
что он собой представляет и для чего нужен. Детальный обзор с примерами
Атрибут «rel=» активно используется разработчиками сайтов для взаимодействия с поисковыми системами. Он включает в себя несколько значений, например nofollow или canonical. Каждый из них предназначен для решения определенных задач.
В сегодняшней статье я подробно разберу атрибут «rel=» и покажу на примерах, в каких случаях его лучше всего использовать.
Атрибут «rel=»: определение и предназначениеRel (от англ. «relationship» – отношение) – это атрибут HTML, описывающий ссылку. Он обозначает, что это за ссылка и на какой адрес она ведет. Работает это следующим образом: когда ссылка направляет пользователя на адрес, атрибут рассказывает поисковым системам, почему ссылка ведет на этот адрес. Например, ссылаться можно на файл стилей, который взаимодействует со страницей.
Еще ссылка может вести на PDF или иноязычную версию документа. Ссылка, как взаимосвязь между текущим и иным документом, часто используется в электронных книгах для переадресации на следующую или предыдущую страницу.
Современные браузеры чаще всего не обращают внимание на атрибут rel, но вот поисковые системы, напротив, уделяют этому пристальное внимание. Кроме того, социальные сети будут лучше взаимодействовать с веб-ресурсом, если его ссылки будут определены.
Атрибут rel может использовать вместе с тегом <a>:
<a rel="..." href="...">...</a>
Также допустимо его появление и в теге <link>:
<link rel="..." href="...">
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Значения атрибута «rel=»Если мы говорим об атрибуте rel, то чаще всего под ним подразумевается использование значения «nofollow», но есть и другие не менее важные значения.
rel=nofollowИспользуется, когда нужно, чтобы страница, на которую ссылается пользователь, не увеличила свой ссылочный вес благодаря этой ссылке. Другими словами, по этой ссылке не передается индекс цитирования, используемый Яндексом, и PageRank, используемый Google.
Другими словами, по этой ссылке не передается индекс цитирования, используемый Яндексом, и PageRank, используемый Google.
<a rel="nofollow" href="index.html">Эту страницу не нужно посещать</a>
Использование такого значения оправдано на сайтах с формами для комментариев: пользователи могут оставлять ссылки на некачественные ресурсы, а из-за этого сайт рискует потерять доверие поисковых систем.
rel=alternateИспользуется для указания того, что ссылка ведет на альтернативное изображение страницы:
<a rel="alternate" type="application/pdf" href="page.pdf">Страница в формате PDF</a>
Также есть еще одна вариация:
...rel="alternate" hreflang="en"...
Она помогает поисковой системе понять геопринадлежность страницы, чтобы предоставить пользователю нужную языковую версию в результатах поиска. С ее помощью мы показываем поисковым роботам, что на сайте один и тот же контент доступен на разных языках. Благодаря этому поисковики могут автоматически показывать корректную языковую версию на основе географических и языковых данных.
Благодаря этому поисковики могут автоматически показывать корректную языковую версию на основе географических и языковых данных.
<a rel="alternate" hreflang="en" href="english-version.html">English</a>rel=canonical
Указывает на предпочитаемый адрес, который будет участвовать в поиске. Используется в теге <header>:
<link rel="canonical" href="http://www.example.com/">
Указывает на то, что приведенная ссылка относится к информации об авторе данной страницы или статьи.
<a href="/author-page.html" rel="author">link text</a>rel=bookmark
Обозначает, что эта ссылка является якорем и ведет на какую-то часть в этом же документе. Также она говорит поисковым системам, что эта ссылка постоянная.
<a rel="bookmark" href="about.html">Постоянная ссылка на страницу</a>rel=help
Такое значение используется для обозначения справочников. Браузер сопоставляет эту справочную информацию с родительским контейнером, в котором была размещена эта ссылка.
Браузер сопоставляет эту справочную информацию с родительским контейнером, в котором была размещена эта ссылка.
Например, в форме на сайте это прописывается через тег <a>:
<form> <label for="comment">Comment:</label> <textarea></textarea> <input type="submit" value="Text Comment"> <a rel="help" href="comments.html">Help</a> </form>rel=license
Указывает на то, что по ссылке размещено лицензионное соглашение, которое относится к основному тексту страницы.
<a rel="license" href="license.html">Посмотреть лицензионное соглашение</a>rel=dns-prefetch, preconnect, prefetch, preload
Ссылки с такими значениями пригодятся в тех случаях, когда нужно сослаться на внешние ресурсы, которые пользователь откроет с большой вероятностью. Браузер кэширует эту ссылку заранее, поэтому она открывается быстрее:
<a rel="prefetch" href="license.rel=taghtml">Здесь что-то интересное</a>
Определяет категорию сайта или ключевой запрос:
<a rel="tag" href="search.html">Эта ссылка относится к странице с каталогом</a>
Этот тип сообщает, что ссылка ведет на интерфейс поиска:
<a rel="search" href="search.html">Поиск по сайту</a>rel=icon
Необходим для того, чтобы связать содержимое сайта с иконкой:
<link rel="shortcut icon" href="/favicon.ico"></link>rel=external
Означает, что ссылка ведет на другой сайт, будет индексироваться и передавать вес. В WordPress этот атрибут часто используется в комментариях. Может функционировать совместно с nofollow, чтобы ссылка не передавала вес:
<a rel="external nofollow" href="page.html">Открыть в новой вкладке</a>rel=first, up, prev, next, last
Такие значения необходимо прописывать для тех ссылок, которые используются для навигации по странице. Они ведут в начало, конец, на предыдущую или последующую страницу:
Они ведут в начало, конец, на предыдущую или последующую страницу:
<ul> <li><a rel="next" href="page-1.html">Первая страница</a></li> <li>Исходная страница</li> <li><a rel="prey" href="page-3.html">Последняя страница</a></li> </ul>Заключение
Атрибут rel позволяет улучшить связь между страницами и сделать их более привлекательными для поисковых роботов. В результате это может заметно сказаться на посещаемости ресурса. Не бойтесь использовать данный атрибут – он может существенно улучшить показатели вашего сайта.
Атрибут «rel=» что собой представляет и для чего нужен? — статьи СТК Промо
Термин rel в переводе с английского обозначает взаимосвязь. В HTML он его суть заключается в том, чтобы давать информацию, насколько текущий документ связан с тем, на который он содержит ссылку.
Когда определенная ссылка переводит нас на другой ресурс, атрибут rel используется для объяснения логики – почему именно на этот адрес. Ссылаться можно на страницу, содержание которой взаимосвязано с текущим документом, или на файл, который нужно использовать с этим документом. Еще ссылка может быть PDF или иноязычной версией документа. Ссылка, как взаимосвязь между текущим и иным документом используется часто в электронных книгах для переадресации на следующую (предыдущую) страницу.
Ссылаться можно на страницу, содержание которой взаимосвязано с текущим документом, или на файл, который нужно использовать с этим документом. Еще ссылка может быть PDF или иноязычной версией документа. Ссылка, как взаимосвязь между текущим и иным документом используется часто в электронных книгах для переадресации на следующую (предыдущую) страницу.
Сегодня браузеры практически не обращают внимания на атрибут rel, но на него обращают внимание роботы поисковых систем. Некоторые ресурсы, такие как соцсети, также лучше будут взаимодействовать с сайтом, если типы ссылок на нем будут определены. Возможно использование, как к ссылке с тегом <a> с таким синтаксисом:
<a rel="..." href="...">...</a>
Также возможно использование <link>, который отвечает за связь с другим документом. В этой ситуации синтаксис будет таким:
<link rel="..." href="...">
Сегодня активно используют «nofollow». Это значение создает запрет на переход поисковой системы по определенной ссылке.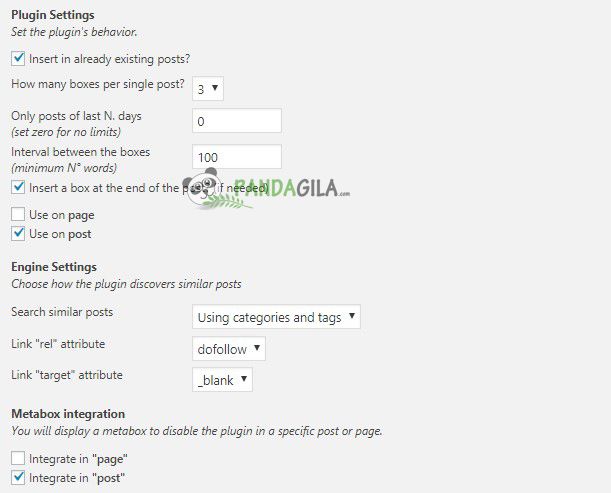 Другими словами не передает им PR и тИЦ. Также используют и другие значения, такие как «canonical». Оно определяет, какой адрес является предпочтительным для поисковых машин. Использование rel может применяться более широко:
Другими словами не передает им PR и тИЦ. Также используют и другие значения, такие как «canonical». Оно определяет, какой адрес является предпочтительным для поисковых машин. Использование rel может применяться более широко:
rel=nofollow
Такое значение используется поисковыми машинами для того, чтобы определить, передает ли ссылка вес той веб-странице, на которую ссылается:
<a rel="nofollow" href="page.html">Робот, не переходи на эту страницу</a>
rel=alternate
Используется для указания того, что ссылка ведет на альтернативное изображение страницы (версия для печати, PDF):
<a rel="alternate" type="application/pdf" href="page.pdf">PDF версия страницы</a>
Для этого типа можно задать hreflang, что позволит указать на то, что ссылка ведет на иноязычную версию:
<a rel="alternate" hreflang="en" href="english-version.html"> Spanish version</a>
rel=canonical
Это значение дает указание на адрес сайта, которому отдается предпочтение при поиске.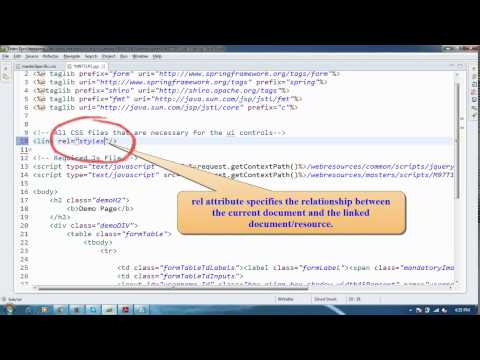
<link rel="canonical" href="http://www.example.com/">
rel=bookmark
Указывает на то, что ссылка не меняется:
<a rel="bookmark" href="about.html">Постоянная ссылка на страницу</a>
rel=author
Используется для сообщения, что ссылка ведет на сведения об авторе страницы (сайта):
<a rel="author" href="about.html">О сайте</a>
rel=help
Говорит о том, что ссылка ведет на текст, являющийся справочной информацией.
<form> <label for="comment">Ваш комментарий:</label> <textarea></textarea> <input type="submit" value="Оставить комментарий"> <a rel="help" href="comments.html">Помощь по комментариям</a> </form>
Эти примеры показывают, что ссылка ведет на контент, раскрывающий информацию о самом тексте, который расположен в комментариях.
rel=license
Указывает на то, что по ссылке размещено лицензионное соглашение, которое относится к основному тексту страницы. Размещение ссылки должно быть ограничено тегом main. Это определяет контент, к которому ссылка привязана:
<a rel="license" href="license.html"> Лицензионное соглашение</a>
rel=dns-prefetch, preconnect preload, preconnect, prefetch
Такие ссылки применяются в случаях, когда используется переадресация на сторонние сайты, которые с высокой степенью вероятности будут открыты. Эта ссылка кэшируется браузером заранее, что позволяет ускорить время на ее открытие в дальнейшем:
<a rel="prefetch" href="license.html">Важная информация!</a>
rel=tag
Определяет категорию сайта или определяет ключевой запрос:
<a rel="tag" href="search.html">Эта страница относится к странице поиска</a>
rel=search
Такая ссылка ведет к поиску на сайте:
<a rel="search" href="search.html">Поиск по сайту</a>
rel=first, up, prev, next, last
Такие ссылки необходимы для навигации по странице. Они ведут на начало, конец, предыдущую, последующую страницы:
<ul> <li><a rel="next" href="page-1.html">2 страница</a></li> <li>Текущая страница</li> <li><a rel="prey" href="page-3.html">4 страница</a></li> </ul>
rel=icon
Необходима для того, чтобы связать содержимое сайта с иконкой:
<link rel="shortcut icon" href="/favicon.ico"></link>
Многие браузеры не учитывают это значение и автоматически связывают содержимое с основным логотипом ресурса. Размер иконки можно менять, для этого используется значение size:
<link rel="icon" href="favicon.png" type="image/png"></link>
rel=external
Такое значение говорит о том, что ссылка будет открыта в новом окне. Также она будет индексироваться. В платформе WordPress это часто используется для комментариев:
Также она будет индексироваться. В платформе WordPress это часто используется для комментариев:
<a rel="external nofollow" href="page.html">Открыть в новом окне</a>
Использование атрибута rel имеет значение и пренебрегать им не стоит. Таким образом вы повысите связь между страницами и в итоге они будут более привлекательно выглядеть для поисковых систем, что скажется на посещаемости сайта.
Атрибут rel=canonical: что это такое
Атрибут rel=«canonical» — специальный тег, который сообщает поисковым системам, какую из страниц с дублированным контентом считать дополнительной, а какую – основной.
Почему появляются страницы с дублированным контентомДубли страниц – это страницы с полностью идентичным содержанием, но с разными URL.
Почему вообще на сайте появляются дублированные страницы? Самые распространенные причины:
- Из-за особенностей CMS на сайте могут появиться страницы с .php или .html, со слэшем и без слэша на конце.
 Например: http://site.ru/page/ и http://site.ru/page
Например: http://site.ru/page/ и http://site.ru/page - На сайте есть страницы с динамическими параметрами URL,
- Меняется структура сайта, но вебмастер, создавая новые страницы, забывает удалить старые.
- Страницы фильтров, сортировок, поиска и страницы пагинации, где текст и мета-теги всех страниц могут быть одинаковыми.
- Сайт переводят на защищенный протокол HTTPS, но он доступен и по HTTP
Если у сайта много дублированных страниц, вебмастеру стоит заняться этим вопросом, т.к.:
- Дубли страниц затрудняют индексацию сайта,
- Яндекс и Google не любят дублированный контент, и сайт может потерять позиции в поиске.
- Поисковая система может отображать в поиске страницу, которая является второстепенной.
Поиск и устранение дублированных страниц является частью поисковой оптимизации сайта. Чаще всего проблему дублей решают с помощью 301 редиректа и атрибута rel=«canonical».
Чаще всего проблему дублей решают с помощью 301 редиректа и атрибута rel=«canonical».
Основная задача атрибута rel=«canonical» показать поисковой системе, какую из страниц с одинаковым контентом считать канонической, т.е. главной, а какую – второстепенной. Благодаря каноническим ссылкам, поисковые роботы поймут, какие страницы нужно индексировать чаще и выбирать для показа в результатах поиска.
Атрибут rel=canonical является одним из сигналов для поискового робота при выборе канонической страницы. Поисковики также ориентируются на протокол (http или https), предпочтительный для пользователя домен, качество страницы, присутствие URL в файле Sitemap и т.д. Несмотря на то что атрибут является лишь рекомендацией для поискового робота, а не строгим предписанием, его использование очень желательно.
Чаще всего вебмастера используют канонические ссылки в следующих случаях:
- Несколько страниц для одной серии продуктов,
- Страницы сортировок товаров в каталоге,
- Использование партнерской программы на сайте,
- Использование одинакового контента на разных доменах или разных языковых версиях сайта,
- Если вебмастер точно знает, что CMS может создавать дубли,
- Страницы с дублями из-за UTM-меток и т.
 д.
д.
Существует несколько способов использования атрибута rel=«canonical»:
- В коде страницы, которая не является основной, между тегами head указать атрибут и абсолютную ссылку на страницу, которую следует считать приоритетной. Например, [link rel=»canonical» href=“https://site.ru/” /].
- Канонические ссылки можно прописывать в файле Sitemap, но так как XML-карта является только рекомендацией для поисковых роботов, они могут ее игнорировать.
- Если страница реализована не в HTML, то можно прописывать канонические ссылки в заголовке HTTP.
- Есть специальные плагины, которые позволяют настраивать канонические ссылки на разных платформах.
Основные ошибки при создании канонических ссылок:
- Каноническая ссылка не индексируется,
- Каноническая ссылка отдает 404 ошибку или 200 код сервера,
- На одной странице прописано несколько ссылок с атрибутом rel=«canonical» (в этом случае будет учитываться только первая ссылка),
- При указании канонических ссылок для одной страницы несколькими способами (например, код сайта и XML-карта), ссылки оказались разными,
- Указанный канонический URL находится на другом домене или поддомене,
- Указана цепочка канонических адресов.
 Например, для страницы site.ru/1 указана каноническая ссылка на страницу site.ru/2, в то время как для адреса site.ru/2 указан канонический адрес site.ru/3.
Например, для страницы site.ru/1 указана каноническая ссылка на страницу site.ru/2, в то время как для адреса site.ru/2 указан канонический адрес site.ru/3. - На страницах пагинации в качестве канонической ссылки указывается первая страница, что делает невозможным индексацию всех остальных страниц. В данном случае корректнее делать каноническую ссылку на страницу «Показать все», если она есть на сайте.
- Содержимое канонической страницы значительно отличается от наполнения второстепенной страницы. В таких случаях поисковые роботы могут игнорировать рекомендации и канонические ссылки.
Проверить корректность размещения ссылок с атрибутом rel=«canonical» можно с помощью программы Screaming Frog SEO Spider.
Поисковый робот узнает об изменениях на сайте при его обходе. Если вебмастер корректно указал канонические страницы и робот последовал рекомендациям, второстепенная страница пропадет из результатов поиска. В Яндексе, например, это можно отследить с помощью сервиса Вебмастер (страница Индексирование — Страницы в поиске (блок Исключённые страницы):
что это такое и как использовать
Оглавление
 org/ListItem»>
Определение nofollow
org/ListItem»>
Определение nofollow- Для чего запрещать индексацию ссылок
- Как проверить наличие закрытых от индексации ссылок
- Обработка значения nofollow атрибута rel поисковой системой Google
- Как используют ссылки в бизнесе
 org/ListItem»>
Какие площадки надо использовать для размещения ссылок
org/ListItem»>
Какие площадки надо использовать для размещения ссылок- Как повысить эффективность закрытых ссылок
Nofollow – тег, который используют веб-мастера при размещении ссылок на сторонние ресурсы, чтобы не превратить сетевой ресурс в бесплатную площадку для наращивания ссылочной массы, не упасть в поисковой выдаче и не быть заблокированным поисковыми системами.
da52af20-8711-4ca8-9bcb-1c66260edad4.png
Ссылки с атрибутом nofollow играют важную роль в продвижении сайтов, несмотря на то, что они не индексируются поисковыми системами. Мнение о полезности использования атрибута rel =»nofollow» расходятся. Многие считают, что на ранжирование сетевого ресурса они не влияют и поэтому получать их бессмысленно.
Давайте узнаем, чем могут быть полезны гиперссылки, закрытые от индексации.
nofollow1.png
nofollow1.png
Определение nofollow
В коде HTML nofollow является одним из множества значений, которые способен принимать атрибут rel. В исходном коде веб-страницы его можно найти после адреса ссылки, например <a href=»http://url.ru/" rel=»nofollow»>текст </a>. Если перевести значение атрибута на русский язык, то получим слово «не следовать». Вписывая атрибут rel со значением «не следовать», веб-мастер дает указание поисковому роботу не индексировать активную ссылку.
Для чего запрещать индексацию ссылок
Есть множество причин. Перечислим самые известные и важные из них.
nofollow2.jpg
nofollow2.jpg
- Ссылки на некачественные, нетематические сайты могут негативно повлиять на ранжирование продвигаемого ресурса.

- Большое количество ссылок, ведущих на сторонние сайты, может стать причиной блокировки ресурса или выпадения из индекса определенных страниц.
- Защита от ссылок, оставляемых пользователями в комментариях.
- Сохранение и перераспределение веса страниц или разделов.
- Желание исключить из индексации страницы или разделы, которые не предназначены для попадания в поисковую выдачу, например страницы с формой регистрации или страницы входа на сайт.
- Потребность в создании естественного ссылочного профиля.
Как проверить наличие закрытых от индексации ссылок
В поисках площадок, подходящих для наращивания ссылочной массы, необходимо быстро и точно определять способ их установки веб-мастером: с тегом rel=»nofollow» или без него. Сделать это можно при помощи разных инструментов.
nofollow3.png
nofollow3.png
Ищем при помощи браузера Google Chrome:
- Открываем страницу в браузере.

- Выделяем проверяемую ссылку.
- При помощи правой кнопки мыши открываем контекстное меню.
- Выбираем в меню строку «Посмотреть код элемента».
- Проверяем HTML-код на наличие тега rel с атрибутом nofollow.
При выборе площадки для размещения обратной ссылки важно уметь определять не только атрибут rel=»nofollow», но и другие теги с похожими функциями. Например, redirect, noindex, dofollow, nofollow noopener. Ссылки с атрибутами и тегами, имеющими перечисленные значения, пользы в плане наращивания ссылочной массы и продвижения сайта в поисковых системах не принесут.
Ищем при помощи дополнения к браузеру:
- Зайдите в магазин Google Chrome.
- Найдите дополнение RDS Bar или аналогичное.
- Установите расширение.
- В настройках дополнения включите подсветку ссылок, закрытых для индексации при помощи соответствующих тегов и атрибутов.
После этого на всех страницах, отрываемых в браузере, будут автоматически зачеркнуты все зарытые для индексации ссылки.
nofollow4.jpg
nofollow4.jpg
Обработка значения nofollow атрибута rel поисковой системой Google
Из официального справочного материала Google можно узнать, что поисковый робот по таким ссылкам не переходит. Если добавить к ссылке атрибут с указанным значением, то ссылка не попадает в сеть Google. Но закрытые таким образом от индексации страницы все равно появляются в индексе, если на них ведут открытые ссылки с других ресурсов или их адреса находятся в карте сайта. В тексте справки вы увидите словосочетание «как правило», которое использовали в предложении о переходе по закрытым от индексации ссылкам. Оно может означать, что поисковая система сама решает, переходить или не переходить, индексировать или не индексировать. Учитывая это и то, что другие поисковые системы не обращают внимания на nofollow, можно сказать, что закрытые таким образом ссылки способны приносить пользу наравне с открытыми.
Как используют ссылки в бизнесе
Прибыль напрямую зависит от посещаемости сетевого ресурса. Если по ссылкам переходят заинтересованные пользователи, то открыты они или закрыты от индексации – большого значения не имеет. Главную функцию они выполняют. Такие ссылки способны:
Если по ссылкам переходят заинтересованные пользователи, то открыты они или закрыты от индексации – большого значения не имеет. Главную функцию они выполняют. Такие ссылки способны:
- повысить узнаваемость бренда, популярность продукции, востребованность услуги. Если ссылка ведет на интересный, полезный контент и по ней переходят целевые посетители, то она рано или поздно окажет положительное влияние и на СЕО. Возрастающий целевой трафик будет по достоинству оценен поисковыми системами и учтен в ранжировании;
- увеличить объем продаж. Если продукт качественный, отвечает заявленным характеристикам, доступен по цене, то все заинтересованные посетители, перешедшие на сайт по закрытым ссылкам, оформят заказ;
- стать причиной появления новых ссылок. Всем известно, что социальные сети являются огромным источником потребителей и все ссылки в любых публикациях закрыты от индексации. То есть для повышения СЕО-показателей размещать их нет смысла.
 Зато они привлекут внимание пользователей, которые поделятся интересной информацией на других сетевых ресурсах.
Зато они привлекут внимание пользователей, которые поделятся интересной информацией на других сетевых ресурсах.
Какие площадки надо использовать для размещения ссылок
Размещать ссылки нужно на площадках, способных приводить на продвигаемый ресурс целевой трафик. Если установленная ссылка увеличивает число потенциальных потребителей, то она полезна, независимо от того, закрытая она или открытая для индексации. Полезные ресурсы:
- видеохостинговые сайты. Например, на Youtube ссылки, которые оставляют пользователи, не учитываются поисковой системой Google, но могут стать постоянным источником трафика с хорошими поведенческими факторами;
- социальные сети. Ссылки в социальных сетях не индексируются. Несмотря на это, их постоянно оставляют в заметках и комментариях. Если опубликованный материал привлекает внимание, трафик по закрытой ссылке обеспечен;
- форумы. Эти ресурсы обычно закрывают ссылки при помощи nofollow или noindex.
 Если поисковые системы эти ссылки не учитывают, то многомиллионная аудитория популярных форумов их видит, переходит по ним, создавая постоянный целевой трафик.
Если поисковые системы эти ссылки не учитывают, то многомиллионная аудитория популярных форумов их видит, переходит по ним, создавая постоянный целевой трафик.
Как повысить эффективность закрытых ссылок
Чтобы пользователи сетевых ресурсов интересовались вашим контентом и переходили по ссылкам на продвигаемые страницы, нужно перед публикацией материалов и установкой ссылок тщательно проверять и тестировать важные элементы статьи и околоссылочного текста. Заголовки, лиды должны мотивировать посетителя перейти на ваш сайт, контент должен быть интересным, полезным и релевантным теме. Чтобы получить максимальную отдачу от ссылки:
- подбирайте не только площадку, но и место установки;
- определите цель для каждой ссылки;
- проверяйте релевантность контента;
- оптимизируйте посадочные страницы.
Ссылки, закрытые от индексации, могут быть полезнее, чем индексируемые. Все зависит от того, где установлена ссылка и куда приводит пользователя. Если для индексируемых ссылок это практически не имеет значения, то для nofollow-ссылок является основным фактором, определяющим ее полезность, так как цели для них преследуются разные. Наращивание массы индексируемых ссылок происходит преимущественно для поднятия показателей сайта, а неиндексируемых – исключительно для привлечения целевой аудитории. То есть открытые ссылки влияют на посещаемость продвигаемого сетевого ресурса косвенно, а закрытые напрямую.
Все зависит от того, где установлена ссылка и куда приводит пользователя. Если для индексируемых ссылок это практически не имеет значения, то для nofollow-ссылок является основным фактором, определяющим ее полезность, так как цели для них преследуются разные. Наращивание массы индексируемых ссылок происходит преимущественно для поднятия показателей сайта, а неиндексируемых – исключительно для привлечения целевой аудитории. То есть открытые ссылки влияют на посещаемость продвигаемого сетевого ресурса косвенно, а закрытые напрямую.
В процессе ранжирования поисковые системы учитывают множество разнообразных факторов, причем делают это по-разному. «Яндекс», Google и другие поисковики принимают во внимание все ссылки, которые находят на страницах сетевых ресурсов, независимо от того, какие дополнительные атрибуты они имеют. Они лишь учитывают желание веб-мастера не допустить индексацию. Окончательное решение всегда остается за поисковой системой.
Что такое атрибут rel canonical? Проверка канонических страниц онлайн
Что такое атрибут rel=»canonical»
Атрибут rel="canonical" применяется для указания поисковым системам канонической страницы. Каноническая страница — это страница на сайте, которая является предпочтительной для индексации в поисковых системах. Поисковый робот, обнаружив атрибут
Каноническая страница — это страница на сайте, которая является предпочтительной для индексации в поисковых системах. Поисковый робот, обнаружив атрибут rel="canonical" на какой-либо странице, вместо нее проиндексирует ту страницу, адрес которой указан в данном атрибуте (каноническую ссылку). В отличие от редиректа, использование rel="canonical" переадресует на другую страницу не пользователей, а только поисковые системы.
Как прописать атрибут rel=»canonical» в коде страницы
Задается он с помощью тега LINK с атрибутом rel=”canonical” в блоке HEAD. Для этого необходимо поместить в HEAD следующую запись:
<link rel=”canonical” href=”канонический адрес URL” />
Где «канонический URL» – указывает страницу, которую вы считаете предпочтительной для появления в результатах поиска.
Пример употребления атрибута:
Обязательно использовать относительный (полный) путь на страницу!
Зачем указывать канонический url?
Этот атрибут применяется в тех случаях, когда на сайте имеются страницы с идентичным или очень похожим контентом. Так же используется для страниц пагинации в интернет-магазинах (первую страницу выбирают для сканирования, остальные — неканонические страницы — игнорируются). Чтобы поисковая система не расценивала такие адреса страниц как дубли, необходимо разместить на них ссылку на одну страницу предпочтительную для индексации каноничную страницу. Таким образом в выдаче появится только одна страница (каноническая версия). Это один из самых простых способов борьбы с дублированием контента. Более подробно изучить информацию про дубли страниц и способы борьбы с ними вы сможете в нашей статье Дубли страниц на сайте.
Так же используется для страниц пагинации в интернет-магазинах (первую страницу выбирают для сканирования, остальные — неканонические страницы — игнорируются). Чтобы поисковая система не расценивала такие адреса страниц как дубли, необходимо разместить на них ссылку на одну страницу предпочтительную для индексации каноничную страницу. Таким образом в выдаче появится только одна страница (каноническая версия). Это один из самых простых способов борьбы с дублированием контента. Более подробно изучить информацию про дубли страниц и способы борьбы с ними вы сможете в нашей статье Дубли страниц на сайте.
Почему это важно для поисковых систем?
Атрибут rel=canonical позволяет поисковым системам определить среди страниц с одинаковым содержанием основную, которую нужно проиндексировать и вывести в результаты поиска.
Информация от Яндекс о поддержке поисковыми роботами rel=canonical появилась в 2011 году. Кроме того, Вы можете ознакомиться с рекомендациями от Яндекс по употреблению rel=canonical в разделе Яндекс. Помощь.
Google также официально рекомендует использовать rel=canonicalдля борьбы с повторяющимися URL. Об этом можно прочитать в руководстве Консолидация повторяющихся URL.
Почему нужно знать, на каких страницах сайта есть rel=canonical?
Очень важно знать, на каких страницах вашего сайта употребляется этот атрибут, поскольку в некоторых случаях канонические страницы могут быть указаны неверно или ссылка может вести не ту страницу, на которую нужно. Это может обернуться для вас ошибками в индексации — одни страницы вашего сайта могут не проиндексироваться, а другие URL будут ошибочно указаны каноническими.
Например, известен кейс, когда на всех страницах сайта в качестве канонической прописали главную страницу, поэтому поисковые системы не могли проиндексировать все остальные страницы веб-ресурса.
Как обнаружить на сайте страницы с rel=canonical?
Это можно сделать с помощью сервиса Labrika. Отчет «Страницы с rel=»canonical» вы можете найти в разделе «Технический аудит» левого бокового меню..png) Страница с отчетом выглядит следующим образом:
Страница с отчетом выглядит следующим образом:
Отчет показывает:
- URL-адрес страницы, на которой найден атрибут
rel=canonical. - URL, указанный в ссылке с
rel=canonicalв качестве канонического. - Код ответа страницы, которая прописана как каноническая — код 200 говорит об успешной обработке запроса (страница доступна).
- Разрешен ли канонический URL для индексации.
Поставив галочки около нужных пунктов в верхней части отчета, можно отфильтровать его содержимое так, чтобы отображались данные только по rel=canonical с выбранными параметрами. Тогда вы сможете проверить наличие конкретных ошибок в указании канонической страницы.
Какие виды ошибок rel=canonical поможет определить Labrika?
Страницы с несколькими rel=canonical
На странице может быть указан только один канонический URL. В случае нескольких объявлений rel=canonical Google и Яндекс проигнорируют все указания канонических страниц.
Страницы с кросс-доменным rel=canonical
Чаще всего ссылка на другой домен при использовании атрибута rel=canonical происходит по ошибке. Если в качестве канонического адреса указан URL на другом домене или субдомене, Яндекс не учитывает канонический адрес. Google допускает выбор основного URL на стороннем домене, но рекомендует проверить правильность такого указания.
Ссылки с rel=canonical на несуществующие страницы
Страница, содержащая rel=canonical, ссылается на несуществующую страницу (ошибка 404). Пользователи не смогут попасть на такие страницы, а поисковые системы исключают их из индекса. Страница, прописанная в атрибуте rel=canonical, должна быть доступна и отдавать код ответа 200.
Указание главной страницы в качестве канонической на всех страницах сайта
Это считается грубой ошибкой, поскольку тогда все страницы веб-ресурса, кроме главной, не будут проиндексированы и не попадут в результаты поиска.
Канонический URL заблокирован для индексации
Не следует запрещать индексирование страниц, которые указаны как канонические. Это не позволит поисковым роботам их проиндексировать, и они не смогут участвовать в поиске. Если указанная в rel=canonicalстраница заблокирована от индексации, нужно снять блокировку или указать в качестве канонической другую страницу, которая доступна для индексирования.
В URL-адресе отсутствует префикс http или https
Абсолютные URL-адреса должны указывать полный путь к канонической странице, включая обозначение протокола (http:// или https://), например:
https:// mysite.ru/blog/page?id=2364, а не /blog/page?id=2364.
rel = canonical найден в <body>
Атрибут rel=canonical должен располагаться только между тегами <head> и </head>. Когда вы ставите rel=canonical в блок <body>, то он игнорируется.
Используйте данные отчета Labrika «Страницы с rel=canonical», чтобы найти и исправить ошибки в указании канонических страниц . Код ответа 200 говорит об успешной обработке запроса (страница доступна). При нажатии на эту кнопку вы скачаете отчет в формате Excel. Ссылка, с помощью которой можно скопировать отчет и отправить другому пользователю. Отчет будет доступен даже тем, кто не имеет аккаунта в Labrika. После получения данных о канонических страницах на сайте вы сможете увидеть ошибки, если они есть и исправить их и избежать проблем с индексацией.
При нажатии на эту кнопку вы скачаете отчет в формате Excel. Ссылка, с помощью которой можно скопировать отчет и отправить другому пользователю. Отчет будет доступен даже тем, кто не имеет аккаунта в Labrika. После получения данных о канонических страницах на сайте вы сможете увидеть ошибки, если они есть и исправить их и избежать проблем с индексацией.
Руководство по использованию атрибута rel=canonical вы найдете в отдельной статье нашего сайта.
Значение атрибута rel=canonical для SEO. Как указать каноническую ссылку?
Автор статьи: Полина Маенкова, главный технолог SEO-эксперт компании SEO.RU
- Что такое канонические страницы?
- Как указать канонический адрес?
- Использование готовых плагинов CMS
- Добавление элемента link в HTML-код
- HTTP-заголовок
- Файл Sitemap
- Для чего используются канонические ссылки?
- Откуда берутся дубли страниц в индексе ПС?
- Rel=canonical или 301 редирект?
- Частые ошибки
- Self-referential canonical
Что такое канонические страницы?
Начнем с определений.
Что такое каноническая страница? Это страница, которая для поисковых систем является главной среди всех остальных с похожим контентом.
Например, на сайте есть карточка товара — телевизора 66 с таким URL:
продавец-техники.ру/крупная-бытовая-техника/телевизоры/телевизор66
При определенных настройках настройках CMS открыть ее можно не только напрямую, но и, например, из раздела акций или Smart TV. Тогда у одного телевизора 66 будет несколько URL-адресов — и из них нужно выбрать оригинальную:
продавец-техники.ру/акции/телевизоры/телевизор66
продавец-техники.ру/smart-tv/телевизор66
продавец-техники.ру/доступно-в-рассрочку/телевизоры/телевизор66
Фильтры — не единственное, что генерирует такие клоны: мобильная версия, AMP и Турбо, пагинация и многое другое способно запускать технику клонирования.
Что такое каноническая ссылка? Это ссылка, содержащая атрибут link rel=»canonical» и указывающая путь к канонической странице.
Каноническая ссылка размещается на неканонических страницах. Если предельно упростить, неканоническая отказывается от статуса канонической с помощью ссылки. Как бы передает его посредством размещения URL страницы-преемницы с атрибутом rel=»canonical».
Если объяснения не помогли, а делать что-то нужно, закажите SEO-аудит у профессионалов: вы получите подробный перечень рекомендаций по улучшению всех сторон сайта.
Как указать канонический адрес?
Задать каноникал можно несколькими способами.
Использование готовых плагинов CMS
Некоторые CMS содержат внутренние решения для указания каноникал.
В WordPress можно использовать YoastSEO — это бесплатный плагин, который поможет решить и другие задачи поисковой оптимизации.
Для движка OpenCart разработано расширение SEO Canonical Links — правда, оно платное (20$):
Для X-Cart — модуль SEO Ultimate (тоже платный — $59.00):
А для системы PrestaShop есть модуль Canonical SEO URLs + Google Hreflang Pro (за 69,99€ в год):
Если сайт реализован на система Joomla!, указать атрибут можно с помощью расширения Custom Canonical:
В Битриксе настройку canonical можно провести без установки дополнительных модулей— достаточно отметить соответствующую опцию в компоненте:
Внутренние функции CMS для работы с канониклами — это простой метод: не нужно перебирать строки кода каждой из неканоничных страниц.
Однако это не самый надежный способ: после использования средств движка или плагинов, стоит проверить наличие canonical и корректность работы.
Добавление элемента link в HTML-код
Этот способ — самый популярный. В HTML-код документа, внутри тега <head> нужно добавить элемент link rel=»canonical».
В коде страницы это выглядит так:
Каноническую ссылку нужно разместить в коде каждой дублирующихся страниц.
HTTP-заголовок
Как использовать canonical для канонизации ссылок на электронные документы (docx, pdf, xlsx и др.)?
Для подобных документов проблема дублирования тоже актуальна: один файл может быть доступен с нескольких URL-адресов. Эти форматы не подразумевают раздела <head>, как HTML-документы, поэтому и способ нужен другой.
Чтобы избежать атаки клонов и вытекающих последствий, нужно указать главный адрес посредством HTTP-заголовка с применением .htaccess или PHP.
Когда запрашивается дублирующийся файл, сервер должен перенаправлять на основной. На примере нашего примера с телевизорами — добавим ссылку на инструкцию:
На примере нашего примера с телевизорами — добавим ссылку на инструкцию:
HTTP/1.1 200 OK Content-Type: manual/pdf Link: <http://продавец-техники.ру/телевизор66/canonical-tags/>; rel="canonical"
Файл Sitemap
Файл Sitemap содержит ссылки, которые подлежат индексации, поэтому все указанные в карте сайта адреса имеют статус канонических. Не нужно указывать атрибуты или прописывать специальные теги. Главное — отследить, чтобы в файле sitemap.xml не было ссылок на дублирующиеся страницы. Иначе краулеры не смогут сориентироваться и правильно проиндексировать сайт.
Для чего используются канонические ссылки?
Главная задача использования каноникал — устранить риск попадания дублей страниц в индекс поисковых систем, чтобы они не засоряли выдачу.
Читайте по теме: Как найти и удалить дубли страниц на сайте? Инструкция
По этой причине поисковые системы борются с дублями: схожесть контента дает краулерам основания считать сайт непригодным для топа. Сайт начинает терять места в выдаче, снижается уникальность всего контента, из-за расплодившихся URL появляются проблемы с индексацией, создается внутренняя конкуренция между документами. Страницам даже необязательно быть совсем одинаковыми: когда бот видит несколько похожих вариантов наполнения, он может интерпретировать это как сигнал некачественного сайта. Но он может выбрать и добавить в индекс совсем не тот URL, который нужен в выдаче. Тут, правда, стоит отметить, что canonical для Яндекс и Гугл — это не прямая директива, а лишь рекомендация, и боты все равно могут включить в поиск другую страницу.
Сайт начинает терять места в выдаче, снижается уникальность всего контента, из-за расплодившихся URL появляются проблемы с индексацией, создается внутренняя конкуренция между документами. Страницам даже необязательно быть совсем одинаковыми: когда бот видит несколько похожих вариантов наполнения, он может интерпретировать это как сигнал некачественного сайта. Но он может выбрать и добавить в индекс совсем не тот URL, который нужен в выдаче. Тут, правда, стоит отметить, что canonical для Яндекс и Гугл — это не прямая директива, а лишь рекомендация, и боты все равно могут включить в поиск другую страницу.
Однако указание canonical помогает избежать многих проблем при продвижении сайта.
Откуда берутся дубли страниц в индексе ПС?
Причин, по которым один и тот же контент доступен по разным URL-адресам, много. В некоторых случаях существование близнецов оправдано — то есть здесь нет никакой ошибки. В других же появление дублей сигнализирует о некорректной настройке сайта.
- Дубли по структуре.
В начале статьи мы приводили пример с URL карточки товара в магазине телевизоров и разными способами перейти к ней. Речь может идти не только о временных разделах типа акций, но и о постоянных разделах категорий.
- Страницы с GET-параметрами.
Источников появления параметрических страниц в индексе поисковых систем очень много (особенно это актуально для больших e-commerce сайтов):
- Страницы сортировки товаров (по убыванию/возрастанию цены, по популярности и т.д).
- Страницы результатов поиска по сайту (чаще всего содержит параметры s или q).
- Страницы фильтров по категориям.
- Ссылки с UTM-метками, которые используются для отслеживания переходов по рекламным источникам.
- Не настроен корректный ответ сервера для несуществующих URL.
Если на сайте не настроена страница 404, то любые вариации URL, которых нет в структуре сайта, будут отдавать ответ 200 ОК, т. е. будут доступны для поисковых роботов. Вероятнее всего, контент таких страниц будет дублировать содержимое каких-то существующих документов, например, страницу каталога.
е. будут доступны для поисковых роботов. Вероятнее всего, контент таких страниц будет дублировать содержимое каких-то существующих документов, например, страницу каталога.
Rel=canonical или 301 редирект?
Каноникал и 301 редирект передают поисковикам принципиально разные сигналы:
-
Rel canonical — это главная среди похожих: существует много URL с одинаковым или похожим контентом, но есть одна, которую нужно индексировать. Доступна и оригинальная страница, и ее сестры-близнецы.
Поэтому использование тега оправдано, когда все URL-адреса нужно сохранить доступными.
-
301 редирект — это новая взамен старой: существует одна страница, но не по старому, а по новому адресу, и именно новую версию нужно индексировать. Контент по оригинальному URL больше не доступен, его поисковая система исключает из индекса.
Настройка 301 редиректа нужна, когда старая страница окончательно удалена и взамен ее создана новая.
Сходства этих двух вариантов заключаются в том, что и 301 редирект, и каноникал передают сигналы ранжирования от одной страницы к другой. Под сигналами ранжирования здесь имеется в виду ссылочный вес страниц и поведенческие факторы (хотя последнее представители поисковых систем официально не подтверждают).
Частые ошибки
- Ошибка в написании канонического URL.
В HTML-коде важен каждый символ — из-за лишнего или недостающего заданный параметр не будет работать. Если canonical не работает, в первую очередь нужно проверить корректность его написания: все ли слеши указаны, корректный ли протокол (HTTP/HTTPS), полная ли ссылка.
- Два и более атрибута rel=canonical.
В этом случае поисковой бот может проигнорировать обе версии. Краулеры Google не смогут понять, какая из страниц является основной, и канонизируют URL по другим сигналам.
- Каноническая ссылка ведет на страницу с 301 или 404 ответом.

При таком сценарии канонической становится страница, которая уже должна быть удалена из индекса и с которой уже настроено перенаправление на новую. Из-за этого боты могут путаться и неверно истолковывать изначальный замысел. Лучше сразу канонизировать новую страницу.
Если каноническая ссылка ведет на URL с 404 ошибкой, сигнал канонизации просто никуда не передается и нигде не учитывается.
- Размещение rel=»canonical» в секции body.
Это ошибка по невнимательности, сродни первому пункту. Атрибут rel = «canonical» работает только в tag <head> или в HTTP-заголовке.
- Каноничная страница закрыта от индексирования.
Если каноничная страница закрыта от индексации в файле robots.txt или с помощью директивы noindex в теге , краулер не будет сканировать ее, и страница не попадет в поисковую выдачу. Зато в таком случае в поиск может попасть ее дубль.
- Каноничная страница не имеет входящих ссылок.
Каноническая страница без внутренних входящих ссылок недоступна для пользователя. Значит, он перейдет на неканонический вариант и атрибут канонизации не сработает.
Значит, он перейдет на неканонический вариант и атрибут канонизации не сработает.
- Неканонические страницы в файле sitemap.xml.
Как описано ранее, все ссылки в Sitemap по умолчанию считаются подлежащими индексации. Неканоническим URL там не место.
Self-referential canonical
Атрибут rel=»canonical» можно применять на самого себя: то есть канонизировать не какую-то другую страницу, а основную. Даже если на сайте нет ни дублированных, ни похожих страниц, данный URL-адрес будет индексироваться поисковыми ботами.
Кроме того, Джон Мюллер из Google рекомендует использовать самоссылающиеся каноникал из-за возможных разночтений версий в нижнем и верхнем регистре, а также при написании адресов с www и без них.
Что такое атрибут Rel? (с изображением)
`;
Атрибут rel — это атрибут HTML, используемый для описания связи целевой страницы со страницей, на которую она ссылается. Информация не отображается непосредственно в браузере, но поисковые системы и программы чтения с экрана могут как подобрать атрибут rel, так и собрать информацию о сети соединений на странице. Обратный — это атрибут rev, используемый для контекстуализации текущей страницы по отношению к тому, на что делается ссылка.
Информация не отображается непосредственно в браузере, но поисковые системы и программы чтения с экрана могут как подобрать атрибут rel, так и собрать информацию о сети соединений на странице. Обратный — это атрибут rev, используемый для контекстуализации текущей страницы по отношению к тому, на что делается ссылка.
Этот атрибут записывается как rel=»property» и будет отображаться в ссылке следующим образом: wiseGEEK. Атрибут rel отмечает, что ресурс, на который делается ссылка, является домашней страницей относительно документа, из которого исходит ссылка, например этой статьи wiseGEEK. Аналогичным образом сайт с партнерскими отношениями может использовать такой код: Дружественный партнер. Когда поисковые системы сканируют сайт, они могут понять отношения между страницами внутри сайта, а также внешние ссылки.
Аналогичным образом сайт с партнерскими отношениями может использовать такой код: Дружественный партнер. Когда поисковые системы сканируют сайт, они могут понять отношения между страницами внутри сайта, а также внешние ссылки.
Другим распространенным примером использования этого атрибута является навигация для предотвращения путаницы и разворотов. Дополнительные записи могут использоваться в блоге для предоставления ссылки на другую страницу записей. Люди также могут использовать такие дескрипторы, как «предыдущий», «таблица стилей» и «индекс», чтобы предоставить описательные теги для ресурсов. Атрибут rel также может быть связан с другим кодом; например, таблица стилей может быть закодирована для отображения маленькой стрелки рядом со ссылкой с rel=»previous» для облегчения навигации.
Атрибут rel также может быть связан с другим кодом; например, таблица стилей может быть закодирована для отображения маленькой стрелки рядом со ссылкой с rel=»previous» для облегчения навигации.
Как и многие атрибуты HTML, атрибут rel применяется непоследовательно. Некоторые сайты могут широко использовать его, и он может быть очень полезен для таких инструментов, как создание карт сайта. Другие сайты вообще не используют его, а иногда возникают странные варианты использования атрибута, которые могут запутать браузеры. По мере изменения стандартов HTML атрибуты то входят, то выходят из моды, и важно следить за тем, чтобы веб-сайты обновлялись соответствующим образом, чтобы избежать таких проблем, как ошибки отображения.
Люди, которым интересно узнать о поддержке браузерами различных атрибутов, могут найти техническую документацию на веб-сайтах для этих браузеров. Важно помнить, что даже если самая последняя версия браузера распознает и знает, как применить атрибут, более старые версии могут этого не делать, и люди, заинтересованные в охвате как можно большего количества браузеров, могут захотеть учитывать это при кодировании сайтов. Иногда необходимо внести коррективы в код сайта для людей, использующих старые браузеры, чтобы они отображались надлежащим образом.
Мэри МакМахон С тех пор как несколько лет назад Мэри начала работать над сайтом, она приняла
захватывающая задача быть исследователем и писателем. Мэри имеет степень по гуманитарным наукам в Годдард-колледже и
проводит свободное время за чтением, приготовлением пищи и прогулками на свежем воздухе.
Мэри имеет степень по гуманитарным наукам в Годдард-колледже и
проводит свободное время за чтением, приготовлением пищи и прогулками на свежем воздухе.
С тех пор как несколько лет назад Мэри начала работать над сайтом, она приняла захватывающая задача быть исследователем и писателем. Мэри имеет степень по гуманитарным наукам в Годдард-колледже и проводит свободное время за чтением, приготовлением пищи и прогулками на свежем воздухе.
Атрибут HTML Link Rel: что это такое и когда его использовать?
Contents
До сих пор вы давали ссылку на вашу SEO-работу или ссылку. Возможно, вы дали эту ссылку из сообщения или страницы на другой веб-сайт. Или, возможно, вы сделали это на своем собственном веб-сайте. Предоставляя эти ссылки, вы используете HTML-атрибут rel для SEO-исследований. Задумывались ли вы когда-нибудь, что такое атрибут HTML-ссылки rel? Если ваш ответ «да», мы проясним этот вопрос для вас в оставшейся части этой статьи. Самый ясный ответ, который мы можем дать на этот вопрос, заключается в следующем.
Предоставляя эти ссылки, вы используете HTML-атрибут rel для SEO-исследований. Задумывались ли вы когда-нибудь, что такое атрибут HTML-ссылки rel? Если ваш ответ «да», мы проясним этот вопрос для вас в оставшейся части этой статьи. Самый ясный ответ, который мы можем дать на этот вопрос, заключается в следующем.
Что такое ссылка Rel HTML?
Атрибут отношения ссылок указывается как link rel=value в технической части SEO. Эта функция используется для информирования поисковых систем о связи между страницами, которые ссылаются друг на друга. Эта функция используется очень часто.
Ссылки Rel являются микроформатами. Это параметры, которые показывают большинство областей использования HTML 4 и HTML 5. REL указывает, как ссылка относится к веб-сайту. Боты поисковых систем идентифицируют и читают ссылки. При этом большое внимание уделяется типу rel. Это потому, что они служат для передачи данных о ссылке роботам поисковых систем. По этим причинам вы должны использовать типы ссылок REL на своих веб-сайтах. Таким образом, вы можете внести значительный вклад в свои веб-сайты с точки зрения SEO. Итак, что такое типы ссылок REL?
Боты поисковых систем идентифицируют и читают ссылки. При этом большое внимание уделяется типу rel. Это потому, что они служат для передачи данных о ссылке роботам поисковых систем. По этим причинам вы должны использовать типы ссылок REL на своих веб-сайтах. Таким образом, вы можете внести значительный вклад в свои веб-сайты с точки зрения SEO. Итак, что такое типы ссылок REL?
Что такое теги HTML Rel Link?
- Альтернативный тип ссылки REL указывает, что ссылка является альтернативной версией текущей страницы. Он указывает разные версии страницы, такие как печатные и переведенные страницы.
- Тип приложения REL указывает, что ссылка является вложением на текущую страницу.
- Author REL указывает автора страницы.
- Закладка REL указывает, что ссылка является закладкой, относящейся к текущей странице.
- Тип главы указывает, что ссылка указывает на любой раздел в серии страниц.
- Contents REL указывает, что ссылка указывает на источник оглавления серии страниц.

- Тип Copyright REL указывает, что ссылка указывает на источник, содержащий информацию об авторских правах текущей страницы.
- Глоссарий REL указывает, что ссылка указывает на глоссарий терминов, описывающих термины, используемые на текущей странице.
- Help REL указывает, что ссылка указывает на страницу справки для текущей страницы. Другими словами, он определяет справочный документ.
Другие теги Rel
- Icon REL определяет значок, представляющий документ.
- Индекс REL указывает, что ссылка указывает на индекс/каталог массива страниц.
- License REL указывает информацию об авторских правах документа.
- Следующий тип REL указывает, что ссылка является страницей после текущей страницы.
- Prefetch REL указывает целевую страницу для кэширования.
- Тип Prev REL указывает, что ссылка является страницей, предшествующей текущей странице.
- Поиск REL указывает, что документ является средством поиска.

- Раздел REL указывает, что ссылка ведет на основную часть текущей страницы.
- Start REL указывает, что ссылка указывает на первую страницу в серии страниц.
- Ссылка REL Таблица стилей указывает, что ссылка содержит шаблоны стилей для текущей страницы.
- Подраздел REL указывает, что ссылка указывает на нижнюю часть текущей страницы.
- Значок быстрого доступа REL указывает на две вещи. Указывает, что ссылка имеет значок для текущей страницы, которая будет отображаться в окне браузера и в списке избранного.
- Тип REL ссылки Nofollow указывает, что ссылка не имеет ничего общего с текущей страницей. Или указывает, что это ссылка, по которой не следует переходить.
Когда использовать теги HTML Rel Link
Вам не нужно определять каждую ссылку на вашем веб-сайте. Таким образом, вам не всегда нужно использовать теги ссылок Rel. Например, давайте посмотрим, когда вам следует использовать теги спонсируемых ссылок Rel. Вы должны всегда использовать этот тег ссылки для платных гиперссылок или ссылок на платную рекламу. Если вы не используете этот тег там, где это необходимо, оценщики качества поиска Google могут пометить ваши веб-страницы. В основе всех SEO-исследований лежит важный вопрос. Это поможет всем поисковым системам понять ваш сайт и его содержание.
Если вы не используете этот тег там, где это необходимо, оценщики качества поиска Google могут пометить ваши веб-страницы. В основе всех SEO-исследований лежит важный вопрос. Это поможет всем поисковым системам понять ваш сайт и его содержание.
Атрибут HTML Link Rel, кратко
Функция HTML Link Rel обеспечивает преимущества SEO для ваших веб-страниц. Эта функция входит в технический объем SEO-исследований. Каждая веб-страница содержит большое количество ссылок, связанных с ее содержанием. Атрибут HTML link rel определяет взаимосвязь между этими ссылками. Чтобы использовать эту функцию более эффективно, вы должны сначала понять, что она делает. Итак, в этой статье мы попытались объяснить, что такое HTML-атрибут ссылки rel. Кроме того, есть пара десятков тегов ссылок HTML Rel. В этой статье мы также рассказали о том, что это за теги.
ПОСЛЕДНИЕ ПОСТЫ
Ошибка 502 Bad Gateway — довольно распространенная, но раздражающая проблема для большинства веб-пользователей. Это один из кодов состояния HTTP, указывающих на наличие …
В документах Word вы можете вводить различные термины, мысли или данные. Не всегда можно выразить необходимую информацию словами и…
Если вам понравилась эта статья и вы хотите узнать больше об HTML, вы можете прочитать наши статьи об этом, например: Что такое HTML?
Часто задаваемые вопросы
Что такое ссылка CSS?
CSS означает каскадные таблицы стилей. CSS Rel определяет, как пользователи просматривают HTML-элементы. Он указывает это для всех носителей.
Что делает внешний CSS?
Используя это, вы можете изменить внешний вид всего вашего веб-сайта, внеся изменения в один файл. Вы можете написать внешний CSS в любом текстовом редакторе. Однако не следует включать тег ссылки HTML во внешний файл CSS.
Вы можете написать внешний CSS в любом текстовом редакторе. Однако не следует включать тег ссылки HTML во внешний файл CSS.
Как связать CSS с HTML?
Существует три способа добавления ссылки CSS HTML. К ним относятся:
Внешний CSS
Внутренний CSS
Встроенный CSS
Каково определение тегов ссылок HTML?
Определение тега ссылки следующее. Он описывает связь между текущим документом и внешним источником.
Что означает атрибут HTML Link Rel для SEO?
Теги атрибутов Rel помогают поисковым роботам Google понять ценность всех ссылок на вашей веб-странице. Если вы правильно используете эти теги ссылок, это означает, что вы правильно классифицируете ссылки на своем веб-сайте. Таким образом, Google легче понимает ваш сайт, что является ключевым принципом SEO.
Как использовать атрибуты Rel для улучшения SEO
Изменено: 08 февраля 2021 г.
Как внутренние, так и внешние ссылки влияют на то, как алгоритм Google и группа обеспечения качества оценивают вашу страницу. Теги HTML помогают веб-браузерам понять, как читать, форматировать и отображать содержимое вашей страницы. С другой стороны, теги атрибута Rel помогают поисковым роботам понять значение каждой ссылки на этой странице.
Теги HTML помогают веб-браузерам понять, как читать, форматировать и отображать содержимое вашей страницы. С другой стороны, теги атрибута Rel помогают поисковым роботам понять значение каждой ссылки на этой странице.
Правильное использование атрибутов rel, таких как теги nofollow, спонсируемый контент и атрибуты пользовательского контента, означает, что ваши ссылки правильно классифицируются, что может помочь Google легче понять ваш сайт — ключевой принцип SEO. Чтобы понять, как их использовать, сначала вам нужно узнать, что такое атрибуты rel.
Что такое атрибут rel?
Атрибуты Rel — это небольшие фрагменты html-текста, в которых подробно описывается взаимосвязь между страницей, на которую указывает ссылка, и страницей или документом, на который она указывает. Атрибуты Rel можно использовать для ссылок, а также других элементов html, таких как навигация по сайту или формы. Во всех случаях их цель — помочь поисковым роботам, поисковым роботам и поисковым роботам Google понять, что происходит на вашем веб-сайте и как различные элементы работают вместе.
Атрибут rel для формы, скорее всего, будет использовать атрибут «таблица стилей», который позволяет поисковым роботам понять причину, по которой часть вашего веб-сайта отформатирована по-другому. HTML-атрибут rel noopener указывает веб-браузерам открывать ссылки в новой вкладке, тогда как атрибут rel в тегах ссылок информирует поисковых роботов о месте назначения ссылки.
Когда дело доходит до атрибутов nofollow, Sponsored и UGC rel, они помогают поисковым системам определять ценность гиперссылок на веб-странице.
Атрибуты Nofollow rel сообщают поисковым роботам, что владелец веб-сайта не предлагает никаких рекомендаций для сайта или страницы, на которую указывает ссылка. Это указывает на то, что кредит рейтинга не должен передаваться на целевую страницу. Вопрос о том, присваивается ли рейтинг, остается на усмотрение Google. Раньше это была инструкция, которой следовали, в наши дни это просто указание, которое отмечает Google.
Rel=»ugc» — это атрибут пользовательского контента rel. Как и следовало ожидать, это идентификация контента, созданного пользователями веб-сайта; комментарии в блогах и форумы являются хорошим примером этого. Это важно, поскольку позволяет Google понять, что владелец веб-сайта не имеет полного контроля над идентифицированным контентом. В некоторых случаях это может помочь владельцам веб-сайтов избежать штрафа Google, поскольку он был создан пользователями, а не владельцем веб-сайта.
Как и следовало ожидать, это идентификация контента, созданного пользователями веб-сайта; комментарии в блогах и форумы являются хорошим примером этого. Это важно, поскольку позволяет Google понять, что владелец веб-сайта не имеет полного контроля над идентифицированным контентом. В некоторых случаях это может помочь владельцам веб-сайтов избежать штрафа Google, поскольку он был создан пользователями, а не владельцем веб-сайта.
Есть также атрибуты рекламной ссылки , которые полезны для гиперссылок, включенных в платную рекламу или партнеров, которые каким-либо образом компенсируют вам размещение гиперссылки на их веб-сайт, продукт или страницу. Это показывает Google, что ссылка является не одобрением редакции, а деловым соглашением. Важно четко указывать эти типы ссылок, чтобы они не воспринимались как черная тактика SEO.
Когда использовать rel nofollow и другие теги атрибутов rel.
Не каждую ссылку нужно определять, и не всегда используются атрибуты rel. В некоторых случаях они совершенно не нужны. Однако в других случаях важно использовать атрибуты rel, чтобы обеспечить максимальную ценность ссылок на вашем веб-сайте и/или избежать необоснованного наказания со стороны алгоритма Google.
В некоторых случаях они совершенно не нужны. Однако в других случаях важно использовать атрибуты rel, чтобы обеспечить максимальную ценность ссылок на вашем веб-сайте и/или избежать необоснованного наказания со стороны алгоритма Google.
Атрибуты Nofollow важны, так как они предотвращают передачу некоторых из ваших кредитов рейтинга сайту или странице, на которую вы ссылаетесь только для справки или дополнительной информации для пользователя веб-сайта. Забыв атрибут «nofollow» rel или другой атрибут rel, вы, по сути, включаете «атрибут rel follow». Поэтому никакие атрибуты подписки не должны быть включены в любые гиперссылки, которые явно не одобрены вами.
Атрибуция пользовательского контента или атрибут rel = «ugc» должен быть включен в все гиперссылок на контент, созданный пользователями веб-сайта, а не одобренным автором. Сюда входят ссылки на разделы комментариев блогов, форумы сообщества, каталоги, сообщения, созданные пользователями, и любой другой контент веб-сайта, созданный пользователями. Правильное определение этих ссылок может привести к большей терпимости сканеров и поисковых роботов к спаму или другому тексту, который может противоречить правилам Google.
Правильное определение этих ссылок может привести к большей терпимости сканеров и поисковых роботов к спаму или другому тексту, который может противоречить правилам Google.
Теги атрибутов Rel=”sponsored” всегда должны использоваться для ваших платных гиперссылок или ссылок на платную рекламу. Пренебрежение этим может привести к тому, что поисковые системы решат, что вы занимаетесь тайными методами SEO, такими как продажа ссылок. Это может привести к тому, что ваш веб-сайт будет помечен Google 9.0142 Search Quality Raters или Bings Search Quality Insight команды.
Помощь поисковым системам в понимании вашего веб-сайта и его содержания лежит в основе эффективного SEO. Атрибуты Rel и теги HTML — это лишь часть процесса. Правильное использование каждого элемента поможет вам улучшить SEO вашего сайта в целом.
Изменено: 08.02.2021
Ссылки в HTML документах
Ссылки в HTML документахпредыдущий следующий содержимое элементы атрибуты индекс
Содержание
- Введение в ссылки и якоря
- Посещение связанного ресурса
- Другие отношения связи
- Указание якорей и ссылок
- Заголовки ссылок
- Интернационализация и ссылки
- А элемент
- Синтаксис имен якорей
- Вложенные ссылки незаконны
- Якоря с id атрибут
- Недоступен и неидентифицируем ресурсы
- Отношения документов: элемент LINK
- Прямые и обратные связи
- Ссылки и внешний стиль листы
- Ссылки и поисковые системы
- Информация о пути: элемент BASE
- Разрешающий родственник URI
HTML предлагает множество традиционных идиом для публикации форматированного текста и
структурированные документы, но что отличает его от большинства других языков разметки, так это
его функции для гипертекстовых и интерактивных документов. В этом разделе представлены ссылка (или гиперссылка, или веб-ссылка), основная гипертекстовая конструкция. А
ссылка — это соединение с одного веб-ресурса на другой. Хотя простой
концепции, ссылка была одной из основных сил, определяющих успех
Веб.
В этом разделе представлены ссылка (или гиперссылка, или веб-ссылка), основная гипертекстовая конструкция. А
ссылка — это соединение с одного веб-ресурса на другой. Хотя простой
концепции, ссылка была одной из основных сил, определяющих успех
Веб.
А звено имеет два конца, называемых якорями , и направление. Ссылка начинается с якоря «источник» и указывает на якорь «назначения», который может быть любым веб-ресурсом (например, изображением, видео клип, звуковой фрагмент, программа, документ HTML, элемент внутри HTML документ и др.).
12.1.1 Посещение связанного ресурса
Поведение по умолчанию, связанное со ссылкой, — получение другой веб-ресурс. Такое поведение обычно и неявно полученный путем выбора ссылки (например, путем нажатия, ввода с клавиатуры, так далее.).
Следующий фрагмент HTML содержит две ссылки, одна
целевой якорь которого является документом HTML с именем «chapter2.html», а
другой, якорем назначения которого является изображение GIF в файле «forest. gif»:
gif»:
<ТЕЛО> ...какой-то текст...Вы найдете гораздо больше в второй главе. См. также эту карту зачарованного леса.
{kind=link}
При активации этих ссылок (щелчком мыши, через клавиатуру ввод, голосовые команды и т. д.), пользователи могут посещать эти ресурсы. Обратите внимание, что href атрибут в каждом исходном якоре указывает адрес целевого якоря с URI.
Якорь назначения ссылки может быть элементом HTML-документа. Якорю назначения должно быть присвоено имя якоря и любой URI, относящийся к нему. якорь должен включать имя в качестве идентификатора фрагмента.
Якоря назначения в документах HTML могут быть указаны либо с помощью A элемент (называя его с помощью имя атрибут) или любым другим элементом (название с атрибутом id ).
Таким образом, например, автор может создать оглавление, записи которого
ссылка на элементы заголовка h3 , h4 и т. д. в том же документе. Использование элемента A для
создать якоря назначения, мы бы написали:
д. в том же документе. Использование элемента A для
создать якоря назначения, мы бы написали:
Содержание
Введение
Введение ...раздел 1... Небольшая предыстория ...секция 2... Личное примечание ...раздел 2.1...
Небольшая предыстория
Личное примечание
...остальное содержание... ...тело документа...
Мы можем добиться того же эффекта, сделав сами элементы заголовка анкеры:
Содержание
Введение
Небольшая предыстория
Личное примечание
...остальное содержание... ...тело документа...Введение
...раздел 1...Небольшая предыстория
...секция 2...
Личное примечание
...раздел 2.1...
12.1.2 Другая ссылка отношения
Безусловно, наиболее распространенное использование ссылки — получение другого веб-сайта. ресурса, как показано в предыдущих примерах. Однако авторы могут вставлять ссылки в своих документах, которые выражают другие отношения между ресурсами чем просто «активировать эту ссылку, чтобы посетить соответствующий ресурс». Ссылки, которые выражать другие типы отношений имеют один или несколько типов ссылок, указанных в их привязке к источнику.
ролей ссылки, определенной A или LINK , указаны через rel и атрибуты версии .
Например, ссылки, определяемые элементом LINK , могут описывать положение документа в серии документов. В следующем отрывке ссылки в документе под названием «Глава 5» указывают на предыдущую и следующую главы:
<ГОЛОВА> ...другая информация о головке...
Глава 5 <ССЫЛКА rel="prev" href="chapter4.html"> <ССЫЛКА rel="следующая" href="chapter6.html">
Тип первой ссылки — «предыдущая», а второй — «следующая». (два из нескольких распознаваемых типов ссылок). Ссылки, указанные ССЫЛКА , , а не отображаются вместе с документом. содержимое, хотя пользовательские агенты могут отображать его другими способами (например, как средства навигации).
Даже если они не используются для навигации, эти ссылки могут интерпретироваться в интересные способы. Например, пользовательский агент, который печатает серию HTML документы как единый документ могут использовать эту информацию о ссылках в качестве основы для формирование связного линейного документа. Ниже приведена дополнительная информация об использовании ссылки в интересах поисковых систем.
12.1.3 Указание якорей и ссылок
Хотя некоторые элементы и атрибуты HTML создают ссылки на другие
ресурсов (например, элемент IMG , элемент элемент ФОРМА и т. д.), в этой главе обсуждаются ссылки и якоря.
создается элементами LINK и A . Элемент LINK может появляться только в
глава документа. Элемент A может появляться только в теле.
д.), в этой главе обсуждаются ссылки и якоря.
создается элементами LINK и A . Элемент LINK может появляться только в
глава документа. Элемент A может появляться только в теле.
Когда Элемент атрибут href установлен, элемент определяет источник привязка для ссылки, которая может быть активирована пользователем для получения веб-ресурса. Исходная привязка — это расположение экземпляра A и целевой привязки. является веб-ресурсом.
Пользовательский агент может обрабатывать полученный ресурс несколькими способами:
открытие нового HTML-документа в том же окне пользовательского агента, открытие нового HTML-документа
документ в другом окне, запуская новую программу для обработки ресурса,
и т.д. С Элемент имеет содержимое (текст, изображения и т. д.), пользовательские агенты могут отображать
этот контент таким образом, чтобы указать на наличие ссылки (например, путем
подчеркивание содержания).
Когда установлены атрибуты name или id элемента A , элемент определяет привязку, которая может быть местом назначения других ссылок.
Авторы могут установить атрибуты name и href одновременно в тот же Экземпляр .
Элемент LINK определяет связь между текущим документом и другой ресурс. Хотя LINK не имеет содержимого, определяемые им отношения могут быть обработаны некоторыми пользовательскими агентами.
12.1.4 Заголовки ссылок
Атрибут title может быть установлен как для A , так и для LINK на добавить информацию о характере ссылки. Эта информация может быть произнесена пользовательский агент, отображаемый в виде всплывающей подсказки, вызывает изменение изображения курсора и т. д.
Таким образом, мы можем дополнить предыдущий пример предоставление заголовка для каждой ссылки:
<ТЕЛО> ...какой-то текст...
Вы найдете гораздо больше в вторая глава. вторая глава. См. также этот карта заколдованный лес.
12.1.5 Интернационализация и ссылки
Поскольку ссылки могут указывать на документы, закодированные с использованием разных кодировок символов, A и LINK элементы поддерживают атрибут charset . Этот атрибут позволяет авторам информировать пользовательские агенты о кодировании данных на другом конце ссылки.
Атрибут hreflang предоставляет агентам пользователя информация о языке ресурса в конце ссылки, как и Атрибут lang предоставляет информацию о языке содержимое элемента или значения атрибутов.
Вооружившись этими дополнительными знаниями, пользовательские агенты должны иметь возможность избегать
предоставление «мусора» пользователю. Вместо этого они могут либо найти ресурсы
необходимые для правильного оформления документа или, если они не могут
найти ресурсы, они должны как минимум предупредить пользователя о том, что документ будет
быть нечитаемым и объяснить причину.
Вместо этого они могут либо найти ресурсы
необходимые для правильного оформления документа или, если они не могут
найти ресурсы, они должны как минимум предупредить пользователя о том, что документ будет
быть нечитаемым и объяснить причину.
12.2
А элемент
A - - (%inline;)* -(A) -- привязка -->
кодировка %кодировка; #ПРЕДПОЛАГАЕТСЯ -- символьная кодировка связанного ресурса --
тип %ContentType; #ПРЕДПОЛАГАЕТСЯ -- рекомендательный тип контента --
имя CDATA #ПРЕДПОЛАГАЕТСЯ -- именованный конец ссылки --
href %URI; #ПРЕДПОЛАГАЕТСЯ -- URI связанного ресурса --
hreflang %LanguageCode; #ПРЕДПОЛАГАЕТСЯ -- код языка --
отн. %LinkTypes; #ПРЕДПОЛАГАЕТСЯ -- типы ссылок вперед --
ред. %LinkTypes; #ПРЕДПОЛАГАЕТСЯ -- типы обратной ссылки --
ключ доступа %Символ; #ПРЕДПОЛАГАЕТСЯ -- ключевой символ специальных возможностей --
форма %форма; rect -- для использования с клиентскими картами изображений --
координат %Координаты; #ПРЕДПОЛАГАЕТСЯ -- для использования с клиентскими картами изображений --
tabindex НОМЕР #ПРЕДПОЛАГАЕТСЯ -- позиция в порядке табуляции --
onfocus %Script; #ПРЕДПОЛАГАЕТСЯ -- элемент получил фокус --
onblur %Script; #ПРЕДПОЛАГАЕТСЯ -- элемент потерял фокус --
>
Начальный тег: требуется , Конечный тег: требуется
Определения атрибутов
- имя = cdata [CS]
- Этот атрибут называет текущую привязку так, чтобы она могла быть местом назначения
другой ссылки.
 Значение этого атрибута должно быть уникальным именем привязки.
областью действия этого имени является текущий документ. Обратите внимание, что этот атрибут разделяет
то же пространство имен, что и id атрибут.
Значение этого атрибута должно быть уникальным именем привязки.
областью действия этого имени является текущий документ. Обратите внимание, что этот атрибут разделяет
то же пространство имен, что и id атрибут. - href = uri [CT]
- Этот атрибут указывает расположение веб-ресурса, тем самым определяя связь между текущим элементом (исходным якорем) и целевым якорем определяется этим атрибутом.
- hreflang = код языка [CI]
- Этот атрибут указывает базовый язык ресурса, обозначенного href и может использоваться только при указании href .
- тип = тип контента [CI]
- Этот атрибут дает рекомендательную подсказку относительно типа содержимого.
доступны по целевому адресу ссылки. Это позволяет пользовательским агентам выбрать использование
резервный механизм, а не извлекать содержимое, если им сообщают, что они
получат контент в типе контента, который они не поддерживают.

- Авторы, использующие этот атрибут, берут на себя ответственность за управление рисками, это может стать несовместимым с контентом, доступным в целевой ссылке адрес.
- Актуальный список зарегистрированных типов контента см. [МИМЕТИПЫ].
- отн. = типов ссылок [CI]
- Этот атрибут описывает связь между текущим документом и привязка, указанная атрибутом href . Значение этого атрибута равно разделенный пробелами список типов ссылок.
- rev = типов ссылок [CI]
- Этот атрибут используется для описания обратной ссылки от якоря, указанного href атрибут к текущему документу. значением этого атрибута является список типов ссылок, разделенных пробелами.
- кодировка = кодировка [CI]
- Этот атрибут указывает кодировку символов назначенного ресурса
по ссылке. Пожалуйста, обратитесь к разделу о характере
кодировки для более подробной информации.
Атрибуты, определенные в другом месте
- id , class (идентификаторы всего документа)
- язык (язык информация), дир (текст направление)
- title (заголовок элемента)
- стиль (встроенный информация о стиле)
- формы и координаты (изображение карты)
- onfocus , onblur , onclick , ondblclick , onmousedown , onmouseup , onmouseover , onmousemove , , нажатие клавиши , onkeydown , onkeyup (внутренние события)
- цель (цель информация о кадре)
- tabindex (навигация с помощью вкладок)
- ключ доступа (ключи доступа)
Каждый Элемент определяет якорь
- Содержимое элемента определяет позицию привязки.
- Атрибут name называет якорь так, чтобы он мог быть местом назначения ноль или более ссылок (см. также анкоры с идентификатор ).
- Атрибут href делает этот якорь исходным якорем ровно для одного ссылка на сайт.
Авторы также могут создать элемент A , не определяющий якорей, т. е. не указывает href , имя или идентификатор . Значения этих атрибутов могут быть установить позже через скрипты.
В следующем примере Элемент определяет ссылку. Исходный якорь текст «Веб-сайт W3C» и якорь назначения — «http://www.w3.org/»:
Для получения дополнительной информации о W3C обратитесь к веб-сайт W3C.
Эта ссылка указывает на домашнюю страницу консорциума World Wide Web. Когда
пользователь активирует эту ссылку в пользовательском агенте, пользовательский агент получит
ресурс, в данном случае HTML-документ.
Пользовательские агенты обычно отображают ссылки таким образом, чтобы сделать их очевидной для пользователей (подчеркивание, перевернутое видео и т. д.). Точный рендеринг зависит от пользовательского агента. Рендеринг может варьироваться в зависимости от того, есть ли у пользователя уже побывали по ссылке или нет. Возможный визуальный рендеринг предыдущего ссылка может быть:
Дополнительные сведения о W3C см. на веб-сайте W3C.
~~~~~~~~~~~~~
Чтобы явно указать агентам пользователя, какая кодировка символов целевая страница, установите кодировка атрибут:
Для получения дополнительной информации о W3C обратитесь к Веб-сайт W3C
Предположим, мы определили привязку с именем «anchor-one» в файле «one.html».
...текст перед якорем... Это расположение первой привязки. ...текст после якоря...
Это создает привязку вокруг текста «Это расположение привязки один.». Обычно содержимое A не отображаются особым образом, когда A определяет только якорь.
Определив якорь, мы можем ссылаться на него с того же или другого документ. URI, обозначающие якоря, содержат символ «#», за которым следует имя якоря (фрагмент идентификатор). Вот несколько примеров таких URI:
- Абсолютный URI: http://www.mycompany.com/one.html#anchor-one
- Относительный URI: ./one.html#anchor-one или one.html#anchor-один
- Когда ссылка определена в том же документе: #anchor-one
Таким образом, ссылка, определенная в файле «two.html» в том же каталоге, что и «one.html» будет ссылаться на якорь следующим образом:
. ...текст перед ссылкой... Для получения дополнительной информации см. якорь один. ...текст после ссылки...
Элемент в следующем примере указывает ссылку (с href ) и одновременно создает именованный якорь (с именем ):
Я только что вернулся из отпуска! Вотsomecompany.com/People/Ian/vacation/family.png"> фото моей семьи на озере..
Этот пример содержит ссылку на веб-ресурс другого типа (файл PNG изображение). Активация ссылки должна привести к извлечению ресурса изображения. из Интернета (и, возможно, отображается, если система настроена на выполнение так).
Примечание. Пользовательские агенты должны уметь находить якоря создан пустыми элементами A , но некоторые этого не делают. Например, какой-то пользователь агенты могут не найти «пустой якорь» в следующем фрагменте HTML:
...немного HTML... Ссылка на пустой якорь
12.2.1 Синтаксис привязки имена
Имя привязки представляет собой значение либо имя или идентификатор атрибут при использовании в контексте якорей. Имена якорей должны соответствовать следующие правила:
- Уникальность: Имена якорей должны быть
уникальный в пределах документа.
 Имена якорей, отличающиеся только регистром, могут не отображаться
в том же документе.
Имена якорей, отличающиеся только регистром, могут не отображаться
в том же документе. - Соответствие строк: сравнения между идентификаторами фрагментов и имена якорей должны быть выполнены путем точного (с учетом регистра) совпадения.
Таким образом, следующий пример корректен в отношении сопоставления строк и должны рассматриваться агентами пользователя как совпадения:
... ...дополнительный документ...
НЕЗАКОННЫЙ ПРИМЕР:
Следующий пример недопустим с точки зрения уникальности, так как два имени
те же, за исключением случая:
Хотя следующий отрывок является допустимым HTML, поведение пользовательского агента не определено; некоторые пользовательские агенты могут (ошибочно) считать это совпадением и другие не могут.
... ...дополнительный документ.
..
Имена якорей должны быть ограничены ASCII персонажи. Пожалуйста, обратитесь к приложению для получения дополнительной информации о не-ASCII-символы в URI значения атрибутов.
12.2.2 Вложенные ссылки недопустимы
Ссылки и привязки, определенные Элемент не должен быть вложенным; элемент A не должен содержать никаких других A элементов.
Поскольку DTD определяет LINK элемент должен быть пустым, LINK элементы также не могут быть вложенными.
12.2.3 Анкеры с
идентификатор атрибутАтрибут id может использоваться для создания якоря в начальном теге любого элемент (включая элемент A ).
В этом примере показано использование атрибута id для позиционирования привязки в элемент h3 . Якорь связан с через А элемент.
Подробнее об этом можно прочитать в разделе втором.... далее в документе
Раздел второй
... далее в документеСм. раздел второй выше. Больше подробностей.
В следующем примере якорь назначения именуется с идентификатором . атрибут:
Я только что вернулся из отпуска! Вот фото моей семьи на озере..
Атрибуты id и name имеют одно и то же пространство имен. Это означает, что они не могут оба определить якорь с тем же именем в том же документе. Это допустимо используйте оба атрибута, чтобы указать уникальный идентификатор элемента для следующих элементы: А , ПРИЛОЖЕНИЕ , ФОРМА , РАМА , IFRAME , IMG и MAP . Когда оба атрибута используются в одном элементе, их значения должны быть идентичный.
НЕЗАКОННЫЙ ПРИМЕР:
Следующий отрывок является недопустимым HTML, так как эти атрибуты объявляют одно и то же
имя дважды в одном и том же документе.
... ......страниц и страниц... <А имя="a1">
В следующем примере показано, что id и имя должны быть одинаковыми, когда оба появляются в начальном теге элемента:
Из-за спецификации в HTML DTD имя атрибут может содержать ссылки на символы. Таким образом, значение Dürst является действительный name значение атрибута, как Dürst . идентификатор Атрибут, с другой стороны, не может содержать ссылки на символы.
Использовать id или имя ? Авторы должны учитывать следующее проблемы при принятии решения об использовании id или имя для имени якоря:
- Атрибут id может действовать не только как имя привязки (например, стиль
селектор листов, идентификатор обработки и т.
 д.).
д.). - Некоторые старые пользовательские агенты не поддерживают привязки, созданные с идентификатором атрибут.
- Атрибут name позволяет использовать более богатые имена привязок (с сущностями).
12.2.4 Недоступно и неопознанные ресурсы
Ссылка на недоступный или неидентифицируемый ресурс является ошибкой. Хотя пользовательские агенты могут по-разному обрабатывать такую ошибку, мы рекомендуем следующее поведение:
- Если пользовательский агент не может найти связанный ресурс, он должен предупредить пользователь.
- Если пользовательский агент не может определить тип связанного ресурса, он должен еще попробуй обработать. Это должно предупредить пользователя и может позволить пользователю вмешаться и определить тип документа.
12.3 Отношения документов:
ССЫЛКА элемент
LINK - O EMPTY -- независимая от носителя ссылка -->
кодировка %кодировка; #ПРЕДПОЛАГАЕТСЯ -- символьная кодировка связанного ресурса --
href %URI; #ПРЕДПОЛАГАЕТСЯ -- URI связанного ресурса --
hreflang %LanguageCode; #ПРЕДПОЛАГАЕТСЯ -- код языка --
тип %ContentType; #ПРЕДПОЛАГАЕТСЯ -- рекомендательный тип контента --
отн. %LinkTypes; #ПРЕДПОЛАГАЕТСЯ -- типы ссылок вперед --
ред. %LinkTypes; #ПРЕДПОЛАГАЕТСЯ -- типы обратной ссылки --
медиа %MediaDesc; #ПРЕДПОЛАГАЕТСЯ -- для рендеринга на этих носителях --
>
%LinkTypes; #ПРЕДПОЛАГАЕТСЯ -- типы ссылок вперед --
ред. %LinkTypes; #ПРЕДПОЛАГАЕТСЯ -- типы обратной ссылки --
медиа %MediaDesc; #ПРЕДПОЛАГАЕТСЯ -- для рендеринга на этих носителях --
>
Начальный тег: требуется , Конечный тег: запрещено
Атрибуты, определенные в другом месте
- id , class (идентификаторы всего документа)
- язык (язык информация), дир (текст направление)
- title (заголовок элемента)
- стиль (встроенный информация о стиле)
- onclick , ondblclick , onmousedown , onmouseup , onmouseover , onmousemove , onmouseout , onkeypress , onkeydown , onkeyup (внутренние события)
- href , hreflang , тип , rel , rev (ссылки и анкеры)
- цель (цель информация о кадре)
- носитель (заголовок информация о стиле)
- кодировка (символ кодировки)
Этот элемент определяет ссылку. В отличие от A , он может появиться только в HEAD .
раздел документа, хотя он может появляться любое количество раз. Хотя ССЫЛКА не имеет содержания, он передает информацию об отношениях, которая может быть представлена
пользовательские агенты различными способами (например, панель инструментов с раскрывающимся меню
ссылки).
В отличие от A , он может появиться только в HEAD .
раздел документа, хотя он может появляться любое количество раз. Хотя ССЫЛКА не имеет содержания, он передает информацию об отношениях, которая может быть представлена
пользовательские агенты различными способами (например, панель инструментов с раскрывающимся меню
ссылки).
В этом примере показано, как несколько определений LINK могут отображаться в HEAD раздел документа. Текущий документ — «Chapter2.html». отн. атрибут определяет отношение связанного документа с текущим документ. Значения «Index», «Next» и «Prev» объясняются в разделе по типам ссылок.
<ГОЛОВА>Глава 2 <ССЫЛКА rel="Предыдущая" href="Глава1.html"> ...остальная часть документа...
12.3.1 Прямые и обратные ссылки
Атрибуты rel и rev играют взаимодополняющие роли — отн. атрибут указывает прямую ссылку, а атрибут rev указывает обратную ссылка на сайт.
Рассмотрим два документа A и B.
Документ А:
Имеет то же значение, что и:
.Документ Б:
Оба атрибута могут быть указаны одновременно.
12.3.2 Ссылки и внешние таблицы стилей
Когда ССЫЛКА элемент связывает внешнюю таблицу стилей с документом, Атрибут type определяет язык таблицы стилей и тип . Атрибут media указывает предполагаемый носитель или носитель рендеринга. Пользовательские агенты могут сэкономить время, извлекая из сети только те листы, которые относятся к текущему устройству.
Типы носителей далее
обсуждалось в разделе о таблицах стилей.
12.3.3 Ссылки и поисковые системы
Авторы могут использовать LINK для предоставления разнообразной информации поисковые системы, в том числе:
- Ссылки на альтернативные версии документа, написанные другим человеком язык.
- Ссылки на альтернативные версии документа, предназначенные для разных носителей, например, версия, специально подходящая для печати.
- Ссылки на стартовую страницу сборника документов.
В приведенных ниже примерах показано, как информация о языке, типах мультимедиа и типы ссылок могут быть объединены для улучшения обработки документов поисковыми системами.
В следующем примере мы используем атрибут hreflang , чтобы сообщить поиску
Engines, где можно найти версии документа на голландском, португальском и арабском языках.
Обратите внимание на использование атрибута charset для арабского руководства. Обратите также внимание на
использование lang , чтобы указать, что значение заголовка Атрибут элемента LINK , обозначающий руководство на французском языке, указан на французском языке.
<ГОЛОВА>Руководство на английском языке
В следующем примере мы сообщаем поисковым системам, где найти вариант руководства.
<ГОЛОВА>Справочное руководство com/manual/postscript.ps">
В следующем примере мы сообщаем поисковым системам, где найти переднюю страница сборника документов.
<ГОЛОВА>Справочное руководство -- стр. 5
Дополнительная информация приведена в примечаниях к приложению о том, как помочь поисковым системам проиндексировать ваш веб-сайт. сайт.
12.4 Информация о пути:
БАЗА элементBASE - O EMPTY -- URI базы документов --> href %URI; #REQUIRED -- URI, который действует как базовый URI -- >
Начальный тег: требуется , Конечный тег: запрещено
Определения атрибутов
- href = uri [CT]
- Этот атрибут указывает абсолютный URI, который действует как базовый URI для
разрешение относительных URI.

Атрибуты, определенные в другом месте
- цель (цель информация о кадре)
В HTML ссылки и ссылки на внешние изображения, апплеты, обработку форм программы, таблицы стилей и т. д. всегда указываются с помощью URI. Относительные URI разрешается в соответствии с базовым URI, который может поступать из разных источников. Элемент BASE позволяет авторам явно указывать базовый URI документа.
При наличии Элемент BASE должен появиться в HEAD раздел HTML-документа перед любым элементом, ссылающимся на внешний источник. Информация о пути, указанная элементом BASE , влияет только на URI в документ, в котором появляется элемент.
Например, учитывая следующее объявление BASE и A декларация:
<ГОЛОВА>Наши продукты aviary.com/products/intro.html"> <ТЕЛО>
Вы видели наши клетки для птиц?
{kind=link}
относительный URI «../cages/birds.gif» будет разрешаться в:
http://www.aviary.com/cages/birds.gif
12.4.1 Разрешение относительных URI
Пользовательские агенты должны вычислять базовый URI для разрешения относительных URI. согласно [RFC1808], раздел 3. Ниже описано, как [RFC1808] относится конкретно к HTML.
Пользовательские агенты должны вычислять базовый URI в соответствии со следующим приоритеты (от наивысшего приоритета к низшему):
- Базовый URI задается Элемент BASE .
- Базовый URI определяется метаданными, обнаруженными во время протокола взаимодействие, например заголовок HTTP (см. [RFC2616]).
- По умолчанию базовым URI является URI текущего документа. Не весь HTML
документы имеют базовый URI (например, действительный HTML-документ может появиться в электронном письме
и не может обозначаться URI).
 Такие HTML-документы считаются
ошибочны, если они содержат относительные URI и полагаются на базовый URI по умолчанию.
Такие HTML-документы считаются
ошибочны, если они содержат относительные URI и полагаются на базовый URI по умолчанию.
Кроме того, 9Элементы 0218 OBJECT и APPLET определяют атрибуты, которые имеют приоритет над значением, установленным элементом BASE . Пожалуйста, проконсультируйтесь с определения этих элементов для получения дополнительной информации о проблемах URI, характерных для их.
Примечание. Для версий HTTP, определяющих заголовок Link, пользовательские агенты должны обрабатывать эти заголовки точно так же, как LINK элементы в документе. HTTP 1.1, как определено в [RFC2616], не включить поле заголовка Link (см. раздел 19.6.3).
предыдущий следующий содержимое элементы атрибуты индекс
html tutorial — атрибут rel в HTML — html5 — html-код — html-форма — In 30Sec by Microsoft Award MVP —
Learn html — руководство по html — атрибут Rel в html — примеры html — программы html
- Атрибут rel используется для указания отношения между связанным документом и текущим документом.
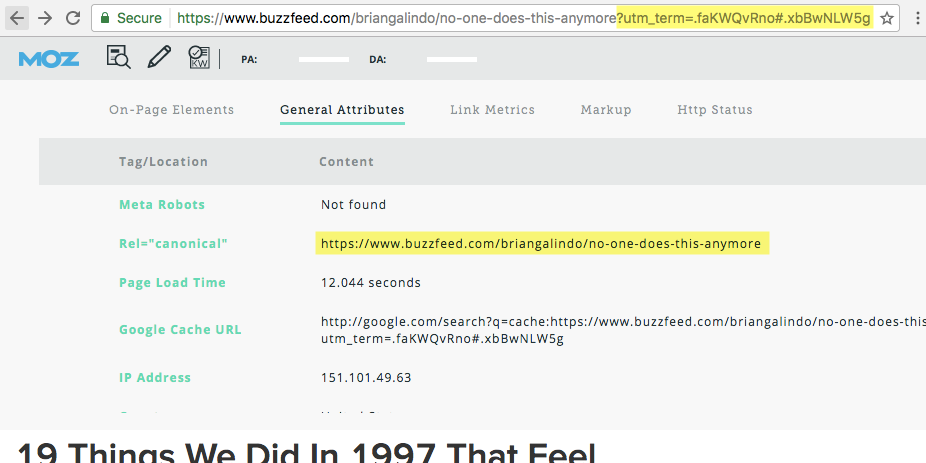
Синтаксис атрибута rel в HTML:
Разница между HTML 4.01 и HTML 5 для атрибута rel:
HTML 4.01
- HTML 4 поддерживает некоторые значения в rel атрибут.
HTML 5
- Некоторые значения удалены, а некоторые добавлены в HTML 5.
Применяется к:
Значения атрибутов rel:
| Значение | Описание |
|---|---|
| авто | Для загрузки всего медиафайла при загрузке страницы. |
| альтернативный | Предоставляет ссылку на альтернативное представление документа (например, печатную страницу, переведенное или зеркальное отображение) |
| альтернативный | Ссылки на альтернативную версию документа (например, печатную страницу, переведенную или зеркальную) |
| автор | Предоставляет ссылку на автора документа |
| закладка | Постоянный URL-адрес, используемый для создания закладок |
| предварительная выборка DNS | Указывает, что браузер должен упреждающе выполнять разрешение DNS для источника целевого ресурса |
| внешний | Указывает, что документ, на который делается ссылка, не является частью того же сайта, что и текущий документ |
| помощь | Предоставляет ссылку на справочный документ |
| значок | Импортирует значок для представления документа. |
| лицензия | Предоставляет ссылку на информацию об авторских правах для документа |
| следующий | Предоставляет ссылку на следующий документ в серии |
| nofollow | Ссылки на неутвержденный документ, например платная ссылка. |
| ноупер | Требует, чтобы любой контекст просмотра, созданный путем перехода по гиперссылке, не имел открывающего контекст просмотра |
| нереферер | Требует, чтобы браузер не отправлял заголовок реферера HTTP, если пользователь переходит по гиперссылке |
| пингбэк | Предоставляет адрес сервера проверки связи, который обрабатывает обратную связь с текущим документом |
| предварительное соединение | Указывает, что браузер должен заблаговременно подключаться к источнику целевого ресурса. |
| предварительная выборка | Указывает, что целевой документ должен быть кэширован |
| предварительная выборка | Указывает, что браузер должен упреждающе извлекать и кэшировать целевой ресурс, поскольку он может потребоваться для последующей навигации |
| предварительная нагрузка | Указывает, что агент браузера должен упреждающе извлекать и кэшировать целевой ресурс для текущей навигации в соответствии с пунктом назначения, заданным атрибутом «как» (и приоритетом, связанным с этим пунктом назначения). |
| предыд. | Указывает, что документ является частью серии и что предыдущий документ в серии является ссылочным документом |
| поиск | Предоставляет ссылку на ресурс, который можно использовать для поиска в текущем документе и связанных с ним страницах. |
| таблица стилей | Импорт таблицы стилей |
| бирка | Тег (ключевое слово) для текущего документа |
Пример кода для атрибута rel в HTML:
Tryit
<голова>
Атрибут Wikitechy rel
<тело>
Регистрация в Wikitechy
Код Пояснение для атрибута rel в HTML:
- Этот атрибут rel используется для указания отношения к связанному документу.
- «nofollow» используется для указания поисковой системе не переходить по ссылке.
Вывод для атрибута rel в HTML:
- Вывод показывает, что ссылка на «Wikitechy SignUp» . Что целевая страница не отслеживается поисковой системой.
Поддержка браузером атрибута rel в HTML:
| Да | Да | Да | Да | Да |
Поиски, связанные с атрибутом rel в html
rel Атрибут таблица стилей html отн. css html5 относительный атрибут относительный предел воздействия отн. nofollow html rel означает в html? ссылка отн. относительные значения атрибутов html tutorialshtml редактор html код html форма html учебник html цвет html цветовые коды html таблица html html img html5 html код для сайта html и css html программы html сайт бесплатный html редактор html5 учебник wysiwyg html редактор html учебник pdf html конвертер php учебник html пример html учебник css учебник html css html теги html основы кода html html онлайн html mailto html lang список html тегов HTML-атрибуты Мы обнаружили, что вы используете AdBlock Plus или какое-либо другое программное обеспечение для блокировки рекламы, которое препятствует полной загрузке страницы.
У нас нет баннеров, Flash, анимации, неприятных звуков или всплывающих окон. Мы не реализуем эти надоедливые виды рекламы!
Нам нужны деньги для работы сайта, и почти все они поступают от нашей интернет-рекламы.
Добавьте wikitechy.com в белый список блокировки рекламы или отключите программное обеспечение для блокировки рекламы.
×
Атрибуты тега Rel и их влияние на ваш веб-сайт Безопасность и SEO
Если вы занимаетесь контент-маркетингом или просто владеете веб-сайтом, возможно, вы использовали тег rel. Наиболее частая встреча с тегом rel связана с атрибутом «nofollow». Это не что иное, как то, что указывает на то, что вы не связаны с веб-сайтом, с которым вы связались. Хотя на этом история не заканчивается даже для «nofollow». Фактически, становится крайне необходимо увидеть, как эти теги могут быть использованы для ваших преимуществ и как они могут повлиять на ваш сайт. Поэтому, чтобы узнать, как теги rel влияют на безопасность вашего сайта, прочитайте статью ниже.
Что такое атрибуты Rel Tag?
Ну, если вы совсем новичок, то можете и не знать об этом. Хотя разных тегов rel нет, меняется только значение внутри скобки. Значение внутри тега rel, которое используется с вашим тегом привязки, говорит о вашей связи со связанной веб-страницей. Или просто связь, которую вы хотите показать сканеру с этой веб-страницей. Эти значения известны как атрибуты Rel Tag. Симпатичный пример применения тега rel может быть следующим:
P.S: На всякий случай, если вы беспокоитесь о применении этого тега rel тогда я должен сказать вам, что он поддерживается всеми основными платформами просмотра.
Различные атрибуты Rel
Альтернатива: Изначально использование двух отдельных ссылок для веб-сайта и мобильного устройства было обычной практикой. Это было сделано, поскольку мобильные сайты были значительно легче. Хотя, если с вашего мобильного сайта поступает приличное количество трафика, важно определить альтернативный атрибут. Это значение тега rel создаст ассоциацию с вашим настольным и мобильным веб-сайтом. Это означает, что если ваш веб-сайт сканируется, поисковый робот также свяжет мобильную версию с той же картинкой. Например, если вы хотите указать ссылку на YouTube на своей веб-странице, а также хотите включить мобильную версию, ее синтаксис будет следующим:
автор ” href=» [email protected] «> Текст ссылки
Внешний: Это еще один документ, который упоминается на вашем веб-сайте. Предположим, вы хотите упомянуть любой документ, который доступен на каком-то другом веб-сайте, когда вы его используете. Внешнее значение будет просто означать, что это внешний документ, а не часть вашего веб-сайта. Синтаксис этого следующий:
bookmark » href=» www.document-link.com «> Текст документа
Лицензия: Это просто пометка о лицензионной информации о любом документ. Предположим, есть кто-то, кто хочет узнать о лицензионной информации, которая отображается на вашем сайте, тогда это подходящий тег. Его синтаксис следующий:
Nofollow: Очевидно, это один из самых важных существующих атрибутов rel. Если цифровой маркетолог не знает об этом, то он даже не новичок. Это используется всякий раз, когда вы используете внешнюю ссылку на своем веб-сайте, но не хотите ее одобрять. Это останавливает сок SEO вашего сайта, чтобы принести пользу связанному сайту. Атрибут имеет очень большое значение для создания обратных ссылок, которые в конечном итоге влияют на авторитет домена и рейтинг вашего сайта в целом. Синтаксис использования атрибута следующий:
По этой причине «nofollow» обычно используется в URL-адресах многих веб-страниц.
номер ссылки: Всякий раз, когда кто-то размещает внешнюю ссылку на своем веб-сайте, он в основном ссылается на нее. Хотя, если по каким-то причинам не хочется, то можно использовать значение «noreferrer». Например, предположим, что вы размещаете ссылку A на свою веб-страницу и используете «noreferrer», учитывая, что ссылка A является внешней ссылкой на другую веб-страницу. Затем, когда автор ссылается на страницу веб-сайта, будет проверяться на предмет анализа в Google Analytics, показанный трафик не будет связанной категорией, а будет считаться прямым трафиком. Синтаксис его следующий:
Это значение rel служит важной цели для всех, кто серьезно относится к SEO своего сайта. Каноническое значение указывается на главной странице, а ссылка на дублирующую страницу содержимого может быть указана как ссылка. Синтаксис использования атрибута следующий: