
Количество унифицированных шейдерных блоков (или универсальных процессоров)
Унифицированные шейдерные блоки объединяют два типа перечисленных выше блоков, они могут исполнять как вершинные, так и пиксельные программы (а также геометрические, которые появились в DirectX 10). Унификация блоков шейдеров значит, что код разных шейдерных программ (вершинных, пиксельных и геометрических) универсален, и соответствующие унифицированные процессоры могут выполнить любые программы из вышеперечисленных. Соответственно, в новых архитектурах число пиксельных, вершинных и геометрических шейдерных блоков как бы сливается в одно число — количество универсальных процессоров.
Блоки текстурирования (tmu)
Эти блоки работают совместно с шейдерными процессорами всех указанных типов, ими осуществляется выборка и фильтрация текстурных данных, необходимых для построения сцены. Число текстурных блоков в видеочипе определяет текстурную производительность, скорость выборки из текстур. И хотя в последнее время большая часть расчетов осуществляется блоками шейдеров, нагрузка на блоки TMU до сих пор довольно велика, и с учетом упора некоторых приложений в производительность блоков текстурирования, можно сказать, что количество блоков TMU и соответствующая высокая текстурная производительность являются одними из важнейших параметров видеочипов. Особое влияние этот параметр оказывает на скорость при использовании трилинейной и анизотропной фильтраций, требующих дополнительных текстурных выборок.
Блоки операций растеризации (rop)
Блоки растеризации осуществляют операции записи рассчитанных видеокартой пикселей в буферы и операции их смешивания (блендинга). Как уже отмечалось выше, производительность блоков ROP влияет на филлрейт и это — одна из основных характеристик видеокарт. И хотя в последнее время её значение несколько снизилось, еще попадаются случаи, когда производительность приложений сильно зависит от скорости и количества блоков ROP. Чаще всего это объясняется активным использованием фильтров постобработки и включенным антиалиасингом при высоких настройках изображения.
Объем видеопамяти
Собственная память используется видеочипами для хранения необходимых данных: текстур, вершин, буферов и т.п. Казалось бы, что чем её больше — тем лучше. Но не всё так просто, оценка мощности видеокарты по объему видеопамяти — это наиболее распространенная ошибка! Значение объема памяти неопытные пользователи переоценивают чаще всего, используя его для сравнения разных моделей видеокарт. Оно и понятно — раз параметр, указываемый во всех источниках одним из первых, в два раза больше, то и скорость у решения должна быть в два раза выше, считают они. Реальность же от этого мифа отличается тем, что рост производительности растет до определенного объема и после его достижения попросту останавливается.
В каждом приложении есть определенный объем видеопамяти, которого хватает для всех данных, и хоть 4 ГБ туда поставь — у нее не появится причин для ускорения рендеринга, скорость будут ограничивать исполнительные блоки. Именно поэтому почти во всех случаях видеокарта с 320 Мбайт видеопамяти будет работать с той же скоростью, что и карта с 640 Мбайт (при прочих равных условиях). Ситуации, когда больший объем памяти приводит к видимому увеличению производительности, существуют, это очень требовательные приложения в высоких разрешениях и при максимальных настройках. Но такие случаи весьма редки, поэтому, объем памяти учитывать конечно нужно, но не забывая о том, что выше определенного объема производительность просто не растет, есть более важные параметры, такие как ширина шины памяти и ее рабочая частота.
Вычисления на графических процессорах | Дайджест новостей
Вычисления на графических процессорах
Технология CUDA (англ. Compute Unified Device Architecture) — программно-аппаратная архитектура, позволяющая производить вычисления с использованием графических процессоров NVIDIA, поддерживающих технологию GPGPU (произвольных вычислений на видеокартах). Архитектура CUDA впервые появились на рынке с выходом чипа NVIDIA восьмого поколения — G80 и присутствует во всех последующих сериях графических чипов, которые используются в семействах ускорителей GeForce, ION, Quadro и Tesla.
CUDA SDK позволяет программистам реализовывать на специальном упрощённом диалекте языка программирования Си алгоритмы, выполнимые на графических процессорах NVIDIA и включать специальные функции в текст программы на Cи. CUDA даёт разработчику возможность по своему усмотрению организовывать доступ к набору инструкций графического ускорителя и управлять его памятью, организовывать на нём сложные параллельные вычисления.
История
В 2003 г. Intel и AMD участвовали в совместной гонке за самый мощный процессор. За несколько лет в результате этой гонки тактовые частоты существенно выросли, особенно после выхода Intel Pentium 4.
После прироста тактовых частот (между 2001 и 2003 гг. тактовая частота Pentium 4 удвоилась с 1,5 до 3 ГГц), а пользователям пришлось довольствоваться десятыми долями гигагерц, которые вывели на рынок производители (с 2003 до 2005 гг.тактовые частоты увеличились 3 до 3,8 ГГц).
Архитектуры, оптимизированные под высокие тактовые частоты, та же Prescott, так же стали испытывать трудности, и не только производственные. Производители чипов столкнулись с проблемами преодоления законов физики. Некоторые аналитики даже предрекали, что закон Мура перестанет действовать. Но этого не произошло. Оригинальный смысл закона часто искажают, однако он касается числа транзисторов на поверхности кремниевого ядра. Долгое время повышение числа транзисторов в CPU сопровождалось соответствующим ростом производительности — что и привело к искажению смысла. Но затем ситуация усложнилась. Разработчики архитектуры CPU подошли к закону сокращения прироста: число транзисторов, которое требовалось добавить для нужного увеличения производительности, становилось всё большим, заводя в тупик.
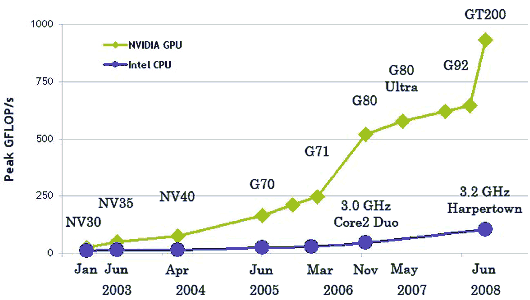
Причина, по которой производителям GPU не столкнулись с этой проблемой очень простая: центральные процессоры разрабатываются для получения максимальной производительности на потоке инструкций, которые обрабатывают разные данные (как целые числа, так и числа с плавающей запятой), производят случайный доступ к памяти и т.д. До сих пор разработчики пытаются обеспечить больший параллелизм инструкций — то есть выполнять как можно большее число инструкций параллельно. Так, например, с Pentium появилось суперскалярное выполнение, когда при некоторых условиях можно было выполнять две инструкции за такт. Pentium Pro получил внеочередное выполнение инструкций, позволившее оптимизировать работу вычислительных блоков. Проблема заключается в том, что у параллельного выполнения последовательного потока инструкций есть очевидные ограничения, поэтому слепое повышение числа вычислительных блоков не даёт выигрыша, поскольку большую часть времени они всё равно будут простаивать.
Работа GPU относительно простая. Она заключается в принятии группы полигонов с одной стороны и генерации группы пикселей с другой. Полигоны и пиксели независимы друг от друга, поэтому их можно обрабатывать параллельно. Таким образом, в GPU можно выделить крупную часть кристалла на вычислительные блоки, которые, в отличие от CPU, будут реально использоваться.
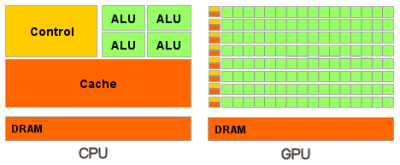
GPU отличается от CPU не только этим. Доступ к памяти в GPU очень связанный — если считывается тексель, то через несколько тактов будет считываться соседний тексель; когда записывается пиксель, то через несколько тактов будет записываться соседний. Разумно организуя память, можно получить производительность, близкую к теоретической пропускной способности. Это означает, что GPU, в отличие от CPU, не требуется огромного кэша, поскольку его роль заключается в ускорении операций текстурирования. Всё, что нужно, это несколько килобайт, содержащих несколько текселей, используемых в билинейных и трилинейных фильтрах.
Первые расчёты на GPU
Самые первые попытки такого применения ограничивались использованием некоторых аппаратных функций, таких, как растеризация и Z-буферизация. Но в нынешнем веке, с появлением шейдеров, начали ускорять вычисления матриц. В 2003 г. на SIGGRAPH отдельная секция была выделена под вычисления на GPU, и она получила название GPGPU (General-Purpose computation on GPU) — универсальные вычисления на GPU).
Наиболее известен BrookGPU — компилятор потокового языка программирования Brook, созданный для выполнения неграфических вычислений на GPU. До его появления разработчики, использующие возможности видеочипов для вычислений, выбирали один из двух распространённых API: Direct3D или OpenGL. Это серьёзно ограничивало применение GPU, ведь в 3D графике используются шейдеры и текстуры, о которых специалисты по параллельному программированию знать не обязаны, они используют потоки и ядра. Brook смог помочь в облегчении их задачи. Эти потоковые расширения к языку C, разработанные в Стэндфордском университете, скрывали от программистов трёхмерный API, и представляли видеочип в виде параллельного сопроцессора. Компилятор обрабатывал файл .br с кодом C++ и расширениями, производя код, привязанный к библиотеке с поддержкой DirectX, OpenGL или x86.
Появление Brook вызвал интерес у NVIDIA и ATI и в дальнейшем, открыл целый новый его сектор — параллельные вычислители на основе видеочипов.
В дальнейшем, некоторые исследователи из проекта Brook перешли в команду разработчиков NVIDIA, чтобы представить программно-аппаратную стратегию параллельных вычислений, открыв новую долю рынка. И главным преимуществом этой инициативы NVIDIA стало то, что разработчики отлично знают все возможности своих GPU до мелочей, и в использовании графического API нет необходимости, а работать с аппаратным обеспечением можно напрямую при помощи драйвера. Результатом усилий этой команды стала NVIDIA CUDA.
Области применения параллельных расчётов на GPU
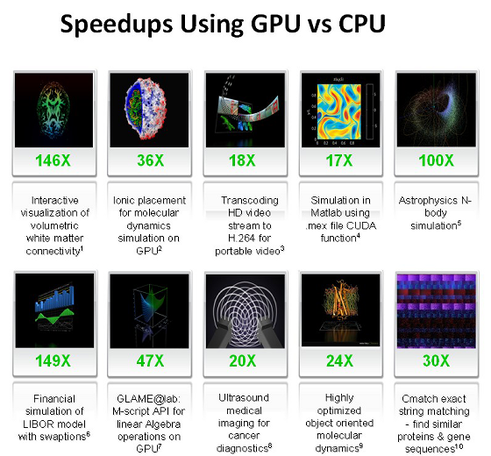
При переносе вычислений на GPU, во многих задачах достигается ускорение в 5-30 раз, по сравнению с быстрыми универсальными процессорами. Самые большие цифры (порядка 100-кратного ускорения и даже более!) достигаются на коде, который не очень хорошо подходит для расчётов при помощи блоков SSE, но вполне удобен для GPU.
Это лишь некоторые примеры ускорений синтетического кода на GPU против SSE-векторизованного кода на CPU (по данным NVIDIA):
• Флуоресцентная микроскопия: 12x.
• Молекулярная динамика (non-bonded force calc): 8-16x;
• Электростатика (прямое и многоуровневое суммирование Кулона): 40-120x и 7x.
Таблица, которую NVIDIA, показывает на всех презентациях, в которой показывается скорость графических процессоров относительно центральных.
Перечень основных приложений, в которых применяются вычисления на GPU: анализ и обработка изображений и сигналов, симуляция физики, вычислительная математика, вычислительная биология, финансовые расчёты, базы данных, динамика газов и жидкостей, криптография, адаптивная лучевая терапия, астрономия, обработка звука, биоинформатика, биологические симуляции, компьютерное зрение, анализ данных (data mining), цифровое кино и телевидение, электромагнитные симуляции, геоинформационные системы, военные применения, горное планирование, молекулярная динамика, магнитно-резонансная томография (MRI), нейросети, океанографические исследования, физика частиц, симуляция свёртывания молекул белка, квантовая химия, трассировка лучей, визуализация, радары, гидродинамическое моделирование (reservoir simulation), искусственный интеллект, анализ спутниковых данных, сейсмическая разведка, хирургия, ультразвук, видеоконференции.
Преимущества и ограничения CUDA
С точки зрения программиста, графический конвейер является набором стадий обработки. Блок геометрии генерирует треугольники, а блок растеризации — пиксели, отображаемые на мониторе. Традиционная модель программирования GPGPU выглядит следующим образом:

Чтобы перенести вычисления на GPU в рамках такой модели, нужен специальный подход. Даже поэлементное сложение двух векторов потребует отрисовки фигуры на экране или во внеэкранный буфер. Фигура растеризуется, цвет каждого пикселя вычисляется по заданной программе (пиксельному шейдеру). Программа считывает входные данные из текстур для каждого пикселя, складывает их и записывает в выходной буфер. И все эти многочисленные операции нужны для того, что в обычном языке программирования записывается одним оператором!
Поэтому, применение GPGPU для вычислений общего назначения имеет ограничение в виде слишком большой сложности обучения разработчиков. Да и других ограничений достаточно, ведь пиксельный шейдер — это всего лишь формула зависимости итогового цвета пикселя от его координаты, а язык пиксельных шейдеров — язык записи этих формул с Си-подобным синтаксисом. Ранние методы GPGPU являются хитрым трюком, позволяющим использовать мощность GPU, но без всякого удобства. Данные там представлены изображениями (текстурами), а алгоритм — процессом растеризации. Нужно особо отметить и весьма специфичную модель памяти и исполнения.
Программно-аппаратная архитектура для вычислений на GPU компании NVIDIA отличается от предыдущих моделей GPGPU тем, что позволяет писать программы для GPU на настоящем языке Си со стандартным синтаксисом, указателями и необходимостью в минимуме расширений для доступа к вычислительным ресурсам видеочипов. CUDA не зависит от графических API, и обладает некоторыми особенностями, предназначенными специально для вычислений общего назначения.
Преимущества CUDA перед традиционным подходом к GPGPU вычислениям
CUDA обеспечивает доступ к разделяемой между потоками памяти размером в 16 Кб на мультипроцессор, которая может быть использована для организации кэша с широкой полосой пропускания, по сравнению с текстурными выборками;
• более эффективная передача данных между системной и видеопамятью;
• отсутствие необходимости в графических API с избыточностью и накладными расходами;
• линейная адресация памяти, и gather и scatter, возможность записи по произвольным адресам;
• аппаратная поддержка целочисленных и битовых операций.
Основные ограничения CUDA:
• отсутствие поддержки рекурсии для выполняемых функций;
• минимальная ширина блока в 32 потока;
• закрытая архитектура CUDA, принадлежащая NVIDIA.
Слабыми местами программирования при помощи предыдущих методов GPGPU является то, что эти методы не используют блоки исполнения вершинных шейдеров в предыдущих неунифицированных архитектурах, данные хранятся в текстурах, а выводятся во внеэкранный буфер, а многопроходные алгоритмы используют пиксельные шейдерные блоки. В ограничения GPGPU можно включить: недостаточно эффективное использование аппаратных возможностей, ограничения полосой пропускания памяти, отсутствие операции scatter (только gather), обязательное использование графического API.
Основные преимущества CUDA по сравнению с предыдущими методами GPGPU вытекают из того, что эта архитектура спроектирована для эффективного использования неграфических вычислений на GPU и использует язык программирования C, не требуя переноса алгоритмов в удобный для концепции графического конвейера вид. CUDA предлагает новый путь вычислений на GPU, не использующий графические API, предлагающий произвольный доступ к памяти (scatter или gather). Такая архитектура лишена недостатков GPGPU и использует все исполнительные блоки, а также расширяет возможности за счёт целочисленной математики и операций битового сдвига.
CUDA открывает некоторые аппаратные возможности, недоступные из графических API, такие как разделяемая память. Это память небольшого объёма (16 килобайт на мультипроцессор), к которой имеют доступ блоки потоков. Она позволяет кэшировать наиболее часто используемые данные и может обеспечить более высокую скорость, по сравнению с использованием текстурных выборок для этой задачи. Что, в свою очередь, снижает чувствительность к пропускной способности параллельных алгоритмов во многих приложениях. Например, это полезно для линейной алгебры, быстрого преобразования Фурье и фильтров обработки изображений.
Удобнее в CUDA и доступ к памяти. Программный код в графических API выводит данные в виде 32-х значений с плавающей точкой одинарной точности (RGBA значения одновременно в восемь render target) в заранее предопределённые области, а CUDA поддерживает scatter запись — неограниченное число записей по любому адресу. Такие преимущества делают возможным выполнение на GPU некоторых алгоритмов, которые невозможно эффективно реализовать при помощи методов GPGPU, основанных на графических API.
Также, графические API в обязательном порядке хранят данные в текстурах, что требует предварительной упаковки больших массивов в текстуры, что усложняет алгоритм и заставляет использовать специальную адресацию. А CUDA позволяет читать данные по любому адресу. Ещё одним преимуществом CUDA является оптимизированный обмен данными между CPU и GPU. А для разработчиков, желающих получить доступ к низкому уровню (например, при написании другого языка программирования), CUDA предлагает возможность низкоуровневого программирования на ассемблере.
Недостатки CUDA
Один из немногочисленных недостатков CUDA — слабая переносимость. Эта архитектура работает только на видеочипах этой компании, да ещё и не на всех, а начиная с серии GeForce 8 и 9 и соответствующих Quadro, ION и Tesla. NVIDIA приводит цифру в 90 миллионов CUDA-совместимых видеочипов.
Альтернативы CUDA
• OpenCL
Фреймворк для написания компьютерных программ, связанных с параллельными вычислениями на различных графических и центральных процессорах. В фреймворк OpenCL входят язык программирования, который базируется на стандарте C99, и интерфейс программирования приложений (API). OpenCL обеспечивает параллелизм на уровне инструкций и на уровне данных и является реализацией техники GPGPU. OpenCL является полностью открытым стандартом, его использование не облагается лицензионными отчислениями.
Цель OpenCL состоит в том, чтобы дополнить OpenGL и OpenAL, которые являются открытыми отраслевыми стандартами для трёхмерной компьютерной графики и звука, пользуясь возможностями GPU. OpenCL разрабатывается и поддерживается некоммерческим консорциумом Khronos Group, в который входят много крупных компаний, включая Apple, AMD, Intel, nVidia, Sun Microsystems, Sony Computer Entertainment и другие.
• CAL/IL(Compute Abstraction Layer/Intermediate Language)
ATI Stream Technology — это набор аппаратных и программных технологий, которые позволяют использовать графические процессоры AMD, совместно с центральным процессором, для ускорения многих приложений (не только графических).
Областями применения ATI Stream являются приложения, требовательные к вычислительному ресурсу, такие, как финансовый анализ или обработка сейсмических данных. Использование потокового процессора позволило увеличить скорость некоторых финансовых расчётов в 55 раз по сравнению с решением той же задачи силами только центрального процессора.
Технологию ATI Stream в NVIDIA не считают очень сильным конкурентом. CUDA и Stream — это две разные технологии, которые стоят на различных уровнях развития. Программирование для продуктов ATI намного сложнее — их язык скорее напоминает ассемблер. CUDA C, в свою очередь, гораздо более высокоуровневый язык. Писать на нём удобнее и проще. Для крупных компаний-разработчиков это очень важно. Если говорить о производительности, то можно заметить, что её пиковое значение в продуктах ATI выше, чем в решениях NVIDIA. Но опять всё сводится к тому, как эту мощность получить.
• DirectX11 (DirectCompute)
Интерфейс программирования приложений, который входит в состав DirectX — набора API от Microsoft, который предназначен для работы на IBM PC-совместимых компьютерах под управлением операционных систем семейства Microsoft Windows. DirectCompute предназначен для выполнения вычислений общего назначения на графических процессорах, являясь реализацией концепции GPGPU. Изначально DirectCompute был опубликован в составе DirectX 11, однако позже стал доступен и для DirectX 10 и DirectX 10.1.
NVDIA CUDA в российской научной среде.
По состоянию на декабрь 2009 г., программная модель CUDA преподается в 269 университетах мира. В России обучающие курсы по CUDA читаются в Московском, Санкт-Петербургском, Казанском, Новосибирском и Пермском государственных университетах, Международном университете природы общества и человека «Дубна», Объединённом институте ядерных исследований, Московском институте электронной техники, Ивановском государственном энергетическом университете, БГТУ им. В. Г. Шухова, МГТУ им. Баумана, РХТУ им. Менделеева, Российском научном центре «Курчатовский институт», Межрегиональном суперкомпьютерном центре РАН, Таганрогском технологическом институте (ТТИ ЮФУ).
Кодовое имя Условное обозначение графического процессора | GT200 | GF100 | GF104 | GF114 | GK104 | GM206 | |||
|---|---|---|---|---|---|---|---|---|---|
Год выхода | 2008 | 2009 | 2010 | 2011 | 2012 | 2015 | |||
PCI DeviceID Идентификатор шины PCI графического процессора | 05E1 | 05E3 | 06C4 | 0E22 | 0E23 | 1200 | 1180 | 1401 | 1402 |
Частота вычислительных блоков в режиме 3D, МГц Частота работы шейдерных процессоров (SPU) при использовании 3D функций | 1296 | 1476 | 1215 | 1350 | 1300 | 1645 | 1006 | 1127 | 1024 |
Частота блоков рендеринга в режиме 3D, МГц Частота работы блоков рендеринга (TMU и ROP) при использовании 3D функций | 600 | 648 | 607 | 675 | 650 | 822 | 1006 | 1127 | 1024 |
Частота GPU в режиме Boost, МГц Тактовая частота GPU в режиме ускорения | 1178 | 1188 | |||||||
Транзисторов, млн | 1400 | 3000 | 1950 | 3540 | 2940 | ||||
Технологический процесс, нм Технологическая норма изготовления графического процессора | 65 | 55 | 40 | 28 | |||||
Вычислительных блоков Число шейдерных процессоров (SPU) | 240 | 352 | 336 | 288 | 384 | 1536 | 1024 | 768 | |
Блоков текстурирования Число блоков наложения текстур (TMU) | 80 | 44 | 56 | 48 | 64 | 128 | |||
Блоков растеризации Число блоков растеризации (ROP) | 32 | ||||||||
Максимально накладываемых текстур за проход | 80 | 44 | 56 | 48 | 64 | 128 | |||
Вычислительная производительность, гигафлопс Одинарная точность | 933.1 | 1063 | 855.4 | 907.2 | 748.8 | 1263 | 3090 | 2308 | 1572 |
Вычислительная производительность, гигафлопс Двойная точность | 77.8 | 88.6 | 106.9 | 75.6 | 62.4 | 105.2 | 147.4 | 72,1 | 49,1 |
Cкорость заполнения сцены, млн. пикселей/с Fillrate, без текстурирования | 19200 | 20730 | 19400 | 21600 | 20800 | 26304 | 32200 | 39300 | 32700 |
Cкорость заполнения сцены, млн. текселей/с Fillrate, с текстурированием | 48000 | 51840 | 26700 | 37800 | 31200 | 52608 | 128800 | 72100 | 49200 |
Тип видеопамяти Поддерживаемые типы видеопамяти | GDDR3 | GDDR5 | |||||||
Максимальный объем видеопамяти, МБ Максимальный поддерживаемый графическим процессором объем видеопамяти | 2048 | 4096 | |||||||
Ширина шины видеопамяти, бит | 512 | 256 | 128 | ||||||
Частота шины видеопамяти, МГц Опорная частота шины данных, ½ от DDR | 1100 | 1242 | 1604 | 1800 | 1700 | 2004 | 6008 | 7000 | 6610 |
Полоса пропускания шины видеопамяти, ГБ/с | 140.8 | 159.0 | 102.7 | 115.2 | 108.8 | 128.2 | 192.3 | 112 | 106 |
Интерфейс шины Поддерживаемые шины компьютера | PCI Express 2.0 x16 | PCI Express 3.0 x16, PCI Express 2.0 x16 | PCI Express 3.0×16 | ||||||
Поддержка SLI Поддерживаемые графическим процессором режимы NVIDIA SLI | SLI, 3-Way SLI | SLI | SLI, 2-Way SLI | ||||||
Универсальные шейдеры, версия Максимальная поддерживаемая версия универсальных шейдеров | 4.0 | 5.0 | |||||||
Тесселяция (tesselation) Поддерживаемые алгоритмы тесселяции | Нет | программируемая | программируемая, аппаратная | ||||||
Кубические карты среды (CEM) | Да | ||||||||
Наложение рельефа (Bump mapping) Поддерживаемые алгоритмы наложения рельефа | Emboss, DOT3, EMBM | ||||||||
Объемные (3D) текстуры | Да | ||||||||
Сжатие текстур Поддерживаемые алгоритмы сжатия текстур | S3TC, RGTC | S3TC, RGTC, BCTC | S3TC, RGTC, BCTC, Delta, Color rev 3 | ||||||
Paletted (indexed) текстуры Поддержка текстур с индексированной цветовой палитрой | Нет | ||||||||
Текстуры произвольного размера Поддержка текстур с размерами, не кратными 2 | Да | ||||||||
Максимальный размер текстур, пикселей | 8192×8192 | 16384×16384 | |||||||
Форматы буфера глубины Поддерживаемые форматы буфера глубины | Z (16b, 24b fixed, 32b float) | ||||||||
UltraShadow, версия Поддержка технологии NVIDIA UltraShadow | 2.0 | ||||||||
Поддержка G-Sync Поддержка технологии синхронизации кадра с дисплеем | Да | ||||||||
Степени анизотропной фильтрации (AF) | 2, 4, 8, 16 | ||||||||
Степени полноэкранного сглаживания (FSAA) | MSAA RGS 2x, 4x, 8xQ CSAA 8x, 16x, 16xQ | MSAA RGS 2x, 4x, 8xQ CSAA 8x, 16x, 16xQ, 32x | MSAA RGS 2x, 4x, 8xQ MFAA, TXAA, DSR | ||||||
Максимальная глубина цвета на канал, бит Внутренняя для 3D рендеринга | 32 | ||||||||
Расширенный динамический диапазон цветопередачи (HDR), бит | 128 | ||||||||
Параллельный рендеринг (MRT) Рендеринг одновременно в № буферов | 8 | ||||||||
Декодирование MPEG-2 Поддерживаемые уровни декодирования видео | IDCT, MoComp | VLD, IDCT, MoComp | VLD, IDCT, MoComp, Deblocking, Data Partitioning | ||||||
Декодирование WMV Поддерживаемые уровни декодирования видео | IDCT | VLD, IDCT, MoComp, Deblocking, Data Partitioning | |||||||
Декодирование VC-1 Поддерживаемые уровни декодирования видео | IDCT | VLD, IDCT | VLD, IDCT, MoComp, Deblocking, Data Partitioning | ||||||
Декодирование H.264 Поддерживаемые уровни декодирования видео | VLD_NoFGT | VLD, IDCT, MoComp, Deblocking, Data Partitioning | |||||||
Декодирование MPEG-4 Part 2 Поддерживаемые уровни декодирования видео | VLD, IDCT, Deblocking | ||||||||
Декодирование AVC MVC Ускорение декодирования для Blu-Ray 3D | Нет | Да | |||||||
Декодирование HEVC Аппаратное декодирование HEVC | Да | ||||||||
Dual-Stream Поддержка декодирования двух видеопотоков одновременно | Да | ||||||||
Максимальное разрешение MPEG1/MPEG2, пикселей Макимальное разрешение, при котором поддерживается аппаратное ускорение декодирования MPEG1/MPEG2 | 4080*4080 | ||||||||
Максимальное разрешение H.264 Макимальное разрешение, при котором поддерживается аппаратное ускорение декодирования H.264 | 4096*4096 | ||||||||
Поддержка Pure video, Вт Поддерживаемая версия NVIDIA Pure Video | VP7 | ||||||||
Устранение чересстрочности (Deinterlacing) Поддерживаемые алгоритмы устранения чересстрочности | PixelAdaptive | ||||||||
Поддержка Direct3D, версия Маскимальная поддерживаемая версия API | 10.0 | 11.0 | 11.1 | 12.0 | 12, Feature Level 12.1 | ||||
Поддержка OpenGL, версия Маскимальная поддерживаемая версия API | 3.3 | 4.1 | 4.2 | 4.5 | |||||
Поддержка CUDA, ComputeCapability | 1.3 | 2.0 | 2.1 | 3.0 | 5.2 | ||||
Поддержка PhysX | Да | ||||||||
Поддержка OpenCL, версия Маскимальная поддерживаемая версия API | 1.0 | 1.1 | 1.2 | ||||||
Поддержка DXVA, версия Маскимальная поддерживаемая версия API | 2.0 | ||||||||
Поддержка XvMC | Нет | ||||||||
Поддержка VDPAU Поддерживаемый набор функций для API, A | A | C | F | ||||||
Частота интегрированного RAMDAC, МГц | 2×400 | 400 | |||||||
Максимальное разрешение для VGA | 2048*1536*85 Гц | 2048×1536*85 Гц | |||||||
Максимальное разрешение для цифрового подключения | 2560*1600*60 Гц | 2560×1600*60 Гц | 5120×3200*60 Гц | ||||||
Поддержка TwinView Возможность одновременной работы с двумя дисплеями | Да | ||||||||
Многомониторность Максимальное количество поддерживаемых дисплеев | 4 | ||||||||
Поддержка 30-битного режима | Да* | нет данных | Нет данных | ||||||
Интегрированная поддержка TV-выхода Аналоговый ТВ-выход (Composite и S-Video) | Да | Нет | |||||||
Интегрированная поддержка HDTV Аналоговый ТВ-выход (Component YPbPr) | 1080i | Нет | |||||||
Интегрированная поддержка DVI, версия Трансмиттер TMDS | 2xDual-Link* | 2xDual-Link | 1xDual-Link | ||||||
Интегрированная поддержка DisplayPort, версия | 1.0 | 1.1 | 1.2 | 3*1.2 | |||||
Интегрированная поддержка HDMI | 1.3 | 1.4 | 1.4a | 2.0 | |||||
Поддержка HDCP Система защиты цифрового сигнала (DRM) | Да* | Да | |||||||
HDMI Audio, Вт Поддерживаемые форматы звука | LPCM 2.0, DD 5.1, DTS 5.1* | LPCM 7.1, DD 5.1, DD+ 7.1, DTS 5.1, AAC 5.1 | LPCM 7.1, DD 5.1, DD+ 7.1, D-TrueHD 7.1, DTS 5.1, DTS-HD 7.1, AAC 5.1 | ||||||
VR Direct Поддержка технологии виртуальной реальности | Да | ||||||||
Максимальное энергопотребление, Вт | 236 | 245 | 230 | 160 | 170 | 195 | 120 | 90 | |
Усиление электропитания Тип коннектора | PCIE 8p + PCIE 6p | 2 PCIE 6p | 1 PCIE 6p | ||||||
Блоки операций растеризации (ROP). Поломка и ремонт видеокарты
Похожие главы из других работ:
Автоматизация учета банковских операций и ее реализация в программе «1С Бухгалтерия»
2.2 Характеристика бизнес-процессов по учету банковских операций. Декомпозиция бизнес процесса банковских операций
Если всю деятельность компании можно разделить на бизнес процессы, то и процессы можно разделить на более мелкие составляющие. В методологии построения бизнес процессов это называется декомпозицией…
Внутренние и периферийные устройства ПК
1.7. Блоки расширения
Блоки (платы) расширения или карты (Card), как их иногда называют, могут использоваться для обслуживания устройств, подключаемых к IBM PC. Они могут использоваться для подключения дополнительных устройств (адаптеров дисплея, контроллера дисков и т.п.)…
Изучение дискретной модели популяции при помощи программы Model Vision Studium
1.4 Блоки и связи
Основным « строительным элементом » описания в MVS является блок. Блок — это некоторый активный объект, функционирующий параллельно и независимо от других объектов непрерывном времени. Блок является ориентированным блоком…
Использование LMS Moodle в учебном процессе
3.2 Блоки в курсе
Для любого курса обязательно наличие центральной области. Левой и правой колонки с блоками может не быть. Но различные блоки, входящие в состав системы управления обучением Moodle, увеличивают функциональность…
Исследование возможностей преподавателя в системе дистанционного обучения Moodle
2.2 Блоки курса
Для добавления новых ресурсов, элементов, блоков или редактирования имеющихся в вашем курсе нажмите кнопку Редактировать, расположенную в блоке управления. Общий вид окна курса в режиме редактирования представлен на рисунке 2.5: Рисунок 2…
Моделирование при разработке программного обеспечения
5. Строительные блоки UML
Словарь языка UML включает три вида строительных блоков: сущности; отношения; диаграммы. Сущности — это абстракции, являющиеся основными элементами модели…
Моделирование работы в библиотеке
1.1 Операторы — блоки
Операторы — блоки формируют логику модели. В GPSS/PC имеется около 50 различных видов блоков, каждый из которых выполняет свою конкретную функцию. За каждым из таких блоков стоит соответствующая подпрограмма транслятора…
Основные возможности CSS3
5. Разговорные блоки
Можно оригинально оформить текст с помощью разнообразных разговорных блоков, которые, опять таки, сделаны на основе CSS3 технологий. (Рис 5.) Рис 5…
Основные возможности CSS3
9. Полупрозрачные блоки
Эффект полупрозрачности элемента хорошо заметен на фоновом рисунке и получил распространении в разных операционных системах, потому что смотрится стильно и красиво…
Подготовка текстового документа в соответствии с СТП 01-01
2.7. Блоки расширения
Блоки (платы) расширения или карты (Card), как их иногда называют, могут использоваться для обслуживания устройств, подключаемых к IBM PC. Они могут использоваться для подключения дополнительных устройств (адаптеров дисплея, контроллера дисков и т.п.)…
Поломка и ремонт видеокарты
Блоки текстурирования (TMU)
Эти блоки работают совместно с шейдерными процессорами всех указанных типов, ими осуществляется выборка и фильтрация текстурных данных, необходимых для построения сцены…
Программа регистрации процесса производства для автоматизированной системы управления предприятием электронной промышленности
1.2.2 Блоки MES-систем
Различают 11 типов блоков, из которых может быть изготовлена конкретная MES система для того или иного производства…
Разработка программного комплекса расчета компенсаций по капитальному ремонту
4.2 Блоки данных
На самом низшем уровне гранулярности данные базы данных Oracle хранятся в блоках данных. Один блок данных соответствует определенному числу байтов физического пространства на диске…
Розробка апаратно-програмного забезпечення системи управління транспортними платформами в Simatic Step-7
1.3.2 Системні блоки
Системні блоки є компонентами операційної системи. Вони можуть містити програми (системні функції, SFC) або дані (системні блоки даних, SDB). Системні блоки надають доступ до важливих системних функцій…
Устройства, входящие в состав ЭВМ7. Блоки расширения
Блоки (платы) расширения или карты (Card), как их иногда называют, могут использоваться для обслуживания устройств, подключаемых к IBM PC. Они могут использоваться для подключения дополнительных устройств (адаптеров дисплея, контроллера дисков и т.п.)…
Обзор видеокарты ASUS STRIX R9 380 | Дайджест новостей
Доброго времени суток, уважаемые читатели блогов на сайте Клуба Экспертов!
«На носу» замечательный праздник — Новый год! Впереди нас ждут 11 дней, которые, несомненно, стоит посвятить семье, близким людям и родственникам, друзьям и подругам, безбашенным вечеринкам и домашним посиделкам, зимним играм и забавам, лыжам и санкам, снежкам и ледянкам, походам в кино и театр, ёлке, салату оливье и мандаринкам … Простите, что-то меня понесло не в ту сторону. Целых 11 дней для того, чтобы форма вашей пятой точки приняла очертания компьютерного стула, а глаза приобрели красный оттенок, ведь впереди, по ту сторону экрана, сотни поверженных врагов, километры дерзких автопогонь, часы налета на лучших истребителях всех времен и тысячи потраченных боеприпасов в танках. А что нужно для всего этого компьютерного фана? Конечно, хорошая видеокарта. Не собираюсь вдаваться в сравнение продукции двух столпов рынка — AMD и NVidia, никаких выискиваний лучших или наиболее эффективных в своей ценовой категории. Просто перейду к обзору поступившей мне на обзор видеокарты ASUS STRIX-R9380-DC2OC-2GD5-GAMING.

Если вы хоть раз занимались самостоятельным подбором гаджетов или различных комплектующих, то название компании ASUS вам известно с вероятностью 99%. С ее именем неразрывно связан термин «инновационность». Действительно сильный бренд на рынке, продукция которого отвечает высочайшим стандартам качества. В большинстве своем выпускает устройства собственной разработки либо существенно доработанные, по сравнению с референсными вариантами. Один из ведущих игроков на рынке околокомпьютерной техники по разным направлениям, постоянный победитель всевозможных рейтингов и обладатель «золотых» наград и титулов «лучший выбор» именитых профильных журналов и изданий.
Официальный сайт — www.asus.com
Упаковка, в которой продается видеокарта, приличных размеров, целых 41 сантиметр в длину, 23.5 сантиметра в высоту и 9 сантиметров в глубину. Она очень красочно и стильно оформлена. Ключевым образом выбрана кибер-сова, ведь карта относится к «геймерской» серии ASUS STRIX, на название которой, маркетологов вдохновили древние мифы о сове, как обладателе самого острого слуха и зрения, позволяющих заметить и, бесшумно и точно, среагировать даже на малейшее движение.


На обратной стороне коробки отражены ключевые особенности видеокарты:
- высокоэффективная и малошумная система охлаждения DirectCU II с большой площадью радиаторов системы охлаждения
- поддержка бесшумной работы при низкой нагрузке на графическую подсистему
- высококачественная система питания видеокарты, построенная на элементах премиум класса
- программное обеспечение GPU Tweak II и XSplit / Gamecaster для удобного разгона и записи стримов игрового процесса.

Внутри основной коробки вложены стильные коробки с комплектацией, проложенные толстыми слоями вспененного уплотнителя. Видеокарта помещена в антистатический пакет и надежно защищена от внешнего воздействия при транспортировке.
К сожалению в оформлении отсутствует русский язык, единственное исключение — рекомендуемые системные требования к компьютеру, в который будет устанавливаться видеокарта:
- оперативная память — 4 ГБ или более
- материнская плата с портом PCI Express и установленным драйвером чипсета PCIe
- операционная система Windows 7 или новее
- минимальная мощность блока питания 500 Вт (до 24 А по линии питания 12 В)
- один разъем дополнительного питания 8-pin.
Примечание: на коробке указана необходимость 6-pin разъема дополнительного питания, по факту на видеокарте 8-pin разъем.

Как ныне модно писать в магазинах — «никто не любит вскрытые упаковки», поэтому на коробке присутствуют заводские наклейки-пломбы.
- Модель: ASUS STRIX-R9380-DC2OC-2GD5-GAMING
- Видеопроцессор: AMD Radeon R9 380
- Технологический процесс: 28 нм
- Количество универсальных процессоров: 1792
- Число текстурных блоков: 112
- Число блоков растеризации: 32
- Версия шейдеров: 5.0
- Объем видеопамяти: 2 ГБ
- Тип памяти: GDDR5
- Частота GPU: 990 МГц (Gaming), 1010 МГц (OC)
- Эффективная частота памяти: 5500 МГц
- Разрядность шины памяти: 256 бит
- Интерфейс подключения: PCI-E 3.0
- Интерфейсы подключения устройств вывода: 1 x DisplayPort, 1 x HDMI, 1 x DVI-D, 1 x DVI-I
- Максимальное разрешение: по DVI 2560 x 1600
- Разъемы дополнительного питания: 1 x 8 pin
- Минимальные требования к блоку питания: 500 Вт (24 А по линии 12В )
- Система охлаждения: DirectCU II (два вентилятора) с поддержкой бесшумного режима
- Количество занимаемых слотов: 2 (два)
- Размеры: 271 мм x 139 мм x 42 мм

Несмотря на крайне стильное и презентабельное оформление упаковки, комплектация весьма скромная, это сама видеокарта, DVD-диск с драйверами, наклейка STRIX и инструкция по быстрой установке. Производители потихоньку перестают комплектовать видеокарты переходниками для дополнительного питания, так как, в большей своей массе, современные блоки питания уже оснащены необходимыми разъемами.

Лицевую часть видеокарты занимает массивная система охлаждения. К оформлению пластикового декоративного кожуха, выполняющего роль крепежа для вентиляторов, дизайнеры ASUS подошли основательно. Он полностью стилизован под специфичные для серии STRIX рубленые формы черного цвета с декоративными вставками узоров красного цвета и кругами на вентиляторах, похожими на глаза хищницы совы. Контактные площадки PCI-E закрыты резиновым колпачком, который необходимо снять перед установкой карты в слот.

С обратной стороны видеокарты — металлическая пластина, закрывающая плату, цель которой не только теплоотвод, но и увеличение механической жесткости конструкции и исключение прогибания (под собственным весом), все таки длина карты не маленькая, по спецификации — 271 мм, реальный замер показал — 274 мм.

ASUS STRIX R9 380 оснащена четырьмя выходами для подключения мониторов или других устройств отображения, это DisplayPort, HDMI, DVI-D и DVI-I. Разъемы DVI закрыты заглушками на период транспортировки. Переходника для подключения мониторов или проекторов через VGA нет в комплекте.

В части дополнительного питания, видеокарта имеет достаточно скромные аппетиты и использует всего один разъем 8-pin блока питания. Он развернут в верхнюю часть видеокарты, за счет чего повышаются шансы вместить ее в корпусы с жесткими ограничениями по свободному месту. Близкое расположение к тепловой трубке на удобство подключения штекера особо не влияет.

Вентиляторы системы охлаждения подключены отдельным кабелем к 5-ти контактному разъему питания на самой видеокарте.

Пластиковый кожух, на котором они закреплены, снимается просто, так как закреплен на пластиковых защелках. Это позволяет не трогать гарантийную пломбу и упрощает процедуру чистки радиатора от пыли.

Для активного охлаждения применены 11-ти лопастные вентиляторы модели FD10015h22S производства FirstD, с питанием 12 В. При включении компьютера и прохождении первичного теста они стартуют на несколько секунд, после чего останавливаются. При низкой нагрузке находятся в покое, обеспечивая полностью бесшумную работу видеокарты. При росте температуры графического ядра выше 70 градусов происходит запуск вентиляторов со скоростью вращения около 900 оборотов в минуту, при этом звук их работы по прежнему не слышен. Дальнейшее повышение оборотов происходит постепенно, в зависимости от температуры графического ядра. На оборотах от 1500 до 1900 оборотов в минуту, звук их работы можно назвать умеренным, в диапазоне от 2100 до 2450 оборотов кроме шума потока воздуха добавляется неприятный гул крыльчатки, на больших скоростях, вплоть до максимальных 3000 оборотов, гул пропадает и превращается в настоящий рёв вентиляторов абсолютно некомфортного уровня. На практике добиться работы вентилятора выше 1900-2000 оборотов тяжело, максимальная температура при сильной нагрузке держится в пределах 75 C, соответственно скорость «вертушек» находится близко к минимальным значениям.

Радиатор охлаждения большой площади, длиннее платы. Он построен на трех тепловых трубках с диаметром около 1 см. Радиатор охлаждает только графическое ядро, с которым соприкасается по принципу прямого контакта тепловых трубок. Оребрение, увеличивающее площадь рассеивания тепла, совмещено с трубками посредством пайки.
Компания ASUS не приветствует снятие системы охлаждения пользователем, поэтому на одном из винтов, ее крепящих, стоит заводская пломба. Сняв ее вы автоматически лишаетесь гарантийного обслуживания, а это, ни много ни мало, целых 3 года спокойствия. Больше всего страдают от этого факта любители поставить водяное охлаждение, так как сделать это, не лишившись гарантии, у них нет возможности.


ASUS традиционно использует текстолит черного цвета при производстве своих видеокарт серии STRIX. При изготовлении, используются твердотельные конденсаторы, МОП-транзисторы и дроссели высокого качества, а как иначе, учитывая малошумность системы охлаждения, нелепо бы звучали паразитные звуки от системы питания, да и долгую работу в высокотемпературных режимах выдержат только действительно качественные элементы. По центру платы расположен графический чип AMD R9 380 (Antigua) закрытый защитной рамкой. Схемотехника платы отличается от референсной, больше всего в части системы питания, которая выполнена в виде 6-ти фаз питания графического ядра (с охлаждением дополнительным единым радиатором черного цвета) и 2-х фаз питания видеопамяти без дополнительного охлаждения.

В качестве ШИМ-контроллера установлена микросхема с маркировкой Digi+ ASP1300.

Память набрана из 8 микросхем Elpida W2032BBBG по 256 МБ каждая, общий объем 2 ГБ, разрядность шины 256 бит. По отзывам разных энтузиастов, данная память не очень хорошо работает на частотах выше номинальных, поэтому задела для разгона практически нет.
Тестирование видеокарты ASUS STRIX R9 380 проводилось в системном блоке на базе следующих комплектующих:
- Корпус: Cougar Solution 2
- Процессор: Intel Core i5-3330 3 ГГц
- Кулер: DEEPCOOL Ice Edge Mini FS v2.0
- Материнская плата: Gigabyte H77-DS3H
- ОЗУ: Kingston KHX1866C9D3/4GX х 2
- Жесткие диски: WD GREEN 10EARS и Seagate ST2000DM001
- SSD: Transcend TS128GSSD320
- Блок питания: Corsair CS550M.

В корпусе Cougar Solution 2 достаточно места для установки длинных видеокарт, поэтому с креплением проблем не возникло. Попутно обнаружилось, что на видеокарте, рядом с разъемом дополнительного питания, есть светодиод-индикатор включенного состояния/ошибки.

Первым делом, после установки платы, потребовалось установить драйвер в операционной системе. Использовалась последняя стабильная версия (на момент написания обзора) ПО Radeon — 15.12. Также была обновлена версия прошивки видеокарты с заводской 015.048.000.061 на 015.049.000.004.

GPU-Z

По характеристикам GPU и памяти, ASUS STRIX-R9380-DC2OC-2GD5-GAMING отличается от референсных плат только увеличенной на 20 МГц частотой графического процессора. Кроме того, на программном уровне реализована работа в двух режимах «Gaming» и «OC», последний отличается повышением частоты GPU до 1010 МГц. Честно говоря, никогда не понимал такой оверклокинг (на пару процентов скорости), результаты которого в тестах тяжело заметить и они больше похожи на погрешность в измерениях. Дальнейшее тестирование проводилось в «стандартном» режиме «Gaming» GPU 990 МГц/Память 5500 МГц.
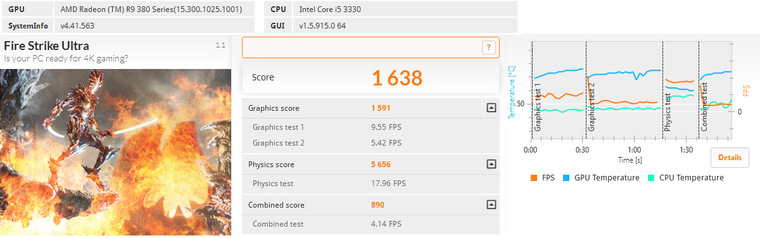
Тестовые пакеты дают цифры которыми можно оперировать сравнивая производительность различных моделей видеокарт в относительных единицах. Ниже приведены значения, полученные в популярных бенчмарках.
3DMark
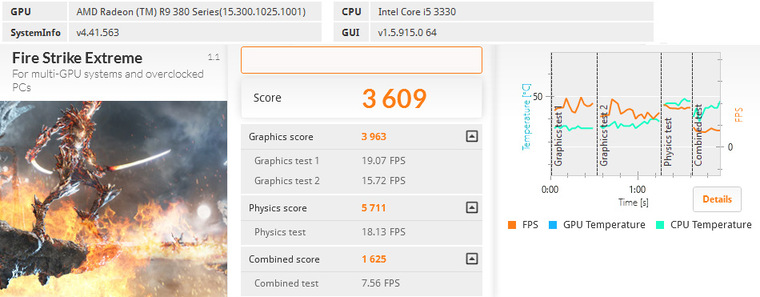


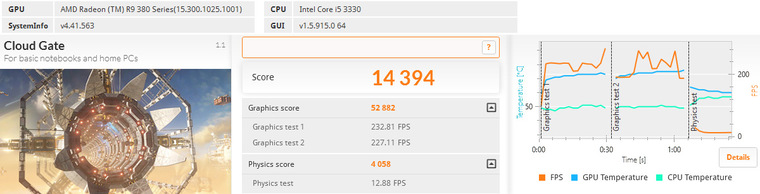
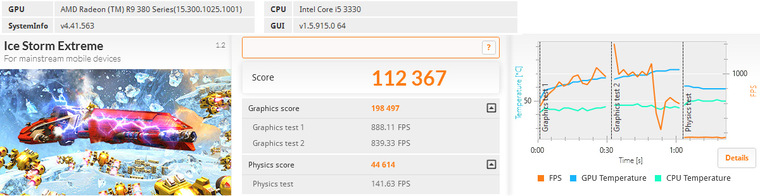
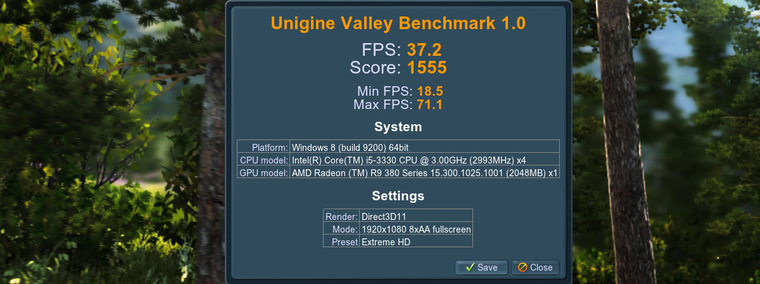
Valley Benchmark 1.0
FurMark 1.17

В Furmark GPU Benchmark с настройками 1080 (FHD), получилось 3006 баллов и 50 FPS в среднем. В режиме прогрева видеокарты (GPU Stress Test) в течение 60 минут, максимальная температура составила 75 градусов Цельсия при температуре в помещении 26 C.
Игры
Цифры в синтетике хороши для сравнительного анализа, но не могут дать однозначный ответ на вопрос: «Сколько кадров в секунду будет в конкретном приложении?». Именно поэтому были проведены замеры минимального, среднего и максимального значения кадров в секунду (FPS) в нескольких популярных играх. Во всех из них было выставлено разрешение 1920 x 1080 (FullHD) и максимально возможные настройки графики. Параметры сглаживания (FXAA, TAA и т.п.) выставлялись на минимально возможные значения (2х), так как, на мой взгляд, даже в FullHD разрешении, при отключенном сглаживании, «лесенки» пикселей по краям объектов сильно портят впечатление от игры, а настройки сглаживания выше 2х в динамичной картинке «на глаз» практически не отличаются. Хотелось получить цифры как можно более приближенные к обычной эксплуатации в качестве игровой станции. Замеры FPS проводились во время реального игрового процесса или с помощью встроенных в игры бенчмарков, показания снимались программой FRAPS.
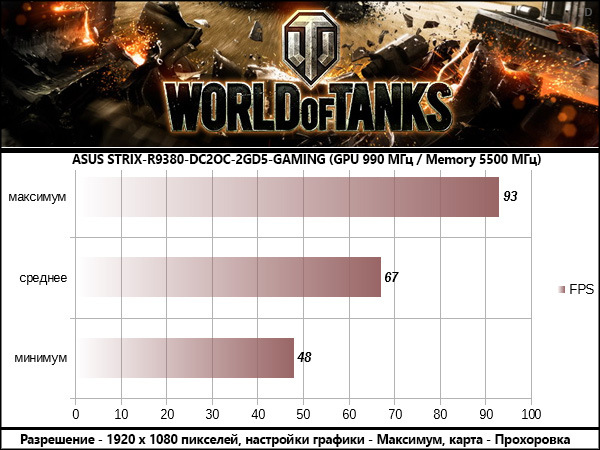
World of Tanks
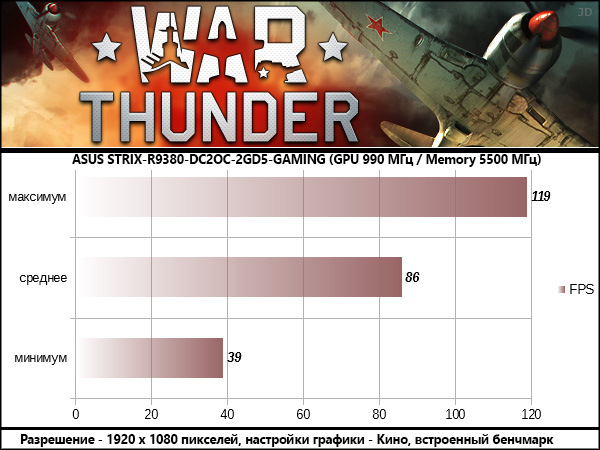
War Thunder
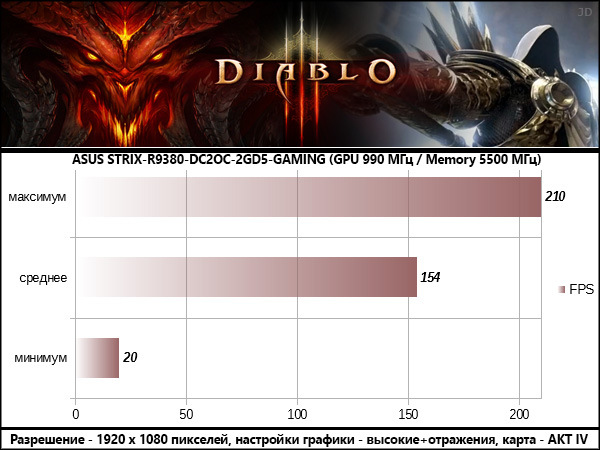
Diablo 3
Warface

Dying Light

FarCry 4

GTA V

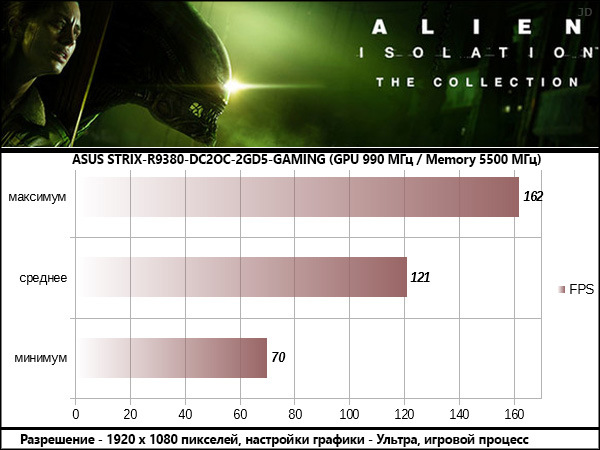
Alien Isolation
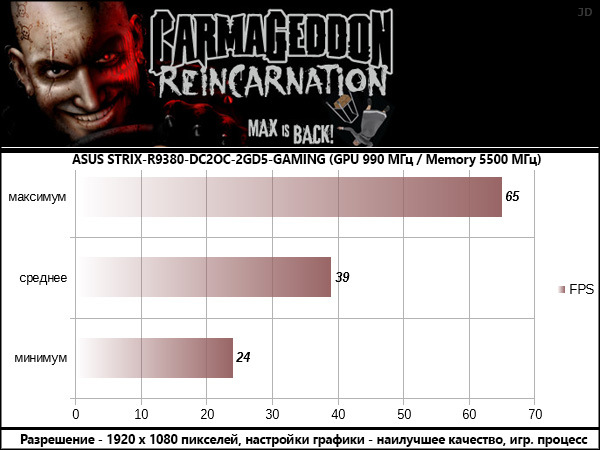
Carmageddon Reincarnation
Fallout 4

The Witcher 3: Wild Hunt
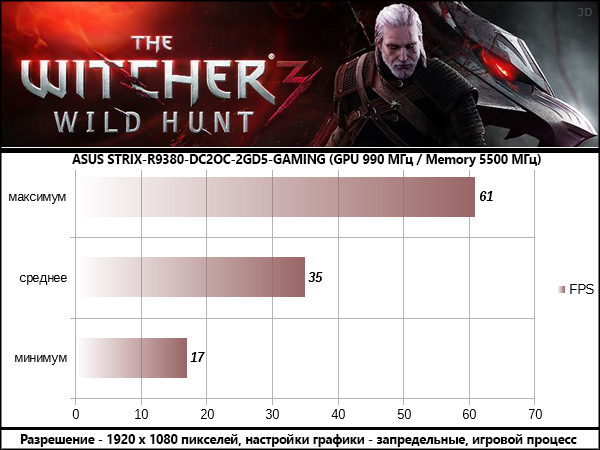
В результатах всех протестированных игр опираться стоит на среднее значение FPS, оглядываясь на значение минимального, как индикатора возможных узких мест в сценах перегруженных спецэффектами . Максимальные значения статистической пользы не несут, так как «выстреливают» в редкие моменты, когда в поле зрения игрока находится мало объектов, как правило это игровые сцены внутри помещений.
Для энтузиастов, в комплекте к картам серии


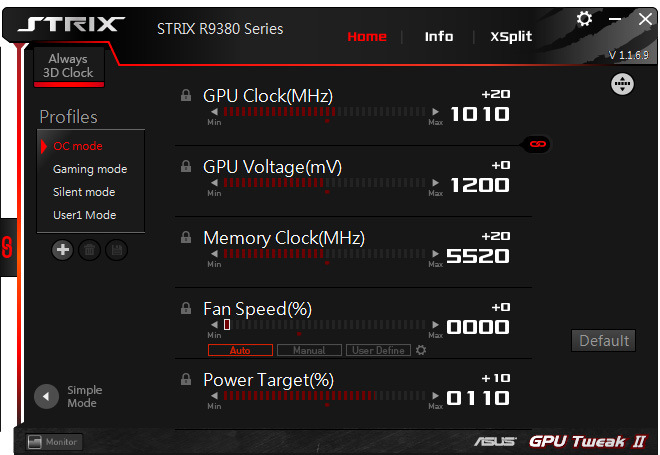
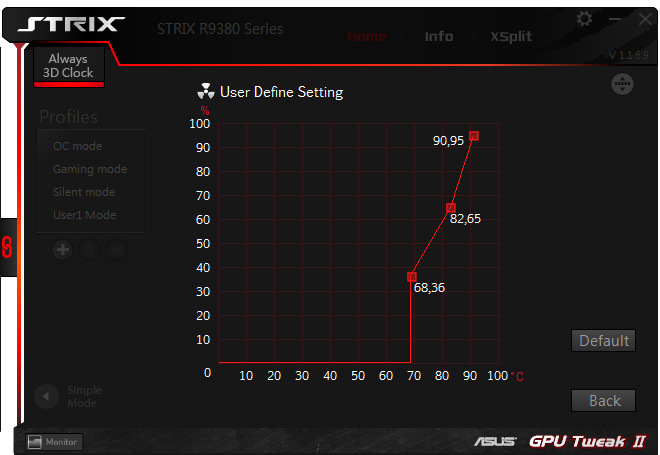
Примечание: в ходе попыток разгона, сначала были найдены значения, при которых отсутствовали артефакты и отвалы графического драйвера — частота GPU 1200 МГц, эффективная частота памяти 5700 МГц при поднятии напряжения на GPU до 1,331 В. При этом результаты в 3DMark и играх не изменились, по сравнению с базовыми частотами. Данный факт навел на мысли о недостаточности производительности тестовой конфигурации ПК или пределе возможностей GPU. Но детальный анализа показал, что, при выставленных 1200 МГц на GPU, под нагрузкой идет постоянный throttling, итоговый график частот — пилообразный, т.е. среднее значение намного ниже установленного. Данный факт не сразу бросился в глаза, так как, по умолчанию, в ASUS GPU TweakII стоит интервал обновления графиков — 3 секунды и их пилообразность смазывалась редким обновлением показаний. При снятии значений с датчиков раз в секунду все стало отлично видно.
Опытным путем были получены значения, при которых графический чип не уходил в тротлинг — GPU 1150 МГц, напряжение на GPU — 1.3 В. Память стабильно заработала на эффективной частоте 5848 МГц, при больших значениях наблюдалось пропадание изображения.

Повторный прогон теста 3DMark Firestrike Extreme 1.1, при таком разгоне, показал увеличение результата до 3840 тестовых пунктов, т.е. приблизительно на 6,5%.

Если переводить эти цифры в реальные приложения, то получается увеличение среднего FPS в играх на 1-3 кадра в секунду. Такие колебания FPS близки к погрешности замеров, поэтому говорить о целесообразности разгона данной видеокарты не приходится.
Видеокарта ASUS STRIX-R9380-DC2OC-2GD5-GAMING, пришедшая на смену R9-285, показала неплохие результаты в протестированных играх. Разработчики компьютерных «игрушек», как правило, разделяют варианты настроек качества изображения на несколько градаций вида: минимум / средние / высокие / ультравысокие. Если вы играете в широко распространенном ныне разрешении FullHD 1920 x 1080 точек (или меньше) и не будете выставлять запредельные/ультра настройки графики в играх, а ограничитесь «высокими» параметрами картинки, то сможете комфортно играть с количеством кадров в секунду (FPS) около 35-45. Кроме того, карта не требует вложений в мощный блок питания, для ее функционирования подойдет практически любой от 500 Вт с одним 8-пин разъемом. Установленная система охлаждения весьма эффективна и работает очень тихо, а в моменты низкой нагрузки, так вообще бесшумно.
Разгонный потенциал тестового экземпляра ASUS STRIX R9 380 слабый и не представляет интереса. Я не сторонник излишней нагрузки на комплектующие из-за нескольких FPS. Возможно, позже, при появлении более требовательных игр или при переходе на большее разрешение этот вопрос станет актуальнее, но, по моему личному опыту, к тому времени актуальнее будет сменить платформу полностью, чем выжимать из нее «последние соки».
Обсуждать цену в рамках данного обзора также не буду, потому как постоянные курсовые разницы кардинально изменили ситуацию на рынке комплектующих, при том что доходы большинства покупателей остались на прежнем уровне и говорить сейчас о пресловутом среднем ценовом диапазоне вообще кощунственно.

На этом я заканчиваю свой финальный (в 2015 году) обзор и хочу пожелать всем хорошего, позитивного, Нового Года и, несмотря на мое шуточное введение в начале текста, все-таки потратить ближайшие каникулы отдыхая подальше от экрана монитора 🙂
Фотографии к обзору в большем разрешении доступны для просмотра в соответствующем фотоальбоме.