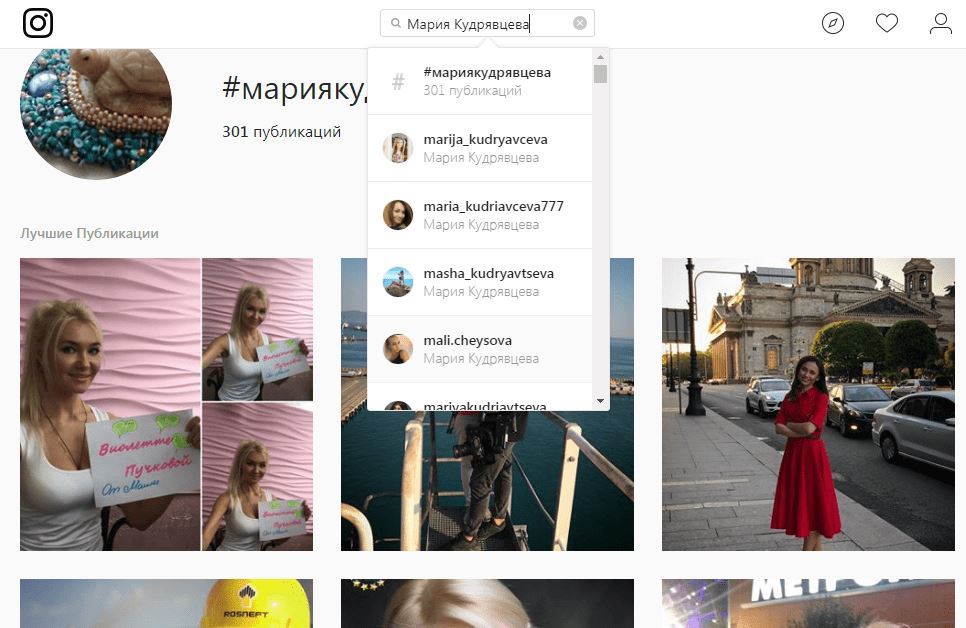
Как «пробить» организации и компании по email?
- Вбить email в поисковик и посмотреть результаты поиска;
- Воспользоваться сервисом poiskmail.com.
- В поиске людей Google контакты, Facebook, Мой Мир вбить адрес электронной почты и получить данные аккаунта с именем и фамилией.
Что делать, если не могу найти человека?
В таком случае откройте страницы Ваших общих знакомых и «в друзьях» попытайтесь найти этого человека по фото. Имейте в виду, что он может быть зарегистрирован под фейковым именем, если же это девушка, она могла сменить фамилию, выйдя замуж.
Как понять, что Вы столкнулись с мошенником в социальных сетях?
Как же отличить мошенников? Ниже представлены признаки, которые помогут его выявить:
- Если к Вам добавился «в друзья» человек, у которого очень мало информации и фотографий на странице, при этом он с Вами очень общителен.
- Новый знакомый проявляет странный интерес к работе, количеству времени, которое Вы проводите на ней, интересуется, куда ходите по вечерам и уезжаете ли на выходных.
- Много общих интересов и совпадений.
- Расспрашивает Вас о жизни, ничего не рассказывая о себе взамен.
- Много общих друзей, однако, никто о нем не знает.
Ответственность и наказание
Приступая к поискам человека, не забывайте о действующей Конституции. Согласно закону любой человек имеет право на частную жизнь и неразглашение персональной информации. За нарушение личной неприкосновенности предусматривается уголовная ответственность.
Источник: https://vlada-rykova.com/?p=4059
Данный материал является частной записью члена сообщества Club.CNews.
Редакция CNews не несет ответственности за его содержание.