
Поисковые системы
Содержание статьи:
- Что такое поисковые системы и как они работают
- Типы поисковых систем по способу работы
- Индексные поисковые системы
- Каталоговые системы поиска
- Метапоисковые системы
- Специализированные поисковые системы
- Типы поисковых систем по области поиска
- Советы по эффективному поиску информации
- Язык запросов
- Основные возможности языка запросов поисковой системы Google и Yandex
- Особенности работы с поисковыми системами
- Рекомендации по безопасному использованию поисковых систем
Что такое поисковые системы и как они работают
Поисковая система – это программно-аппаратный комплекс, который предназначен для осуществления поиска в сети Интернет. Он помогает пользователям быстро найти необходимые сведения, реагируя на запрос пользователя выдачей списка ссылок на источники информации. Достаточно набрать в строке поиска интересующий вопрос или фразу, нажать на кнопку «Поиск» или «Search», и через несколько секунд поисковая система выдаст необходимую информацию.
Он помогает пользователям быстро найти необходимые сведения, реагируя на запрос пользователя выдачей списка ссылок на источники информации. Достаточно набрать в строке поиска интересующий вопрос или фразу, нажать на кнопку «Поиск» или «Search», и через несколько секунд поисковая система выдаст необходимую информацию.
Поисковые системы классифицируют по способу работы и по области использования. По данным LiveInternet.ru, в 2012 году 53,8% российских пользователей предпочитали Яндекс, 34,2% – Google 9,4% – Поиск Mail. ru и 1,2% – Rambler .
Каждая поисковая система имеет собственный алгоритм поиска, который определенным образом анализирует релевантность сайтов, чтобы выдать результат, наиболее соответствующий запросу пользователя.
Типы поисковых систем по способу работы
Индексные поисковые системы собирают информацию в Интернете автоматически, с помощью специальных программ-роботов, посещающих веб-страницы. Они осуществляют всесторонний поиск по ключевым словам.
Индексная поисковая система состоит из трех основных компонентов:
Агент (паук или кроулер)
Агент – это специальная программа, которая запускается на сервере поисковой системы с целью посещения веб-страниц. Когда агент находит новую страницу, удовлетворяющую алгоритму поисковой системы, он индексирует ее, то есть добавляет в базу данных поисковой системы. Посещать страницы агенту помогает система гиперссылок, благодаря которой программа может бесконечно переходить с одной страницы на другую.
База данных поисковой системы
В ней хранятся все найденные и обработанные документы (индексы). Индекс позволяет быстро совершать поиск и обычно состоит из списка ключевых слов и информации о них (позиции в тексте, веса и др.). База регулярно обновляется, и именно из последнего ее обновления выдаются результаты для поставленного запроса. Частота обновления базы данных – критически важный параметр любой поисковой системы.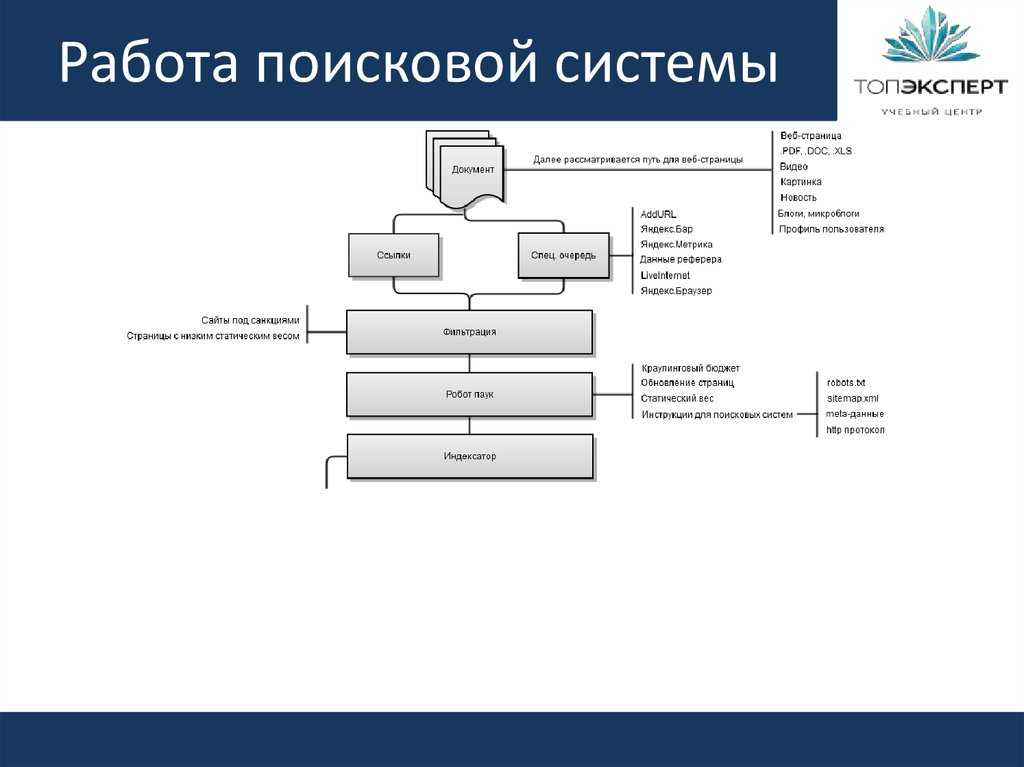
Поисковый механизм
Поисковый механизм – интерфейс для взаимодействия пользователя и базы данных, то есть та самая программа, с которой мы непосредственно имеем дело.
Индексные поисковые системы работают по одному общему принципу. Сначала агент начинает сканирование сети с определенного адреса. На сервере создаются индексированные копии документов, своего рода вспомогательные файлы. Затем сохраненные документы просматриваются, определяются гиперссылки с этих страниц, по ним осуществляется переход на новые страницы. После сохранения копий найденных документов весь процесс повторяется. Все веб-страницы, проиндексированные поисковой системой, попадают в базу данных, что позволяет пользователю, формирующему запрос на поиск необходимой информации, мгновенно получить ссылки на нее.
Каталоговые системы поиска содержат тематически структурированный каталог серверов и чаще всего пополняются вручную модераторами. Эти системы устроены так же, как тематический каталог обычной библиотеки. Ссылки в них хранятся по теме категорий. Начав с основной страницы каталога, нужно выбрать ссылку, обозначающую главную категорию, а затем на последующих страницах указывать подкатегории до тех пор, пока не будут достигнуты ссылки на конкретные страницы. Каталог обычно имеет тематическую разбивку на подкаталоги, те в свою очередь могут подразделяться на более мелкие поддиректории и т. д. Ярким примером каталога является система Yahoo.
Эти системы устроены так же, как тематический каталог обычной библиотеки. Ссылки в них хранятся по теме категорий. Начав с основной страницы каталога, нужно выбрать ссылку, обозначающую главную категорию, а затем на последующих страницах указывать подкатегории до тех пор, пока не будут достигнуты ссылки на конкретные страницы. Каталог обычно имеет тематическую разбивку на подкаталоги, те в свою очередь могут подразделяться на более мелкие поддиректории и т. д. Ярким примером каталога является система Yahoo.
Индексные поисковые системы и поисковые каталоги отличаются так же, как содержание и алфавитный указатель в книге. Задача и содержания, и алфавитного указателя – помочь найти в книге нужный раздел. Содержание – это пример каталогизации. Алфавитный указатель – пример индексации. Читатель находит в указателе нужный термин и получает номер страницы, на которой он встречается.
Метапоисковые системы –это системы, которые используют для поиска базы данных других поисковых систем. Они посылают запрос одновременно на несколько поисковых систем, каталогов и иногда в так называемую невидимую (скрытую) паутину – хранилище онлайн-информации, не считанной традиционными поисковыми системами. Собрав результаты, метапоисковая система удаляет дублированные ссылки и в соответствии со своим алгоритмом объединяет результаты в общем списке. Примером такой системы может служить российское решение Nigma , использующее для поиска Google , Yahoo , Апорт и Яндекс.
Они посылают запрос одновременно на несколько поисковых систем, каталогов и иногда в так называемую невидимую (скрытую) паутину – хранилище онлайн-информации, не считанной традиционными поисковыми системами. Собрав результаты, метапоисковая система удаляет дублированные ссылки и в соответствии со своим алгоритмом объединяет результаты в общем списке. Примером такой системы может служить российское решение Nigma , использующее для поиска Google , Yahoo , Апорт и Яндекс.
Специализированные поисковые системы, в отличие от поисковых систем общего назначения, которые ищут любую интересующую информацию, ищут информацию определенного вида, например, изображения, книги, организации, людей, то есть работают в какой-то конкретной области. Примерами таких систем могут служить moresoft.ru для поиска программ и файлов, bukinist.agava.ru для поиска книг и других электронных текстов, kinopoisk . ru для поиска информации о фильмах, Яндекс.Маркет для поиска описаний и цен товаров, представленных в Интернет-магазинах, drivers. ru для поиска драйверов, wink.com для поиска людей.
ru для поиска драйверов, wink.com для поиска людей.
Типы поисковых систем по области поиска
По области поиска поисковые системы можно разделить на глобальные и локальные.
Глобальные предназначены для поиска информации по всей сети Интернет либо по значительной ее части, а локальные – по какой-либо части Сети, например, по одному или нескольким сайтам, либо по локальной сети. Часто локальные поисковые системы собирают информацию в пределах одного национального домена, как, например, yandex.ru .
Также существуют локальные поисковые машины, которые можно установить себе на компьютер, например Copernic Desktop Search для Microsoft Windows, Spotlight для Mac OS X, Tracker для Linux . Они значительно облегчают жизнь тех пользователей, которые хранят огромные архивы нерассортированных файлов.
Советы по эффективному поиску информации
Алгоритм создания эффективного запроса выглядит следующим образом:
- Сформулируйте задачу поиска.
 Для получения необходимой информации, в первую очередь, нужно понять, на какой именно вопрос вы ищете ответ.
Для получения необходимой информации, в первую очередь, нужно понять, на какой именно вопрос вы ищете ответ.
- Ограничьте область поиска. Выдача результатов может различаться в зависимости от региона, поэтому нужно добавить в запрос тот город, регион или страну, результаты по которым вас интересуют.
- Подберите ключевые слова, то есть слова и фразы, относящиеся к теме поиска. Ключевые слова делят на высоко-, средне- и низкочастотные, это зависит от частоты запроса и определяется на основе статистики поисковой системы.
- Сформируйте запрос. Важные слова поместите в начало запроса, для более эффективного поиска используйте язык запросов.
Язык запросов
Поисковые системы – это разумный инструмент, использующий язык запросов, то есть определенные команды и символы в строке поиска, которые помогают быстрее найти нужную информацию.
Основные возможности языка запросов поисковой системы Google и Yandex
Если вам необходимо найти слово или фразу в точно таком виде, как вы вводите, без всяких изменений форм и порядка слов, то заключите свой поисковый запрос в кавычки.
Если вам необходимо исключить из результатов поиска в Google все страницы, содержащие определенное слово, то поставьте перед этим словом в запросе знак минус (–). Например, если ввести в строку поиска «вирус –компьютерный», то система выдаст документы, в которых не встречается ключевое слово «компьютерный». В Яндексе же подобная операция производится с помощью символа тильда (~), поставленного в запросе перед словом, которое нужно исключить из поиска.
Оператор site: в Google позволяет осуществлять поиск на конкретном сайте. Например, если набрать в строке поиска Google «поступление site:www.msu.ru», то система будет искать информацию о поступлении именно на сайте МГУ. В Яндексе подобная операция осуществляется с помощью оператора host:
Символом звездочка (*) можно заменять в запросе неизвестные слова. Например, «буря * небо кроет».
Оператор define: в Google позволяет искать определения слова, указанного в запросе.
В обычном режиме Google старается найти страницы, содержащие все указанные слова. Если же вставить между словами оператор OR (заглавными буквами), то система покажет страницы, включающие в себя как минимум одно из этих слов. Например,купить квартиру в Москве OR Подмосковье. В Яндексе же подобная операция производится с помощью символа прямой слэш (|), поставленного между словами запроса, например;билеты Лондон | Париж;.
Чтобы получить в выдаче Google диапазон чисел «от и до», нужно между ними поставить две точки, например, «снять квартиру $1000..$1500».
Язык запросов поддерживают многие поисковые системы. Перед их использованием рекомендуется посмотреть описание в разделе помощи сайта конкретной поисковой системы, которую планируется использовать.
Особенности работы с поисковыми системами
Использование поисковых систем может стать причиной проникновения на компьютер пользователя вредоносной программы. Выдавая результаты по запросам пользователей, поисковые системы могут выдавать адреса зараженных сайтов.
Выдавая результаты по запросам пользователей, поисковые системы могут выдавать адреса зараженных сайтов.
Также нужно иметь в виду, что поисковые системы выдают лишь ссылки на релевантные сайты, но не отвечают за достоверность информации, которая на этих сайтах содержится. Задача поисковых систем – максимально быстро и точно ответить на запрос, поэтому не стоит безоговорочно доверять всей информации, которая находится по выдаваемым ссылкам. Сайты, полученные при поиске, могут содержать некорректную или откровенно ложную информацию, которая может ввести в заблуждение пользователя, ведь далеко не все источники, скорее меньшая их часть, пишутся и проверяются действительно компетентными людьми. Например, информацию на таком популярном ресурсе как Википедия размещают все желающие, следствием чего является высокий процент ошибок в статьях. Рекомендуется крайне осторожно выбирать источники для школьных, студенческих и научных работ, да и вообще перепроверять любую информацию, особенно из совершенно незнакомой области.
Рекомендации по безопасному использованию поисковых систем
- Старайтесь внимательно относиться к сайтам, выдаваемым поисковой системой, поскольку они могут содержать вирусы. Соблюдайте меры предосторожности: не стоить заходить на сомнительные сайты, особенно если антивирус предупреждает о нежелательности такого действия.
- Обязательно используйте и регулярно обновляйте антивирусные средства защиты – программы, позволяющие обнаруживать и удалять вредоносные программы, восстанавливать зараженные файлы, а также предотвращать проникновение вирусов на устройство.
- Проверяйте достоверность информации, полученной из Интернета. Самый простой способ – сравнить хотя бы несколько источников, которые не дублируют друг друга.
- Время от времени проверяйте, какую информацию выдают поисковые системы, когда вы пытаетесь найти в них сведения о себе. Это поможет вам узнать, нет ли в Сети ваших личных данных, которые вы предпочли бы не делать общеизвестными, и в случае необходимости вовремя подать жалобу руководству соответствующих сайтов.

Интернет-портал «Безопасность пользователей в сети Интернет» [email protected] https://safe-surf.ru
структуры, функция, характеристики. Что нужно знать о поисковиках для успешного продвижения сайтов?
Поисковые системы (ПС) уже давно являются обязательной частью интернета и нашей повседневной жизни. Сегодня они громадные и сложнейшие механизмы, которые представляют собой не только инструмент для нахождения любой необходимой информации, но и довольно увлекательные сферы для бизнеса.
Многие пользователи поиска никогда не думали о принципах их работы, о способах обработки пользовательских запросов, о том, как построены и функционируют данные системы. Данный материал поможет людям, которые занимаются оптимизацией и продвижение своих сайтов, понять устройство и основные функции поисковых машин.
Функции и понятие ПС
Поисковая система – это аппаратно-программный комплекс, который предназначен для осуществления функции поиска в интернете, и реагирующий на пользовательский запрос который обычно задают в виде какой-либо текстовой фразы (или точнее поискового запроса), выдачей ссылочного списка на информационные источники, осуществляющейся по релевантности. Самые распространенные и крупные системы поиска: Google, Bing, Yahoo, Baidu. В Рунете – Яндекс, Mail.Ru, Рамблер.
Самые распространенные и крупные системы поиска: Google, Bing, Yahoo, Baidu. В Рунете – Яндекс, Mail.Ru, Рамблер.
Рассмотрим поподробнее само значение запроса для поиска, взяв для примера систему Яндекс.
Запрос обязан быть сформулирован пользователем в полном соответствии с предметом его поиска, максимально просто и кратко. К примеру, мы желаем найти информацию в данном поисковике: «как выбрать автомобиль для себя». Чтобы сделать это, открываем главную страницу и вводим запрос для поиска «как выбрать авто». Потом наши функции сводятся к тому, чтобы зайти по предоставленным ссылкам на информационные источники в сети.
Но даже действуя таким образом, можно и не получить необходимую нам информацию. Если мы получили подобный отрицательный результат, нужно просто переформировать свой запрос, или же в базе поиска действительно нет никакой полезной информации по данному виду запроса (такое вполне возможно при заданных «узких» параметров запроса, как, к примеру, «как выбрать автомобиль в Туле»).
Самая основная задача каждой поисковой системы – доставить людям именно тот вид информации, который им нужен. Приучить же пользователей создавать «правильный» вид запросов к поисковым системам, то есть фразы, которые будут соответствовать их принципам работы, практически, невозможно.
Именно поэтому специалисты-разработчики поисковиков делают такие принципы и алгоритмы их работы, которые бы давали пользователям находить интересующие их сведения. Это означает, что система, должна «думать» так же, как мыслит человек при поиске необходимой информации в интернете.
Когда он вводит свой запрос в поисковую машину, он желает найти то, что ему надо, как можно проще и быстрее. Получив результат, пользователь составляет свою оценку работе системы, руководствуясь несколькими критериями. Получилось ли у него найти нужную информацию? Если нет, то сколько раз ему пришлось переформатировать текст запроса, чтобы найти ее? Насколько актуальная информация была им получена? Как быстро поисковая система обработала его запрос? Насколько удобно были предоставлены поисковые результаты? Был ли нужный результат первым, или находился на 30-ом месте? Сколько «мусора» (ненужной информации) было найдено вместе с полезными сведениями? Найдется ли актуальная для него информация, при использовании ПС, через неделю, либо через месяц?
Для того чтобы получить правильные ответы на подобные вопросы, разработчики поиска постоянно улучшают принципы ранжирования и его алгоритмы, добавляют им новые возможности и функции и любыми средствами пытаются сделать быстрее работу системы.
Основные характеристики поисковых систем
Обозначим главные характеристики поиска:
Полнота.
Полнота является одной из главнейших характеристик поиска, она представляет собой отношение цифры найденных по запросу информационных документов к их общему числу в интернете, относящихся к данному запросу. Например, в сети есть 100 страниц имеющих словосочетание «как выбрать авто», а по такому же запросу было отобрано всего 60 из общего количества, то в данном случае полнота поиска составит 0,6. Понятно, что чем полнее сам поиск, тем больше вероятность, что пользователь найдет именно тот документ, который ему необходим, конечно, если он вообще существует.
Точность.
Еще одна основная функция поисковой системы – точность. Она определяет степень соответствия запросу пользователя найденных страниц в Сети. К примеру, если по ключевой фразе «как выбрать автомобиль» найдется сотня документов, в половине из них содержится данное словосочетание, а в остальных просто есть в наличии такие слова (как грамотно выбрать автомагнитолу, и установить ее в автомобиль»), то поисковая точность равна 50/100 = 0,5.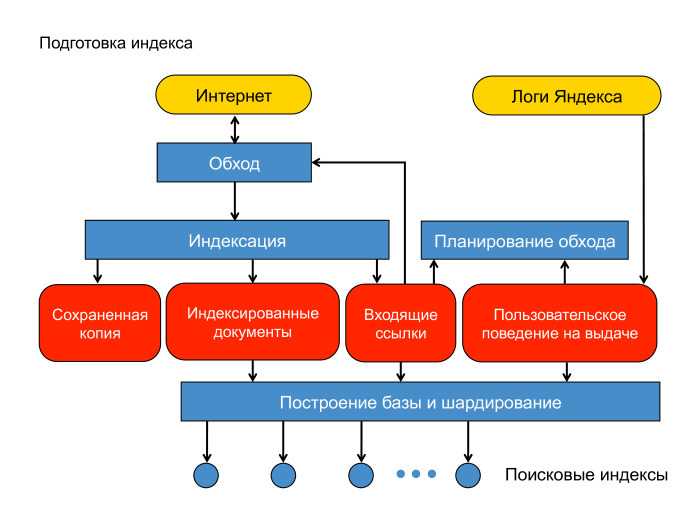
Чем поиск точнее, тем скорее пользователь найдет необходимую ему информацию, тем меньше разнообразного «мусора» будет встречаться среди результатов, тем меньше найденных документов будут не соответствовать смыслу запроса.
Актуальность.
Это значимая составляющая поиска, которую характеризует время, проходящее с момента опубликования информации в интернете до занесения ее в индексную базу поисковика.
К примеру, на следующий день после возникновения информации о выходе нового iPad, множество пользователей обратилась к поиску с соответствующими видами запросов. В большинстве случаев информация об этой новости уже доступна в поиске, хотя времени с момента ее появления прошло очень мало. Это происходит благодаря наличию у крупных поисковых систем «быстрой базы», которая обновляется несколько раз за день.
Скорость поиска.
Такая функция как скорость поиска теснейшим образом связана с так называемой «устойчивостью к нагрузкам». Ежесекундно к поиску обращается огромное количество людей, подобная загруженность требует значительного сокращения времени для обработки одного запроса. Тут интересы, как поисковой системы, так и пользователя целиком совпадают: посетитель хочет получить результаты как можно быстрее, а поисковая система должна отработать его запрос тоже максимально быстро, чтобы не притормозить обработку последующих запросов.
Ежесекундно к поиску обращается огромное количество людей, подобная загруженность требует значительного сокращения времени для обработки одного запроса. Тут интересы, как поисковой системы, так и пользователя целиком совпадают: посетитель хочет получить результаты как можно быстрее, а поисковая система должна отработать его запрос тоже максимально быстро, чтобы не притормозить обработку последующих запросов.
Наглядность.
Наглядное представление результатов является важнейшим элементом удобства поиска. По множеству запросов поисковая система находит тысячи, а в некоторых случаях и миллионы разных документов. Вследствие нечеткости составления ключевых фраз для поиска или его не точности, даже самые первые результаты запроса не всегда имеют только нужные сведения.
Это значит, что человеку часто приходится осуществлять собственный поиск среди предоставленных результатов. Разнообразные компоненты страниц выдачи ПС помогают ориентироваться в поисковых результатах.
История развития поисковых систем
Когда интернет только начал развиваться, число его постоянных пользователей было небольшим, и объем информации для доступа был сравнительно невеликим. В основном доступ к этой сети имели лишь специалисты научно-исследовательских сфер. В то время, задача нахождения информации не была столь актуальна как сейчас.
Одним из самых первых методов организации широкого доступа к ресурсам информации стало создание каталогов сайтов, причем ссылки на них начали группировать по тематике. Таким первым проектом стал ресурс Yahoo.com, который открылся весной 1994-ого года. Впоследствии когда количество сайтов в Yahoo-каталоге существенно увеличилось, была добавлена опция поиска необходимых сведений по каталогу. Это еще не было в полной мере поисковой системой, так как область такого поиска была ограничена только сайтами, входящими в данный каталог, а не абсолютно всеми ресурсами в интернете. Каталоги ссылок весьма широко использовались раньше, однако в настоящее время, практически в полной мере утратили свою популярность.
Ведь даже сегодняшние, громадные по своим объемам каталоги имеют информацию о незначительно части сайтов в интернете. Самым известным и большим каталогом в мире был DMOZ (прекратил работу 14 марта 2017 года) имеет информацию о пяти миллионах сайтов, когда база Google содержит информацию о более чем 25 миллиардов страниц.
Самой первой настоящей поисковой системой стала WebCrawler, возникшая еще в 1994-ом году.
В следующем году появились AltaVista и Lycos. Причем первая была лидером по поиску информации очень длительное время.
В 1997-ом году Сергей Брин вместе с Ларри Пейджем создал машину поисковую Google как исследовательский проект в Стэндфордском университете. Сегодня именно Google, самая востребованная и популярная поисковая система в мире.
В сентябре 1997-ом году была анонсирована (официально) ПС Yandex, которая в настоящий момент является самой популярной системой поиска в Рунете.![]()
Доля поисковых систем
По данным на апрель 2020 года, доли поисковых систем в мире распределены следующим образом:
- Google — 70,83 %;
- Bing — 12,61 %;
- Baidu — 11,83 %;
- Yahoo! — 2,30 %;
- Яндекс — 1,41 %;
- DuckDuckGo — 0,42 %;
По данным на апрель 2020 года, доли поисковых систем в Рунете (данные сервиса Яндекс.Радар):
- Яндекс — 59,10%
- Google — 38,85%
- Поиск.Mail.ru — 1,18%
- Rambler — 0,07%
- Остальные — 0,80%
Принципы работы поисковой системы
В России главной системой поиска является Яндекс, затем Google, а потом Поиск@Mail.ru. Все большие системы поиска имеют свою структуру, которая весьма отличается от других. Но все-таки можно выделить общие для всех поисковиков основные элементы.
Модуль индексирования.
Данный компонент состоит из трех программ-роботов:
Spider (по англ. паук) – программа которая предназначена для того чтобы скачивать веб-страницы. «Паук» скачивает определенную страницу, одновременно извлекая из нее все ссылки. Скачивается код html практически с каждой страницы. Для этого роботы используют HTTP-протоколы.
«Паук» функционирует следующим образом. Робот передает запрос на сервер “get/path/document” и иные команды запроса HTTP. В ответ программа-робот получает поток текста, который содержит информацию служебного вида и, естественно, сам документ.
Извлекаются все ссылки из тэгов. Вместе с ними обрабатывают редиректы. Любая скачанная страница сохраняется в таком формате:
- URL скаченной страницы;
- дата, когда осуществлялось скачивание страницы;
- заголовок http-ответа сервера;
- html-код, «тела» страницы.

Crawler («путешествующий» паук). Данная программа автоматически заходит на все ссылки, которые найдены на странице, а также выделяет их. Его задача – определиться, куда в дальнейшем должен заходить паук, основываясь на этих ссылках или исходя из заданного списка адресов.
Crawler, исследуя найденные ссылки, ищет новые документы, еще не ставшие известными поисковой системе.
Indexer (робот-индексатор) – это программа, анализирующая страницы, которые скачали пауки.
Индексатор полностью разбирает страницу на составные элементы и проводит их анализ, применяя свои морфологические и лексические виды алгоритмов.
Анализ проводится над разнообразными частями страницы, такими как заголовки, текст, ссылки, стилевые и структурные особенности, теги html и др.
Таким образом, модуль индексирования дает возможность проходить по ссылкам заданного количества ресурсов, скачивать страницы, извлекать ссылочную массу на новые страницы из полученных документов и делать подробный их анализ.
База данных
База данных (или индекс поисковика) — комплекс хранения данных, массив информации в котором сохраняются определенным образом переделанные параметры каждого обработанного модулем индексации и скачанного документа.
Поисковый сервер
Это самый важный элемент всей системы, потому что от алгоритмов, лежащих в основе ее функциональности, прямо зависит скорость и, конечно же, качество поиска.
Поисковый сервер работает следующим образом:
- Запрос, который идет от пользователя подвергается морфологическому анализу. Информационное окружение любого документа, имеющегося в базе, генерируется (оно и будет в дальнейшем отображаться как сниппет, т.е. информационное поле текста соответствующего данному запросу).
- Полученные данные передают как входные параметры специализированному модулю ранжирования. Они обрабатываются по всем документам, и в итоге для каждого такого документа рассчитывается свой рейтинг, который характеризует релевантность такого документа запросу пользователя, и иных составляющих.

- В зависимости от условий заданных пользователем этот рейтинг вполне может быть подкорректирован дополнительными.
- Затем генерируется сам сниппет, т.е. для любого найденного документа из соответствующей таблицы извлекают заголовок, аннотацию, наиболее отвечающую запросу, и ссылка на этот документ, при этом найденные словоформы и слова подсвечивают.
- Результаты полученного поиска передаются осуществившему его человеку в виде страницы, на которую выдают поисковые результаты (SERP).
Все эти элементы тесно связаны между собой и функционируют, взаимодействуя, образовывая отчетливый, но достаточно непростой механизм функционирования ПС, требующий громадных затрат ресурсов.
что это, виды, как устроена
Поисковая система (ПС) — это набор алгоритмов, позволяющих проводить поиск в интернете. Характерная особенность ПС — мгновенное нахождение информации по конкретной фразе или определенному слову. Благодаря процессу индексирования она способна сканировать и затем извлекать данные из миллионов документов. И все это — за считанные миллисекунды.
Благодаря процессу индексирования она способна сканировать и затем извлекать данные из миллионов документов. И все это — за считанные миллисекунды.
Присоединяйтесь к нашему Telegram-каналу!
- Теперь Вы можете читать последние новости из мира интернет-маркетинга в мессенджере Telegram на своём мобильном телефоне.
- Для этого вам необходимо подписаться на наш канал.
История поисковых систем
Первой ПС принято считать W3Catalog — она появилась в 1993 году. W3Catalog представлял из себя не классическую поисковую машину (ПМ), а скорее обычный каталог, содержащий списки сайтов / адресов. Полноценная ПМ в интернете появилась в 1994 году: и это была вовсе не Google, а Aliweb 🙂
W3Catalog доступен и в 2022 году. Пример сайтов — в разделе Media and EntertainmentAliweb первой в мире начала обрабатывать контент сайтов: сканировать, индексировать его, перемещая в собственный индекс.
Но даже у Aliweb еще не было краулеров в привычном для нас понимании, т. е. для автоматического сканирования всех новых страниц. Информацию о новых сайтах добавляли сами вебмастеры: они указывали названия и ключевые слова для каждой страницы в общую базу данных (БД), которую позже и сканировал Aliweb.
За несколько десятилетий было создано свыше тысячи разнообразных ПС. Лишь десятки из них сумели дойти до наших дней и остаются работоспособными сегодня. Самыми популярными поисковыми системами в России уже долгие годы остается Google и «Яндекс».
Самые популярные ПС в мире. Динамика с 2014 по 2021 годыКак устроены поисковые системы
Если проводить аналогию с нецифровым миром, ПС — это картотека в библиотеке, где у каждой книги есть свой уникальный номер. По этому номеру ее можно найти в каталоге.
Упрощенный алгоритм работы таков:
- Пользователь указывает поисковый запрос.
- ПС анализирует весь ранее собранный индекс и находит документы, которые ему максимально релевантны.

- Наиболее релевантные документы сортируются: от наиболее близких поисковому запросу к наименее.
- Результаты выводятся на странице поисковой выдачи.
Что такое краулер поисковой системы
Краулер — это специальная программа, используемая ПС для перехода по URL, которые он обнаруживает на веб-странице. Затем краулер помечает такие ссылки специальным образом.
Благодаря найденным URL поисковый робот находит все новые и новые страницы (о которых ПС не знала ранее)Последовательность работы ПС: этапы обработки документа
Поисковая система состоит из трех компонентов:
Далее поговорим о том, как индексирование документов помогает функционировать поисковым системам.
Зачем поисковым системам нужен индекс
Индекс по своей сути — это просто база данных, необходимая для ускорения поискового процесса: извлечения данных о документах, обработки и представлении результатов поиска пользователю. Любые данные из индексной БД «вынимаются» за миллисекунды, ведь в индексе ПС уже хранится информация обо всех страницах в интернете.
Индексация — извлечение важных для ПС данных и дальнейшая их конвертация в понятные поисковой системе форматы
Кэш поисковой системы нужен для ускорения экстракции данных (по аналогии, например, с разархивированием архива в WinRar) с ранее посещенных веб-страниц.
ПС хранят индекс не просто так: они обращаются к нему в дальнейшем, при работе с запросами. Так что хранить эту базу данных где-то, в любом случае, нужно.
Читайте также:
Индексация в поисковых системах: что это простыми словами
Как поисковые системы хранят индекс на своей стороне
Google хранит документы фрагментарно или полностью на своих серверах. Само хранение происходит в кэше (это отдельная память, обладающая высокой скоростью доступа). Другие поисковики хранят только определенные фразы или каждое слово и связывают его с документом в дальнейшем.
Как ПС обновляют свой индекс и базы данных
В среде SEO-специалистов обновления индекса систем называются апдейтами выдачи. У каждой поисковой системы такие апдейты происходят по-разному. Google добавляет новые документы в свой индекс ежедневно, причем несколько раз в сутки. «Яндекс» действует по-другому — новые страницы попадают в индекс произвольно (апдейт происходит 2 раза в неделю, например).
У каждой поисковой системы такие апдейты происходят по-разному. Google добавляет новые документы в свой индекс ежедневно, причем несколько раз в сутки. «Яндекс» действует по-другому — новые страницы попадают в индекс произвольно (апдейт происходит 2 раза в неделю, например).
Самыми важными факторами является суммарная релевантность ключевой фразы и подобранного документа, проработанность индекса и особенности морфологических параметров языка пользователя.
Виды поисковых систем
Выделим три классификации:
- По особенностям использования индекса.
- По типу индекса.
- По области поиска.
I По особенностям использования индекса
Безиндексные ПС
Это мультипотоковые системы, которые функционируют через крупные поисковые системы. Безиндексные системы просто агрегатируют их результаты поиска и проводят собственную сортировку.
Примеры: Bing (Microsoft Bing), AskNet, Quintura, Ixuick, MetaCrawler.
«Нигма» — самая известная российская метапоисковая система (ныне не существует)Классические поисковые машины
Еще говорят «поисковый движок», «поисковые машины с индексом». Пауки ПС сканируют все страницы в интернете, затем формируют собственный индекс (базы данных) с информацией о веб-документах. Поиск по БД в случае классической поисковой машины, условно, состоит из трех этапов:
Пауки ПС сканируют все страницы в интернете, затем формируют собственный индекс (базы данных) с информацией о веб-документах. Поиск по БД в случае классической поисковой машины, условно, состоит из трех этапов:
- Нахождение наиболее релевантного поисковой фразе документа.
- Ранжирование остальных документов исходя из их суммарной релевантности.
- Кластеризация документов.
Кроме этих функций, маркер классической ПМ — разные методы поиска ссылок в ручном и автоматическом режимах. В первом случае их добавляют в поисковую машину сами вебмастеры, во втором — краулеры сканируют сеть самостоятельно.
Google имеет черты гибридной ПСПримеры: Google и «Яндекс».
Гибридные ПС
Относятся к классическим поисковым машинам, однако с неким допущением можно выделить их и в отдельную категорию.
Индекс здесь собирается не только за счет сканирования краулером ПС, но и благодаря пользовательским источникам данных: реестрам документов, каталогам, справочникам.
Примеры: Yahoo, «Яндекс», Google.
«Яндекс» — поисковая машина гибридного типаЧитайте также:
Отличия SEO под Яндекс и Google
Каталожные поисковые системы
Это пользовательские БД, где все данные добавляются вручную. Качество результатов поиска в таких ПС в теории должно быть заметно выше, чем в автогенерируемых системах.
Они могут выглядеть как рубрикатор заданной иерархии с большим количеством категорий и подкатегорий. Для каждого сайта указывается описание контента, заголовок и ссылка на страницу.
ПС Open Directory Project (также известная как dmoz). Больше не существуетПримеры: Russia on the Net, AtRus, Yahoo!, Directory (сейчас некоторые уже не существуют).
II По типу индекса
В 2022 году массово распространены два типа ПС: с инвертированным индексом и с индексом, имеющим предопределенное расположение ключевых слов. Разница между ними легко прослеживается.
Разница между ними легко прослеживается.
Инвертированный индекс (ИИ)
Для слов в наборе документов указаны все страницы в реестре, где они упоминались. В свою очередь, сам ИИ может быть двух видов:
- Лист документов для каждого слова.
- Лист документов для каждого слова + позиция слова в каждом веб-документе.
Пример: Google.
Индекс с предопределенным расположением ключевых слов (устаревший)
Все фразы упорядочены и отсортированы уже изначально по иерархическому принципу. В настоящий момент не известно ни одной крупной поисковой машины с этим типом индекса.
III По области поиска
Локальная ПС
Отдельностоящее ПО либо веб-приложение, которое разворачивается на компьютере пользователя и позволяет искать информацию, например, на жестком диске или в в пределах домашней сети.
Spotlight для операционной системы Mac OS — локальная поисковая системаПримеры: Tracker, Copernic Desktop Search.
Глобальная ПС
Веб-сайт / веб-приложение / сервис для поиска документов во всем интернете (или, например, в пределах конкретной доменной зоны).
Примеры: Google, Bing, Yandex, Baidu.
При этом они могут содержать в себе элементы локальных поисковых систем: например, поиск в определенной доменной зоне или поддержка китайского языка по умолчанию, как Baidu. Есть также национальные ПС, созданные для использования в конкретной стране — наши «Спутник» и «Поиск Mail.ru».
Также существуют поисковые системы для поиска информации только в определенных каналах. Например:
- на новостных сайтах;
- внутри FTP-хранилищ.
- в RSS-каналах;
- в библиотечных ресурсах;
- в интернет-магазинах;
- в юзнете.
Юзнет — это глобальная компьютерная сеть для интернет-дискуссий и публикации файлов, состоит из набора групп новостей, организованных по темам. Пользователи размещают статьи или сообщения в этих группах новостей. Затем эти материалы публикуются уже на других платформах.
Что нужно знать о поисковых системах вебмастеру и пользователю
Поисковая система — это сложный набор алгоритмов, которые работают внутри единой компьютерной программы.
Чтобы новая страница сайта отображалась в результатах поиска, она должна попасть в индекс. Краулеры ПС автоматически обходят все страницы в интернете, добавляя их в специальную базу данных. Обрабатывается также и содержимое страниц.
Читайте также:
Факторы ранжирования Google и «Яндекс»: что это и как работает
Поисковая выдача зависит от суммарной релевантности документа по отношению к запросу. У каждой ПС свои методы определения релевантности, и подробно о них узнать нельзя. Известно лишь об общих принципах оценки:
- Семантический анализ слов в запросе, включая слова в поисковых фразах вместе и по отдельности.
- Идентифицирование типа запроса.
- Интерпретация орфографических ошибок.
- Определение синонимичности запроса.
- Сопоставление поисковой фразы с особенностями языковой модели.

- Определение актуальности информации.
- Определение региональности запроса.
СДЕЛАЕМ САЙТ, КОТОРЫЙ НРАВИТСЯ ПОИСКОВЫМ СИСТЕМАМ
Сайт
Телефон
Что такое поисковые системы и как они работают?
Что такое поисковая система?
Поисковая система — это онлайн-инструмент, предназначенный для поиска веб-сайтов в Интернете на основе поискового запроса пользователя.
Ищет результаты в собственной базе данных, сортирует их и составляет упорядоченный список этих результатов, используя уникальные алгоритмы поиска. Этот список называется страницей результатов поисковой системы (SERP).
Хотя в мире существуют различные поисковые системы (например, Google, Bing, Yahoo и т. д.), общие принципы поиска и предоставления ответов одинаковы во всех них.
Как работают поисковые системы
Поисковые системы могут отличаться друг от друга по способам предоставления ответов пользователю, но все они построены на трех фундаментальных принципах:
- Сканирование
- Индексация
- Рейтинг
1.
 Сканирование
СканированиеФактическое обнаружение новых веб-страниц в Интернете начинается с процесса, называемого сканированием.
Поисковые системы используют небольшие программы, называемые поисковыми роботами (иногда называемые ботами или роботами-пауками), которые переходят по ссылкам с уже известных страниц на новые, которые необходимо открыть.
Каждый раз, когда поисковый робот находит новую веб-страницу по ссылке, он сканирует и передает ее содержимое для дальнейшей обработки (так называемой индексации) и продолжает обнаружение новых веб-страниц.
2. Индексирование
После того, как боты просканируют данные, наступает время индексации — процесса проверки и сохранения содержимого веб-страниц в базе данных поисковой системы, которая называется «индекс». Это в основном большая библиотека всех веб-сайтов.
Ваш веб-сайт должен быть проиндексирован, чтобы он отображался на странице результатов поисковой системы. Имейте в виду, что и сканирование, и индексирование — это непрерывные процессы, которые выполняются снова и снова, чтобы поддерживать базу данных в актуальном состоянии.
После того, как веб-страница проанализирована и сохранена в индексе, ее можно использовать в качестве результата поиска для потенциального поискового запроса.
3. Ранжирование
Последний шаг включает в себя выбор лучших результатов и создание списка страниц, которые будут отображаться на странице результатов.
Каждая поисковая система использует десятки сигналов ранжирования, и большинство из них держится в секрете, недоступном для общественности.
Как сказал Мартин Сплитт, аналитик тенденций для веб-мастеров:
«У нас есть более 200 сигналов для этого. Поэтому мы смотрим на такие вещи, как заголовок, мета-описание, фактический контент, который есть на вашей странице, изображения, ссылки и многое другое». (Мартин Сплитт, аналитик тенденций для веб-мастеров)
Что такое алгоритм поисковой системы?
Алгоритм поисковой системы — это термин, используемый для определения сложной системы из нескольких алгоритмов, которая оценивает все проиндексированные страницы и определяет, какие из них должны отображаться в результатах поиска по заданному запросу.
Например, алгоритм Google использует десятки факторов (многие из них хорошо известны, а некоторые держат в секрете) в нескольких областях, таких как:
- Значение запроса (понимание того, что пользователь означает использование точных слов, которые они использовали, какова цель поиска и т. д.)
- Релевантность страницы (поисковику необходимо узнать, отвечает ли страница на поисковый запрос)
- Качество контента (алгоритмы определяют, являются ли веб-страницы отличным источником информации на основе внутренних и внешних факторов; здесь важны количество и качество обратных ссылок)
- Удобство использования страницы (учитывает качество веб-страницы с технической точки зрения — отзывчивость, скорость страницы, безопасность и т. д.)
Поисковая оптимизация
Поисковые системы не только предоставляют пользователям полезную информацию, но и помогают брендам продвигать свои веб-сайты.
Оптимизация вашего веб-сайта для релевантных поисковых запросов является важной частью любой стратегии онлайн-маркетинга, поскольку она может привлечь больше трафика на ваши веб-страницы.
Сумма всех практик и методов, которые владельцы веб-сайтов используют для улучшения своего поискового рейтинга, называется поисковой оптимизацией (SEO).
Если бы мы хотели упростить SEO, мы могли бы сказать, что все вращается вокруг трех наиболее важных факторов:
- Техническая оптимизация
- Отличный контент
- Качественные обратные ссылки
Какие поисковые системы самые популярные?
Хотя в мире существуют сотни поисковых систем, лишь немногие из них доминируют на общем рынке поисковых систем и остаются популярными благодаря своему качеству, полезности и т. д. годы. Это список 5 самых популярных поисковых систем:
1. Google
Google — крупнейшая и самая популярная поисковая система в мире.
Компания Google, принадлежащая материнской компании Alphabet, доминирует на рынке поисковых систем, занимая более 90 процентов мирового рынка.
Благодаря всем своим функциям, включая сложные алгоритмы, эффективное сканирование, индексирование и ранжирование, Google обеспечивает отличные результаты поиска не только в своей собственной поисковой системе, но и в некоторых других поисковых системах (например, ask.com).
2. Microsoft Bing
Bing — вторая по величине поисковая система. Он был запущен в 2009 году и принадлежит Microsoft.
Хотя невозможно сравнивать Bing как реального соперника Google, занимающего всего 2–3 процента от общей доли рынка поисковых систем, это все же отличная альтернатива для тех, кто хотел бы попробовать что-то другое.
Microsoft Bing во многом похож на Google, предоставляя такие типы результатов поиска, как изображения, видео, места, карты или новости.
Хотя Bing использует основные принципы поисковых систем (сканирование, индексирование, ранжирование), он также использует специальный алгоритм под названием «Дерево разделов пространства и график», основанный на векторах для категоризации информации и ответов на поисковые запросы.
3. Yahoo!
Yahoo — популярный веб-сайт, провайдер электронной почты и третья по величине поисковая система в мире, на долю которой приходится почти 2% общей доли рынка поисковых систем.
Некогда очень популярная и доминирующая поисковая система Yahoo с годами падала в цене и стала несколько затмеваться Google.
В настоящее время Yahoo конкурирует с более мелкими поисковыми системами, такими как Bing или DuckDuckGo.
4. Яндекс
Яндекс (от термина « Y et Another i NDEX er») — поисковая система, популярная в основном в восточных странах.
Хотя на нее приходится менее 1 процента общей доли рынка поисковых систем, она является одной из самых популярных поисковых систем в таких странах, как Россия (более 60 процентов всех поисковых запросов в стране), Турция, Украина или Беларусь.
Подобно Google, Яндекс предоставляет различные виды услуг, включая Карты, Переводчик, Яндекс Деньги и даже Яндекс Музыку.
5. Baidu
Baidu является самой доминирующей поисковой системой в Китае. Несмотря на то, что его общая доля на мировом рынке составляет всего 1 процент, на него приходится более 80 процентов доли рынка в Китае с миллиардами поисковых запросов каждый день.
Baidu во многом похож на Google. Он предоставляет классические синие ссылки с зелеными URL-адресами и показывает расширенные результаты так же, как это делает Google.
Часто задаваемые вопросы
Ответим на несколько часто задаваемых вопросов о поисковых системах.
Почему Google является самой популярной поисковой системой?
Google, как поисковая система, уже много лет является лидером в своей отрасли и до сих пор доминирует на рынке поисковых систем. Есть несколько причин, по которым Google является наиболее широко используемой поисковой системой.
- Одна из первых поисковых систем
- Предлагает релевантные результаты
- Быстро
- Постоянно совершенствуется
- Подключен к нескольким бесплатным сервисам
Как поисковые системы зарабатывают деньги?
Основным источником дохода поисковых систем, таких как Google, являются различные косвенные источники. Поисковые системы могут монетизировать свои услуги через:
Поисковые системы могут монетизировать свои услуги через:
- Реклама — Google использует собственный рекламный сервис под названием Google Ads, благодаря которому он может помогать брендам отображать свои продукты в результатах поиска, а взамен берет небольшую комиссию каждый раз, когда пользователь кликает по объявлению.
- Интернет-магазины — поисковые системы могут продвигать различные продукты в расширенных результатах поиска. Если пользователь нажимает или покупает один из продуктов, поисковая система взамен берет небольшой процент от покупки.
- Службы — Google объединяет свои службы (например, Play Store, Google Cloud, Google Apps и т. д.) со своей собственной поисковой системой и, следовательно, получает доход от клиентов, которые их используют.
Какой была первая поисковая система?
Archie (от названия «Архив») — первая поисковая система, созданная в 1990 году студентом Аланом Эмтаджем.
Хотя и раньше существовало несколько программ индексации (например, «X.500» или «Whois»), Archie была первой настоящей поисковой системой, способной находить определенные файлы в Интернете.
Archie работал довольно просто — он просматривал доступные в Интернете сайты и индексировал их как загружаемые файлы. Однако он не мог индексировать содержимое сайтов и поэтому страницы результатов имели вид простого списка.
В чем разница между браузером и поисковой системой?
Веб-браузер (например, Chrome, Firefox, Microsoft Edge и т. д.) — это программное приложение, которое устанавливается на компьютер или смартфон. Целью браузера является предоставление удобного интерфейса для отображения веб-страниц.
Поисковая система (например, Google, Bing, Yahoo! и т. д.) — это онлайн-инструмент, доступный на веб-сайте, к которому можно получить доступ через веб-браузер. Цель поисковой системы — предоставлять ответы на запросы пользователей в виде соответствующих веб-страниц.
Что такое поисковые системы и как они работают?
Поисковая система — это программа, предоставляющая информацию в соответствии с запросом пользователя. Он находит различные веб-сайты или веб-страницы, доступные в Интернете, и дает соответствующие результаты в соответствии с поиском. Например, студент хочет выучить язык C++, поэтому он ищет в поисковой системе «C++ tutorial GeeksforGeeks». Таким образом, студент получает список ссылок, содержащих ссылки на учебники GeeksforGeeks. Или мы можем сказать, что поисковая система — это интернет-программа, основной задачей которой является сбор большого количества данных или информации о том, что находится в Интернете, затем классификация данных или информации, а затем помощь пользователю в поиске необходимой информации. из классифицированной информации. Google, Yahoo, Bing — самые популярные поисковые системы.
Как работают поисковые системы?
Поисковые системы, как правило, работают над тремя частями: сканированием, индексированием и ранжированием. Эти программы сканируют Интернет и создают список всех доступных веб-сайтов. Затем они посещают каждый веб-сайт и, читая HTML-код, пытаются понять структуру страницы, тип содержимого, значение содержимого, а также время его создания или обновления. Почему важно ползать? Потому что ваша первая забота при оптимизации вашего веб-сайта для поисковых систем — убедиться, что они могут получить к нему правильный доступ. Если они не смогут найти ваш контент, вы не получите ни рейтинга, ни трафика из поисковых систем.
Эти программы сканируют Интернет и создают список всех доступных веб-сайтов. Затем они посещают каждый веб-сайт и, читая HTML-код, пытаются понять структуру страницы, тип содержимого, значение содержимого, а также время его создания или обновления. Почему важно ползать? Потому что ваша первая забота при оптимизации вашего веб-сайта для поисковых систем — убедиться, что они могут получить к нему правильный доступ. Если они не смогут найти ваш контент, вы не получите ни рейтинга, ни трафика из поисковых систем.
2. Индексирование: Информация, идентифицированная сканером, должна быть организована, отсортирована и сохранена, чтобы ее можно было позже обработать алгоритмом ранжирования. Поисковые системы не хранят всю информацию в вашем индексе, но они сохраняют такие вещи, как заголовок и описание страницы, тип контента, связанные ключевые слова, количество входящих и исходящих ссылок и множество других параметров, которые необходимы Алгоритм ранжирования. Почему важна индексация? Поскольку, если ваш веб-сайт не находится в их индексе, он не будет отображаться ни в одном поиске, это также означает, что если у вас есть проиндексированные страницы, у вас больше шансов появиться в результатах поиска по соответствующему запросу.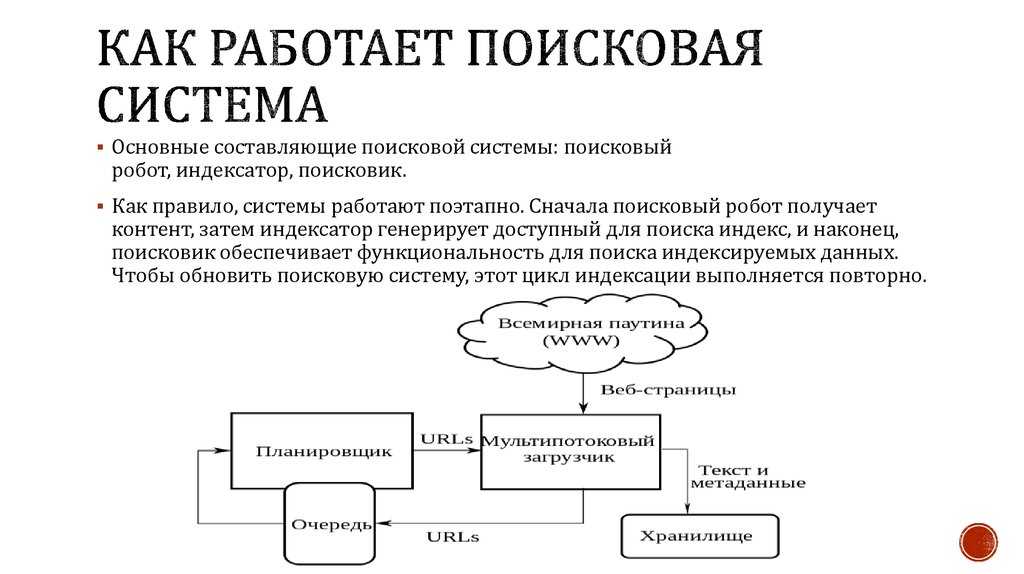
3. Рейтинг: Рейтинг — это позиция, на которой ваш веб-сайт находится в любой поисковой системе. (Есть три шага, на которых работает ранжирование).
- Шаг 1: Анализ пользовательского запроса. Этот шаг позволяет понять, какую информацию ищет пользователь. Для этого проанализируйте запрос пользователя, разбив его на ряд значимых ключевых слов. Ключевое слово — это слово, которое имеет определенное значение и цель, например, когда вы вводите, как сделать шоколадный кекс, поисковые системы знают, что вы ищете конкретную информацию, поэтому результаты будут содержать рецепты и пошаговые инструкции. Они также могут понять значение слова «как заменить лампочку» так же, как «заменить лампочку». Поисковые системы достаточно умны, чтобы интерпретировать и орфографические ошибки.
- Шаг 2: Поиск подходящих страниц. Этот шаг заключается в просмотре их индекса и поиске наиболее подходящих страниц, например, если вы ищете темные обои, это дает вам изображения, а не текст.

- Шаг 3: Представление результатов пользователям. Типичная страница результатов поиска включает десять обычных результатов, в большинстве случаев она обогащена другими элементами, такими как платная реклама, прямые ответы на определенные запросы и т. д.
Эффективность поиска Двигатель
Производительность поисковой системы определяется двумя требованиями. Это:
- Эффективность (качество результата).
- Эффективность (время отклика и пропускная способность).
Компоненты поисковой системы
В поисковой системе есть три компонента. Это веб-сканер, база данных и поисковый интерфейс:
- Веб-сканер: Поисковая система использует несколько веб-сканеров для сканирования всемирной паутины и сбора информации. Это в основном программное обеспечение, которое также известно как летучая мышь или паук.
- База данных: Информация, собираемая поисковым роботом при сканировании через Интернет, хранится в базе данных.

- Интерфейс поиска: Интерфейс поиска — это просто интерфейс к базе данных, который используется пользователем для поиска в базе данных.
В основном есть два строительных блока, которые выполняют различные действия.
- Индексация
- Запрос
- Индексирование: Индексирование Индексирование выполняет в основном 3 действия: получение текста, создание индекса преобразования текста.
i) Получение текста: Получение текста в основном идентифицирует и сохраняет документы в базе данных для индексации.
- Он преобразует различные документы в единый формат данных.
- Он также хранит текстовые метаданные и другую связанную информацию документа.
ii) Преобразование текста: Преобразует документ в проиндексированные термины.
- Синтаксический анализатор : Он распознает «слова» в тексте с помощью токенизатора и обрабатывает последовательность текстовых токенов для распознавания структурного шаблона.
- Остановка: Удаляет стоп-слова, такие как «и», «или», «the».
- Основа: Объединяет все слова, происходящие от одной основы.
- Анализ ссылок: Используется для определения популярности страницы. Он использует ссылки и якорный текст с веб-страниц.
- Извлечение информации: Извлечение информации идентифицирует классы индексных терминов, которые важны для некоторых приложений.
- Классификатор: Идентифицирует относящиеся к классу данные документа.
iii) Создание индекса:
- Статистика документа: Собирает такие функции, как положение и количество слов.
- Взвешивание: Вычисляет веса элементов индекса.

- Инверсия: Поскольку формат инвертированных файлов является быстрым для обработки запросов, он преобразует информацию термина документа в информацию термина документа
2. Запрос: Он состоит из следующих трех задач предоставляет интерфейс и парсер для языка запросов. Затем он преобразует запрос, улучшая запрос. Затем он показывает вывод, создавая отображение ранжированных документов для запроса.
Использование поисковой системы
Поисковые системы имеют так много применений, и некоторые из них:
- Поиск информации: Люди используют поисковую систему для поиска любой информации в Интернете. Например, Рохит хочет купить мобильный телефон, но не знает, какой из них лучше.
 Поэтому он ищет в поисковой системе «лучшие мобильные телефоны 2021 года» и получает список лучших мобильных телефонов вместе с их функциями, обзорами и ценами.
Поэтому он ищет в поисковой системе «лучшие мобильные телефоны 2021 года» и получает список лучших мобильных телефонов вместе с их функциями, обзорами и ценами. - Поиск изображений и видео: Поисковые системы также используются для поиска изображений и видео. В Интернете доступно так много видео и изображений в различных категориях, таких как растения, животные, цветы и т. д., вы можете искать их в соответствии с вашими потребностями.
- Место поиска: Поисковые системы также используются для поиска мест. Например, Сима путешествует по Гоа, но не знает, где находится пляж Палолем. Поэтому она ищет «пляж Палолем» в поисковой системе, а затем поисковая система выдает лучший маршрут, чтобы добраться до пляжа Палолем.
- Поиск людей: Поисковые системы также используются для поиска людей в Интернете по всему миру.
- Покупки: поисковые системы также используются для совершения покупок. Поисковые системы оптимизируют страницы под нужды пользователя и выдают списки всех сайтов, содержащих указанный товар, по лучшей цене, отзывам, бесплатной доставке и т.
 д.
д. - Развлечения: Поисковые системы также используются в развлекательных целях. Он используется для поиска видео, фильмов, игр, трейлеров к фильмам, обзоров фильмов, сайтов социальных сетей и т. д. Например, Рохан хочет посмотреть фильм под названием «Рам», затем он ищет этот фильм в поисковой системе, а поиск движок возвращает список ссылок (веб-сайтов), содержащих фильм Ram.
- Образование: Поисковые системы также используются в образовательных целях. С помощью поисковых систем люди могут узнать все, что они хотели, например, кулинарию, языки программирования, украшения для дома и т. д. Это похоже на открытую школу, где вы можете научиться чему угодно бесплатно.
Как мы используем поисковую систему?
Поисковые системы просты в использовании. Ежедневно с помощью поисковых систем выполняются миллиарды поисковых запросов. По оценкам, в день выполняется более 5,6 миллиардов поисковых запросов. Например, поиск в Google, поэтому для этого просто откройте веб-браузер. Затем введите «www.google.com» в строке поиска веб-браузера и нажмите «Ввод». Затем откроется поисковая система Google, и теперь мы готовы искать любую информацию в поисковой системе Google. Всегда помните, что не все результаты, возвращаемые поисковой системой, могут быть релевантны поиску, потому что она будет возвращать результаты поиска, в которых есть поисковые слова, и они не обязательно расположены в том же порядке, в котором вы их ввели.
Затем введите «www.google.com» в строке поиска веб-браузера и нажмите «Ввод». Затем откроется поисковая система Google, и теперь мы готовы искать любую информацию в поисковой системе Google. Всегда помните, что не все результаты, возвращаемые поисковой системой, могут быть релевантны поиску, потому что она будет возвращать результаты поиска, в которых есть поисковые слова, и они не обязательно расположены в том же порядке, в котором вы их ввели.
Например, нам нужно открыть веб-сайт GeeksforGeeks, чтобы выучить язык Python. Итак, мы пишем «geeksforgeeks Python» в строке поиска Google и нажимаем ввод, и вы увидите список ссылок, которые перенаправят вас на учебник по Python на портале GeeksforGeeks.
Как работают поисковые системы: сканирование, индексирование и ранжирование. Руководство для начинающих по SEO
Руководство для начинающих по SEO
Изучите главы:
Сначала покажитесь.
Как мы упоминали в главе 1, поисковые системы — это машины-ответчики. Они существуют для того, чтобы находить, понимать и систематизировать интернет-контент, чтобы предлагать наиболее релевантные результаты на вопросы, которые задают искатели.
Чтобы ваш контент отображался в результатах поиска, сначала он должен быть виден поисковым системам. Это, пожалуй, самая важная часть SEO-головоломки: если ваш сайт не может быть найден, вы никогда не появится в SERP (странице результатов поисковой системы).
Как работают поисковые системы?
Поисковые системы выполняют три основные функции:
- Сканирование: Поиск контента в Интернете, просмотр кода/контента каждого найденного URL.
- Индексирование: Храните и систематизируйте содержимое, найденное в процессе сканирования. Как только страница попадает в индекс, она начинает отображаться в результате соответствующих запросов.
- Рейтинг: Предоставляйте части контента, которые лучше всего отвечают на запрос пользователя, что означает, что результаты упорядочены от наиболее релевантных к наименее релевантным.

Что такое сканирование поисковыми системами?
Сканирование — это процесс обнаружения, при котором поисковые системы посылают команду роботов (известных как сканеры или пауки) для поиска нового и обновленного контента. Контент может быть разным — это может быть веб-страница, изображение, видео, PDF-файл и т. д. — но независимо от формата контент обнаруживается по ссылкам.
Что означает это слово?
Возникли проблемы с определением в этом разделе? Наш глоссарий SEO содержит определения для конкретных глав, которые помогут вам оставаться в курсе событий.
См. определения в главе 2.
Робот Googlebot сначала выбирает несколько веб-страниц, а затем переходит по ссылкам на этих веб-страницах, чтобы найти новые URL-адреса. Переходя по этому пути ссылок, сканер может найти новый контент и добавить его в свой индекс под названием Caffeine — обширную базу данных обнаруженных URL-адресов — для последующего извлечения, когда искатель ищет информацию о том, что контент на этом URL-адресе является хороший матч для.
Что такое индекс поисковой системы?
Поисковые системы обрабатывают и сохраняют информацию, которую они находят, в индексе, огромной базе данных всего контента, который они обнаружили и который они считают достаточно хорошим, чтобы предоставить его поисковикам.
Ранжирование в поисковых системах
Когда кто-то выполняет поиск, поисковые системы просматривают свой индекс в поисках релевантного контента, а затем упорядочивают этот контент в надежде найти ответ на запрос пользователя. Такое упорядочение результатов поиска по релевантности называется ранжированием. В общем, вы можете предположить, что чем выше рейтинг веб-сайта, тем более релевантным поисковая система считает этот сайт для запроса.
Можно заблокировать доступ сканеров поисковых систем к части или всему вашему сайту или запретить поисковым системам сохранять определенные страницы в своем индексе. Хотя для этого могут быть причины, если вы хотите, чтобы ваш контент был найден поисковиками, вы должны сначала убедиться, что он доступен для поисковых роботов и индексируется. В противном случае это так же хорошо, как невидимо.
В противном случае это так же хорошо, как невидимо.
К концу этой главы у вас будет контекст, необходимый для работы с поисковой системой, а не против нее!
В SEO не все поисковые системы одинаковы
Многие новички задаются вопросом об относительной важности отдельных поисковых систем. Большинство людей знают, что у Google самая большая доля рынка, но насколько важна оптимизация для Bing, Yahoo и других? Правда в том, что, несмотря на существование более 30 основных поисковых систем, SEO-сообщество обращает внимание только на Google. Почему? Короткий ответ: Google — это место, где подавляющее большинство людей ищут в Интернете. Если мы включим Google Images, Google Maps и YouTube (собственность Google), более 90% веб-поисков происходят в Google — это почти в 20 раз больше, чем Bing и Yahoo вместе взятые.
Сканирование: Могут ли поисковые системы найти ваши страницы?
Как вы только что узнали, проверка того, что ваш сайт сканируется и индексируется, является обязательным условием для появления в поисковой выдаче. Если у вас уже есть веб-сайт, было бы неплохо начать с просмотра того, сколько ваших страниц находится в индексе. Это даст отличное представление о том, сканирует ли Google и находит ли все страницы, которые вы хотите, и нет тех, которые вам не нужны.
Если у вас уже есть веб-сайт, было бы неплохо начать с просмотра того, сколько ваших страниц находится в индексе. Это даст отличное представление о том, сканирует ли Google и находит ли все страницы, которые вы хотите, и нет тех, которые вам не нужны.
Одним из способов проверки проиндексированных страниц является оператор расширенного поиска «site:yourdomain.com». Перейдите в Google и введите «site:yourdomain.com» в строку поиска. Это вернет результаты, которые Google имеет в своем индексе для указанного сайта:
Количество результатов, отображаемых Google (см. «О результатах XX» выше), не является точным, но дает четкое представление о том, какие страницы проиндексированы на вашем сайте и как они в настоящее время отображаются в результатах поиска.
Чтобы получить более точные результаты, отслеживайте и используйте отчет об индексировании в Google Search Console. Вы можете зарегистрировать бесплатную учетную запись Google Search Console, если у вас ее еще нет. С помощью этого инструмента вы можете, среди прочего, отправлять карты сайта для своего сайта и отслеживать, сколько отправленных страниц фактически добавлено в индекс Google.
С помощью этого инструмента вы можете, среди прочего, отправлять карты сайта для своего сайта и отслеживать, сколько отправленных страниц фактически добавлено в индекс Google.
Если вы нигде не отображаются в результатах поиска, тому может быть несколько возможных причин:
- Ваш сайт новый и еще не просканирован.
- На ваш сайт нет ссылок с каких-либо внешних веб-сайтов.
- Навигация вашего сайта затрудняет его эффективное сканирование роботом.
- Ваш сайт содержит базовый код, называемый директивами сканера, который блокирует поисковые системы.
- Google оштрафовал ваш сайт за рассылку спама.
Сообщите поисковым системам, как сканировать ваш сайт
Если вы использовали Google Search Console или оператор расширенного поиска «site:domain.com» и обнаружили, что некоторые из ваших важных страниц отсутствуют в индексе если неважные страницы были проиндексированы по ошибке, есть некоторые оптимизации, которые вы можете реализовать, чтобы лучше указать роботу Googlebot, как вы хотите, чтобы ваш веб-контент сканировался. Указание поисковым системам, как сканировать ваш сайт, может дать вам лучший контроль над тем, что попадает в индекс.
Указание поисковым системам, как сканировать ваш сайт, может дать вам лучший контроль над тем, что попадает в индекс.
Посмотрите, какие страницы Google может сканировать с помощью Moz Pro
Moz Pro может выявить проблемы с просматриваемостью вашего сайта, от критических проблем с поисковым роботом, которые блокируют Google, до проблем с контентом, влияющих на рейтинг. Воспользуйтесь бесплатной пробной версией и начните решать проблемы уже сегодня:
Начните мою бесплатную пробную версию
Большинство людей думают о том, чтобы Google мог найти их важные страницы, но легко забыть, что есть страницы, которые вы не хотите, чтобы робот Googlebot находил. К ним могут относиться такие вещи, как старые URL-адреса с недостаточным содержанием, повторяющиеся URL-адреса (например, параметры сортировки и фильтрации для электронной коммерции), специальные страницы с промо-кодами, промежуточные или тестовые страницы и т. д.
Чтобы отвести робота Googlebot от определенных страниц и разделов вашего сайта, используйте файл robots. txt.
txt.
Robots.txt
Файлы robots.txt расположены в корневом каталоге веб-сайтов (например, yourdomain.com/robots.txt) и указывают, какие части вашего сайта поисковые системы должны и не должны сканировать, а также скорость, с которой они сканируют ваш сайт, с помощью специальных директив robots.txt.
Как робот Googlebot обрабатывает файлы robots.txt
- Если робот Googlebot не может найти файл robots.txt для сайта, он продолжает его сканирование.
- Если робот Googlebot находит файл robots.txt для сайта, он обычно следует рекомендациям и продолжает сканирование сайта.
- Если робот Googlebot обнаруживает ошибку при попытке доступа к файлу robots.txt сайта и не может определить, существует ли он или нет, он не будет сканировать сайт.
Оптимизируйте краулинговый бюджет!
Бюджет сканирования — это среднее количество URL-адресов, которые робот Googlebot просканирует на вашем сайте перед тем, как уйти, поэтому оптимизация бюджета сканирования гарантирует, что робот Googlebot не будет тратить время на сканирование неважных страниц, рискуя проигнорировать важные страницы. Бюджет сканирования наиболее важен на очень больших сайтах с десятками тысяч URL-адресов, но никогда не будет плохой идеей заблокировать доступ сканеров к контенту, который вам определенно не нужен. Просто не блокируйте доступ сканера к страницам, на которые вы добавили другие директивы, такие как канонические теги или теги noindex. Если Googlebot заблокирован на странице, он не сможет увидеть инструкции на этой странице.
Бюджет сканирования наиболее важен на очень больших сайтах с десятками тысяч URL-адресов, но никогда не будет плохой идеей заблокировать доступ сканеров к контенту, который вам определенно не нужен. Просто не блокируйте доступ сканера к страницам, на которые вы добавили другие директивы, такие как канонические теги или теги noindex. Если Googlebot заблокирован на странице, он не сможет увидеть инструкции на этой странице.
Не все веб-роботы следуют файлу robots.txt. Люди с плохими намерениями (например, очистители адресов электронной почты) создают ботов, которые не следуют этому протоколу. На самом деле, некоторые злоумышленники используют файлы robots.txt, чтобы узнать, где вы разместили свой личный контент. Хотя может показаться логичным заблокировать сканеры на частных страницах, таких как страницы входа и администрирования, чтобы они не отображались в индексе, размещение этих URL-адресов в общедоступном файле robots.txt также означает, что люди со злым умыслом их легче найти.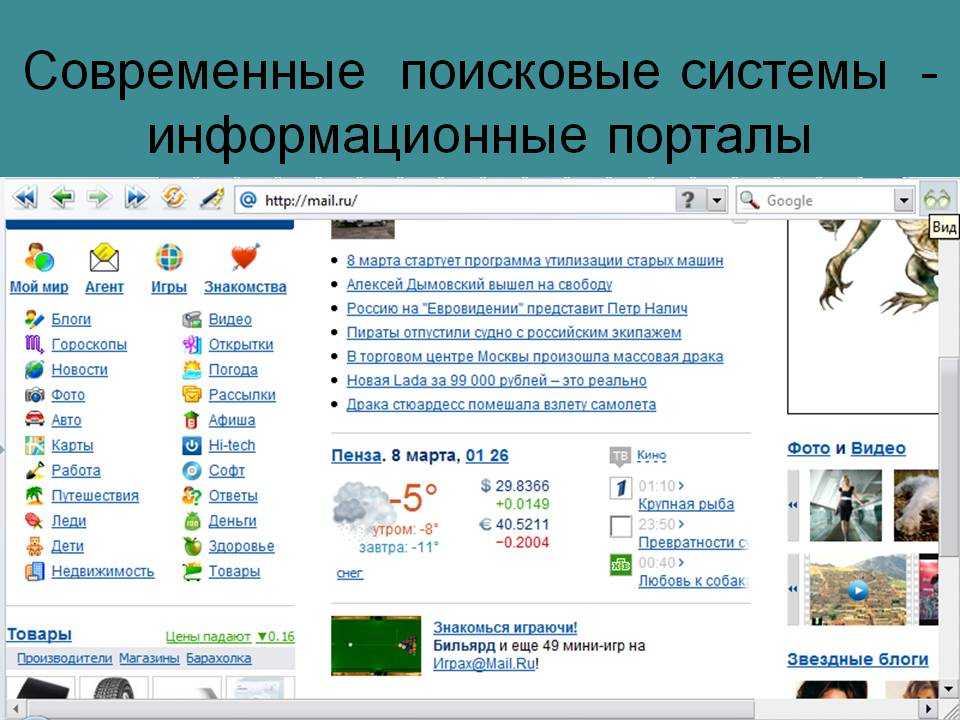 Лучше не индексировать эти страницы и скрывать их за формой входа, а не помещать их в файл robots.txt.
Лучше не индексировать эти страницы и скрывать их за формой входа, а не помещать их в файл robots.txt.
Подробнее об этом можно прочитать в разделе robots.txt нашего Центра обучения.
Определение параметров URL-адреса в GSC
Некоторые сайты (наиболее распространенные в сфере электронной коммерции) делают один и тот же контент доступным по нескольким различным URL-адресам, добавляя определенные параметры к URL-адресам. Если вы когда-либо делали покупки в Интернете, вы, вероятно, сузили область поиска с помощью фильтров. Например, вы можете выполнить поиск по запросу «обувь» на Amazon, а затем уточнить поиск по размеру, цвету и стилю. При каждом уточнении URL немного меняется:
https://www.example.com/products/women/dresses/green.htmhttps://www.example.com/products/women?category=dresses&color=greenhttps://example.com/shopindex.php? product_id=32&highlight=green+dress&cat_id=1&sessionid=123$affid=43
Как Google узнает, какую версию URL следует показывать пользователям, выполняющим поиск? Google довольно хорошо справляется с определением репрезентативного URL-адреса самостоятельно, но вы можете использовать функцию параметров URL-адреса в Google Search Console, чтобы точно указать Google, как вы хотите, чтобы они обрабатывали ваши страницы. Если вы используете эту функцию, чтобы сообщить роботу Googlebot «не сканировать URL-адреса с параметром ____», то вы, по сути, просите скрыть этот контент от робота Googlebot, что может привести к удалению этих страниц из результатов поиска. Это то, что вам нужно, если эти параметры создают дубликаты страниц, но не идеально, если вы хотите, чтобы эти страницы были проиндексированы.
Если вы используете эту функцию, чтобы сообщить роботу Googlebot «не сканировать URL-адреса с параметром ____», то вы, по сути, просите скрыть этот контент от робота Googlebot, что может привести к удалению этих страниц из результатов поиска. Это то, что вам нужно, если эти параметры создают дубликаты страниц, но не идеально, если вы хотите, чтобы эти страницы были проиндексированы.
Могут ли поисковые роботы найти весь ваш важный контент?
Теперь, когда вы знаете некоторые тактики, позволяющие роботам поисковых систем держаться подальше от вашего неважного контента, давайте узнаем об оптимизации, которая может помочь роботу Googlebot находить важные страницы.
Иногда поисковая система может найти части вашего сайта путем сканирования, но другие страницы или разделы могут быть скрыты по той или иной причине. Важно убедиться, что поисковые системы могут обнаружить весь контент, который вы хотите проиндексировать, а не только вашу домашнюю страницу.
Задайте себе вопрос: может ли бот просканировать ваш сайт с по , а не только на него?
Ваш контент скрыт за формами входа?
Если вы требуете от пользователей входа в систему, заполнения форм или ответов на опросы перед доступом к определенному контенту, поисковые системы не увидят эти защищенные страницы. Поисковый робот точно не войдет в систему.
Поисковый робот точно не войдет в систему.
Вы полагаетесь на поисковые формы?
Роботы не могут использовать формы поиска. Некоторые люди считают, что если они разместят окно поиска на своем сайте, поисковые системы смогут найти все, что ищут их посетители.
Скрывается ли текст в нетекстовом содержимом?
Нетекстовые формы мультимедиа (изображения, видео, GIF и т. д.) не должны использоваться для отображения текста, который вы хотите проиндексировать. Хотя поисковые системы совершенствуются в распознавании изображений, нет никакой гарантии, что они смогут прочитать и понять их прямо сейчас. Всегда лучше добавлять текст в разметку вашей веб-страницы.
Могут ли поисковые системы отслеживать навигацию по вашему сайту?
Точно так же, как поисковому роботу необходимо найти ваш сайт по ссылкам с других сайтов, ему нужен путь ссылок на вашем собственном сайте, чтобы вести его от страницы к странице. Если у вас есть страница, которую вы хотите, чтобы поисковые системы находили, но на нее нет ссылок с других страниц, она практически невидима. Многие сайты совершают серьезную ошибку, структурируя свою навигацию способами, недоступными для поисковых систем, что мешает им попасть в результаты поиска.
Многие сайты совершают серьезную ошибку, структурируя свою навигацию способами, недоступными для поисковых систем, что мешает им попасть в результаты поиска.
- Мобильная навигация, результаты которой отличаются от результатов навигации на компьютере
- Любой тип навигации, в котором элементы меню не представлены в HTML, например, навигация с поддержкой JavaScript. Google стал намного лучше сканировать и понимать Javascript, но это все еще не идеальный процесс. Более верный способ гарантировать, что что-то будет найдено, понято и проиндексировано Google, — это поместить это в HTML.
- Персонализация или отображение уникальной навигации для определенного типа посетителей по сравнению с другими может показаться маскировкой для сканера поисковой системы. подписывайтесь на новые страницы!
Вот почему важно, чтобы ваш веб-сайт имел четкую навигацию и полезную структуру папок URL.
У вас чистая информационная архитектура?
Информационная архитектура — это практика организации и маркировки контента на веб-сайте для повышения эффективности и удобства поиска для пользователей. Лучшая информационная архитектура интуитивно понятна, а это означает, что пользователям не нужно слишком много думать, чтобы пройти через ваш веб-сайт или что-то найти.
Используете ли вы карты сайта?
Карта сайта — это то, на что это похоже: список URL-адресов на вашем сайте, которые поисковые роботы могут использовать для обнаружения и индексации вашего контента. Один из самых простых способов убедиться, что Google находит ваши страницы с наивысшим приоритетом, — это создать файл, соответствующий стандартам Google, и отправить его через Google Search Console. Хотя отправка карты сайта не заменяет необходимость хорошей навигации по сайту, она, безусловно, может помочь поисковым роботам проследить путь ко всем вашим важным страницам.
Убедитесь, что вы включили только те URL-адреса, которые вы хотите проиндексировать поисковыми системами, и убедитесь, что сканерам даны согласованные указания. Например, не включайте URL-адрес в свою карту сайта, если вы заблокировали этот URL-адрес с помощью robots.txt, или включайте в свою карту сайта URL-адреса, которые являются дубликатами, а не предпочтительной канонической версией (мы предоставим дополнительную информацию о канонизации в главе 5!).
Например, не включайте URL-адрес в свою карту сайта, если вы заблокировали этот URL-адрес с помощью robots.txt, или включайте в свою карту сайта URL-адреса, которые являются дубликатами, а не предпочтительной канонической версией (мы предоставим дополнительную информацию о канонизации в главе 5!).
Узнайте больше о XML-картах сайта
Если на ваш сайт не ссылаются другие сайты, вы все равно можете проиндексировать его, отправив свою XML-карту сайта в Google Search Console. Нет никакой гарантии, что они включат отправленный URL в свой индекс, но попробовать стоит!
Получают ли сканеры ошибки при попытке доступа к вашим URL-адресам?
В процессе сканирования URL-адресов на вашем сайте сканер может столкнуться с ошибками. Вы можете перейти к отчету Google Search Console «Ошибки сканирования», чтобы определить URL-адреса, на которых это может происходить — этот отчет покажет вам ошибки сервера и ненайденные ошибки. Файлы журналов сервера также могут показать вам это, а также кладезь другой информации, такой как частота сканирования, но поскольку доступ к файлам журналов сервера и их анализ — более продвинутая тактика, мы не будем подробно обсуждать это в Руководстве для начинающих, хотя вы можете узнать больше об этом здесь.
Прежде чем вы сможете что-либо сделать с отчетом об ошибках сканирования, важно понять ошибки сервера и ошибки «не найдено». Коды
4xx: когда сканеры поисковых систем не могут получить доступ к вашему контенту из-за ошибки клиента. Ошибки
4xx — это ошибки клиента, означающие, что запрошенный URL-адрес содержит неверный синтаксис или не может быть выполнен. Одной из самых распространенных ошибок 4xx является ошибка «404 — не найдено». Это может произойти из-за опечатки URL, удаленной страницы или неправильной переадресации, и это лишь несколько примеров. Когда поисковые системы получают ошибку 404, они не могут получить доступ к URL-адресу. Когда пользователи получают ошибку 404, они могут разочароваться и уйти.
Коды 5xx: когда сканеры поисковых систем не могут получить доступ к вашему контенту из-за ошибки сервера.
Ошибки 5xx — это ошибки сервера, означающие, что сервер, на котором расположена веб-страница, не смог выполнить запрос поисковика или поисковой системы на доступ к странице. . В отчете Google Search Console «Ошибка сканирования» есть вкладка, посвященная этим ошибкам. Обычно это происходит из-за того, что время ожидания запроса URL истекло, поэтому робот Googlebot отказался от запроса. Просмотрите документацию Google, чтобы узнать больше об устранении проблем с подключением к серверу.
. В отчете Google Search Console «Ошибка сканирования» есть вкладка, посвященная этим ошибкам. Обычно это происходит из-за того, что время ожидания запроса URL истекло, поэтому робот Googlebot отказался от запроса. Просмотрите документацию Google, чтобы узнать больше об устранении проблем с подключением к серверу.
К счастью, есть способ сообщить поисковикам и поисковым системам, что ваша страница была перемещена — 301 (постоянная) переадресация.
Создавайте собственные страницы 404!
Настройте страницу 404, добавив ссылки на важные страницы вашего сайта, функцию поиска по сайту и даже контактную информацию. Это должно снизить вероятность того, что посетители уйдут с вашего сайта, когда попадут на страницу 404.
Узнайте больше о настраиваемых страницах 404
Скажем, вы перемещаете страницу с example.com/young-dogs/ от до example.com/puppies/ . Поисковым системам и пользователям нужен мост, чтобы перейти от старого URL к новому. Этот мост представляет собой переадресацию 301.
Этот мост представляет собой переадресацию 301.
| При реализации 301: | Если вы не реализуете 301: | |
|---|---|---|
| Ссылочный капитал | Переносит ссылочный вес со старого местоположения страницы на новый URL. 906:50 | Без ошибки 301 полномочия предыдущего URL-адреса не передаются новой версии URL-адреса. |
| Индексация | Помогает Google найти и проиндексировать новую версию страницы. | Наличие ошибки 404 на вашем сайте само по себе не вредит поисковой эффективности, но если ранжирование/посещаемость страниц с ошибкой 404 может привести к их выпадению из индекса, а вместе с ними и ранжирование и трафик — ура! 906:50 |
| Взаимодействие с пользователем | Гарантирует, что пользователи найдут страницу, которую ищут. | Разрешив вашим посетителям нажимать на неработающие ссылки, они перенаправят их на страницы с ошибками, а не на предполагаемую страницу, что может быть неприятно. |
Сам код состояния 301 означает, что страница была постоянно перемещена в новое место, поэтому избегайте перенаправления URL-адресов на нерелевантные страницы — URL-адреса, где содержимое старого URL-адреса фактически не существует. Если страница ранжируется по запросу, а вы 301 перенаправляете ее на URL-адрес с другим содержимым, она может упасть в рейтинге, потому что контента, который сделал ее релевантной для этого конкретного запроса, больше нет. 301 — это мощно — перемещайте URL-адреса ответственно!
У вас также есть вариант 302 перенаправления страницы, но его следует зарезервировать для временных перемещений и в тех случаях, когда передача ссылочного веса не так важна. 302-е вроде как объезд дороги. Вы временно перекачиваете трафик по определенному маршруту, но это не будет продолжаться вечно.
302-е вроде как объезд дороги. Вы временно перекачиваете трафик по определенному маршруту, но это не будет продолжаться вечно.
Остерегайтесь цепочек переадресации!
Роботу Googlebot может быть сложно получить доступ к вашей странице, если он должен пройти несколько переадресаций. Google называет эти «цепочки переадресации» и рекомендует максимально их ограничивать. Если вы перенаправляете с example.com/1 на example.com/2, а затем решите перенаправить его на example.com/3, лучше исключить посредника и просто перенаправить с example.com/1 на example.com/3.
Узнайте больше о цепочках переадресации
После того, как вы убедились, что ваш сайт оптимизирован для сканирования, следующая задача — убедиться, что он может быть проиндексирован.
Индексирование: Как поисковые системы интерпретируют и сохраняют ваши страницы?
После того, как вы убедились, что ваш сайт просканирован, следующая задача — убедиться, что он может быть проиндексирован. Правильно — то, что ваш сайт может быть обнаружен и просканирован поисковой системой, не обязательно означает, что он будет сохранен в их индексе. В предыдущем разделе о сканировании мы обсуждали, как поисковые системы обнаруживают ваши веб-страницы. Индекс — это место, где хранятся обнаруженные вами страницы. После того, как сканер находит страницу, поисковая система отображает ее так же, как и браузер. При этом поисковая система анализирует содержимое этой страницы. Вся эта информация хранится в его индексе.
Правильно — то, что ваш сайт может быть обнаружен и просканирован поисковой системой, не обязательно означает, что он будет сохранен в их индексе. В предыдущем разделе о сканировании мы обсуждали, как поисковые системы обнаруживают ваши веб-страницы. Индекс — это место, где хранятся обнаруженные вами страницы. После того, как сканер находит страницу, поисковая система отображает ее так же, как и браузер. При этом поисковая система анализирует содержимое этой страницы. Вся эта информация хранится в его индексе.
Читайте дальше, чтобы узнать, как работает индексация и как убедиться, что ваш сайт попал в эту важнейшую базу данных.
Могу ли я посмотреть, как поисковый робот Googlebot видит мои страницы?
Да, кешированная версия вашей страницы будет отражать снимок последнего сканирования роботом Googlebot.
Google сканирует и кэширует веб-страницы с разной частотой. Более авторитетные и известные сайты с частыми публикациями, такие как https://www.nytimes. com, будут сканироваться чаще, чем гораздо менее известный веб-сайт подработки Роджера Мозбота, http://www.rogerlovescupcakes… , (если бы это было реально…)
com, будут сканироваться чаще, чем гораздо менее известный веб-сайт подработки Роджера Мозбота, http://www.rogerlovescupcakes… , (если бы это было реально…)
Вы можете просмотреть, как выглядит ваша кешированная версия страницы, щелкнув стрелку раскрывающегося списка рядом с URL-адресом в поисковой выдаче и выбрав «Кэшированный»:
Вы также можете просмотреть текстовую версию своего сайта, чтобы определить если ваш важный контент сканируется и кэшируется эффективно.
Удаляются ли когда-либо страницы из индекса?
Да, страницы можно удалять из индекса! Некоторые из основных причин, по которым URL-адрес может быть удален, включают:
- URL-адрес возвращает ошибку «не найден» (4XX) или ошибку сервера (5XX). не настроено) или преднамеренно (страница была удалена и получила ошибку 404, чтобы удалить ее из индекса)
- В URL-адрес добавлен метатег noindex. Этот тег может быть добавлен владельцами сайтов, чтобы указать поисковой системе исключить страницу из своего индекса.

- URL-адрес был оштрафован вручную за нарушение Руководства поисковой системы для веб-мастеров и в результате был удален из индекса.
- URL-адрес заблокирован для сканирования с добавлением пароля, необходимого для доступа посетителей к странице.
Если вы считаете, что страница на вашем веб-сайте, которая ранее была в индексе Google, больше не отображается, вы можете использовать инструмент проверки URL-адресов, чтобы узнать статус страницы, или использовать «Просмотреть как Google», который имеет «Запрос индексации». » для отправки отдельных URL-адресов в index. (Бонус: инструмент GSC «выборка» также имеет опцию «рендеринга», которая позволяет вам увидеть, есть ли какие-либо проблемы с тем, как Google интерпретирует вашу страницу).
Сообщите поисковым системам, как индексировать ваш сайт
Мета-директивы роботов
Мета-директивы (или «мета-теги») — это инструкции, которые вы можете дать поисковым системам относительно того, как вы хотите, чтобы ваша веб-страница обрабатывалась.
Вы можете сообщить роботам поисковых систем, например, «не индексировать эту страницу в результатах поиска» или «не передавать никакого ссылочного веса любым ссылкам на странице». Эти инструкции выполняются с помощью метатегов Robots в
ваших HTML-страниц (наиболее часто используемых) или с помощью X-Robots-Tag в заголовке HTTP.Метатег robots
Метатег robots можно использовать в
HTML вашей веб-страницы. Он может исключать все или определенные поисковые системы. Ниже приведены наиболее распространенные мета-директивы, а также ситуации, в которых вы можете их применять. index/noindex сообщает системам, следует ли сканировать страницу и сохранять ее в индексе поисковых систем для извлечения. Если вы решите использовать «noindex», вы сообщаете поисковым роботам, что хотите, чтобы страница была исключена из результатов поиска. По умолчанию поисковые системы предполагают, что они могут индексировать все страницы, поэтому использование значения «индекс» не требуется.
- Когда вы можете использовать: Вы можете пометить страницу как «без индекса», если вы пытаетесь обрезать тонкие страницы из индекса Google вашего сайта (например, созданные пользователем страницы профиля), но вы все равно хотите, чтобы они были доступны посетителям.
follow/nofollow сообщает поисковым системам, следует ли переходить по ссылкам на странице или использовать nofollow. «Follow» приводит к тому, что боты переходят по ссылкам на вашей странице и передают ссылочный вес на эти URL-адреса. Или, если вы решите использовать «nofollow», поисковые системы не будут следовать или передавать какой-либо ссылочный вес по ссылкам на странице. По умолчанию предполагается, что все страницы имеют атрибут «follow».
- Когда вы можете использовать: nofollow часто используется вместе с noindex, когда вы пытаетесь предотвратить индексацию страницы, а также предотвратить переход сканера по ссылкам на странице.
noarchive используется, чтобы запретить поисковым системам сохранять кэшированную копию страницы. По умолчанию поисковые системы сохраняют видимые копии всех проиндексированных ими страниц, доступных для искателей через кешированную ссылку в результатах поиска.
- Когда вы можете использовать: Если вы используете сайт электронной коммерции и ваши цены регулярно меняются, вы можете использовать тег noarchive, чтобы поисковики не видели устаревшие цены.
Вот пример метатега robots noindex, nofollow:
...
В этом примере все поисковые системы исключаются из индексации страницы и перехода по любым ссылкам на странице. Если вы хотите исключить несколько поисковых роботов, таких как, например, googlebot и bing, можно использовать несколько тегов исключения роботов.
Мета-директивы влияют на индексирование, а не на сканирование
Роботу Googlebot необходимо просканировать вашу страницу, чтобы увидеть ее мета-директивы, поэтому, если вы пытаетесь запретить поисковым роботам доступ к определенным страницам, мета-директивы не подходят для этого. . Теги robots должны быть просканированы, чтобы их уважали.
. Теги robots должны быть просканированы, чтобы их уважали.
X-Robots-Tag
Тег x-robots используется в заголовке HTTP вашего URL-адреса, обеспечивая большую гибкость и функциональность, чем метатеги, если вы хотите блокировать поисковые системы в масштабе, поскольку вы можете использовать регулярные выражения, блокировать -HTML и применять теги noindex для всего сайта.
Например, вы можете легко исключить целые папки или типы файлов (например, moz.com/no-bake/old-recipes-to-noindex):
Набор заголовков X-Robots-Tag «noindex, nofollow»
Производные, используемые в метатеге robots, также могут использоваться в X-Robots-Tag.
Или определенные типы файлов (например, PDF):
Набор заголовков X-Robots-Tag «noindex, nofollow»
Для получения дополнительной информации о тегах Meta Robot см. Спецификации метатегов роботов Google.
Совет WordPress:
В панели инструментов > Настройки > Чтение убедитесь, что флажок «Видимость поисковой системы» установлен на , а не на . Это блокирует доступ поисковых систем к вашему сайту через файл robots.txt!
Это блокирует доступ поисковых систем к вашему сайту через файл robots.txt!
Понимание того, как вы можете влиять на сканирование и индексирование, поможет вам избежать распространенных ошибок, которые могут препятствовать обнаружению важных страниц.
Рейтинг: Как поисковые системы ранжируют URL-адреса?
Как поисковые системы гарантируют, что когда кто-то вводит запрос в строку поиска, он получает в ответ релевантные результаты? Этот процесс известен как ранжирование или упорядочение результатов поиска по наиболее релевантным и наименее релевантным для конкретного запроса.
Для определения релевантности поисковые системы используют алгоритмы, процесс или формулу, с помощью которых хранимая информация извлекается и упорядочивается осмысленным образом. Эти алгоритмы претерпели множество изменений за эти годы, чтобы улучшить качество результатов поиска. Google, например, вносит коррективы в алгоритмы каждый день — некоторые из этих обновлений представляют собой незначительные улучшения качества, в то время как другие представляют собой базовые/общие обновления алгоритмов, развернутые для решения конкретной проблемы, например, Penguin для борьбы со спамом со ссылками. Ознакомьтесь с нашей Историей изменений алгоритмов Google, чтобы получить список как подтвержденных, так и неподтвержденных обновлений Google, начиная с 2000 года.
Ознакомьтесь с нашей Историей изменений алгоритмов Google, чтобы получить список как подтвержденных, так и неподтвержденных обновлений Google, начиная с 2000 года.
Почему так часто меняется алгоритм? Google просто пытается держать нас в напряжении? Хотя Google не всегда раскрывает подробности того, почему они делают то, что делают, мы знаем, что целью Google при корректировке алгоритма является улучшение общего качества поиска. Вот почему в ответ на вопросы об обновлении алгоритма Google ответит что-то вроде: «Мы постоянно делаем качественные обновления». Это указывает на то, что если ваш сайт пострадал после настройки алгоритма, сравните его с Руководством по качеству Google или Руководством по оценке качества поиска, оба очень красноречивы с точки зрения того, что хотят поисковые системы.
Чего хотят поисковые системы?
Поисковые системы всегда хотели одного и того же: давать полезные ответы на вопросы искателя в наиболее удобном формате. Если это правда, то почему сейчас кажется, что SEO отличается от того, что было в прошлые годы?
Подумайте об этом как о человеке, изучающем новый язык.
Поначалу их понимание языка очень рудиментарно — «Видеть на месте». Со временем их понимание начинает углубляться, и они изучают семантику — значение языка и отношения между словами и фразами. В конце концов, при достаточной практике учащийся знает язык достаточно хорошо, чтобы даже понимать нюансы, и может давать ответы даже на расплывчатые или неполные вопросы.
Когда поисковые системы только начинали изучать наш язык, было намного проще обмануть систему, используя уловки и приемы, которые на самом деле противоречат стандартам качества. Возьмем, к примеру, наполнение ключевыми словами. Если вы хотите ранжироваться по определенному ключевому слову, например «смешные шутки», вы можете несколько раз добавить слова «смешные шутки» на свою страницу и выделить их жирным шрифтом в надежде повысить свой рейтинг по этому запросу:
Добро пожаловать до приколов ! Рассказываем самых смешных анекдотов в мире. Смешные шутки веселые и безумные.Ваша смешная шутка ждет. Устройтесь поудобнее и прочитайте смешных анекдотов , потому что смешных анекдотов могут сделать вас счастливыми и смешнее . Некоторые смешных любимых анекдотов .
Эта тактика привела к ужасному опыту пользователей, и вместо того, чтобы смеяться над забавными шутками, люди были засыпаны раздражающим, трудночитаемым текстом. Возможно, это работало в прошлом, но поисковые системы никогда этого не хотели.
Проверьте рейтинг вашего сайта в Moz Pro
Вы можете проверить рейтинг своего сайта и отслеживать его с течением времени в Moz Pro. Откройте для себя возможности с 30-дневной бесплатной пробной версией:
Начать бесплатную пробную версию
Роль ссылок в поисковой оптимизации
Когда мы говорим о ссылках, мы можем иметь в виду две вещи. Обратные ссылки или «входящие ссылки» — это ссылки с других веб-сайтов, которые указывают на ваш веб-сайт, а внутренние ссылки — это ссылки на вашем собственном сайте, которые указывают на другие ваши страницы (на том же сайте).
Ссылки исторически играли большую роль в поисковой оптимизации. На очень раннем этапе поисковым системам требовалась помощь в определении того, какие URL-адреса заслуживают большего доверия, чем другие, чтобы помочь им определить, как ранжировать результаты поиска. В этом им помог подсчет количества ссылок, указывающих на тот или иной сайт.
Обратные ссылки работают очень похоже на рефералы WoM (из уст в уста) в реальной жизни. Возьмем в качестве примера гипотетическую кофейню Jenny’s Coffee:
- Рекомендации от других = хороший знак авторитета
- Пример: Множество разных людей говорили вам, что Jenny’s Coffee — лучший в городе
- Рекомендации от вас = предвзятость, поэтому не является хорошим признаком авторитета
- Пример: Дженни утверждает, что Jenny’s Coffee — лучший в городе
- Рефералы из нерелевантных или некачественных источников = не очень хороший признак авторитета и могут даже пометить вас как спам
- Пример: Дженни заплатила за то, чтобы люди, которые никогда не посещали ее кофейню, рассказывали другим, насколько она хороша.

- Пример: Дженни заплатила за то, чтобы люди, которые никогда не посещали ее кофейню, рассказывали другим, насколько она хороша.
- Нет направлений = неясный авторитет
- Пример: Кофе Дженни может быть хорошим, но вы не смогли найти никого, у кого есть мнение, поэтому вы не можете быть уверены.
Вот почему был создан PageRank. PageRank (часть основного алгоритма Google) — это алгоритм анализа ссылок, названный в честь одного из основателей Google Ларри Пейджа. PageRank оценивает важность веб-страницы, измеряя качество и количество ссылок, указывающих на нее. Предполагается, что чем более актуальной, важной и заслуживающей доверия является веб-страница, тем больше ссылок она получит.
Чем больше у вас естественных обратных ссылок с авторитетных (надежных) веб-сайтов, тем выше ваши шансы занять более высокое место в результатах поиска.
Роль контента в поисковой оптимизации
В ссылках не было бы смысла, если бы они не направляли пользователей к чему-либо. Что-то устал! Содержание — это больше, чем просто слова; это все, что предназначено для использования поисковиками — есть видеоконтент, контент изображения и, конечно же, текст. Если поисковые системы — это машины для ответов, контент — это средство, с помощью которого они доставляют эти ответы.
Если поисковые системы — это машины для ответов, контент — это средство, с помощью которого они доставляют эти ответы.
Каждый раз, когда кто-то выполняет поиск, возможны тысячи результатов, так как же поисковые системы решают, какие страницы искатель найдет ценными? Большая часть определения того, где ваша страница будет ранжироваться по заданному запросу, — это то, насколько хорошо контент на вашей странице соответствует цели запроса. Другими словами, соответствует ли эта страница словам, по которым производился поиск, и помогает ли выполнить задачу, которую пытался выполнить искатель?
Из-за такого внимания к удовлетворенности пользователей и выполнению задач не существует строгих критериев того, какой длины должен быть ваш контент, сколько раз он должен содержать ключевое слово или что вы помещаете в свои теги заголовков. Все это может играть роль в том, насколько хорошо страница работает в поиске, но основное внимание следует уделять пользователям, которые будут читать контент.
Сегодня, с сотнями или даже тысячами сигналов ранжирования, тройка лидеров остается довольно стабильной: ссылки на ваш веб-сайт (которые служат сторонними сигналами доверия), контент на странице (качественный контент, который соответствует намерениям пользователя). и RankBrain.
Что такое RankBrain?
RankBrain — это компонент машинного обучения основного алгоритма Google. Машинное обучение — это компьютерная программа, которая со временем продолжает улучшать свои прогнозы благодаря новым наблюдениям и обучающим данным. Другими словами, он постоянно учится, а поскольку он постоянно учится, результаты поиска должны постоянно улучшаться.
Например, если RankBrain заметит, что URL-адрес с более низким рейтингом обеспечивает лучший результат для пользователей, чем URL-адреса с более высоким рейтингом, вы можете поспорить, что RankBrain скорректирует эти результаты, переместив более релевантный результат выше и понизив менее релевантные страницы в качестве побочного продукта.
Как и большинство вещей, связанных с поисковой системой, мы точно не знаем, что включает в себя RankBrain, но, по-видимому, не знают и люди из Google.
Что это значит для оптимизаторов?
Поскольку Google продолжит использовать RankBrain для продвижения наиболее релевантного и полезного контента, нам нужно больше, чем когда-либо прежде, сосредоточиться на удовлетворении намерений пользователей. Предоставьте наилучшую возможную информацию и опыт для пользователей, которые могут попасть на вашу страницу, и вы сделали большой первый шаг к хорошей работе в мире RankBrain.
Показатели вовлеченности: корреляция, причинно-следственная связь или и то, и другое?
При ранжировании Google показатели вовлеченности, скорее всего, являются частично корреляционными и частично причинно-следственными.
Когда мы говорим о показателях взаимодействия, мы имеем в виду данные, которые показывают, как пользователи взаимодействуют с вашим сайтом из результатов поиска. Сюда входят такие вещи, как:
Сюда входят такие вещи, как:
- Клики (посещения из поиска)
- Время на странице (количество времени, которое посетитель провел на странице, прежде чем покинуть ее)
- Показатель отказов (процент всех сеансов веб-сайта, когда пользователи просматривали только одну страницу)
- Pogo-sticking (нажатие на органический результат, а затем быстрый возврат в поисковую выдачу для выбора другого результата)
Много тестов, включая собственное исследование факторов ранжирования, проведенное Moz, показали, что показатели вовлеченности коррелируют с более высоким рейтингом, но причинно-следственная связь вызывает горячие споры. Хорошие показатели вовлеченности указывают только на сайты с высоким рейтингом? Или сайты занимают высокие позиции, потому что они обладают хорошими показателями вовлеченности?
Что сказал Google
Хотя они никогда не использовали термин «прямой сигнал ранжирования», Google ясно дал понять, что они абсолютно используют данные о кликах для изменения SERP для определенных запросов.
По словам бывшего начальника отдела качества поиска Google Уди Манбера:
«Данные о кликах влияют на ранжирование. Если мы обнаружим, что по конкретному запросу 80% людей нажимают на № 2 и только 10% нажимают на № 1, через некоторое время мы выясним, что, вероятно, № 2 — это то, что людям нужно, поэтому мы поменяем его».
Еще один комментарий от бывшего инженера Google Эдмонда Лау подтверждает это:
«Совершенно очевидно, что любая разумная поисковая система будет использовать данные о кликах в своих собственных результатах, чтобы влиять на рейтинг и улучшать качество результатов поиска. Фактическая механика использования данных о кликах часто является частной собственностью, но Google делает очевидным, что использует данные о кликах со своими патентами на такие системы, как элементы контента с поправкой на рейтинг».
Поскольку Google необходимо поддерживать и улучшать качество поиска, кажется неизбежным, что показатели вовлеченности — это нечто большее, чем корреляция, но похоже, что Google не может назвать показатели вовлеченности «сигналом ранжирования», поскольку эти показатели используются для улучшения качества поиска, и рейтинг отдельных URL-адресов является лишь побочным продуктом этого.
Что подтвердили тесты
Различные тесты подтвердили, что Google будет корректировать порядок выдачи в ответ на активность пользователей:
- Тест Рэнда Фишкина в 2014 году привел к тому, что результат #7 поднялся на позицию #1 после того, как около 200 человек нажмите на URL из поисковой выдачи. Интересно, что улучшение рейтинга, казалось, было связано с местоположением людей, которые посетили ссылку. Позиция в рейтинге резко возросла в США, где находилось много участников, тогда как на странице в Google Canada, Google Australia и т. д. она оставалась ниже 9.0016
- Сравнение ведущих страниц и их среднего времени пребывания до и после RankBrain, проведенное Ларри Кимом, показало, что компонент машинного обучения алгоритма Google понижает позиции в рейтинге страниц, на которые люди не тратят столько времени.
- Тестирование Даррена Шоу также показало влияние поведения пользователя на результаты локального поиска и набора карт.
Поскольку показатели вовлеченности пользователей явно используются для корректировки результатов поисковой выдачи по качеству, а изменение позиции в рейтинге является побочным продуктом, можно с уверенностью сказать, что SEO-специалисты должны оптимизировать взаимодействие. Вовлеченность не меняет объективное качество вашей веб-страницы, а скорее вашу ценность для искателей по сравнению с другими результатами по этому запросу. Вот почему после того, как ваша страница или ее обратные ссылки не будут изменены, она может снизиться в рейтинге, если поведение пользователей указывает на то, что им больше нравятся другие страницы.
Вовлеченность не меняет объективное качество вашей веб-страницы, а скорее вашу ценность для искателей по сравнению с другими результатами по этому запросу. Вот почему после того, как ваша страница или ее обратные ссылки не будут изменены, она может снизиться в рейтинге, если поведение пользователей указывает на то, что им больше нравятся другие страницы.
С точки зрения ранжирования веб-страниц показатели вовлеченности действуют как средство проверки фактов. Объективные факторы, такие как ссылки и контент, сначала ранжируют страницу, а затем показатели вовлеченности помогают Google скорректировать, если они ошиблись.
Эволюция результатов поиска
В те времена, когда поисковым системам не хватало изощренности, которую они имеют сегодня, термин «10 синих ссылок» был придуман для описания плоской структуры поисковой выдачи. Каждый раз, когда выполнялся поиск, Google возвращал страницу с 10 обычными результатами, каждый в одном и том же формате.
В этой поисковой среде первое место было святым Граалем поисковой оптимизации. Но потом что-то случилось. Google начал добавлять результаты в новых форматах на свои страницы результатов поиска, которые называются функциями SERP. Некоторые из этих функций SERP включают в себя:
Но потом что-то случилось. Google начал добавлять результаты в новых форматах на свои страницы результатов поиска, которые называются функциями SERP. Некоторые из этих функций SERP включают в себя:
- Платная реклама
- Избранные сниппеты
- Блоки «Люди также спрашивают»
- Локальный (карта) пакет
- Панель знаний
- Дополнительные ссылки
- Релевантность
- Расстояние
- Известность
3 9000 Google добавляет новые. Они даже экспериментировали с «выдачей с нулевым результатом» — явлением, когда в поисковой выдаче отображался только один результат из сети знаний, а под ним не было никаких результатов, за исключением опции «просмотреть больше результатов».
Добавление этих функций вызвало панику по двум основным причинам. Во-первых, многие из этих функций привели к тому, что органические результаты оказались ниже в поисковой выдаче. Другим побочным продуктом является то, что меньше искателей нажимают на органические результаты, поскольку на большее количество запросов отвечает сама поисковая выдача.
Так зачем Google это делать? Все восходит к опыту поиска. Поведение пользователей указывает на то, что некоторые запросы лучше удовлетворяются за счет разных форматов контента. Обратите внимание, как различные типы функций SERP соответствуют различным типам запросов.
| Намерение запроса | Возможная функция поисковой выдачи сработала |
|---|---|
| Информационный | Избранный фрагмент |
| Информационная с одним ответом | График знаний / мгновенный ответ 906:50 |
| Местный | Пакет карт |
| Транзакционный | Покупка |
Подробнее о намерении мы поговорим в главе 3, а сейчас важно знать, что ответы могут быть доставлены пользователям в самых разных форматах, и то, как вы структурируете свой контент, может повлиять на формат, в котором он появляется в поиске.
Локализованный поиск
Поисковая система, такая как Google, имеет собственный собственный индекс списков местных компаний, из которого она создает результаты локального поиска.
Если вы выполняете локальную SEO-работу для компании, которая имеет физическое местонахождение, которое могут посетить клиенты (например, стоматолог), или для компании, которая путешествует, чтобы навестить своих клиентов (например, сантехник), убедитесь, что вы утверждаете, проверяете и оптимизировать бесплатное объявление Google My Business.
Когда речь идет о локализованных результатах поиска, Google использует три основных фактора для определения рейтинга:
Релевантность
Релевантность — это то, насколько местный бизнес соответствует тому, что ищет пользователь. Чтобы убедиться, что бизнес делает все возможное, чтобы быть актуальным для пользователей, выполняющих поиск, убедитесь, что информация о бизнесе заполнена полностью и точно.
Расстояние
Google использует ваше географическое положение, чтобы лучше предоставлять вам местные результаты. Результаты локального поиска чрезвычайно чувствительны к близости, которая относится к местоположению искателя и/или местоположению, указанному в запросе (если искатель включил его).
Результаты обычного поиска чувствительны к местоположению искателя, хотя и редко так явно, как в результатах локального поиска.
Известность
Принимая во внимание известность как фактор, Google стремится поощрять компании, хорошо известные в реальном мире. В дополнение к известности бизнеса в офлайне Google также учитывает некоторые онлайн-факторы для определения локального рейтинга, такие как:
Отзывы
Количество отзывов Google, которые получает местный бизнес, и настроение этих отзывов оказывают заметное влияние. от их способности занять место в местных результатах.
Цитирование
«Коммерческое цитирование» или «коммерческий список» — это веб-ссылка на «NAP» местного бизнеса (имя, адрес, номер телефона) на локализованной платформе (Yelp, Acxiom, YP, Infogroup). , Localeze и др.).
, Localeze и др.).
На местные рейтинги влияет количество и постоянство упоминаний местных компаний. Google извлекает данные из самых разных источников, постоянно составляя свой индекс местного бизнеса. Когда Google находит несколько последовательных ссылок на название компании, местонахождение и номер телефона, это укрепляет «доверие» Google к достоверности этих данных. Затем это приводит к тому, что Google может показать бизнес с более высокой степенью уверенности. Google также использует информацию из других источников в Интернете, например ссылки и статьи.
Органическое ранжирование
Лучшие практики поисковой оптимизации также применимы к локальному поисковому продвижению, поскольку Google также учитывает позицию веб-сайта в результатах органического поиска при определении локального рейтинга.
В следующей главе вы познакомитесь с передовыми методами работы с страницами, которые помогут Google и пользователям лучше понять ваш контент.
[Бонус!] Местное взаимодействие
Несмотря на то, что оно не указано Google как местный фактор ранжирования, роль вовлечения будет только возрастать с течением времени. Google продолжает обогащать локальные результаты за счет включения реальных данных, таких как популярные времена посещения и средняя продолжительность посещений…
Google продолжает обогащать локальные результаты за счет включения реальных данных, таких как популярные времена посещения и средняя продолжительность посещений…
Интересует точность цитирования определенного местного бизнеса? У Moz есть бесплатный инструмент, который может помочь, метко названный Check Listing.
Проверить точность листинга
…и даже дает пользователям возможность задавать деловые вопросы!
Несомненно, сейчас больше, чем когда-либо прежде, локальные результаты зависят от реальных данных. Эта интерактивность — это то, как пользователи, осуществляющие поиск, взаимодействуют с местными предприятиями и реагируют на них, а не просто статическая (и игровая) информация, такая как ссылки и цитаты.
Поскольку Google хочет предоставить пользователям, выполняющим поиск, лучшие и наиболее релевантные местные компании, для них имеет смысл использовать показатели вовлеченности в режиме реального времени для определения качества и релевантности.