
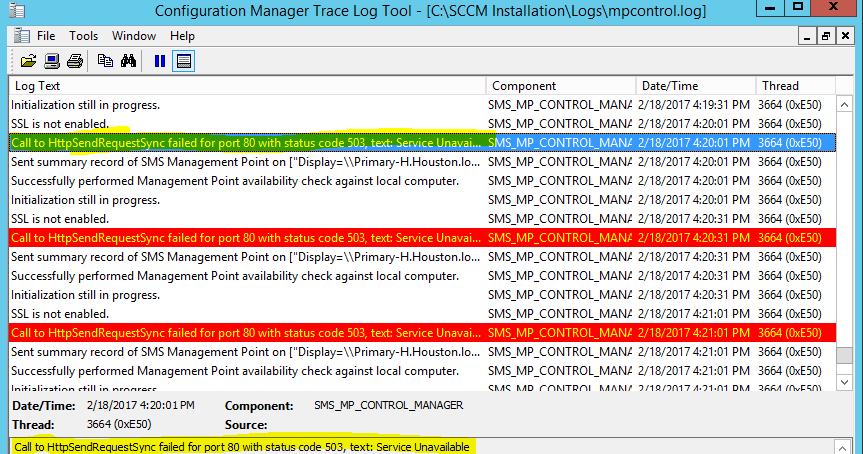
что это значит, что делать, чтобы устранить этот код ответа хоста
Мы увеличиваем посещаемость и позиции в выдаче. Вы получаете продажи и платите только за реальный результат, только за целевые переходы из поисковых систем
Заказывайте честное и прозрачное продвижение
Получи нашу книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
Подпишись на рассылку и получи книгу в подарок!
Ошибка сервера 503 — говорит о том, что его сайт прекратил прием новых запросов по определенному адресу.
Больше видео на нашем канале — изучайте интернет-маркетинг с SEMANTICA
Сервер, на котором располагается сайт, может обработать ограниченное число запросов к нему. Это зависит от мощности. Если на него отправляется больше запросов, чем в состоянии обработать машина, то пользователи, чьи запросы отклонены, видят ошибку 503.
Представьте, что вы стоите в очереди за колбасой (вспомните недавнее советское прошлое). Перед вами огромное количество людей и все они совершают один и тот же запрос — хотят купить колбасу. Продавец по очереди обрабатывает их запросы, и вот лимит исчерпан — колбаса закончилась. Киоск закрывается на перерыв, оставшиеся люди в очереди уходят не с чем. Но через время, когда запасы киоска пополнятся, продажа возобновится. Аналогичным образом работает и хостинг. Хостинг — это киоск, пользователи — люди за колбасой, запрос — желание купить колбасу, а ошибка 503 — табличка на киоске с надписью «ПЕРЕРЫВ».
Обычно 503 ошибка временная. Сервер обработает текущие запросы, освободит свои мощности для следующих.
Если удаленный сервер возвратил именно этот код ответа, значит на сервере сейчас большая очередь, и он просто не может обработать ее.
Причин может быть несколько:
- Скрипты зависли.
- К серверу сейчас направлено много обращений.
Решением данных проблем должны заниматься администратор сайта и его владелец, веб-мастер. Требуется аудит сайта и оптимизация его работы.
Требуется аудит сайта и оптимизация его работы.
Скрипты могут зависать под действием различных факторов, рассмотрим эти факты и варианты их устранения:
- Отправка больших файлов. Данные файлы нужно отправлять напрямую, избегая использования скриптов. Это объясняется тем, что скрипты имеют лимит рабочего времени, когда время истекает, передача прерывается. Также файловая передача через PHP является отдельным процессом, из-за которого обработка пользовательских запросов останавливается.
- Подключение к удаленным серверам. Лучше отказаться от подобного типа соединений.Если это невозможно, то установить минимальное время ожидания ответа и выстроить отличную связь с подобными серверами.
- Много неработоспособных, «тяжелых» модулей CMS. Когда вы используете CMS, регулярно проверяйте плагины на емкость ресурсов и работоспособность. Если какие-то модули ухудшают работу ресурса, их нужно заменить на более мощные. Если какие-либо компоненты движка не используются, лучше их деинсталлировать.

- Почтовая рассылка работает некорректно. Скрипт рассылки почты нужно запускать только в том случае, если нагрузка на сервер минимальна.
- Выполнение сложных запросов к базе данных MySQL. Это можно увидеть в файле mysql-slow.log, его обновление происходит ежедневно. Внутри представлен перечень проблемных запросов к базе. Загрузите компоненты кеширования, выполните оптимизацию запросов, сделайте индексацию таблиц по различным столбцам, изменить CMS.
Есть несколько вариантов, приводящих к к ошибке 503 из-за большого числа запросов:
- На интернет-ресурсе много ссылок на файлы, которые подгружаются через отдельные запросы.
- На ресурсе есть элемент, который отправляет серверу AJAX-запросы.
- Работают индексирующие боты. Осуществляются AJAX-запросы.
Выяснив, какая именно причина имеется на вашем ресурсе, можно устранить проблему.
Полезно будет также выполнить следующие действия:
- Проверить компьютер на наличие вредоносного программного обеспечения.
- Удалить временные файлы и папки. Обновить используемые драйвера.
- Проверить системные файлы через Windows («sfc /scannow»).
Теперь вы знаете, что из себя представляет ошибка 503 “Service Unavailable”.
Главная » Общие вопросы
Естественно, что перед тем, как убрать эту неприятность, важно понять, что означает ошибка 503 service temporarily unavailable.
Как известно, для полноценной работы любого сайта необходимо выполнение определенного ряда процессов. Все эти процедуры выполняются в порядке очереди, и на каждую из них требуется выделение определенного времени.
Все эти процедуры выполняются в порядке очереди, и на каждую из них требуется выделение определенного времени.
Если одна из операций не успевает завершиться в отведенный ей промежуток времени, то на экране компьютера, откуда делает запрос доступа к сайту, возникает сообщение об ошибке, более известной, как 503 service temporarily unavailable.
К сожалению, но первопричин такой неприятности очень много, поэтому вебмастеру следует запастись терпением, чтобы исправить возникшую ситуацию.
Чтобы окончательно избавиться от подобной ошибки, потребуется выполнить целый комплекс работ, основанных на различных причинах ее возникновения и рекомендуемых методиках исправления ситуации:
- Число запросов к используемому серверу не совпадает с реальным количеством страниц сайта. Это связано с тем, что на ресурсе может располагать множество различных типов информации – изображения, таблицы, скрипты и так далее. В итоге, может возникнуть конфликт. Для исправления рекомендуется выполнить оптимизацию сайта, постараться удалить все лишнее и не нужное.
- Огромное число посещений сайта различными автоматическими программами, роботами, ботами, анализаторами. Решение – выполнить анализ лог-файла. Закрыть для посещения некоторые разделы сайта, необязательные для поисковых роботов и аналогичных служб.
- Использование технологии AJAX при создании игровых проектов, различных чатов и других «тяжелых» услуг может привести к перегрузке сервера. Рекомендация – смена серверных услуг на более мощные, например, на VPS.
- Использование подгрузки с других интернет-ресурсов также может привести к подобной ситуации, особенно если некоторые из них прекратили свою работу. Необходимо проверить источники на доступность и оставить только те, которые можно считать надежными.
- DDOS-атака. К сожалению, придется ждать ответных мер со стороны самого хостинг-провайдера. На это требуется время, пока не будет полностью проанализирована ситуация.
Следующий пакет первопричин возникновения 503 service temporarily unavailable непосредственно связан с работой установленных скриптов:
- Использование дополнительных запросов при обращении к серверу.
 Следует убедиться, прежде всего, в хорошей скорости обработки поступающих запросов, установить минимальный таймаут на ожидание отклика, исключить в рабочем процессе использование путей вида http://.
Следует убедиться, прежде всего, в хорошей скорости обработки поступающих запросов, установить минимальный таймаут на ожидание отклика, исключить в рабочем процессе использование путей вида http://. - Применение очень «тяжелых» скриптов, использование поврежденных, устаревших, нерабочих плагинов. Решение – перепроверка этих элементов и отключение всех ненужных, малоэффективных.
- Скрипты применяются для процедуры передачи файлов большого объема. Найти решение, позволяющее выполнять подобное напрямую, исключая работу подобных дополнений.
- Не правильное использование почтовых рассылок. Рекомендуется установить ограничение на количество, а также выполнять рассылку в тот момент времени, когда нагрузка на применяемый сервис является минимальной.
Получается, что практически всегда причиной подобной неприятности являются какие-то решения и настройки со стороны владельца интернет-ресурса. Естественно, что подобные проблемы стоит исправлять оперативно, так как малейшее промедление грозит потерей популярности, выпадением из поисковых рейтингов и снижению дохода с сайта.
Понравилась статья? Поделиться с друзьями:
Как решить ошибку «Служба недоступна Scrapy 503»
При очистке или сканировании возникает ошибка «Служба недоступна Scrapy 503». Ошибка является распространенной и запутанной ошибкой, поскольку часто не на 100% ясно, что вызывает ошибку.
A Scrapy 503 Служба недоступна Ошибка регистрируется, когда внутренний сервер, к которому пытается подключиться ваш паук, возвращает код состояния HTTP 503 .
Это означает, что в настоящее время сервер не может обрабатывать входящие запросы. Либо потому что сервер недоступен для обслуживания или слишком перегружен входящими запросами и больше не может обрабатываться.
Однако часто, когда ваш паук получает эту ошибку, вы можете нормально подключиться к целевому веб-сайту с помощью своего браузера. Это означает, что сервер, скорее всего, намеренно возвращает вашему парсеру код состояния HTTP
Это означает, что сервер, скорее всего, намеренно возвращает вашему парсеру код состояния HTTP 503 .
Скорее всего потому, что сервер считает вас парсером и блокирует вас .
В этом руководстве мы расскажем, как устранить неполадки Scrapy 503 Service Unreachable Errors и предоставьте решения, которые вы можете реализовать.
- Определите, действительно ли сервер снизится на
- Легкий способ решения Scrapy 503 Ошибки
- Используйте поддельные пользовательские агенты
- Оптимизировать заголовки запросов
- Использовать вращающиеся прокси
Lets’s Begin …
Определите, если сервер. Вниз
Первый шаг, который вы должны предпринять при попытке отладки Scrapy 503 Service Unreachable Error , чтобы проверить, является ли это настоящей ошибкой 503 или поддельной 503 , потому что веб-сайт думает, что вы парсер.
Проверить это так же просто, как запросить те же URL-адреса с помощью реального веб-браузера или безголового браузера (Selenium, Puppeteer, Playwright).
Если вы НЕ МОЖЕТЕ получить доступ к веб-сайту , значит, сервер временно отключен на техническое обслуживание или слишком занят. В таких случаях ничего не поделаешь.
Сервер веб-сайтов просто отключен, поэтому вам просто нужно подождать, пока он снова не заработает и полностью заработает.
Если вы МОЖЕТЕ получить доступ к веб-сайту с помощью браузера без проблем, то весьма вероятно, что сервер на самом деле не отключен для обслуживания или слишком занят.
Вместо этого сервер, вероятно, пометил ваш спайдер как парсер и блокирует запросы от вашего спайдера .
Чтобы решить эту проблему, нам нужно выяснить, как веб-сайт нас обнаруживает, и сделать нашего паука более незаметным.
Простой способ решить ошибки Scrapy 503
Если сервер работает, но вы получаете Scrapy 503 Service Unreachable Errors , то вполне вероятно, что веб-сайт помечает ваш паук как парсер и блокирует ваши запросы.
Чтобы избежать обнаружения, нам нужно оптимизировать наши программы-пауки для обхода мер противодействия ботам:
- Использование поддельных пользовательских агентов
- Оптимизация заголовков запросов
- Использование прокси-серверов
способ решить эту проблему — использовать интеллектуальное прокси-решение, такое как ScrapeOps Proxy Aggregator.
С агрегатором прокси-серверов ScrapeOps вам просто нужно отправить свои запросы на конечную точку прокси-сервера ScrapeOps, и наш агрегатор прокси-серверов оптимизирует ваш запрос с помощью наилучшего пользовательского агента, заголовка и конфигурации прокси-сервера, чтобы гарантировать, что вы не получите 503 ошибки с вашего целевого веб-сайта.
Просто получите бесплатный ключ API , зарегистрировав бесплатную учетную запись здесь и отредактируйте свой паук Scrapy следующим образом:
import scrapyAPI_KEY = 'YOUR_API_KEY'
def get_scrapeops_url(url):
полезная нагрузка = {'api_key': API_KEY, 'url': url}
proxy_url = 'https://proxy.scrapeops.io/v1/?' + urlencode(payload)
return proxy_urlclass QuotesSpider(scrapy.Spider):
name = "quotes"def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/ 1/',
'http://quotes.toscrape.com/page/2/',
]
для URL-адреса в URL-адресах:
yield scrapy.Request(url=get_scrapeops_url(url), callback=self.parse)
Вы можете ознакомиться с полной документацией здесь.
Или, если вы предпочитаете попробовать оптимизировать свой пользовательский агент, заголовки и конфигурацию прокси-сервера самостоятельно, тогда читайте дальше, и мы объясним, как это сделать.
Использование поддельных пользовательских агентов
Наиболее распространенная причина, по которой веб-сайт блокирует паука Scrapy и возвращает ошибку 503 , заключается в том, что ваш паук сообщает веб-сайту, что ваш паук является автоматическим парсером.
Во многом это связано с тем, что по умолчанию Scrapy сообщает веб-сайту, что он является парсером в пользовательском агенте, который он отправляет с вашим запросом.
Если вы не переопределите настройки Scrapy по умолчанию, ваш паук будет отправлять следующий пользовательский агент с каждым запросом:
пользовательский агент: Scrapy/VERSION (+https://scrapy.org)
Это сообщает веб-сайту что ваши запросы исходят от паука Scrapy, поэтому им очень легко заблокировать ваши запросы и вернуть код состояния 503 .
Решение
Решение этой проблемы состоит в том, чтобы настроить паука на отправку фальшивого пользовательского агента с каждым запросом. Таким образом, веб-сайту будет сложнее определить, исходят ли ваши запросы от парсера или от реального пользователя.
Мы написали полное руководство о том, как установить поддельные пользовательские агенты для парсеров здесь, однако это краткое изложение решения:
Метод 1: Установить поддельный пользовательский агент в файле Settings.py
Самый простой способ изменить пользовательский агент Scrapy по умолчанию — установить пользовательский агент по умолчанию в файле settings.. py
py
Просто раскомментируйте значение USER_AGENT в файле settings.py и добавьте новый пользовательский агент:
## settings.pyUSER_AGENT = 'Mozilla/5.0 (iPad; CPU OS 12_2, например Mac OS X) AppleWebKit/605.1.15 (KHTML, например Gecko) Mobile/15E148'
Здесь вы можете найти огромный список пользовательских агентов.
Это будет работать только с относительно небольшими парсерами, так как если вы используете один и тот же пользовательский агент для каждого отдельного запроса, веб-сайт с более сложным решением для защиты от ботов может легко обнаружить ваш парсер.
Чтобы обойти это, нам нужно пройти через большой пул поддельных пользовательских агентов, чтобы каждый запрос выглядел уникальным.
Способ 2: использование Scrapy-Fake-Useragent
Вы можете собрать большой список поддельных пользовательских агентов и настроить своего паука так, чтобы он просматривал их самостоятельно, как в этом примере, или вы можете использовать промежуточное ПО Scrapy, такое как scrapy-fake -агент пользователя.
scrapy-fake-useragent создает поддельные пользовательские агенты для ваших запросов на основе статистики использования из реальной базы данных и прикрепляет их к каждому запросу.
Установить скрап-поддельный юзерагент очень просто. Просто установите пакет Python:
PIP установить Scrapy-Fake-Useragent
, затем в вашем файле настройки. и RetryUserAgentMiddleware .
## settings.pyDOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': нет,
'scrapy.downloadermiddlewares.retry.RetryMiddleware': нет,
'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 400,
'scrapy_fake_useragent.middleware.RetryUserAgentMiddleware': 401,
}
А затем включите Fake User-Agent Settings Providers, добавив их в файл настроек
.0.7.09.
## settings.pyFAKEUSERAGENT_PROVIDERS = [
'scrapy_fake_useragent.providers.FakeUserAgentProvider', # Это первый провайдер, который мы попробуем сгенерировать для нас строку user-agent
'scrapy_fake_useragent.providers.FixedUserAgentProvider', # Вернитесь к значению USER_AGENT
]## Установите резервный User-Agent
USER_AGENT = '<строка вашего пользовательского агента, к которой вы вернетесь, если все другие провайдеры потерпят неудачу>'
При активации scrapy-fake-useragent будет загружать список наиболее распространенных пользовательских агентов с сайта useragentstring.com и использовать случайный агент при каждом запросе, поэтому вам не нужно создавать свой собственный список.
Вы также можете добавить своих собственных поставщиков строк пользовательского агента или настроить его для создания новых строк пользовательского агента в качестве резервной копии с помощью Faker.
Чтобы увидеть все параметры конфигурации, ознакомьтесь с документацией здесь.
Во многих случаях простое добавление поддельных пользовательских агентов к вашим запросам решит Scrapy 503 Service Unavailable Error , однако, если на веб-сайте есть более сложная система обнаружения ботов, вам также понадобится оптимизировать заголовки запросов.
По умолчанию Scrapy будет отправлять только основные заголовки запросов вместе с вашими запросами, такими как Accept , Accept-Language и User-Agent .
Accept: 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
Accept-Language: 'en'
User-Agent: 'Scrapy/VERSION ( +https://scrapy.org)'
Напротив, вот заголовки запросов, которые браузер Chrome, работающий на компьютере MacOS, отправил бы:
Connection: 'keep-alive'
Cache-Control: 'max -age=0'
sec-ch-ua: '" Not A;Brand";v="99", "Chromium";v="99", "Google Chrome";v="99"'
sec-ch-ua-mobile: '?0'
sec-ch-ua-platform: "macOS"
Upgrade-Insecure-Requests: 1
User-Agent: 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, как Gecko) Chrome/99.0.4844.83 Safari/537.36'
Accept: 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp ,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'
Sec-Fetch-Site: «нет»
Sec-Fetch-Mode: «навигация»
Sec- Fetch-User: «?1»
Sec-Fetch-Dest: «документ»
Accept-Encoding: 'gzip, deflate, br'
Accept-Language: 'en-GB,en-US;q=0.9,en;q=0.8'
Если веб-сайт действительно пытается предотвратить доступ парсеров их содержимое, затем они будут анализировать заголовки запроса, чтобы убедиться, что другие заголовки соответствуют установленному вами пользовательскому агенту, и что запрос включает другие общие заголовки, которые отправит реальный браузер .
Решение
Чтобы решить эту проблему, нам нужно убедиться, что мы оптимизировали заголовки запроса, в том числе убедившись, что поддельный пользовательский агент согласуется с другими заголовками .
Это большая тема, поэтому, если вы хотите узнать больше об оптимизации заголовков, ознакомьтесь с нашим руководством по оптимизации заголовков.
Однако вот краткий пример добавления оптимизированных заголовков к нашим запросам:
# bookspider.py
url_list = ["http://books.toscrape.com"]
HEADERS = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:98.0) Gecko/20100101 Firefox/98.0",
"Accept": "text/html,application/xhtml +xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.5",
"Accept -Encoding": "gzip, deflate",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
"Sec-Fetch-Dest": "document",
"Sec -Fetch-Mode": "навигация",
"Sec-Fetch-Site": "нет",
"Sec-Fetch-User": "?1",
"Cache-Control": "max-age=0",
}def start_requests(self):
для URL в self.url_list:
return Request(url=url, callback=self.parse, headers=HEADERS )def parse(self, response):
для статьи в response.css('article.product_pod'):
book_item = BookItem(
url = article.css("h4 > a::attr(href)" ).get(),
title = article.css("h4 > a::attr(title)").extract_first(),
price = article.css(".price_color::text").extract_first(),
)
yield book_item
Здесь мы добавляем к каждому запросу один и тот же оптимизированный заголовок с поддельным агентом пользователя.
Использовать чередующиеся прокси
Если приведенные выше решения не работают, весьма вероятно, что сервер пометил ваш IP-адрес как используемый парсером и либо ограничивает ваши запросы, либо полностью блокирует их.
Это особенно вероятно при парсинге больших объемов, так как веб-сайтам легко обнаружить парсеры, если они получают неестественно большое количество запросов с одного и того же IP-адреса.
Решение
Вам нужно будет отправлять запросы через чередующийся пул прокси. Здесь мы создали полное руководство по различным вариантам интеграции и ротации прокси-серверов в ваших пауках Scrapy.
Тем не менее, он является одним из возможных решений с использованием промежуточного программного обеспечения scrapy-rotating-proxy.
Для начала просто установите промежуточное ПО:
pip install scrapy-rotating-proxy
Затем нам просто нужно обновить наш settings. для загрузки наших прокси и включения промежуточного ПО scrapy-rotating-proxy ::strip_icc()/i.s3.glbimg.com/v1/AUTH_bc8228b6673f488aa253bbcb03c80ec5/internal_photos/bs/2021/U/v/gzAs6xRfWcaIny9xdIbg/erro.jpg) py
py
## settings.py## Вставьте здесь свой список прокси
ROTATING_PROXY_LIST = [
'proxy1.com:8000',
'proxy2 .com:8031',
'proxy3.com:8032',
]## Включить ПО промежуточного слоя прокси в вашем загрузчике ПО промежуточного слоя
DOWNLOADER_MIDDLEWARES = {
# ...
'rotating_proxies.middlewares.RotatingProxyMiddleware': 00106 'rotating_proxy.middlewares.BanDetectionMiddleware': 620,
# ...
}
И все. После этого все запросы, которые будет делать ваш паук, будут проксироваться с использованием одного из прокси из ROTATING_PROXY_LIST .
Если вам нужна помощь в поиске лучших и самых дешевых прокси для вашего конкретного случая использования, воспользуйтесь нашим инструментом сравнения прокси здесь.
В качестве альтернативы вы можете просто использовать прокси-агрегатор ScrapeOps, как мы обсуждали ранее.
Дополнительные уроки по Scrapy
Вот как вы можете решить Служба Scrapy 503 недоступна Ошибки при их получении.
Если вы хотите узнать больше о Scrapy, обязательно ознакомьтесь с The Scrapy Playbook.
Как исправить ошибку 503 "Служба недоступна"
Ниже приведены наиболее распространенные способы появления ошибки "служба недоступна":
- 503 Служба недоступна
- Служба 503 временно недоступна Http 30091 Http/
- Ошибка HTTP-сервера 503
- Служба недоступна — ошибка DNS
- 503 Ошибка
- HTTP 503
- Ошибка HTTP 503
- Ошибка 503 Служба недоступна
503 Служба недоступна Ошибки могут появляться в любом браузере назад, включая Windows 10 в любой операционной системе , macOS, Linux и т. д.... даже ваш смартфон или другие нетрадиционные компьютеры. Если у него есть доступ в Интернет, то в определенных ситуациях вы можете увидеть 503.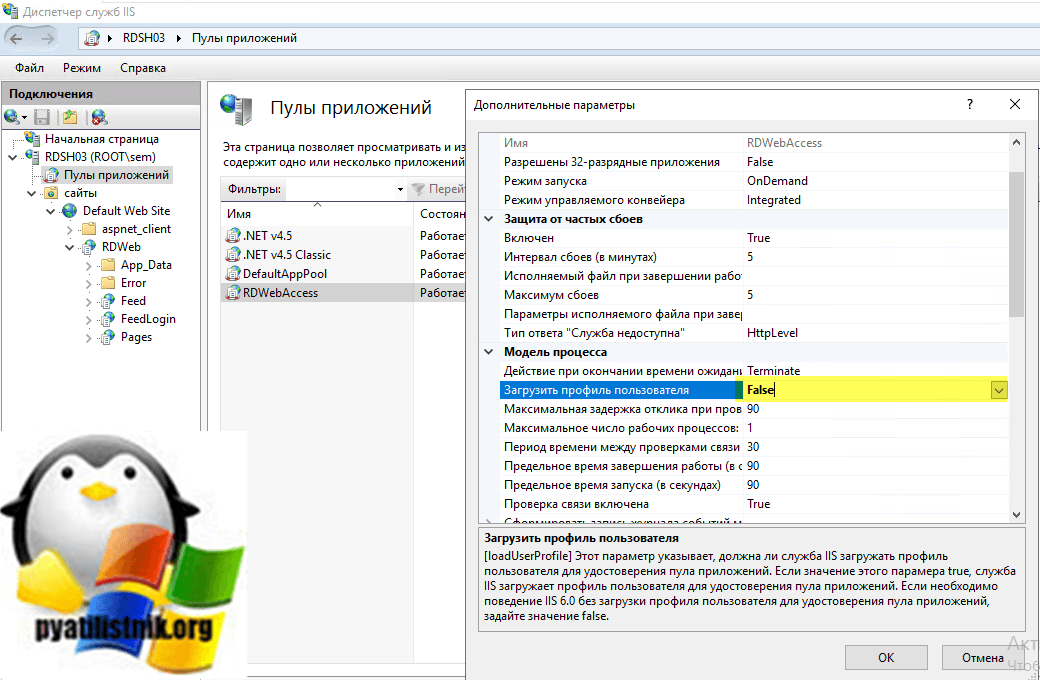
Ошибка 503 Служба недоступна отображается в окне браузера, как и веб-страницы.
Причина ошибки 503 "Служба недоступна"
В большинстве случаев ошибка 503 возникает из-за того, что сервер слишком занят или на нем проводится техническое обслуживание.
Примечание. Сайты, использующие Microsoft IIS, могут предоставлять более конкретную информацию о причине ошибки 503 Service Unreachable, добавляя число после 503, как в HTTP-ошибке 503.2 — Service Unreachable, что означает превышение лимита одновременных запросов. .
Как исправить ошибку 503 "Служба недоступна"
Ошибка 503 "Служба недоступна" является ошибкой на стороне сервера, то есть проблема обычно связана с сервером веб-сайта. Возможно, на вашем компьютере возникла какая-то проблема, которая вызывает ошибку 503, но это маловероятно.
Несмотря на это, вы можете попробовать следующее:
Повторно введите URL-адрес из адресной строки, нажав кнопку перезагрузки/обновления или нажав клавишу F5.
Несмотря на то, что ошибка 503 Служба недоступна означает, что на другом компьютере возникла ошибка, проблема, вероятно, носит временный характер. Иногда достаточно просто попробовать страницу еще раз.
Важно! Если при оплате онлайн-покупки появляется сообщение об ошибке 503 Сервис недоступен, имейте в виду, что несколько попыток оформить заказ могут привести к созданию нескольких заказов и множественных списаний! Большинство платежных систем и некоторые компании, выпускающие кредитные карты, имеют защиту от подобных вещей, но об этом все же следует знать.
Перезагрузите маршрутизатор и модем, а затем компьютер или устройство, особенно если вы видите ошибку «Служба недоступна — сбой DNS».
Хотя ошибка 503, скорее всего, связана с веб-сайтом, который вы посещаете, возможно, существует проблема с конфигурацией DNS-сервера на вашем маршрутизаторе или компьютере, которую можно исправить простым перезапуском обоих.
Совет. Если перезагрузка вашего оборудования не устранила ошибку 503 Ошибка DNS, возможны временные проблемы с самими DNS-серверами. В этом случае выберите новые DNS-серверы из моего списка бесплатных и общедоступных DNS-серверов и измените их на своем компьютере или маршрутизаторе. См. Как изменить DNS-серверы, если вам нужна помощь.
Если перезагрузка вашего оборудования не устранила ошибку 503 Ошибка DNS, возможны временные проблемы с самими DNS-серверами. В этом случае выберите новые DNS-серверы из моего списка бесплатных и общедоступных DNS-серверов и измените их на своем компьютере или маршрутизаторе. См. Как изменить DNS-серверы, если вам нужна помощь.
Другой вариант — обратиться за помощью напрямую на веб-сайт. Есть большая вероятность, что администраторы сайта уже знают об ошибке 503, но сообщить им об этом или проверить статус проблемы — неплохая идея.
См. мой список контактной информации веб-сайта для получения контактной информации для популярных веб-сайтов. У большинства сайтов есть учетные записи социальных сетей на основе поддержки, а у некоторых даже есть номера телефонов и адреса электронной почты.
Совет. Если ошибка 503 на вашем сайте является популярной и вы думаете, что она может быть полностью отключена, умный поиск в Твиттере обычно может дать вам ответ.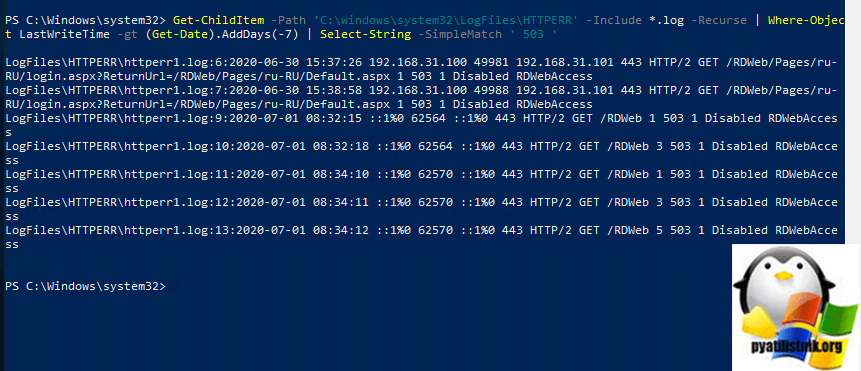 Попробуйте выполнить поиск #websitedown в Твиттере, заменив веб-сайт на название сайта, например, #facebookdown или #youtubedown. Сбой на большом сайте обычно вызывает много разговоров в Твиттере.
Попробуйте выполнить поиск #websitedown в Твиттере, заменив веб-сайт на название сайта, например, #facebookdown или #youtubedown. Сбой на большом сайте обычно вызывает много разговоров в Твиттере.
Зайдите позже. Поскольку ошибка 503 Service Unavailable является распространенным сообщением об ошибке на очень популярных веб-сайтах, когда огромное увеличение трафика посетителей (это вы!) перегружает серверы, простое ожидание часто является вашим лучшим выбором.
Честно говоря, это наиболее вероятное "исправление" ошибки 503. По мере того, как все больше и больше посетителей покидают веб-сайт, шансы на успешную загрузку вашей страницы увеличиваются.
Исправление ошибок 503 на вашем собственном сайте
С таким количеством различных вариантов веб-сервера и даже более общими причинами, по которым ваш сервис может быть недоступен, нет простого «что делать», если ваш сайт дает ваши пользователи 503.
Тем не менее, определенно есть места, с которых можно начать искать проблему.